吴恩达机器学习课后题-01线性回归
线性回归
- 一.单变量线性回归
- 题目
- 损失函数(代价函数)
- 梯度下降函数
- 代价函数可视化
- 整体代码
- 二.多变量线性回归
- 特征归一化(特征缩放)
- 不同学习率比较
- 正规方程
- 正规方程与梯度下降比较
- 使用列表创建一维数组
- 使用嵌套列表创建二维数组(矩阵)
- 创建一个3x3的零矩阵
- 创建一个3x3的1矩阵
- 创建一个3x3的矩阵,所有元素都是42
- 使用arange生成一个一维数组
- 使用linspace在指定间隔内生成均匀间隔的数值
- 生成一个3x3的随机浮点数矩阵
- 生成一个3x3的随机整数矩阵,元素范围在0到10之间
一.单变量线性回归
题目

numpy:科学计算库,处理多维数组,进行数据分析
pandas :是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的
Matplotlib:Python 的2D绘图库
matplotlib.pyplot:提供一个类似matlab的绘图框架


dataframe转数组三种方式
dataframe - > ndarray.
1.df.xalues,
2.df.as_matrix()
3.np.array(df)
绘制散点图

import numpy as np
import pandas as pd
import matplotlib.pyplot as pltdata=pd.read_csv("E:/学习/研究生阶段/python-learning/吴恩达机器学习课后作业/code/ex1-linear regression/ex1data1.txt",names=["population","profit"])
#print(data.describe())
data.plot.scatter("population","profit",label="population")
plt.show()损失函数(代价函数)

def costfunction(x,y,theta):inner=np.power ( x @ theta-y,2)return np.sum(inner)/(2*len(x))
这个函数 costfunction 是用来计算线性回归中的成本(或损失)函数的,具体来说是均方误差(Mean Squared Error, MSE)成本函数。这个函数接受三个参数:x(特征矩阵),y(目标变量向量),和theta(参数向量,即线性模型的权重和偏置项)。下面是该函数的详细解释:
参数解释:
x:特征矩阵,其形状通常为 (m, n),其中 m 是样本数量,n 是特征数量(不包括偏置项)。
y:目标变量向量,其形状为 (m,),即每个样本对应一个目标值。
theta:参数向量,其长度应与 x 的特征数量加1相等(如果 x 不包含偏置项的话),因为我们需要一个额外的偏置项。theta 的第一个元素通常被认为是偏置项(截距),而其余元素对应于每个特征的权重。
函数逻辑:
x @ theta:这是矩阵乘法操作,计算 x 和 theta 的点积。如果 theta 的第一个元素是偏置项,那么 x 应该包含一列全为1的列(通常作为第一列),以对应偏置项。这样,x @ theta 的结果就是一个预测值向量,其形状与 y 相同((m,))。
np.power(x @ theta - y, 2):计算预测值与实际值之间的差的平方。这是计算误差的一种方式,平方是为了确保所有误差都是正的,并且能够放大较大的误差。
np.sum(inner):将上一步得到的误差平方向量中的所有元素相加,得到总误差。
return np.sum(inner)/(2len(x)):将总误差除以 2m(其中 m 是样本数量),得到平均误差的平方的一半。除以2主要是为了在求导时简化表达式,因为在实际应用中,我们经常需要计算成本函数的梯度,而这个操作可以简化梯度的计算。
注意事项:
在使用这个函数之前,需要确保 x 包含了偏置项(即一列全为1的列),除非你的 theta 已经被相应地调整过(例如,theta 的第一个元素不代表偏置项)。
确保 np(NumPy库)已经被正确导入,因为函数中用到了 np.power 和 np.sum 等NumPy库中的函数。
这个函数是线性回归模型训练过程中的一个重要组成部分,通过最小化这个成本函数,我们可以找到最佳的 theta 值,使得模型的预测值尽可能接近实际值。
[[0.] [0.]]
这个数据是一个二维的浮点数列表(或可以视为一个2x1的矩阵),用Python的列表表示法来表示。每个子列表都包含一个浮点数 0.,表示0.0(即0的浮点数表示)。具体来说,数据是这样的:
python
[
[0.], # 第一个子列表,包含一个浮点数0.0
[0.] # 第二个子列表,也包含一个浮点数0.0
]
在Python中,这种数据结构是一个嵌套的列表(list of lists),外层列表包含两个元素,每个元素都是一个包含一个浮点数的内层列表。这种数据结构可以很方便地用numpy库转换成矩阵(numpy array)进行处理。
例如,使用numpy可以这样转换:
python
import numpy as np
data = [[0.], [0.]]
matrix = np.array(data)
print(matrix)
这段代码会输出:
[[0.]
[0.]]
这就是一个2x1的浮点数矩阵。在数据分析、机器学习或科学计算中,这种数据结构非常常见,特别是当使用numpy、pandas或其他科学计算库时。
梯度下降函数
"""
定义梯度下降函数
alpha:学习速率
inters:迭代次数
"""
def gradientDescent(x,y,theta,alpha,inters):for i in range(inters):costs=[]theta=theta-(x.T @ (x@theta-y))*alpha/len(x)cost=costfunction(x,y,theta)costs.append(cost)if i%100==0:print(cost)return theta,costs
代价函数可视化

fig是整张图
ax是
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfig, ax =plt.subplots()
ax.plot()
plt.show()


import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfig, ax =plt.subplots(2,2)
ax1=ax[0,1]
ax1.plot()
plt.show()
整体代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt#定义代价函数
def costfunction(x,y,theta):inner=np.power ( x @ theta-y,2)return np.sum(inner)/(2*len(x))"""
定义梯度下降函数
alpha:学习速率
inters:迭代次数
"""
def gradientDescent(x,y,theta,alpha,inters):costs=[]for i in range(inters):theta=theta-(x.T @ (x@theta-y))*alpha/len(x)cost=costfunction(x,y,theta)costs.append(cost)# if i%100==0:# print(cost)return theta,coststheta=np.zeros((2,1))#theta初始值2x1零矩阵
alpha=0.02#学习速率初始化
inters=2000#迭代次数初始化
data=pd.read_csv("E:/学习/研究生阶段/python-learning/吴恩达机器学习课后作业/code/ex1-linear regression/ex1data1.txt",names=["population","profit"])
#print(data.describe())
#data.plot.scatter("population","profit",label="population")
#plt.show()
data.insert(0,"ones",1)
x=data.iloc[:,0:-1]#取数据的0-倒数第二列,取所有行
#print(x)
y=data.iloc[:,-1:]
x=x.valuesy=y.values#y.shape,求矩阵大小
theta,costs=gradientDescent(x,y,theta,alpha,inters)fig,ax=plt.subplots(1,2)
ax1=ax[0]
ax1.plot(np.arange(inters),costs)
ax1.set(xlabel="inters",ylabel="costs",title="costs Vs inters")x_=np.linspace(y.min(),y.max(),100)
print(x_)
y_=theta[0,0]+theta[1,0]*x_
ax2=ax[1]
ax2.scatter(x[:,1],y,label="training data")
ax2.plot(x_,y_,"r",label="predect")
ax2.legend()
plt.show()
二.多变量线性回归

特征归一化(特征缩放)
1. 消除特征值之间的量纲影响,各特征值处于同一数量级提升
2. 模型的收敛速度
3. 提升模型的精度
在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。

不同学习率比较
#多变量线性回归
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt#定义代价函数
def costfunction(x,y,theta):inner=np.power ( x @ theta-y,2)return np.sum(inner)/(2*len(x))"""
定义梯度下降函数
alpha:学习速率
inters:迭代次数
"""
def gradientDescent(x,y,theta,alpha,inters):costs=[]for i in range(inters):theta=theta-(x.T @ (x@theta-y))*alpha/len(x)cost=costfunction(x,y,theta)costs.append(cost)# if i%100==0:# print(cost)return theta,coststheta=np.zeros((3,1))#theta初始值2x1零矩阵
alpha=[0.0003,0.003,0.03,0.3,0.0001,0.001,0.1]#学习速率初始化
inters=2000#迭代次数初始化"""
归一化函数
data.mean平均值
data.std标准差
"""
def normalize_feature(data):return (data-data.mean())/data.std()
data=pd.read_csv("E:/学习/研究生阶段/python-learning/吴恩达机器学习课后作业/code/ex1-linear regression/ex1data2.txt",names=["size","bedrooms","price"])
data=normalize_feature(data)
# data.plot.scatter("size","price",label="price")
# plt.show()
data.insert(0,"ones",1)
x=data.iloc[:,0:-1]#取数据的0-倒数第二列,取所有行
y=data.iloc[:,-1:]
x=x.values#datafram转数组格式
y=y.values#y.shape,求矩阵大小
fig,ax1=plt.subplots()
for _alpha in alpha:_theta, costs = gradientDescent(x, y, theta, _alpha, inters)ax1.plot(np.arange(inters),costs,label=_alpha)
ax1.legend()#显示图例标签
ax1.set(xlabel="inters",ylabel="costs",title="costs Vs inters")
plt.show()

正规方程

正规方程与梯度下降比较

"""
单变量线性回归为例
"""
import numpy as npimport pandas as pd
import matplotlib.pyplot as plt
#定义正规方程
def normalequation(x,y):theta = np.linalg.inv(x.T @ x) @ x.T @ yreturn thetadata=pd.read_csv("E:/学习/研究生阶段/python-learning/吴恩达机器学习课后作业/code/ex1-linear regression/ex1data1.txt",names=["population","profit"])
#print(data.describe())
#data.plot.scatter("population","profit",label="population")
#plt.show()
data.insert(0,"ones",1)
x=data.iloc[:,0:-1]#取数据的0-倒数第二列,取所有行
#print(x)
y=data.iloc[:,-1:]
x=x.values
y=y.values
theta=normalequation(x,y)
print(theta)
#线性回归求得的参数
theta1=np.array([[-3.8928815],[1.19274237]])
print(theta1)
print(type(theta),type(theta1))
fig,ax=plt.subplots()
x_=np.linspace(y.min(),y.max(),100)
# print(x_)
y_1=theta1[0,0]+theta1[1,0]*x_
y_2=theta[0,0]+theta[1,0]*x_
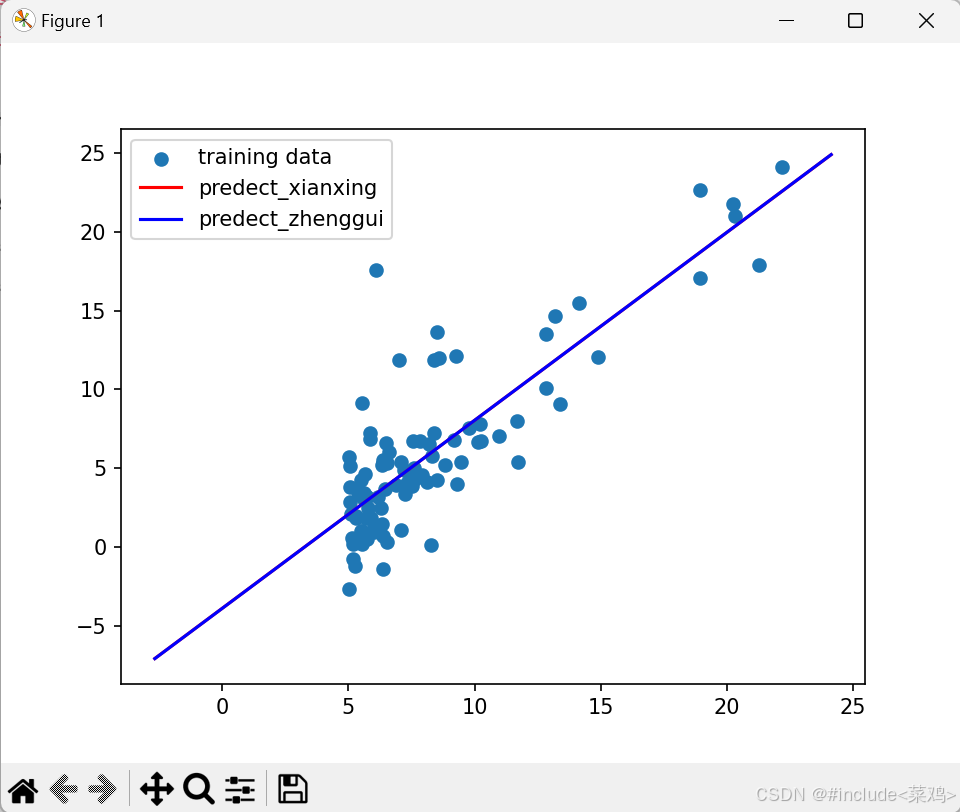
ax.scatter(x[:,1],y,label="training data")
ax.plot(x_,y_1,"r",label="predect_xianxing")
ax.plot(x_,y_2,"b",label="predect_zhenggui")
ax.legend()
plt.show()结果
线性回归:theta1=[[-3.8928815],[1.19274237]]
正规方程:theta=[[-3.89578088], [ 1.19303364]]
基本差不多
在Python中,numpy.ndarray是NumPy库提供的一个用于存储和操作大型多维数组和矩阵的核心对象。NumPy是Python的一个库,它提供了大量的数学函数工具,特别是针对数组的操作。要定义一个numpy.ndarray类型的矩阵,你首先需要安装并导入NumPy库,然后使用NumPy提供的函数或方法来创建数组。
以下是一些创建numpy.ndarray类型矩阵的基本方法:
- 使用numpy.array()
这是最直接的方法,你可以将Python的列表(list)或其他序列类型转换为NumPy数组。
python
import numpy as np
使用列表创建一维数组
arr_1d = np.array([1, 2, 3, 4, 5])
使用嵌套列表创建二维数组(矩阵)
arr_2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr_1d)
print(arr_2d)
2. 使用numpy.zeros(), numpy.ones(), numpy.full()
这些函数分别用于创建指定形状和类型,但所有元素分别为0、1或指定值的数组。
python
创建一个3x3的零矩阵
zero_matrix = np.zeros((3, 3))
创建一个3x3的1矩阵
ones_matrix = np.ones((3, 3))
创建一个3x3的矩阵,所有元素都是42
full_matrix = np.full((3, 3), 42)
print(zero_matrix)
print(ones_matrix)
print(full_matrix)
3. 使用numpy.arange(), numpy.linspace()
这些函数用于生成具有特定间隔的数值数组。
python
使用arange生成一个一维数组
arr_arange = np.arange(0, 10, 2) # 从0开始到10(不包括10),步长为2
使用linspace在指定间隔内生成均匀间隔的数值
arr_linspace = np.linspace(0, 10, 5) # 从0到10生成5个均匀间隔的数
print(arr_arange)
print(arr_linspace.reshape((2, -1))) # 将其重塑为2x2矩阵(注意:这里5个元素不能完美重塑为2x2,仅为示例)
4. 使用numpy.random模块
NumPy的random模块提供了多种生成随机数组的函数。
python
生成一个3x3的随机浮点数矩阵
random_matrix = np.random.rand(3, 3)
生成一个3x3的随机整数矩阵,元素范围在0到10之间
random_int_matrix = np.random.randint(0, 11, size=(3, 3))
print(random_matrix)
print(random_int_matrix)
以上就是在Python中使用NumPy库定义numpy.ndarray类型矩阵的几种基本方法。NumPy提供了丰富的函数和特性,使得数组和矩阵的操作变得既高效又方便。
相关文章:
吴恩达机器学习课后题-01线性回归
线性回归 一.单变量线性回归题目损失函数(代价函数)梯度下降函数代价函数可视化整体代码 二.多变量线性回归特征归一化(特征缩放)不同学习率比较 正规方程正规方程与梯度下降比较 使用列表创建一维数组使用嵌套列表创建二维数组&a…...

白盒报告-jacoco
使用jacoco--执行nvn test 运行过程: 1、idea执行mvn test ,运行过程如下: a.maven-surefire-plugin:0.8.7执行目标动作:prepare-agent, 目的是:执行目标动作是为了在当前的项目名下生成jecoco.…...

【MySQL】SQL语句执行流程
目录 一、连接器 二、 查缓存 三、分析器 四、优化器 五、执行器 一、连接器 学习 MySQL 的过程中,除了安装,我们要做的第一步就是连接上 MySQL 在一开始我们都是先使用命令行连接 MySQL mysql -h localhost -u root -p 你的密码 使用这个命令…...
Selenium自动化防爬技巧:从入门到精通,保障爬虫稳定运行,通过多种方式和add_argument参数设置来达到破解防爬的目的
在Web自动化测试和爬虫开发中,Selenium作为一种强大的自动化工具,被广泛用于模拟用户行为、数据抓取等场景。然而,随着网站反爬虫技术的日益增强,直接使用Selenium很容易被目标网站识别并阻止。因此,掌握Selenium的防爬…...
从数据类型到变量、作用域、执行上下文
从数据类型到变量、作用域、执行上下文 JS数据类型 分类 1》基本类型:字符串String、数字Number、布尔值Boolean、undefined、null、symbol、bigint 2》引用类型:Object (Object、Array、Function、Date、RegExp、Error、Arguments) Symbol是ES6新出…...

一文读懂:AI时代到底需要什么样的网络?
各位小伙伴们大家好哈,我是老猫。 今天跟大家来聊聊数据中心网络。 提到网络,通常把网络比作高速公路,网卡相当于上下高速公路的闸口,数据包就相当于运送数据的汽车,交通法规就是“传输协议”。 如高速公路也会堵车一…...

基于HarmonyOS的宠物收养系统的设计与实现(一)
基于HarmonyOS的宠物收养系统的设计与实现(一) 本系统是简易的宠物收养系统,为了更加熟练地掌握HarmonyOS相关技术的使用。 项目创建 创建一个空项目取名为PetApp 首页实现(组件导航使用) 官方文档:组…...

严格模式报错
部分参考: Android内存泄露分析之StrictMode - 星辰之力 - 博客园 (cnblogs.com)...

nginx: [emerg] the “ssl“ parameter requires ngx_http_ssl_module in nginx.conf
nginx: [emerg] the "ssl" parameter requires ngx_http_ssl_module in /usr/local/nginx/conf/nginx.conf:42 查看/usr/local/nginx/conf/nginx.conf文件第42行数据: listen 443 ssl; # server中的配置 原因是:nginx缺少 http_ssl_modul…...

Docker 部署loki日志 用于微服务
因为每次去查看日志都去登录服务器去查询相关日志文件,还有不同的微服务,不同日期的文件夹,超级麻烦,因为之前用过ELK,原本打算用ELK,在做技术调研的时候发现了一个轻量级的日志系统Loki,果断采…...

[Day 57] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
區塊鏈的零知識證明技術 一、引言 隨著區塊鏈技術的不斷發展,如何在保護用戶隱私的同時確保數據的完整性和可信度成為了研究的焦點。零知識證明(Zero-Knowledge Proof,ZKP)技術就是其中的一項關鍵技術,它允許一方在不…...

06结构型设计模式——代理模式
一、代理模式简介 代理模式(Proxy Pattern)是一种结构型设计模式(GoF书中解释结构型设计模式:一种用来处理类或对象、模块的组合关系的模式),代理模式是其中的一种,它可以为其他对象提供一种代…...

《深入浅出多模态》(九)多模态经典模型:MiniGPT-v2、MiniGPT5
🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、资料共享、行业最新动态以、实践教程、求职…...

调试和优化大型深度学习模型 - 0 技术介绍
调试和优化大型深度学习模型 - 0 技术介绍 flyfish LLaMA Factory LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上…...

华为S3700交换机配置VLAN的方法
1.VLAN的详细介绍 VLAN(Virtual Local Area Network)即虚拟局域网,是一种将一个物理的局域网在逻辑上划分成多个广播域的技术。 1.1基本概念 1)作用: 隔离广播域:通过将网络划分为不同的 VLAN,广播帧只会在同一 VLAN 内传播,而不会扩散到其他 VLAN 中,从而有效…...
:深入详解C++网络编程:套接字(Socket)开发技术)
学懂C++(三十八):深入详解C++网络编程:套接字(Socket)开发技术
目录 一、概述与基础概念 1.1 套接字(Socket)概念 1.2 底层原理与网络协议 1.2.1 网络协议 1.2.2 套接字工作原理 二、C套接字编程核心技术 2.1 套接字编程的基本步骤 2.2 套接字编程详细实现 2.2.1 创建套接字 2.2.2 绑定地址 2.2.3 监听和接…...

SpringBoot-配置加载顺序
目录 前言 样例 内部配置加载顺序 样例 小结 前言 我之前写的配置文件,都是放在resources文件夹,根据当前目录下,优先级的高低,判断谁先被加载。但实际开发中,我们写的配置文件并不是,都放…...

第八周:机器学习笔记
第八周机器学习笔记 摘要Abstract机器学习1. 鱼和熊掌和可兼得的机器学习1.1 Deep network v.s. Fat network 2. 为什么用来验证集结果还是不好? Pytorch学习1. 卷积层代码实战2. 最大池化层代码实战3. 非线性激活层代码实战 总结 摘要 本周学习对李宏毅机器学习视…...

音乐怎么剪切掉一部分?5个方法,轻松学会音频分割!(2024全新)
音乐怎么剪切掉一部分?音频文件是娱乐和创作的重要基础。音频在我们日常生活中发挥着重要作用,从音乐播放列表到有趣的视频,它无处不在。无论是音乐爱好者还是内容创作者,我们常常需要对音频文件进行剪切和编辑。想象一下…...

洛谷 CF295D Greg and Caves
题目来源于:洛谷 题目本质:动态规划dp,枚举 解题思路:将整个洞分成两半,一半递增,一半递减。我们分别 DP 求值,最后合并。状态转移方程为:dpi,jk2∑j(j−k1)dpi−1,k1。枚举极…...

用Python lifetimes库实战:手把手教你用BG/NBD+Gamma-Gamma模型预测电商用户未来3个月价值
用Python lifetimes库实战:电商用户价值预测的极简指南 电商行业的核心挑战之一是如何精准识别高价值用户。想象一下,你手头有一份过去12个月的交易数据,老板要求你在下周的预算会议前,预测未来三个月哪些用户最值得投入营销资源。…...

从零打造3D打印外壳:精准适配Adafruit Trellis控制器全流程
1. 项目概述与核心思路如果你手头有一块Adafruit Trellis按钮板,想把它变成一个握感扎实、外观专业的独立设备,比如一个迷你音乐控制器或者游戏手柄,那么为它设计并打印一个专属外壳,几乎是必经之路。这个项目远不止是把电路板塞进…...

日本租房成本核算沙盘
最近忙着租房子,日本租房不同于国内,有非常多杂乱的费用,这些都是必须在租房子的时候就考虑在内的,所以我制作了这个网站,希望能帮助到各位小伙伴。 目前已经部署在了服务器上,网址如下 http://8.130.68.…...

从特征稀缺到精准定位:基于HS-FPN与可变形注意力的白细胞检测新范式
1. 白细胞检测的现状与挑战 在医学影像分析领域,白细胞检测一直是个让人头疼的问题。想象一下,医生需要从密密麻麻的血细胞图像中找出白细胞,就像在沙滩上找特定形状的贝壳一样困难。传统方法主要依赖医生手动操作显微镜,不仅效率…...

GPU缓存架构优化与AI加速器内存技术解析
1. GPU缓存架构与AI加速器的内存挑战在AI计算领域,内存子系统已成为制约性能提升的关键瓶颈。传统GPU采用的多级缓存架构(L1/L2/L3)虽然能有效缓解"内存墙"问题,但随着Transformer等大模型参数量呈指数级增长࿰…...

STC8单片机按键事件处理代码实现
STC8单片机按键事件处理代码实现 【下载地址】STC8单片机按键事件处理代码实现 本仓库提供了一个用于STC8单片机的按键事件处理代码实现,支持按键的单击、双击和长按事件。该代码设计简洁,易于理解和移植,可以方便地应用于其他单片机平台。 …...
)
TVA智能体范式的工业视觉革命(10)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

量子纠错与Floquet码:动态编码与ZX演算实践
1. 量子纠错与Floquet码基础量子纠错码是构建容错量子计算机的核心技术。与传统纠错码不同,量子态具有不可克隆特性,使得量子纠错必须采用特殊方法。稳定子码(Stabilizer Codes)是目前最成熟的量子纠错方案,通过测量多…...
)
DiagramPainter(图表制作软件)
链接:https://pan.quark.cn/s/9edc83129f49DiagramPainter是一款界面简洁的图表制作软件,内部有很多的图标可以使用,能够快速制作流程图、思维导图、结构图等等图表,还有数字水彩效果,支持保存为多种图像格式ÿ…...

如何通过Magisk实现Android系统无痕定制:开发者的终极实战指南
如何通过Magisk实现Android系统无痕定制:开发者的终极实战指南 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为一款革命性的Android系统定制框架,以其独特的"无系…...