《机器学习》—— 通过下采样方法实现银行贷款分类问题
文章目录
- 一、什么是下采样方法?
- 二、通过下采样方法实现银行贷款分类问题
- 三、下采样的优缺点
一、什么是下采样方法?
机器学习中的下采样(Undersampling)方法是一种处理不平衡数据集的有效手段,特别是在数据集中某些类别的样本数量明显多于其他类别时。下采样的主要目的是通过减少多数类样本的数量来平衡数据分布,从而提高模型的泛化能力和准确性。
二、通过下采样方法实现银行贷款分类问题
- 具体步骤:
- 1、读取并查看数据
- 2、数据标准化
- 3、下采样解决样本不均衡问题
- 4、划分数据集
- 5、训练模型并建立最优模型
- 6、传入测试数据集进行测试
- 1、读取并查看数据
-
这里有一份含有**28万+**数据的csv文件
-
通过pandas方法读取此文件
# 通过pandas方法读取creditcard.csv文件,并用data变量接收 data = pd.read_csv("creditcard.csv") data.head() # 查看data的前几行,默认是5行 -
如下图所示:

-
这个数据的最后一列“Class”标签用来标注是否正常,0表示正常,1表示异常
-
我们可以通过画出条形图来观察两类标签的样本个数
import matplotlib.pyplot as plt """绘制条形图,查看正负样本个数""" labels_count = pd.value_counts(data['Class']) plt.title("正负例样本数") plt.xlabel("类别") plt.ylabel("帧数") labels_count.plot(kind='bar') plt.show() -
结果如下:

-
可以看出0和1标签的样本数据个数相差的非常多,0标签有28万+,而1标签只有几百多,这便是不平衡数据集
-
- 2、数据标准化
- 我们数据的倒数第二(Amount)列可以看出,这一列的特征数值,比其他列特征数值要大很多,如果不做调整就传入模型训练,将会占有很大的权重,导致最后的结果很大的程度上都只受这一个特征的影响
- 通过观察,可以发现,前面的特征数据都是在-1~1之间,所以我们可以用Z标准化的方法,改变其数值范围
from sklearn.preprocessing import StandardScaler """数据标准化:Z标准化""" scaler = StandardScaler() # a = data[['Amount']] # 返回dataframe数据,而不是series # 用StandardScaler中的fit_transform实现Z标准化 data['Amount'] = scaler.fit_transform(data[['Amount']]) - 结果如下:

- 3、下采样解决样本不均衡问题
-
通过随机抽取0特征标签中的数据与1特征标签数量相同,并将两个特征拼接为一个新的数据集
# 数据的第一列(Time)没有作用,删除 data = data.drop(['Time'], axis=1) # 删除无用列"""下采样解决样本不均衡问题""" positive_eg = data[data['Class'] == 0] # 获取所有标签(Class)为0的数据 negative_eg = data[data['Class'] == 1] # 获取所有标签(Class)为1的数据 np.random.seed(seed=3) # 随机种子,保证每次执行这个代码,随机抽选的结果都是一样 # positive_eg = positive_eg.sample(len(negative_eg)) # sample 表示随机从参数里面选择数据,并和1标签的数据数量相同 # 拼接数据 data_c = pd.concat([positive_eg, negative_eg]) # 把两个pandas数据组合为一个 -
可以再次通过绘制条形图观察数据
labels_count = pd.value_counts(data_c['Class']) plt.title("正负例样本数") plt.xlabel("类别") plt.ylabel("帧数") labels_count.plot(kind='bar') plt.show() -
结果如下:

-
- 4、划分数据集
- 这里我们划分两类数据集,一类是经过下采样处理后,形成的小部分数据集,另一类是划分原始数据集
- 划分下采样后的数据集用于模型训练,划分原数据集最后传入模型预测出结果,观察模型的性能是否有所提高
from sklearn.model_selection import train_test_split # 对下采样数据划分 x_s = data_c.drop('Class', axis=1) # 去除标签列作为训练数据 y_s = data_c.Class # 得到标签列 # 划分出30%的测试集,并抛出随机种子,为了后面每次的运行,随机划分的都是相同的数据 x_s_train, x_s_test, y_s_train, y_s_test = train_test_split(x_s, y_s, test_size=0.3, random_state=0)# 对原数据划分 x = data.drop('Class', axis=1) y = data.Class x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)
- 5、训练模型并建立最优模型
-
交叉验证选择较优惩罚因子
-
建立最优模型
# 交叉验证选择较优惩罚因子 scores = [] c_param_range = [0.01, 0.1, 1, 10, 100] # 参数 for i in c_param_range: # 第1次循环的时候C=0.01,5个逻辑回归模型lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=1000)score = cross_val_score(lr, x_s_train, y_s_train, cv=8, scoring='recall') # 交叉验证score_mean = sum(score) / len(score) # 交叉验证后的值 召回率scores.append(score_mean) # 存放所有的交叉验证召回率print(score_mean) # 将不同的C参数分别传入模型, 分别看看哪个模型效果更好best_c = c_param_range[np.argmax(scores)] # 找到scores中最大的值对应的C参数 print("........最优惩罚因子为:{}........".format(best_c))"""建立最优模型""" lr = LogisticRegression(C=best_c, penalty='l2', max_iter=1000) lr.fit(x_s_train, y_s_train) -
运行结果为:

-
- 6、传入测试数据集进行测试
-
predict 方法接受一个数组(或类似数组的结构,如列表的列表、Pandas DataFrame等),其中包含了要预测的目标变量的新数据点。然后,它使用训练好的模型对这些数据点进行预测,并返回一个包含预测结果的数组。
-
metrics.classification_report 是 scikit-learn(一个流行的 Python 机器学习库)中的一个函数,用于展示主要分类指标的文本报告。这个函数特别适用于评估分类模型的性能,尤其是在处理多类分类问题时。它提供了每个类别的精确度(precision)、召回率(recall)、F1 分数(F1-score)和支持度(support,即每个类别的真实样本数量)的详细报告。
from sklearn import metrics# 传入下采样后的测试数据 test_s_predicted = lr.predict(x_s_test) print(metrics.classification_report(y_s_test, test_s_predicted))# 传入原数据的测试数据 test_predicted = lr.predict(x_test) print(metrics.classification_report(y_test, test_predicted)) -
结果如下:

-
下面是未使用下采样方法,使用原数据进行模型训练后的结果

-
对比两次不同数据训练出的结果可以看出,通过下采样的方法处理数据后可以大大提高模型的性能
-
三、下采样的优缺点
- 优点:
- 提升分类器准确率:通过减少多数类样本的数量,使得数据集中不同类别的样本数量更加均衡,从而有助于提升分类器对少数类样本的识别能力,进而提升整体分类准确率。
- 降低训练时间:由于数据集的大小减少,模型的训练时间也会相应缩短。
- 降低过拟合风险:减少多数类样本的数量可以降低模型对多数类样本的过度拟合,提高模型的泛化能力。
- 缺点:
- 降低数据集代表性:随机欠采样可能会剔除一些重要的多数类样本,导致数据集的代表性降低。这可能会影响模型的性能,特别是当被剔除的样本包含对分类任务至关重要的信息时。
- 信息损失:由于剔除了部分多数类样本,数据集中的信息量也会相应减少。这可能会导致模型在训练过程中无法充分学习到多数类的特征分布,从而影响模型的性能。
相关文章:
《机器学习》—— 通过下采样方法实现银行贷款分类问题
文章目录 一、什么是下采样方法?二、通过下采样方法实现银行贷款分类问题三、下采样的优缺点 一、什么是下采样方法? 机器学习中的下采样(Undersampling)方法是一种处理不平衡数据集的有效手段,特别是在数据集中某些类…...

Synchronized重量级锁原理和实战(五)
在JVM中,每个对象都关联这一个监视器,这里的对象包含可Object实例和Class实例.监视器是一个同步工具,相当于一个凭证,拿到这个凭证就可以进入临界区执行操作,没有拿到凭证就只能阻塞等待.重量级锁通过监视器的方式保证了任何时间内只允许一个线程通过监视器保护的临界区代码. …...

linux常用网络工具汇总三
linux常用网络工具汇总 6. 抓包工具6.1 wireshark安装界面介绍使用过滤器TCP协议示例关于wireshark的缺点 6.2 tcpdump命令格式关键字使用关于tcpdump的缺点 6.3 fiddler6.4 burpsuite 6. 抓包工具 6.1 wireshark Wireshark(前称Ethereal)是一个网络封…...

Linux中nano编辑器详解
nano 是一个简单的文本编辑器,通常预装在大多数 Linux 发行版中。它非常适合初学者使用,因为它有一个用户友好的界面和易于理解的命令集。下面是对 nano 编辑器的详细说明。 启动 nano 要启动 nano 并打开一个文件进行编辑,你可以在终端中输…...

26-vector arraylist和linkedlist的区别
Vector, ArrayList, 和 LinkedList 是Java中常见的三种列表实现,它们各自具有不同的特点和适用场景。 同步性与线程安全: Vector 是同步的,即线程安全的,它的所有方法都是同步的,可以由两个线程安全地访问…...

20-redis穿透击穿雪崩
Redis中的缓存穿透、缓存击穿和缓存雪崩是三种常见的缓存问题: 缓存穿透:指缓存和数据库中都没有的数据,但用户还是源源不断地发起请求,导致每次请求都会直接访问数据库,从而可能压垮数据库。缓存击穿&…...

Docker使用教程
Docker 名词解释 镜像(image):Docker镜像就是一个模板,可以通过这个模板来创建容器服务。容器(container):Docker利用容器技术,独立运行一个或者一组应用,通过镜像创建…...

poi-tl循环放图片+文字说明
这几天有个任务,服务端导出word要求从数据库取到多张图片,然后输出到word中,并且说明一共几张,当前是第几张。 网上翻了很久也没有找到示例,不过最终难题还是得到了攻克。 因为之前的代码是有一个导出的map,…...

数据结构之树的存储结构
一、顺序存储结构 顺序存储结构通常用于表示完全二叉树。在这种存储方式中,树中的节点被存储在一个连续的数组中。对于完全二叉树,如果父节点的索引是i(假设从0开始计数),那么它的左子节点的索引是2i1,右子…...

Zotero 常用插件介绍
1. Zotero 插件安装方法 下载以 .xpi 结尾的插件;打开 Zotero → 工具 → 插件 → 右上小齿轮图标 → Install Add-on From File ... → 选择下载好的 .xpi 插件安装 → 重启 Zotero 2. 常用插件介绍 2.1. Scholaread - 靠岸学术 Zotero 英文文献相关插件…...

WebSocket协议解析
文章目录 一、HTTP协议与HTTPS协议1.HTTP协议的用处2.HTTP协议的特点3.HTTP协议的工作流程4.HTTPS协议的用处5.HTTPS协议的特点6.HTTPS协议的工作流程 二、WebSocket协议出现的原因1. 传统的HTTP请求-响应模型2. 轮询(Polling)3. 长轮询(Long…...

ES6 (一)——ES6 简介及环境搭建
目录 简介 环境搭建 可以在 Node.js 环境中运行 ES6 webpack 入口 (entry) loader 插件 (plugins) 利用 webpack 搭建应用 gulp 如何使用? 简介 ES6, 全称 ECMAScript 6.0 ,是 JavaScript 的下一个版本标准,2015.06 发版…...

HarmonyOS开发案例:列表场景实例-TaskPool
介绍 本实例通过列表场景实例讲解,介绍在TaskPool线程中操作关系型数据库的方法,涵盖单条插入、批量插入、删除和查询操作。 效果图预览 使用说明 进入页面有insert(单条数据插入)、batch insert(批量数据插入)、query(查询操作)三个按钮,…...

谷歌浏览器如何隐藏书签
谷歌浏览器的书签栏是一个极为方便的功能,它能够帮助用户快速访问自己频繁使用的网页。然而,有些时候为了保护个人隐私或使浏览界面更为简洁,我们可能需要隐藏书签栏。接下来就为大家分享如何隐藏谷歌浏览器的书签栏,一起来看看吧…...

SQL - 视图
我们可以把查询或子查询存到视图里,视图的作用就像一张虚拟表,再次查询时,就不需要再写一次复杂的查询。创建视图 create view 视图名 as (查询); create or replace view clients_balance as (查询); create or replace view clients_balanc…...

centos7环境升级默认的gcc 4.8.5到gcc 8.2.0, 并且升级glibc到glibc 2.28
这里写目录标题 makegccglibc make #下载 wget http://ftp.gnu.org/gnu/make/make-4.2.tar.gz tar -xf make-4.2.tar.gz cd make-4.2 ./configure make -j4 make install mv /usr/bin/make /usr/bin/make_bak cp ./make /usr/bin/make -v GNU Make 4.2 Built for x86_64-pc-li…...
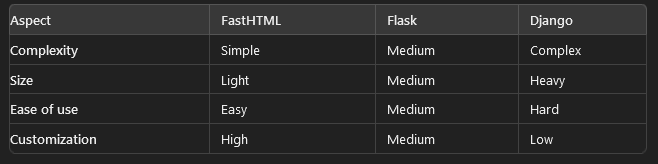
FastHTML:使用 Python 彻底改变 Web 开发
什么是 FastHTML?🌐 FastHTML 是一个现代 Python Web 应用程序框架,其真正目的是让 Python 开发人员轻松进行 Web 开发。它大大减少了对 JavaScript 和 CSS 构建交互式和可扩展 Web 应用程序的依赖。FastHTML 通过使用 Python 对象来表示 HTM…...

快速排序的深入优化探讨
快排性能的关键点分析 决定快排性能的关键点是每次单趟排序后,key对数组的分割,如果每次选key基本⼆分居中,那么快排的递归树就是颗均匀的满⼆叉树,性能最佳。但是实践中虽然不可能每次都是⼆分居中,但是性能也还是可…...
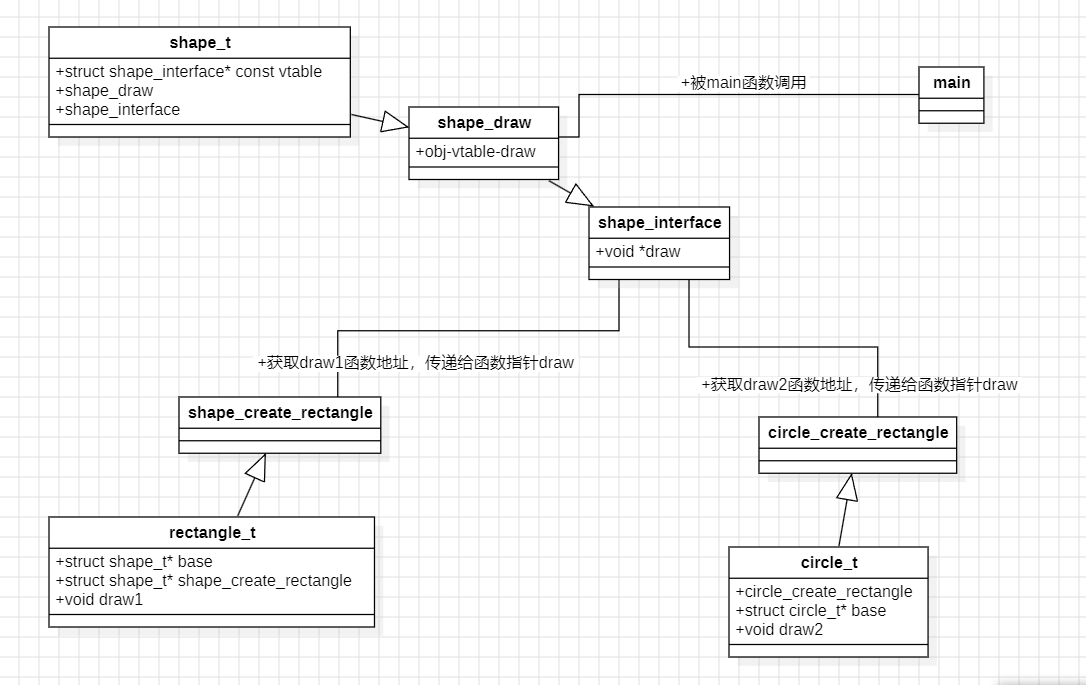
c语言杂谈系列:模拟虚函数
从整体来看,笔者的做法与之前的模拟多态十分相似,毕竟c多态的实现与虚函数密切相关 废话少说,see my code: kernel.c#include "kernel.h" #include <stdio.h>void shape_draw(struct shape_t* obj) {/* Call dr…...
短视频推广App不再难!Xinstall来帮忙
在短视频风靡的今天,如何利用这一热门媒介有效推广App,成为了许多推广者关注的焦点。而Xinstall,作为国内专业的App全渠道统计服务商,正是你解决这一难题的得力助手。 首先,Xinstall在数据维度上的优势无可比拟。它能…...

InsForge:基于Python的Instagram内容自动化创作与发布工具全解析
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫InsForge。这名字听起来有点“工业锻造”的味道,实际上,它是一个专注于Instagram内容创作与自动化的工具集。简单来说,它试图帮你解决在Instagram上创作、发布、管理内容…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

终极FGO自动化助手:告别枯燥刷本,每天节省3小时游戏时间
终极FGO自动化助手:告别枯燥刷本,每天节省3小时游戏时间 【免费下载链接】FGA Auto-battle app for F/GO Android 项目地址: https://gitcode.com/gh_mirrors/fg/FGA Fate/Grand Automata(简称FGA)是一款专为Fate/Grand Or…...

Arm Cortex-X2/X3架构解析与性能优化实践
1. Arm Cortex-X2/X3集群架构概述在Armv9架构的高性能计算领域,Cortex-X2和X3代表了当前最先进的CPU设计理念。作为DynamIQ共享单元(DSU)的核心组件,它们通过可配置的缓存层次结构和智能一致性协议,为现代异构计算提供了灵活的解决方案。1.1 …...

DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具
DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的免费开源工具,专为PC游戏玩家设计,能够智能管理、…...

如何轻松管理Switch游戏:NS-USBLoader完整指南,三步搞定游戏安装与系统引导
如何轻松管理Switch游戏:NS-USBLoader完整指南,三步搞定游戏安装与系统引导 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址…...

量化交易强化学习环境TradingGym:从Gym接口到实战策略训练
1. 项目概述:一个为量化交易策略量身定制的强化学习训练场如果你正在尝试将强化学习(Reinforcement Learning, RL)应用到股票、期货或加密货币的量化交易中,大概率会遇到一个共同的困境:环境太难搭了。市面上的回测框架…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...

WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南
WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争…...