Pytorch cat()与stack()函数详解
torch.cat()
cat为concatenate的缩写,意思为拼接,torch.cat()函数一般是用于张量拼接使用的
cat(tensors: Union[Tuple[Tensor, ...], List[Tensor]], dim: _int = 0, *, out: Optional[Tensor] = None) -> Tensor:
可以看到cat()函数的参数,常用的参数为,第一个参数:可以选择元组或者列表,内部包含需要拼接的张量,需要按照顺序排列,第二个参数为dim,用于指定需要拼接的维度
import torch
import numpy as npdata1 = torch.randint(0, 10, [2, 3, 4])
data2 = torch.randint(0, 10, [2, 3, 4])print(data1)
print(data2)
print("-" * 20)print(torch.cat([data1, data2], dim=0))
print(torch.cat([data1, data2], dim=1))
print(torch.cat([data1, data2], dim=2))
# tensor([[[9, 4, 0, 0],
# [3, 3, 7, 6],
# [6, 1, 0, 8]],
#
# [[9, 1, 1, 2],
# [1, 0, 6, 4],
# [7, 9, 3, 9]]])
# tensor([[[3, 2, 6, 3],
# [8, 3, 1, 1],
# [0, 9, 2, 5]],
#
# [[2, 6, 7, 5],
# [9, 1, 0, 1],
# [0, 6, 4, 4]]])
# --------------------
# tensor([[[9, 4, 0, 0],
# [3, 3, 7, 6],
# [6, 1, 0, 8]],
#
# [[9, 1, 1, 2],
# [1, 0, 6, 4],
# [7, 9, 3, 9]],
#
# [[3, 2, 6, 3],
# [8, 3, 1, 1],
# [0, 9, 2, 5]],
#
# [[2, 6, 7, 5],
# [9, 1, 0, 1],
# [0, 6, 4, 4]]])
# tensor([[[9, 4, 0, 0],
# [3, 3, 7, 6],
# [6, 1, 0, 8],
# [3, 2, 6, 3],
# [8, 3, 1, 1],
# [0, 9, 2, 5]],
#
# [[9, 1, 1, 2],
# [1, 0, 6, 4],
# [7, 9, 3, 9],
# [2, 6, 7, 5],
# [9, 1, 0, 1],
# [0, 6, 4, 4]]])
# tensor([[[9, 4, 0, 0, 3, 2, 6, 3],
# [3, 3, 7, 6, 8, 3, 1, 1],
# [6, 1, 0, 8, 0, 9, 2, 5]],
#
# [[9, 1, 1, 2, 2, 6, 7, 5],
# [1, 0, 6, 4, 9, 1, 0, 1],
# [7, 9, 3, 9, 0, 6, 4, 4]]])上述代码演示了拼接维度为0,1,2的时候的结果,可以看出cat()并不会影响张量的维度,如上述的三维张量拼接,若dim为0则按块(后两位张量组成的二维张量)进行拼接,若dim为1则按行拼接,若dim为2则按列拼接
torch.stack()
stack为堆叠、栈的意思
stack(tensors: Union[Tuple[Tensor, ...], List[Tensor]], dim: _int = 0, *, out: Optional[Tensor] = None) -> Tensor:
可以看到stack()和cat()的用法几乎一致,都是用于堆叠张量组成的列表或元组,以及堆叠的维度dim
import torch
import numpy as npdata1 = torch.randint(0, 10, [2, 3, 4])
data2 = torch.randint(0, 10, [2, 3, 4])print(data1)
print(data2)
print("-" * 20)data3 = torch.stack([data1, data2], dim=0)
data4 = torch.stack([data1, data2], dim=1)
data5 = torch.stack([data1, data2], dim=2)
data6 = torch.stack([data1, data2], dim=3)
print(data3.shape)
print(data3)
print(data4.shape)
print(data4)
print(data5.shape)
print(data5)
print(data6.shape)
print(data6)# tensor([[[1, 6, 6, 1],
# [3, 1, 8, 2],
# [0, 4, 7, 3]],
#
# [[4, 7, 5, 6],
# [5, 4, 0, 2],
# [8, 0, 3, 0]]])
# tensor([[[5, 2, 7, 2],
# [7, 4, 2, 0],
# [8, 5, 5, 9]],
#
# [[7, 1, 5, 6],
# [3, 5, 4, 7],
# [1, 0, 8, 8]]])
# --------------------
# torch.Size([2, 2, 3, 4])
# tensor([[[[1, 6, 6, 1],
# [3, 1, 8, 2],
# [0, 4, 7, 3]],
#
# [[4, 7, 5, 6],
# [5, 4, 0, 2],
# [8, 0, 3, 0]]],
#
#
# [[[5, 2, 7, 2],
# [7, 4, 2, 0],
# [8, 5, 5, 9]],
#
# [[7, 1, 5, 6],
# [3, 5, 4, 7],
# [1, 0, 8, 8]]]])
# torch.Size([2, 2, 3, 4])
# tensor([[[[1, 6, 6, 1],
# [3, 1, 8, 2],
# [0, 4, 7, 3]],
#
# [[5, 2, 7, 2],
# [7, 4, 2, 0],
# [8, 5, 5, 9]]],
#
#
# [[[4, 7, 5, 6],
# [5, 4, 0, 2],
# [8, 0, 3, 0]],
#
# [[7, 1, 5, 6],
# [3, 5, 4, 7],
# [1, 0, 8, 8]]]])
# torch.Size([2, 3, 2, 4])
# tensor([[[[1, 6, 6, 1],
# [5, 2, 7, 2]],
#
# [[3, 1, 8, 2],
# [7, 4, 2, 0]],
#
# [[0, 4, 7, 3],
# [8, 5, 5, 9]]],
#
#
# [[[4, 7, 5, 6],
# [7, 1, 5, 6]],
#
# [[5, 4, 0, 2],
# [3, 5, 4, 7]],
#
# [[8, 0, 3, 0],
# [1, 0, 8, 8]]]])
# torch.Size([2, 3, 4, 2])
# tensor([[[[1, 5],
# [6, 2],
# [6, 7],
# [1, 2]],
#
# [[3, 7],
# [1, 4],
# [8, 2],
# [2, 0]],
#
# [[0, 8],
# [4, 5],
# [7, 5],
# [3, 9]]],
#
#
# [[[4, 7],
# [7, 1],
# [5, 5],
# [6, 6]],
#
# [[5, 3],
# [4, 5],
# [0, 4],
# [2, 7]],
#
# [[8, 1],
# [0, 0],
# [3, 8],
# [0, 8]]]])
可以看到dim设置为几,就会按第几个维度进行堆叠拼接,dim为0则是整体堆叠后升维,dim为1则是按第二个维度也就是后两维张量为一个整体进行两个张量对应堆叠拼接,dim为2为按后两维中的行进行堆叠拼接,dim为3也就是按两个张量的单个值进行对应堆叠拼接
stack()随着维度增加,理解会较为复杂,具体可见代码和结果演示
注意,cat()和stack()中的dim参数也可以使用负索引,即从-1开始进行维度索引
相关文章:
与stack()函数详解)
Pytorch cat()与stack()函数详解
torch.cat() cat为concatenate的缩写,意思为拼接,torch.cat()函数一般是用于张量拼接使用的 cat(tensors: Union[Tuple[Tensor, ...], List[Tensor]], dim: _int 0, *, out: Optional[Tensor] None) -> Tensor: 可以看到cat()函数的参数…...
A. X(质因数分解+并查集)
题意:给定一个序列,求的方案数,其中,,i和j属于两个不同集合内。 解法:考虑怎样必须将某几个数放进一个集合里。如果数列中全是1,那么每个数都是独立的,也就是可以随便拿出这之中的数…...

自动化测试中如何应对网页弹窗的挑战!
在自动化测试中,网页弹窗的出现常常成为测试流程中的一个难点。无论是警告框、确认框、提示框,还是更复杂的模态对话框,都可能中断测试脚本的正常执行,导致测试结果的不确定性。本文将探讨几种有效的方法来应对网页弹窗的挑战&…...

Redission
一、Redis常见客户端 Jedis:简单,和命令最相似, API最丰富,多线程,不安全 SpringDataRedis: RedisTemplate,默认线程安全,底层基于Netty(异步支持),用于一…...

负载均衡详解
概述 负载均衡建立在现有的网络结构之上,提供了廉价、有效、透明的方式来扩展网络设备和服务器的带宽,增加了吞吐量,加强了网络数据的处理能力,提高了网络的灵活性和可用性。项目中常用的负载均衡有四层负载均衡和七层负载均衡。…...

Swift与UIKit:构建卓越用户界面的艺术
标题:Swift与UIKit:构建卓越用户界面的艺术 在iOS应用开发的世界中,UIKit是构建用户界面的基石。自从Swift语言问世以来,它与UIKit的结合就为开发者提供了一个强大而直观的工具集,用于创建直观、响应迅速的应用程序。…...

Spring 中ClassPathXmlApplicationContext
ClassPathXmlApplicationContext 是 Spring Framework 的一个重要类,位于 org.springframework.context.support 包中。它是 ApplicationContext 接口的实现,专门用于从类路径下加载 XML 配置文件。通过这个类,你可以在 Spring 应用程序中设置…...

Springboot邮件发送:如何配置SMTP服务器?
Springboot邮件发送集成方法?如何提升邮件发送性能? 对于使用Springboot的开发者来说,配置SMTP服务器来实现邮件发送并不是一件复杂的事情。AokSend将详细介绍如何通过配置SMTP服务器来实现Springboot邮件发送。 Springboot邮件发送&#x…...
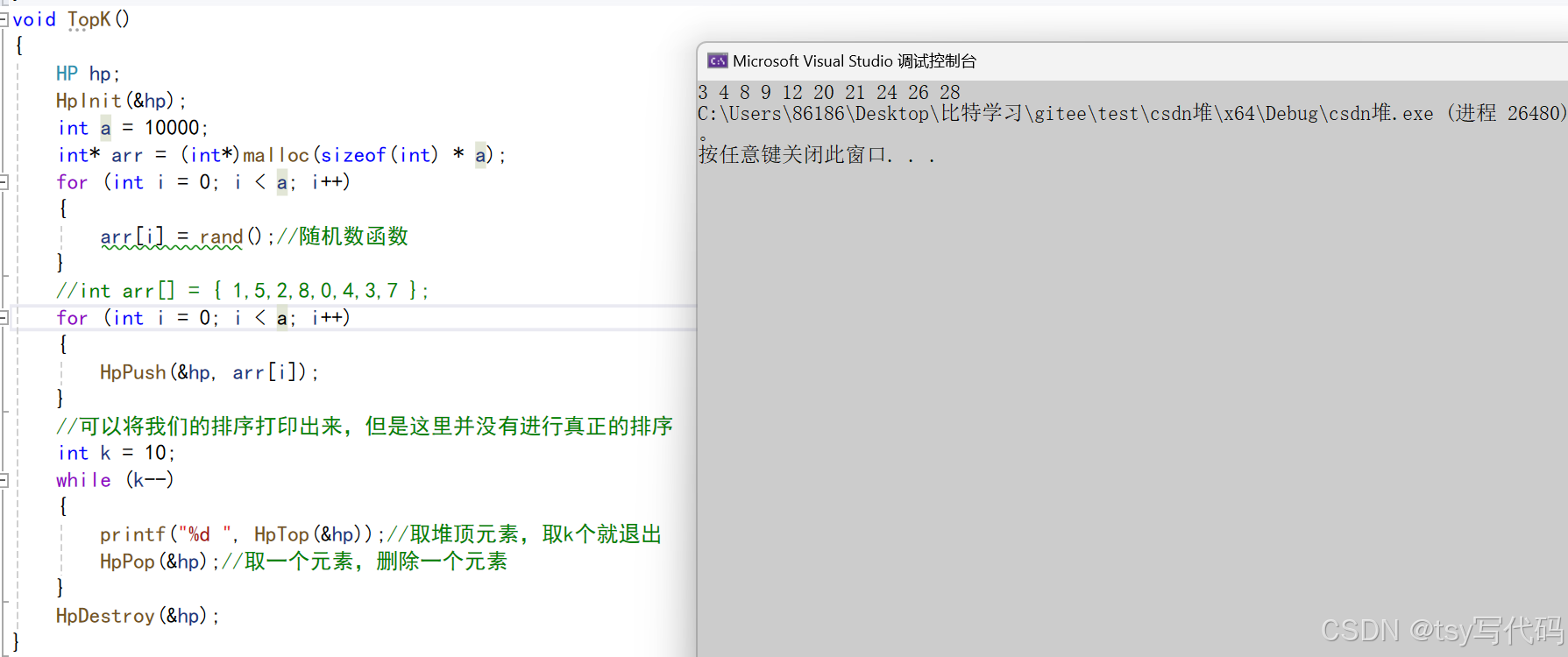
二叉树--堆
二叉树-堆 一、堆的概念及结构1.1 堆的概念与结构1.2 堆的性质 二、堆的实现三、堆的应用1、堆排序 一、堆的概念及结构 1.1 堆的概念与结构 堆就是完全二叉树以顺序存储方式存储于一个数组中。 然后每一个根都大于它的左孩子和右孩子的堆,我们叫做大堆ÿ…...
:Kubernetes 存储之 PersistentVolume)
【K8s】专题十二(2):Kubernetes 存储之 PersistentVolume
本文内容均来自个人笔记并重新梳理,如有错误欢迎指正! 如果对您有帮助,烦请点赞、关注、转发、订阅专栏! 专栏订阅入口 Linux 专栏 | Docker 专栏 | Kubernetes 专栏 往期精彩文章 【Docker】(全网首发)Kyl…...

python3多个图片合成一个pdf文件,生产使用验证过
简单的示例代码,展示如何将多个图片合成为一个 PDF 文件。 步骤 1: 安装依赖库 首先,确保你已经安装了 Pillow 和 reportlab 库: pip install Pillow reportlab步骤 2: 编写代码 下面是一个 Python 脚本,它将指定目录中的所有图片文件合成一个 PDF 文件: from PIL im…...

Stable Diffusion赋能“黑神话”——助力悟空走进AI奇幻世界
《黑神话:悟空》是由游戏科学公司制作的以中国神话为背景的动作角色扮演游戏,将于2024年8月20日发售。玩家将扮演一位“天命人”,为了探寻昔日传说的真相,踏上一条充满危险与惊奇的西游之路。 同时,我们还可以借助AI绘…...

微信小程序登陆
一 问题引入 我们之前的登陆都是:网页http传来请求,我们java来做这个请求的校验。 但是如果微信小程序登陆,就要用到相关的api来实现。 二 快速入门 1 引入依赖 官方依赖,在里面找合适的,去设置版本号。由于我这…...

SQL - 存储过程
假设你在开发一个应用,应用有一个数据库,你要在哪里写SQL语句?你不会在你的应用代码里写语句,它会让你的应用代码很混乱且难以维护。具体在哪里呢?在存储过程中或函数中。存储过程是一组为了完成特定功能的SQL语句集合…...

RabbitMQ环境搭建
2.5.RabbitMQ 安装 a.docker方式安装: 1.在我的docker学习笔记中具有详细的安装过程 b.rpm包方式安装: 1.MQ下载地址2.这里是提前下载好后上传安装包到服务器得opt目录下: 3.安装MQ需要先有Erlang语言环境,安装文件的Linux命令…...
)
多视点抓取(Multi-View Grasping)
目录 前言 一、在机器人抓取检测领域里,多视点抓取是什么意思 二、以GG-CNN为例,GG-CNN是怎么结合多个视点进行抓取预测的 前言 多视点抓取(Multi-View Grasping)是机器人抓取和检测领域的一个重要概念,它涉及到机器…...

【人工智能】对智元机器人发布的远征A1所应用的AI前沿技术进行详细分析,基于此整理一份学习教程。
智元机器人在其新品发布中应用了多项AI前沿技术。我们可以从以下几个方面来分析和整理这些技术,并基于此整理一份学习教程: 一、智元机器人应用的关键AI技术 自然语言处理 (NLP) 语音识别: 利用先进的语音识别技术,如OpenAI的Whisper&#x…...

影刀RPA--如何获取网页当页数据?
(1)点击数据抓取-选择需要获取数据的地方-会弹出是否是获取整个表格(当前页面) (2)点击“是”:则直接获取整个表格数据-点击完成即可 (3)点击“否”:如果你想…...

Bean对象生命周期流程图
Bean生命周期流程图:https://www.processon.com/view/link/5f8588c87d9c0806f27358c1 Spring扫描底层流程:https://www.processon.com/view/link/61370ee60e3e7412ecd95d43...

24/8/17算法笔记 策略梯度reinforce算法
import gym from matplotlib import pyplot as plt %matplotlib inline#创建环境 env gym.make(CartPole-v0) env.reset()#打印游戏 def show():plt.imshow(env.render(mode rgb_array))plt.show() show()定义网络模型 import torch #定义模型 model torch.nn.Sequential(t…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

MQ-3与MiCS-5524气体传感器对比:从原理到实战的选型指南
1. 项目概述与核心价值在嵌入式开发、环境监测乃至一些创意DIY项目中,气体检测是一个常见且关键的需求。无论是为了安全预警(如天然气泄漏),还是进行环境质量评估(如VOC监测),选择一款合适的传感…...

基于Vanilla JS与IndexedDB构建本地化Markdown笔记工具
1. 项目概述:从零开始构建一个轻量级笔记工具最近在整理个人知识库时,发现市面上的笔记软件要么功能过于臃肿,要么云端同步存在隐私顾虑,要么就是定制化程度不够。作为一个有十多年开发经验的从业者,我决定自己动手&am…...

PAC技术演进与核心趋势:从多域控制到边缘智能的工业自动化平台
1. 项目概述:为什么今天还要聊PAC?如果你在工业自动化、楼宇控制或者任何涉及逻辑控制的领域工作,那么“PAC”这个词对你来说应该不陌生。但很多时候,它就像一个熟悉的陌生人——大家好像都知道它,但真要细说它现在发展…...

大语言模型分步推理与自我验证框架:提升AI生成准确性的工程实践
1. 项目概述:当AI学会“自我验证”最近在开源社区里,一个名为“Lets-Verify-Step-by-Step”的项目引起了我的注意。这个项目直指当前大语言模型(LLM)应用中的一个核心痛点:如何让模型在生成复杂答案时,能像…...

基于CircuitPython的嵌入式游戏开发:从帧缓冲区到对象池的Flappy Bird实现
1. 项目概述:当Flappy Bird遇上CircuitPython如果你玩过经典的Flappy Bird,也捣鼓过像Raspberry Pi Pico这样的微控制器,那你有没有想过把这两者结合起来?我最近就用CircuitPython在RP2040开发板上完整复刻了一个“猫版”Flappy B…...

OPAL:基于OPA的实时策略数据分发与权限治理实践
1. 项目概述:什么是OPAL,以及它解决了什么核心痛点?如果你在负责一个微服务架构或者分布式系统的权限管理,大概率遇到过这样的场景:每次权限策略有更新,都需要重启服务、重新部署,或者等待一个漫…...

NoC路由设计与缓存一致性协议的协同优化
1. 项目概述:缓存一致性对NoC路由设计的挑战与机遇在当今多核处理器架构中,片上网络(NoC)作为核心间通信的基础设施,其设计质量直接影响整体系统性能。我曾在一次芯片设计项目中深刻体会到,当核心数量增加到64个时,传统…...

锂电池安全使用指南:从原理到实践,避免常见风险
1. 项目概述:从“能用”到“用好”的锂电安全课如果你玩过任何需要脱离电源线工作的电子项目,无论是给一个Arduino小车供电,还是驱动一架四轴飞行器,最终都绕不开一个核心问题:电源。从最基础的碱性电池,到…...

编写程序统计婚恋交友消费,相处长处度数据,分析理性婚恋模式,减少年轻人恋爱高频无谓消费。
构建一个婚恋交友消费与相处时长统计分析、理性婚恋模式识别的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在当代年轻人的婚恋与社交生活中,存在一种普遍现象:- 约会高度依赖“消费型场景…...