24/8/17算法笔记 MPC算法
MPC算法,在行动前推演一下
MPC(Model Predictive Control,模型预测控制)是一种先进的控制策略,它利用未来预测模型来优化当前的控制动作。MPC的核心思想是,在每一个控制步骤中,都基于当前系统状态的测量值,通过预测模型向前看若干步,并计算出一个使未来输出最优化的控制序列。然后,只应用这个序列的第一个控制动作,并在下一个时间步重复这个过程。
MPC算法的主要特点包括:
-
滚动时域优化:MPC在每一个控制步骤中解决一个有限时间范围内的优化问题,而不是试图直接解决整个控制任务。
-
模型预测:利用系统模型来预测未来的行为。这个模型可以是物理模型,也可以是基于数据的模型。
-
约束处理:MPC可以自然地处理系统的输入和输出约束,例如,限制控制输入的最大和最小值,或者状态变量的运行范围。
-
优化目标:通常包括跟踪预定轨迹、最小化能耗、保证系统稳定性等。
-
反馈校正:由于实际系统与模型之间存在差异,MPC通常会在每个控制周期中使用最新的测量状态来更新预测并重新优化。
MPC算法的一般步骤包括:
-
状态测量:获取当前系统状态的实际测量值。
-
模型预测:使用当前状态和预测模型来预测未来的状态和输出。
-
优化问题设置:定义目标函数和约束条件,设置优化问题。
-
求解优化问题:求解优化问题,得到最优控制序列。
-
应用控制动作:将优化问题的解,即控制序列的第一个控制动作应用到系统上。
-
重复过程:在下一个控制周期,重复上述步骤。
MPC算法广泛应用于化工、石油、交通、航空等众多领域,特别是在需要考虑复杂约束和多步预测的场合。然而,MPC算法的性能在很大程度上依赖于模型的准确性和优化算法的选择。随着计算能力的提升和优化算法的发展,MPC在实际工业应用中的使用越来越广泛。
import gym
#创建环境
env = gym.make('Pendulum-v1')
定义样本池对象
import numpy as np
import torchclass Pool:def __init__(self,limit):#样本池self.datas = []self.limit = limitdef add(self,state,action,reward,next_state,over):if isinstance(state,np.ndarray) or isinstance(state,torch.Tensor):#检查变量 state 是否是 bo.ndarray 或者 torch.Tensor 类型state = state.reshape(3).tolist()action = float(action)reward = float(reward)if isinstance(next_state,np.ndarray) or isinstance(next_state,torch.Tensor):next_state = next_state.reshape(3).tolist()over = bool(over)self.datas.appen((state,action,reward,next_state,over))#数据上限,超出时从最古老的开始删除while len(self.datas)>self.limit:self.datas.pop(0)#获取一批数据样本def get_sample(self):samples = self.datasstate = torch.FloatTensor([i[0] for i in samples]).reshape(-1,3)action = torch.FloatTensor([i[1] for i in samples]).reshape(-1,1)reward = torch.FloatTensor([i[2] for i in samples]).reshape(-1,1) next_state = torch.FloatTensor([i[3]for i in samples]).reshape(-1,3)over = torch.LongTensor([i[4]for i in samples]).reshape(-1,1)input = torch.cat([state,action],dim=1)label = torch.cat([rewarrd,next_state-state],dim=1)return input,labeldef _len_(self):return len(self_datas)初始化样本池,并添加一局游戏的数据
pool = Pool(1000000)#初始化一局游戏的数据
def _():#初始化游戏state = env.reset()#玩到游戏结束为止over = Falsewhile not over:#随机一个动作action = env.action_space.sample()[0]#执行动作,得到反馈next_state,reward,over,_ = env.step([action])#记录数据样本pool.add(state,action,reward,next_state,over)#更新游戏状态,开始下一个动作state = next_state定义主模型
import random
#定义主模型
class Model(torch.nn.Module):#swish激活函数class Swish(torch.nn.Module):def __init__(self):super().__init__()def forward(self,x):return X*torch.sigmoid(x)主模型中的FC层
#定义一个工具层
class FCLayer(torch.nn.Module):def __init__(self,in_size,out_size):super().__init__()self.in_size = in_size#初始化参数std = in_size**0.5std *=2std = 1/stdweight = torch.empty(5, in_size,out_size)torch.nn.init.normal_(weight,mean=0.0,std=std)self.weight = torch.nn.Parameter(weighr)self.bias = torch.nn.Parameter(torch.zeros(5,1,out_size))def forward(self,x):x = torch.bmm(x,self.weight)x = x+self.biasreturn x主模型初始化函数
def __init__(self):super().__init__()self.sequential = torch.nn.Sequential(self.FCLayer(4,200), #全连接层(线性层)self.Swish(), #激活函数层self.FCLayer(200,200),self.Swish(),self.FCLayer(200,200),self.Swish(), self.FCLayer(200,200),self.Swish(),self.FCLayer(200,8),torch.nn.Identity(),)self.softplus = torch.nn.Softplus() #Softplus 是一个平滑的ReLU激活函数self.optimizer = torch.optim.Adam(self.parameters(),lr=1e-3)主模型计算过程,计算结果是一个均值和log方差,对logvar的加减操作是为了调整logvar的最大最小值
def forward(self,x):x = self.sequential(x)mean = x[...,:4]logvar = x[...,4:]logvar = 0.5 - logvarlogva = 0.5 -self.softplus(logvar)logvar = logvar+10logvar = self.softplus(logvar)-10return mean,logvar主模型的训练函数
def train(self,input,label):#反复训练N次for _ in range(len(input)//64*20):#从全量数据中抽样64个,反复抽5遍,形成5份数据select = [torch.randperm(len(input))[:64] for _ in range(5)]select =torch.stack(select)input_select = input[select]label_select = label[select]del select#模型计算mean,logvar = model(input_select)#计算lossmse_loss = (mean - label_select)**2*(-logvar).exp()mse_loss = mse_loss.mean(dim=1).mean()var_loss+logvar.mean(dim=1).mean()loss =mse_loss+var_lossself.optimizer.zero_grad()loss.backward()self.optimizer.step()初始化主模型
model = Model()a,b = model(torch.randn(5,64,4))
a.shape,b.shapeMPC fake step函数,功能是根据state和action估计reward和next_state
class MPC:def _fake_step(self,state,action):input = torch.cat([state,action],dim=1)#重复5遍input = input.unsqueeze(dim=0).repeat([5,1,1])#模型计算with torch.no_grad():mean,std = model(input)std = std.exp().sqrt()del input#means的后3列加上环境数据mean[:,:,1:]+=state#重采样sample = torch.distributions.Normal(0,1).sample(mean.shape)#0-4的值域采样b个元素select = [random.choice(range(5))for _ in range(mean.shape[1])]#重采样结果,第0个维度,0-4随机选择,第二个维度,0-b顺序选择sample = sample[select,range(mean.shape[1])]#切分一下,就成了rewards,next_statereward,next_state = sample[:,:1],sample[:,1:]return reward,next_stateMPC cem优化函数,虚拟N条动作链,并优化M次,求与孤寂结果最佳的分布
def _cem_optimizer(self,state,mean):state = torch.FloatTensor(state).reshape(1,3)var = torch.ones(25)#当前游戏的环境信息,复制50次state = state.repeat(50,1)#循环5次,寻找最优解for _ in range(5):#采样50个标准正态分布数据作为actionactions = torch.distributions.Normal(0,1).sample([50,25])#乘以标准差,加上均值actions *=var**0.5actions +=mean#计算每条动作序列的累计奖励reward_sum = torch.zeros(50,1)#遍历25个动作for i in range(25):action = actions[:,i].unsqueeze(dim=1)#现在是不能真的去玩游戏的,只能去预测reward和next_statereward,next_state = self._fake_step(state,action)reward_sum += rewardstate = next_state#按照reward_sum从小到大排序select = torch.sort(reward_sum.squeeze(dim=1)).indicesactions = actions[select]del select#取发聩最优的10个动作链actions = actions[-5:]#在下一次随机动作时,希望贴近这些动作的分布new_mean = actions.mean(dim= 0)new_var = actions.var(dim=0)#增量更新mean = 0.1*mean +0.9*new_meanvar = 0.1*var+0.9*new_varreturn meanMPC mpc函数,每次动作都预演N次,求预演结果最佳的分布
def mpc(self):#初始化动作的分布均值都是0mean = torch.zeros(25)reward_sum = 0state = env.reset()over = Falsewhile not over:#当前状态下,找25个最优都知道均值actions = self._cem_optimize(state,mean)#执行第一个动作action = actions[0].item()#执行动作next_state,reward,over,_ = env.step([action])#增加数据pool.add(state,action,reward,next_state,over)state = next_statereward_sum +=reward#下个动作的均值,在当前动作均值的基础上寻找mean = torch.empty(actions.shape)mean[:-1] = actions[1:]mean[-1] = 0return reward_sum初始化MPC对象
mpc = MPC()
a,b = mpc._fake_step(torch.randn(200,3),torch.randn(200,1))
print(a.shape,b.shape)
print(mpc._cem_optimize(torch.randn(1,3),,torch.zeros(25)).shape)训练
for i in range(10):input,label = pool.get_sample()model.train(input,label)reward_sum = mpc.mpc()print(i,len(pool),reward_sum)相关文章:

24/8/17算法笔记 MPC算法
MPC算法,在行动前推演一下 MPC(Model Predictive Control,模型预测控制)是一种先进的控制策略,它利用未来预测模型来优化当前的控制动作。MPC的核心思想是,在每一个控制步骤中,都基于当前系统状…...

GROUP_CONCAT 用法详解(Mysql)
GROUP_CONCAT GROUP_CONCAT 是 MySQL 中的一个聚合函数,用于将分组后的多行数据连接成一个单一的字符串。 通常用于将某个列的多个值合并到一个字符串中,以便更方便地显示或处理数据。 GROUP_CONCAT([DISTINCT] column_name[ORDER BY column_name [ASC…...

Golang httputil 包深度解析:HTTP请求与响应的操控艺术
标题:Golang httputil 包深度解析:HTTP请求与响应的操控艺术 引言 在Go语言的丰富标准库中,net/http/httputil包是一个强大的工具集,它提供了操作HTTP请求和响应的高级功能。从创建自定义的HTTP代理到调试HTTP流量,h…...

SQLALchemy 分页
SQLALchemy 分页 1. 使用SQLAlchemy的`slice`和`offset`/`limit`SQLAlchemy 1.4及更新版本SQLAlchemy 1.3及更早版本使用第三方库注意事项在Web开发中,分页是处理大量数据时一个非常重要的功能。SQLAlchemy是一个流行的Python SQL工具包和对象关系映射(ORM)库,它允许开发者…...

快速上手体验MyPerf4J监控springboot应用(docker版快速开始-本地版)
使用MyPerf4J监控springboot应用 快速启动influxdb时序数据库日志收集器telegrafgrafana可视化界面安装最终效果 项目地址 项目简介: 一个针对高并发、低延迟应用设计的高性能 Java 性能监控和统计工具。 价值 快速定位性能瓶颈快速定位故障原因 快速启动 监控本地应用 idea配…...

C语言 之 strlen、strcpy、strcat、strcmp字符串函数的使用和模拟实现
文章目录 strlen的使用和模拟实现函数的原型strlen模拟实现:方法1方法2方法3 strcpy的使用和模拟实现函数的原型strcpy的模拟实现: strcat的使用和模拟实现函数的原型strcat的模拟实现: strcmp的使用和模拟实现函数的原型strcmp的模拟实现 本…...
)
CAPL使用结构体的方式组装一条DoIP车辆识别请求报文(payload type 0x0002)
DoIP车辆识别请求(payload type 0x0002)报文的格式为: /******************************************************** +--------+--------+--------+--------+ |version | inVer | type | +--------+--------+--------+--------+ | length …...

数据接入教学
数据接入教学 1、开通外部网络策略2、检查本地防火墙策略3、测试网络连通性4、工具抓包命令5、本地测试发送与监听 1、开通外部网络策略 保证外部网络联通、保证内部防火墙开通策略(可以关闭进行测试) 2、检查本地防火墙策略 关闭进行测试 停止firewa…...

炒作将引发人工智能寒冬
我们似乎经常看到人工智能的进步被吹捧为机器真正变得智能的一大飞跃。我将在这里挑选其中的一个例子,并确切解释为什么这种态度会为人工智能的未来埋下隐患。 这很酷,这是一个非常困难且非常具体的问题,这个团队花了3 年时间才解决。他们一定…...
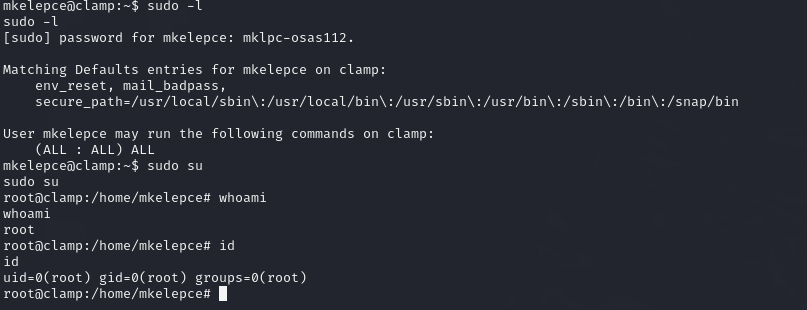
clamp靶机复现
靶机设置 设置靶机为NAT模式 靶机IP发现 nmap 192.168.112.0/24 靶机IP为192.168.112.143 目录扫描 dirsearch 192.168.112.143 访问浏览器 提示让我们扫描更多的目录 换个更大的字典,扫出来一个 /nt4stopc/ 目录 目录拼接 拼接 /nt4stopc/ 发现页面中有很多…...

mfc100u.dll丢失问题分析,详细讲解mfc100u.dll丢失解决方法
面对mfc100u.dll文件丢失带来的挑战时,许多用户都可能感到有些无助,尤其是当这一问题影响到他们日常使用的软件时。但实际上,存在几种有效方法可以帮助您快速恢复该关键的系统文件。为了方便不同水平的用户,本文将详细解析各种处理…...

【C++】什么是内存管理?
如果有不懂的地方,可以看我以往文章哦! 个人主页:CSDN_小八哥向前冲 所属专栏:C入门 目录 C/C内存分布 C内存管理方式 new/delete操作内置类型 new/delete操作自定义类型 operator new与operator delete函数 new和delete实现…...

产业经济大脑建设方案(五)
为了提升产业经济的智能化水平,我们提出建设一个综合产业经济大脑系统,该系统通过整合大数据分析、人工智能和云计算技术,构建全方位的数据采集、处理和决策支持平台。该平台能够实时监测产业链各环节的数据,运用智能算法进行深度…...

如何在 Odoo 16 中覆盖创建、写入和取消链接方法
Odoo 是一款强大的开源业务应用程序套件,可为各种业务运营提供广泛的功能。其主要功能之一是能够自定义和扩展其功能以满足特定的业务需求。在本博客中,我们将探讨如何覆盖Odoo 16中的创建、写入和取消链接方法,从而使您无需修改核心代码…...

pip离线安装accelerate
一、离线下载到当前文件夹 pip download accelerate -d ./anzhuangbao# 制定版本使用以下命令pip download accelerate0.32.0 -d ./anzhuangbao二、离线安装 cd anzhuangbaipip install --no-index --find-links. accelerate三、验证是否安装 pip show accelerateAccelerate: …...

VUE3请求意外报跨越错误或者500错误问题
1.有可能是请求传参和传参类型写错了 首先要确保该请求接口是支持跨域的(不支持叫后端改) access-control-allow-headers:Content-Type, Accept, Access-Control-Allow-Origin, api_key, Authorization access-control-allow-methods:GET, POST, OPTIO…...

vue 关于两个if条件中的promise
一、案例效果 期望if判断条件里的两个promise 都同时执行完成 二、 初始代码案例 const formatDetail async (fnArgsJsonParams: MapLogicType) > {if (fnArgsJsonParams?.targetFeatureName) {const resDetailData await formatFeatureInfo(fnArgsJsonParams.targetF…...

C/C++移位运算问题
目录 上期答案揭晓: 回忆: 问题1展现: 问题2展现: 改进方案: 下期预告:C语言类型转换的问题。 上期答案揭晓: 上期的问题大家是否都有了想法,下面说说我的思路。 上次我们提到…...

录屏工具 Icecream Screen Recorder PRO v7.41
Icecream Screen Recorder的免费屏幕录制工具,具备捕捉视频、音频、图片和游戏等多种功能。以前推荐过的icecreamPDF也是他家的非常好用! 下载链接:「录屏」来自UC网盘分享https://drive.uc.cn/s/b474616b91534...

解决连接不上Linux和服务器中的Nacos(Windows中能连接但是Linux中却不行)
报错 com.alibaba.nacos.shaded.io.grpc.StatusRuntimeException: UNKNOWN: Uncaught exception in the SynchronizationContext. Re-thrown. at com.alibaba.nacos.shaded.io.grpc.Status.asRuntimeException(Status.jav 2024-08-13T10:21:52.93708:00 ERROR 27764 --- …...

新手避坑指南:你的FPGA按键消抖仿真为什么和板子对不上?
FPGA按键消抖实战:从仿真完美到真实失效的深度排查手册 刚接触FPGA开发的工程师常会遇到一个诡异现象:按键消抖模块在ModelSim里跑得风生水起,波形干净漂亮,可一旦下载到开发板就各种失灵——要么按键没反应,要么按一次…...

Perplexity搜索功能隐藏入口全解锁:9个未公开Pro技巧,第7个连官方文档都没写!
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索功能隐藏入口全解锁:现象与价值重估 Perplexity.ai 的公开界面长期以简洁问答框为核心,但其底层实际嵌套了多组未在UI中显式暴露的高级搜索能力——包括语义过滤、…...
)
保姆级教程:用TensorFlow 2.x和EfficientNetB0搞定CASIA-HWDB手写汉字识别(附完整代码)
从零构建手写汉字识别系统:TensorFlow 2.x与EfficientNetB0实战指南 在数字化办公场景中,手写体识别技术正逐渐成为提升效率的隐形助手。无论是银行票据处理、教育作业批改还是历史档案数字化,准确识别手写汉字的能力都显得尤为重要。本文将带…...

Linux下MT7601 USB无线网卡驱动编译与网络配置全攻略
1. 项目概述:从零构建一个可用的USB无线网卡最近在折腾一个基于老旧工控板的自制家庭服务器项目,手头正好有一块闲置的、芯片方案为MT7601的USB无线网卡。在Linux系统下,这类第三方芯片的网卡往往不像Intel、Realtek那样有完善的内核原生支持…...

2026年4K投影仪画质横评:明基W系列“色彩科学”解析
一、开篇点题:画质之争,终归是色彩之争2026年的4K投影仪市场,参数竞赛已进入白热化。当分辨率、亮度、对比度等硬指标逐渐趋同,真正拉开产品差距的,是那个决定画面灵魂的核心——色彩。一台投影仪能否精准还原电影导演…...

如何3步在Mac上运行Windows软件:Whisky终极免费方案
如何3步在Mac上运行Windows软件:Whisky终极免费方案 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在Mac上运行Windows软件却不想安装虚拟机?Whisky正是你…...

百度网盘直链解析:5分钟实现全速下载的完整指南
百度网盘直链解析:5分钟实现全速下载的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘蜗牛般的下载速度而烦恼吗?今天我要向你…...

从LMS到BLMS:自适应滤波的‘批处理’思想如何解决工程中的收敛难题?
从LMS到BLMS:批处理思想如何重塑自适应滤波的工程实践 在实时信号处理领域,工程师们常常面临一个经典困境:算法响应速度与系统稳定性能之间的微妙平衡。想象一下,当你正在调试一套语音降噪系统时,每次麦克风接收到一个…...

大模型应用开发:从需求分析到上线的全流程指南
一、需求分析:锚定测试视角下的开发方向对于软件测试从业者而言,大模型应用开发的需求分析阶段,核心是跳出传统功能测试的思维局限,从“验证功能正确性”转向“定义AI能力边界”。首先要明确业务场景的核心诉求,比如开…...

推荐五家SF6在线监测报警系统
在有六氟化硫气体存在的场所,如小区配电室、变电站、电厂等,SF6在线监测报警系统起着至关重要的作用。它能实时监测现场气体浓度,在浓度超标时第一时间发出报警信号,及时消除隐患。今天就为大家推荐五家SF6在线监测报警系统品牌&a…...