大数据技术——实战项目:广告数仓(第六部分)报表数据导出至clickhouse
目录
第11章 报表数据导出
11.1 Clickhouse安装
11.2 Clickhouse建表
11.2.1 创建database
11.2.2 创建table
11.3 Hive数据导出至Clickhouse
第11章 报表数据导出
由于本项目最终要出的报表,要求具备交互功能,以及进行自助分析的能力,所以为保证数据分析的最大灵活度,我们需要提供明细数据。
上述描述对计算引擎提出来了两点要求:
第一点:延迟低,交互式的自助分析,一般都要求低延时。
第二点:支持的数据量大:由于需要计算明细数据,所说数据量相对较大。
综合考虑:我们选择使用clickhouse作为分析引擎。
11.1 Clickhouse安装
Clickhouse的安装和使用可参考以下博客。
大数据技术—— Clickhouse安装-CSDN博客
11.2 Clickhouse建表
11.2.1 创建database
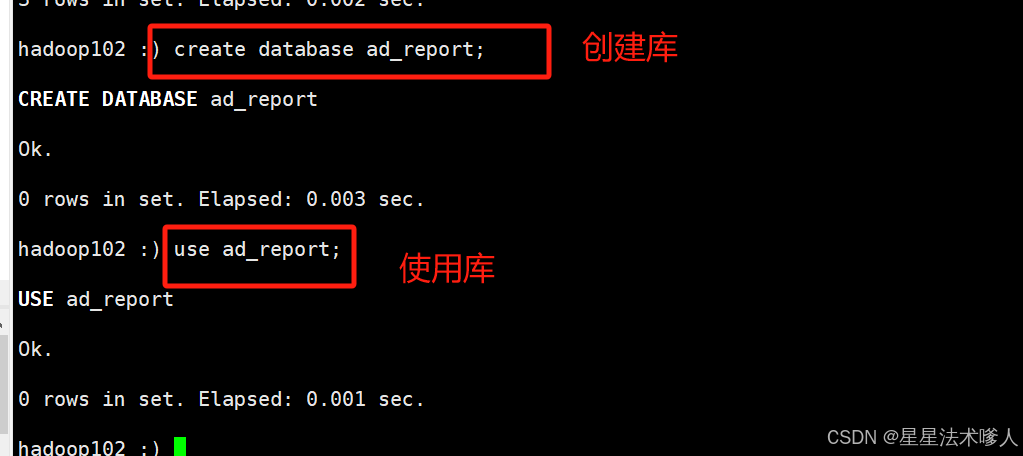
需要先启动hiveserver2,并执行clickhouse-client -m连接server
hadoop102 :)
create database ad_report;
use ad_report;
11.2.2 创建table
drop table if exists dwd_ad_event_inc;
create table if not exists dwd_ad_event_inc
(event_time Int64 comment '事件时间',event_type String comment '事件类型',ad_id String comment '广告id',ad_name String comment '广告名称',ad_product_id String comment '广告产品id',ad_product_name String comment '广告产品名称',ad_product_price Decimal(16, 2) comment '广告产品价格',ad_material_id String comment '广告素材id',ad_material_url String comment '广告素材url',ad_group_id String comment '广告组id',platform_id String comment '推广平台id',platform_name_en String comment '推广平台名称(英文)',platform_name_zh String comment '推广平台名称(中文)',client_country String comment '客户端所处国家',client_area String comment '客户端所处地区',client_province String comment '客户端所处省份',client_city String comment '客户端所处城市',client_ip String comment '客户端ip地址',client_device_id String comment '客户端设备id',client_os_type String comment '客户端操作系统类型',client_os_version String comment '客户端操作系统版本',client_browser_type String comment '客户端浏览器类型',client_browser_version String comment '客户端浏览器版本',client_user_agent String comment '客户端UA',is_invalid_traffic UInt8 comment '是否是异常流量'
) ENGINE = MergeTree()ORDER BY (event_time, ad_name, event_type, client_province, client_city, client_os_type,client_browser_type, is_invalid_traffic);
11.3 Hive数据导出至Clickhouse
本项目使用spark-sql查询数据,然后通过jdbc写入Clickhouse,具体操作如下:
1)创建Maven项目,pom.xml文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu</groupId><artifactId>ad_hive_to_clickhouse</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><!-- 引入mysql驱动,目的是访问hive的metastore元数据--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.31</version></dependency><!-- 引入spark-hive模块--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.3.1</version><scope>provided</scope></dependency><!--引入clickhouse-jdbc驱动,为解决依赖冲突,需排除jackson的两个依赖--><dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.2.4</version><exclusions><exclusion><artifactId>jackson-databind</artifactId><groupId>com.fasterxml.jackson.core</groupId></exclusion><exclusion><artifactId>jackson-core</artifactId><groupId>com.fasterxml.jackson.core</groupId></exclusion></exclusions></dependency><!-- 引入commons-cli,目的是方便处理程序的输入参数 --><dependency><groupId>commons-cli</groupId><artifactId>commons-cli</artifactId><version>1.2</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><!--将依赖编译到jar包中--><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><!--配置执行器--><execution><id>make-assembly</id><!--绑定到package执行周期上--><phase>package</phase><goals><!--只运行一次--><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>2)创建com.atguigu.ad.spark.HiveToClickhouse类,并编辑如下内容
package com.atguigu.ad.spark;import org.apache.commons.cli.*;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;public class HiveToClickhouse {public static void main(String[] args) {// 使用common-cli处理传入参数// 1 定义能够传入哪些参数Options options = new Options();options.addOption(OptionBuilder.withLongOpt("hive_db").withDescription("hive数据库名称(required)").hasArg(true).isRequired(true).create());options.addOption(OptionBuilder.withLongOpt("hive_table").withDescription("hive表名称(required)").hasArg(true).isRequired(true).create());options.addOption(OptionBuilder.withLongOpt("hive_partition").withDescription("hive分区(required)").hasArg(true).isRequired(true).create());options.addOption(OptionBuilder.withLongOpt("ck_url").withDescription("clickhouse的jdbc url(required)").hasArg(true).isRequired(true).create());options.addOption(OptionBuilder.withLongOpt("ck_table").withDescription("clickhouse表名称(required)").hasArg(true).isRequired(true).create());options.addOption(OptionBuilder.withLongOpt("batch_size").withDescription("数据写入clickhouse时的批次大小(required)").hasArg(true).isRequired(true).create());// 2 解析参数GnuParser gnuParser = new GnuParser();CommandLine cmd = null;try {cmd = gnuParser.parse(options, args);} catch (ParseException e) {e.printStackTrace();return;}// 创建spark-sql环境SparkConf conf = new SparkConf().setAppName("HiveToClickhouse");SparkSession sparkSession = SparkSession.builder().enableHiveSupport().config(conf).getOrCreate();// 读取hive中的数据//5.设置如下参数,支持使用正则表达式匹配查询字段sparkSession.sql("set spark.sql.parser.quotedRegexColumnNames=true");Dataset<Row> dataset = sparkSession.sql("" +"select `(dt)?+.+` from " + cmd.getOptionValue("hive_db") + "." + cmd.getOptionValue("hive_table") + " where dt='" + cmd.getOptionValue("hive_partition") + "'");// 写入到clickhouse中dataset.write().format("jdbc").mode(SaveMode.Append).option("url",cmd.getOptionValue("ck_url")).option("driver","ru.yandex.clickhouse.ClickHouseDriver").option("dbtable",cmd.getOptionValue("ck_table")).option("batch_size",cmd.getOptionValue("batch_size")).save();sparkSession.close();}}
3)上传hive-site.xml、文件到项目的resource目录下
4)打包,并上传xxx-jar-with-dependencies.jar到hadoop102节点/opt/module/spark
5)执行如下命令测试
spark-submit \
--class com.atguigu.ad.spark.HiveToClickhouse \
--master yarn \
ad_hive_to_clickhouse-1.0-SNAPSHOT-jar-with-dependencies.jar \
--hive_db ad \
--hive_table dwd_ad_event_inc \
--hive_partition 2023-01-07 \
--ck_url jdbc:clickhouse://hadoop102:8123/ad_report \
--ck_table dwd_ad_event_inc \
--batch_size 1000
6) 在clickhouse中运行select * from dwd_ad_event_inc; ,可看到数据已经导入clickhouse
注意事项:
(1)本地安装的Spark,需由原来数仓安装的纯净版,替换为:
https://archive.apache.org/dist/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
(2)为保证之前数仓的hive on spark环境可继续使用,需要在$HIVE_HOME/conf/spark-defaults.conf中增加如下参数:
spark.yarn.populateHadoopClasspath true
增加原因如下:
Running Spark on YARN - Spark 3.5.2 Documentation
(3)为保证任务可提交到yarn运行,需在$SPARK_HOME/conf/spark-env.sh文件中增加如下参数:
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop/
我们此项目安装的不是纯净版,所以不需要执行此操作。
前面章节:
大数据项目——实战项目:广告数仓(第一部分)-CSDN博客
大数据项目——实战项目:广告数仓(第二部分)-CSDN博客
大数据技术——实战项目:广告数仓(第三部分)-CSDN博客
大数据技术——实战项目:广告数仓(第四部分)-CSDN博客
大数据技术——实战项目:广告数仓(第五部分)-CSDN博客
相关文章:
大数据技术——实战项目:广告数仓(第六部分)报表数据导出至clickhouse
目录 第11章 报表数据导出 11.1 Clickhouse安装 11.2 Clickhouse建表 11.2.1 创建database 11.2.2 创建table 11.3 Hive数据导出至Clickhouse 第11章 报表数据导出 由于本项目最终要出的报表,要求具备交互功能,以及进行自助分析的能力,…...

Android studio模拟制作-简易的订餐交易小案例
一、最终呈现效果 订餐支付小案例效果 二、布局设计activity_main.xml <?xml version"1.0" encoding"utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android"http://schemas.android.com/apk/res/android"xml…...
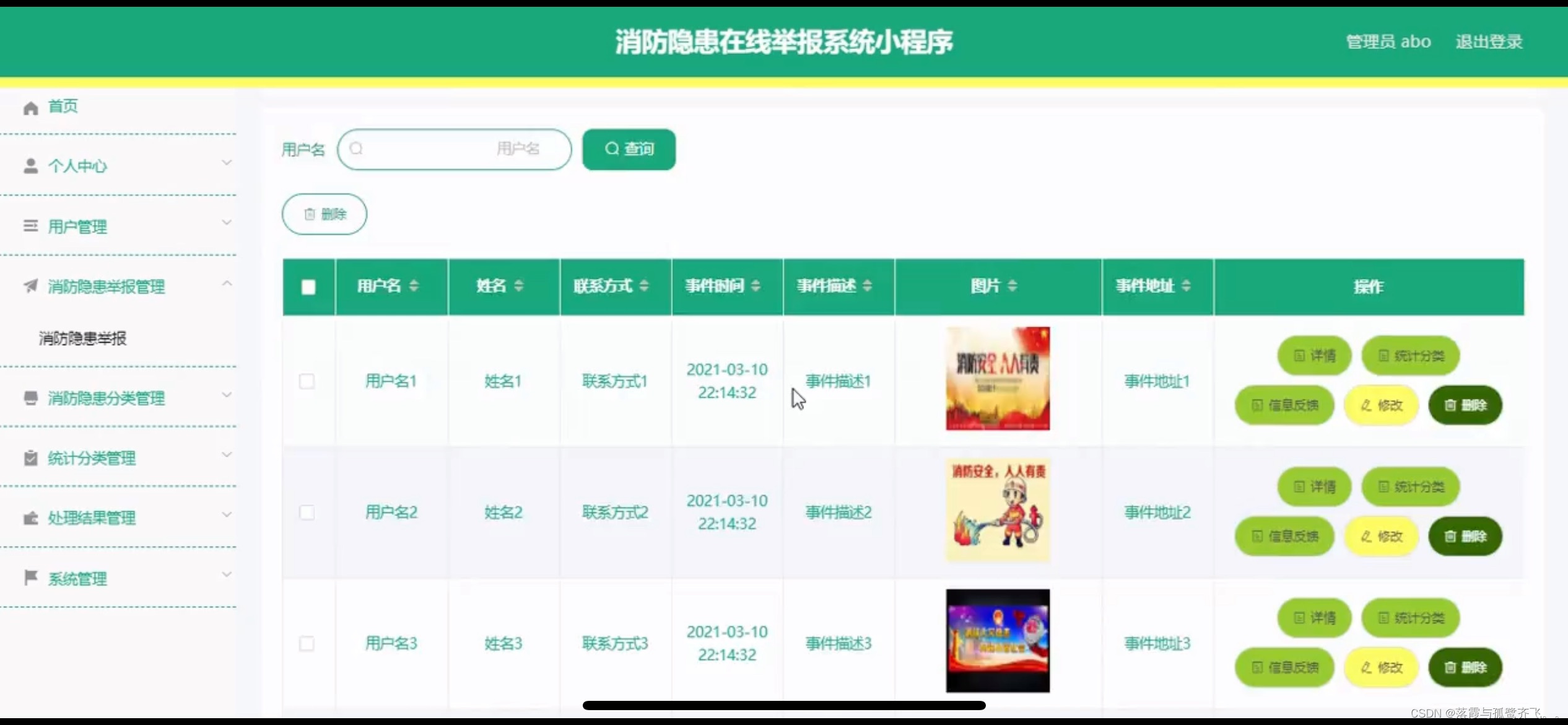
消防隐患在线小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,消防隐患举报管理,消防隐患分类管理,统计分类管理,处理结果管理,系统管理 微信端账号功能包括:系统首页,我…...

【Vue3】路由Params传参
【Vue3】路由Params传参 背景简介开发环境开发步骤及源码总结 背景 随着年龄的增长,很多曾经烂熟于心的技术原理已被岁月摩擦得愈发模糊起来,技术出身的人总是很难放下一些执念,遂将这些知识整理成文,以纪念曾经努力学习奋斗的日…...
授权cleanmymac访问全部磁盘 Mac授权访问权限 cleanmymac缺少权限
CleanMyMac是Mac系统下的一款专业的苹果电脑清理软件,同时也是一款优秀的电脑系统管理软件。它能有效清理系统垃圾,快速释放磁盘内存,缓解卡顿现象,保障系统顺畅地运行。 全磁盘访问权限,就好比机场内进行的安全检查。…...

Ubuntu/18.04 LTS下编译 BoringSSL 库
1、准备一个 Ubuntu/18.04 LTS 系统的设备 2、安装软件 GIT、GCC、CMAKE、G、Golang:1.16 及以上版本 3、克隆仓库源 git clone https://boringssl.googlesource.com/boringssl cd boringssl 4、使用特定版本 git checkout 9fc1c33e9c21439ce5f87855a6591a9324e569fd 5、编…...

【stm32项目】多功能智能家居室内灯光控制系统设计与实现(完整工程资料源码)
多功能智能家居室内灯光控制系统设计与实现 目录: 目录: 前言: 一、项目背景与目标 二、国内外研究现状: 2.1 国内研究现状: 2.2 国外研究现状: 2.3 发展趋势 三、硬件电路设计 3.1 总体概述 3.2 硬件连接总…...

xss靶场详解
目录 1.第一题 2.第二题 3.第三题 4.第四题 5.第五题 6.第六题 7.第七题 8.第八题 1.第一题 在源码script标签里边,innerhtml是用于访问或修改 HTML 元素内的 HTML 内容的,这里是访问spaghet这个元素的,并通过括号里面的东西搜索当前…...
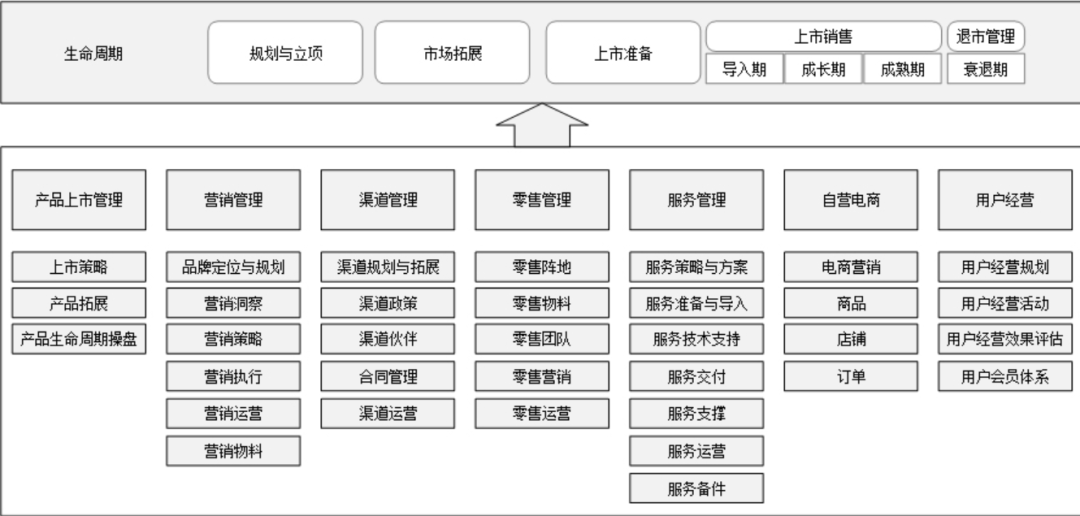
华为的流程管理
华为建设流程体系始于2000年,那时华为公司面临着快速扩张和全球化发展的挑战,意识到传统的管理模式已经无法满足业务发展的需求。为了提高公司的管理效率和竞争优势,华为决定启动流程体系的建设。在建设过程中,华为借鉴了业界最佳…...

操作系统Linux
1.Linux命令 ls:查看当前目录下所有目录和文件ps:查看所有正在运行的进程top:显示当前系统中占用资源最多的一些进程,shiftm按照内存查看大小netstat:查看端口的命令vi:查看文件的命令rm:删除文…...

1、.Net UI框架:MAUI - .Net宣传系列文章
.NET MAUI(Multi-platform App UI)是一个跨平台的UI框架,它是.NET统一应用模型的一部分,允许开发者使用C#和.NET来创建适用于iOS、Android、macOS和Windows的应用程序。MAUI继承了Xamarin.Forms的一些概念,但提供了更多的原生平台集成和改进的…...

Spring boot 使用 jSerialComm 对串口使用发送信息并接收
什么是 jSerialComm? jSerialComm 是一个 Java 库,旨在提供一种独立于平台的方式来访问标准串行端口,而无需外部库、本机代码或任何其他工具。它旨在替代 RxTx 和(已弃用的)Java Communications API,具有更…...

江协科技STM32学习笔记(第10章 SPI通信)
第10章 SPI通信 10.1 SPI通信协议 10.1.1 SPI通信 SPI(Serial Peripheral Interface)是由Motorola公司开发的一种通用数据总线; 串行外设接口; I2C无论是软件还是软件电路,设计的都还是比较复杂的,硬件…...

力扣热题100_回溯_22_括号生成
文章目录 题目链接解题思路解题代码 题目链接 22. 括号生成 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:[“((()))”,“(()())”,“(())()…...

【k8s】ubuntu24.04 containerd 手动从1.7.15 换为1.7.20
24.04的这个应该是apt 安装的1.7.20-1 root@k8s-master-pfsrv:~# sudo apt update && sudo apt install containerd.io -y 命中:1 http://mirrors.aliyun.com/docker-ce/linux/ubuntu noble InRelease 命中:2 https://dl.google.com/linux/chrome/deb stable InRelease…...

Java二十三种设计模式-备忘录模式(19/23)
本文深入探讨了备忘录模式,从定义、组成、实现到使用场景、优缺点、与其他模式的比较,以及最佳实践和替代方案,全面解析了如何在软件开发中有效地保存和恢复对象状态,以支持复杂的撤销操作和历史状态管理。 备忘录模式:…...

js一些杂乱理解
js 的值类型和引用类型 引用类型:object,array,function值类型:诸如number,stringboolean,null,Undefined,Symbol js使用变量访问对象属性示例 var myDog "Hunter"; var dogs { Fido: "Mutt", Hunter: "Doberman", Snoopie: "Beagle&q…...

机器学习 之 线性回归算法
目录 线性回归:理解与应用 什么是线性回归? 一元线性回归 正态分布的重要性 多元线性回归 实例讲解 数据准备 数据分析 构建模型 训练模型 验证模型 应用模型 代码实现 线性回归:理解与应用 线性回归是一种广泛使用的统计方法&…...

ThreadLoad如何防止内存溢出
优质博文:IT-BLOG-CN 从 ThreadLocalMap看 ThreadLocal使用不当的内存泄漏问题 【1】基础概念 : 首先我们先看看ThreadLocalMap的类图,我们知道 ThreadLocal只是一个工具类,他为用户提供get、set、remove接口操作实际存放本地变…...

2024.8.19 学习记录 —— 作业
一、TCP机械臂测试 #include <myhead.h>#define SER_PORT 8888 // 与服务器保持一致 #define SER_IP "192.168.0.114" // 服务器ip地址int main(int argc, const char *argv[]) {// 创建文件描述符打开键盘文件int fd open("/dev/input/event1…...

关键字[Static]
一、static 的三种用法 1. 静态局部变量 * 特性: * - 只初始化一次(程序启动时) * - 函数返回后值保留(不销毁) * - 下次调用时保持上次的值 * - 存储在静态区,不在栈上 2. 静态全局变量(文件作用域限制) 仅在 xx.c 内可见,其他文件无法访问 3. 静态函数(文件作用域限…...

3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析
3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

AI临床研究助手会先在哪些环节跑出来,真正的效率杠杆是什么
AI 临床研究助手最先落地的地方,不会是直接替代研究者做关键判断,而是进入高频、重复、可审计、边界清晰的研究流程节点。本文从技术架构角度拆解它会优先出现在哪些环节,以及开发团队如何用 workflow engine、LLM API、audit log 和 metrics…...

【实战】Latex|在保留ACM-Reference-Format格式的前提下,实现参考文献按引用顺序排列
1. 问题背景与核心痛点 当你使用ACM官方模板撰写论文时,参考文献格式要求必须采用ACM-Reference-Format样式。这个格式有个让人头疼的特性:它会强制按作者姓氏字母顺序排列参考文献,而不是按照文中实际引用顺序。想象一下,你精心设…...
)
py每日spider案例之某website壁纸接口(无加密)
import requestsheaders = {"accept": "*/*","accept-language": "zh-CN,zh;q=0.9","cache-control": "no-cache","pragma"...

智能硬件行业现状与未来趋势:技术、市场与盈利三重门解析
1. 项目概述:为什么现在要聊智能硬件?最近几年,身边的朋友、客户,甚至家里的长辈,都在问我同一个问题:“现在做智能硬件还有机会吗?” 这个问题背后,其实反映了一个普遍的行业焦虑&a…...

嵌入式ADC性能评估:CDBCAPTURE系统改造与实战调试指南
1. 项目概述:CDBCAPTURE系统与嵌入式ADC性能评估在嵌入式系统开发,尤其是涉及模拟信号采集的领域,工程师们常常面临一个核心挑战:如何准确、高效地评估模数转换器(ADC)在真实系统环境下的性能?是…...

从LCD屏幕到车载摄像头:聊聊LVDS接口在你身边那些‘看不见’的应用
从LCD屏幕到车载摄像头:聊聊LVDS接口在你身边那些‘看不见’的应用 走在科技产品琳琅满目的商场里,你可能不会注意到,那些让你眼前一亮的4K显示屏、流畅的触控体验,甚至自动驾驶汽车里的"眼睛",背后都藏着一…...

32位寄存器全解析:逆向分析与系统底层开发的基石
1. 从零开始:为什么32位寄存器是逆向分析的基石如果你刚开始接触逆向工程或者系统底层开发,面对一堆以E开头的寄存器缩写,是不是感觉有点头大?EAX、EBP、ESP……这些看起来神秘的代号,其实是理解程序如何“思考”和“行…...

别再死记硬背了!用这 5 个核心功能理解 Final Cut Pro 的设计哲学
Final Cut Pro 的设计哲学:5个核心功能如何重塑你的剪辑思维 当你第一次打开Final Cut Pro(简称FCPX),可能会被它与其他剪辑软件截然不同的界面所困惑。这不是一个需要你适应传统时间线的工具,而是一个重新思考剪辑流程…...