faiss向量数据库测试《三体》全集,这家国产AI加速卡,把性能提了7倍!
在人工智能和机器学习技术的飞速发展中,向量数据库在处理高维数据方面扮演着日益重要的角色。近年来,随着大型模型的流行,向量数据库技术也得到了进一步的发展和完善。
向量数据库为大型模型提供了一个高效的数据管理和检索平台,使得这些模型能够更加高效地处理非结构化数据,并在各种应用场景中发挥其潜力,执行复杂的查询和分析任务。
Faiss(Facebook AI Similarity Search)是一个用于高效相似性搜索和密集向量聚类的库,它广泛应用于图像检索、推荐系统和自然语言处理等领域。然而,随着数据规模的不断扩大和维度的增加,如何在保证搜索质量的同时提升搜索速度成为了一个挑战。海光DCU(Data Center Unit)作为一种高性能的计算加速解决方案,能够有效提升Faiss向量数据库的搜索性能。
Faiss向量数据库简介
Faiss是由Facebook AI Research团队开发的一个开源库,专门用于高效地进行大规模向量的相似性搜索和聚类。它支持对十亿级别的向量进行搜索,是目前较为成熟的近似近邻搜索库之一。Faiss用C++编写,并提供了与Numpy紧密结合的Python接口,不仅支持CPU计算,对一些核心算法还支持GPU计算。
海光DCU简介
海光DCU(Data Center Unit)是一款高效通用的GPGPU加速卡,专为人工智能和科学计算任务设计。它在兼容性、软件生态和市场应用方面展现出卓越的价值。海光DCU全面兼容“类 CUDA”环境。这种强大的兼容性为用户提供了在AI和大数据处理领域的强大计算服务能力,其在国产加速卡领域中的生态兼容性处于领先地位。
DCU环境部署
本次测试使用了一台装备有两张海光Z100L加速卡的服务器X7840H0,服务器操作系统为Ubuntu 22.04.1 LTS。
准备开发测试环境,相关的程序和文档可以通过光和开发者社区获取,地址是https://developer.hpccube.com。

在服务器系统上部署开发测试环境,用户可以通过点击页面上的资源工具访问驱动、DTK、DAS、镜像等资源的下载界面。

《开发环境安装部署手册》可以通过点击DTK Toolkit下载地址,然后选择最新的latest,然后选择Document目录获取。除了开发环境安装部署手册外,还有开发环境使用手册、兼容性手册等常用的说明文档。

《开发环境安装部署手册》中包含了多个常用系统下的基础环境部署,可以根据使用的系统选择对应的环境部署流程:

根据测试机服务器的操作系统版本,本次测试选择Ubuntu20.04.1操作系统基础环境部署。

按照手册中要求的首先安装驱动以及DTK的依赖包,然后安装驱动程序和DTK,设备的DCU开发测试环境即可部署完成。环境部署完成后输入hy-smi指令即可查询DCU的使用信息:

除了使用物理机的系统环境开发测试外,还可以使用官方提供的基础环境镜像,镜像下载地址:https://sourcefind.cn/#/main-page。

使用官方提供的镜像可以节省大量基础环境的部署工作。本次测试就使用到了名称为1.13.1-centos7.6-dtk-23.04.1-py38-latest的镜像,镜像内已部署好了pytorch等相关的第三方包。然后安装光和开发者社区中提供的faiss安装包以及测试代码所需的pandas等三方包就可以进入下一步准备faiss的测试程序。
搜索性能测试
为了测试faiss的搜索效率,本次测试以文本相似度搜索为例,分别在CPU和GPU场景下进行测试。测试流程包括将批量文本数据导入faiss向量数据库,然后搜索一段文本中不存在的数据,并取多次测试的平均值进行对比。
将文本数据转换为向量数据需要用到Embedding嵌入模型,本次测试中选择了效果出色的shibing624/text2vec-base-chinese。

文本内容本次测试选择了《三体》全集,文本存储在三体.txt文件中。由于Embedding嵌入模型的输入长度限制,首先需要将文本内容进行分段再传入嵌入模型。然后将嵌入模型转换完成的向量数据使用numpy存储在本地data.npy文件中,用来方便后续测试。代码如下:
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import pandas as pd
df=pd.read_csv("三体.txt",encoding='utf-8',sep="#",header=None, names=["sentence"])
print(df)
from sentence_transformers import SentenceTransformer
model=SentenceTransformer('shibing624/text2vec-base-chinese')
sentences =df['sentence'].tolist()
sentence_embeddings=model.encode(sentences)
print("数据向最维度:")
print(sentence_embeddings.shape)
save_file = "data.npy"
import numpy as np
np.save(save_file,sentence_embeddings)
import os
file_size = os.path.getsize(save_file)
print("保存数据文件:%7.3f MB"%(file_size/1024/1024))
运行代码之后打印信息如下:

向量数据准备好之后使用faiss分别加载三体全集和data.npy向量数据,然后使用faiss中提供的IndexFlatL2索引方式加载这些向量数据,然后在搜索“大史喜欢抽烟”这几个原文中没有的文本。faiss_test.py测试代码如下:
import faiss
import numpy as np
import pandas as pd
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
print("load 三体.txt...")
df = pd.read_csv("三体.txt", encoding='utf-8', sep="#", header=None, names=["sentence"])
print("load vector data...")
sentence_embeddings = np.load("data.npy")
dimension = sentence_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(sentence_embeddings)
import time
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('shibing624/text2vec-base-chinese')
topk = 5
words = ["大史喜欢抽烟"]
search = model.encode(words)
print("search: " + str(words))
costs = []
for i in range(10):to = time.time()D, I = index.search(search, topk)ti = time.time()costs.append(ti - to)
print(D)
print(I)
print(df['sentence'].iloc[I[0]])
print("平均耗时 %7.3f ms" % ((sum(costs) / len(costs)) * 1000.0))
使用GPU的方式搜索可以将上面代码中的index使用index_cpu_to_all_gpus的方法将索引数据创建在GPU中,然后构建索引数据。faiss_gpu_test.py代码如下:
import faiss time warnings
import numpy as np
import pandas as pd
warnings.simplefilter(action='ignore', category=FutureWarning)
print("load 三体.txt...")
df = pd.read_csv("三体.txt", encoding='utf-8', sep="#", header=None, names=["sentence"])
print("load vector data...")
sentence_embeddings = np.load("data.npy")
dimension = sentence_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
ngpus = faiss.get_num_gpus()
print("number of GPU:", ngpus)
gpu_index = faiss.index_cpu_to_all_gpus(index)
gpu_index.add(sentence_embeddings)
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('shibing624/text2vec-base-chinese')
topk = 5
words = ["大史喜欢抽烟"]
search = model.encode(words)
print("search: " + str(words))
costs = []
for i in range(10):to = time.time()D, I = gpu_index.search(search, topk)ti = time.time()costs.append(ti - to)
print(D)
print(I)
print(df['sentence'].iloc[I[0]])
print("平均耗时 %7.3f ms" % ((sum(costs) / len(costs)) * 1000.0))
在服务器环境中分别运行faiss_test.py和faiss_gpu_test.py即可获取到faiss的搜索结果:

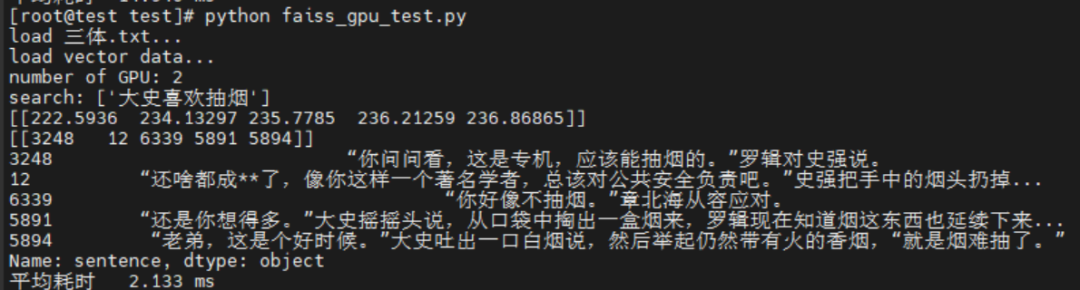
分析汇总
对两份代码的运行结果进行对比可以明显看到海光DCU的加速效果明显,较CPU索引的方式提高了7倍左右的性能。
本次测试使用到的文本数据量较低,随着数据量的增加,DCU的加速效果会更加明显。测试代码中的索引方式使用到了faiss中最基本的IndexFlatL2,它使用 L2 距离(欧氏距离)进行暴力搜索(brute-force search),适用于向量数量较小的情况。由于它在内存中存储所有向量,因此当向量数量较大时,内存开销会很大。除此之外faiss中常用的还有IndexIVFFlat、IndexIVFPQ等索引方式可以显著减少索引的内存资源占用。
相关文章:
faiss向量数据库测试《三体》全集,这家国产AI加速卡,把性能提了7倍!
在人工智能和机器学习技术的飞速发展中,向量数据库在处理高维数据方面扮演着日益重要的角色。近年来,随着大型模型的流行,向量数据库技术也得到了进一步的发展和完善。 向量数据库为大型模型提供了一个高效的数据管理和检索平台,…...
)
负载均衡---相关概念介绍(一)
负载均衡(Load Balance)是集群技术的一种重要应用,旨在将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行,从而提高系统的并发处理能力、增加吞吐量、加强网络处理能力,并提供故障转移以…...

计算机基础知识复习8.14
子线程抛异常主线程能否catch 在不做任何处理的情况下,主线程不能catch 解决方式: 子线程使用try catch来捕获异常 为线程设置未捕获异常处理器UncaughtExceptionHandler 通过future的get方法捕获异常 JVM相关参数 显示指定堆内存-Xms和-Xmx指定最…...

【io深层理解】
io深层理解 1.内核态2.用户态3. select IO多路复用执行原理4. select io多路复用限制和不足 1.内核态 一个进程会涉及多文件的修改,比如说。那么在内核态就会维护一个表,这个表叫文件描述符bitmap,这个表会传递给内核态,当然肯定传…...

【懒人工具】指定新文件,替换全盘旧文件
没辙,就是懒 最近在调整.clang-format,这个format文件要跟着项目走,只换本地默认的还不够。调整好以后一个项目一个项目的换,有时候会漏掉,索性全盘一次性换完。 基于自己操作的流程,写了个脚本࿰…...
:设置节点样式)
React+Vis.js(02):设置节点样式
文章目录 1、修改vis.js的节点和关系颜色2、修改vis.js节点的字体颜色2.1 统一设置节点字体颜色2.2 自定义某个节点的字体颜色3、设置vis.js节点的边框颜色和宽度3.1 设置单个节点3.2 统一设置1、修改vis.js的节点和关系颜色 在vis.js中,可以通过color属性,来给node节点添加…...

3G网络要彻底没了
2月21日,三大运营商公布了最新的用户数据,移动联通电信三家5G套餐用户数合计超过了7.5亿。信通院早前公布的数据显示,一月份,国内市场5G手机出货量2632.4万部,占同期手机出货量的79.7%。 这两项数据,说明我们已经进入到了5G时代,5G的普及速度远超很多人的想象。就在5G逐…...

如何配置ESXI主机的IP地址管理
🏡作者主页:点击! 🐧Linux基础知识(初学):点击! 🐧Linux高级管理防护和群集专栏:点击! 🔐Linux中firewalld防火墙:点击! ⏰️创作…...

软件测试学习笔记丨测试用例设计方法
本文转自测试人社区,原文链接:https://ceshiren.com/t/topic/31921 一,黑盒测试方法论 1,等价类 1.1 定义 等价类划分是一种重要的、常用的黑盒测试方法不需要考虑程序的内部结构,只需要考虑程序的输入规格即可它将…...

MinIO基本用法
在现代云计算和大数据领域,对象存储因其可扩展性、可靠性和低成本成为数据存储的重要选择。MinIO作为一个高性能、分布式的对象存储系统,凭借其开源、简单易用以及与Amazon S3兼容的特性,在业界得到了广泛的应用。本文将带您了解MinIO的基本用…...

MySQL windows版本安装
一、下载MySQL安装包 访问MySQL官网:首先,访问MySQL的官方网站(MySQL),或者更具体地,访问MySQL的下载页面(MySQL :: Download MySQL Community Server)。 选择适合的版本࿱…...

Python实现人脸轮廓提取
目录 一、背景知识1.1 人脸检测和轮廓提取的意义1.2 人脸检测方法概述1.3 轮廓提取方法概述二、常用的人脸轮廓提取方法2.1 基于边缘检测的轮廓提取2.2 基于形态学操作的轮廓提取2.3 基于特征点检测的轮廓提取三、Python实现人脸轮廓提取3.1 安装依赖库3.2 使用Dlib进行人脸检测…...

Prettier+Vscode setting提高前端开发效率
文章目录 前言Prettier第一步:下载依赖(团队合作)或下载插件(独立开发)第二步:添加.prettierrc.json文件**以下是我使用的****配置规则** 第三步:添加.prettierignore文件**以下是我常用的****配…...

YOLOv10实时端到端目标检测
文章目录 前言一、非极值大抑制(NMS)二、NMS算法的具体原理和步骤三、YOLOV10创新点四、YOLOv10使用教程五、官方github地址 前言 距离上次写YOLOv5已经过去了两年,正好最近用YOLOv10重构了项目,总结下YOLOv10。 YOLOv10真正实时端到端目标检测ÿ…...

Java中的Annotation注解
常用注解 override:重写方法deprecated:弃用SuppressWarnings:抑制编译器警告 元注解(注解的注解) Target:描述注解所能修饰的类型Retention:描述注解的生命周期(SOURCE源代码、C…...

小五金加工:细节决定产品质量与性能
在小五金加工领域,细节往往决定着最终产品的质量、性能以及市场竞争力。看似微不足道的细微之处,实际上蕴含着巨大的影响。时利和将介绍小五金加工中细节的重要性。 首先,细节关乎产品的精度。小五金零件通常尺寸较小,但对精度的要…...

VS Code安装配置ssh服务结合内网穿透远程连接本地服务器详细步骤
文章目录 前言1. 安装OpenSSH2.VS Code配置ssh3. 局域网测试连接远程服务器4. 公网远程连接4.1 ubuntu安装cpolar内网穿透4.2 创建隧道映射4.3 测试公网远程连接 5. 配置固定TCP端口地址5.1 保留一个固定TCP端口地址5.2 配置固定TCP端口地址5.3 测试固定公网地址远程 前言 远程…...
世界首位「AI科学家」问世!独立生成10篇学术论文! 横扫「顶会」?
大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪 AI科学家出世 最近一位人工智能AI科学家横空出世。 它是…...

【高阶数据结构】图
图 1. 图的基本概念2. 图的存储结构2.1 邻接矩阵2.2 邻接表2.3 邻接矩阵的实现2.4 邻接表的实现 3. 图的遍历3.1 图的广度优先遍历3.2 图的深度优先遍历 4. 最小生成树4.1 Kruskal算法4.2 Prim算法 5. 最短路径5.1 单源最短路径--Dijkstra算法5.2 单源最短路径--Bellman-Ford算…...

调研-音视频
音视频 基础概念主要内容音频基础概念音频量化过程音频压缩技术视频基础概念视频bug视频编码H264视频像素格式YUVRGB参考文献基础概念 ● 实时音视频应用环节 ○ 采集、编码、前后处理、传输、解码、缓冲、渲染等很多环节。 主要内容 音频 基础概念 三要素:音调(音频)、…...

Matlab 2020b隐藏技能:用Image Labeler制作自定义数据集,轻松喂给你的深度学习模型
Matlab 2020b图像标注实战:从零构建医学影像分割数据集 在医学影像分析领域,数据标注的质量直接决定了深度学习模型的性能上限。许多研究者花费大量时间调试模型结构,却忽略了最基础的数据准备环节。Matlab 2020b内置的Image Labeler工具&am…...

如何彻底摆脱网盘限速:8大主流网盘直链下载助手完整指南
如何彻底摆脱网盘限速:8大主流网盘直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

ESJsonFormat-Xcode泛型支持:Xcode 7及以上版本的优化特性
ESJsonFormat-Xcode泛型支持:Xcode 7及以上版本的优化特性 【免费下载链接】ESJsonFormat-Xcode 将JSON格式化输出为模型的属性 项目地址: https://gitcode.com/gh_mirrors/es/ESJsonFormat-Xcode 如果你是一位iOS开发者,那么你一定遇到过将JSON数…...

STM32 FSMC/FMC接口配置与调试:从时序参数到实战应用
1. 项目概述:为什么FSMC/FMC是STM32开发者绕不开的“硬骨头”?在STM32的众多外设中,FSMC(Flexible Static Memory Controller,灵活静态存储器控制器)及其升级版FMC(Flexible Memory Controller&…...

CNC木质树莓派外壳制作:从设计到加工的全流程实践
1. 项目概述:当数字制造遇上经典木艺 给树莓派找个“家”,这事儿我干过不少。从3D打印的塑料壳到亚克力板拼的“鱼缸”,总觉得差点意思。塑料感太强,亚克力又显得冰冷。直到有一次在工作室里看到一块边角料的硬枫木,纹…...
:准确率、溯源性、逻辑连贯性三维评分,这份清单决定你是否该立刻升级)
NotebookLM问答功能终极评估报告(基于217份真实研究笔记测试):准确率、溯源性、逻辑连贯性三维评分,这份清单决定你是否该立刻升级
更多请点击: https://intelliparadigm.com 第一章:NotebookLM问答功能终极评估报告概览 NotebookLM 是 Google 推出的基于用户上传文档构建个性化知识代理的 AI 工具,其核心问答能力依赖于对私有资料的深度语义理解与上下文精准锚定。本章聚…...

langchain4j笔记-09
RAG 1. easy rag Test void test03() {// 1. 创建模型// 2. 加载文档List<Document> documents ClassPathDocumentLoader.loadDocuments("excel");//List<Document> documents FileSystemDocumentLoader.loadDocuments("/home/langchain4j/docum…...

终极指南:3步重塑你的Windows桌面视觉体验
终极指南:3步重塑你的Windows桌面视觉体验 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想象一下,当你专注工作…...
)
别光看代码!聊聊51单片机做计算器时,那些新手容易踩的坑(键盘消抖、变量溢出、显示刷新)
51单片机计算器开发进阶指南:从功能实现到工程优化的深度解析 第一次在51单片机上实现计算器功能时,那种按下按键能看到数码管显示正确结果的兴奋感至今难忘。但真正投入实际使用后,各种问题接踵而至——按键偶尔失灵、大数运算出错、显示闪烁…...
)
NotebookLM引用格式生成失效真相:Google官方未公开的citation token截断限制(含绕过验证方案)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM引用格式生成失效真相:Google官方未公开的citation token截断限制(含绕过验证方案) NotebookLM 在处理长篇 PDF 或网页源时,常出现引用标记&am…...