【Python】 Scrapyd:Python Web Scraping 的强大分布式调度工具
我听见有人猜
你是敌人潜伏的内线
和你相知多年
我确信对你的了解
你舍命救我画面
一一在眼前浮现
司空见惯了鲜血
你忘记你本是娇娆的红颜
感觉你我彼此都那么依恋
🎵 许嵩《内线》
在网络爬虫项目中,Scrapy 是 Python 中最流行和强大的爬虫框架之一。然而,当你需要将 Scrapy 项目部署到服务器上,并自动调度、监控和管理多个爬虫时,仅仅依赖 Scrapy 本身可能还不够。此时,Scrapyd 是一个非常实用的解决方案。
Scrapyd 是一个专为 Scrapy 设计的分布式爬虫调度系统,它允许你轻松地将 Scrapy 项目部署到服务器上,提供 API 来管理和调度多个爬虫任务。通过 Scrapyd,开发者可以实现爬虫的持续运行、分布式调度、任务管理和日志查看等功能,大大提高了爬虫项目的可管理性和可维护性。
1. 什么是 Scrapyd?
Scrapyd 是 Scrapy 项目的守护进程,它提供了一个基于 HTTP 的 API,允许你通过 API 来管理爬虫任务。使用 Scrapyd 你可以:
- 将 Scrapy 爬虫部署到服务器上。
- 启动、停止、调度爬虫任务。
- 查看爬虫任务的状态和日志。
- 支持多项目管理,便于多个爬虫项目的部署和管理。
- 提供 Web API,用于远程控制和监控爬虫。
Scrapyd 可以在服务器上长时间运行,开发者通过 HTTP 请求就能控制服务器上的 Scrapy 爬虫,适合用于生产环境中的爬虫任务管理。
2. 安装 Scrapyd
Scrapyd 的安装非常简单。你可以使用 pip 来进行安装:
pip install scrapyd
安装完成后,你可以通过命令行直接启动 Scrapyd:
scrapyd
启动后,Scrapyd 会在本地的 http://localhost:6800/ 提供一个 API 服务,默认端口为 6800。通过这个 API,你可以与 Scrapyd 交互,控制和管理爬虫。
3. 部署 Scrapy 项目到 Scrapyd
要将 Scrapy 项目部署到 Scrapyd 上,你需要使用 scrapyd-client 工具。scrapyd-client 是一个专门用于将 Scrapy 项目打包并上传到 Scrapyd 的命令行工具。
3.1 安装 scrapyd-client
首先,安装 scrapyd-client:
pip install scrapyd-client
3.2 配置 Scrapy 项目
在你的 Scrapy 项目中,确保存在 scrapy.cfg 配置文件,它会指定项目的基本信息。然后,你可以通过在 scrapy.cfg 文件中添加 Scrapyd 服务器的配置来连接 Scrapyd:
[settings]
default = myproject.settings[deploy]
url = http://localhost:6800/
project = myproject
在这里,url 指向 Scrapyd 服务器的地址,project 指定项目名称。
3.3 部署项目
当配置完成后,你可以使用以下命令将 Scrapy 项目打包并上传到 Scrapyd:
scrapyd-deploy
这个命令会将当前 Scrapy 项目打包为一个 .egg 文件,并将其部署到 Scrapyd 服务器上。部署完成后,你的项目就可以通过 Scrapyd 的 API 进行管理和调度了。
4. 使用 Scrapyd API
Scrapyd 提供了一个基于 HTTP 的 RESTful API,允许你通过发送 HTTP 请求来管理爬虫任务。下面介绍一些常用的 API 操作:
4.1 启动爬虫
通过向 Scrapyd 的 /schedule.json 端点发送 POST 请求,你可以启动一个爬虫任务:
curl http://localhost:6800/schedule.json -d project=myproject -d spider=myspider
其中 project 是项目名称,spider 是你要启动的爬虫名称。成功启动后,Scrapyd 会返回任务 ID,你可以使用这个 ID 来监控任务的状态。
4.2 停止爬虫
如果你需要停止正在运行的爬虫,可以使用 /cancel.json 端点,并传入任务 ID 来取消任务:
curl http://localhost:6800/cancel.json -d project=myproject -d job=<job_id>
4.3 查看爬虫状态
通过 /listjobs.json 端点,你可以查看指定项目的爬虫任务状态:
curl http://localhost:6800/listjobs.json?project=myproject
这会返回正在运行(running)、等待(pending)和已完成(finished)的任务列表,帮助你实时监控爬虫的执行情况。
4.4 查看爬虫日志
Scrapyd 还允许你查看爬虫任务的日志。每个爬虫任务运行时都会生成日志,日志可以通过 /logs 端点访问:
http://localhost:6800/logs/myproject/myspider/<job_id>.log
在这里,myproject 是项目名称,myspider 是爬虫名称,<job_id> 是任务的 ID。
5. Scrapyd 的进阶使用
除了基本的任务管理功能,Scrapyd 还提供了一些高级功能,适合需要更复杂调度或分布式爬虫的场景。
5.1 定时任务调度
Scrapyd 本身不支持直接的定时调度功能,但是可以通过结合系统的任务调度工具(如 Linux 的 cron)或其他第三方工具(如 APScheduler)来实现定时启动爬虫任务。
例如,使用 cron 设置每天凌晨 3 点启动一次爬虫:
0 3 * * * curl http://localhost:6800/schedule.json -d project=myproject -d spider=myspider
5.2 分布式爬虫
Scrapyd 允许你将爬虫部署到多台服务器上,并通过分布式的方式运行多个爬虫实例。你只需要在不同的服务器上启动 Scrapyd 实例,并通过 API 在各个服务器上调度爬虫任务。这样可以提升爬取速度,适应大规模爬虫的需求。
5.3 使用 Docker 部署 Scrapyd
Scrapyd 也可以通过 Docker 来轻松部署。在服务器上运行 Scrapyd 的 Docker 容器,可以简化安装和配置。以下是使用 Docker 启动 Scrapyd 的基本命令:
docker run -d -p 6800:6800 --name scrapyd vimagick/scrapyd
这样你就可以在 http://localhost:6800/ 访问 Scrapyd,并通过 API 控制和管理爬虫任务。
6. Scrapyd 的优缺点
优点:
简洁易用:Scrapyd 提供了简单的 API 来控制和管理爬虫任务,易于使用。
支持多项目管理:你可以在同一个 Scrapyd 实例上管理多个 Scrapy 项目。
灵活的调度方式:结合系统工具或第三方调度器,可以灵活实现定时和分布式调度。
日志管理:Scrapyd 自动记录爬虫运行日志,便于调试和监控爬虫状态。
缺点:
无内置定时调度:Scrapyd 本身不支持定时任务调度,需要结合其他工具。
分布式管理依赖外部工具:虽然支持分布式爬虫,但需要手动在多个服务器上部署 Scrapyd 实例,并通过外部工具实现任务的协调。
7. 总结
Scrapyd 是一个强大且易于使用的 Scrapy 项目部署和管理工具。它为开发者提供了灵活的 API 来控制和调度爬虫任务,使得管理多个爬虫项目和任务变得更加简单和高效。通过结合系统级的调度工具(如 cron)或其他第三方调度工具,Scrapyd 可以在生产环境中有效地管理和自动化你的爬虫任务。
对于那些需要部署和管理大规模爬虫任务的开发者,Scrapyd 提供了一个强大的工具链,使得你可以将 Scrapy 爬虫项目轻松扩展到服务器上,并实现分布式爬虫、日志管理、任务调度等功能。如果你正在使用 Scrapy 进行 Web 爬取,并且需要管理多个爬虫实例或任务,Scrapyd 将是一个非常值得使用的解决方案。
相关文章:

【Python】 Scrapyd:Python Web Scraping 的强大分布式调度工具
我听见有人猜 你是敌人潜伏的内线 和你相知多年 我确信对你的了解 你舍命救我画面 一一在眼前浮现 司空见惯了鲜血 你忘记你本是娇娆的红颜 感觉你我彼此都那么依恋 🎵 许嵩《内线》 在网络爬虫项目中,Scrapy 是 Python 中最流行和…...
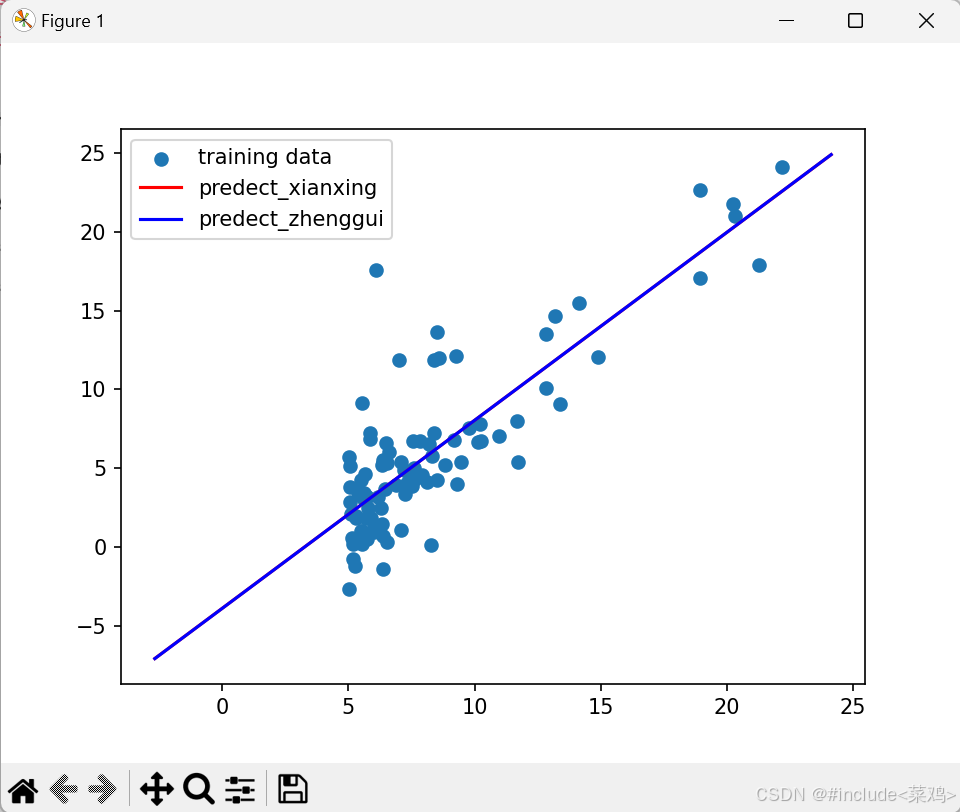
吴恩达机器学习课后题-01线性回归
线性回归 一.单变量线性回归题目损失函数(代价函数)梯度下降函数代价函数可视化整体代码 二.多变量线性回归特征归一化(特征缩放)不同学习率比较 正规方程正规方程与梯度下降比较 使用列表创建一维数组使用嵌套列表创建二维数组&a…...

白盒报告-jacoco
使用jacoco--执行nvn test 运行过程: 1、idea执行mvn test ,运行过程如下: a.maven-surefire-plugin:0.8.7执行目标动作:prepare-agent, 目的是:执行目标动作是为了在当前的项目名下生成jecoco.…...

【MySQL】SQL语句执行流程
目录 一、连接器 二、 查缓存 三、分析器 四、优化器 五、执行器 一、连接器 学习 MySQL 的过程中,除了安装,我们要做的第一步就是连接上 MySQL 在一开始我们都是先使用命令行连接 MySQL mysql -h localhost -u root -p 你的密码 使用这个命令…...
Selenium自动化防爬技巧:从入门到精通,保障爬虫稳定运行,通过多种方式和add_argument参数设置来达到破解防爬的目的
在Web自动化测试和爬虫开发中,Selenium作为一种强大的自动化工具,被广泛用于模拟用户行为、数据抓取等场景。然而,随着网站反爬虫技术的日益增强,直接使用Selenium很容易被目标网站识别并阻止。因此,掌握Selenium的防爬…...
从数据类型到变量、作用域、执行上下文
从数据类型到变量、作用域、执行上下文 JS数据类型 分类 1》基本类型:字符串String、数字Number、布尔值Boolean、undefined、null、symbol、bigint 2》引用类型:Object (Object、Array、Function、Date、RegExp、Error、Arguments) Symbol是ES6新出…...

一文读懂:AI时代到底需要什么样的网络?
各位小伙伴们大家好哈,我是老猫。 今天跟大家来聊聊数据中心网络。 提到网络,通常把网络比作高速公路,网卡相当于上下高速公路的闸口,数据包就相当于运送数据的汽车,交通法规就是“传输协议”。 如高速公路也会堵车一…...

基于HarmonyOS的宠物收养系统的设计与实现(一)
基于HarmonyOS的宠物收养系统的设计与实现(一) 本系统是简易的宠物收养系统,为了更加熟练地掌握HarmonyOS相关技术的使用。 项目创建 创建一个空项目取名为PetApp 首页实现(组件导航使用) 官方文档:组…...

严格模式报错
部分参考: Android内存泄露分析之StrictMode - 星辰之力 - 博客园 (cnblogs.com)...

nginx: [emerg] the “ssl“ parameter requires ngx_http_ssl_module in nginx.conf
nginx: [emerg] the "ssl" parameter requires ngx_http_ssl_module in /usr/local/nginx/conf/nginx.conf:42 查看/usr/local/nginx/conf/nginx.conf文件第42行数据: listen 443 ssl; # server中的配置 原因是:nginx缺少 http_ssl_modul…...

Docker 部署loki日志 用于微服务
因为每次去查看日志都去登录服务器去查询相关日志文件,还有不同的微服务,不同日期的文件夹,超级麻烦,因为之前用过ELK,原本打算用ELK,在做技术调研的时候发现了一个轻量级的日志系统Loki,果断采…...

[Day 57] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
區塊鏈的零知識證明技術 一、引言 隨著區塊鏈技術的不斷發展,如何在保護用戶隱私的同時確保數據的完整性和可信度成為了研究的焦點。零知識證明(Zero-Knowledge Proof,ZKP)技術就是其中的一項關鍵技術,它允許一方在不…...

06结构型设计模式——代理模式
一、代理模式简介 代理模式(Proxy Pattern)是一种结构型设计模式(GoF书中解释结构型设计模式:一种用来处理类或对象、模块的组合关系的模式),代理模式是其中的一种,它可以为其他对象提供一种代…...

《深入浅出多模态》(九)多模态经典模型:MiniGPT-v2、MiniGPT5
🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、资料共享、行业最新动态以、实践教程、求职…...

调试和优化大型深度学习模型 - 0 技术介绍
调试和优化大型深度学习模型 - 0 技术介绍 flyfish LLaMA Factory LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上…...

华为S3700交换机配置VLAN的方法
1.VLAN的详细介绍 VLAN(Virtual Local Area Network)即虚拟局域网,是一种将一个物理的局域网在逻辑上划分成多个广播域的技术。 1.1基本概念 1)作用: 隔离广播域:通过将网络划分为不同的 VLAN,广播帧只会在同一 VLAN 内传播,而不会扩散到其他 VLAN 中,从而有效…...
:深入详解C++网络编程:套接字(Socket)开发技术)
学懂C++(三十八):深入详解C++网络编程:套接字(Socket)开发技术
目录 一、概述与基础概念 1.1 套接字(Socket)概念 1.2 底层原理与网络协议 1.2.1 网络协议 1.2.2 套接字工作原理 二、C套接字编程核心技术 2.1 套接字编程的基本步骤 2.2 套接字编程详细实现 2.2.1 创建套接字 2.2.2 绑定地址 2.2.3 监听和接…...

SpringBoot-配置加载顺序
目录 前言 样例 内部配置加载顺序 样例 小结 前言 我之前写的配置文件,都是放在resources文件夹,根据当前目录下,优先级的高低,判断谁先被加载。但实际开发中,我们写的配置文件并不是,都放…...

第八周:机器学习笔记
第八周机器学习笔记 摘要Abstract机器学习1. 鱼和熊掌和可兼得的机器学习1.1 Deep network v.s. Fat network 2. 为什么用来验证集结果还是不好? Pytorch学习1. 卷积层代码实战2. 最大池化层代码实战3. 非线性激活层代码实战 总结 摘要 本周学习对李宏毅机器学习视…...

音乐怎么剪切掉一部分?5个方法,轻松学会音频分割!(2024全新)
音乐怎么剪切掉一部分?音频文件是娱乐和创作的重要基础。音频在我们日常生活中发挥着重要作用,从音乐播放列表到有趣的视频,它无处不在。无论是音乐爱好者还是内容创作者,我们常常需要对音频文件进行剪切和编辑。想象一下…...

告别浏览器标签混乱:5分钟搭建高效Gmail桌面邮件中心
告别浏览器标签混乱:5分钟搭建高效Gmail桌面邮件中心 【免费下载链接】gmail-desktop :postbox: Gmail desktop app for macOS, Windows & Linux (formerly Gmail Desktop) 项目地址: https://gitcode.com/gh_mirrors/gm/gmail-desktop 厌倦了在浏览器标…...

从双非到科软:我的22408备考复盘与实战指南
1. 双非逆袭科软:我的备考心路历程 作为一名双非院校的计算机专业学生,我深知考研这条路有多难走。去年这个时候,我也和屏幕前的你一样,在知乎、贴吧疯狂搜索各种经验贴,既期待又忐忑。现在回想起来,从3月到…...
)
别再为JDK版本头疼了!用Adoptium JRE 13搞定OpenTCS 5.11开发环境(附完整变量配置)
开源AGV调度系统OpenTCS 5.11开发环境配置实战指南 在自动化物流系统开发领域,OpenTCS作为一款功能强大的开源交通控制系统,正逐渐成为AGV(自动导引车)调度解决方案的热门选择。然而对于初次接触该系统的开发者而言,J…...

Beam Search不是训练用的!搞懂它在NLP模型评估中的正确打开方式
Beam Search在NLP模型评估中的正确实践指南 当你在调试一个文本生成模型时,是否遇到过这样的困惑:训练时指标表现优异,实际生成时却频频输出不连贯的句子?这往往源于对序列生成任务中关键环节——推理阶段解码策略的误解。许多开发…...

物业临时工考勤记录管理痛点与栎偲考勤神器技术实现方案
物业行业临时工考勤一直是HR管理的“老大难”:人员流动性大、班次碎片化(如早班/晚班/临时替班)、外勤打卡场景多(如园区巡检、设备维修),传统Excel统计不仅耗时,还常因数据错漏引发薪资纠纷。本…...

Unity加载倾斜摄影模型踩坑记:从3MX/OSGB文件到流畅渲染,我解决了这几个问题
Unity倾斜摄影模型加载实战:从3MX/OSGB到跨平台渲染的深度解决方案 第一次在Unity中加载倾斜摄影模型时,那种期待和忐忑交织的心情至今难忘。作为智慧城市项目的核心展示环节,我们需要将航拍生成的3MX和OSGB格式模型无缝集成到Unity场景中。本…...

【亲测免费】 探索卷积神经网络之美:一键绘制专业结构图的利器
探索卷积神经网络之美:一键绘制专业结构图的利器 【下载地址】卷积神经网络结构绘制工具 本资源适用于需要展示卷积神经网络具体结构的研究人员。用户下载本项目后,按照README官方教程中的“Getting Started”部分进行操作,简单学习语法后即可…...

多智能体会被“单强模型”取代吗:从系统复杂度看真实趋势
标题:多智能体会被“单强模型”取代吗:从系统复杂度看真实技术演化趋势 关键词:多智能体系统、通用人工智能、大语言模型、系统复杂度、涌现性、任务分解、AI范式演化 摘要:2024年以来,GPT-4o、Claude 3 Opus等单一大模型的通用能力边界持续突破,不少开发者发现此前需要…...

生物 --- 免疫力
1、免疫的概念免疫是人体的一种生理功能。识别“自己”和“非己”。破坏和排斥进入人体内的抗原物质,如病原体。指机体识别和清除外来入侵抗原及体内突变或衰老细胞,并维持自身内环境稳定的生理功能。2、免疫系统的构成免疫系统主要由免疫器官、免疫细胞…...

多智能体强化学习中的分层安全架构设计与实现
1. 多智能体强化学习中的分层安全架构设计在复杂动态环境中实现多智能体系统的安全协调一直是个极具挑战性的问题。传统方法要么过于保守导致效率低下,要么缺乏理论安全保障。我们提出的分层安全架构通过将智能体邻近空间划分为三个明确区域,为这一问题提…...