【MySQL 07】表的增删查改 (带思维导图)
文章目录
- 🌈 一、insert 添加数据
- ⭐ 1. 单行数据 + 全列插入
- ⭐ 2. 多行数据 + 指定列插入
- ⭐ 3. 插入否则更新
- ⭐4. 插入否则替换
- 🌈 二、select 查询数据
- ⭐ 1. select 列
- 🌙 1.1 全列查询
- 🌙 1.2 指定列查询
- 🌙 1.3 查询字段为表达式
- 🌙 1.4 为查询结果指定别名
- 🌙 1.5 结果去重
- ⭐ 2. where 条件查询
- 🌙 2.1 运算符介绍
- 🌙 2.2 where 使用案例
- ⭐ 3. order by 结果排序
- 🌙 3.1 order by 语法格式
- 🌙 3.2 order by 使用案例
- ⭐ 4. limit 筛选分页结果
- 🌙 4.1 limit 语法格式
- 🌙 4.2 limit 使用案例
- 🌈 三、update 修改数据
- ⭐ 1. update 语法格式
- ⭐ 2. update 使用案例
- 🌈 四、delete 删除数据
- ⭐ 1. delete 语法格式
- ⭐ 2. 删除指定记录
- ⭐ 3. 删除全表数据
- ⭐ 4. truncate 截断表
- 🌙 4.1 truncate 语法格式
- 🌙 4.2 truncate 使用案例
- 🌈 五、插入查询结果
- ⭐ 1. 语法格式
- ⭐ 2. 使用案例
- 🌈 六、聚合函数
- ⭐ 1. 常见聚合函数
- ⭐ 2. 聚合函数案例
- 🌈 七、group by 分组查询
- ⭐ 1. 分组概念
- ⭐ 2. group by 语法格式
- ⭐ 3. group by 使用案例
- 🌙 3.1 准备工作
- 🌙 3.2 使用案例
- ⭐ 4. having 条件
- 🌙 4.1 having 使用案例
- 🌙 4.2 where 和 having 的区别

🌈 一、insert 添加数据
INSERT [INTO] 表名 [(列名1 [, 列名2, ..., 列名n])] VALUES (值1, 值2, ..., 值n) [, (值1, 值2, ..., 值n)];
参数说明
- 虽然 MySQL 不区分大小写,但此处还是要用大写清楚的表示哪些是关键字。
- 方括号 [ ] 括起来的是可选项。
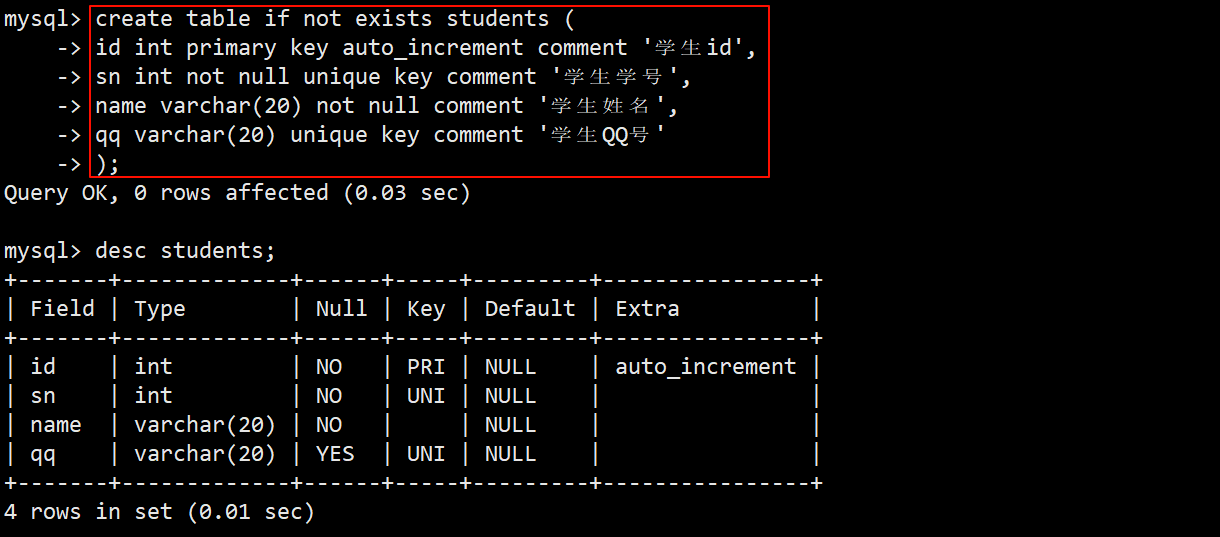
准备工作
- 为了方便之后的操作,现在创建一张名为 students 的学生表。
- 表中包含自增长的主键 id、非空且唯一键的学号 sn、非空的姓名 name 和唯一键的 qq 号这四个字段。
⭐ 1. 单行数据 + 全列插入
INSERT [INTO] 表名 VALUES (给第1列的值) [, (给第2列的值, ..., 给第n列的值)];
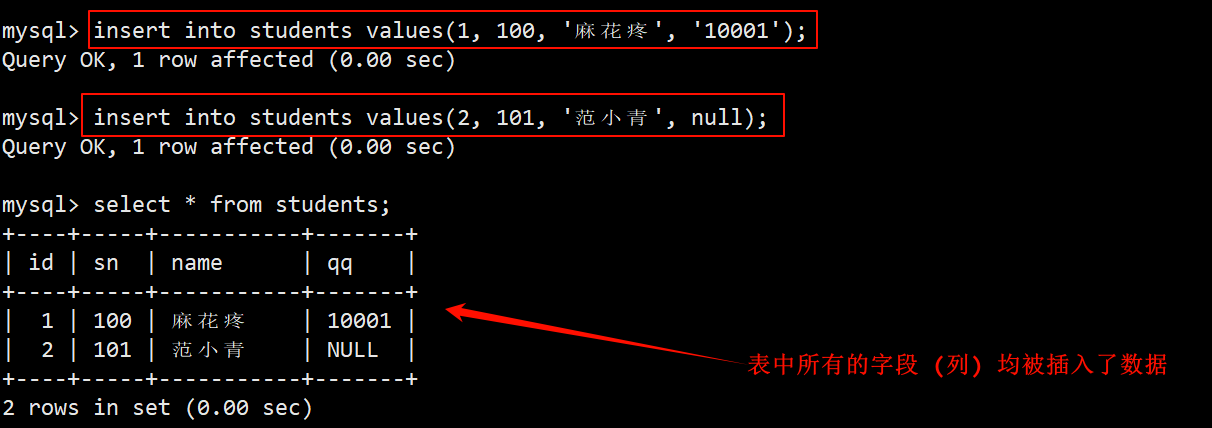
- 每次向表中插入一行数据,在插入数据时不指定字段名,表示按照表中默认的字段顺序进行全列插入,插入的数据的类型要和表中对应字段一致。
- 插入单行数据时,可以对指定列进行插入,也可以进行全列插入,这里就只演示全列插入。
⭐ 2. 多行数据 + 指定列插入
INSERT [INTO] 表名 (列名1 [, 列名2, ..., 列名n])] VALUES (值1, 值2, ..., 值n) [, (值1, 值2, ..., 值n)];
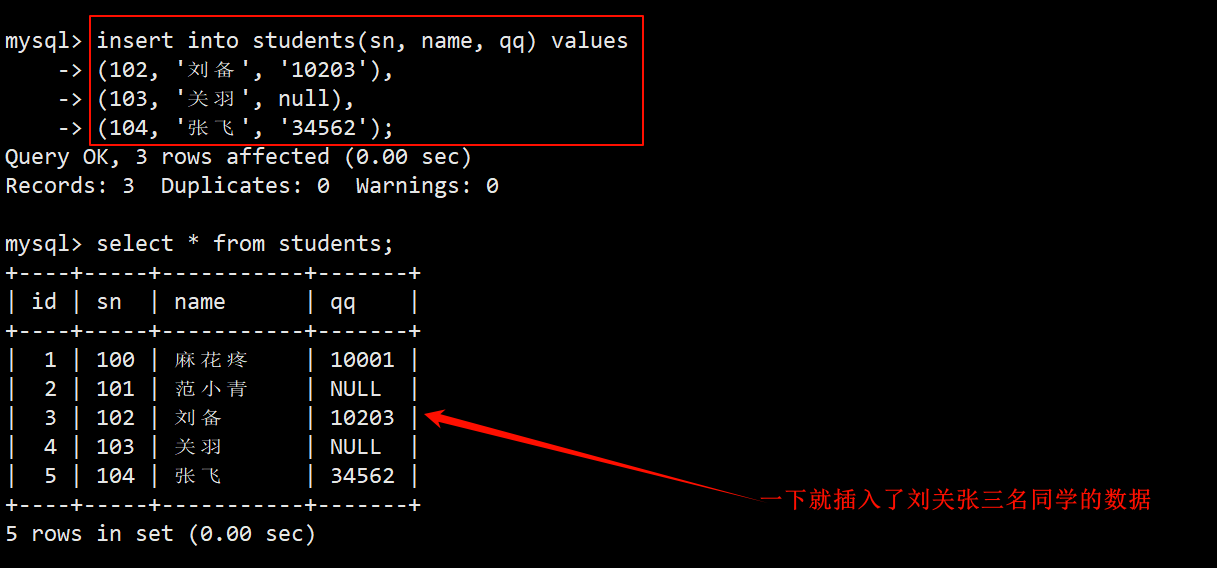
- 可以一次性向表中插入多条数据,插入的多条数据之间使用逗号隔开。
- 插入多行数据时,可以对指定列进行插入,也可以进行全列插入,这里就只演示对指定的 sn、name、qq 这三列进行插入。
- 注:在对指定列插入数据时,只有允许为空的字段和设置了自增长属性的字段能不指定值插入,不允许为空的字段必须指定值插入。
⭐ 3. 插入否则更新
- 在往向表中插入数据时,如果主键或唯一键的值与已有数据发生了冲突,会导致本次操作被 MySQL 拦截。
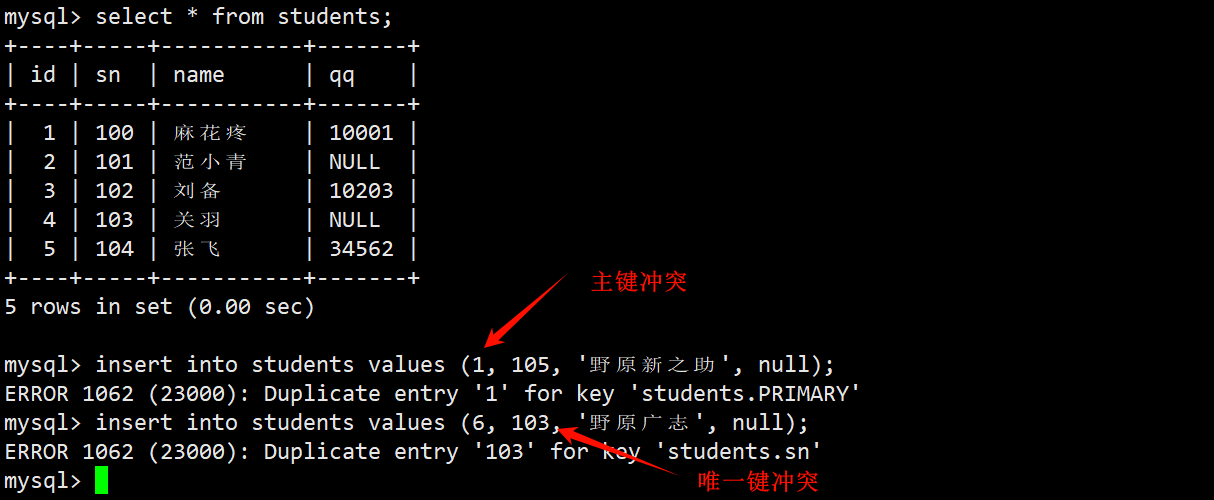
- 此时就需要使用插入否则更新的 sql 语句出马了。
1. 插入否则更新的语法格式
INSERT ... ON DUPLICATE KEY UPDATE 列名1 = 值1 [, 列名2 = 值2, ..., 列明n = 值n];
// 语句中的 字段=值,表示当插入数据时,如果出现冲突则需要更新的字段值。
- 如果表中 未 发生数据冲突,则插入数据到表中。
- 如果表中 有 发生数据冲突,则更新表中的数据。
2. 插入否则更新的使用示例
- 向表中插入数据时,如果发生了主键冲突,则直接更新表中学号 sn 字段和姓名 name 字段的值,QQ 号就不更新了。
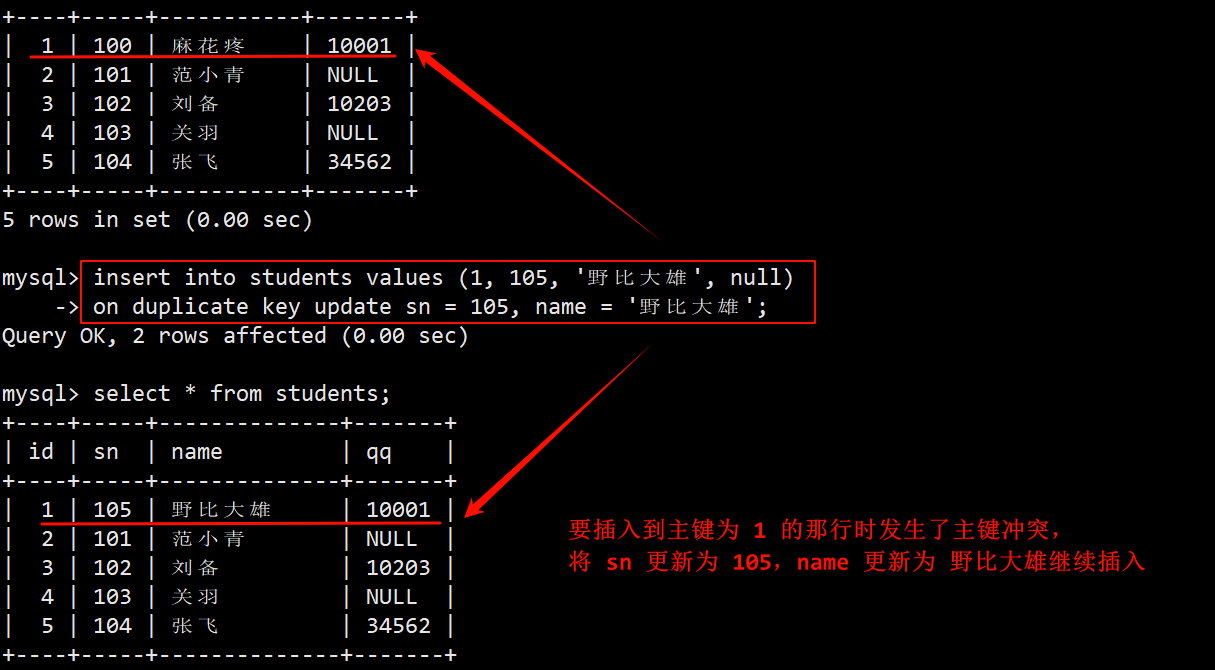
3. 判读数据的插入情况
- 执行插入否则更新的语句之后,能通过反映回来的受影响的数据行数来判断数据的插入情况。
- 0 row affected:表中发生数据冲突,但冲突数据的值和更新的值相等。
- 1 row affected:表中没有发生数据冲突,数据直接被插入。
- 2 rows affected:表中发生数据冲突,并且数据已经被更新。
⭐4. 插入否则替换
REPLACE INTO 表名 [(列名1 [, 列名2, ..., 列名n])] VALUES (值1, 值2, ..., 值n) [, (值1, 值2, ..., 值n)];
// 只是将 插入数据 语法中的 INSERT 替换成了 REPLACE 而已
- 当 未 和表中现有的主键或唯一键字段的数据发生冲突时,会直接将数据插入到表中。
- 当 有 和表中现有的主键或唯一键字段的数据发生冲突时,会先将表中发生冲突的数据删除,然后再插入新的数据。
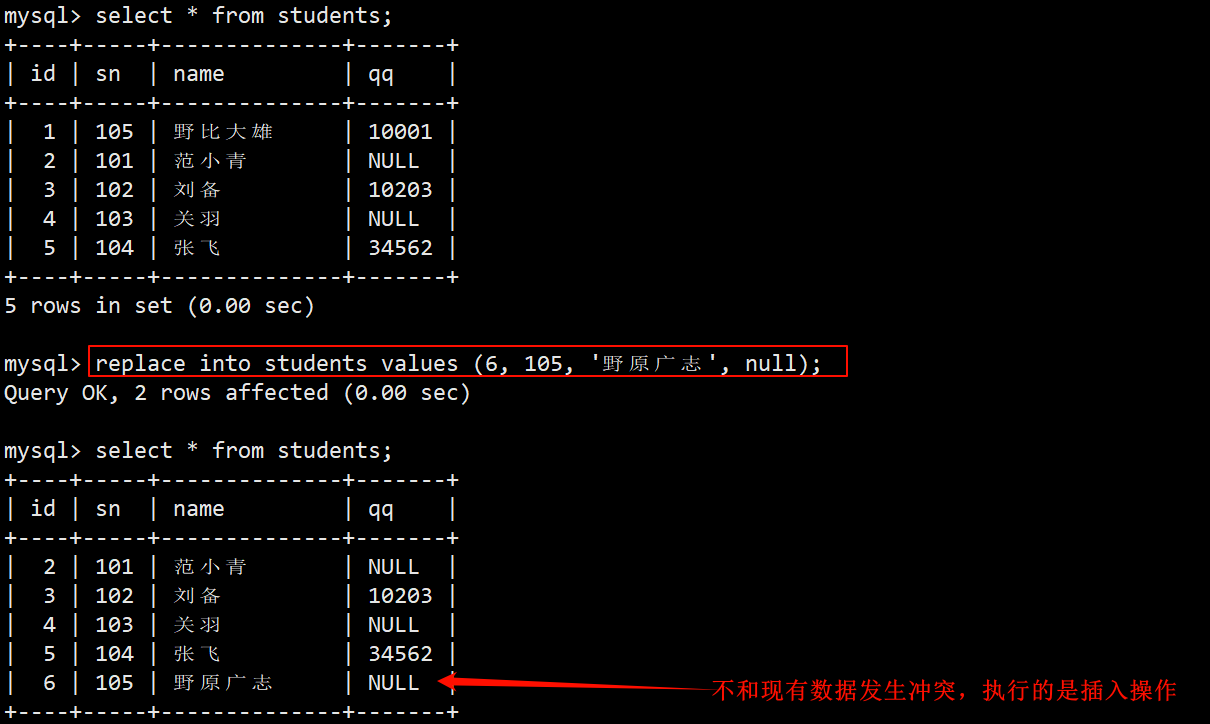
1. 插入否则替换的使用示例
- 不和现有数据发生冲突,执行的仅仅是插入功能。
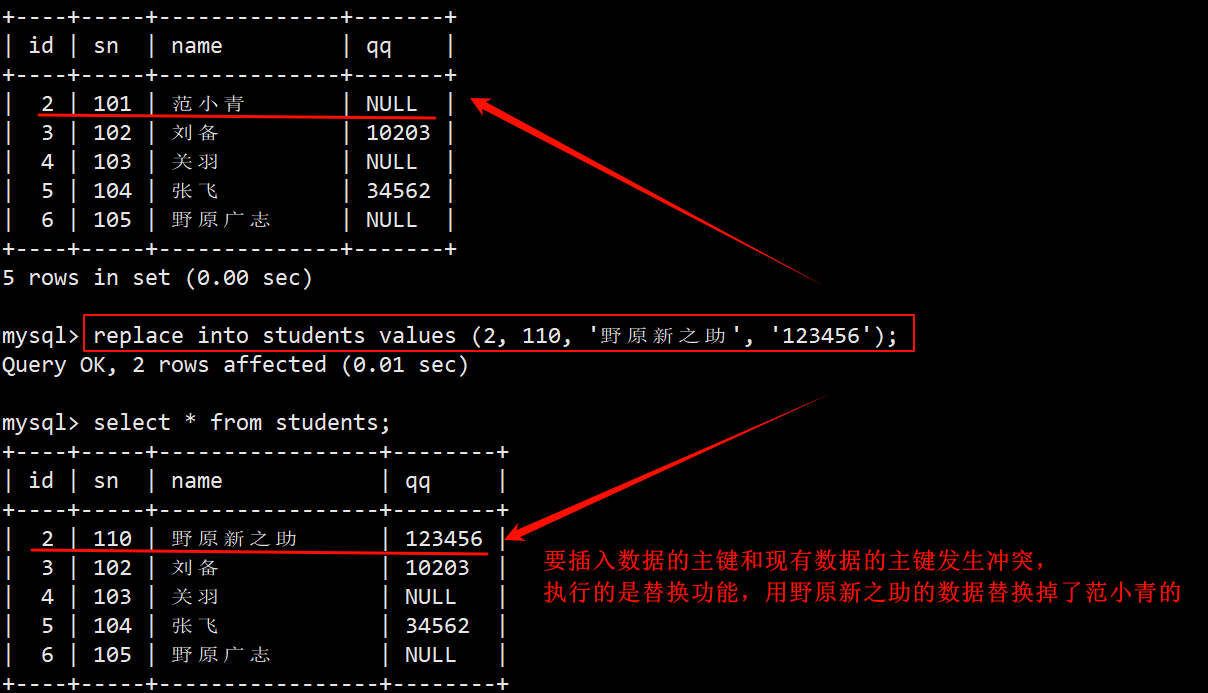
- 和现有数据发生冲突,执行的是替换功能。
2. 判断数据替换的情况
- 执行插入否则替换的语句之后,能通过反映回来的受影响的数据行数来判断数据的插入情况。
- 1 row affected:表中没有发生数据冲突,数据直接被插入。
- 2 rows affected:表中发生了数据冲突,表中的冲突数据被删除后插入了新的数据。
🌈 二、select 查询数据
SELECT [DISTINCT] {* 或 {列名1 [, 列名2, ..., 列名n] ...}} FROM 表名 [WHERE ...] [ORDER BY ...] [LIMIT ...];
准备工作
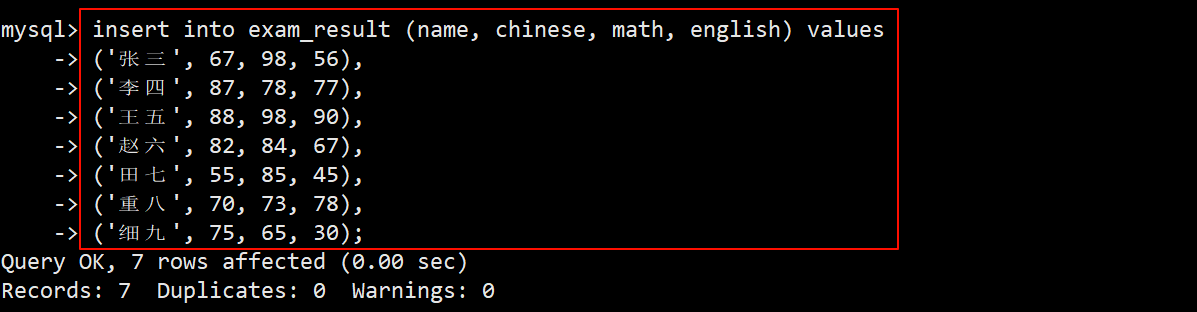
- 为了方便之后的操作演示,先创建一张名为 exam_result 的学生成绩表。
- 表中包含自增长的主键 id,非空的学生姓名 name,语文成绩 chinese、数学成绩 math 和英语成绩 engilsh 这五个字段。
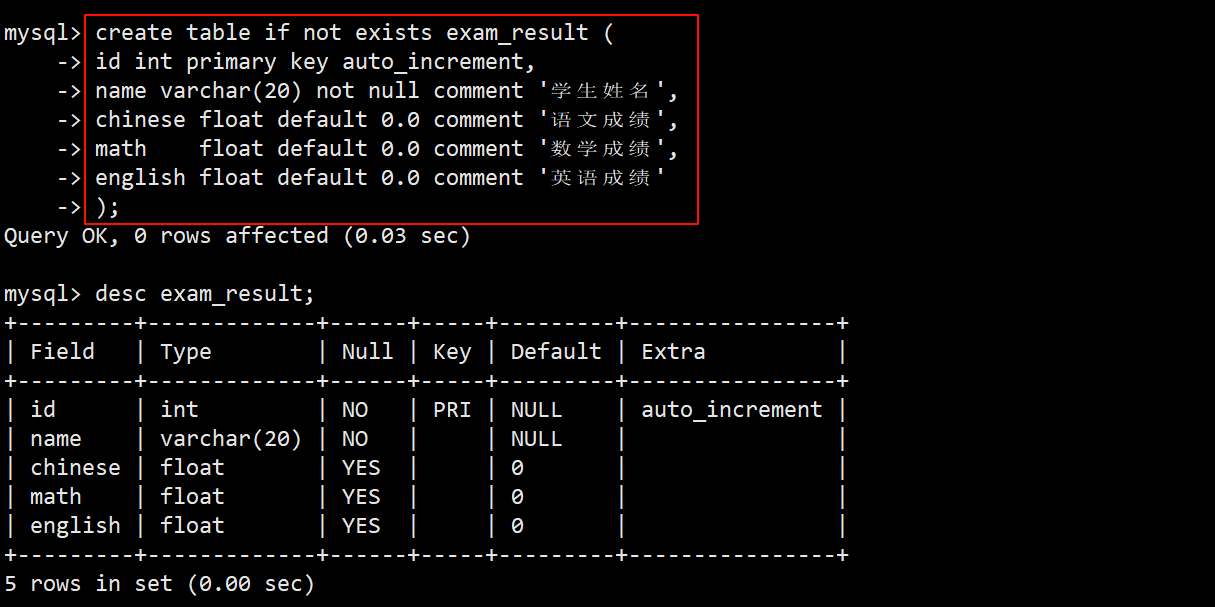
- 创建完表之后,再插入几条测试数据,方便之后进行查询操作。
⭐ 1. select 列
🌙 1.1 全列查询
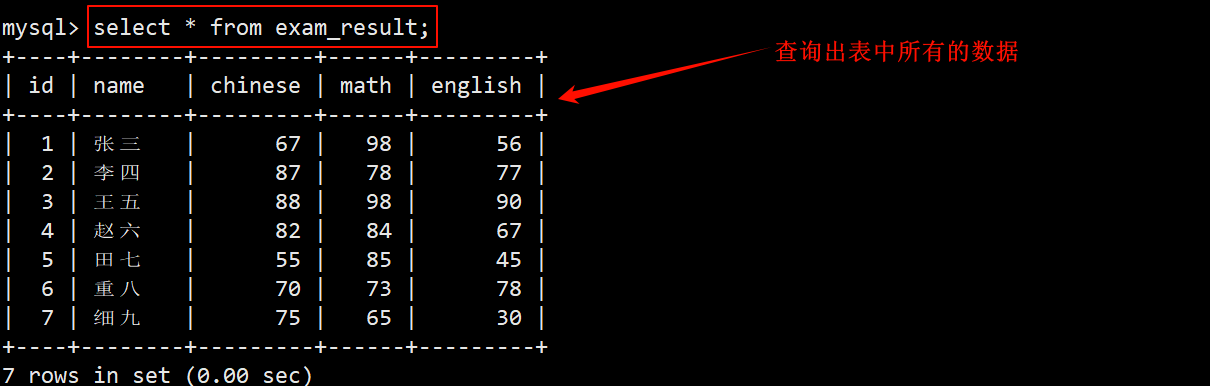
- 全列查询表示的是要将信息全部读取出来。
SELECT [DISTINCT] * FROM 表名 [WHERE ...] [ORDER BY ...] [LIMIT ...];
通常情况下不建议使用 * 进行全列查询
-
被查询到的数据需要通过网络从 MySQL 服务器传输到本主机,查询的列数越多,意味着需要传输的数据量越大。
-
使用全列查询可能还会影响到索引的使用。
🌙 1.2 指定列查询
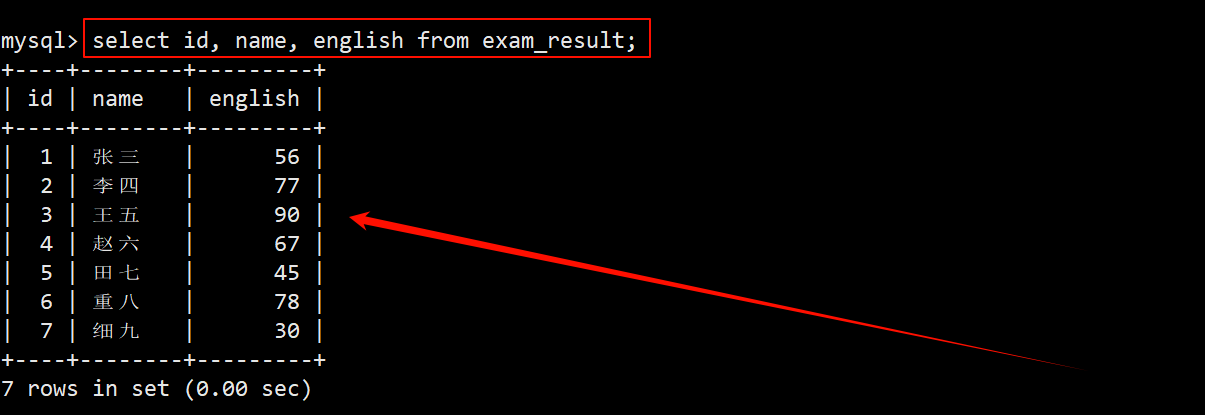
- 在查询数据时也可以只对指定的某些列进行查询。
SELECT [DISTINCT] 字段1 [, 字段2, ..., 字段n] FROM 表名 [WHERE ...] [ORDER BY ...] [LIMIT ...];
- 指定查询成绩表 exam_result 中的姓名 name 字段和数学 math 字段。表示当前只想查看所有学生的数学成绩。

- 指定查询 id、name、english 这三列的内容。
🌙 1.3 查询字段为表达式
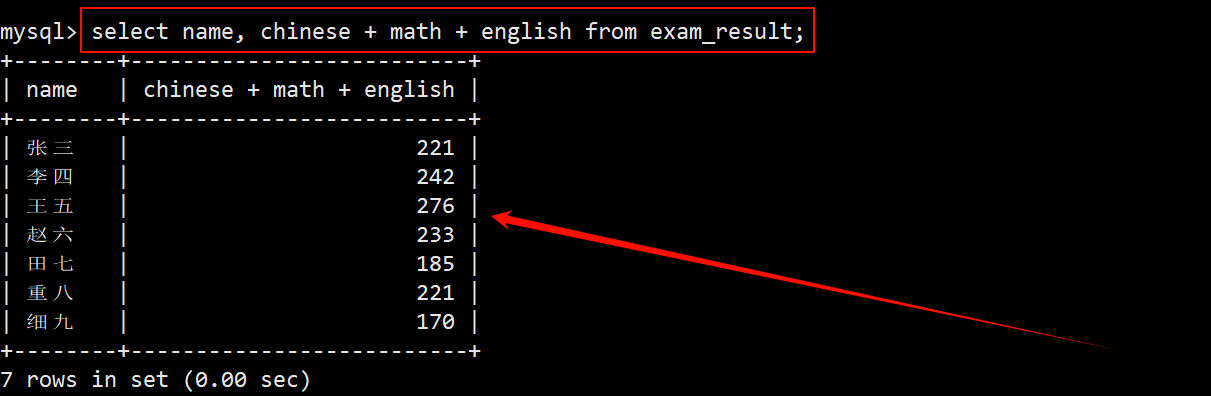
- select 是个很特殊的关键字,它可以是 select 自带的各种子句、指定表的字段名、普通表达式等。
- select 不仅能够用来查询数据,还可以用来计算某些表达式的值或执行某些函数。

- 列表中的表达式也可以包含多个表中已有的字段,可以通过表达式计算这些字段获得其他特别的数据。
- 求每名同学的语数英三科成绩的总分。
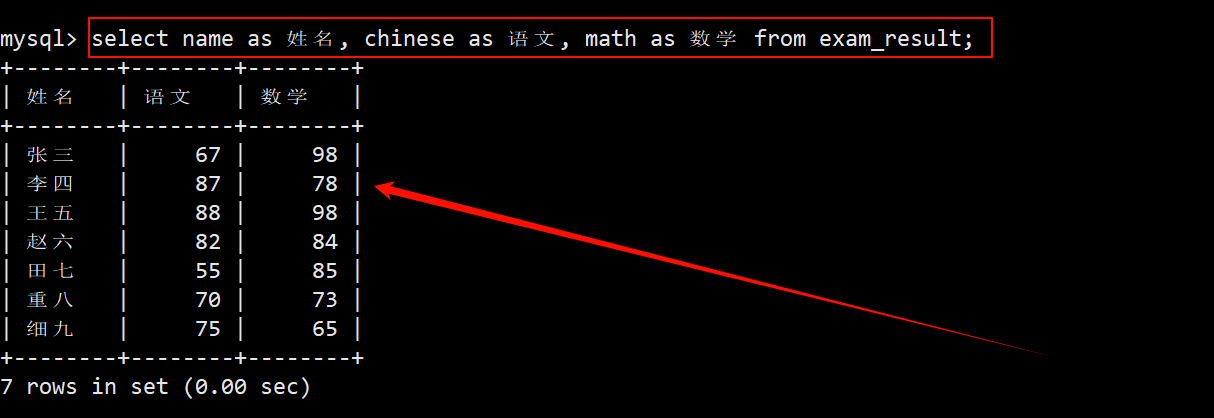
🌙 1.4 为查询结果指定别名
- 可以给表的某一列取个别名,用来更好的分辨某一列的功能。
- 对列做重命名属于显示的范畴,是最后一步已经拿完数据了,只是做个改名操作而已,只能在 select 语句这里进行重命名。
- 执行顺序在 select 之前的子句无法对列取别名。
SELECT 指定列名 [AS] 指定列的别名 [...] FROM 表名;
- 将成绩表中每名同学的语数英成绩加起来,并对该表达式起个名为总分的列别名。
- 虽然 as 可带可不带,但是为了更好的阅读体验建议还是带上。
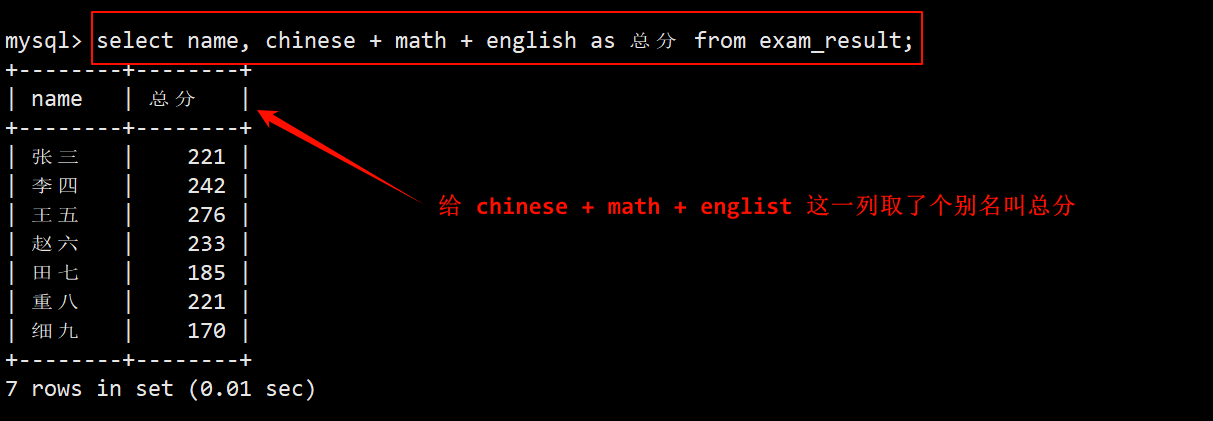
- 还可以为表中自带的字段取别名。
🌙 1.5 结果去重
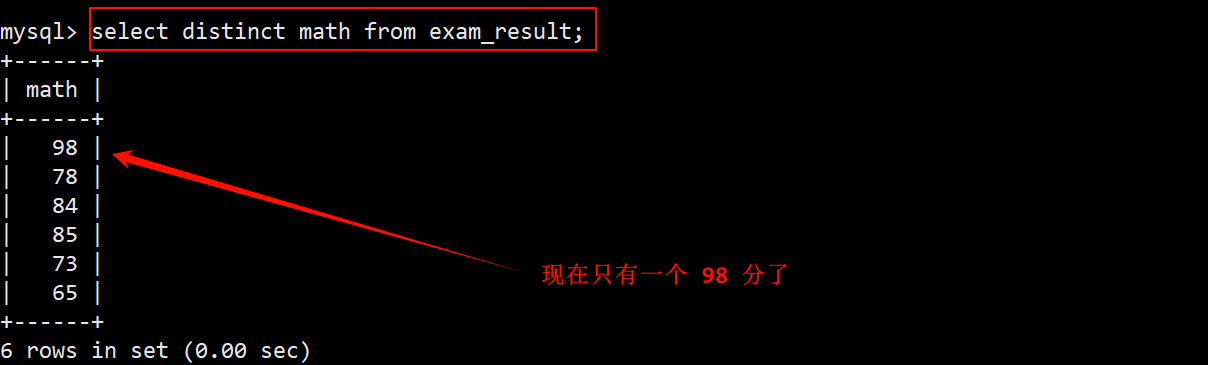
SELECT DISTINCT 字段列表 from 表名;
- 在进行查询时,可能会有重复的数据出现。

- 可以在 select 关键字的后面加上 distinct 关键字,当要筛选的那一列出现重复的数据时,只保留一份数据。
⭐ 2. where 条件查询
- 在查询时,也不是每次都要查询表中所有的行的数据,还需要根据一些筛选条件查看指定行的数据。where 筛选影响的是显示出来的行数。
- 在查询数据时如果使用了 where 子句,则会先根据 where 子句筛选出符合条件的行数据,然后将符合条件的行数据作为数据源依次执行 select 语句,从而找出符合条件的列数据。
🌙 2.1 运算符介绍
- where 子句可以指定 1/ n 个筛选条件,where 使用特定的比较运算符和逻辑运算符类决定如何进行筛选。
1. 比较运算符
| 比较运算符 | 说明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,如:NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 是安全的,如:NULL <=> NULL 的结果是 TRUE |
| !=,<> | 不等于 |
| BETWEEN 值1 AND 值2 | 在 [值1, 值2] 这个范围之内取值 (含最小值和最大值) |
| IN (…) | 从 IN 之后的多个值之中,进行多选一 |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE 占位符 | 模糊匹配,占位符如果是下划线 _ 表示任意一个字符;如果是百分号 % 表示任意 0 ~ n 个字符 |
2. 逻辑运算符
- MySQL 支持通过逻辑运算符将多条筛选语句组合起来。
| 逻辑运算符 | 说明 |
|---|---|
| AND 或 && | 并且 (多个条件需要同时成立) |
| OR 或 || | 或者 (多个条件任意一个成立) |
| NOT 或 ! | 非 (条件为真,结果为假;条件为假,结果为真) |
🌙 2.2 where 使用案例
- 当前准备了如下的 where 子句的使用案例
- 查询英语不及格的同学及其英语成绩。
- 查询语文成绩在 [80, 90] 分之间的同学及其语文成绩。
- 查询数学成绩是 58 或者是 59 或者是 98 或者是 99 分的同学及其数学成绩。
- 查询姓赵的同学以及赵某同学。
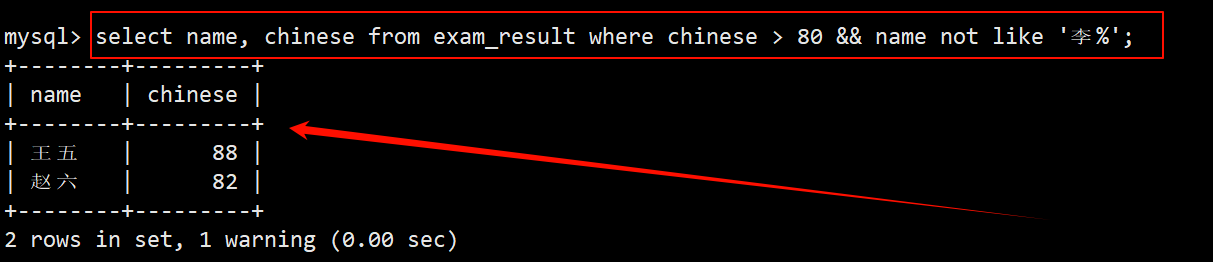
- 查询语文成绩优于英语成绩的同学。
- 查询总分在 200 分以下的所有同学的信息。
- 查询语文成绩 > 80 并且不姓李的同学。
- 查询重某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80 分。
- NULL 的查询。
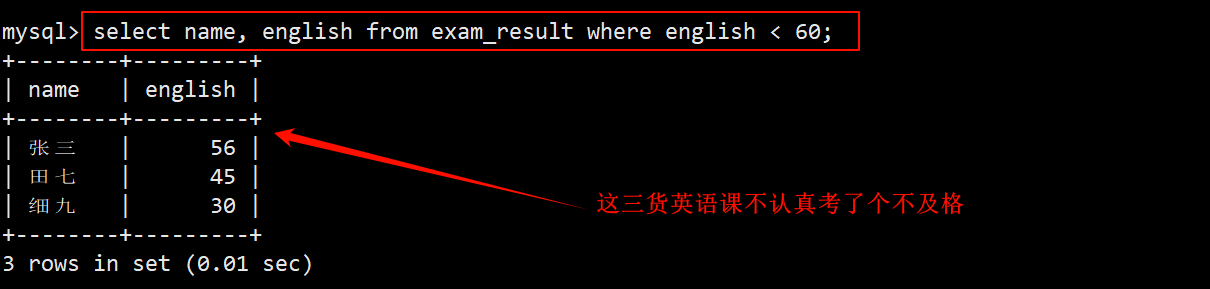
1. 查询英语不及格的同学及其英语成绩
- 在 where 子句中指定筛选条件为 english < 60,在 select 的字段列表中指明要查询的字段为 name 和 english。
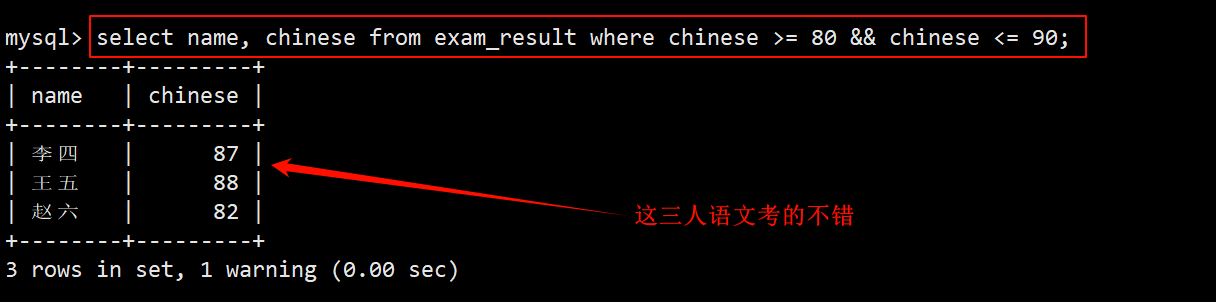
2. 查询语文成绩在 [80, 90] 分之间的同学及其语文成绩
- 在 where 子句中指定筛选条件为 chinese >= 80 && chinese <= 90,在 select 的字段列表中指明要查询的列为 name 和 chinese。
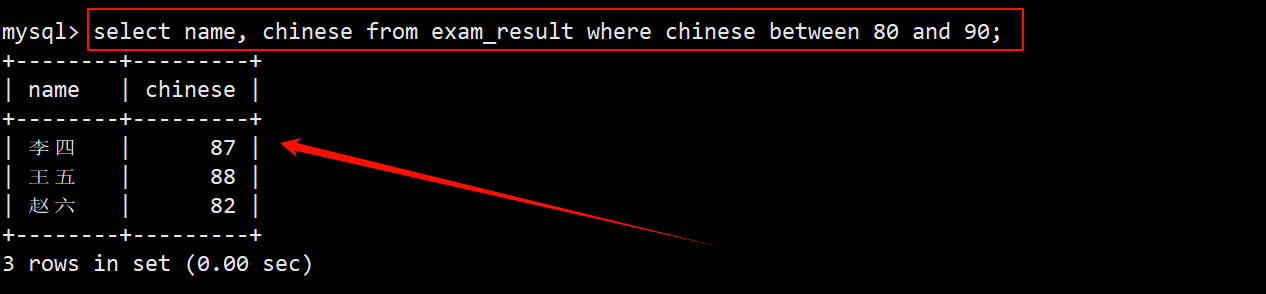
- 也可以在 where 子句中使用 between 80 and 90 查询 [80, 90] 分的同学的信息。
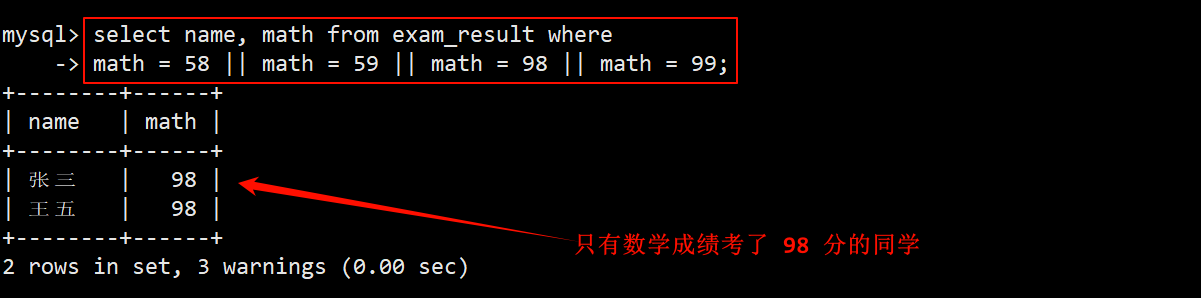
3. 查询数学成绩是 58 或者是 59 或者是 98 或者是 99 分的同学及其数学成绩
- 在 where 子句中指定筛选条件为数学成绩为 58 || 59 || 98 || 99,在 select 的字段列表指定要查询的列为 name 和 math。
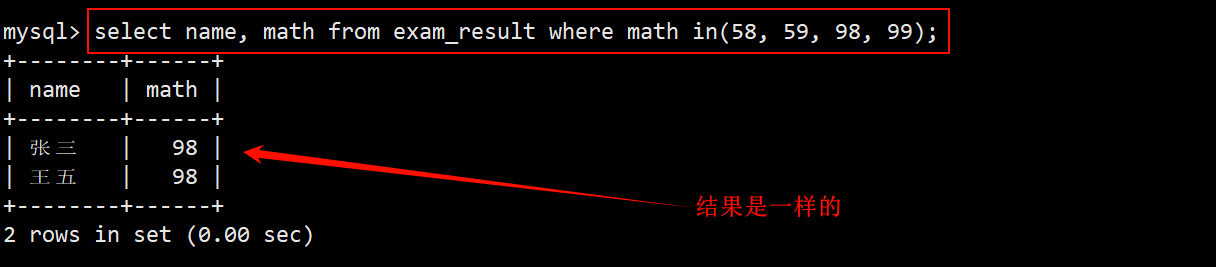
- 除了用或的方式筛选之外,还可以使用 in(58, 59, 98, 99) 从这 4 个值中任选一个。
4. 查询姓赵的同学以及赵某同学
- 查询姓赵的同学:即不管姓名有几个字,只要姓赵即可。在 where 子句中可用 name like ‘赵%’,% 能匹配任意多个字符。

- 查询赵某同学,即查询姓赵且名字个数为 2 的同学。在 where 子句中可使用 name like ‘赵_’ 来匹配,_只能匹配一个字符。
- 由于表中只有一个赵六姓赵,所以查询效果会看着和使用 % 没什么区别。

5. 查询语文成绩优于英语成绩的同学
- 在 where 子句中指定筛选条件为 chinese > english,在 select 的字段列表中指定要查询的列为 name、chinese 和 english。
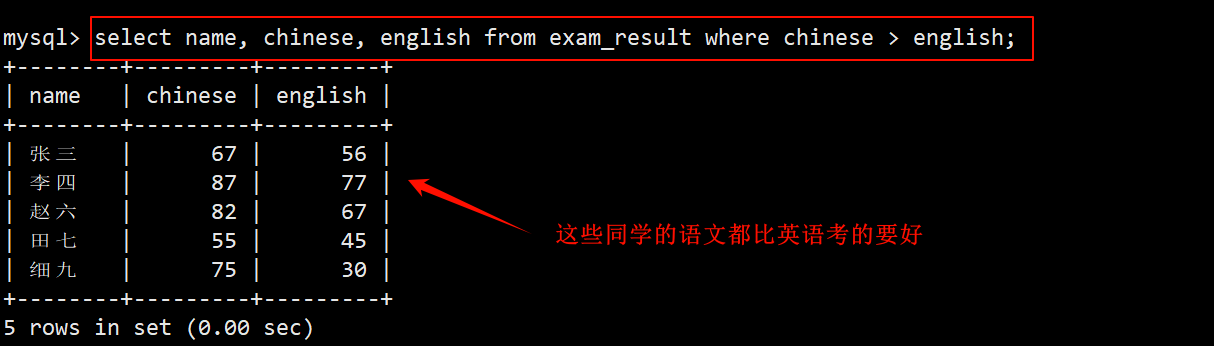
6. 查询总分在 200 分以下的所有同学的信息
- 在 where 子句中的筛选条件为 chinese + math + english < 200,在 select 的字段列表中指定要查询的列为 name 和三科总分。
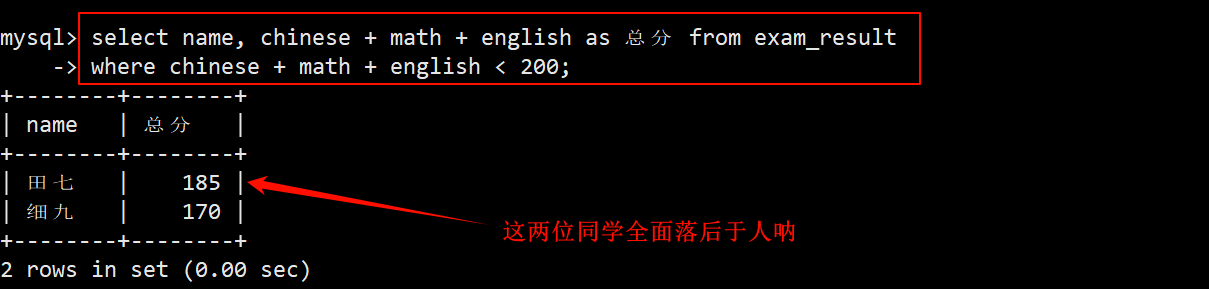
7. 查询语文成绩 > 80 并且不姓李的同学
- 在 where 子句中,指定筛选调教为 chinese > 80 并且 name 非 like ‘李%’。
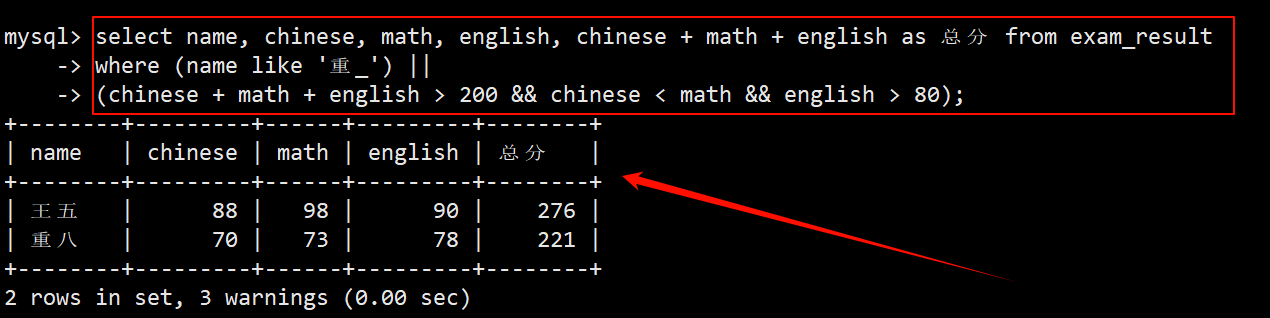
8. 查询重某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80 分
- 被查询的人要么是重某,要么是总成绩 > 200 并且 chinese < math 并且 english > 80 的同学。
- 重八满足条件 1,王五满足条件 2,都符合 或者 的定义,因此是这两个人被查询出来了。
9. NULL 的查询
- 为了方便演示,此处使用在添加数据那里使用的 students 学生表进行查询。
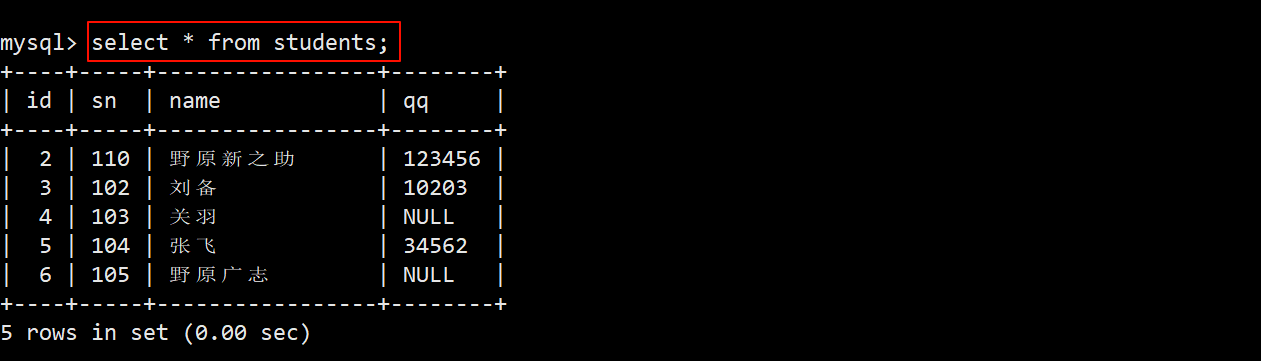
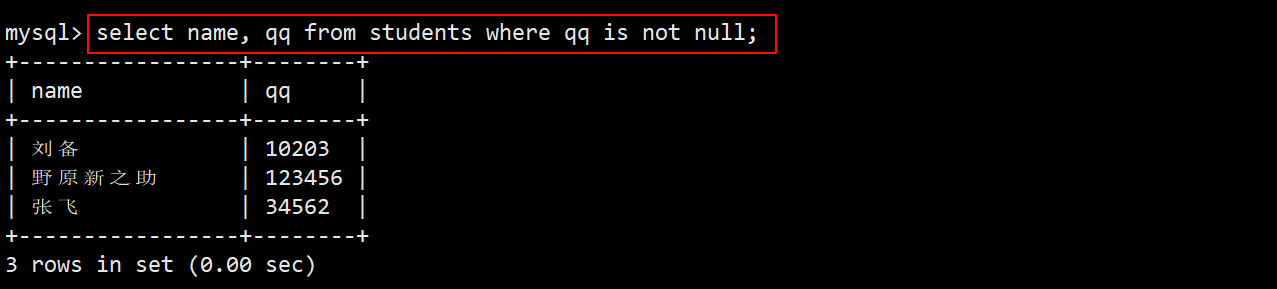
- 查询 qq 号已知的同学:即查询 qq 号 is not null 不为空的同学。
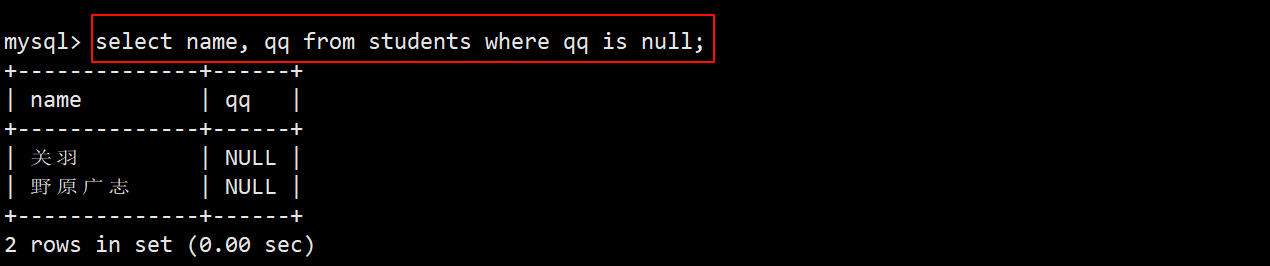
- 查询 qq 号未知的同学,即查询 qq 号 is null 为空的同学。
⭐ 3. order by 结果排序
- 由于查询的结果是个表结构,可能会有多行信息,通常将一行数据称之为记录,此时就需要对这些筛选出来的记录进行排序。
🌙 3.1 order by 语法格式
SELECT ... FROM 表名 [WHERE ...] ORDER BY 字段1 [ASC 或 DESC], [...];
- ASC 表示升序,DESC 表示降序,默认为升序 ASC。
- 如果查询语句中没有 order by 子句,则返回的顺序是未定义的。
- 可以根据多个字段进行排序,当根据字段 1 的值排序完之后出现了重复值,则再根据字段 2 的值对重复的部分排序,以此类推。
🌙 3.2 order by 使用案例
- 当前准备了如下 order by 子句的使用案例。
- 查询所有的同学及其数学成绩,查询结果按 数学成绩 升序显示。
- 查询所有的同学及其 qq 号,查询结果按 qq 号排序显示。
- 查询同学的各门成绩,查询结果依次按 数学降序、英语升序、语文升序 的方式进行显示。
- 查询所有同学的成绩总分,查询结果按 总分 降序显示。
- 查询姓 赵 的的同学或者姓 王 的同学的数学成绩,查询结果按 数学成绩 降序显示。
1. 查询所有的同学及其数学成绩,查询结果按 数学成绩 升序显示
- 在成绩表中查询:在 select 的字段列表中指定要查询的列为 name 和 math,在 order by 子句中指定按照 math 进行 asc 排序。
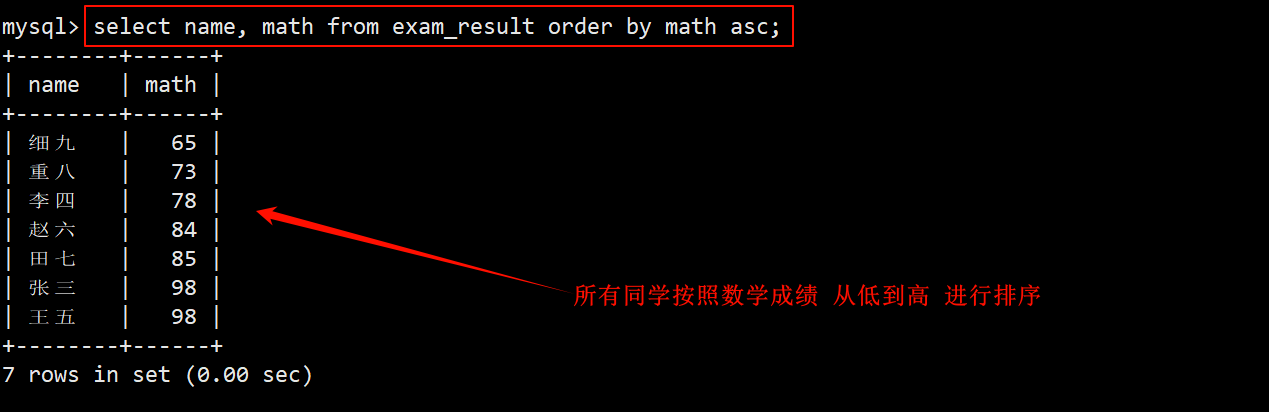
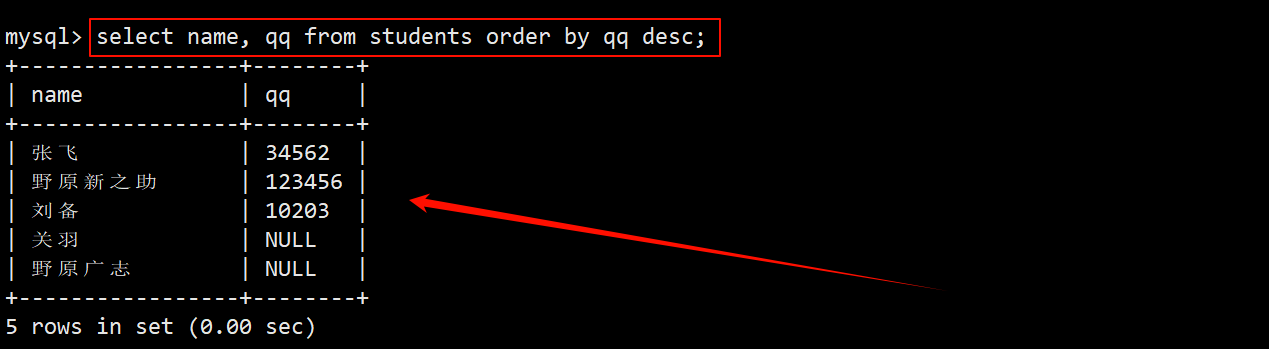
2. 查询所有的同学及其 qq 号,查询结果按 qq 号排序显示
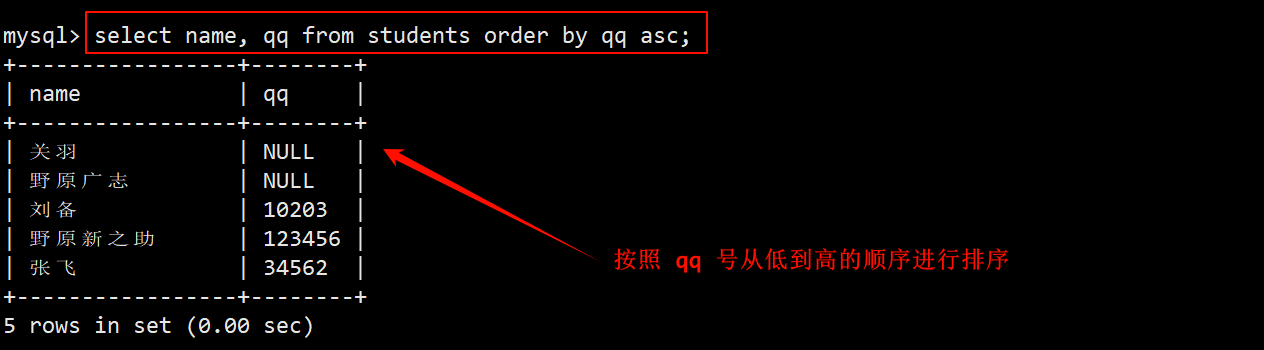
- 在学生表中查询:排升序,在 select 的字段列表中指定要查询的列为 name 和 qq,在 order by子句中按照 qq 号进行 asc 排序。
- 注:由于 qq 的数据类型是 varchar,因此采用 ASCII 码进行比较。
- 在学生表中查询:排降序,在 select 的字段列表中指定要查询的列为 name 和 qq,在 order by子句中按照 qq 号进行 desc 排序。
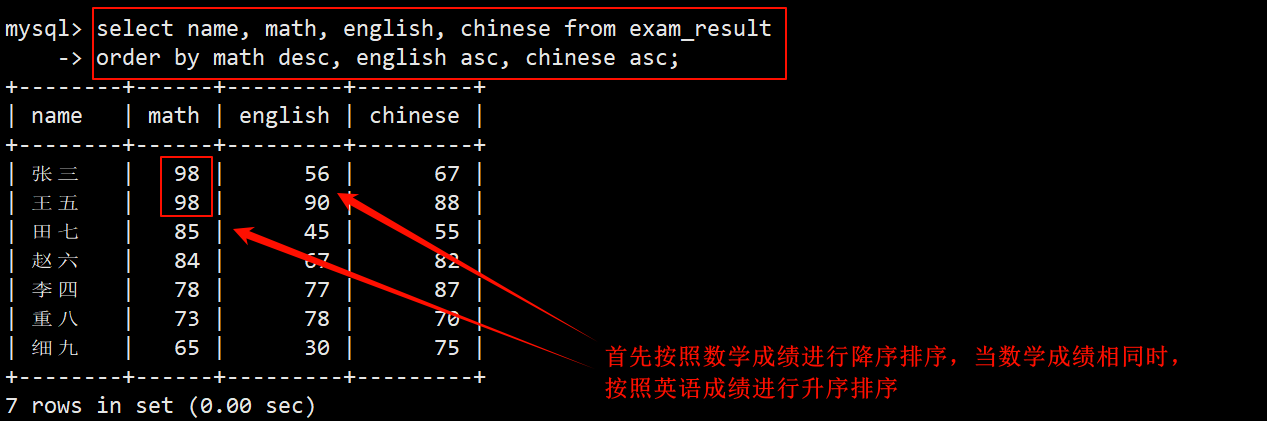
3. 查询同学的各门成绩,查询结果依次按 数学降序、英语升序、语文升序 的方式进行显示
- 在成绩表中查询,在 select 的字段列表中指明要查询的列为 name、math、english 和 chinese,在 order by 子句中指明依次按照 math desc, english asc, chinese asc 进行排序。
- 首先按照数学成绩进行降序排序的,在相同的数学成绩之间按照英语进行升序排序。
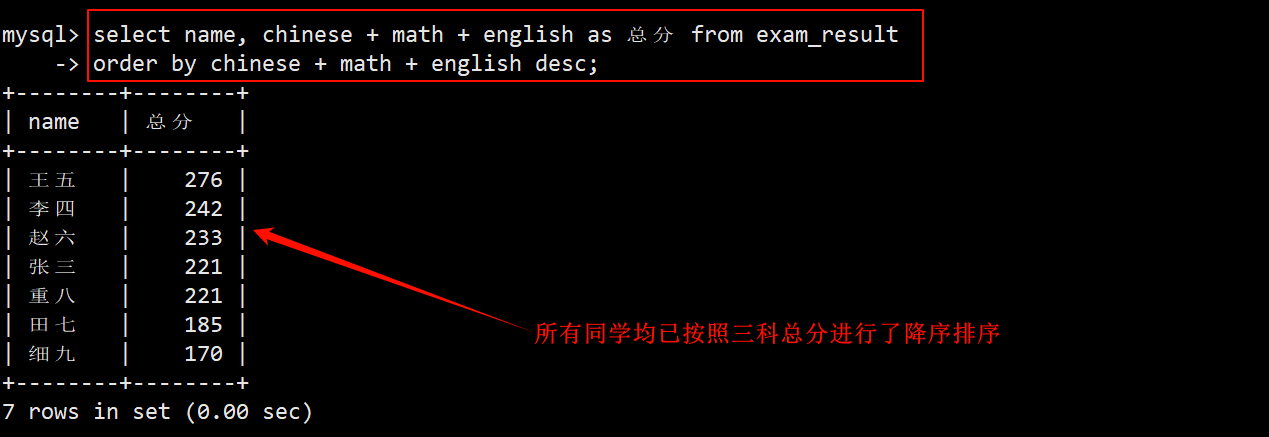
4. 查询所有同学的成绩总分,查询结果按 总分 降序显示
- 在成绩表中查询:在 select 的字段列表中指中指定要查询的列为 name 和 总分 (表达式查询),在 order by 子句中指明按照 chinese + math + english 进行 desc 排序。
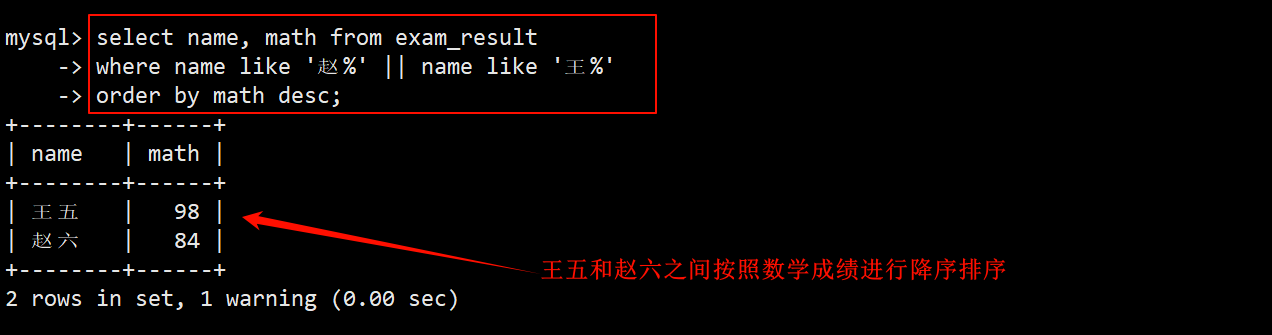
5. 查询姓 赵 的的同学或者姓 王 的同学的数学成绩,查询结果按 数学成绩 降序显示
- 在成绩表中查询:在 where 子句中指定筛选条件为姓 赵 / 王,再在 order by 子句中指定为按 math 进行 desc 排序。
⭐ 4. limit 筛选分页结果
- 对获取出来的结果信息进行分页显示。
🌙 4.1 limit 语法格式
-
从第 0 行数据开始,向后筛选出 n 行数据。
SELECT ... FROM 表名 [WHERE ..] [ORDER BY ...] LIMIT n; -
从第 s 行数据开始,向后筛选出 n 行数据。
SELECT ... FROM 表名 [WHERE ...] [ORDER BY ...] LIMIT s, n -
从第 s 行数据开始,向后筛选出 n 行数据 (比第二种用法更明确,建议使用)。
SELECT ... FROM 表名 [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
- 注意:limit 子句在筛选记录时,记录的下标从 0 开始,即第一行数据的下标为 0。
- 建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死。
🌙 4.2 limit 使用案例
- 当前准备了如下 limit 子句的使用案例。
- 按 id 对成绩表进行分页,每页 3 行数据,分别显示第 1、2、3 页。
- 查询班级总分第一名的学生
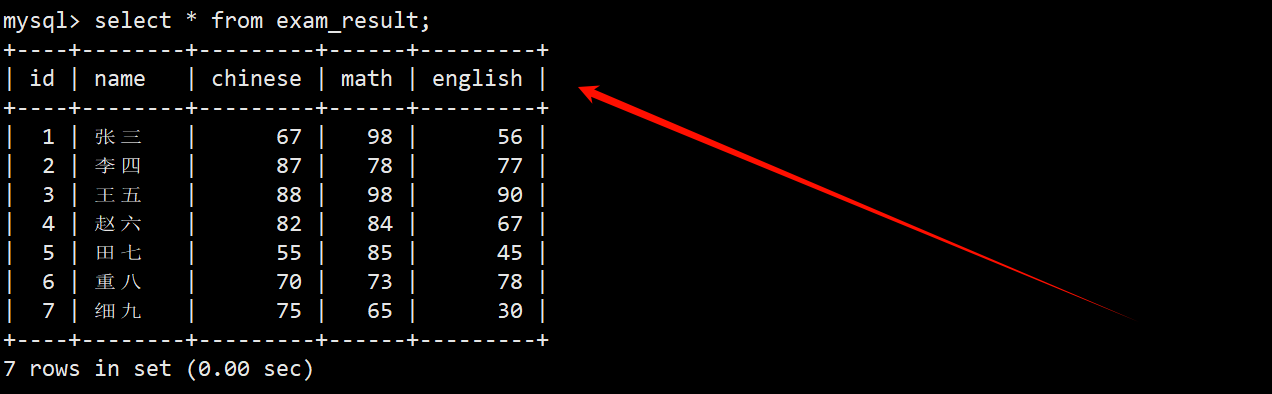
1. 按 id 对成绩表进行分页,每页 3 行数据,分别显示第 1、2、3 页
- 成绩表 exam_result 当前的表中数据如下:
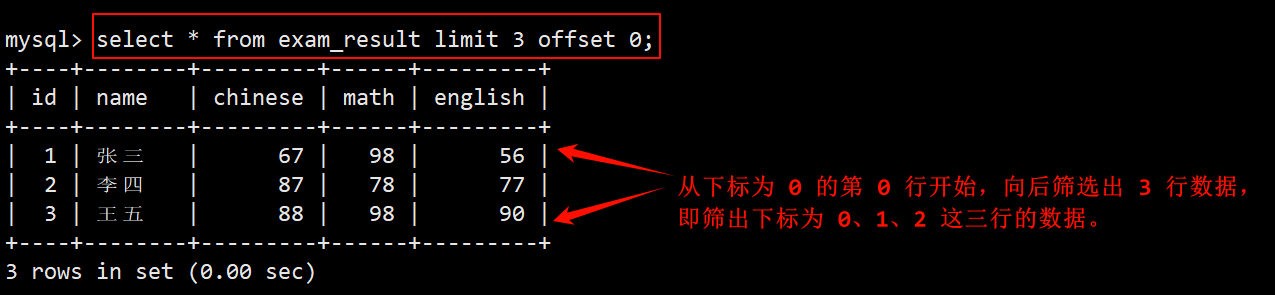
- 查询第一页:从第 0 行数据开始向后筛选出 3 行数据 (即筛出下标为 0、1、2 这三行数据)。
- 不要被主键 id 的数字影响。
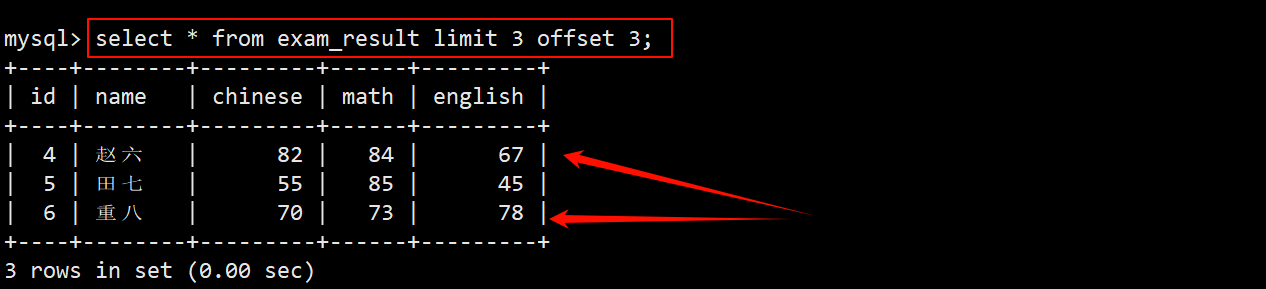
- 查询第二页:从下标为 3 的记录开始,往后筛选出 3 条记录。
- 查询第三页:从下标为 6 的记录开始,向后筛选出 3 条记录。
- 如果从表中筛选出的记录不足 n 个,则筛选出几个就显示几个。

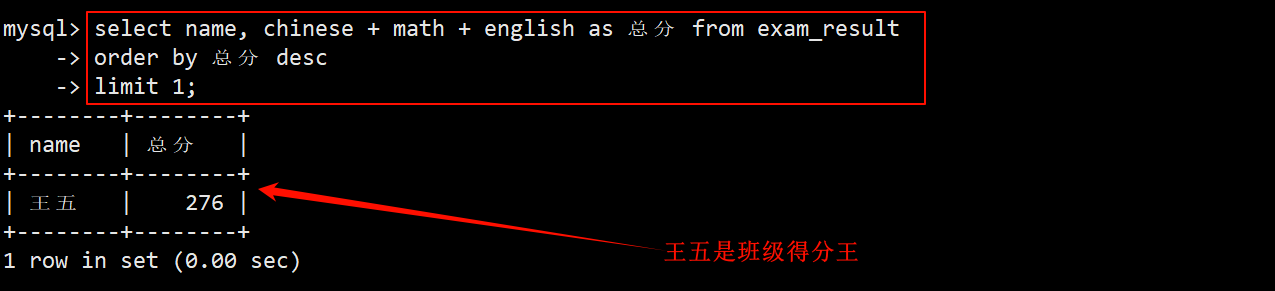
2. 查询班级总分第一名的学生
- 在 select 中显示的列为 name 和 总分,在 order by 中按照三科总分降序 desc 排序,再使用 limit 中筛选出第一行数据。
- 由于 order by 的执行顺序在 select 之后,因此可以使用 select 定义的对三科总分的别名。
🌈 三、update 修改数据
⭐ 1. update 语法格式
UPDATE 表名 SET 列名1 = 值1 [, 列名2 = 值2, ..., 列名n = 值n] [WHERE ...] [ORDER BY ...] [LIMIT ...]
- where 和 limit 是用来筛选出具体要修改的是哪几行,如果不加筛选条件,则默认是修改所有行的指定列。
- 慎用能够对全表进行更新的语句。
⭐ 2. update 使用案例
- 当前准备了如下 update 的使用案例。
- 将李四同学的数学成绩变更为 80 分。
- 将赵六同学的数学成绩变更为 60 分,语文成绩变更为 70 分。
- 将总成绩倒数前三的同学的数学成绩加上 30 分。
- 将所有同学的语文成绩变更为原来的 2 倍。
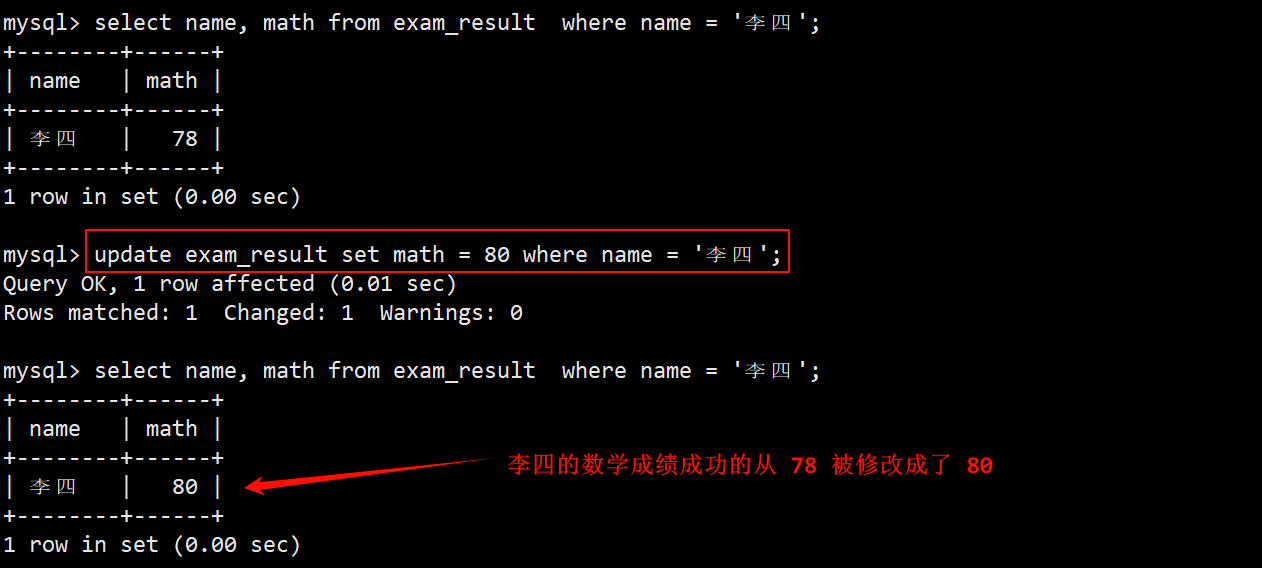
1. 将李四同学的数学成绩变更为 80 分
- 在 where 子句中使用 name = ‘李四’ 找出该同学,在在 update 中使用 set math = 80 将数学成绩变更为 80 分。
- 如果不设置像 where 这样的筛选条件,所有人的数学成绩都会被弄成 80。
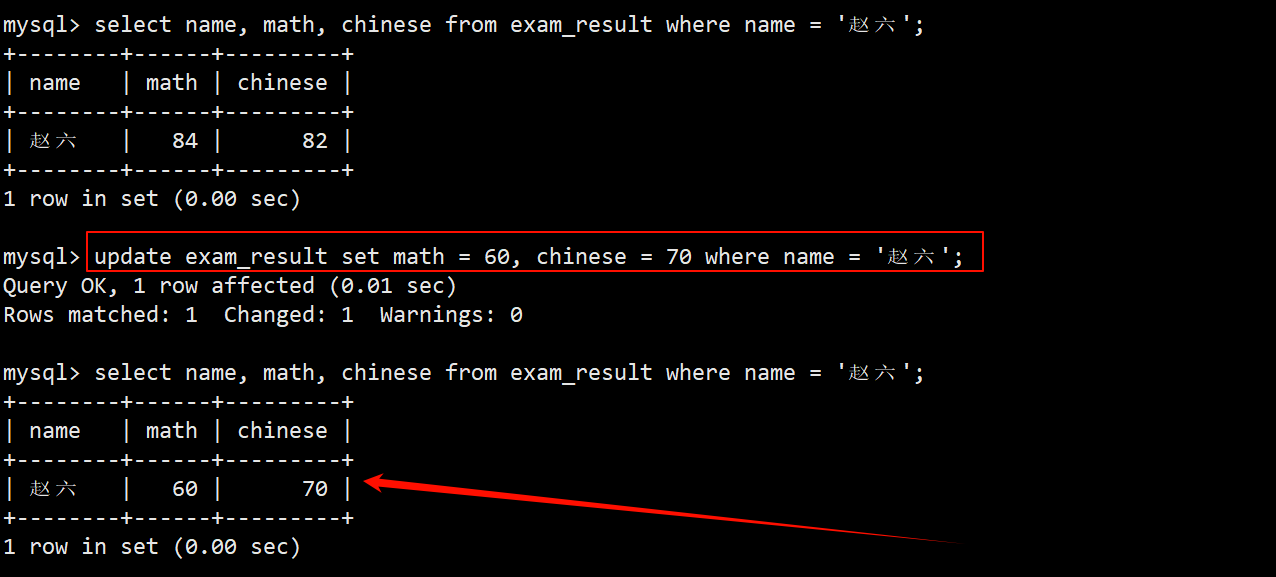
2. 将赵六同学的数学成绩变更为 60 分,语文成绩变更为 70 分
- 在 where 子句中使用 name = ‘赵六’,在 update 总使用 set math = 60, chinese = 70。
3. 将总成绩倒数前三的同学的数学成绩加上 30 分
- 找出倒数前三:在 order by 子句中将总成绩按照升序排序,再使用 limit 3 显示排序后的前 3 行数据.
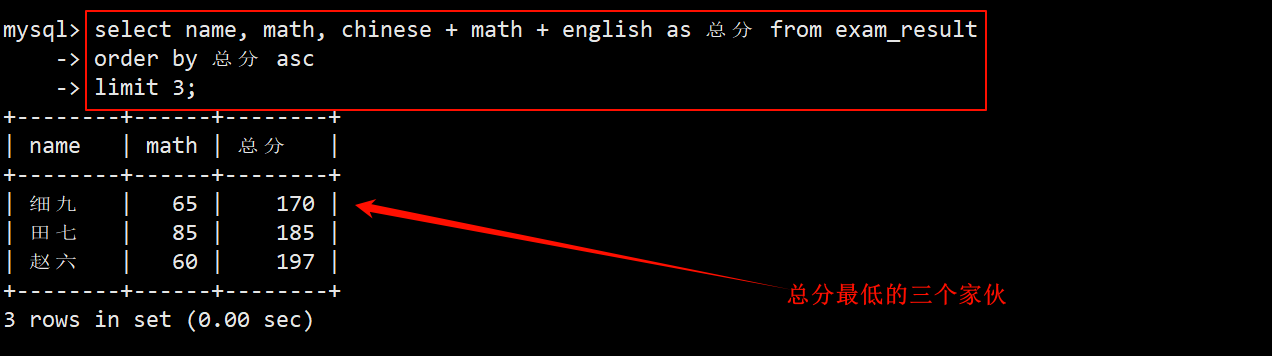
- 将这 3 个家伙的数学成绩统统加上 30 分,即在 update 中使用 set math = math + 30。
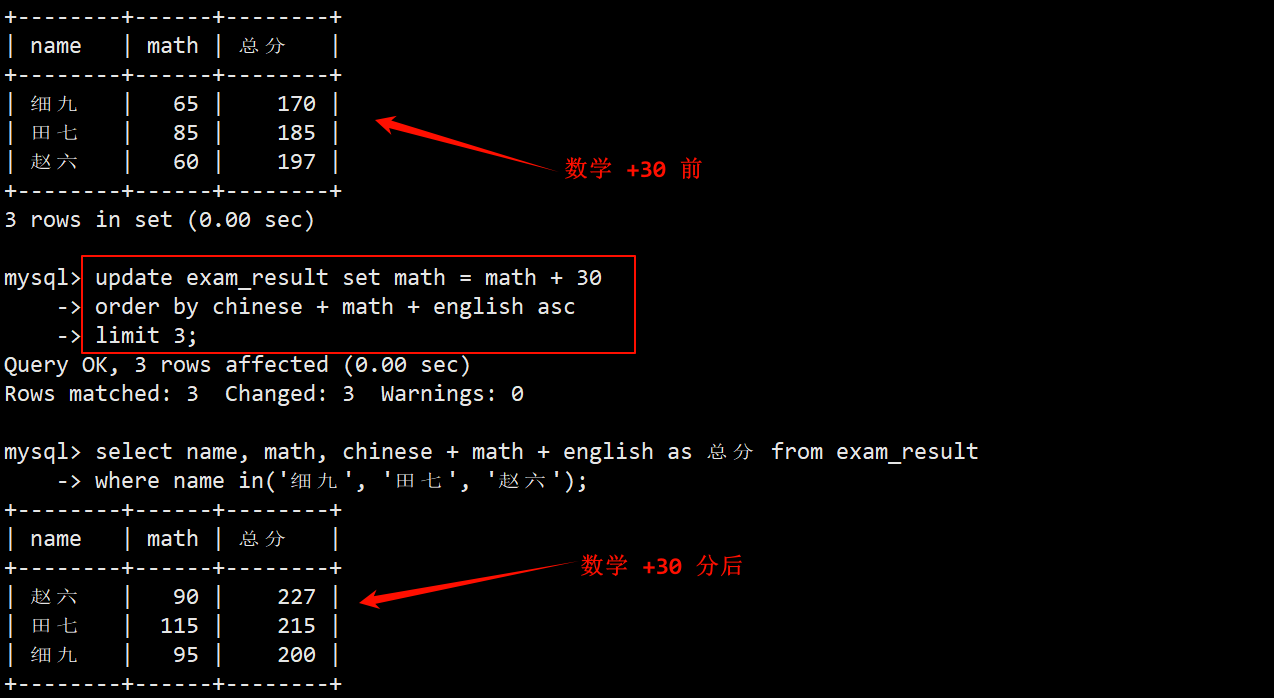
- 这 3 个人数学各加了 30 分之后可能就不再是倒数前三了,因此再执行一次查询倒数前三的操作后,显示出来的数据可能会发生变化。
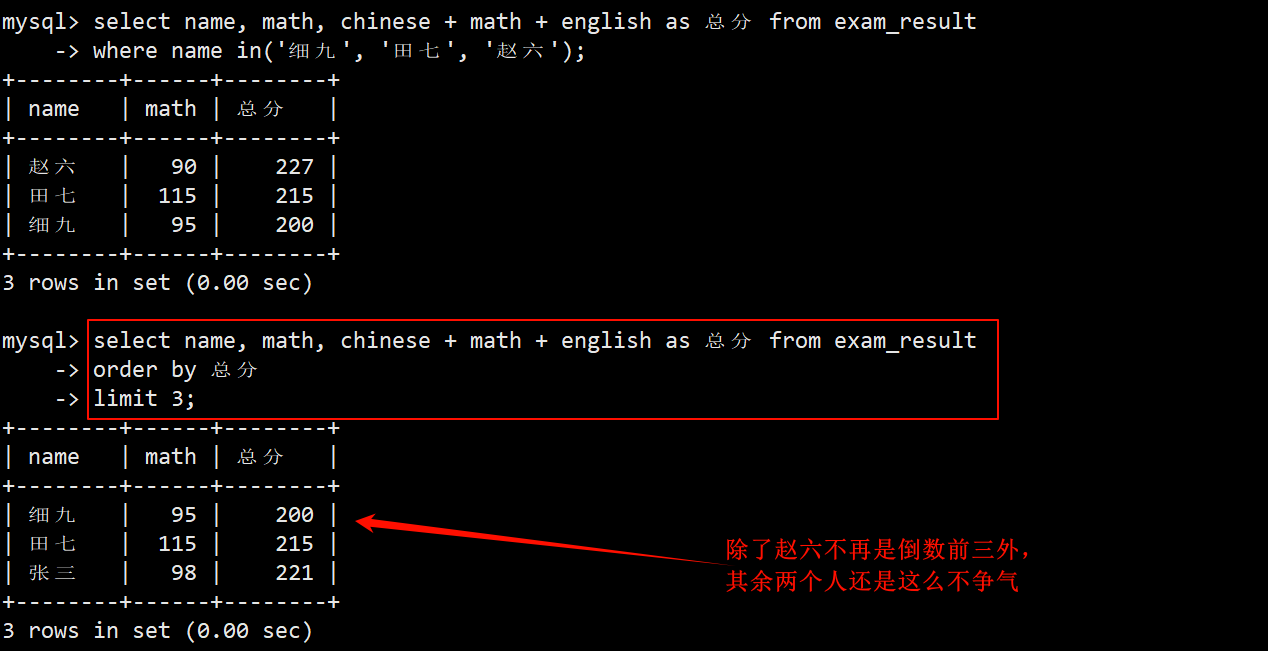
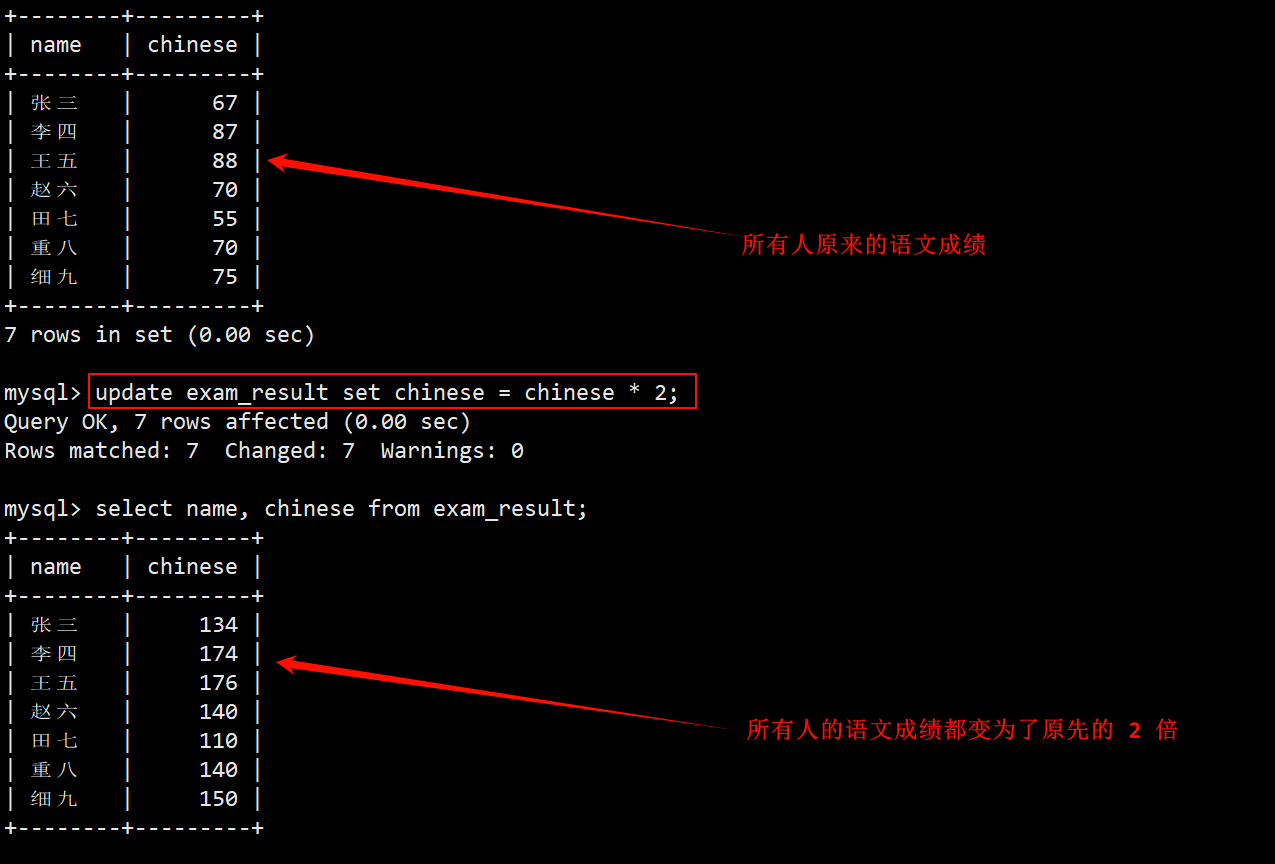
4. 将所有同学的语文成绩变更为原来的 2 倍
- 不加任何筛选条件,直接在 update 中使用 set chinese = chinese * 2 即可将所有人的语文成绩变成原来的 2 倍。
- 慎用能够对全表进行更新的语句。
🌈 四、delete 删除数据
⭐ 1. delete 语法格式
DELETE FROM 表名 [WHERE ...] [ORDER BY ...] [LIMIT ...];
- 在删除数据前需要先找到要删除的的记录,delete 语句中的 where、order by 和 limit 子句就是用筛选要删除的数据的。
- delete 删除的数据以行为单位。
- 如果不添加筛选条件的话,默认就是删除整张表的数据。
- 慎用能够对全表进行删除的语句。
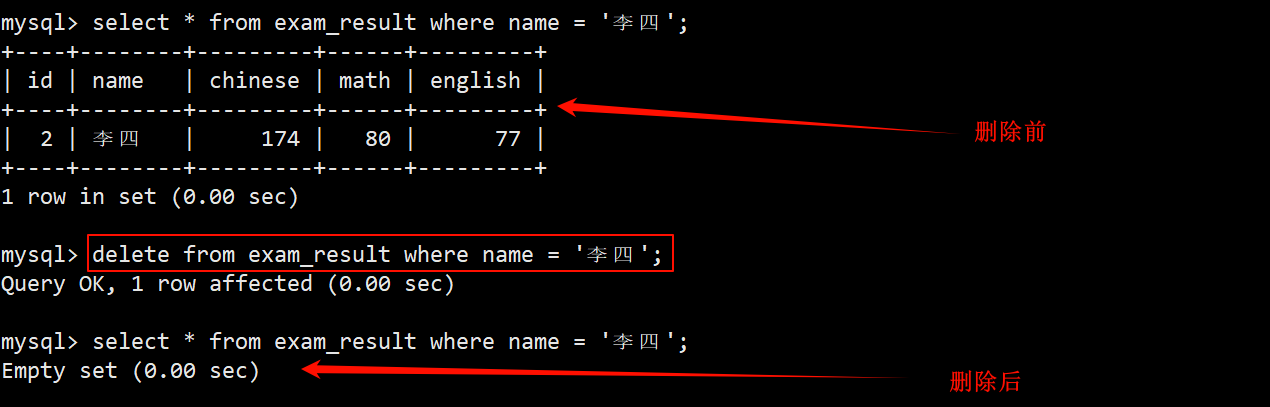
⭐ 2. 删除指定记录
删除李四同学的考试成绩
- 即将李四同学从 exam_result 成绩表中删除,在 where 子句中使用 name = ‘李四’ 筛选出李四所在的这一行数据。
⭐ 3. 删除全表数据
- 先创建一张名为 for_delete 的测试删除数据表,表中分别包含 id 和 name 两个字段。
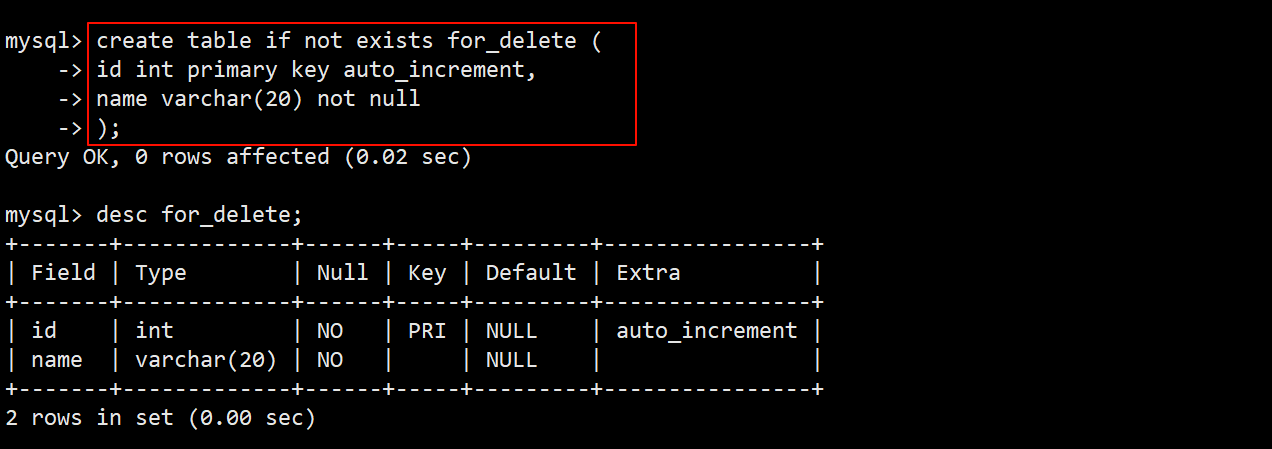
- 往表中插入一些临时数据,用来后续对其进行删除。
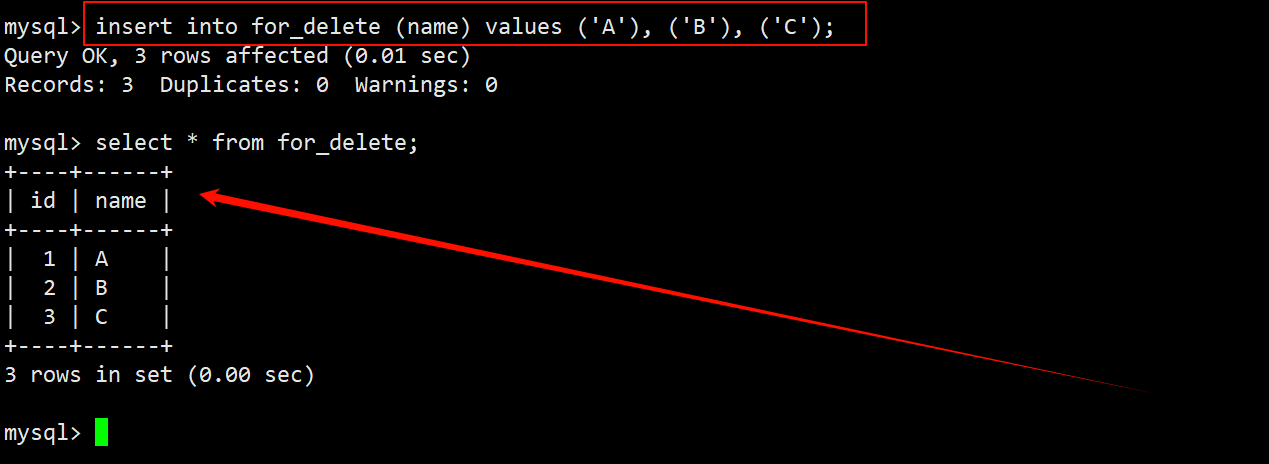
- 在 delete 语句中只指定要删除数据的表名,而不指定筛选条件,即可删除整张表的数据。
- 慎用能够对全表进行删除的语句。

- 如果之后再向该表中插入数据,但不指明自增长字段的值,会发现自增长 id 值是在之前的基础上继续增长的。
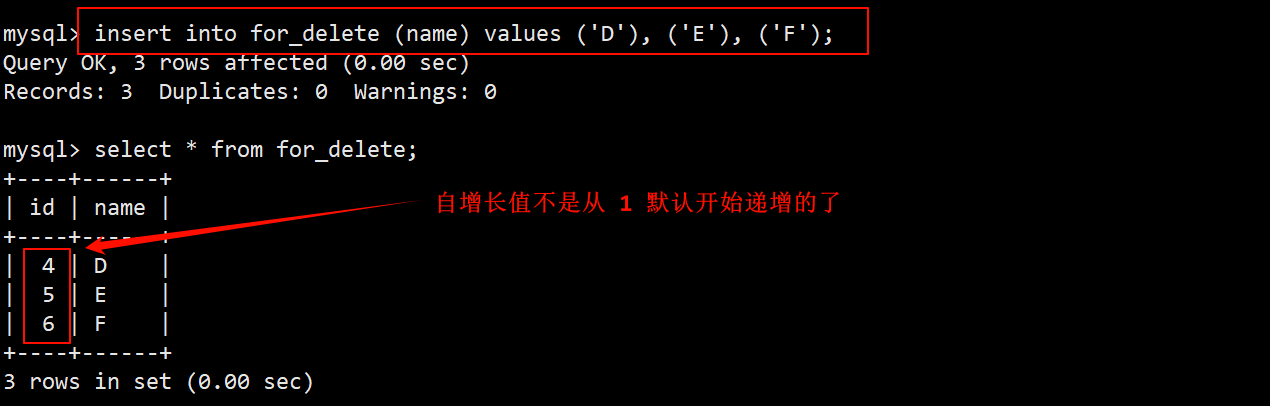
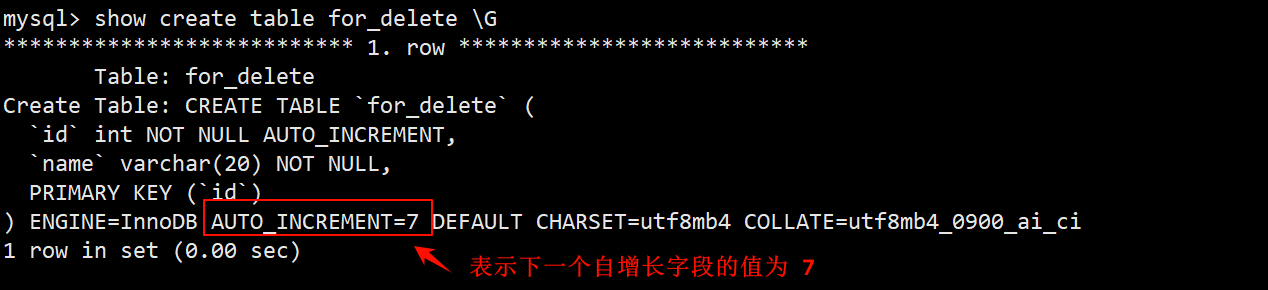
- 在查看 for_delete 的建表语句时会发现,有一个 AUTO_INCREMENT=n 的字段,该字段表示下一次插入数据时自增长字段的值应该为 n。
- 使用 delete 删除整表数据时,不会重置 AUTO_INCREMENT=n 字段,因此删除整表数据后再插入自增长字段的值会在原基础上递增。
⭐ 4. truncate 截断表
🌙 4.1 truncate 语法格式
TRUNCATE [TABLE] 表名;
- 属于清空表数据的一种,在效果上和 delete 的清空表数据一致,但细节和原理上有所差别。
- truncate 只能对整张表进行操作,不能像 delete 一样针对部分数据进行操作。
- truncate 实际上是不对数据进行操作的,在清空数据方面,会比 delete 更快。
- truncate 在删除数据的时候,不会经过真正的事务 (即不会将自己的操作记录在日志中),因此无法对数据进行回滚。
- truncate 会重置 AUTO_INCREMENT=n 这一项。
🌙 4.2 truncate 使用案例
- 创建一张名为 for_truncate 的测试截断表,表中包含一个自增长的主键 id 和 name 这两个字段。
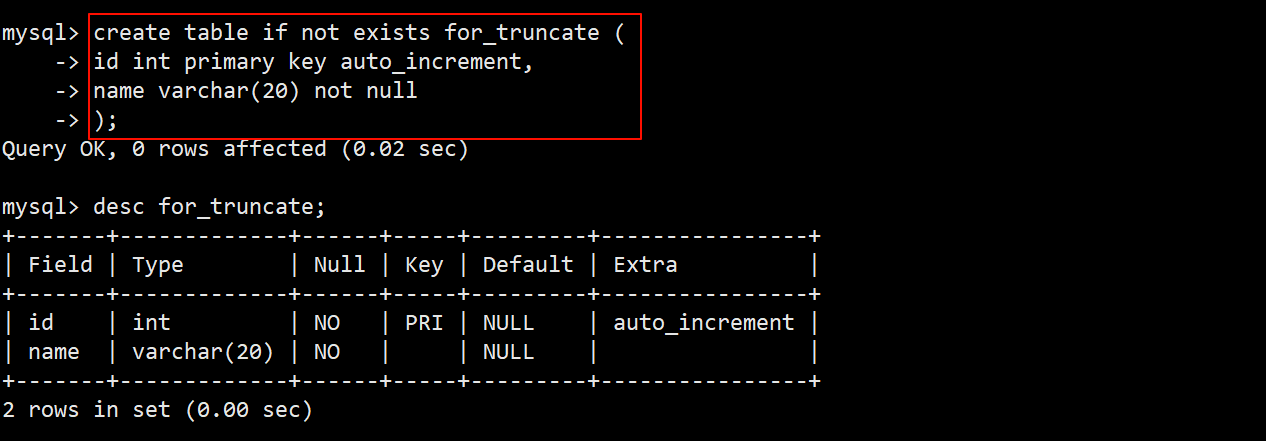
- 往表中插入一些临时数据,用来后续对其进行截断。
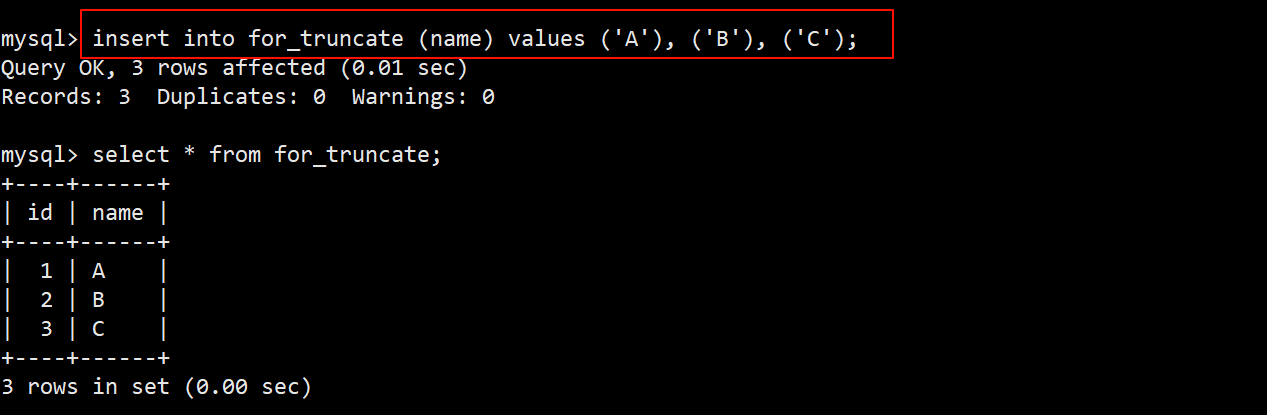
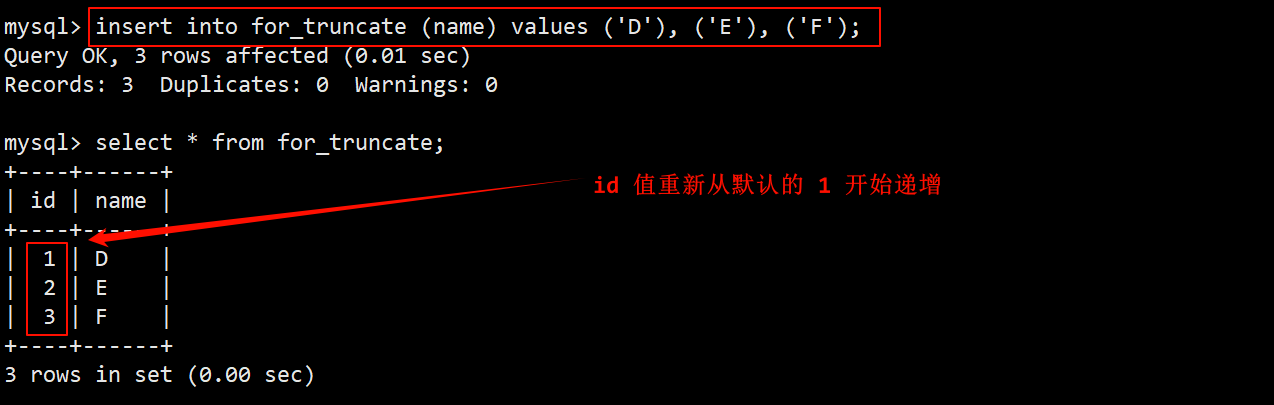
- 在 truncate 语句指定要截断的表名为 for_truncate,即可清空该表的数据。
- 因为 truncate 不会对数据进行操作,因此执行 truncate 语句后看到影响行数为 0。

- 由于 truncate 会重置 AUTO_INCREMENT=n,再往表中重新插入数,可以看到自增长字段的值从 1 开始继续递增了。
🌈 五、插入查询结果
⭐ 1. 语法格式
- MySQL 也支持将对表的查询结果插入到另一张表中。
INSERT [INTO] 表名 [(列1 [, 列2, ..., 列n] ...)] SELECT ... [WHERE ...] [ORDER BY ...] [LIMIT ...];
- 该语句的作用是将从其他表中筛选出来的数据插入到指定的表中。
- 其中的列1 ~ 列n 表示将筛选出的记录的各个列插入到表中的指定列。
⭐ 2. 使用案例
- 案例:删除表中重复的记录,让重复的数据只能有一份。
1. 准备工作
- 创建一张名为 duplicate_table 的测试用表,表中包含 id 和 name 两个字段。
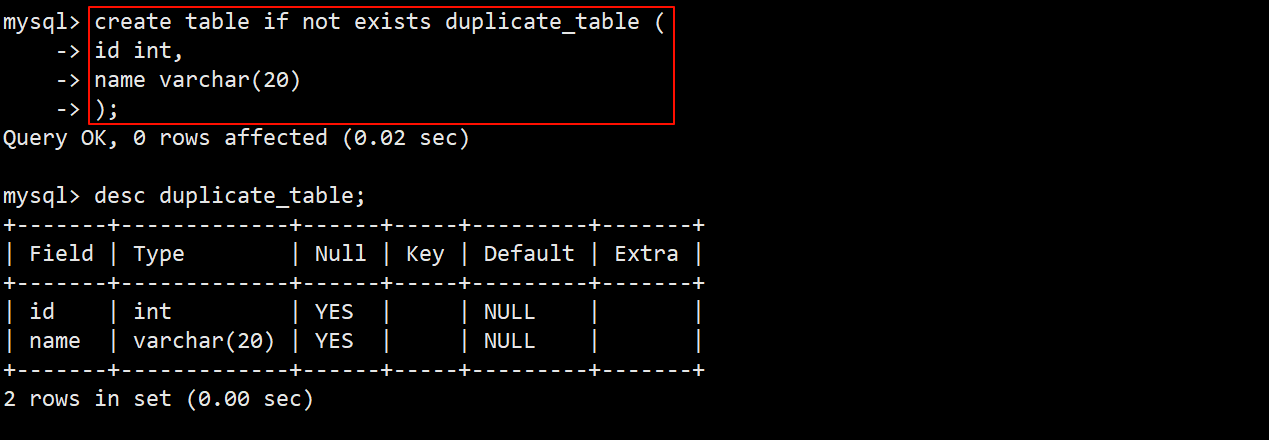
- 往表中插入一些包含重复数据的测试数据。
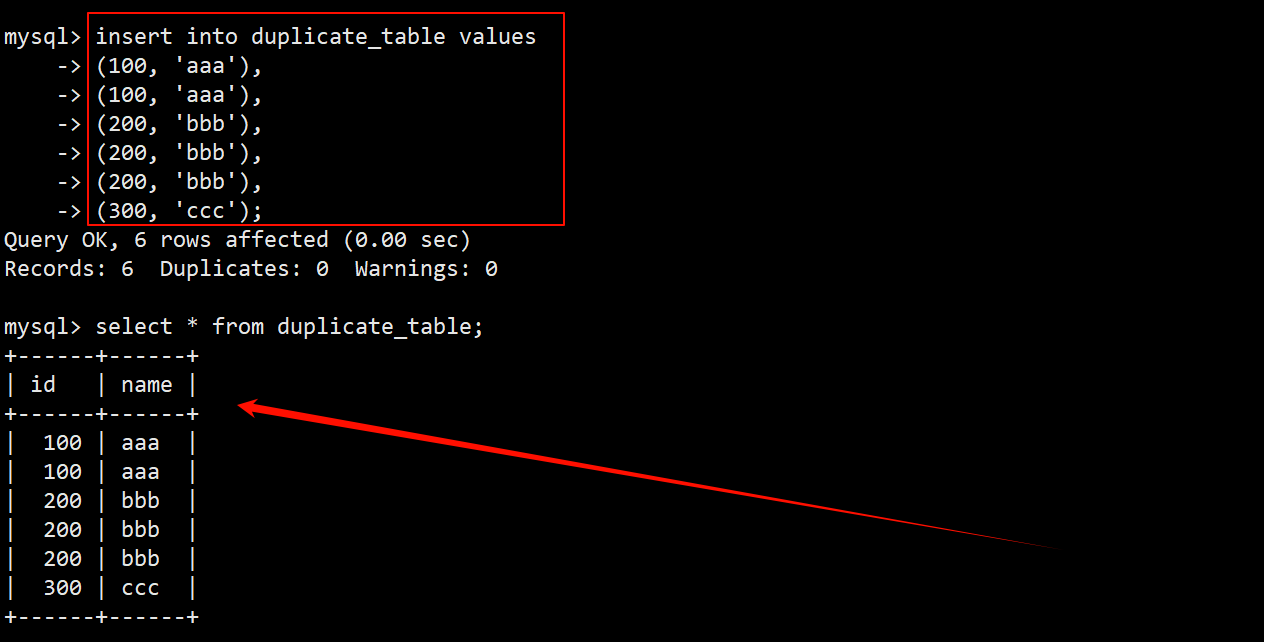
2. 删除表中重复的数据
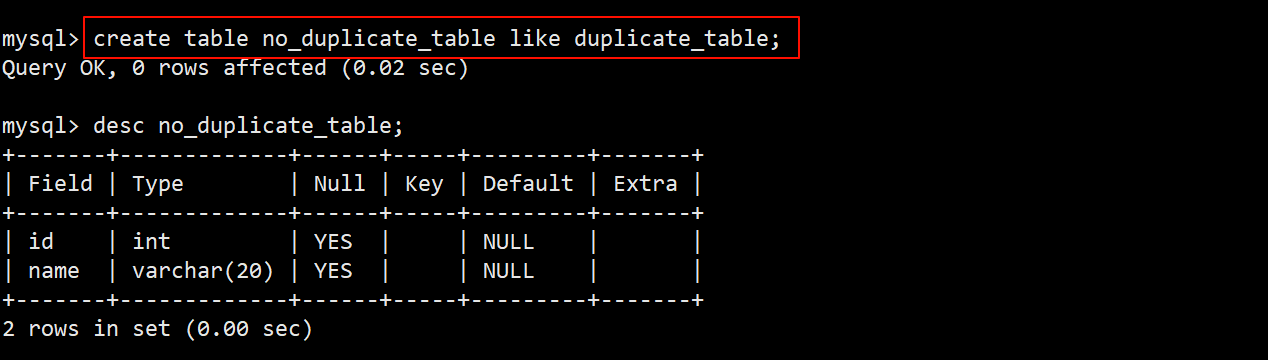
- 创建一张临时的空表 no_duplicate_table,其表结构和 duplicate_table 一致。
- 由于两张表的表结构相同,因此在创建临时表时可以借助 like。
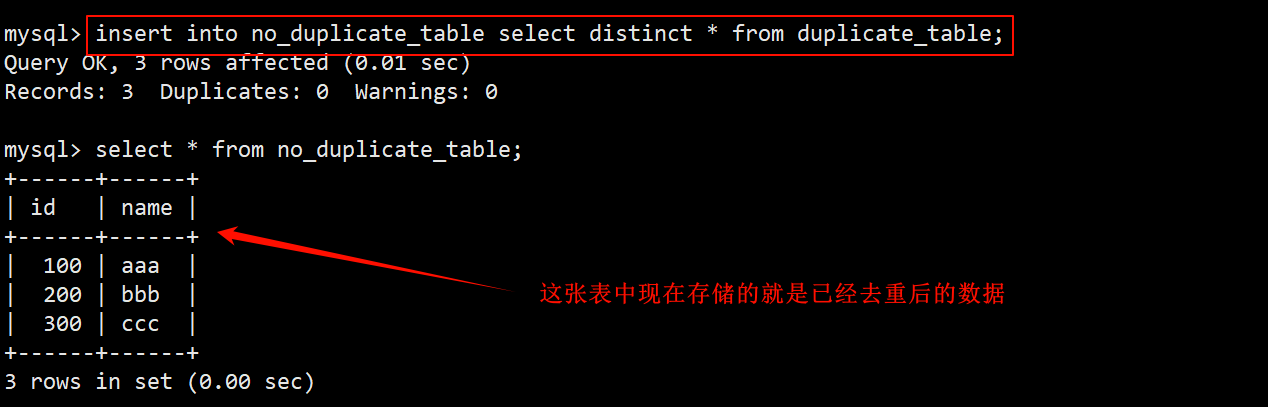
- 将 duplicate_table 的数据使用 DISTINCT 去重后插入到 no_duplicate_table 表中。
- 由于两张表的表结构一致,并且 select 进行的是全列查询,因此在插入时不用在表名后指定字段列表。
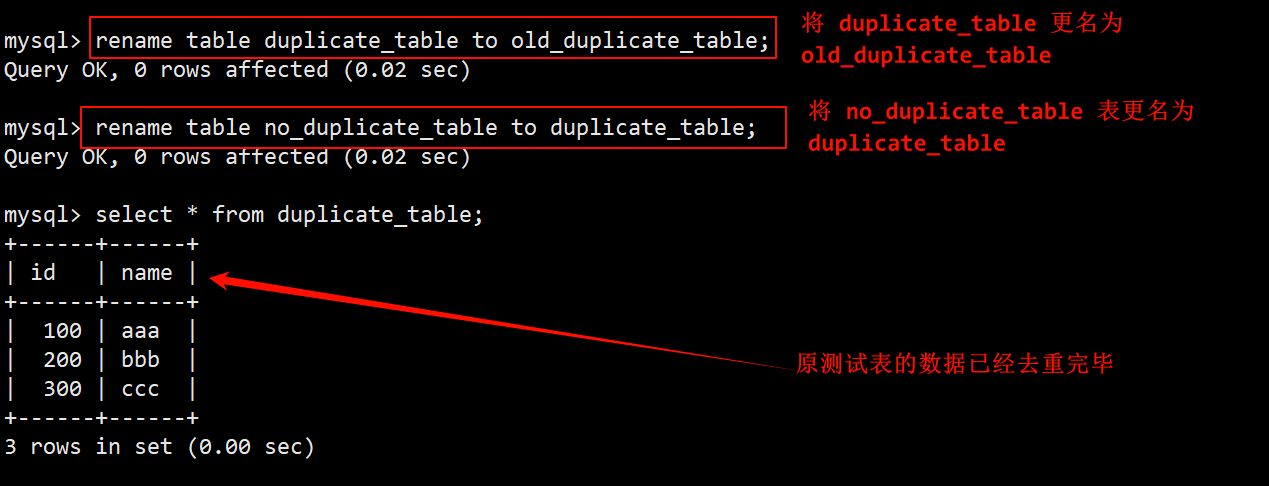
- 分别对两张表进行重命名操作,实现原子的去重操作。
- 将 duplicate_table 测试表重命名为其他名字 (相当于对去重前的数据进行备份,如果不需要可以直接删除);
- 将 no_duplicate_table 临时表重命名为 duplicate_table 测试表的名字,此时便完成了对原始表数据的去重操作。
🌈 六、聚合函数
select 函数名(参数) from 表名 [WHERE ...] [ORDER BY ...] [LIMIT ...];
- 聚合函数能够对一组值进行计算,并返回单一的值。
- 这些函数以查询出的记录为单位做聚合统计。
⭐ 1. 常见聚合函数
- 聚合函数可以在 select 语句中使用,select 在每处理一条记录时,都会将对应的参数传递给这些聚合函数。
| 函数 | 说明 |
|---|---|
| COUNT ( [DISTINCT] expr ) | 返回查询到的数据的数量 |
| SUM ( [DISTINCT] expr ) | 返回查询到的数字的总和,expr 参数如果不是数字则没有意义 |
| AVG ( [DISTINCT] expr ) | 返回查询到的数据的平均值,expr 参数如果不是数字则没有意义 |
| MAX ( [DISTINCT] expr ) | 返回查询到的数据的最大值,expr 参数如果不是数字则没有意义 |
| MIN ( [DISTINCT] expr ) | 返回查询到的数据的最小值,expr 参数如果不是数字则没有意义 |
⭐ 2. 聚合函数案例
- 当前准备了如下聚合函数使用案例。
- 统计班级共有多少名同学。
- 统计班级收集的 qq 号有多少。
- 统计本次考试的数据成绩分数个数。
- 统计所有同学的数学成绩总分。
- 统计所有同学的三科总分的平均值。
- 返回英语成绩的最高分。
- 返回 > 80 分的的数学的最低分。
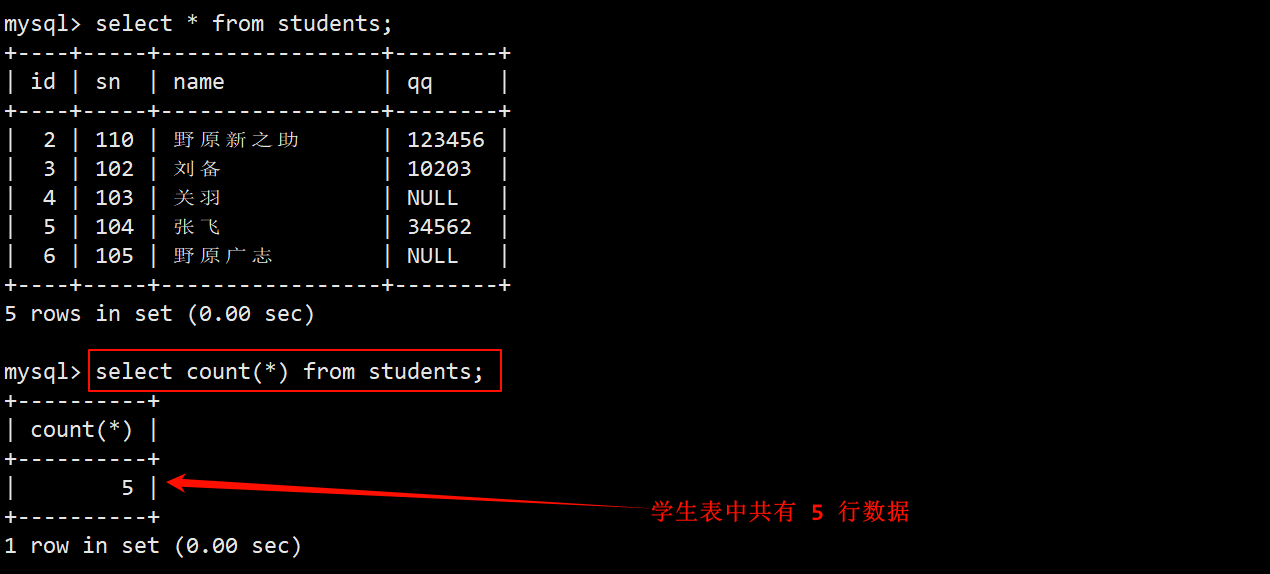
1. 统计班级共有多少名同学
- 使用 * 统计:在 select 语句中,使用 count 函数时,可将 * 作为参数传递给它,用以统计表中有多少行数据。
- 对学生表进行操作。
- 使用该表达式统计:在 select 语句中,使用 count 函数时,可将表达式作为参数传递给它,用以统计表中有多少行数据。

- 使用表达式做统计这种写法相当于在查询表中数据时,临时新增了一列名为对应表达式的列,用 count 函数统计该列中有多少行数据。
- 在这里只是新增了一列数字 1,然后 count 统计的是这一列的 1 的个数。

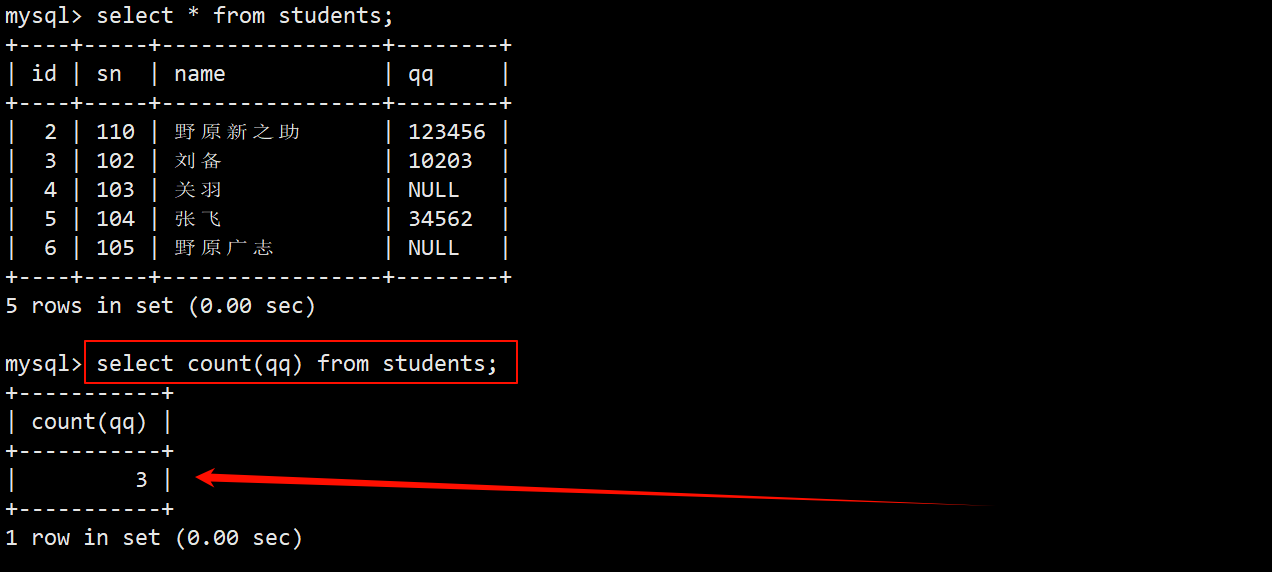
2. 统计班级收集的 qq 号有多少
- 在 select 语句中,使用 count 函数统计 qq 那一列中数据的个数。
- 由于 count 函数的参数是一个确定的字段名,因此 count 会自动忽略 null 值。
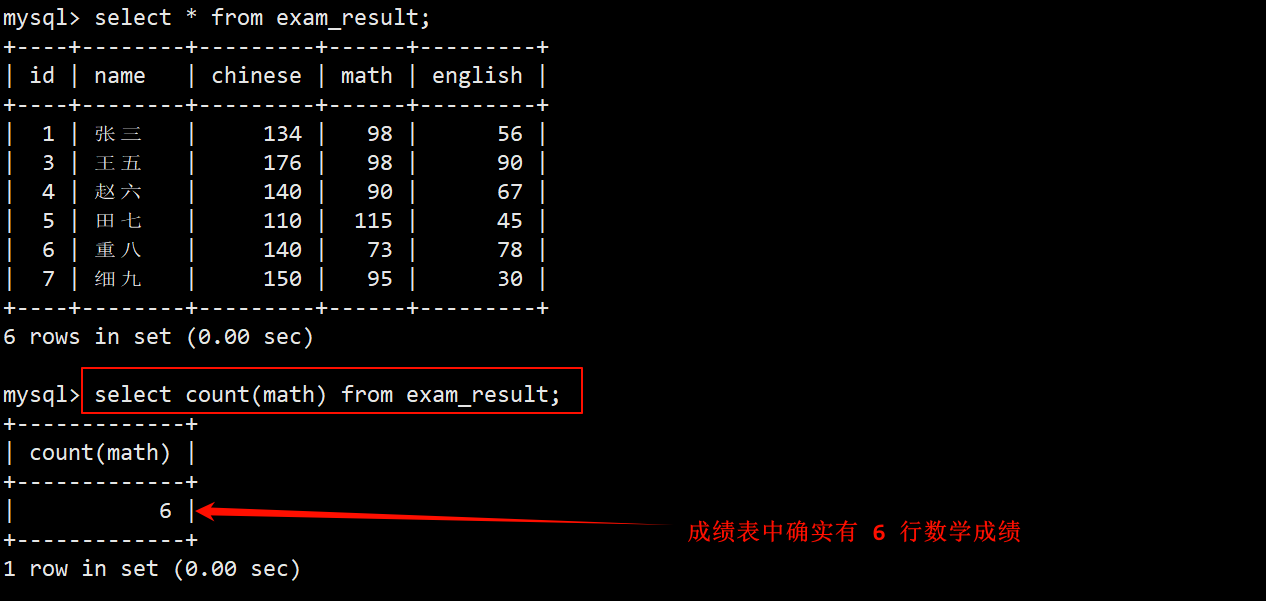
3. 统计本次考试的数据成绩分数个数
- 统计数学分数的个数:在 select 语句中,使用 count 函数统计 math 那一列中数据的个数。
- 对成绩表进行操作。
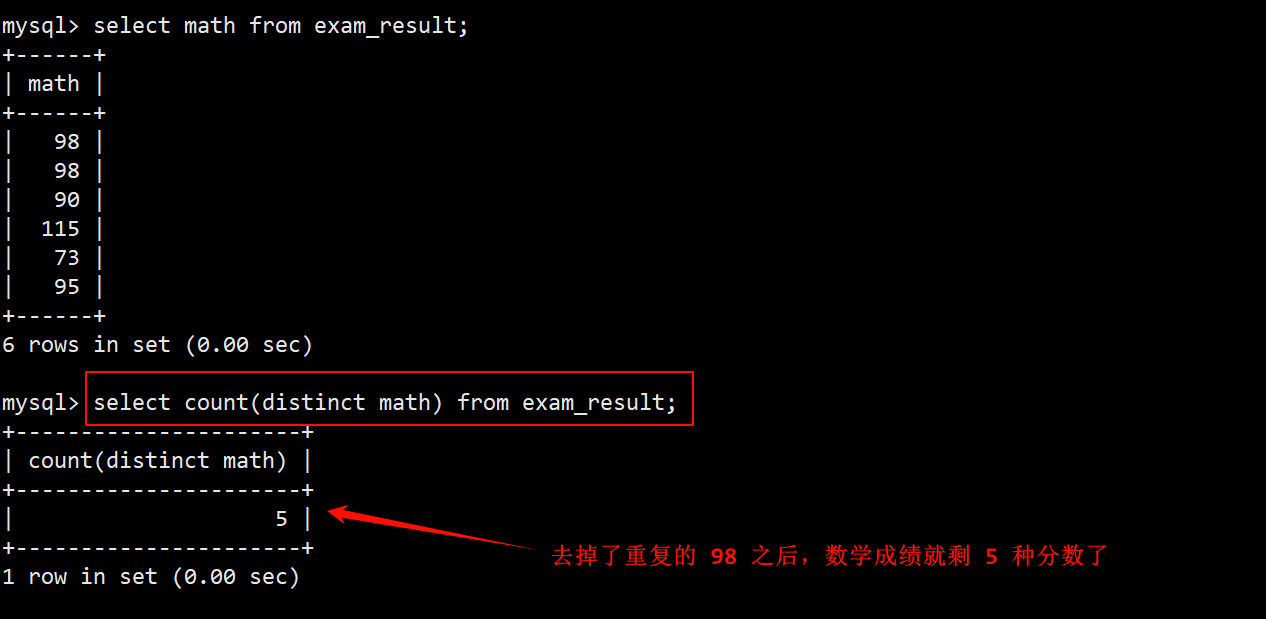
- 统计数学分数的种类:即要执行去重操作,在传递给 count 函数的参数中,加上一个 distinct 即可。
4. 统计所有同学的数学成绩总分
- 统计数学成绩总分:在 select 语句中使用 sum 函数统计 math 这一列数据的总和。

- 统计不及格的数学成绩总分:在 where 子句种指定筛选条件为 math < 60,在 select 语句种使用 sum 函数统计 math 这一列被 where 子句筛选出来的的数据之后。

5. 统计所有同学的三科总分的平均值
- 在 select 语句中使用 avg 函数计算所有同学的 chinese + math + english 的平均值。

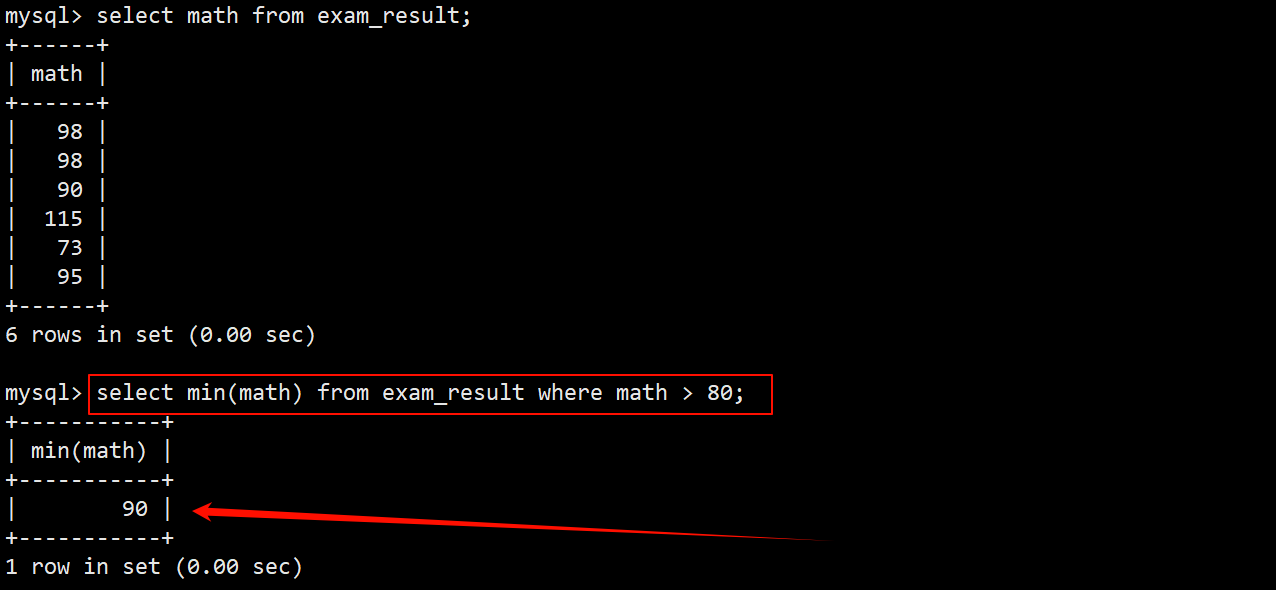
6. 返回英语成绩的最高分
- 在 select 语句中使用 max 函数 english 这一列中所有数据的最大值。
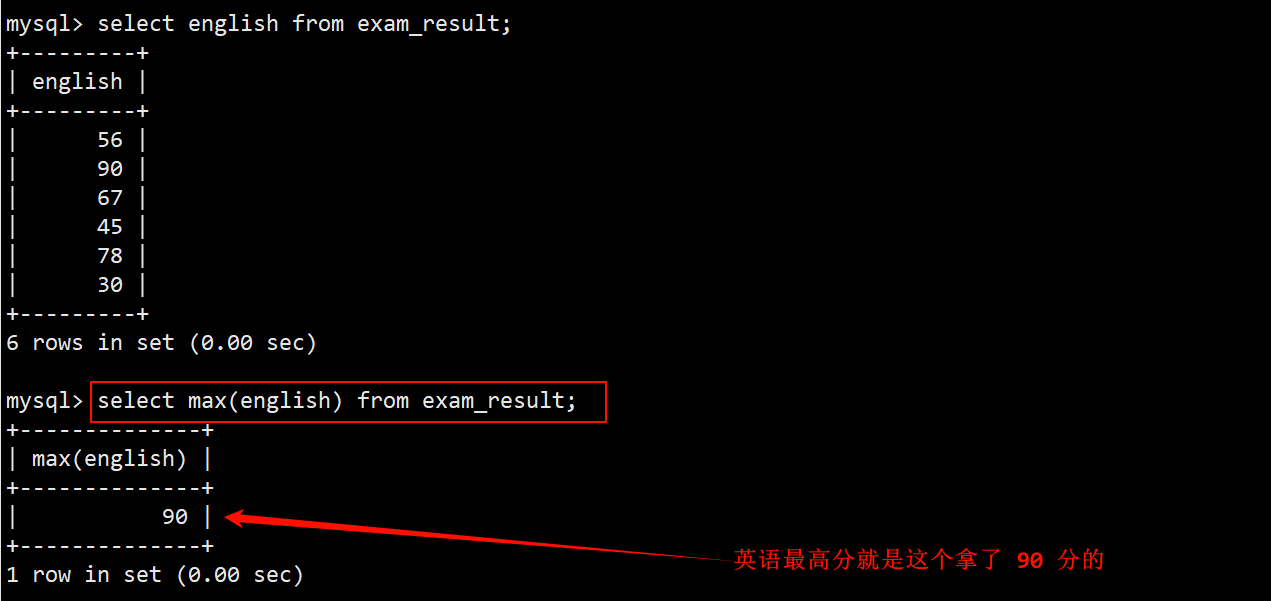
7. 返回 > 80 分的的数学的最低分
- 在 where 子句中指定筛选条件为 math > 80,然后在 select 语句中使用 min 函数取 math 这一列被筛选出来的数据的最小值。
🌈 七、group by 分组查询
⭐ 1. 分组概念
-
分组是指对表中的数据进行分组,分组的目的是为了方便聚合统计。
- 例:根据性别将成绩分成两组,再对这两组数据分别进行聚合统计。
-
指定列名,实际分组,是用所指定发的列的不同的行数据来进行分组的。
-
分组就是将一张表按照指定条件分成了多个组,进行各自组内的统计。
-
分组也被称为 “分表”,就是将一张表按照指定的条件再逻辑上拆分成了多个子表,然后再分队对各自的子表进行聚合统计。
- 在 MySQL 中,一切皆表,只要能够处理好对一张表的增删查改,则所有的 sql 场景都能用统一的方式进行。
⭐ 2. group by 语法格式
select 字段列表 from 表名 [where 分组前过滤条件] group by 分组字段名 [having 分组后过滤条件];
⭐ 3. group by 使用案例
🌙 3.1 准备工作
1. 创建数据库
- 创建一个名为 scott 的数据库,并将其设置成当前操作数据库。
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott`;USE `scott`;
2. 创建雇员信息表
- 创建一张雇员信息表,表中包含三张表:员工表 (emp)、部门表 (dept)、工资等级表 (salgrade)。
- 部门表 dept 包含的字段有:部门编号 (deptno)、部门名称 (dname)、部门所在地 (loc)。
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept`
(`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
- 员工表 emp 包含的字段有:员工编号 (empno)、员工姓名 (ename)、员工职位 (job)、员工领导编号 (mgr)、雇佣时间 (hiredate)、月薪 (sal)、奖金 (comm)、部门编号 (deptno)。
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp`
(`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7, 2) DEFAULT NULL COMMENT '工资月薪',`comm` decimal(7, 2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
- 工资等级表 salgrade 包含的字段有: 等级 (grade)、该等级所对应的最低工资 (losal)、该等级所对应的最高工资 (hisal)。
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade`
(`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
3. 插入数据
- 往部门表 dept 中插入数据:
insert into dept (deptno, dname, loc) values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc) values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc) values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc) values (40, 'OPERATIONS', 'BOSTON');
- 往员工表 emp 中插入数据:
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500, 0, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
- 往 工资等级表 salgrade 中插入数据:
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
🌙 3.2 使用案例
- 当前为 group by 准备了如下两种案例
- 显示每个部门的平均工资和最高工资。
- 显示每个部门的每种岗位的平均工资和最低工资。
- 显示不包含员工名为 SMITH 在内的每个部门的每种岗位最高和最低工资。
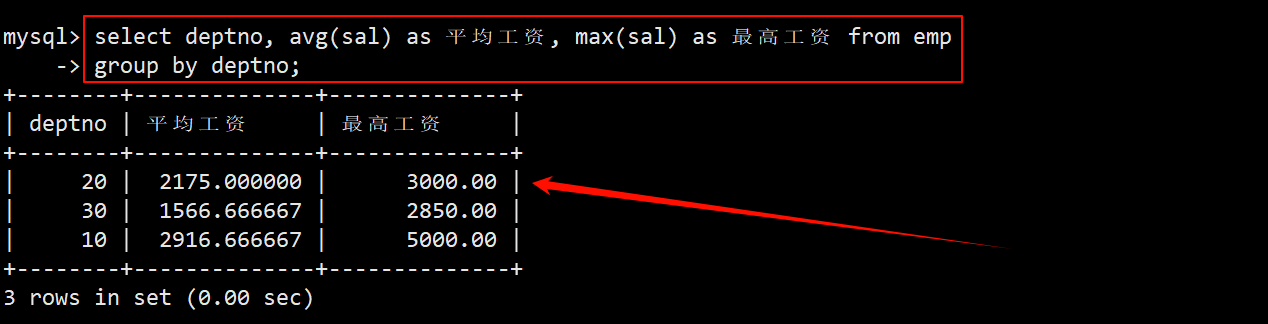
1. 显示每个部门的平均工资和最高工资
- 在员工表 emp 中查询:在 group by 子句中指定按照部门编号 deptno 进行分组。在 select 语句中使用 avg 函数和 max 函数,然后查询筛选出来的所有分组的平均工资和最高工资。
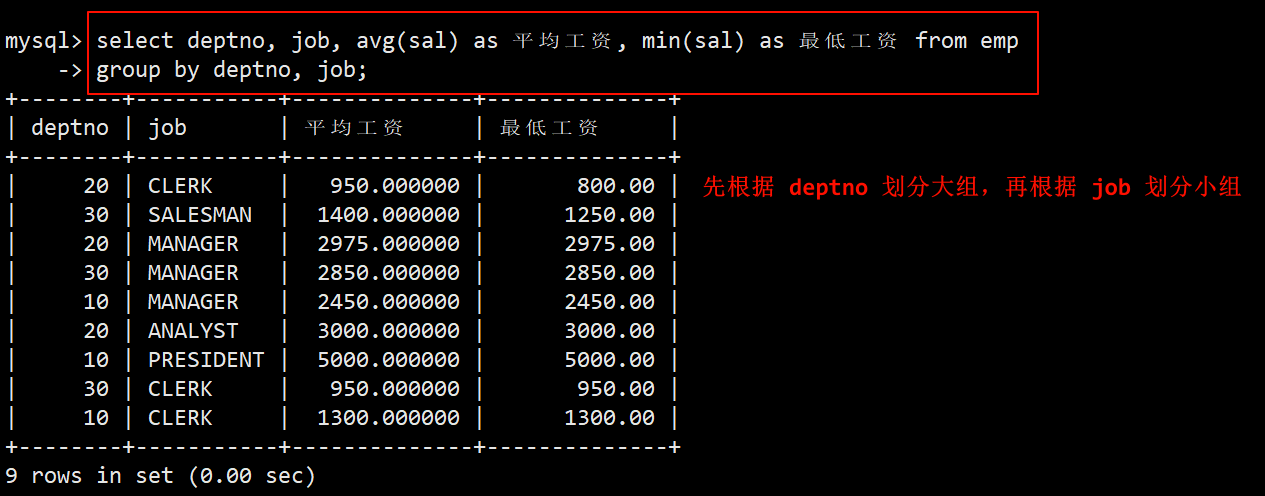
2. 显示每个部门的每种岗位的平均工资和最低工资
- 在员工表 emp 中查询:在 group by 子句中指定按照部门编号 deptno 先分成多个大组,再按照岗位 job 将这些大组划分成多个小组。在 select 语句中使用 avg 函数和 min 函数,然后查询筛选出来的所有小组的平均工资和最低工资。
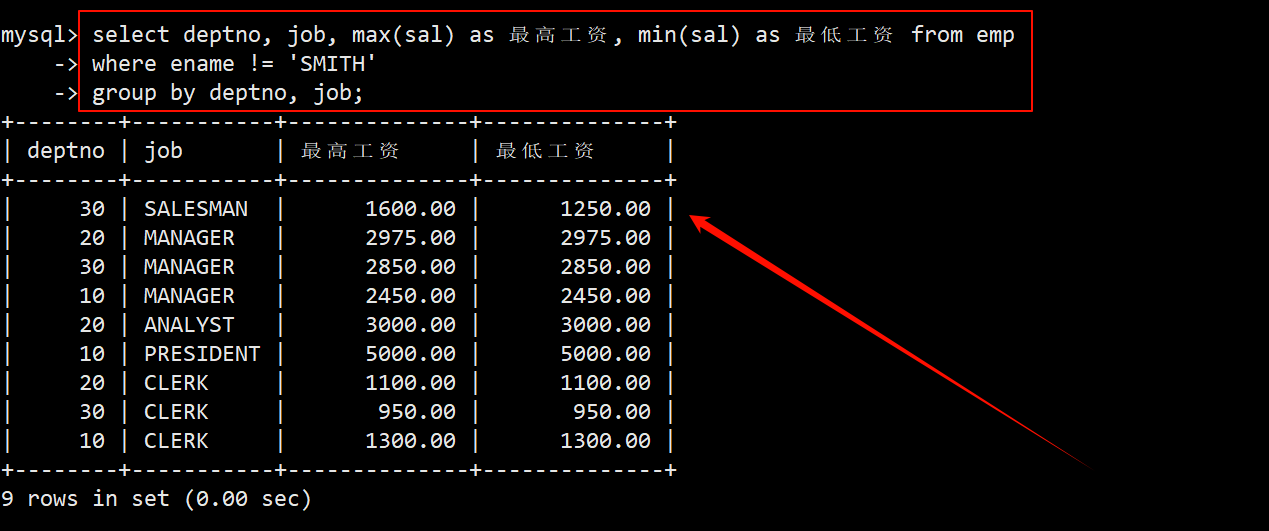
3. 显示不包含员工名为 SMITH 在内的每个部门的每种岗位最高和最低工资
- 在 where 子句中指定员工姓名 ename != ‘SMITH’。在 group by 子句中指定按照部门编号 deptno 分大组,再按照岗位 job 分小组。在 sleect 语句中使用 max 和 min 求每个小组的薪水 sal 最大最小值。
⭐ 4. having 条件
SELECT ... FROM table_name [WHERE ...] [GROUP BY ...] [HAVING ...] [order by ...] [LIMIT ...];
- 在 having 子句中,可以指定 1 ~ n 个筛选条件。
🌙 4.1 having 使用案例
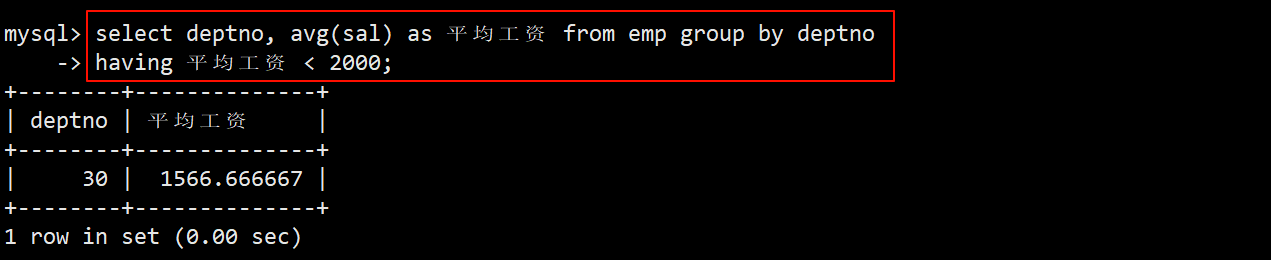
显示平均工资低于2000的部门和它的平均工资
- 统计每个部门的平均工资:在 group by 子句中指定按照部门编号 deptno 进行分组。在 select 语句中使用 avg 函数查询每个分组的平均工资。
- 通过 having 子句筛选出平均工资低于 2000 的部门:在 having 子句中指定筛选条件为 avg(sal) < 2000。
🌙 4.2 where 和 having 的区别
-
where 子句放在表名之后,而 having 子句必须搭配 group by 子句使用,放在group by 子句之后。
-
where 子句是具体的任意列进行条件筛选,而 having 子句是对分组聚合后的数据进行条件筛选。
-
where 子句中不能使用聚合函数和别名,而 having 子句中可以使用聚合函数和别名。
-
where 的执行顺序在分组之前,而 having 的执行顺序在分组之后。
相关文章:
【MySQL 07】表的增删查改 (带思维导图)
文章目录 🌈 一、insert 添加数据⭐ 1. 单行数据 全列插入⭐ 2. 多行数据 指定列插入⭐ 3. 插入否则更新⭐4. 插入否则替换 🌈 二、select 查询数据⭐ 1. select 列🌙 1.1 全列查询🌙 1.2 指定列查询🌙 1.3 查询字段…...

快速上手Git
Git相关概念 Git是一个开源的分布式版本控制系统,由Linus Torvalds在2005年创建,用于有效、高速地处理从小到大的项目版本管理。它是由 Linux 之父 Linus Torvalds 开发的,并已经成为了现代软件开发领域中最流行的版本控制系统之一。 git的工…...

RTC时钟测试
1. 基础知识 Linux 的系统时间有时跟硬件时间是不同步的。 Linux时钟分为系统时钟(System Clock)和硬件(Real Time Clock,简称RTC)时钟。系统时钟是指当前Linux Kernel中的时钟,而硬件时钟则是主板上由电池供电的时钟,这个硬件时钟可以在BIO…...
大数据技术——实战项目:广告数仓(第六部分)报表数据导出至clickhouse
目录 第11章 报表数据导出 11.1 Clickhouse安装 11.2 Clickhouse建表 11.2.1 创建database 11.2.2 创建table 11.3 Hive数据导出至Clickhouse 第11章 报表数据导出 由于本项目最终要出的报表,要求具备交互功能,以及进行自助分析的能力,…...

Android studio模拟制作-简易的订餐交易小案例
一、最终呈现效果 订餐支付小案例效果 二、布局设计activity_main.xml <?xml version"1.0" encoding"utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android"http://schemas.android.com/apk/res/android"xml…...
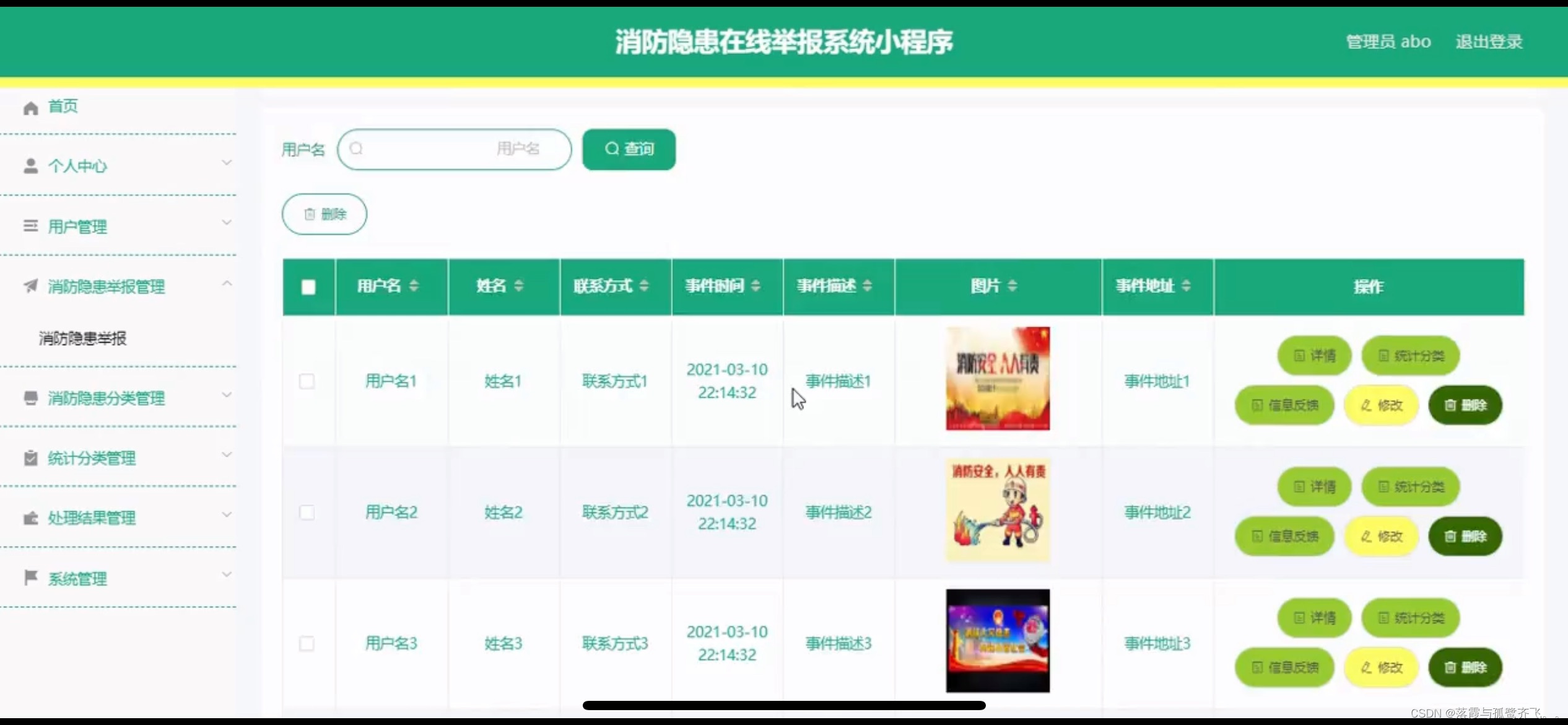
消防隐患在线小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,消防隐患举报管理,消防隐患分类管理,统计分类管理,处理结果管理,系统管理 微信端账号功能包括:系统首页,我…...

【Vue3】路由Params传参
【Vue3】路由Params传参 背景简介开发环境开发步骤及源码总结 背景 随着年龄的增长,很多曾经烂熟于心的技术原理已被岁月摩擦得愈发模糊起来,技术出身的人总是很难放下一些执念,遂将这些知识整理成文,以纪念曾经努力学习奋斗的日…...
授权cleanmymac访问全部磁盘 Mac授权访问权限 cleanmymac缺少权限
CleanMyMac是Mac系统下的一款专业的苹果电脑清理软件,同时也是一款优秀的电脑系统管理软件。它能有效清理系统垃圾,快速释放磁盘内存,缓解卡顿现象,保障系统顺畅地运行。 全磁盘访问权限,就好比机场内进行的安全检查。…...

Ubuntu/18.04 LTS下编译 BoringSSL 库
1、准备一个 Ubuntu/18.04 LTS 系统的设备 2、安装软件 GIT、GCC、CMAKE、G、Golang:1.16 及以上版本 3、克隆仓库源 git clone https://boringssl.googlesource.com/boringssl cd boringssl 4、使用特定版本 git checkout 9fc1c33e9c21439ce5f87855a6591a9324e569fd 5、编…...

【stm32项目】多功能智能家居室内灯光控制系统设计与实现(完整工程资料源码)
多功能智能家居室内灯光控制系统设计与实现 目录: 目录: 前言: 一、项目背景与目标 二、国内外研究现状: 2.1 国内研究现状: 2.2 国外研究现状: 2.3 发展趋势 三、硬件电路设计 3.1 总体概述 3.2 硬件连接总…...

xss靶场详解
目录 1.第一题 2.第二题 3.第三题 4.第四题 5.第五题 6.第六题 7.第七题 8.第八题 1.第一题 在源码script标签里边,innerhtml是用于访问或修改 HTML 元素内的 HTML 内容的,这里是访问spaghet这个元素的,并通过括号里面的东西搜索当前…...
华为的流程管理
华为建设流程体系始于2000年,那时华为公司面临着快速扩张和全球化发展的挑战,意识到传统的管理模式已经无法满足业务发展的需求。为了提高公司的管理效率和竞争优势,华为决定启动流程体系的建设。在建设过程中,华为借鉴了业界最佳…...

操作系统Linux
1.Linux命令 ls:查看当前目录下所有目录和文件ps:查看所有正在运行的进程top:显示当前系统中占用资源最多的一些进程,shiftm按照内存查看大小netstat:查看端口的命令vi:查看文件的命令rm:删除文…...

1、.Net UI框架:MAUI - .Net宣传系列文章
.NET MAUI(Multi-platform App UI)是一个跨平台的UI框架,它是.NET统一应用模型的一部分,允许开发者使用C#和.NET来创建适用于iOS、Android、macOS和Windows的应用程序。MAUI继承了Xamarin.Forms的一些概念,但提供了更多的原生平台集成和改进的…...

Spring boot 使用 jSerialComm 对串口使用发送信息并接收
什么是 jSerialComm? jSerialComm 是一个 Java 库,旨在提供一种独立于平台的方式来访问标准串行端口,而无需外部库、本机代码或任何其他工具。它旨在替代 RxTx 和(已弃用的)Java Communications API,具有更…...

江协科技STM32学习笔记(第10章 SPI通信)
第10章 SPI通信 10.1 SPI通信协议 10.1.1 SPI通信 SPI(Serial Peripheral Interface)是由Motorola公司开发的一种通用数据总线; 串行外设接口; I2C无论是软件还是软件电路,设计的都还是比较复杂的,硬件…...

力扣热题100_回溯_22_括号生成
文章目录 题目链接解题思路解题代码 题目链接 22. 括号生成 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:[“((()))”,“(()())”,“(())()…...

【k8s】ubuntu24.04 containerd 手动从1.7.15 换为1.7.20
24.04的这个应该是apt 安装的1.7.20-1 root@k8s-master-pfsrv:~# sudo apt update && sudo apt install containerd.io -y 命中:1 http://mirrors.aliyun.com/docker-ce/linux/ubuntu noble InRelease 命中:2 https://dl.google.com/linux/chrome/deb stable InRelease…...

Java二十三种设计模式-备忘录模式(19/23)
本文深入探讨了备忘录模式,从定义、组成、实现到使用场景、优缺点、与其他模式的比较,以及最佳实践和替代方案,全面解析了如何在软件开发中有效地保存和恢复对象状态,以支持复杂的撤销操作和历史状态管理。 备忘录模式:…...

js一些杂乱理解
js 的值类型和引用类型 引用类型:object,array,function值类型:诸如number,stringboolean,null,Undefined,Symbol js使用变量访问对象属性示例 var myDog "Hunter"; var dogs { Fido: "Mutt", Hunter: "Doberman", Snoopie: "Beagle&q…...

【最新v2.7.5 版本安装包】保姆级一步到位,OpenClaw 零基础无需命令一键部署即能用
🚀 OpenClaw 一键安装包|一键部署甩掉复杂环境配置 【点击下方链接下载最新安装包】 https://xiake.yun/api/download/package/16?promoCodeIVBE1F235167 📌 适配信息 适配系统:Windows10/11 64 位 当前版本:…...

Beyond Compare 5密钥生成器终极指南:3种简单方法获取永久授权
Beyond Compare 5密钥生成器终极指南:3种简单方法获取永久授权 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期到期而烦恼吗?想要免费…...

AIGC 检测算法 1.0 到 4.0 升级了什么?嘎嘎降 AI 实测 80% AI 率降到 6% 答辩稳过
AIGC 检测算法 1.0 到 4.0 升级了什么?嘎嘎降 AI 实测 80% AI 率降到 6% 答辩稳过 很多同学不理解——为什么 2024 年用换同义词就能降下 AI 率、2025 年开始这招就半失效了、2026 年完全没用了?真相是——AIGC 检测算法从 1.0 升级到 4.0 经历了 4 次大…...

开发同城短途散步治愈路线生成程序,根据定位生成小众风景散步路线,适配日常解压。
基于创新思维与创业实验方法的「同城短途散步治愈路线生成程序,保持中立、去营销化、无引流。 一、实际应用场景描述 城市上班族常见状态: - 工作日长期处于高压、久坐状态 - 周末不想远行,但市内缺乏“新鲜感” - 热门公园人多、吵闹&…...

别再浪费主板上的PCIE插槽了!手把手教你用VL805芯片打造高速USB3.0扩展坞
释放主板潜能:基于VL805芯片的USB3.0扩展方案实战指南 当你的工作台摆满外设却苦于主板接口不足时,那些闲置的PCIE插槽正等待被唤醒。本文将从芯片选型到性能调优,完整呈现如何将一块VL805-QFN68芯片转化为高性能USB3.0扩展方案。 1. 硬件选型…...

HiC-Pro跑完数据后,你的结果文件都看懂了吗?从out文件夹到可视化图谱的完整解读指南
HiC-Pro结果文件全解析:从原始数据到发表级图谱的实战指南 当HiC-Pro顺利完成运行后,面对out文件夹中密密麻麻的文件,很多研究者会陷入"数据沼泽"——明明流程跑通了,却不知道如何从这些中间文件中提取有价值的信息。本…...

Apollo2 BLE自定义服务开发指南:GATT数据库配置与回调实现
1. 项目概述与核心价值最近在折腾一个基于Apollo2 Blue的低功耗蓝牙项目,需要自定义一个服务(Service)来实现特定的数据交互功能。如果你也在用Ambiq Micro的Apollo2或Apollo3 Blue系列芯片做BLE开发,大概率会遇到类似的需求&…...

2026学术发文避坑攻略:拒绝排版内耗,垂直学术编辑器实测推荐
进入2026年,国内核心期刊的稿件接收标准持续提高。不少科研工作者都会遇到这样的困境:自身的实验数据严谨可信、研究方向具备创新价值,但稿件在编辑初审环节就被退回。深究背后原因,并非研究的学术价值不足,更多是因为…...

2026年光电传感器在不同检测距离中的选型方法与检测距离参数
在自动化产线、物流分拣、包装机械、电子制造等领域,光电传感器的检测距离是选型时最先映入眼帘的参数。然而,很多工程师在实际应用中会发现:标称检测距离为10米的传感器,装上后检测5米的黑色物体就不稳定了;标称0.5米…...

为你的Hermes Agent项目配置Taotoken作为自定义模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent项目配置Taotoken作为自定义模型提供商 应用场景类,假设你正在使用Hermes Agent框架并希望接入更多…...