c语言开源库之uthash用法
目录
(1)uthash介绍和下载地址
(2)uthash基本用法
1.定义自己要使用的哈希表结构体
2.初始化哈希表的头指针
3.插入数据(不同key类型对应不同函数)
4.查找数据(不同key类型对应不同函数)
5.获取键值对个数
6.排序
7.遍历
8.删除
(3)不同类型key值的uthash用法
1.字符串数组作为key
2.指针作为key
3.结构体作为key
(4)注意事项
插入元素时是重复key怎么办
删除数据时注意事项
(1)uthash介绍和下载地址
uthash是C的比较优秀的开源代码,它实现了常见的hash操作函数,例如查找、插入、删除等。该套开源代码采用宏的方式实现了hash函数的相关功能,支持c语言的任意数据结构作为key值(可以是基本类型,也可以是自定义的struct),甚至可以采用多个值作为key。
uthash使用所需文件:由于该代码采用宏的方式实现,所有的实现代码都在uthash.h文件中,因此只需要在自己的代码中包含该头文件即可。
uthash头文件下载地址:https://github.com/troydhanson/uthash
(2)uthash基本用法
1.定义自己要使用的哈希表结构体
如下所示,必须是结构体。
结构体可以有任意个成员,比如这里有4个成员。
变量名字也可以随便取。结构体名字也可以随便取,比如这里为Hash。
但是要包含UT_hash_handle hh这个成员,必须要有。不用对它赋值,就像下面这样就行。
后面我们会理解到,value就是这个结构体,key可以为这个结构体中的任意一种成员。
#include "uthash.h"#define NAME_LEN 10typedef struct {int id;int age;int grade;char name[NAME_LEN];UT_hash_handle hh;
} Hash;2.初始化哈希表的头指针
初始化自己需要使用的哈希表,像下面这样(推荐用全局变量)
Hash *hashHead = NULL;注意必须初始化为NULL,UTHash会根据指针是否为NULL进行判断是否需要初始化。
这里的hashHead指针叫做哈希表指针,类似于链表的头指针。
hashHead => key-value结构体 => key-value结构体 => key-value结构体3.插入数据(不同key类型对应不同函数)
假设key类型为int,用HASH_ADD_INT
Hash *data = (Hash *)malloc(sizeof(Hash));data->id = 1;data->age = 18;data->grade = 100;strcpy(data->name, "tom");HASH_ADD_INT(hashHead, id, data);其中第一个参数为哈希表指针,第二个参数为哈希表结构体中的某个成员名,要将哪个成员作为key,就填哪个,第三个参数是value,为哈希表结构体指针。
4.查找数据(不同key类型对应不同函数)
假设key类型为int,用HASH_FIND_INT
Hash *findRet = NULL;int key = 1;HASH_FIND_INT(hashHead, &key, findRet);if (findRet != NULL) {printf("%s\n", findRet->name);}第一个参数为哈希表指针,第二个参数为待查找key的地址,第三个参数为传出参数,即查找到的value,找不到的话为NULL。
5.获取键值对个数
用HASH_COUNT
int count = HASH_COUNT(hashHead);printf("%d\n", count);6.排序
使用HASH_SORT,实现对哈希表中的元素排序。以下是先按照成绩降序,再年龄升序,再id升序排序的例子
int CmpFunc(Hash *a, Hash *b)
{/* 排序比较函数:返回值小于0表示不交换a和b,即升序 返回值小于0表示交换a和b,即降序*/if (a->grade != b->grade) {return b->grade - a->grade;}if (a->age != b->age) {return a->age - b->age;}return a->id - b->id;
}HASH_SORT(hashHead, CmpFunc);7.遍历
使用HASH_ITER,实现对哈希表中元素的遍历
Hash *curr = NULL;Hash *next = NULL;HASH_ITER(hh, hashHead, curr, next) {if (curr != NULL) {printf("curr grade=%d\n", curr->grade);}if (next != NULL) {printf("next grade=%d\n", next->grade);}}curr和next这里是传出参数。
curr是遍历到的元素,next是curr的下一个元素。一般关注curr即可。
注意当curr为最后一个键值对时,next将会为NULL。
8.删除
使用HASH_DEL,实现对哈希表中元素的删除。
注意这里需要先找到哈希表中的目标元素,然后利用HASH_DEL进行删除,注意只是从哈希表中删除,然后再利用free进行内存回收。
Hash *value = NULL;int boy_id = 1;HASH_FIND_INT(hashHead, &boy_id, value);if (value != NULL) {HASH_DEL(hashHead, value);free(value);}
如果要对哈希表中的全部元素删除,可遍历结合使用HASH_DEL
Hash *curr = NULL;Hash *next = NULL;HASH_ITER(hh, hashHead, curr, next) {HASH_DEL(hashHead, curr);free(curr);}(3)不同类型key值的uthash用法
不同类型key时,插入数据和查找数据的函数将会不同,其余基本还是相同的。
1.字符串数组作为key
比如哈希结构体Hash中成员chae name[10]
// 设计一个数据Hash *data = (Hash *)malloc(sizeof(Hash));data->id = 1;data->age = 18;data->grade = 100;strcpy(data->name, "tom");// 以name作为key进行插入HASH_ADD_STR(hashHead, name, data);// 查找Hash *findRet = NULL;char boy_name[] = "tom";HASH_FIND_STR(hashHead, boy_name, findRet);if (findRet != NULL) {printf("%s\n", findRet->name);}2.指针作为key
示例代码如下,注意查找时是传入指针的地址
#include <stdio.h>
#include <string.h>#include "uthash.h"#define NAME_LEN 10typedef struct {void *key;int id;int age;int grade;char name[NAME_LEN];UT_hash_handle hh;
} Hash;Hash *hashHead = NULL;int main()
{ // 某个值int *index = (int *)malloc(sizeof(int));*index = 99;// 设计一个数据Hash *data = (Hash *)malloc(sizeof(Hash));data->key = index;data->id = 1;data->age = 18;data->grade = 100;strcpy(data->name, "tom");// 以指针作为key进行插入HASH_ADD_PTR(hashHead, key, data);// 查找Hash *findRet = NULL;HASH_FIND_PTR(hashHead, &index, findRet); // 注意这里需要 &index if (findRet != NULL) {printf("%s\n", findRet->name);}return 0;
}3.结构体作为key
插入用HASH_ADD,与之前相比,多了两个参数,一个句柄hh,一个结构体大小
查找用HASH_FIND,与之前相比,多了两个参数,一个句柄hh,一个结构体大小
示例代码如下
#include <stdio.h>
#include <string.h>#include "uthash.h"#define NAME_LEN 10typedef struct {int id;int age;int grade;} KeyStruct;typedef struct {KeyStruct key;char name[NAME_LEN];UT_hash_handle hh;
} Hash;Hash *hashHead = NULL;int main()
{ // 设计一个数据Hash *data = (Hash *)malloc(sizeof(Hash));data->key.age = 18;data->key.grade = 100;data->key.id = 1;strcpy(data->name, "tom");// 以结构体作为key进行插入HASH_ADD(hh, hashHead, key, sizeof(KeyStruct), data);// 查找Hash *findRet = NULL;HASH_FIND(hh, hashHead, data, sizeof(KeyStruct), findRet);if (findRet != NULL) {printf("%s\n", findRet->name);}return 0;
}(4)注意事项
插入元素时是重复key怎么办
当使用 HASH_ADD_INT(或类似的 HASH_ADD 宏,但指定了整数类型作为键)向 uthash 哈希表中添加元素时,如果哈希表中已经存在一个具有相同键(key)的元素,那么新元素不会替换旧元素,而是会导致未定义行为(undefined behavior, UB)。
uthash 库没有提供直接的机制来更新已存在的键的值,它主要设计用于插入新元素和查找元素。如果你尝试使用相同的键插入一个新元素,而该键已经存在于哈希表中,uthash 不会自动合并或更新旧元素。相反,它可能会破坏哈希表的内部结构,导致数据损坏、内存泄漏或程序崩溃等问题。
如果你需要更新哈希表中已存在元素的值,你应该首先使用 HASH_FIND_INT(或相应的查找宏)来查找该元素。如果找到了,你可以直接修改该元素的值。如果没有找到,你可以使用 HASH_ADD_INT 来插入新元素。
下面是一个简单的示例,展示了如何安全地更新哈希表中已存在元素的值:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "uthash.h" typedef struct { int id; // 假设这是我们的键 int value; // 我们要更新的值 UT_hash_handle hh;
} HashElement; HashElement *hashHead = NULL; void update_or_add_element(int id, int newValue) { HashElement *element; HASH_FIND_INT(hashHead, &id, element); if (element != NULL) { // 如果元素已存在,则更新其值 element->value = newValue; } else { // 如果元素不存在,则创建并插入新元素 element = malloc(sizeof(HashElement)); if (element == NULL) { fprintf(stderr, "Memory allocation failed\n"); exit(EXIT_FAILURE); } element->id = id; element->value = newValue; HASH_ADD_INT(hashHead, id, element); }
} void free_hash_table()
{HashElement *curr = NULL;HashElement *next = NULL;HASH_ITER(hh, hashHead, curr, next) {HASH_DEL(hashHead, curr);free(curr);}
}int main()
{ // 插入一些初始元素 update_or_add_element(1, 100); update_or_add_element(2, 200); // 尝试更新已存在的元素 // 将id为1的元素的值更新为150 update_or_add_element(1, 150); // 查找并打印更新后的值 HashElement *element;int target_key = 1; HASH_FIND_INT(hashHead, &target_key, element); if (element != NULL) { printf("Value for id 1: %d\n", element->value); // 应该输出 150 } // 释放哈希表中的所有元素free_hash_table(); return 0;
}删除数据时注意事项
如果你尝试传入一个不是哈希表中元素或键的地址来删除数据,那么结果将是未定义的。可能导致程序崩溃、数据损坏、或者无效果等。
为了避免这些问题,你应该始终确保:
- 使用正确的键或指向哈希表中元素的指针来执行删除操作。
- 如果你有指向哈希表中某个元素的指针,并且想要删除它,你应该直接使用该指针(确保它是指向包含
UT_hash_handle成员的结构体的指针)和HASH_DEL宏。 - 如果你只有键的值,你应该先使用查找宏(如
HASH_FIND_INT)来找到对应的元素,然后再使用HASH_DEL宏来删除它。
这里是一个简单的示例,展示了如何正确地删除哈希表中的元素:
#include <stdio.h>
#include <stdlib.h>
#include "uthash.h" typedef struct { int id; char name[50]; UT_hash_handle hh;
} HashElement; HashElement *hashHead = NULL; void delete_element(int id) { HashElement *element; HASH_FIND_INT(hashHead, &id, element); if (element != NULL) { HASH_DEL(hashHead, element); free(element); // 不要忘记释放内存 }
} end
相关文章:

c语言开源库之uthash用法
目录 (1)uthash介绍和下载地址 (2)uthash基本用法 1.定义自己要使用的哈希表结构体 2.初始化哈希表的头指针 3.插入数据(不同key类型对应不同函数) 4.查找数据(不同key类型对应不同函数&a…...

OurTV v3.1.1 — 完全免费,播放流畅的电视直播软件
OurTV是一款专业的魔改大屏版开源电视直播软件,与“我的电视”类似,内含丰富的电视频道,完全免费且无广告,画质清晰,播放流畅,提供良好的观影体验。此外,该软件还提供手机版。 链接:…...

精武杯的部分复现
标红的为答案 计算机手机部分 1、请综合分析计算机和⼿机检材,计算机最近⼀次登录的账户名是?admin 2.请综合分析计算机和⼿机检材,计算机最近⼀次插⼊的USB存储设备串号是?S3JKNX0JA05097Y 3.请综合分析计算机和⼿机检材,谢弘…...

verdaccio搭建npm私服
安装verdaccio npm i verdaccio -g执行命令verdaccio启动私服 verdaccio nrm启动的私 nrm use https://privateservernpm.xxx.com/添加用户 npm adduser --registry https://privateservernpm.xxx.com/发布包到私服 npm publish删除包 npm unpublish <package-nameve…...

oracle的dataguard physical standby转 snapshot standby操作文档
oracle的dataguard physical standby转 snapshot standby操作文档 一 physical standby 转 snapshot 1.1 查看 fast recovery area 是否配置 show parameter db_recovery_file_dest如果未设置或者设置太小,则需要调整 alter system set db_recovery_file_destDAT…...
:网络编程——深入详解 HTTP、HTTPS 及基于 Windows 系统的 C++ 实现)
学懂C++(四十):网络编程——深入详解 HTTP、HTTPS 及基于 Windows 系统的 C++ 实现
目录 一、引言 二、HTTP 协议 1. HTTP 概述 2. HTTP 工作原理 3. HTTP 请求和响应格式 HTTP 请求格式 4. HTTP 状态码 三、HTTPS 协议 1. HTTPS 概述 2. HTTPS 工作原理 四、基于 Windows 系统的 C 实现 1. 准备工作 2. HTTP 客户端实现 示例代码 3. HTTPS 客户…...

Element-06.案例
一.目标 实现下面这个页面,表格中的数据使用axois异步加载数据 二.实现步骤 首先在vue项目的views文件夹中新建一个tlias文件夹,用来存储该案例的相关组件。员工页面组件(EmpView.vue)和部门页面组件(DeptView.vue&…...

Axure高端交互元件库:助力产品与设计
用户体验(UX)和用户界面(UI)设计对于任何产品的成功都至关重要。为了在这个竞争激烈的市场中脱颖而出,设计师和产品开发团队需要依赖强大的工具来创造引人注目且功能丰富的交互界面。下面介绍一款Axure精心制作的"…...
后端开发刷题 | 二叉树的前序遍历
描述 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 数据范围:二叉树的节点数量满足 1≤n≤100 ,二叉树节点的值满足 1≤val≤100,树的各节点的值各不相同 示例 1: 示例1 输入: {1,#,2,3} 返…...

自动化之响应式Web设计:纯HTML和CSS的实现技巧
大家好,我是程序员小羊! 前言 响应式Web设计是一种使Web页面在各种设备和屏幕尺寸下都能良好显示的设计方法。随着移动设备的普及,响应式设计已经成为Web开发中的标准实践。本文将探讨如何使用纯HTML和CSS实现响应式Web设计,覆…...

SolarMarker 正在使用水坑攻击与伪造的 Chrome 浏览器更新进行攻击
在过去的三个月里,eSentire 的安全研究团队发现信息窃密恶意软件 SolarMarker 都没有发动攻击,却在最近忽然重返舞台。此前,SolarMarker 的运营者使用 SEO 投毒或者垃圾邮件来引诱受害者,受害者试图下载一些文档的免费模板&#x…...

uView的u-notice-bar组件横向滚动不生效问题解决
uView的u-notice-bar组件横向滚动不生效问题解决 此问题导致我换了vant组件的 notice-bar,一度以为是该组件存在bug。uniapp中有vant组件打包小程序又是一个问题,于是乎不得不回来继续折腾uView的u-notice-bar组件,偶然发现css属性animation-…...

基于免疫算法的最优物流仓储点选址方案MATLAB仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 基于免疫算法的最优物流仓储点选址方案MATLAB仿真。 2.测试软件版本以及运行结果展示 MATLAB2022A版本运行 (完整程序运行后无水印) 3…...

基于Java爬取微博数据(三) 微博主页用户数据
基于Java爬取微博数据三 微博主页用户数据 数据分析爬取数据注意点 上一篇文章简单讲述了基于Java爬取微博数据(二),那么这篇将讲述如何基于 Java 爬取微博主页用户数据,下面开始具体的操作。 数据分析 在开始爬取微博主页用户数据之前,我们…...

Openstack 与 Ceph集群搭建(中): Ceph部署
文章目录 一、部署前说明1. ceph 版本选择依据2. ceph网络要求3. 硬件要求 二、部署架构三、部署过程1. 通用步骤2. 部署管理节点创建账号安装Cephadm运行bootstrap 3. 登录Ceph web4. 将其他节点加入集群同步ceph key安装ceph CLI命令行添加主机节点到集群添加OSD节点将监控节…...
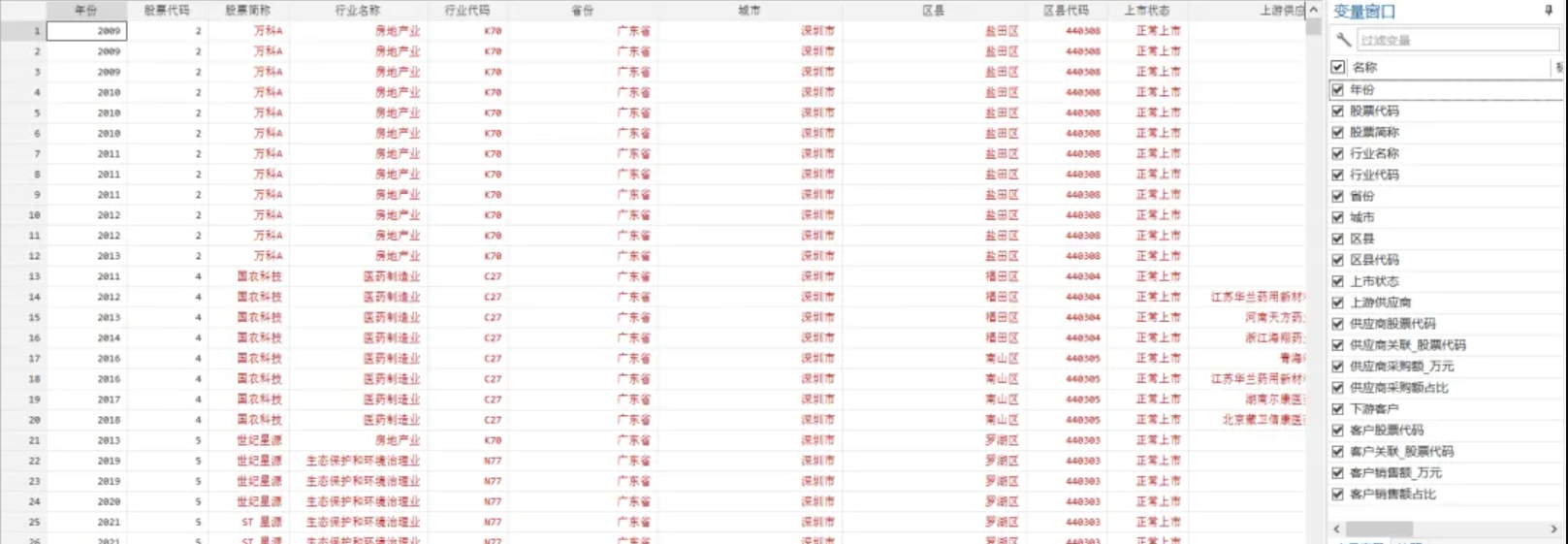
上市公司上下游、客户数据匹配数据集(2001-2023年)
参考《中国工业经济》中陶锋(2023)的做法,对上市公司的上下游供应商和客户数据进行匹配。形成“上游供应商—目标企业—下游客户一年度数据集” 一、数据介绍 数据名称:上市公司-上下游和客户数据匹配 数据范围:上市…...

Promise 对象
Promise 对象是 JavaScript 中用于处理异步操作的一种机制。它代表了一个最终可能完成(fulfilled)或失败(rejected)的异步操作及其结果值。Promise 对象使得异步代码更加容易编写、理解和维护,因为它提供了一种链式调用…...
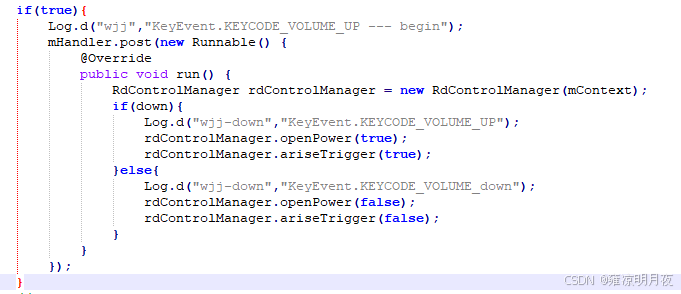
扫码头测试检测适配步骤
需求分析:适配扫码头看是否能正常工作即适配其能否调用相应的节点其能点亮扫码头并进一步获取其扫码的值。 1.首先先检验其串口是否正常通讯。 2.检验扫码头是否正常工作。 3.上电后拉高是否正常操作触发脚拉高其扫码头有无正常点亮。 4.按侧边键是否正常点亮扫…...

解决k8s分布式集群,子节点加入到主节点失败的问题
1.问题情况 Master主节点在 使用 kubeadm init 成功进行初始化后,如下所示 Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/k…...

什么是XSS跨站攻击?如何防护?
什么是XSS跨站攻击?如何防护? 什么是XSS攻击 XSS攻击,即跨站脚本攻击(Cross-Site Scripting),是一种常见的网络安全威胁。其本质是通过在网页中注入恶意的脚本代码,当其他用户浏览这些网页时&…...

SenseNova-SI-1.5:8B参数大模型空间智能新突破
SenseNova-SI-1.5:8B参数大模型空间智能新突破 【免费下载链接】SenseNova-SI-1.5-InternVL3-8B 项目地址: https://ai.gitcode.com/SenseNova/SenseNova-SI-1.5-InternVL3-8B 导语 SenseNova-SI-1.5-InternVL3-8B大模型正式发布,以8B轻量化参数…...

盈鹏飞T527评估板AHD摄像头实战:从硬件连接到QT界面调试全流程
盈鹏飞T527评估板AHD摄像头全流程开发指南:从硬件对接到QT界面优化 在嵌入式视觉系统开发中,AHD摄像头因其长距离传输优势成为安防、工业检测等场景的首选。盈鹏飞T527评估板搭载全志T527处理器,通过TP2815转换板实现四路AHD摄像头接入&#…...

收藏!小白程序员必看:5大AI Agent框架深度解析,助你轻松入门大模型时代!
2026年,GitHub上AI Agent相关项目星标总量已突破500万。但大多数团队在选型时只看星星数,结果花3个月踩坑才明白——框架没有最好,只有最合适。今天我们不吹不黑,从架构哲学、学习曲线、生产成熟度、多Agent协作、长任务支持、可观…...

东方电机RS485嵌入式协议库:多型号统一控制与工业可靠性设计
1. 项目概述OrientalCommon_asukiaaa 是一个专为东方电机(Oriental Motor)RS485通信设备设计的嵌入式通用接口库。该库不直接实现物理层驱动,而是聚焦于协议层抽象与控制逻辑封装,为上层应用提供统一、可移植、符合工业现场总线规…...

OpenClaw安全防护方案:Phi-3-mini-128k-instruct任务执行边界控制
OpenClaw安全防护方案:Phi-3-mini-128k-instruct任务执行边界控制 1. 为什么需要安全防护 当我第一次让OpenClaw接管本地电脑操作权限时,那种既兴奋又忐忑的心情至今记忆犹新。看着AI自动整理文件、发送邮件、执行脚本的同时,一个挥之不去的…...

基于单片机的室内环境监测控制系统的设计与实现
一、系统介绍 本论文针对室内环境监测和控制的需求,设计并实现了一套基于单片机的智能环境监测控制系统。系统包括硬件设计和软件设计两个主要部分。在硬件设计方面,系统涵盖了单片机最小系统、OLED显示屏、按键电路模块、DHT11模块、ESP8266-01s模块和继…...

BD663474车载LCD驱动芯片技术解析与CARIAD集成实践
1. BD663474驱动芯片技术解析:面向CARIAD车载显示系统的TFT-LCD底层控制实现BD663474是ROHM半导体推出的一款专为汽车级TFT-LCD面板设计的源极驱动(Source Driver)与栅极驱动(Gate Driver)集成控制器,广泛应…...

Android学习资源与成长指南
Android学习资源与成长指南 概述 本文将Android开发者的成长路径、学习资源、开源项目、技术社区、推荐书籍和面试准备整合为一份完整指南,覆盖从入门到架构师的全阶段。一、学习路线图:从入门到架构师 1.1 第一阶段:初级开发(0-6…...

无痛人流三天能出门吗?术后出行与身体恢复科学指南
很多女性在无痛人流术后都会关心出行与恢复问题,其中 “无痛人流三天能出门吗” 是高频咨询内容。术后恢复不仅关系到短期舒适度,也影响生殖系统长期健康。结合临床护理经验与行业康复标准,本文对术后出行时机、注意事项及科学修护方式进行客…...

Elsevier投稿状态监控插件:3分钟告别手动刷新的终极解决方案
Elsevier投稿状态监控插件:3分钟告别手动刷新的终极解决方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 你是否每天都要反复登录Elsevier投稿系统,只为查看那迟迟不来的审稿状态…...