python数组和队列
一、数组
如果一个列表只包含数值,那么使用array.array会更加高效,数组不仅支持所有可变序列操作(.pop、.insert、.extent等),而且还支持快速加载项和保存项的方法(.fromfile、.tofile等)
创建array对象时要提供类型代码,它是一个字母,用来确定底层使用什么C类型存储数组中各项,并且指定类型后,不允许向数组中添加与指定类型不同的值。类型码如下所示:
| Typecode | C Type | python Type | size in bytes |
| 'b' | signed char | int | 1 |
| 'B' | unsigned char | int | 1 |
| 'h' | signed short | int | 2 |
| 'H' | unsigned short | int | 2 |
| 'i' | signed int | int | 2 |
| 'I' | unsigned int | int | 2 |
| 'l' (lower L) | signed long | int | 4 |
| 'L' | unsigned long | int | 4 |
| 'q' | signed long long | int | 8 |
| 'Q' | unsigned long long | int | 8 |
| 'f' | float(单精度浮点数) | float | 4 |
| 'd' | double(双精度浮点数) | float | 8 |
示例:创建、保存、加载一个大型浮点数数组
from array import array
from random import random# 创建一个双精度浮点数数组
floats = array('d', [random() for i in range(10**7)])
print(floats[-1]) # output: 0.6150799221528432
# 将数组写入文件
with open('floats.bin', 'wb') as fp:floats.tofile(fp)floats2 = array('d')
# 从二进制文件中读取1000万个数并赋值给float2
with open('floats.bin', 'rb') as fp:floats2.fromfile(fp, 10**7)
print(floats2[-1]) # output: 0.6150799221528432
print(floats == floats2) # output: True处理大型数值时使用数组的优势:
1.效率高:在使用array.tofile和array.fromfile时,发现二者的运行速度非常快,读取时无须使用内置函数float一行一行解析,比从文本文件中读取快;保存文件也比一行一行写入文本文件快很多。
2.占用内存少:保存1000万个双精度浮点数的二进制文件占80 000 000个字节(一个双精度浮点数占8字节);保存相同数据量文本文件占181 515 739字节。
补充:array类型没有列表那种就地排序算法sort,如果需要对数组进行排序,需要使用内置函数sorted重新构建数组
from array import arraynum = array('i', sorted([12, 432, 5, 6]))
print(num) # output: array('i', [5, 6, 12, 432])二、memoryview
内置的memoryview类是一种共享内存的序列类型,可以在不复制字节的情况下处理数组的切片,对处理大型数据集来说是非常重要的。
memoryview允许python代码访问支持缓冲协议的对象的内部数据,而无需复制(内存视图直接引用目标内存)。支持缓冲协议的对象:在python中有某些对象可以包装对底层内存阵列或缓冲区的访问,包括内置对象bytes和bytearray以及一些如array.array的扩展类型。
示例:展示如何将同一个6字节数组处理为不同的视图
from array import arrayoctets = array('B', range(6))
m1 = memoryview(octets)
# .tolist()表示将缓存区内的数据以一个列表的形式返回
print(m1.tolist()) # output: [0, 1, 2, 3, 4, 5]
# 根据前一个memoryview对象构建一个新的memoryvie对象,并转换为2行3列
m2 = m1.cast('B', [2, 3])
print(m2.tolist()) # output: [[0, 1, 2], [3, 4, 5]]
# 转换为3行2列
m3 = m1.cast('B', [3, 2])
print(m3.tolist()) # output: [[0, 1], [2, 3], [4, 5]]
m2[1, 1] = 22
m3[1, 1] = 33
# 显示原数组,证明octets、m1、m2、m3之间的内存是共享的
print(octets) # output: array('B', [0, 1, 2, 33, 22, 5])三、NumPy
如果想对数组做一些高级数值处理应该使用NumPy库。NumPy实现了多维同构数组和矩阵类型,处理存放数值之外,还可以存放用户定义的记录,而且提供了高效的元素层面操作。
NumPy的数组类被调用N维数组对象ndarray,它是一系列同类型数据的集合,这与python标准库类array中的array不同,array.array只处理一维数组并提供较少的功能。
ndarray对象的重要属性:
ndarray.ndim:数组的轴(维度)的个数;
ndarray.shape:返回一个整数的元组,表示每个维度中数组的大小,shape元组的长度就是维度可数ndim;
ndarray.size:数组元素的总数,等于 shape 各个元素的乘积;
ndarray.dtype:一个描述数组中元素类型的对象;
ndarray.itemsize:数组中每个元素的字节大小。
示例:numpy.ndarray中行和列的基本操作
import numpy as np# arange([start, ]stop[, step]用于生成数组ndarray,值在半开区间[start,stop]内
a = np.arange(12)
print(a) # output: [ 0 1 2 3 4 5 6 7 8 9 10 11]
print(type(a)) # output: <class 'numpy.ndarray'>
print(a.size) # output: 12
print(a.shape) # output: (12,)
print(a.dtype) # output: int64
print(a.itemsize) # output: 8
# 改变数组的维度
a.shape = 3, 4
print(a)
# output:
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(a.ndim) # output: 2
print(a[:, 1]) # output: [1 5 9]
print(a[2, 1]) # output: 9
# 转置数组
print(a.transpose())
# output:
# [[ 0 4 8]
# [ 1 5 9]
# [ 2 6 10]
# [ 3 7 11]]NumPy还支持一些高级操作,如加载、保存和操作numpy.ndarray对象的所有元素
numpy.savetxt():以简单的文本文件格式(txt文件或csv文件)存储数据;
numpy.loadtxt():基本功能是从文本文件中读取数据,并将其转换为NumPy数组,主要处理如CSV文件或空格分隔的文件,它会自动处理数据的分隔符、数据类型和行结束符,使读取文本数据变得简单;
numpy.save():将数组保存到以.npy为扩展名的文件中,文件中的数据是乱码的,因为是Numpy专用的二进制格式化后的数据;
numpy.savez():将多个数组保存到以.npz为扩展名的文件中;
numpy.load():读取以.npy文件为扩展名的数据。
四、双端队列
借助.append、.pop方法,列表也可以当做栈或队列使用,但是在列表头部插入或删除项有一定开销,因为整个列表必须在内存中移动。collections.deque类实现一种线程安全的双端队列,旨在快速在两端插入和删除项(近似O(1)的性能),但从deque对象中部删除项的速度并不快。
deque对象可以固定长度,在对象被填满后,从一端添加新项,将从另一端丢弃另一项,这是实现保留“最后几项”或类似操作的唯一选择。
示例:展示deque对象可执行的一些典型操作
from collections import deque# maxlen为deque的限制长度
dq = deque(range(10), maxlen=10)
print(dq) # output: deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
# 轮转:num>0,从右端取num项放到左端;num<0,从左端取num项放到右端
dq.rotate(3)
print(dq) # output: deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
dq.rotate(-4)
print(dq) # output: deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
# 左端添加元素-1,此时向已满,左端端添加几项,右端就要舍弃几项
dq.appendleft(-1)
print(dq) # output: deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
# extend(iter)依次将iter中的元素追加到deque右端
dq.extend([11, 22, 33])
print(dq) # output: deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
# extendleft(iter)依次将iter中的元素追加到deque左端
dq.extendleft([10, 20, 30, 40])
print(dq) # output: deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)list和deque之间的方法:
deque实现了多数list方法,另外增加了专用方法,如:popleft和rotate。
deque中的append和popleft是原子操作(执行时不会被打断,执行前后系统状态保持一致),因此可以放心的在多线程应用中把deque作为先进先出队列使用,无须加锁。
五、其他队列
除deque外,python标准库中的其他包还实现了以下队列:
1.queue
实现了面向多生产线程、多消费线程的队列。提供了几个同步队列类,可用于构建多线程应用程序:
simpleQueue:无界的先进先出队列构造函数,缺少任务跟踪等高级功能;
Queue:有界的先进先出队列;
LifoQueue:有界的后进先出队列;
PriorityQueue:有界的先级队列,按照级别顺序取出元素,级别低的最先取出。
注:queue提供的有界队列与deque的有界不同,它们不像deque那样为了腾出空间而把项丢弃,而是在队列填满后阻塞插入新项,等待其他线程从队列中取出一项。
2.multiprocessing
实现了面向多生产进程、多消费进程的队列。该模块单独实现了无界的simpleQueue和有界的Queue。
与queue.Queue的区别:
queue.Queue是进程内用的队列,是多线程的
multiprocessing.Queue是跨进程通信队列,是多进程的
3.asyncio
实现了面向多生产协程、多消费协程的队列,提供了Queue、PriorityQueue、LifoQueue和JoinableQueue,API源自queue和multiprocessing模块中的类,但是为管理异步编程任务做了修改。
4.heapq
与前三个模块相比,heapq并没有实现任何队列类,但是提供了一系列函数可把可变序列当作堆队列(小顶堆)或优先级队列使用。
heapq相关函数:
heappush(heap,num):先创建一个空堆,然后将数据一个一个添加到堆中,每添加一个数据后,heap都满足小顶堆的特性;
heapify(array):直接将数据列表调整成一个小顶堆;
heappop(heap):将堆顶的数据出堆,并将堆中剩余的数据构造成新的小顶堆;
nlargest(num,heap):从堆中取出num个元素,从最大的数据开始取,返回一个列表;
nsmallest(num,heap):从堆中取出num个元素,从最小的数据开始取,返回一个列表。
相关文章:

python数组和队列
一、数组 如果一个列表只包含数值,那么使用array.array会更加高效,数组不仅支持所有可变序列操作(.pop、.insert、.extent等),而且还支持快速加载项和保存项的方法(.fromfile、.tofile等) 创建…...
Vision Transformer(ViT)一种将Transformer架构应用于计算机视觉领域的模型
Vision Transformer(ViT)是一种将Transformer架构应用于计算机视觉领域的模型,它通过自注意力机制处理图像数据,与传统的卷积神经网络(CNN)相比,ViT能够更好地捕捉全局依赖关系。以下是对ViT的详…...

得到任务式 大模型应用开发学习方案
根据您提供的文档内容以及您制定的大模型应用开发学习方案,我们可以进一步细化任务式学习的计划方案。以下是具体的任务式学习方案: 任务设计 初级任务 大模型概述:阅读相关资料,总结大模型的概念、发展历程和应用领域。深度学…...

使用el-menu跳转时偶尔会出现路由已经变了,但是页面却显示空白的情况
刚开始我以为是我数据加载的问题,后来又看有人说是template里不能包多个div,但我去看我出错的组件,并没有出现两个div。 后来我就把每个都给改了,即使是elemen-ui的标签也全部改在一个div里,就发现没问题了。 我改的…...
)
C语言家教记录(七)
C语言家教记录(七) 导语字符串字面量变量读写字符串操作函数惯用法数组 结构联合枚举总结与复习 导语 本次授课的内容如下:字符串,结构体、联合体、枚举 辅助教材为 《C语言程序设计现代方法(第2版)》 字…...

【数据结构】——十大排序详解分析及对比
【数据结构】——十大排序详解分析及对比 文章目录 【数据结构】——十大排序详解分析及对比前言1. 排序的概念及其运用1.1 排序的概念1.2 排序的应用 2. 插入排序2.1 直接插入排序2.2 希尔排序 3. 选择排序3.1 选择排序3.2 堆排序 4 交换排序4.1 冒泡排序4.2 快速排序4.2.1 霍…...
散点图适用于什么数据 thinkcell散点图设置不同颜色
在数据可视化的众多工具和技巧中,散点图是一种极为有效的方式,能够揭示变量之间的关系,尤其是在探索数据集的相关性、分布趋势、集群现象时。而在众多助力于制作高质量散点图的工具中,think-cell插件以其高效的操作和丰富的功能&a…...
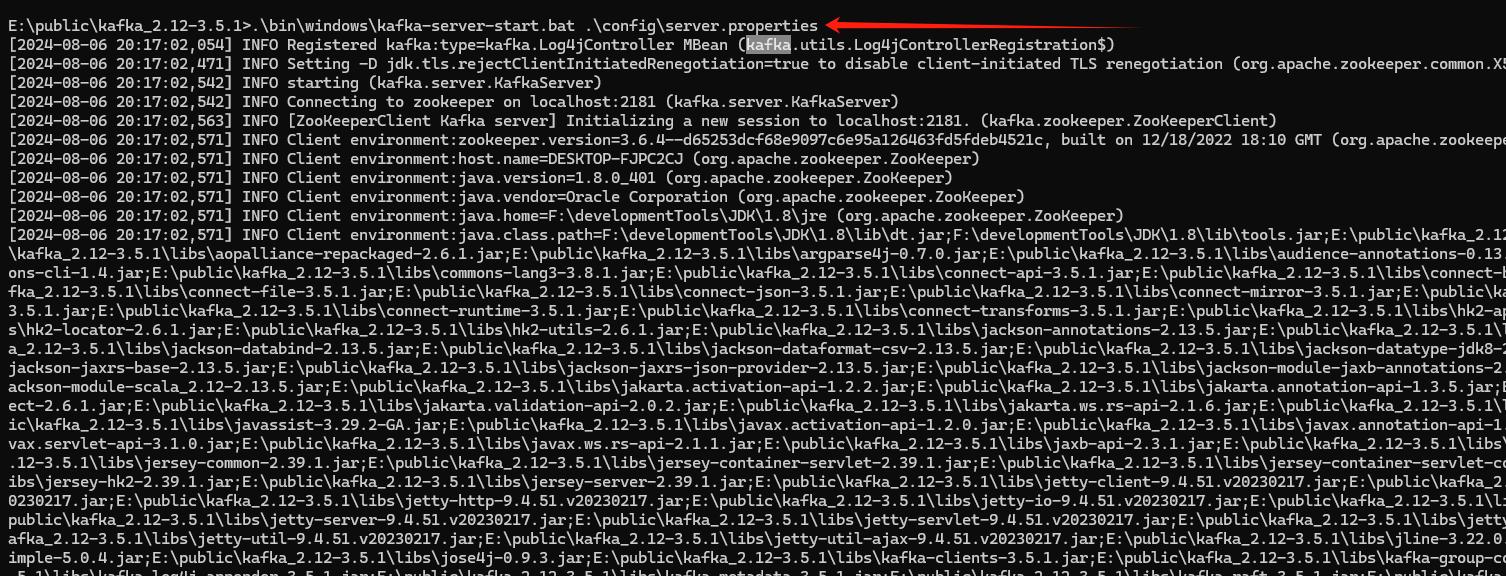
1. windows搭建Kafka教程
目录 1. 部署zookeeper 1.1 下载地址 1.3 修改zoo配置 1.4 启动zookeepe服务 02 部署kafka 2.1 下载组件包 2.2 解压安装包 2.3 修改配置 2.4 启动kafka服务端 1. 部署zookeeper 1.1 下载地址 下载地址: kafka/zookeeper 下载地址 (qq.com) 1.2 解压 (…...

XSS复现
目录 XSS简单介绍 一、反射型 1、漏洞逻辑: 为什么有些标签可以触发,有些标签不能触发 可以触发的标签 不能触发的标签 为什么某些标签能触发而某些不能 二、DOM型 1、Ma Spaghet! 要求: 分析: 结果: 2、J…...

怎么利用XML发送视频彩信
传统的短信推广主要以文字为主,用户接收到的信息往往显得单调乏味。而视频彩信则不同,它结合了视频和音频的优势,通过生动的画面和悦耳的音乐,给用户带来强烈的视听冲击,从而极大地提高了用户的吸引力。 XML成功返回示…...

5G+工业互联网产教融合创新实训室解决方案
一、建设背景 随着第五代移动通信技术(5G)的快速普及和工业互联网的迅猛发展,全球制造业正面临着前所未有的深刻变革。5G技术凭借其超高的传输速率、极低的延迟以及大规模的连接能力,为工业自动化、智能制造等领域带来了革命性的…...

象棋布局笔记
文章目录 布局中炮(当头炮)当头炮的缺点如何应对平车压马平炮对车的理解中炮对屏风马急进中兵 中炮盘头马盘头马两翼突破 盖马三锤 反宫马克制反宫马 顺手炮 士角炮56炮破解56炮 小当头 屏风马7卒分支3卒分支屏风马红车二进六败招(黑未挺7卒前直接进车)马八进九变车三退一变马二…...

百度AI智能云依赖库OpenSSL库和Curl库及jsoncpp库安装
开发百度AI项目时,需要用到https协议,因此需要安装OpenSSl和curl库。 若只安装curl库,只支持http协议,不支持https协议。此外,还需要jsoncpp库,用以组包及解析与百度AI通信的json格式协议。 1.Ubuntu上安装…...

智慧空调离线语音控制方案:NRK3301芯片的深度解析与应用
随着AI技术的大爆发和智能家居的风潮,语音交互已成为智能家居产品的一项必备技能,在家电、音箱、穿戴设备乃至墙壁开关等贴近生活的产品中应用越来越广泛,智能语音识别是当前最热门的方案之一。 九芯智能顺应家居行业智能语音交互市场需求&a…...

基础第3关:LangGPT结构化提示词编写实践
提示词: # Role: 伟大的数学家 ## Profile - author: LangGPT - version: 1.0 - language: 中文 - description: 一个伟大的数学家,能够解决任何的数学难题 ## Goals: 根据关键词进行描述,避免与已有描述重复。 ## Background: 你正在被…...

Nginx系列-负载均衡
文章目录 Nginx系列-负载均衡1. 负载均衡基础1.1 负载均衡定义1.2 Nginx负载均衡原理 2. 负载均衡策略2.1 轮询(Round Robin)2.2 加权轮询(Weighted Round Robin)2.3 IP哈希(IP Hash)2.4 最少连接ÿ…...
中职物联网实训室
一、中职物联网实训室建设背景 在当今科技日新月异的浪潮中,物联网技术以其迅猛的发展势头,成为了撬动数字化转型的关键杠杆,深刻地重塑着经济社会的面貌。面对这一变革,社会对精通物联网技术的应用型人才需求激增。鉴于此&#x…...

Image-coloring的部署,在Ubuntu22.04系统下——点动科技
一、ubuntu22.04基本环境配置 1.1 更换清华Ubuntu镜像源 删除原来的文件 rm /etc/apt/sources.list开始编辑新文件 vim /etc/apt/sources.list先按i键,粘贴以下内容 # 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 deb https:…...

Springboot 整合 Swagger3(springdoc-openapi)
使用springdoc-openapi这个库来生成swagger的api文档 官方Github仓库: https://github.com/springdoc/springdoc-openapi 官网地址:https://springdoc.org 目录题 1. 引入依赖2. 拦截器设置3. 访问接口页面3.1 添加配置项,使得访问路径变短…...

netty4报错:io.netty.util.IllegalReferenceCountException: refCnt: 0, decrement: 1
背景:netty执行链中有一串自定义的handler,目前我想要在中间再加上一个pingPonghandler来进行控制帧的处理,从而避免ng的读写超时(客户要求,与他们建立的通道一直连接,不进行断连,从而需要考虑n…...

【Perplexity医疗搜索实战指南】:3大临床决策加速器与5个被90%医生忽略的精准检索技巧
更多请点击: https://codechina.net 第一章:Perplexity医疗搜索的核心价值与临床适配性 Perplexity医疗搜索并非通用搜索引擎的简单垂直化迁移,而是专为临床决策闭环设计的认知增强工具。其核心价值在于将海量异构医学文献、指南更新、药品说…...

词达人自动化助手终极指南:10倍效率解放你的英语学习时间
词达人自动化助手终极指南:10倍效率解放你的英语学习时间 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 核心关键词:词达人自动化助手、P…...
和MSB8020错误的根治方法)
别再只改项目属性了!彻底搞懂Visual Studio平台工具集(Platform Toolset)和MSB8020错误的根治方法
深入解析Visual Studio平台工具集:从MSB8020错误到构建系统精要 当你在Visual Studio中打开一个历史项目时,是否曾被突如其来的MSB8020错误打断工作流程?这个看似简单的"找不到生成工具"提示背后,隐藏着Visual Studio构…...
)
为什么你的Perplexity图标总返回404?深度逆向其图标CDN路由算法(附Python自动化探测脚本)
更多请点击: https://intelliparadigm.com 第一章:Perplexity图标资源搜索 Perplexity AI 官方未提供公开的图标资源包(如 SVG、Favicon 或 App Icon 套件),但开发者可通过合法合规方式获取其品牌视觉资产用于技术文档…...

ARM Cortex-M微控制器与瑞萨RA系列开发实战指南
1. 项目概述:从“ARM”到“瑞萨RA”的认知之旅在嵌入式开发的江湖里,如果你还在纠结于8位、16位单片机的选型,或者对“ARM Cortex-M”这个名词感到既熟悉又陌生,那么这篇文章就是为你准备的。我接触过不少从传统8051、AVR转型过来…...

用AI Agent + 亚马逊实时数据API打破大卖家数据垄断:架构设计与完整实现
Tags: Amazon API AI Agent LangChain Python 电商数据 实时数据 难度: 中级 | 阅读时长: 15分钟背景与问题 亚马逊大卖家(年GMV 1000万)的核心竞争优势之一是实时数据能力:每15-30分钟采样竞品BSR、价格、库存&#x…...

从零开始在Taotoken模型广场选择并测试最适合的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始在Taotoken模型广场选择并测试最适合的模型 当你开始使用大模型时,面对众多厂商和不同能力的模型,…...

别再傻傻分不清了!Lua中load和loadstring到底怎么用?一个例子讲透
深入解析Lua中的动态代码加载:load与loadstring的实战指南 在Lua开发中,动态代码加载是一个强大但容易引发困惑的功能。许多开发者在不同环境下使用load和loadstring时,经常会遇到各种报错信息,比如"bad argument #1 to load…...
)
从Demo到实战:手把手教你用OpenMMLab的MMDetection训练自己的第一个目标检测模型(附数据集制作)
从零构建目标检测模型:OpenMMLab实战指南与数据集制作全流程 当你第一次成功运行OpenMMLab的Demo时,那种成就感可能很快会被新的困惑取代——如何让这套强大的工具识别你自己的数据?本文将带你跨越从"跑通示例"到"训练自定义模…...

为OpenClaw配置Taotoken作为自定义模型供应商的详细指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken作为自定义模型供应商的详细指南 OpenClaw是一个流行的开源Agent框架,它允许开发者灵活地配置和…...