Python3网络爬虫开发实战(10)模拟登录(需补充账号池的构建)
文章目录
- 一、基于 Cookie 的模拟登录
- 二、基于 JWT 模拟登入
- 三、账号池
- 四、基于 Cookie 模拟登录爬取实战
- 五、基于JWT 的模拟登录爬取实战
- 六、构建账号池
很多情况下,网站的一些数据需要登录才能查看,如果需要爬取这部分的数据,就需要实现模拟登入的一些机制;模拟登录现在主要分为两种方式,一种是基于 Session 和 Cookie 的模拟登入,一种是基于 JWT(Json Web Token)的模拟登录。
对于第一种模式,打开网页后模拟登录,服务器会返回带有 Set-Cookie 字段的响应头,客户端会生成对应的 Cookie,其中保存着与 SessionID 相关的信息,之后发送给服务器的请求都会携带这个生成的 Cookie。服务器接收到请求后,会根据 Cookie 中保存的 SessionID 找到对应的 Session,同时效验 Cookie 里的相关信息,如果当前 Session 是有效的并且效验成功,服务器就判断当前用户已经登录,返回请求的页面信息,所以这种模式的核心是获取客户端登录后生成的 Cookie;
对于第二种模式,是因为现在有很多的网站采取的开发模式是前后端分离模式,所以使用 JWT 进行登录效验越来越普遍,在请求数据时,服务器会效验请求中携带的 JWT 是否有效,如果有效,就返回正常的数据,所以这种模式其实就是获取 JWT;
一、基于 Cookie 的模拟登录
如果要使用爬虫实现基于 Session 和 Cookie 的模拟登录,最为主要的是要维护好 Cookie 的信息,因为爬虫相当于客户端的浏览器;
- 如果在浏览器中登录了自己的账号,可以直接把网页中的 Cookie 复制给爬虫,就相当于手动在浏览器中登录;
- 如果让爬虫完全自动化操作,可以直接使用爬虫模拟登录过程,这个过程基本上就是一个 POST 请求,用爬虫把用户名,密码等信息提交给服务器,服务器会返回一个 Set-Cookie 字段,我们只需要将该字段保存下来,然后提交给爬虫请求就好;
- 如果 POST 请求难以构造,我们可以使用自动化工具来模拟登录,例如使用 Selenium,Playwright 来发送请求,然后获取 Cookie 进行发送请求;
二、基于 JWT 模拟登入
JWT 的字符串就是用户访问的凭证,所以模拟登录只需要做到以下几步:
- 模拟登录操作,例如拿着用户名和密码信息请求登录接口,获取服务器返回的结果,这个结果中通常包含 JWT 信息,将其保存下来即可;
- 之后发送给服务器的请求均携带 JWT,在 JWT 不过期的情况下,通常能正常访问和执行操作,携带方式多种多样,因网站而异;
- 如果 JWT 过期了,可能需要再次做第一步,重新获取 JWT;
三、账号池
如果爬虫要求爬取的数据量比较大,或者爬取速度比较快,网站又有单账号并发限制或者访问状态检测等反爬虫手段,我们的账号可能就无法访问网站或者面临封号的风险;
这时我们建立一个账号池进行分流,用多个账号随机访问网站或爬取数据,这样能大幅提高爬虫的并发量,降低被封号的风险,例如准备 100 个账号,将这 100 个账号都模拟登录,并保存对应的 Cookie 和 JWT,每次都随机抽取一个来访问,账号多,所以每个账号被选取的概率就小,也就避免了单账号并发量过大的问题,从而降低封号风险;
四、基于 Cookie 模拟登录爬取实战
目标网址:Scrape | Movie
账号:admin
密码:admin
这里由于登入请求构造并没有涉及到加密过程,因此我们可以直接构造 requests 请求来执行请求;仔细分析后可以发现登入请求返回的状态码是 302,同时登入完毕后页面自动发生了跳转,因此在使用 requests 够着 post 请求的时候,需要将 allow_redirects 参数设置为 False;
import requests
import parselheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Cache-Control': 'max-age=0','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded','Origin': 'https://login2.scrape.center','Referer': 'https://login2.scrape.center/login','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-origin','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0','sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}data = {'username': 'admin','password': 'admin',
}response = requests.post('https://login2.scrape.center/login', headers=headers, data=data, allow_redirects=False)# 得到 cookies
cookies = response.cookies.get_dict()# 将获取到的 cookie 放入 requests 的 get 请求中
response = requests.get('https://login2.scrape.center/', cookies=cookies, headers=headers)# 解析网页数据
selector = parsel.Selector(response.text)
names = selector.xpath('//*[@id="index"]/div[1]/div[1]/div/div/div/div[2]/a/h2/text()').getall()# 打印名字
print(names)# ['霸王别姬 - Farewell My Concubine',
# '这个杀手不太冷 - Léon',
# '肖申克的救赎 - The Shawshank Redemption',
# '泰坦尼克号 - Titanic',
# '罗马假日 - Roman Holiday',
# '唐伯虎点秋香 - Flirting Scholar',
# '乱世佳人 - Gone with the Wind',
# '喜剧之王 - The King of Comedy',
# '楚门的世界 - The Truman Show',
# '狮子王 - The Lion King']
在这里我们首先获得了 cookies,然后又手动要将 cookies 放入到后续的请求之中,这里我们可以构建 Session 请求来自动化添加 cookies;如下
import requests
import parselheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Cache-Control': 'max-age=0','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded','Origin': 'https://login2.scrape.center','Referer': 'https://login2.scrape.center/login','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-origin','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0','sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}data = {'username': 'admin','password': 'admin',
}# 构建 session
session = requests.Session()# 发送登入请求
response = session.post('https://login2.scrape.center/login', headers=headers, data=data, allow_redirects=False)# 无需手动配置 cookies,发送页面请求
response = session.get('https://login2.scrape.center/', headers=headers)# 解析网页数据
selector = parsel.Selector(response.text)
names = selector.xpath('//*[@id="index"]/div[1]/div[1]/div/div/div/div[2]/a/h2/text()').getall()# 打印名字
print(names)# ['霸王别姬 - Farewell My Concubine',
# '这个杀手不太冷 - Léon',
# '肖申克的救赎 - The Shawshank Redemption',
# '泰坦尼克号 - Titanic',
# '罗马假日 - Roman Holiday',
# '唐伯虎点秋香 - Flirting Scholar',
# '乱世佳人 - Gone with the Wind',
# '喜剧之王 - The King of Comedy',
# '楚门的世界 - The Truman Show',
# '狮子王 - The Lion King']
这里是对于请求未涉及到加密或者带有验证码的网站,如果涉及到加密但是又不会解密,我们可以使用自动化工具来获取 Cookie;这里以 Playwright 为例子;
import requests
import parsel
from playwright.sync_api import sync_playwrightdef get_cookies():with sync_playwright() as playwright:cookies = {}browser = playwright.chromium.launch(headless=True)context = browser.new_context()page = context.new_page()page.goto("https://login2.scrape.center/login")page.locator('input[name="username"]').fill("admin")page.locator('input[name="password"]').fill("admin")page.locator('input[type="submit"]').click()cookieList = context.cookies()context.close()browser.close()for cookie in cookieList:cookies[cookie['name']] = cookie['value']return cookiesheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Cache-Control': 'max-age=0','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded','Origin': 'https://login2.scrape.center','Referer': 'https://login2.scrape.center/login','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-origin','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0','sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}cookies = get_cookies()
response = requests.get('https://login2.scrape.center/', cookies=cookies, headers=headers)# 解析网页数据
selector = parsel.Selector(response.text)
names = selector.xpath('//*[@id="index"]/div[1]/div[1]/div/div/div/div[2]/a/h2/text()').getall()# 打印名字
print(names)# ['霸王别姬 - Farewell My Concubine',
# '这个杀手不太冷 - Léon',
# '肖申克的救赎 - The Shawshank Redemption',
# '泰坦尼克号 - Titanic',
# '罗马假日 - Roman Holiday',
# '唐伯虎点秋香 - Flirting Scholar',
# '乱世佳人 - Gone with the Wind',
# '喜剧之王 - The King of Comedy',
# '楚门的世界 - The Truman Show',
# '狮子王 - The Lion King']
五、基于JWT 的模拟登录爬取实战
目标网址:Scrape | Movie
账号:admin
密码:admin
import requestsheaders = {"Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Connection": "keep-alive","Content-Type": "application/json;charset=UTF-8","Origin": "https://login3.scrape.center","Sec-Fetch-Dest": "empty","Sec-Fetch-Mode": "cors","Sec-Fetch-Site": "same-origin","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0","sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',"sec-ch-ua-mobile": "?0","sec-ch-ua-platform": '"Windows"',
}json_data = {"username": "admin","password": "admin",
}# 这里使用 json 而不是使用 data 传参是因为 headers 中的 Content-Type 接受的是 application/json 数据
response = requests.post("https://login3.scrape.center/api/login", headers=headers, json=json_data
)# 获取 token 构建 headers 中的 Authorization
token = response.json()["token"]
Authorization = "jwt " + token
headers = {"Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Authorization": Authorization,"Connection": "keep-alive","Sec-Fetch-Dest": "empty","Sec-Fetch-Mode": "cors","Sec-Fetch-Site": "same-origin","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0","sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',"sec-ch-ua-mobile": "?0","sec-ch-ua-platform": '"Windows"',
}params = {"limit": "18","offset": "0",
}# 直接使用 get 请求获取数据
response = requests.get("https://login3.scrape.center/api/book", params=params, headers=headers
)print(response.json())# {
# "count": 9200,
# "results": [
# {
# "id": "34473697",
# "name": "R数据科学实战:工具详解与案例分析",
# "authors": ["刘健", "邬书豪"],
# "cover": None,
# }
# ],
# }
在这里由于使用的是 JWT,响应头中并不会返回一个 Set-Cookies 参数,因此使用 Session 来完成 JWT 是没有效果的,只能单个请求进行构建;
六、构建账号池
相关文章:
Python3网络爬虫开发实战(10)模拟登录(需补充账号池的构建)
文章目录 一、基于 Cookie 的模拟登录二、基于 JWT 模拟登入三、账号池四、基于 Cookie 模拟登录爬取实战五、基于JWT 的模拟登录爬取实战六、构建账号池 很多情况下,网站的一些数据需要登录才能查看,如果需要爬取这部分的数据,就需要实现模拟…...

SQL 调优最佳实践笔记
定义与重要性 SQL 调优:提高SQL性能,减少查询时间和资源消耗。目标:减少查询时间和扫描的数据行数。 基本原则 减少扫描行数:只扫描所需数据。使用合适索引:确保WHERE条件命中最优索引。合适的Join类型:…...
Eclipse的使用配置教程:必要设置、创建工程及可能遇到的问题(很详细,很全面,能解决90%的问题)
Eclipse的使用配置: Ⅰ、Eclipse 的必要配置:1、Eclipse 的安装:其一、将 Eclipse 解压或安装到没有中文且没有空格的路径下。其二、拿到 eclipse.exe 文件,傻瓜式安装即可; 2、设置工作空间(workspace):其一、首次启动…...

遗传算法与深度学习实战(4)——遗传算法详解与实现
遗传算法与深度学习实战(4)——遗传算法详解与实现 0. 前言1. 遗传算法简介1.1 遗传学和减数分裂1.2 类比达尔文进化论 2. 遗传算法的基本流程2.1 创建初始种群2.2 计算适应度2.3 选择、交叉和变异2.4算法终止条件 3. 使用 Python 实现遗传算法3.1 构建种…...

Nginx+Tomcat实现负载均衡、动静分离集群部署
文章目录 一、Nginx实现负载均衡原理1.正向代理和反向代理2.负载均衡模式1. 轮询(Round Robin):2. 最少连接数(Least Connections):3. IP 哈希(IP Hash):4. 加权轮询…...

英语学习8月19日
词根前缀后缀 accomplishment 成就 acid n.酸的,adj.酸的 acidity n.酸性 ace adj.顶尖的 acute adj.敏锐的;急性的;严重的 acuity n.敏锐 obtuse adj.迟钝的;钝角的 acuity n.敏锐,严重 1.前缀ac: 尖&#x…...
关于windows环境使用nginx的一些性能问题
遇到的问题 最近在一个windows环境中部署nginx,遇到了以下问题: 1. nginx启动了九个线程(1master8woekr),但是所有链接都被1个woker接收,其余worker不工作 2. 用户端访问web很慢,登录服务器使…...
“解决Windows电脑无法投影到其他屏幕的问题:尝试更新驱动程序或更换视频卡“
背景: 今天在日常的工作中, 我想将笔记本分屏到另一个显示屏,我这电脑Windows10,当我按下Windows键P键,提示我"你的电脑不能投影到其他屏幕,请尝试从新安装驱动程序或使用"遇到这种问题。 解决方法1: 1.快…...

第10章 无持久存储的文件系统 (2)
目录 10.1 proc文件系统 10.1.2 数据结构 10.1.3 初始化 10.1.4 装载 proc 文件系统 10.1.5 管理 /proc 数据项 10.1.6 读取和写入信息 10.1.7 进程相关信息 10.1.8 系统控制机制 本专栏文章将有70篇左右,欢迎关注,查看后续文章。 10.1 proc文件…...
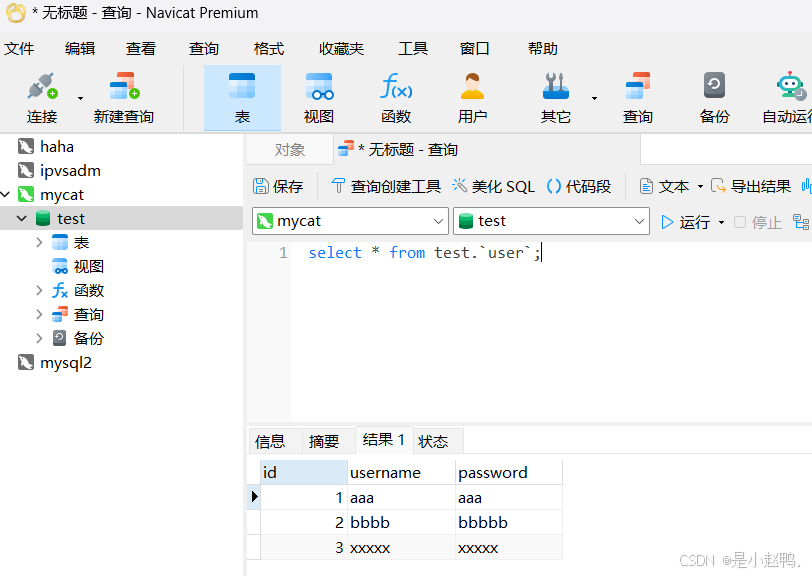
云计算实训29——mysql主从复制同步、mysql5.7版本安装配置、python操作mysql数据库、mycat读写分离实现
一、mysql主从复制及同步 1、mysql主从自动开机同步 2、配置mysql5.7版本 mysql-5.7.44-linux-glibc2.12-x86_64.tar 启动服务、登录 对数据库进行基本操作 3、使用python操纵mysql数据库 4、编辑python脚本自动化操纵mysql数据库 二、mycat读写分离实现 1.上传jdk和mycat安装…...
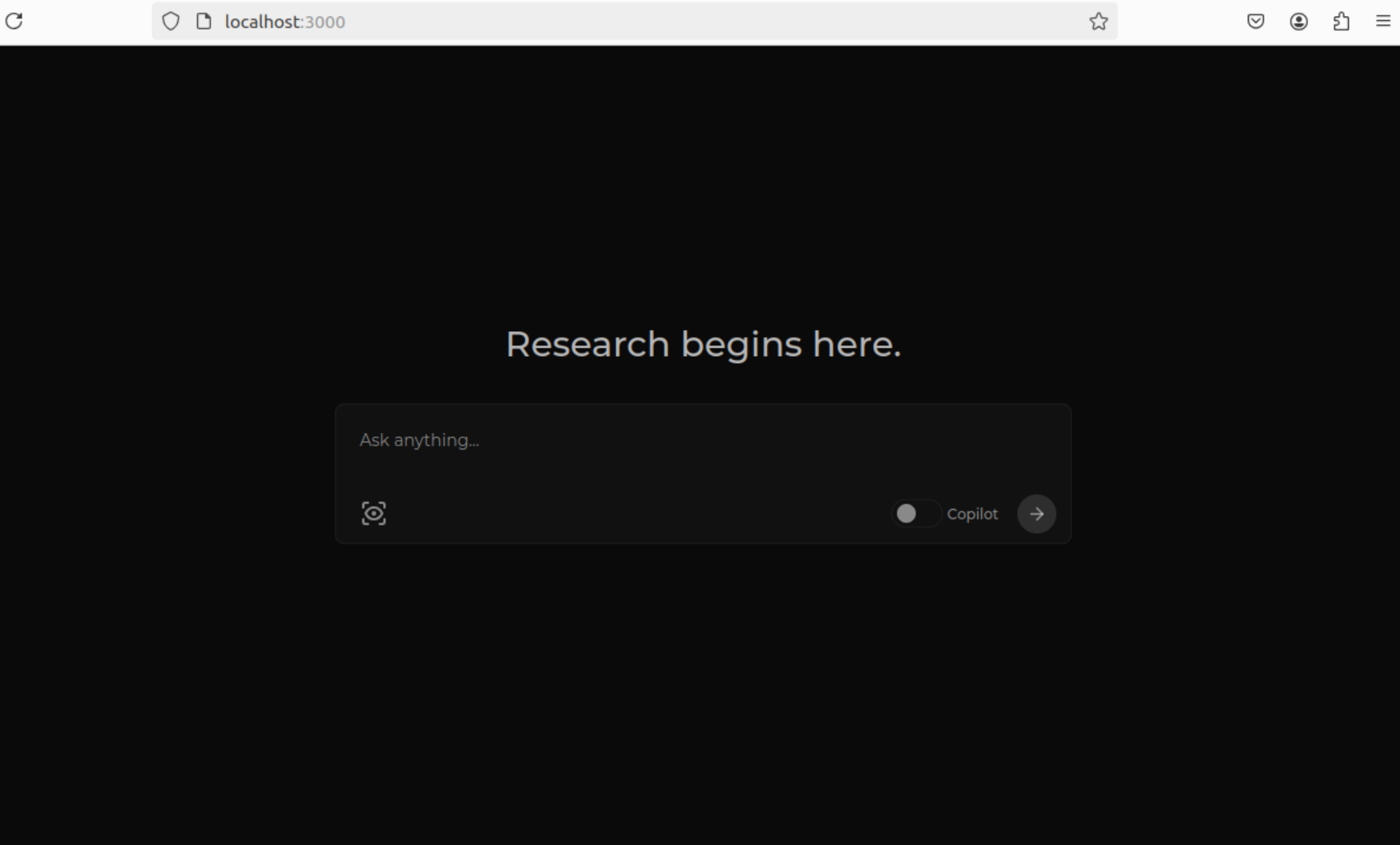
AI搜索引擎Perplexica的本地部署(之二)Perplexica的非docker安装
Perplex 是一个开源的AI 驱动的搜索引擎,可以使用 Grok 和 Open AI 等模型在计算机上本地安装和运行。它为学术研究、写作、YouTube 和 Reddit 提供了一系列搜索功能。用户可以通过选择不同的模型、设置本地嵌入模型和探索各种搜索选项来定制他们的体验。该工具演示…...

Oracle环境下在相同参数和数据源的情况,mybatis-plus查询和sql查询结果不一致
场景: 在系统中某个对象执行修改的时候,查询对象为空,造成修改报错 分析: 在传参中有一个eq的参数需要传null,mybatis-plus在执行eq时可能是拼成" null",但是oracle中查null必须要用is null, null是查不出东西的 解决: 改成用sql查询修改,或者加判断如果这个参…...
springboot静态资源访问问题归纳
以下内容基于springboot 2.3.4.RELEASE 1、默认配置的springboot项目,有四个静态资源文件夹,它们是有优先级的,如下: "classpath:/META-INF/resources/", (优先级最高) "classpath:/reso…...
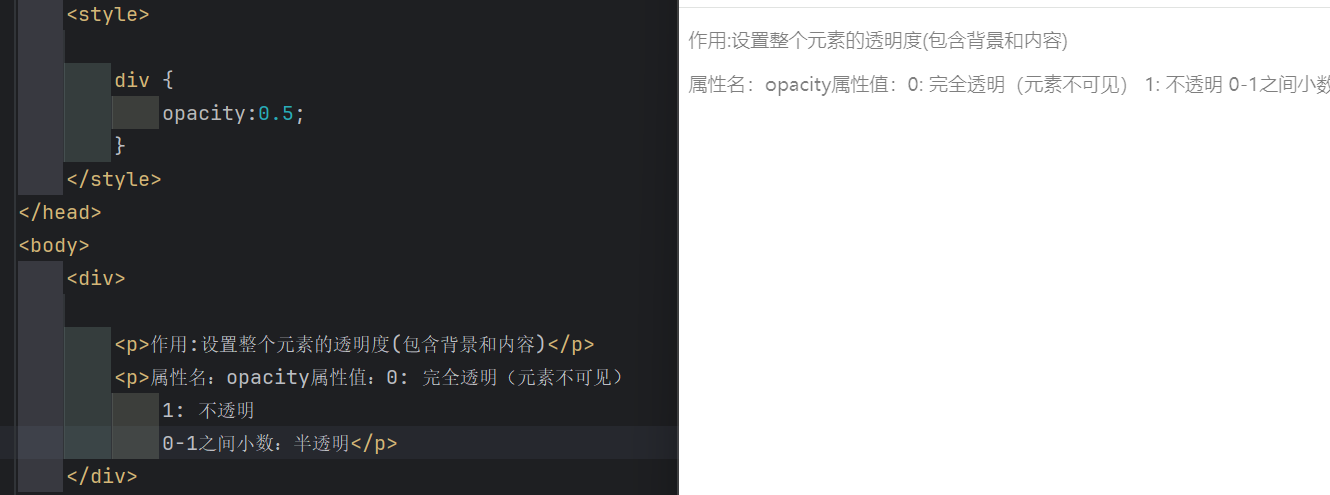
HTML与CSS学习Day01
文章目录 一 、CSS技巧1.1 CSS精灵(CSS Sprites)1.1.1 实现步骤1.1.2 例子 1.2 字体图标1.2.1如何使用字体图标1.2.2 字体图标使用总结 1.3 垂直对齐方式vertical-align1.3.1 值1.3.2 例子 1.4 过渡效果transition1.4.1 CSS过渡效果(transiti…...
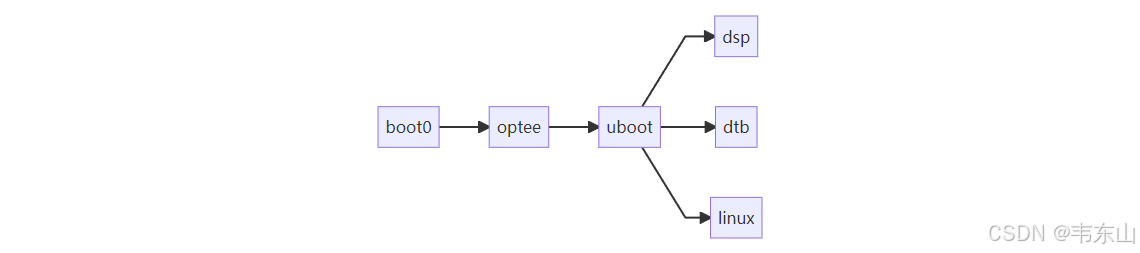
Tina-Linux Bootloaer简述
Tina-Linux Bootloaer简述 目录介绍 ubuntuubuntu1804:~/tina-v2.0-sdk/lichee/brandy-2.0$ tree -L 1 . ├── build.sh ├── opensbi ├── spl //boot0 ├── spl-pub //boot0 ├── tools └── u-boot-2018 /ubootTina-Linux 启动流程简述...

【Python】 Scrapyd:Python Web Scraping 的强大分布式调度工具
我听见有人猜 你是敌人潜伏的内线 和你相知多年 我确信对你的了解 你舍命救我画面 一一在眼前浮现 司空见惯了鲜血 你忘记你本是娇娆的红颜 感觉你我彼此都那么依恋 🎵 许嵩《内线》 在网络爬虫项目中,Scrapy 是 Python 中最流行和…...
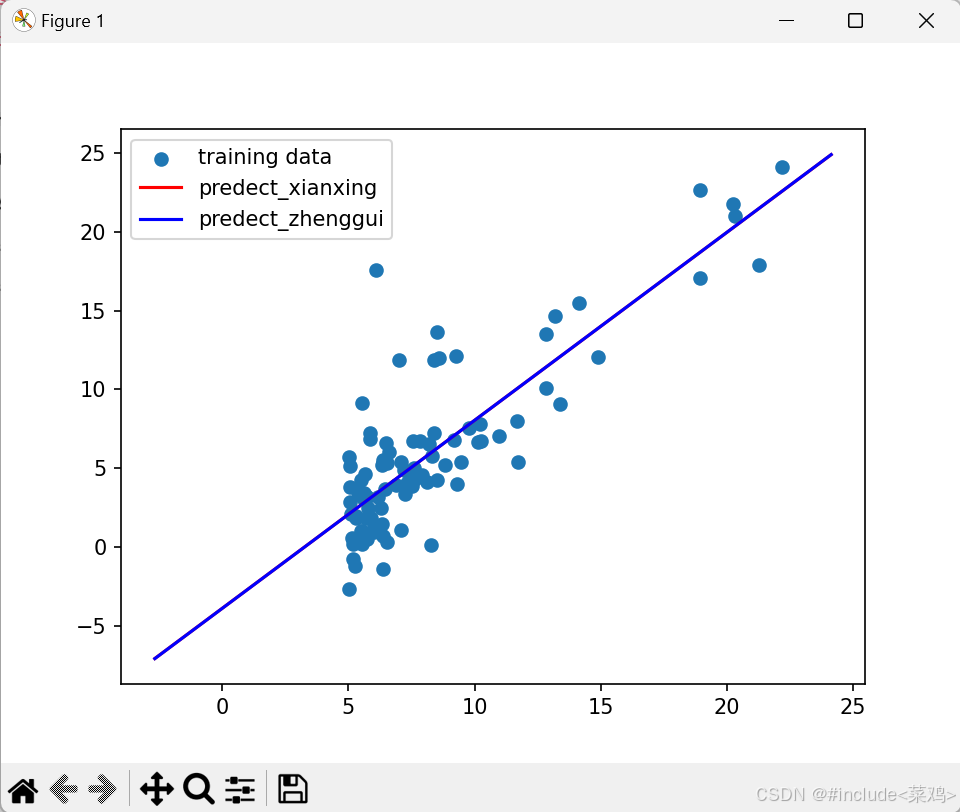
吴恩达机器学习课后题-01线性回归
线性回归 一.单变量线性回归题目损失函数(代价函数)梯度下降函数代价函数可视化整体代码 二.多变量线性回归特征归一化(特征缩放)不同学习率比较 正规方程正规方程与梯度下降比较 使用列表创建一维数组使用嵌套列表创建二维数组&a…...

白盒报告-jacoco
使用jacoco--执行nvn test 运行过程: 1、idea执行mvn test ,运行过程如下: a.maven-surefire-plugin:0.8.7执行目标动作:prepare-agent, 目的是:执行目标动作是为了在当前的项目名下生成jecoco.…...

【MySQL】SQL语句执行流程
目录 一、连接器 二、 查缓存 三、分析器 四、优化器 五、执行器 一、连接器 学习 MySQL 的过程中,除了安装,我们要做的第一步就是连接上 MySQL 在一开始我们都是先使用命令行连接 MySQL mysql -h localhost -u root -p 你的密码 使用这个命令…...
Selenium自动化防爬技巧:从入门到精通,保障爬虫稳定运行,通过多种方式和add_argument参数设置来达到破解防爬的目的
在Web自动化测试和爬虫开发中,Selenium作为一种强大的自动化工具,被广泛用于模拟用户行为、数据抓取等场景。然而,随着网站反爬虫技术的日益增强,直接使用Selenium很容易被目标网站识别并阻止。因此,掌握Selenium的防爬…...
)
用于免训练手术视频分割的记忆增强SAM2(MA-SAM2)
学影像 手术视频 基础模型增强 ──────────────────────────────────────── 1. 标题 英文:Memory-Augmented SAM2 for Training-Free Surgical Video Segmentation 中文:用于免训练手术视频分割的记忆增强SAM2(MA-SAM2) 2. 作者…...

别再死记硬背了!用Python模拟D触发器与JK触发器波形,5分钟搞定时序逻辑难题
用Python动态模拟时序逻辑:D触发器与JK触发器的可视化实践 时序逻辑电路是数字系统设计的核心基础,但对于许多初学者而言,纯理论推导和手工绘制波形图往往令人望而生畏。本文将带你用Python构建一个直观的触发器模拟系统,通过代码…...

实验室新到Franka机器人?保姆级Ubuntu20.04+ROS Noetic配置避坑指南
Franka机器人开箱配置全攻略:Ubuntu 20.04与ROS Noetic深度适配指南 当实验室那台崭新的Franka Emika机械臂拆箱时,整个团队都围了上来——这台价值不菲的协作机器人即将成为我们最重要的研究伙伴。但很快我们就发现,从开箱到真正让机械臂流畅…...

一款强大的PHP视频播放器:轻松嵌入,高效播放
一款强大的PHP视频播放器:轻松嵌入,高效播放 【下载地址】PHP视频播放器源码 本仓库提供了一个PHP视频播放器的源码,支持播放m3u8和mp4格式的资源。该播放器可以直接嵌入到网站中,方便用户在线观看视频内容 项目地址: https://g…...

换背景照片怎么制作?一篇全网最全的AI抠图工具对比指南
最近经常有朋友问我:"怎样才能快速换背景照片啊?"确实,随着自媒体时代的到来,无论是做电商展示产品、准备证件照,还是制作社交媒体内容,都离不开换背景这个需求。今天我就把这两年用过的所有抠图…...
)
基于单相全波晶闸管的基本交流电压控制器,带电阻负载(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

RV1126平台GC2053摄像头驱动移植与VLC视频流调试实战
1. RV1126与GC2053摄像头驱动移植实战 最近在一个人脸识别项目中遇到了一个有趣的技术挑战:需要在RV1126开发板上为GC2053红外摄像头添加驱动支持。这个看似简单的任务实际上涉及硬件连接、内核配置、设备树修改等多个环节。作为嵌入式开发者,我花了三天…...

<数据集>yolo 易拉罐识别<目标检测>
数据集下载链接https://download.csdn.net/download/qq_53332949/92882375数据集格式:VOCYOLO格式 图片数量:3253张 标注数量(xml文件个数):3253 标注数量(txt文件个数):3253 标注类别数:1 标注类别名称ÿ…...

智能体状态管理:会话、上下文与检查点
从一个“跑了三天三夜的Agent突然失忆”说起,聊聊状态管理的那些坑先给你讲一个让我头皮发麻的运维事故。 去年冬天,我们做了一个自动爬取竞品价格并生成调价建议的Agent。它跑得很好,连续工作了三天,完成了两万多件商品的价格监控…...

Ti AWR2243实测:毫米波雷达通道积累,选相干还是非相干?一个实验讲清楚
Ti AWR2243毫米波雷达通道积累策略:工程实践中的深度抉择 毫米波雷达在现代自动驾驶系统中扮演着关键角色,而通道积累策略的选择直接影响着目标检测的精度与系统实时性。面对192个虚拟通道的海量数据,工程师们常常陷入两难:是追求…...