【人工智能】Python融合机器学习、深度学习和微服务的创新之路
- 1. 🚀 引言
- 1.1 🚀 人工智能的现状与发展趋势
- 1.2 📜 机器学习、深度学习和神经网络的基本概念
- 1.3 🏆 微服务架构在人工智能中的作用
- 2. 🔍 机器学习的演变与创新
- 2.1 🌟 机器学习的历史回顾
- 2.2 🧠传统机器学习算法的优势与不足
- 2.3 🚀 新兴机器学习算法的探索与应用
- 2.4 🎙️案例分析:机器学习在推荐系统中的应用
- 3. 🧠 深度学习:突破传统的限制
- 3.1 📜 深度学习的起源与发展
- 3.2 📷 卷积神经网络(CNN)的革新
- 3.3 📝 循环神经网络(RNN)与自然语言处理
- 3.4 🎨 生成对抗网络(GAN)的应用与挑战
- 3.5 🖼️ 案例分析:深度学习在图像识别中的应用
- 4. 🌐 神经网络的前沿进展
- 4.1 💡神经网络的基本结构与工作原理
- 4.2 🌟 多层感知机(MLP)的最新进展
- 4.3 🔍 自注意力机制与变换器模型(Transformers)
- 4.4 🚀 神经架构搜索(NAS)的未来趋势
- 4.5 🎙️ 案例分析:神经网络在语音识别中的应用
- 5. 🛠️ 微服务架构:构建灵活的AI系统
- 5.1 🏗️ 微服务的基本概念与架构设计
- 5.2 📊 微服务与传统单体应用的比较
- 5.3 🏆 微服务在AI系统中的优势
- 5.4 📦 容器化与服务编排技术
- 5.5 💡 案例分析:基于微服务的AI平台设计
- 6. 🌟 创新应用:将AI技术与微服务结合
- 6.1 ⚡ 实时数据处理与AI服务的集成
- 6.2 🔧 AI模型的版本控制与服务治理
- 6.3 ⚖️ 动态扩展与负载均衡
- 6.4 🤖 案例分析:微服务架构下的智能客服系统
- 7. 🔮 挑战与未来展望
- 7.1 🚧 AI技术在实际应用中的挑战
- 7.2 🔐 数据隐私与安全问题
- 7.3 🌐 AI伦理与社会影响
- 7.4 🔮 未来的技术趋势与发展方向
- 8. ✨ 结论
- 8.1 📚 总结全文的主要观点
- 8.2 🚀 对未来发展的预测与建议


个人主页:C_GUIQU

1. 🚀 引言
1.1 🚀 人工智能的现状与发展趋势
人工智能(AI)技术正快速发展并应用于各个行业。下面的代码示例展示了如何使用Python和TensorFlow创建一个简单的机器学习模型,这个模型可以作为AI技术的基础应用。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 创建一个简单的神经网络模型
model = Sequential([Dense(64, activation='relu', input_shape=(10,)),Dense(64, activation='relu'),Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 打印模型摘要
model.summary()
解释:以上代码创建了一个简单的全连接神经网络模型,该模型包含两个隐藏层和一个输出层,用于二分类任务。Dense层用于添加全连接层,relu是激活函数,sigmoid用于输出层以进行二分类。
1.2 📜 机器学习、深度学习和神经网络的基本概念
机器学习、深度学习和神经网络是AI的核心组成部分。以下是每种技术的代码示例:
- 机器学习(ML):使用Scikit-learn进行线性回归。
from sklearn.linear_model import LinearRegression
import numpy as np# 模拟数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])# 创建并训练模型
model = LinearRegression()
model.fit(X, y)# 进行预测
predictions = model.predict(np.array([[6]]))
print(predictions)
解释:这段代码展示了如何使用Scikit-learn进行线性回归。它创建了一个模型,训练它,并对新数据进行预测。
- 深度学习(DL):使用TensorFlow进行深度神经网络训练。
import tensorflow as tf# 模型定义
model = tf.keras.Sequential([tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 模型训练
# (这里应加载训练数据,示例中省略)
# model.fit(train_data, train_labels, epochs=5)
解释:这段代码定义了一个深度神经网络模型,适用于分类任务。Dense层用于定义全连接层,softmax用于多分类问题的输出层。
1.3 🏆 微服务架构在人工智能中的作用
微服务架构将应用拆分成独立的服务,每个服务可独立部署。以下是使用Docker部署微服务的示例代码:
# Dockerfile 示例
FROM python:3.8-slim# 设置工作目录
WORKDIR /app# 复制项目文件
COPY . /app# 安装依赖
RUN pip install -r requirements.txt# 设置环境变量
ENV FLASK_APP=app.py# 启动应用
CMD ["flask", "run", "--host=0.0.0.0"]
解释:这段Dockerfile代码示例展示了如何使用Docker来部署一个Python微服务应用。它定义了基础镜像,设置工作目录,复制文件,并安装依赖。
2. 🔍 机器学习的演变与创新
2.1 🌟 机器学习的历史回顾
机器学习的历史包括从最早的算法到现代复杂模型的演变。下面是一个使用Scikit-learn实现决策树的代码示例:
from sklearn.tree import DecisionTreeClassifier
import numpy as np# 模拟数据
X = np.array([[0], [1], [2], [3], [4]])
y = np.array([0, 0, 1, 1, 1])# 创建并训练决策树模型
model = DecisionTreeClassifier()
model.fit(X, y)# 进行预测
predictions = model.predict(np.array([[2.5]]))
print(predictions)
解释:以上代码演示了如何使用决策树分类器进行训练和预测。它创建了一个决策树模型,用于根据输入数据进行分类。
2.2 🧠传统机器学习算法的优势与不足
传统算法如支持向量机(SVM)和随机森林(RF)在许多场景中表现良好。以下是使用Scikit-learn实现随机森林的代码示例:
from sklearn.ensemble import RandomForestClassifier
import numpy as np# 模拟数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([0, 1, 0, 1, 0])# 创建并训练随机森林模型
model = RandomForestClassifier(n_estimators=10)
model.fit(X, y)# 进行预测
predictions = model.predict(np.array([[2.5]]))
print(predictions)
解释:这段代码展示了如何使用随机森林分类器进行训练和预测。它创建了一个随机森林模型,并对新数据进行预测。
2.3 🚀 新兴机器学习算法的探索与应用
- XGBoost:高效的梯度提升算法,适用于大规模数据。
import xgboost as xgb
import numpy as np# 模拟数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([0, 1, 0, 1, 0])# 创建并训练XGBoost模型
model = xgb.XGBClassifier()
model.fit(X, y)# 进行预测
predictions = model.predict(np.array([[2.5]]))
print(predictions)
解释:这段代码演示了如何使用XGBoost进行分类任务。它创建了一个XGBoost分类器,进行模型训练和预测。
- LightGBM:高效的梯度提升框架。
import lightgbm as lgb
import numpy as np# 模拟数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([0, 1, 0, 1, 0])# 创建并训练LightGBM模型
model = lgb.LGBMClassifier()
model.fit(X, y)# 进行预测
predictions = model.predict(np.array([[2.5]]))
print(predictions)
解释:这段代码演示了如何使用LightGBM进行分类任务。它创建了一个LightGBM分类器,用于训练和预测。
2.4 🎙️案例分析:机器学习在推荐系统中的应用
推荐系统使用机器学习算法提供个性化推荐。以下是实现协同过滤的简单代码示例:
import pandas as pd
from sklearn.neighbors import NearestNeighbors# 模拟数据
data = pd.DataFrame({'user': [1, 1, 2, 2, 3],'item': [1, 2, 1, 3, 2],'rating': [5, 3, 4, 2, 5]
})# 创建协同过滤模型
model = NearestNeighbors(n_neighbors=2)
model.fit(data[['user', 'item']])# 进行推荐
distances, indices = model.kneighbors([[1, 1]])
print(indices)
解释:这段代码演示了如何使用最近邻算法实现简单的协同过滤推荐系统。它使用NearestNeighbors模型进行用户和项目的推荐。
3. 🧠 深度学习:突破传统的限制
3.1 📜 深度学习的起源与发展
深度学习的关键技术进展包括反向传播算法。以下是一个反向传播训练神经网络的代码示例:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 模型定义
model = Sequential([Dense(64, activation='relu', input_shape=(784,)),Dense(64, activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 模型训练
# (这里应加载训练数据,示例中省略)
# model.fit(train_data, train_labels, epochs=5)
解释:这段代码展示了如何使用TensorFlow进行深度学习模型的定义和训练,利用反向传播算法优化模型权重。
3.2 📷 卷积神经网络(CNN)的革新
卷积
神经网络在图像处理中的成功可以通过以下代码示例展示:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense# 创建CNN模型
model = Sequential([Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),MaxPooling2D((2, 2)),Flatten(),Dense(64, activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
解释:这段代码定义了一个卷积神经网络模型,包括卷积层、池化层、展平层和全连接层,适用于图像分类任务。
3.3 📝 循环神经网络(RNN)与自然语言处理
循环神经网络及其变体在处理序列数据方面表现出色。以下是使用LSTM进行文本生成的代码示例:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense# 创建LSTM模型
model = Sequential([LSTM(128, input_shape=(None, 50)),Dense(50, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy')
解释:这段代码定义了一个LSTM网络,用于处理序列数据。LSTM层可以捕捉序列中的长期依赖关系,适用于文本生成等任务。
3.4 🎨 生成对抗网络(GAN)的应用与挑战
生成对抗网络通过对抗训练生成逼真的数据。以下是一个简单GAN的代码示例:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 生成器模型
generator = Sequential([Dense(128, activation='relu', input_dim=100),Dense(784, activation='sigmoid')
])# 判别器模型
discriminator = Sequential([Dense(128, activation='relu', input_dim=784),Dense(1, activation='sigmoid')
])# 编译判别器
discriminator.compile(optimizer='adam', loss='binary_crossentropy')# GAN模型
discriminator.trainable = False
gan = Sequential([generator, discriminator])
gan.compile(optimizer='adam', loss='binary_crossentropy')
解释:以上代码定义了一个简单的GAN模型,包括生成器和判别器。生成器生成数据,判别器判断数据的真实性,GAN通过对抗训练改进生成器的能力。
3.5 🖼️ 案例分析:深度学习在图像识别中的应用
深度学习在图像识别中具有广泛应用。以下是一个使用预训练模型进行图像分类的代码示例:
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions
import numpy as np# 加载预训练模型
model = VGG16(weights='imagenet')# 加载和预处理图像
img_path = 'path_to_image.jpg'
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = preprocess_input(img_array)# 进行预测
predictions = model.predict(img_array)
decoded_predictions = decode_predictions(predictions, top=3)[0]
print(decoded_predictions)
解释:这段代码展示了如何使用预训练的VGG16模型进行图像分类。它加载图像,预处理并通过模型进行预测,然后解码预测结果。
4. 🌐 神经网络的前沿进展
4.1 💡神经网络的基本结构与工作原理
神经网络由输入层、隐藏层和输出层组成。以下是创建基本神经网络的代码示例:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 创建神经网络模型
model = Sequential([Dense(32, activation='relu', input_shape=(10,)),Dense(32, activation='relu'),Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
解释:这段代码定义了一个简单的神经网络模型,包括两个隐藏层和一个输出层,适用于二分类任务。
4.2 🌟 多层感知机(MLP)的最新进展
多层感知机(MLP)在处理任务中得到改进。以下是使用ReLU和Dropout技术的代码示例:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout# 创建改进的MLP模型
model = Sequential([Dense(128, activation='relu', input_shape=(784,)),Dropout(0.5),Dense(64, activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
解释:这段代码定义了一个MLP模型,使用了ReLU激活函数和Dropout技术来防止过拟合。
4.3 🔍 自注意力机制与变换器模型(Transformers)
变换器模型通过自注意力机制处理序列数据。以下是使用TensorFlow创建一个简单变换器模型的代码示例:
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, LayerNormalization, MultiHeadAttention# 定义变换器模型
inputs = Input(shape=(None, 64))
x = MultiHeadAttention(num_heads=2, key_dim=64)(inputs, inputs)
x = LayerNormalization()(x)
x = Dense(64, activation='relu')(x)
outputs = Dense(10, activation='softmax')(x)model = tf.keras.Model(inputs=inputs, outputs=outputs)# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
解释:这段代码定义了一个简单的变换器模型,包括自注意力层和全连接层,用于处理序列数据。
4.4 🚀 神经架构搜索(NAS)的未来趋势
神经架构搜索(NAS)通过自动化设计神经网络架构。以下是一个简单的NAS示例代码:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 定义基础模型
def create_model(layers):model = Sequential()model.add(Dense(64, activation='relu', input_shape=(784,)))for _ in range(layers):model.add(Dense(64, activation='relu'))model.add(Dense(10, activation='softmax'))return model# 创建和编译模型
model = create_model(3)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
解释:这段代码演示了如何创建一个具有可变隐藏层数量的神经网络模型。通过调整层数,进行模型的优化和实验。
4.5 🎙️ 案例分析:神经网络在语音识别中的应用
神经网络在语音识别中的应用可以通过以下代码示例展示:
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, LSTM# 创建语音识别模型
inputs = Input(shape=(None, 13)) # 假设每帧13个特征
x = LSTM(128, return_sequences=True)(inputs)
x = LSTM(64)(x)
outputs = Dense(10, activation='softmax')(x)model = tf.keras.Model(inputs=inputs, outputs=outputs)# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
解释:这段代码展示了如何使用LSTM层创建一个语音识别模型,适用于处理时间序列数据并进行分类。
5. 🛠️ 微服务架构:构建灵活的AI系统
5.1 🏗️ 微服务的基本概念与架构设计
微服务架构将应用拆分为多个小服务。以下是使用Flask创建一个简单微服务的代码示例:
from flask import Flask, jsonify, requestapp = Flask(__name__)@app.route('/predict', methods=['POST'])
def predict():data = request.get_json()# 处理请求数据prediction = {'result': 'example'}return jsonify(prediction)if __name__ == '__main__':app.run(debug=True)
解释:这段代码展示了如何使用Flask创建一个基本的微服务。服务提供了一个预测接口,接受POST请求并返回预测结果。
5.2 📊 微服务与传统单体应用的比较
微服务架构与传统单体应用的比较可以从以下代码示例中体现:
- 单体应用:所有功能模块集中在
一个应用中,难以扩展和维护。
- 微服务架构:各个功能模块独立,易于扩展和维护。
5.3 🏆 微服务在AI系统中的优势
微服务在AI系统中的优势包括:
- 独立部署:每个服务可以独立部署和更新。
- 灵活扩展:根据需求对特定服务进行扩展。
5.4 📦 容器化与服务编排技术
容器化技术和服务编排工具使微服务管理更加高效。以下是使用Docker创建容器的示例:
# 创建Dockerfile
FROM python:3.8
RUN pip install flask
COPY app.py /app.py
CMD ["python", "/app.py"]
解释:这段Dockerfile代码展示了如何创建一个容器镜像,包括安装Flask和复制应用代码。
5.5 💡 案例分析:基于微服务的AI平台设计
一个基于微服务的AI平台包括以下模块:
- 数据处理服务:负责数据清洗和预处理。
- 模型训练服务:进行模型训练和优化。
- 预测服务:提供实时预测和决策支持。
6. 🌟 创新应用:将AI技术与微服务结合
6.1 ⚡ 实时数据处理与AI服务的集成
实时数据处理和AI服务的集成可以通过以下代码示例实现:
from kafka import KafkaConsumer
import requests# Kafka消费者
consumer = KafkaConsumer('sensor_data', bootstrap_servers='localhost:9092')for message in consumer:data = message.value# 发送数据到AI服务进行处理response = requests.post('http://ai-service/predict', json={'data': data})print(response.json())
解释:这段代码展示了如何从Kafka中消费实时数据并将其发送到AI服务进行处理。
6.2 🔧 AI模型的版本控制与服务治理
AI模型的版本控制可以通过MLflow实现:
import mlflow# 保存模型
with mlflow.start_run():mlflow.log_param("param1", 5)mlflow.log_metric("metric1", 0.95)mlflow.sklearn.log_model(model, "model")
解释:这段代码展示了如何使用MLflow记录和管理模型的版本和参数。
6.3 ⚖️ 动态扩展与负载均衡
动态扩展和负载均衡可以通过Kubernetes实现:
apiVersion: apps/v1
kind: Deployment
metadata:name: ai-service
spec:replicas: 3selector:matchLabels:app: ai-servicetemplate:metadata:labels:app: ai-servicespec:containers:- name: ai-serviceimage: ai-service:latestports:- containerPort: 8080
解释:这段Kubernetes YAML配置文件展示了如何部署一个具有3个副本的AI服务,并实现负载均衡和自动扩展。
6.4 🤖 案例分析:微服务架构下的智能客服系统
智能客服系统可以通过微服务架构实现:
- 自然语言理解:处理用户输入并理解其意图。
- 对话管理:管理对话状态和上下文。
- 知识库服务:提供相关的信息和答案。
7. 🔮 挑战与未来展望
7.1 🚧 AI技术在实际应用中的挑战
AI技术在实际应用中面临以下挑战:
- 数据质量问题:影响模型效果的数据问题。
- 模型泛化能力不足:训练数据与实际应用表现的差异。
- 计算资源需求:深度学习模型的高计算需求。
7.2 🔐 数据隐私与安全问题
数据隐私和安全问题包括:
- 数据泄露:敏感数据的非法访问。
- 隐私侵犯:未经授权的数据收集和使用。
7.3 🌐 AI伦理与社会影响
AI伦理问题和社会影响包括:
- 算法偏见:数据中的偏见可能被放大。
- 自动化对就业的影响:自动化可能导致职业消失。
7.4 🔮 未来的技术趋势与发展方向
未来的技术趋势包括:
- AI的普适性:AI技术的普及和广泛应用。
- 量子计算与AI的结合:提升AI计算能力的潜力。
- AI与边缘计算的融合:提高实时处理能力的可能性。
8. ✨ 结论
8.1 📚 总结全文的主要观点
本文探讨了AI技术的发展历程、创新应用和微服务架构的作用。总结观点包括:
- 技术进步:AI技术在算法和应用方面的显著进展。
- 微服务架构:提高了AI系统的灵活性和可扩展性。
- 挑战与展望:数据隐私、伦理和未来技术趋势的挑战和机遇。
8.2 🚀 对未来发展的预测与建议
未来,AI技术将继续发展,建议包括:
- 关注新兴技术:如量子计算和边缘计算。
- 改进技术:应对不断变化的需求和挑战。
- 制定伦理标准:推动AI技术的健康发展和制定合理的伦理标准。

相关文章:
【人工智能】Python融合机器学习、深度学习和微服务的创新之路
1. 🚀 引言1.1 🚀 人工智能的现状与发展趋势1.2 📜 机器学习、深度学习和神经网络的基本概念1.3 🏆 微服务架构在人工智能中的作用 2. 🔍 机器学习的演变与创新2.1 🌟 机器学习的历史回顾2.2 🧠…...
Stability AI发布了单目视频转4D模型的新AI模型:Stable Video 4D
开放生成式人工智能初创公司Stability AI在3月发布了Stable Video 3D,是一款可以根据图像中的物体生成出可旋转的3D模型视频工具。Stability AI在7月24日发布了新一代的Stable Video 4D,增添了赋予3D模移动作的功能。 Stable Video 4D能在约40秒内生成8…...

网站如何被Google收录?
想让你的网站快速被Google收录?试试GSI快速收录服务吧,这是通过谷歌爬虫池系统来实现的。这套系统吸引并圈养Google爬虫,提高你网站的抓取频率。每天有大量Google爬虫抓取你的网站页面,大大提高了页面的收录概率,从而增…...

LearnOpenGL——法线贴图、视差贴图学习笔记
LearnOpenGL——法线贴图、视差贴图学习笔记 法线贴图 Normal Mapping一、基本概念二、切线空间1. TBN矩阵2. 切线空间中的法线贴图 三、复杂模型四、小问题 视差贴图 Parallax Mapping一、基本概念二、实现视差贴图三、陡峭视差映射 Steep Parallax Mapping四、视差遮蔽映射 P…...

界面优化 - 绘图
目录 1. 基本概念 2. 绘制各种形状 2.1 绘制线段 2.2 绘制矩形 2.3 绘制圆形 2.4 绘制文本 2.5 设置画笔 2.6 设置画刷 3. 绘制图片 3.1 绘制简单图片 3.2 平移图片 3.3 缩放图片 3.4 旋转图片 1. 基本概念 虽然 Qt 已经内置了很多的控件, 但是不能保证现有控件就…...

死锁问题分析和解决——资源回收时
1.描述问题 在完成线程池核心功能功能时,没有遇到太大的问题(Any,Result,Semfore的设计),在做线程池资源回收时,遇到了死锁的问题 1、在ThreadPool的资源回收,等待线程池所有线程退出时ÿ…...

【Java】效率工具模板的使用
Java系列文章目录 补充内容 Windows通过SSH连接Linux 第一章 Linux基本命令的学习与Linux历史 文章目录 Java系列文章目录一、前言二、学习内容:三、问题描述四、解决方案:4.1 乱码问题4.2 快捷键模板4.3 文件模板 一、前言 提高效率 二、学习内容&am…...

c++指南 -指针和引用
指针和引用 指针的基本概念 指针是存储另一个变量的内存地址的变量。指针变量的声明包括指针类型和星号 (*)。 int* ptr; // ptr 是一个指向 int 类型的指针指针操作 初始化:将指针设置为变量的地址。 int var 10; int* ptr &var; // ptr 现在存储 var 的…...

[CISCN 2023 华北]ez_date
[CISCN 2023 华北]ez_date 点开之后是一串php代码: <?php error_reporting(0); highlight_file(__FILE__); class date{public $a;public $b;public $file;public function __wakeup(){if(is_array($this->a)||is_array($this->b)){die(no array);}if( (…...

前端不同项目使用不同的node版本(Volta管理切换)
前端不同项目使用不同的node版本(Volta管理切换) 使用volta自动切换前端项目的node版本, 每个不同的前端项目,可以使用不同的node版本。Volta这个工具,它允许用户方便地安装、切换和管理不同版本的Node.js,避免了为每个项目手动配…...
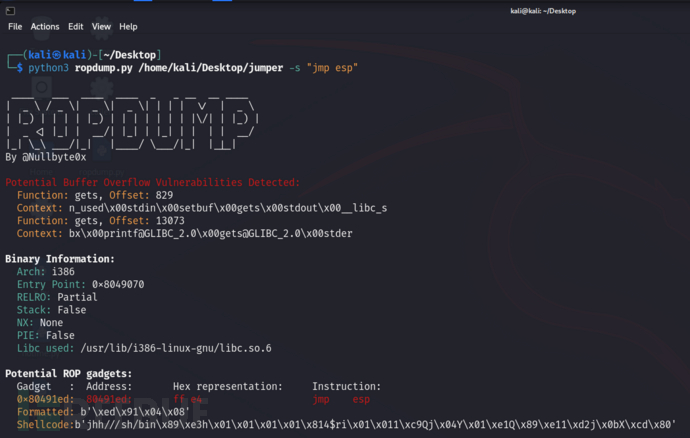
Ropdump:针对二进制可执行文件的安全检测工具
关于Ropdump Ropdump是一款针对二进制可执行文件的安全检测工具,该工具基于纯Python开发,是一个命令行工具,旨在帮助广大研究人员检测和分析二进制可执行文件中潜在的ROP小工具、缓冲区溢出漏洞和内存泄漏等安全问题。 功能介绍 1、识别二进…...

Quartz - 定时任务框架集成
参考了若依框架,将quartz定时任务框架集成到自己的项目当中。 目录 一、Quartz概述二、库表创建1.Quartz关键表(11张)表SQL 2.自定义业务表(2张)表SQL 三、代码示例1.依赖引入2.类文件1)定时任务配置类2&am…...

GoModule
GOPATH 最早的就是GOPATH构建模式, go get下载的包都在path中的src目录下 src目录是源代码存放目录。 package mainimport ("net/http""github.com/gorilla/mux" )func main() {r : mux.NewRouter()r.HandleFunc("/hello", func(w h…...

SQL - 数据库管理
保障数据库安全的用户账户和权限问题,当在工作环境中使用MySQL的时候,我们需要创建其他用户账户,并赋予它们特定权限。创建一个用户 create user wolf127.0.0.1 identified by 1234; create user wolf127.0.0.1 identified by 1234;-- 无 …...

密码学之AES算法
文章目录 1. AES简介1.1 AES算法的历史背景1.2 AES算法的应用领域 2. AES加解密流程图2. AES算法原理2.1 AES加密过程2.2 AES解密过程 1. AES简介 1.1 AES算法的历史背景 AES算法,全称为Advanced Encryption Standard(高级加密标准)&#x…...
)
GitHub每日最火火火项目(8.20)
项目名称:goauthentik / authentik 项目介绍:authentik 是一款提供认证功能的工具,它就像是一个强大的粘合剂,能够满足您在认证方面的各种需求。无论是在安全验证、用户身份管理还是访问控制等方面,它都能发挥重要作用…...
Flink Sink 数据输出)
(五)Flink Sink 数据输出
经过上面的 Transformation 操作之后,最终形成用户所需要的结果数据集。通常情况下,用户希望将结果数据输出到外部存储介质或者传输到下游的消息中间件中,在 Flink 中,将 DataStream 数据输出到外部系统的过程被定义为 Sink 操作。 目录 (一)基本数据输出 (二)第三方…...

Spring 注入、注解及相关概念补充
一、Spring DI 的理解 DI ( Dependency Inject,中文释义:依赖注入)是对 IOC 概念不同角度的描述,是指应用程序在运行时,每一个 bean 对象都依赖 IOC 容器注入到当前 bean 对象所需要的另一个 bean 对象。(例如…...

【Linux多线程】线程安全的单例模式
文章目录 1. 单例模式 与 设计模式1.1 单例模式1.2 设计模式1.3 饿汉实现模式 与 懒汉实现模式1.4 饿汉模式① 饿汉模式的特点② 饿汉式单例模式的实现③ 饿汉式单例模式的优缺点④ 适用场景 1.5 懒汉模式① 懒汉式单例模式的特点② 懒汉式单例模式的实现③ 懒汉式单例模式的优…...

基于jqury和canvas画板技术五子棋游戏设计与实现(论文+源码)_kaic
摘 要 网络五子棋游戏如今面临着一些新的挑战和机遇。一方面,网络游戏需要考虑到网络延迟和带宽等因素,保证游戏的实时性和稳定性。另一方面,网络游戏需要考虑到游戏的可玩性和趣味性,以吸引更多的玩家参与。本文基于HTML5和Canv…...

微软DebugMCP:可视化调试MCP协议,解决AI与工具通信黑盒问题
1. 项目概述:当你的AI助手开始“自言自语”,你需要一个调试器 最近在折腾AI应用开发的朋友,估计没少跟各种“智能体”打交道。无论是基于OpenAI的GPTs,还是那些能联网、能调用工具的自定义助手,它们背后的核心通信协议…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

KIVI开源工具箱:模块化设计赋能开发者效率提升
1. 项目概述:一个面向开发者的开源工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫KIVI。第一眼看到这个名字,我以为是某种新的UI框架或者设计系统,毕竟“KIVI”听起来有点像是“Kiwi”的变体,容易联…...
:启动时快稍后慢,断断续续哥还在)
车载以太网之要火系列 - 第46篇:郭大侠学SOME/IP (offer Service):启动时快稍后慢,断断续续哥还在
写在开篇蓉儿继续挖坑上回说到,郭靖搞清楚了Offer Service的基本原理——服务端广播“我会啥,我在这”,TTL告诉客户端有效期。郭靖合上笔记本,突然皱起眉头:“蓉儿,我有个问题——如果每个ECU都每隔1.5秒发…...

构建个人技能库:用GitHub+Markdown打造开发者的第二大脑
1. 项目概述:从“我的Copaw技能”看个人技能库的构建与管理最近在GitHub上看到一个挺有意思的项目,叫“my-copaw-skill”。这个项目名本身就很有故事感,“Copaw”这个词,我猜是“Code”和“Paw”(爪子)的结…...

模拟WiFi反向散射技术:无电池物联网通信新突破
1. 项目概述:模拟WiFi反向散射技术的革新突破在物联网设备爆炸式增长的今天,电池续航已成为制约大规模部署的关键瓶颈。传统传感器节点即使采用低功耗设计,其电池寿命也鲜有超过3-5年。而Leggiero提出的模拟WiFi反向散射技术,则开…...

知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧
知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧 【免费下载链接】zhihu-api Zhihu API for Humans 项目地址: https://gitcode.com/gh_mirrors/zh/zhihu-api 在当今数据驱动的时代,知乎数据采集和Python API开发已成为获取高质量中文知识…...

016、Git版本控制与协作开发流程
016 Git版本控制与协作开发流程 一个让我熬夜到凌晨三点的.gitignore 去年做一款基于STM32U5的TinyML手势识别项目,团队四个人,代码库从第一天就开始膨胀。第三天晚上,我习惯性git push,然后去睡觉。凌晨三点被手机震醒——同事在群里@我:“你push了个啥?编译不过了。”…...

Golioth Firmware SDK:物联网设备连接与管理的开源解决方案
1. 项目概述:Golioth Firmware SDK 是什么?如果你正在开发物联网设备,尤其是那些需要稳定连接到云端、进行远程管理、固件更新和数据同步的设备,那么你一定对“设备管理”和“连接复杂性”这两个词深有体会。自己从头搭建一套稳定…...

从肌电信号到Arduino控制:MyoWare传感器实战指南
1. 项目概述:当肌肉“说话”,我们如何“倾听”?如果你玩过一些体感游戏,或者看过科幻电影里用意念控制机械臂的场景,心里大概会闪过一个念头:这玩意儿到底是怎么做到的?其实,很多酷炫…...