迁移学习代码复现
一、前言
说来可能令人难以置信,迁移学习技术在实践中是非常简单的,我们仅需要保留训练好的神经网络整体或者部分网络,再在使用迁移学习的情况下把保留的模型重新加载到内存中,就完成了迁移的过程。之后,我们就可以像训练普通神经网络那样训练迁移过来的神经网络了。
我们使用已经训练好的大型图像分类卷积神经网络来做一个分类任务:区分画面上的动物是蚂蚁还是蜜蜂。
二、数据导入
将蚂蚁蜜蜂数据集进行一些(增强)图形处理,如随机从原始图像中切下来一块224×224大小的区域,随机水平翻转图像,将图像的色彩数值标准化等等。数据增强的目的是:增强模型的鲁棒性,提高模型的泛化能力和性能。
1、导入相应的函数库
# 加载程序所需要的包
#import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import copy
import os
导入蚂蚁蜜蜂数据集,并将这些照片进行一定的照片增强处理,最后以data_loader的形式存储。注:该代码是在kaggle上进行训练,所以data_dir是kaggle中input存储的位置,运行时,需根据具体情况修改文件路径。
# 数据存储总路径
data_dir = '/kaggle/input/bees-and-ants/蚂蚁蜜蜂数据集'
# 图像的大小为224×224
image_size = 224
# 加载的过程将会对图像进行如下增强操作:
# 1. 随机从原始图像中切下来一块224×224大小的区域
# 2. 随机水平翻转图像
# 3. 将图像的色彩数值标准化
train_dataset = datasets.ImageFolder(os.path.join(data_dir, 'train'),transforms.Compose([transforms.RandomResizedCrop(image_size),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]))# 加载校验数据集,对每个加载的数据进行如下处理:
# 1. 放大到256×256
# 2. 从中心区域切割下224×224大小的区域
# 3. 将图像的色彩数值标准化
val_dataset = datasets.ImageFolder(os.path.join(data_dir, 'val'),transforms.Compose([transforms.Resize(256),transforms.CenterCrop(image_size),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]))
# 创建相应的数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size = 4, shuffle = True, num_workers=4)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size = 4, shuffle = True, num_workers=4)
# 读取得出数据中的分类类别数
num_classes = len(train_dataset.classes)
2、展示部分照片
数据存储在train_loader(val_loader)的迭代器中,其中imgs是以数字的形式展示。在 PyTorch 中,图像数据通常以 (C, H, W) 的顺序存储,其中 C 是颜色通道数(例如 RGB 的 3 个通道),H 是图像的高度,W 是图像的宽度。然而,matplotlib 的 imshow 函数期望的图像数据是 (H, W, C) 顺序的,即高度和宽度作为前两个维度,颜色通道作为最后一个维度。所以img_np是通过通道转换后的照片(同时也通过Normalize标准化后的照片),imgs[0][0]是灰度的照片。
imgs,label=next(iter(train_loader))
fig,ax=plt.subplots(1,2,figsize=(12,6))
# 展示标准化后的照片
img_np = imgs[0].permute(1, 2, 0).numpy()
ax[0].imshow(img_np)
# 展示标准化后的照片
ax[1].imshow(imgs[0][0])
plt.show()
原图如下:

图如下:

三、使用自定义的模型进行训练
1、定义模型
自定义卷积神经网络模型,并确定前向传播每层之间的连接方式。
# 使用自定义的CNN模型
depth = [4, 8]
class ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = nn.Conv2d(3, 4, 5, padding = 2) #输入通道为3,输出通道为4,窗口大小为5,padding为2self.pool = nn.MaxPool2d(2, 2) #一个窗口为2*2的pooling运算self.conv2 = nn.Conv2d(depth[0], depth[1], 5, padding = 2) #第二层卷积,输入通道为depth[0], 输出通道为depth[1],窗口为15,padding为2相关文章:
迁移学习代码复现
一、前言 说来可能令人难以置信,迁移学习技术在实践中是非常简单的,我们仅需要保留训练好的神经网络整体或者部分网络,再在使用迁移学习的情况下把保留的模型重新加载到内存中,就完成了迁移的过程。之后,我们就可以像训练普通神经网络那样训练迁移过来的神经网络了。 我们…...
常用命令)
Elasticsearch(ES)常用命令
常用运维命令 一、基本命令1.1、查看集群的健康状态1.2、查看节点信息1.3、查看索引列表1.4、创建索引1.5、删除索引1.6、关闭索引1.7、打开索引1.8、查看集群资源使用情况(各个节点的状态,包括磁盘,heap,ram的使用情况࿰…...

C/C++ 不定参函数
C语言不定参函数 函数用法总结 Va_list 作用:类型定义,生命一个变量,该变量被用来访问传递给不定参函数的可变参数列表用法:供后续函数进调用,通过该变量访问参数列表 typedefchar* va_list; va_start 作用ÿ…...

C语言——函数专题
1.概念 在C语言中引入函数的概念,有些翻译为子程序。C语言中的函数就是一个完成某项特定任务的一小段代码,这个代码是有特殊的写法和调用方法的。一般我们可以分为两种函数:库函数和自定义函数。 2.库函数 C语言国际标准ANSIC规定了一些常…...

springboot打可执行jar包
1. pom文件如下 <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><m…...

【SQL】科目种类
目录 题目 分析 代码 题目 表: Teacher ------------------- | Column Name | Type | ------------------- | teacher_id | int | | subject_id | int | | dept_id | int | ------------------- 在 SQL 中,(subject_id, dept_id) 是该表的主键。 该表…...

【深度学习】【语音】TTS,最新TTS模型概览,扩散模型TTS,MeloTTS、StyleTTS2、Matcha-TTS
文章目录 基础介绍对比基础介绍 MeloTTS: MeloTTS 是 MyShell.ai 开发的一个多语言语音合成模型,支持包括英语、西班牙语、法语、中文、日语和韩语等多种语言。它以高质量的语音合成为特色,尤其擅长处理中英混合内容。该模型优化了在 CPU 上的实时推理能力,使其在多种应用场…...

【论文笔记】LION: Linear Group RNN for 3D Object Detection in Point Clouds
原文链接:https://arxiv.org/abs/2407.18232 简介:Transformer在3D点云感知任务中有二次复杂度,难以进行长距离关系建模。线性RNN则计算复杂度较低,适合进行长距离关系建模。本文提出基于窗口的网络线性组RNN(即对分组…...

打造高可用集群的基石:深度解析Keepalived实践与优化
高可用集群 集群类型 集群类型主要分为负载均衡集群(LB)、高可用集群(HA)和高性能计算集群(HPC)三大类。每种集群类型都有其特定的应用场景和优势。 1. 负载均衡集群(LB) 负载均衡集…...

Web大学生网页作业成品——环保主题介绍网页网站设计与实现(HTML+CSS)(5个页面)
🎉🎉🎉 常见网页设计作业题材有**汽车、环保、明星、文化、国家、抗疫、景点、人物、体育、植物、公益、图书、节日、游戏、商城、旅游、家乡、学校、电影、动漫、非遗、动物、个人、企业、美食、婚纱、其他**等网页设计题目, 可满足大学生网…...

Qt登录窗口设计
widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QIcon> //图标类 #include <QPushButton> #include <QLineEdit> //行编辑 #include <QLabel> #include <QTextEdit> #include <QMovie>class Widge…...

探索数据矿藏:我的AI大模型与数据挖掘实战经验分享
🚀 探索数据矿藏:我的AI大模型与数据挖掘实战经验分享 💖 前言:数据的金矿,AI的翅膀 在人工智能的浪潮中,我有幸作为项目负责人,带领团队深入挖掘数据的潜力,利用AI大模型的力量&am…...

linux C语言strcat函数及相关函数
讯飞星火 strcat函数是C语言中的一个字符串处理函数,用于将一个字符串追加到另一个字符串的末尾。它的原型如下: char *strcat(char *dest, const char *src);参数说明: dest:目标字符串,即要将src字符串追加到这个字符串的末尾。src:源字符串,即要追加到dest字符串末…...

使用 sort 进行文本文件处理
sort 使用经验笔记 一、简介 sort 是一个命令行工具,用于对文本文件中的行进行排序。它广泛应用于 Unix/Linux 系统中,可以用来对文件的内容进行简单的排序操作,也可以与其他命令结合使用来完成更复杂的任务。 二、基本用法 排序文件: sor…...

HarmonyOS笔记4:从云数据库获取数据
移动应用获取数据的方式主要有: 1.从网络中获取数据接口API。 2.从华为云数据库获取云数据库的资源。 3.从移动终端直接获取本地的数据 在HarmonyOS笔记3中已经完成了方式一从网络中获取数据接口API的方式。在本篇笔记中,将讨论从云数据库中获取数据。 因…...
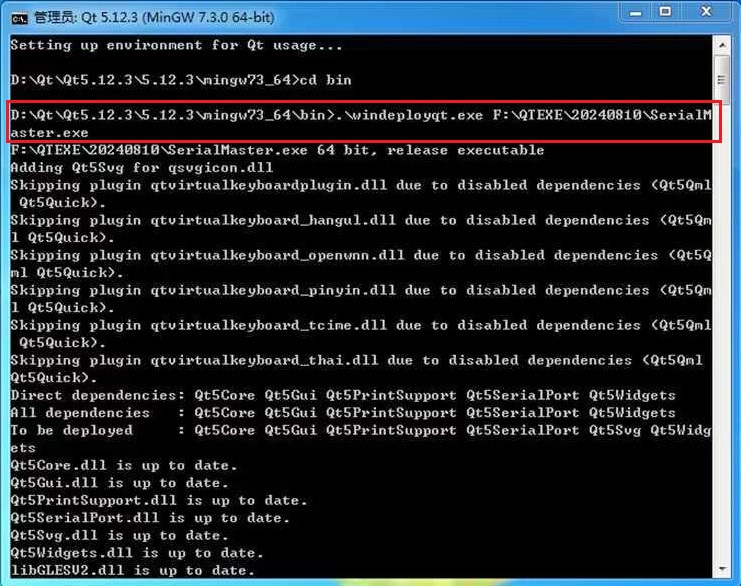
QT5生成独立运行的exe文件
目录 1 生成独立运行的exe文件1.1 设置工程Release版本可执行文件存储路径1.2 将工程编译成Release版本 2 使用QT5自带的windeployqt拷贝软件运行依赖项3 将程序打包成一个独立的可执行软件exe4 解决QT5 This application failed to start because no Qt platform plugin could…...
LabVIEW光纤水听器闭环系统
开发了一种利用LabVIEW软件开发的干涉型光纤水听器闭环工作点控制系统。该系统通过调节光源频率和非平衡干涉仪的光程差,实现了工作点的精确控制,从而提高系统的稳定性和检测精度,避免了使用压电陶瓷,使操作更加简便。 项目背景 …...
)
Shell——流程控制语句(if、case、for、while等)
在 Shell 编程中,流程控制语句用于控制脚本的执行顺序和逻辑。这些语句包括 if、case、for、while 等,它们的使用可以使脚本实现更复杂的逻辑。以下是它们的详细说明和语法结构: 1. if 语句 if 语句用于条件判断,执行符合条件的…...

【redis的大key问题】
在使用 Redis 的过程中,如果未能及时发现并处理 Big keys(下文称为“大Key”),可能会导致服务性能下降、用户体验变差,甚至引发大面积故障。 本文将介绍大Key产生的原因、其可能引发的问题及如何快速找出大Key并将其优…...

HighPoint SSD7749M2:128TB NVMe 存储卡实现28 GB/s高速传输
HighPoint Technologies推出了一款全新的SSD7749M2 RAID卡,能够在标准的桌面工作站中安装多达16个M.2 SSD,实现高达128TB的闪存存储。该卡通过PCIe Gen4 x16接口提供高达28 GB/s的顺序读写性能。这些令人瞩目的性能规格伴随着高昂的价格标签。 #### 技术…...

AI Agents 越智能,企业的人类判断力需求反而会爆炸式增长:Jevons 悖论在企业落地中的隐形反弹
在企业全面拥抱 AI Agents 的当下,最容易被忽略的不是模型能力,而是“智能变便宜”之后带来的责任边界扩张。产品团队让 Agent 自动起草客户邮件、更新工单、标记流失风险、总结销售通话、推荐代码变更、升级支持问题、准备决策材料——每一步都变得前所…...

服务器电源线选购全攻略
5选服务器电源线,接口匹配、电流承载、安全认证、线缆长度、线材材质五大要点缺一不可,劣质线材容易过载发热、烧毁设备,严重还会引发火灾,机房布线一定要选用靠谱的睿阜高品质电源线。先对接口:物理适配是第一关键&am…...

如何3分钟精准定位Windows热键冲突:Hotkey Detective深度技术解析
如何3分钟精准定位Windows热键冲突:Hotkey Detective深度技术解析 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

微软UFO项目:基于视觉大模型的GUI自动化智能体实战解析
1. 项目概述:当“全能”AI助手遇见复杂任务编排 最近在AI应用开发圈里,一个来自微软研究院的项目“UFO”引起了我的注意。这名字听起来挺科幻,全称是“UI-Focused Agent”,直译过来是“专注于用户界面的智能体”。但别被这个直白的…...

MPLAB Harmony 2.0固件框架:从MISRA-C合规到图形化开发的嵌入式开发新范式
1. 项目概述:为什么我们需要一个“全功能”的固件框架?如果你和我一样,在PIC32单片机的世界里摸爬滚打过几年,肯定经历过这样的场景:项目启动,面对Microchip提供的海量外设库、驱动代码和中间件,…...

量子计算中的辛基理论与MBQC实现
1. 量子计算中的辛基基础概念在量子计算领域,辛基(Symplectic Basis)是描述多量子比特系统的重要数学工具。它本质上是一个满足特定对易关系的基组,能够简洁地表示量子态和量子操作。理解辛基需要从有限域上的向量空间开始——具体…...
)
为什么顶尖社会学期刊编辑开始拒收未使用AI辅助验证的民族志推论?(NotebookLM可复现性协议首曝)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM社会学研究辅助 面向质性研究的语义增强工作流 NotebookLM 是 Google 推出的基于用户上传文档进行“可信引用”的 AI 助手,特别适用于社会学研究中对访谈转录稿、田野笔记、政策…...

AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控
AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...

基于CircuitPython与RP2350的嵌入式多声道音频系统设计与实践
1. 项目概述:用CircuitPython打造你的专属交互式音频系统如果你玩过树莓派Pico或者Adafruit的Feather系列开发板,可能会觉得在微控制器上处理音频是件挺麻烦的事——要么得用专门的解码芯片,要么代码复杂得让人头疼。但最近我在一个互动艺术装…...

怎么限制用户上传到MongoDB GridFS的文件总容量
GridFS不支持全局容量配额,需在应用层实现配额校验:上传前聚合查询fs.files中指定用户的length总和,判断是否超限,且须防范并发写入导致的超限问题。GridFS 本身不提供全局容量配额机制MongoDB 的 GridFS 是一个文件分片存储规范&…...