50道深度NLP和人工智能领域面试题+答案

编者按:分享一个很硬核的免费人工智能学习网站,通俗易懂,风趣幽默, 可以当故事来看,轻松学习。
-
什么是自然语言处理(NLP)?自然语言处理是一种人工智能领域,致力于使计算机能够理解、解释、生成和操作人类语言的技术。
-
NLP 中常见的任务有哪些?NLP 中常见的任务包括文本分类、命名实体识别、情感分析、机器翻译、文本生成、对话系统等。
-
什么是词嵌入(Word Embedding)?词嵌入是将单词映射到连续向量空间的技术,它可以捕捉单词之间的语义和语法关系,常用的算法包括Word2Vec、GloVe和FastText。
-
解释一下循环神经网络(RNN)和长短时记忆网络(LSTM)。RNN 是一种具有循环连接的神经网络,用于处理序列数据;LSTM 是一种特殊的RNN结构,通过门控机制解决了传统RNN的梯度消失和梯度爆炸问题。
-
什么是注意力机制(Attention Mechanism)?注意力机制是一种用于加强神经网络在处理序列数据时的性能的技术,它允许网络动态地关注输入序列的不同部分,提高模型的表现力。
-
请解释一下机器翻译中的编码器-解码器(Encoder-Decoder)结构。编码器将输入序列转换为潜在表示,解码器根据编码器的输出生成翻译序列,这种结构常用于机器翻译任务。
-
什么是 BERT(Bidirectional Encoder Representations from Transformers)?它在NLP中有什么样的作用?BERT是一种预训练语言模型,通过训练深度双向Transformer模型,实现了在大规模语料上学习通用的自然语言表示,广泛应用于各种NLP任务,如问答系统、命名实体识别和文本分类。
-
请解释一下 GPT(Generative Pre-trained Transformer)模型及其在生成文本方面的应用。GPT是一种基于Transformer架构的预训练语言模型,通过自回归方式不断生成基于上下文的文本,被用于生成对话、摘要以及自动写作。
-
请比较一下Word2Vec和GloVe这两种常见的词嵌入技术,以及它们各自的优缺点。
Word2Vec和GloVe都是常见的词嵌入技术,前者基于Skip-gram和CBOW模型,后者基于全局词频统计;Word2Vec在小规模数据和相似词识别上表现突出,GloVe在全局语义信息建模上更有效。 -
请介绍一下情感分析(Sentiment Analysis)在NLP中的应用和常见的算法。 情感分析用于识别文本中的情感倾向,常用的算法包括基于机器学习的分类模型、深度学习的卷积神经网络和循环神经网络。
- 介绍一下Transformer模型和它在NLP任务中的作用。 Transformer模型是一种融合自注意力机制的网络结构,在NLP任务中取得了显著成就,例如在机器翻译和语言建模中取代了传统的循环神经网络。
- 解释一下条件随机场(Conditional Random Field,CRF)在命名实体识别任务中的应用原理。CRF是一种概率图模型,通过建模标签序列的条件概率来解决序列标注任务,常用于解决命名实体识别问题,在句子级别解决标注不一致和概率一致性问题。
- 什么是迁移学习(Transfer Learning),在NLP中如何应用?迁移学习是一种机器学习技术,旨在将从一个任务中学到的知识应用到另一个相关任务中。在NLP中,预训练模型(如BERT和GPT)是迁移学习的典型应用。通过在大规模文本数据上进行预训练,这些模型可以通过微调适应特定的NLP任务,如情感分析和问答系统。
- 什么是预训练和微调(Fine-tuning)的过程?预训练是指在大规模数据集上训练一个模型以学习语言的普遍特征,而微调是在特定任务的数据集上对预训练模型进行进一步训练,使模型能够适应特定的应用场景。通过先进行预训练,然后根据目标任务微调,通常能获得比从头训练效果更好的模型。
- 请解释一下字节对编码(Byte Pair Encoding,BPE)的原理及其在NLP中的作用。BPE是一种常见的子词分词方法,通过反复合并最频繁的字符对来生成子词单元。这种方法能够有效处理OOV(Out-Of-Vocabulary)词,并减少词汇表的大小,使得模型在处理稀有词和新词时更为灵活。BPE被广泛应用于模型如GPT和BERT的输入处理。
- 什么是领域适应(Domain Adaptation)?如何在NLP中实现领域适应?领域适应是一种迁移学习的方法,主要用于解决源领域和目标领域之间的差异。在NLP中,可以通过对源领域数据进行微调增加目标领域数据的训练,或者使用对抗训练等方法,让模型对不同领域的特征具有更好的泛化能力。
- 请讨论如何评估NLP模型的性能,常用的评价指标有哪些?评估NLP模型的性能通常依赖于具体的任务。常用的评价指标包括:
- 对于文本分类:准确率、精确率、召回率和F1得分。
- 对于生成任务:BLEU分数、ROUGE分数等。
- 对于信息抽取任务:准确率和召回率。
- 对于问答系统:EM(Exact Match)和F1得分。
- 介绍一下生成对抗网络(GAN)在NLP中的应用。生成对抗网络(GAN)是一种生成模型,通过两个网络(生成器和判别器)相互对抗进行训练。在NLP中,GAN可以用于生成更自然和流畅的文本,例如在对话生成和文本生成任务中,通过生成器产生候选文本,判别器判断其真实性,促使生成器产生更优质的输出。
- 什么是双向注意力机制,如何在Transformer中实现?双向注意力机制允许模型同时考虑上下文信息,在编码器中,每个位置的输出都依赖于所有输入位置的表示。这通过"自注意力"机制实现,模型通过计算输入序列中每个词的加权和来实现并行化,从而捕捉长程依赖和上下文信息。
- Graph Neural Network(图神经网络)在NLP中的应用有哪些?图神经网络(GNN)可以用于表示文本数据的结构化信息,例如在知识图谱构建、社交网络分析和文本分类等任务中。GNN能够捕捉节点之间的关系,增强信息传播的能力,从而在某些任务上超越传统的序列模型。
- 如何处理NLP中的歧义问题?处理歧义问题可以通过上下文敏感的方法来解决,例如使用BERT等上下文嵌入模型。这些模型根据上下文来动态表示词义,并应用Word Sense Disambiguation(词义消歧)等技术来识别并消除歧义。此外,使用积极的标注数据和精细的规则也可以帮助减轻歧义问题。
- 什么是结构化预测(Structured Prediction),在NLP中有什么应用?结构化预测是指同时预测多个相关输出的任务,例如序列标注和图形标注。NLP中的应用包括句法分析、命名实体识别和文本摘要,它通常依赖于条件随机场(CRF)等模型来考虑输出之间的相关性。
- 请解释索引编码(Index Encoding)在信息检索中的工作原理。索引编码用于有效地存储和检索文本数据。当文档被创建时,系统会将文档的词及其位置索引到倒排索引表中,以便可以迅速根据查询找到相关文档。这种结构化信息存储方法能大幅度提高检索速度和效率,尤其是在大规模数据集上的应用得到广泛认可。
- 如何评估和优化深度学习模型在NLP任务中的表现?评估深度学习模型的表现可以使用交叉验证、混淆矩阵和ROC曲线,选择合适的评估指标(如F1分数、BLEU分数)以反映任务需求。优化方法包括超参数调优(如学习速率、批量大小的选择)、正则化(如Dropout、L2正则化)以及使用合适的优化算法(如Adam、RMSProp)。
- 请描述如何使用集成学习(Ensemble Learning)提高NLP模型的性能。集成学习通过结合多个模型的预测结果来提高最终预测的准确性。在NLP中,可以使用不同类型的模型(如传统机器学习模型与深度学习模型)进行集成,或通过领域知识训练多个基模型,然后通过投票、加权平均或堆叠等技术将模型的输出合并,从而降低过拟合风险并提升模型的整体性能。
- 请讲解“注意力机制”(Attention Mechanism)的原理及其在NLP中的重要性。注意力机制是一种能够动态分配注意力的机制,使模型可以根据当前输入数据的不同部分调整其注意力重点。在NLP中,注意力机制可以帮助模型更好地理解长文本和捕捉重要信息,从而在机器翻译、文本摘要和问答等任务中显著改善表现。
- 什么是文本生成中的“多样性”和“连贯性”之间的权衡?在文本生成中,多样性指生成文本的丰富性和变异性,而连贯性指文本的逻辑性和自然流畅性。优化多样性可能导致生成文本的质量下降,而优化连贯性可能限制表达的多样性。解决这个权衡的问题可以采用惩罚策略、温度控制或使用控制生成内容的条件输入等方法,以实现更好的平衡。
- 在NLP中,如何使用数据增强(Data Augmentation)来提高模型的性能?数据增强是在不增加额外获取训练样本的情况下,提高数据集多样性的方法。在NLP中,可以通过同义词替换、随机插入和回译(使用翻译模型)来生成新的训练样本。这有助于提高模型对数据噪声和变异性的鲁棒性。
- 请阐述BERT的“Masked Language Model”训练目标及其优势。BERT通过“Masked Language Model”训练目标随机掩盖输入中的某些词,然后要求模型预测这些被掩盖的词。该训练目标使BERT能够学习上下文依赖的表征,使模型在处理句子内部和句子间关系时更为有效,进而提高了多个NLP任务的性能。
- 什么是基于图的神经网络(Graph Neural Networks)在NLP中的具体应用?基于图的神经网络在处理具有复杂结构的信息时很有用。在NLP中,GNN可用于学习文本内容与外部知识(如知识图谱)的关系,如在问答、文档分类和推荐系统中,通过建模文本与知识图谱的连接,提高模型理解的准确性。
- 请解释如何使用预训练模型进行迁移学习,以及它的应用实例。迁移学习可通过使用在大规模通用语料上预训练的模型(如BERT、GPT等),然后对特定领域的数据进行微调。举例来说,可以在医学文本数据上微调BERT,以提升模型在医学文献分类或临床决策支持系统中的表现。这种方法能够显著减少训练时间,提高数据稀缺场景的模型效果。
- 如何评价NLP中的模型公平性(Fairness)问题?你认为解决方案有哪些?模型公平性是指在不同人群(如性别、种族等)之间,模型的表现应保持一致性。为解决这一问题,可以采用公平性评估指标(如一般性评估、群体公平性等),以及数据去偏(de-biasing)和算法去偏方法来减少模型在训练过程中的偏见。此外,可以确保多样化的训练数据,以提高模型对不同背景的适应性。
- 请讨论 Word2Vec 和 FastText 之间的区别及各自的优势。Word2Vec 使用固定的词嵌入表示,而 FastText 则通过将词拆分为子词(subword),构建词嵌入。这使得 FastText 能够更好地处理未登录词(OOV)并捕获形态变化(如词根、前后缀等)。因此,FastText 在处理低资源语言和领域特定术语时更具优势。
- 请解释通用语言理解评测(GLUE)和SuperGLUE的目的及其重要性。GLUE 和 SuperGLUE 是用于评估模型在多种NLP任务上理解能力的基准。GLUE包含多种文本理解任务,而SuperGLUE则提出了一些更具挑战性的任务和评价标准。它们的重要性在于为研究人员提供了一种衡量和比较各种NLP模型性能的统一标准,推动了模型在通用语言理解能力上的发展。
- 请解释模型压缩(Model Compression)在NLP中的重要性及其方法。模型压缩是减小深度学习模型大小和提高推理效率的过程,这在NLP中尤为重要,因为许多模型(如BERT、GPT)体积庞大,计算消耗高。常见的压缩方法有剪枝(Pruning)、量化(Quantization)和知识蒸馏(Knowledge Distillation)。通过这些技术,可以在保持模型性能的同时,显著减少存储需求和计算开销,使得模型更适宜部署在移动设备或边缘计算环境中。
- 如何在情感分析中处理否定词(Negation)?否定词对情感分析的影响重大,因为它们可以改变整体情感的方向。处理否定词的方法包括:使用简单的规则(如在含有否定词的句子中反转相邻词的情感分数),或利用上下文的嵌入表示(如BERT)进行情感的上下文计算。更复杂的模型可以引入显式的否定特征,以更好地捕捉情感变化。
- 请讨论自回归模型和自编码模型之间的区别,以及各自适用于哪些任务。自回归模型(如GPT)逐步生成文本,每一步依赖于前一步的输出,适合用于文本生成和语言建模任务。而自编码模型(如BERT)则尝试从整个输入中理解和编码信息,适用于分类和序列标注任务。自回归模型强调生成的连贯性,自编码模型则注重理解的深度和上下文捕捉。
- 问答系统中的信息检索和机器推理有何不同?信息检索(IR)侧重于从大量数据中找到相关的信息和文档,而机器推理则重点在于理解和推导信息间的逻辑关系。在问答系统中,IR用于获取与用户查询相关的文档,而机器推理则帮助系统在已知的信息基础上提供更具逻辑性和准确性的回答。综合两者的模型通常能提高问答系统的整体性能。
- 请解释语义分割(Semantic Segmentation)在NLP中的应用。在NLP中,语义分割通常指对文本的细粒度分析,将文本的每个部分(如单词、短语)与特定的类别或标签相关联。例如,在法律文档分析中,可以将文档中的各个条款、案例等标记为不同的类。通过使用序列标注模型(如CRF或LSTM变体),可以实现高效的文本分割,并帮助用户更好地理解和处理文档内容。
- 如何使用深度学习技术提升命名实体识别(NER)的效果?深度学习技术(如LSTM、BiLSTM和Transformer)通过构建上下文感知的嵌入,能够捕捉到实体前后文本的依赖关系,从而提升NER的效果。此外,通过结合条件随机场(CRF)模型,可以进一步优化标签的序列关系,从而提高整体识别精度。预训练语言模型(如BERT)在NER任务上表现尤为出色,因为它能够在大规模语料上进行上下文学习。
- 请阐述知识图谱(Knowledge Graph)在NLP中的用途及构建方法。知识图谱通过存储实体及其之间的关系,为NLP任务提供背景信息。在问答和推荐系统中,知识图谱能够提供更准确的信息和上下文。构建知识图谱的方法包括信息提取(从文本中提取实体和关系)、图谱链接和知识融合(将来自不同源的知识整合),以及使用图嵌入方法(如TransE、GraphSAGE)来捕捉实体之间的深层关系。
- 请讨论BERT模型中的“位置编码”(Positional Encoding)的作用。由于BERT等Transformer模型不使用循环结构,因此需要位置编码来提供输入序列中词语的位置信息。位置编码通过给每个词添加相应的位置信息,使得模型可以识别输入中各词的位置,从而捕捉到序列数据的顺序关系。这对于理解句子的语法结构和语义至关重要。
- 请阐述文本摘要中的“提取式摘要”(Extractive Summarization)和“抽象式摘要”(Abstractive Summarization)的区别。提取式摘要是通过选择原文中的关键句子或短语来生成摘要,保留源文本的完整性,常用的方法包括文本Rank和TF-IDF等。而抽象式摘要则生成全新句子,合成相关信息,可能涉及重写和重新表述,通常使用生成模型(如Seq2Seq或Transformer)。抽象式摘要更具创造性,但实现难度大,要求模型能够理解上下文和逻辑关系。
- 如何防止NLP模型中的偏见(Bias)问题?偏见问题在NLP中常源于训练数据的偏见。防止模型偏见的方法包括:标注带有多样性和包容性的训练数据,使用去偏算法(如对抗训练),以及在模型训练时引入公平性约束。此外,通过定期审查和评估模型输出,确保其对不同群体保持中立,是实现公平AI的重要步骤。
- 请讨论“生成对抗网络”(GANs)在文本生成中的应用与挑战。生成对抗网络(GANs)通常用于图像生成,但也可以在文本生成中应用,特别是在生成高质量文本或对话系统中。GAN由两个网络(生成器和判别器)组成,生成器尝试创建真实的文本,判别器则区分生成文本和真实文本。挑战在于文本的离散性质使得直接优化生成文本困难,许多研究使用策略梯度方法来解决这一问题,但仍面临生成连贯且语法正确文本的难题。
- 请解释“无监督学习”(Unsupervised Learning)在NLP中的应用。无监督学习在NLP中常用于从未标注数据中提取潜在结构与模式。如聚类算法(如K-means)可用于文本聚类,word embedding(词嵌入)技术能够从语料库中学习词的语义关系。此外,主题建模(例如LDA)通过识别文本中的潜在主题来管理和组织文档,更好地理解大规模文本数据。
- 如何使用迁移学习(Transfer Learning)改善小样本学习在NLP中的应用?迁移学习通过利用大型预训练模型(如GPT、BERT),使得在小样本学习任务中能快速适应。当特定任务的数据量不足时,可以采用在相关任务上进行的预训练,然后对新任务进行微调,利用已有知识以提升模型效果。在小样本场景下,这种方法能够显著提高准确度,降低过拟合风险。
- 探讨NLP中的“上下文意识”(Context Awareness)及其实现方法。上下文意识是指模型在理解和生成语言时能够考虑周围信息。实现方法包括使用上下文嵌入(例如ELMo和BERT)来捕捉每个词在特定上下文中的含义。这种能力在对话系统、个性化助手和文本生成任务中至关重要,因为它帮助模型理解用户意图和回应的适当性。
- 请讲解“多模态学习”(Multimodal Learning)在NLP中的发展与应用。多模态学习是结合不同类型的数据(如图像、文本和音频)进行处理的创新方法。在NLP中,多模态学习可用于理解和生成与视觉信息相关的文本,如图像描述生成。通过将视觉信息与文本处理相结合,模型能够在更丰富的上下文中进行学习,提升生成任务的准确性和相关性。
- 在NLP中,如何评估模型的可解释性(Interpretability)?可解释性评估可以通过多种手段实现,包括使用注意力机制可视化模型关注的输入部分,利用SHAP和LIME等方法解释模型决策背后的因素。可解释性对于确保模型的可靠性和可用性至关重要,尤其是在敏感领域(如医疗和司法)中,使用可解释性工具可以帮助开发者和用户理解模型行为,增加信任度。
相关文章:
50道深度NLP和人工智能领域面试题+答案
编者按:分享一个很硬核的免费人工智能学习网站,通俗易懂,风趣幽默, 可以当故事来看,轻松学习。 什么是自然语言处理(NLP)?自然语言处理是一种人工智能领域,致力于使计算机…...
C卷(JavaPythonC++Node.jsC语言))
最小矩阵宽度(85%用例)C卷(JavaPythonC++Node.jsC语言)
给定一个矩阵,包含N*M个整数,和一个包含K个整数的数组。 现在要求在这个矩阵中找一个宽度最小的子矩阵,要求子矩阵包含数组中所有的整数。 输入描述: 第一行输入两个正整数N,M,表示矩阵大小。 接下来N行M列表示矩阵内容。 下一行包含一个正整数K。 下一行包含K个整数,…...

STM32数据按字符截取与转换
目录 1. 截取2. 转换 1. 截取 以SW,33,55,78,\r\n为例 char* pa,pb,pc,pd,pe; uint8_t usart5_rxsavebuf[] "SW,12,32,33,55,78,\r\n";strtok((char *)usart5_rxsavebuf, ","); pa strtok(NULL, ","); pb strtok(NULL, ","); pc …...

使用kubeadm快速部署一套K8S集群
一、Kubernetes概述 1.1 Kubernetes是什么 Kubernetes是Google在2014年开源的一个容器集群管理系统,Kubernetes简称K8S。 K8S用于容器化应用程序的部署,扩展和管理。 K8S提供了容器编排,资源调度,弹性伸缩,部署管理…...

【Kotlin】在Kotlin项目中使用AspectJ
前言 AOP编程在Java开发中是一个非常火热的话题,最著名的库为AspectJ Kotlin项目中,通过Gradle插件,也能够使用该库,这是我们下面讲解的重点 由于AspectJ的原理是在预编译阶段,通过插件修改代码,生成代理…...
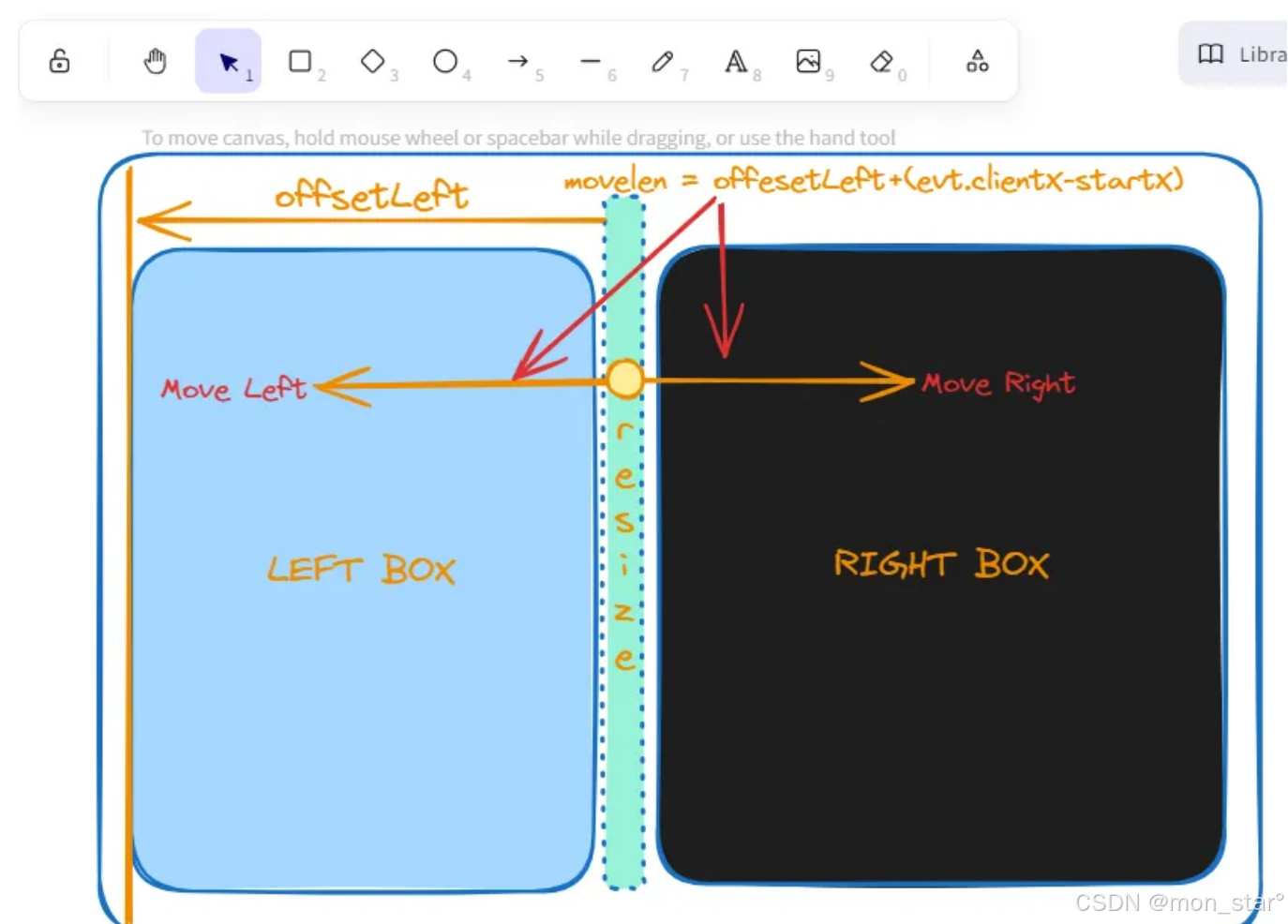
web实现drag拖拽布局
这种拖拽布局功能其实在电脑操作系统或者桌面应用里面是经常使用的基础功能,只是有时候在进行web开发的时候,对这个功能需求量不够明显,但却是很好用,也很实用。能够让用户自己拖拽布局,方便查看某个区域更多内容&…...

Linux网络编程—listen、accept、connect
一、网络四件套 #include <sys/types.h> //头文件;这四个文件一包,基本网络就无问题了; #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> 二、listen 监听:将套…...

logback.xml自定义标签节点
logback.xml自定义标签节点 问题 <?xml version"1.0" encoding"UTF-8" ?> <configuration scan"true" scanPeriod"60 seconds" debug"false"><appender name"console" class"ch.qos.logb…...

探索DevExpress WinForms:.NET世界中的UI库之星
开篇概述 作为一名资深的技术专家,我对.NET开发和UI库有着深入的了解。今天,我要向您介绍的是DevExpress WinForms —— 一款在.NET开发领域广受欢迎的开源UI库。它以其强大的功能、优雅的设计和卓越的性能,成为了众多开发者的首选。 主体讲解…...

零基础学习Redis(4) -- 常用数据结构介绍
我们之前提到过,redis中key只能是字符串类型,而value有多种类型。 redis中的数据结构有自己独特的实现方式能根据特定的场景进行优化 1. string(字符串) 内部编码: raw:最基本的字符串,类比我们平常使用的Stringin…...

Python实现水果忍者(开源)
一、整体介绍: 1.1 前言: 游戏代码基于Python制作经典游戏案例-水果忍者做出一些改动,优化并增加了一些功能。作为自己Python阶段学习的结束作品,文章最后有源码链接。 1.2 Python主要知识: (1…...

Windows自动化3️⃣WindowsPC拽起时长问题解决方案
问题描述: Windows应用从点击, 到加载完成, 需要一定的时间后台是否已经启动过当前程序?启动后, 前后台应用关闭问题等 我的解决思路: 首先检查进程 , 当前进程是否在运行, 如果进程在运行, 需要先关闭进程 关闭进程后, 开始我们的自动化流程, 去拽起 应用 拽起应用后, 可以先…...
)
一篇文章入门Java虚拟机(JVM)
JVM全称是Java Virtual Machine,中文译名Java虚拟机。本质上是一个运行在计算机上的程序 一,JVM的功能 功能描述解释和运行对字节码文件中的指令,实时的解释成机器码,让计算机执行内存管理自动为对象、方法等分配内存࿱…...

vue3里面的组件实例类型(包括原生的html标签类型)
在 通过 ref(null)获取组件的时候,我们想要为 组件标注组件类型,可以通过 any 类型来进行标注,但是很明显,这些的代码很不优雅,所以我们可以利用 vue3 里面的 InstanceType 来进行类型标注 这是…...

谷歌正式开放Imagen 3访问权限!OpenAI的GPT-4o连续两周迎来两次更新!|AI日报
文章推荐 马斯克Grok 2打响反内容限制第一枪,盛大网络狂欢!一起来看网友花式整活! GPT-4o一天迎来2大劲敌!Grok-2发布测试版!Gemini Live即刻上线! 今日热点 OpenAI发布chatgpt-4o-latest AI模型&#…...

C语言内存操作函数
目录 一. C语言内存操作函数 1. memcpy的使用和模拟实现 2. memmove函数 3. memset函数 4. memcmp函数 一. C语言内存操作函数 随着知识的不断积累,我们所想要实现的目标程序就会更加复杂,今天我们来学习一个新的知识叫做C语言内存操作函数&#x…...

深入探索 PyTorch:torch.nn.Parameter 与 torch.Tensor 的奥秘
标题:深入探索 PyTorch:torch.nn.Parameter 与 torch.Tensor 的奥秘 在深度学习的世界里,PyTorch 以其灵活性和易用性成为了众多研究者和开发者的首选框架。然而,即使是经验丰富的 PyTorch 用户,也可能对 torch.nn.Pa…...

成为Python砖家(1): 在本地查询Python HTML文档
目的 Python3 官方文档位于 https://docs.python.org/3/ , 有时候网络无法连接,或者连接速度慢, 这对于学习 Python 时的反馈造成了负面影响。准备一份本地 Python 文档可以让反馈更加及时。 下面给出 macOS 和 Win11 下的 Python 离线文档…...

深度学习基础—RMSprop算法与Adam 优化算法
1.RMSprop算法 1.1.算法流程 除了动量梯度下降法,RMSprop算法也可以加快梯度下降,这个算法的算法流程如下:深度学习基础—动量梯度下降法http://t.csdnimg.cn/zeGRo 1.2.算法原理 和动量梯度下降不同的是,对dW和db的变成了平方项…...

单片机原理及技术(六)—— 中断系统的工作原理
目录 一、AT89S51中断技术概述 二、AT89S51中断系统结构 2.1 中断请求源 2.2 中断请求标志寄存器 2.2.1 TCON 寄存器 2.2.2 SCON 寄存器 三、中断允许与中断优先级的控制 3.1 中断允许寄存器 IE 3.2 中断优先级寄存器 IP 四、响应中断请求的条件 五、外部中断的触发…...

ESXI系统安装全流程详解:从U盘启动到网络配置
1. 制作ESXI系统U盘启动盘 准备一个容量至少8GB的U盘,建议使用USB3.0接口的高速U盘,这样写入速度会快很多。我实测过,用USB2.0的U盘写入一个ESXI镜像可能需要20分钟,而USB3.0通常5分钟就能搞定。 首先需要下载两个关键文件&#x…...

3步实现GitHub资源精准获取:DownGit带来的开发者效率革命
3步实现GitHub资源精准获取:DownGit带来的开发者效率革命 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 在日常开发工作中,每个开发者平均每周需要从GitHub获取3-5次代码资源…...

Z-Image-Turbo-rinaiqiao-huiyewunv实战落地:高校动漫社AI辅助创作工作流搭建
Z-Image-Turbo-rinaiqiao-huiyewunv实战落地:高校动漫社AI辅助创作工作流搭建 1. 项目背景与核心价值 高校动漫社团经常面临创作效率低、人手不足的问题。传统手绘方式需要大量时间,而通用AI绘图工具又难以保持角色一致性。Z-Image Turbo (辉夜大小姐-…...

经典35kW V型磁钢永磁同步电机设计:基于Maxwell的成熟方案解析
基于Maxwell设计的 经典35kW,外径290 轴向长度88 3000RPM,111.5Nm, 6极36槽永磁同步电机(PMSM)设计案例(V型磁钢),该案例已制作样机,方案成熟,运行稳定,可直接用于生产,…...

基于pyqt的规则匹配的恶意代码检测系统
当前的恶意代码检测研究中,尽管传统特征匹配(signature-based detection)仍然广泛应用,但面对快速更新且具有混淆、加壳、动态加载、自变异(polymorphism/metamorphism)等能力的新型恶意代码&am…...

YOLOv8显存溢出?CPU轻量版部署教程让资源占用降低80%
YOLOv8显存溢出?CPU轻量版部署教程让资源占用降低80% 1. 项目背景与价值 你是不是遇到过这样的情况:想用YOLOv8做目标检测,结果一运行就显存溢出,或者GPU资源被占满导致其他程序卡顿?这种情况在资源有限的开发环境中…...

深圳小学数学期末试卷创新题型引热议,数学与文学跨界融合成焦点
1. 当数学题遇上古诗词:深圳试卷创新设计背后的教育逻辑 深圳某区五年级数学期末卷上的一道"跨界题"最近在家长群炸开了锅。题目要求学生分析函数单调性后,将其与《琵琶行》中琵琶女的情感变化对应起来。这种"数学古诗文"的混搭模式…...

MDS vs PCA:哪种降维方法更适合你的数据?
MDS与PCA深度对比:从算法原理到实战选型指南 当面对高维数据时,降维技术就像一把打开数据奥秘的钥匙。在众多降维方法中,多维尺度变换(MDS)和主成分分析(PCA)是最常被比较的两种经典技术。它们都能将复杂的高维数据简化为更易理解的二维或三维…...

别再让传感器‘各走各的时’:5种无线传感网时间同步协议实战对比与选型指南
无线传感网时间同步协议实战指南:从原理到选型的深度解析 在工业物联网和智能环境监测系统中,我们常常遇到这样的场景:分布在厂区各处的振动传感器记录着设备运行状态,但当工程师调取数据时,却发现各节点的时间戳存在…...

Windows音频路由终极指南:如何免费实现应用程序级音频设备管理
Windows音频路由终极指南:如何免费实现应用程序级音频设备管理 【免费下载链接】audio-router Routes audio from programs to different audio devices. 项目地址: https://gitcode.com/gh_mirrors/au/audio-router 你是否曾遇到过这样的困扰:在…...