CLIP-VIT-L + Qwen 多模态学习笔记 -3
多模态学习笔记 - 3
参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE
吐槽
今天接着昨天的源码继续看,黑神话:悟空正好今天发售,希望广大coder能玩的开心~
学习心得
前情提要
详情请看多模态学习笔记 - 2
上次我们讲到利用view()函数对token_type_ids、position_ids进行重新塑形,确保这些张量的最后一个维度和input_shape(输入序列数据)的最后一个维度相等。重构的代码中默认启用缓存键值对(显然use_cache的bool值有点可有可无了QAQ),如果past_key_values的值为空,代表处于推理或者训练的第一步,此时我们初始化past_length为0,初始化past_key_values为长度为Qwen模型层数量的元组,self.h是Qwen模型的成员变量,我们无需太过关心(因为我们只是继承Qwen模型的成员变量,并重构了forward方法)。
如果我们当前不处于训练或推理的第一步,past_key_values显然就不为空(因为我们默认启用缓存键值对,ps:科研级代码是这样的),不管缓存量化(use_cache_quantization)启用与否,我们将past_length更新为第一个注意力头键张量的第二个或倒数第二个维度。这里唯一的区别只是元组的维数和维度不太一样。
如果position_ids为None,我们需要初始化一个position_ids,起始位置为past_length,终止位置为psst_lenght + input_shape[=1],确保我们的position_ids长度与input_shape的最后一个维度相等,随后重新塑形,同样是为了确保position_ids为二维张量,且最后一个维度与input_shape对齐,代码如下:
if token_type_ids is not None:token_type_ids = token_type_ids.view(-1, input_shape[-1])if position_ids is not None:position_ids = position_ids.view(-1, input_shape[-1])if past_key_values is None:past_length = 0past_key_values = tuple([None] * len(self.h))else:if self.use_cache_quantization:past_length = past_key_values[0][0][0].size(2)else:past_length = past_key_values[0][0].size(-2)if position_ids is None:position_ids = torch.arange(past_length,input_shape[-1] + past_length,dtype=torch.long,device=device,)position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
新的记忆
代码块1
接着上面的代码,继续看MQwen.py中MQwenModel中重构的forward方法,代码如下:
if attention_mask is not None:# image_feaute_length = self.otherConfig["image_context_length"]*self.otherConfig["image_feature_hidden_size"]# attention_mask_length = attention_mask.shape[-1] - image_feaute_length + self.otherConfig["image_context_length"]# attention_mask = torch.ones((batch_size, attention_mask_length), dtype=torch.long, device=device)if batch_size <= 0:raise ValueError("batch_size has to be defined and > 0")attention_mask = attention_mask.view(batch_size, -1)attention_mask = attention_mask[:, None, None, :]attention_mask = attention_mask.to(dtype=self.dtype)attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
如果没有传入attention_mask,我们需要根据batch_size重塑一个注意力掩码,注意力掩码用于告诉模型应该关注和忽略序列数据中的哪些部分,并且防止信息泄露,在处理序列到序列任务时利用未来信息生成当前输出。
首先检测传入的batch_size是否小于等于0,这很显然,对于空数据,是无法初始化一个合法的注意力掩码的。
如果batch_size合法,我们重塑attention_mask的第一个维度为batch_size。并且将attention_mask扩展为一个四维张量,其中第二第三维度为1,attention_mask的维度大致为(batch_size,1,1,未知),扩展为四维是为了适用于多头机制,对每一个头的输出进行操作。而后将attention_mask的数据类型变更为self.dtype这一题继承而来的成员变量。对于attention_mask的值进行翻转,将原先的1变为0,0变为1,然后让attention_mask乘以一个极大的负数。这样做的目的是让应该被忽略的地方变为一个极大的负数,而被注意的地方仍为0,考虑到softmax函数如下:
S o f t m a x ( x 1 ) = e x i ∑ j e x j Softmax(x_1) = \frac{e^{x_i}}{\sum_{j}e^{x_j}} Softmax(x1)=∑jexjexi
其中 x i x_i xi是输入序列中当前元素的掩码值, x j x_j xj代表任意元素的掩码值。如果掩码值为0, e x i e^{x_i} exi的值为1,如果掩码只为极大负数,值趋近于0而不为0。
这样做的目的是为了让模型完全忽略本不应该关注的部分。如果按照原先的mask,我们将应当被忽略的地方置0,在softmax操作时,幂0的e值为1,仍然会对输出有贡献,如果将其变为一个极大的负数,那么它就能真正的趋于0,被完全忽略。
代码块2
encoder_attention_mask = Nonehead_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
我们将encoder_attention_mask置为None,在多模态场景中,Qwen作为解码器使用,不需要encoder_attention_mask,后续也没有给它赋值。head_mask则使用继承成员方法self.get_mask获取,传入两个参数,一个是head_mask,默认为None,一个是隐藏层层数,头掩码用来选择性地忽略部分头的输出,效果与attention_mask类似
代码块3
if inputs_embeds is None:inputs_embeds = self.wte(input_ids)hidden_states = inputs_embedsif images is not None and first_step:new_hidden_states = []for b_idx, img_idx in enumerate(image_index):new_hidden_states.append(torch.cat([hidden_states[b_idx][:img_idx], images[b_idx], hidden_states[b_idx][img_idx:]], dim = 0)) ############# concat image and texthidden_states = torch.stack(new_hidden_states, dim = 0).to(hidden_states)
如果没有传入input_embeds,将传入的input_ids利用成员方法生成inputs_embeds,并将其作为初始的隐藏状态。
如果我们当前处于推理或者训练的第一步,并且传入了图像数据,就对图像数据和文本数据进行融合,具体来说,我们先新初始化一个列表new_hidden_states用于存储每个批次的合并数据。image_index在多模态大模型学习笔记 - 1中说明过,用来判断每个输入序列数据中图像信息的起始位置。利用torch.cat方法,将每一批次的图像信息插入到word_embeds中,最后再用torch,stack堆叠为一个新的批次,至此,图像数据和文本数据的融合完毕。
代码块4
kv_seq_len = hidden_states.size()[1]if past_key_values[0] is not None:# past key values[0][0] shape: bs * seq_len * head_num * dimif self.use_cache_quantization:kv_seq_len += past_key_values[0][0][0].shape[2]else:kv_seq_len += past_key_values[0][0].shape[1]
hidden_states的size大致为(batch_size, new_seq_len, 未知),new_seq_len是原始的文本数据序列长度加上图上数据序列长度,kv_seq_len获取不同模态数据合并后的序列长度
如果发现有过去缓存的键值对信息,我们就对kv_seq_len进行累加,这里的shape有点抽象,我们只用知道这些都是以缓存键值对的序列长度即可~
代码块5(ntk,选看)
if self.training or not self.use_dynamic_ntk:ntk_alpha_list = [1.0]elif kv_seq_len != hidden_states.size()[1]:ntk_alpha_list = self.rotary_emb._ntk_alpha_cached_listelse:ntk_alpha_list = []if attention_mask is not None and kv_seq_len > self.seq_length:true_seq_lens = attention_mask.squeeze(1).squeeze(1).eq(0).sum(dim=-1, dtype=torch.int32)for i in range(hidden_states.size()[0]):true_seq_len = true_seq_lens[i].item()ntk_alpha = self.get_ntk_alpha(true_seq_len)ntk_alpha_list.append(ntk_alpha)else:ntk_alpha = self.get_ntk_alpha(kv_seq_len)ntk_alpha_list.append(ntk_alpha)
NTK比较复杂,作用也很多,这里不展开说,它的主要目的是加速收敛,线性化训练动态,提高模型解释性等(ps:我也不知道干啥用的,但感觉是用来分析模型的训练和决策过程,增强可解释性的)。
首先我们检查当前是否处于训练状态,并且不使用动态NTK,如果是,我们初始化NTK系数为1.0。
反之,我们进一步判断kv_seq_len是否和hidden_states的seq_len长度相等,假如我们先前更新了kv_seq_len的长度,即我们有以缓存的键值对,那么这里必然是不相等的,我们初始化一个ntk_alpha_list,这里调用的是继承的成员变量。
其他情况,我们初始化一个空的ntk_alpha_list,如果存在attention_mask且kv_seq_len大于继承的成员变量self.seq_len,我们用attenrion_mask计算序列的实际长度,这里去除掉四维张量attenrion_mask的中间两个维度,计算seq_len维度中指为0的元素数量(由于之前翻转了attention_mask,所以值为0代表我们需要关注的元素)。我们获取每个批次的true_seq_len,并利用成员方法获取ntk_alpha值,添加到之前初始化的ntk_alpha_list中。
如果没有提供注意力掩码或键值序列长度不大于设定的序列长度,直接为整个键值序列长度计算一个NTK缩放因子,并添加到列表中。
ps:最一头雾水的代码块。
代码块6
self.rotary_emb._ntk_alpha_cached_list = ntk_alpha_listrotary_pos_emb_list = [self.rotary_emb(kv_seq_len, ntk_alpha=ntk_alpha) for ntk_alpha in ntk_alpha_list]hidden_states = self.drop(hidden_states)
将初始化好的ntk_alpha_list缓存到_ntk_alpha_cached_list中,以便重复利用,调用self.rotary_emb方法生成旋转嵌入,传递参数皆在之前初始化完成,生成的旋转嵌入都存储于旋转嵌入列表中。
最后启用dropout随即将一些激活值置为0,提高泛化能力,防止过拟合。
代码块7
output_shape = input_shape + (hidden_states.size(-1),)if self.gradient_checkpointing and self.training:if use_cache:logger.warning_once("`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")use_cache = False回顾一下inpui_shape的size为(batch_size,text_seq_len + image_seq_len)是一个二维张量,这里再加上hidden_stete的最后一个维度,结合为三维张量,其中hidden_state的最后一个维度就是多模态数据融合后的embed_size(参考之前代码块3中的融合过程)。
如果启用了梯度累积,并且当前处于训练状态,我们检查是否启用了缓存,由于梯度累积和缓存冲突,将use_cache置为False。梯度累积是一个内存优化技术,可以模拟大batch_size的训练,多次小批量训练后将梯度累积,并一次性用于优化器更新权重,这样能够让小批量训练类似于使用大批量训练,提高训练的稳定性和性能。
代码块8
presents = () if use_cache else Noneall_self_attentions = () if output_attentions else Noneall_hidden_states = () if output_hidden_states else Nonefor i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)if self.gradient_checkpointing and self.training:def create_custom_forward(module):def custom_forward(*inputs):# None for past_key_valuereturn module(*inputs, use_cache, output_attentions)return custom_forwardoutputs = torch.utils.checkpoint.checkpoint(create_custom_forward(block),hidden_states,rotary_pos_emb_list,None,attention_mask,head_mask[i],encoder_hidden_states,encoder_attention_mask,)else:outputs = block(hidden_states,layer_past=layer_past,rotary_pos_emb_list=rotary_pos_emb_list,attention_mask=attention_mask,head_mask=head_mask[i],encoder_hidden_states=encoder_hidden_states,encoder_attention_mask=encoder_attention_mask,use_cache=use_cache,output_attentions=output_attentions,)hidden_states = outputs[0]if use_cache is True:presents = presents + (outputs[1],)if output_attentions:all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)presents用于缓存键值对信息,如果启用了use_cache。
all_self_attentions用于输出每一层的注意力分数
all_hidden_states则存储每一层的隐藏层状态。
遍历模型的每一层,如果我们要输出每一层的隐藏状态,就添加当前层的隐藏状态进入元祖all_hidden_states。
如果启用了梯度累积技术,并且当前处于训练状态,我们就新建一个工厂函数,这个函数接受一个模块,并且返回一个新的函数customer_forward,这个函数可以在调用原始函数前向传播的同时,传递入新的参数。
使用pytorch的checkpoint函数执行前向传播,传递参数含义如下:
create_custom_forward(block):当前层的自定义前向传播函数,
hidden_states:当前层的隐藏状态
rotary_pos_emb_list:旋转位置嵌入列表,在之前初始化完成
各种mask:用于控制模型注意和忽略的部分
encoder_hidden_states:编码器的隐藏状态
反之,直接调用当前层的网络块进行前向传播计算,参数含义前文中都有说明,不再赘述。
从outputs中提取到当前层的隐藏状态。
判断是否启动缓存,如果启用,将当前层计算得到的键值对存储到prensents元组中。
如果output_attentions为True,将自注意力力权重存入all_self_attentions,这里根据是否启动缓存,索引有所不同。
代码块9
hidden_states = self.ln_f(hidden_states)hidden_states = hidden_states.view(output_shape)# Add last hidden stateif output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)
首先对hidden_states执行层归一化操作,提高训练过程的稳定性。然后将hidden_states塑形为out_put_shape,在之前有提及,就是Input_shape + 图像和文本embed合并后的最后一个维度,如果out_put_hidden_states为True,将当前层归一化后的hidden_states添加入all_hidden_states。
代码块10
if not return_dict:return tuple(v for v in [hidden_states, presents, all_hidden_states] if v is not None)return BaseModelOutputWithPast(last_hidden_state=hidden_states,past_key_values=presents,hidden_states=all_hidden_states,attentions=all_self_attentions,)
这段代码主要处理的是返回值类型。如果不要求返回值为字典类型,则返回一个元祖,对于hidden_states等元组,依次遍历里面不为None的元素并返回。
如果返回字典,我们创建一个自定义类BaseModelOutputWithPast的实例,将各种元组传递进去,最后的返回值应该是一个字典类型的数据。
至此,MQwenModel类的forward源码看完,下面要看的就是MQwenLMHeadModel的源码。
QwenModel是基座模型,包含了Qwen的主要架构,QwenLMHeadModel 是在 QwenModel 的基础上增加了一个或多个特定的下游任务头,可以用于特定的下游任务。
相关文章:

CLIP-VIT-L + Qwen 多模态学习笔记 -3
多模态学习笔记 - 3 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 吐槽 今天接着昨天的源码继续看,黑神话:悟空正好今天发售,希望广大coder能玩的开心~ 学习心得 前情提要 详情请看多模态学习笔记 - 2 上次我们讲到利用view(…...
如何将网站地图Sitemap提交至百度、谷歌及Bing搜索引擎
原文:如何将网站地图Sitemap提交至百度、谷歌及Bing搜索引擎 - 孔乙己大叔 (rebootvip.com) 在当今高度竞争的互联网环境中,搜索引擎优化(SEO)对于网站的可见性和成功至关重要。网站地图(Sitemap)ÿ…...

DC-DC FB分压电阻计算 (MP1584 SY8205为例)
【本文发布于https://blog.csdn.net/Stack_/article/details/141371702,未经许可不得转载,转载须注明出处】 获取文件 【MP1584 MP2451 SY8205 SY8201 FB分压电阻计算】 一般DC-DC芯片对输出电压的调节,是以FB引脚达到0.6V或者0.8V为止的&…...

ESLint详解及在WebStorm中的应用
ESLint是一个开源的JavaScript代码检查工具,用于识别和报告JavaScript代码中的模式问题。它可以帮助开发者遵循一定的编码规范和最佳实践,提高代码质量和可维护性。 ESLint的工作原理是通过插件和配置文件来定义一系列规则,对JavaScript代码…...

数据库系统 第20节 云数据库
云数据库是一种基于云计算技术的数据库服务,它允许用户通过互联网访问和操作数据库,而无需在本地服务器上安装和维护数据库软件。以下是云数据库的一些主要特点和优势: 弹性扩展:云数据库能够根据应用的需求动态调整计算和存储资源…...

用excel内容批量建立文件夹
建文件夹是电脑操作过程中比较常见的,但是用EXCEL内容批量建文件夹,这似乎不相关的两个操作,那么怎么实现这样的一个功能,我们需要用到专门的软件进行关联,推荐:可易文件夹批量生成器,这个软件有…...

SIRA-PCR: Sim-to-Real Adaptation for 3D Point Cloud Registration 论文解读
目录 一、导言 二、 相关工作 1、三维点云配准工作 2、无监督域适应 三、SIRA-PCR 1、FlyingShape数据集 2、Sim-to-real自适应方法 3、配准 4、损失函数 一、导言 该论文来自于ICCV2023,论文提出了一种新的方法SIRA-PCR,通过利用合成数据Flying…...

IDEA安装和使用(配图)
功能强大: 1、强大的整合能力,比如Git,Maven,Spring等 2、开箱即用(集成版本控制系统,多语言支持的框架随时可用) 3、符合人体工程学 1、高度智能 2、提示功能的快速,便捷,范围广 3、好用…...

leetcode67. 二进制求和,简单模拟
leetcode67. 二进制求和 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 1: 输入:a “11”, b “1” 输出:“100” 示例 2: 输入:a “1010”, b “1011” 输出:“10101” …...

Python:读写操作
一、读写txt 模式: rawx 【读、加写(add 无则创建)、覆盖写、新创建写(无则报错)】 bt【可以和上面四个组合使用,分别代表‘读写都行’、‘二进制’、‘文本模式’】 with open(药品数据.txt,r,encodingu…...

软体水枪在灭火工作中发挥什么作用_鼎跃安全
火灾,这一频繁侵袭我们日常生活的灾难性事件,以其迅猛之势对人类的生存环境与日常生活构成了极其严重的破坏与威胁。它不仅能够在瞬间吞噬财产,更可怕的是,它无情地剥夺了生命,破坏了家庭,给社会留下了难以…...

ES与MySQL数据同步实现方式
1.什么是数据同步: 1.Elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,Elasticsearch也必须跟着改变,这个就是Elasticsearch与mysql之间的数据同步 2.数据同步实现方式: 常见的数据同步方案有三种&#x…...

Prometheus 服务发现
一、基于文件的服务发现 基于文件的服务发现是仅仅略优于静态配置的服务发现方式,它不依赖于任何平台或第三方服务,因而也是最为简单和通用的实现方式。 Prometheus Server 会定期从文件中加载 Target 信息,文件可使用 YAML 和 JSON 格式&am…...
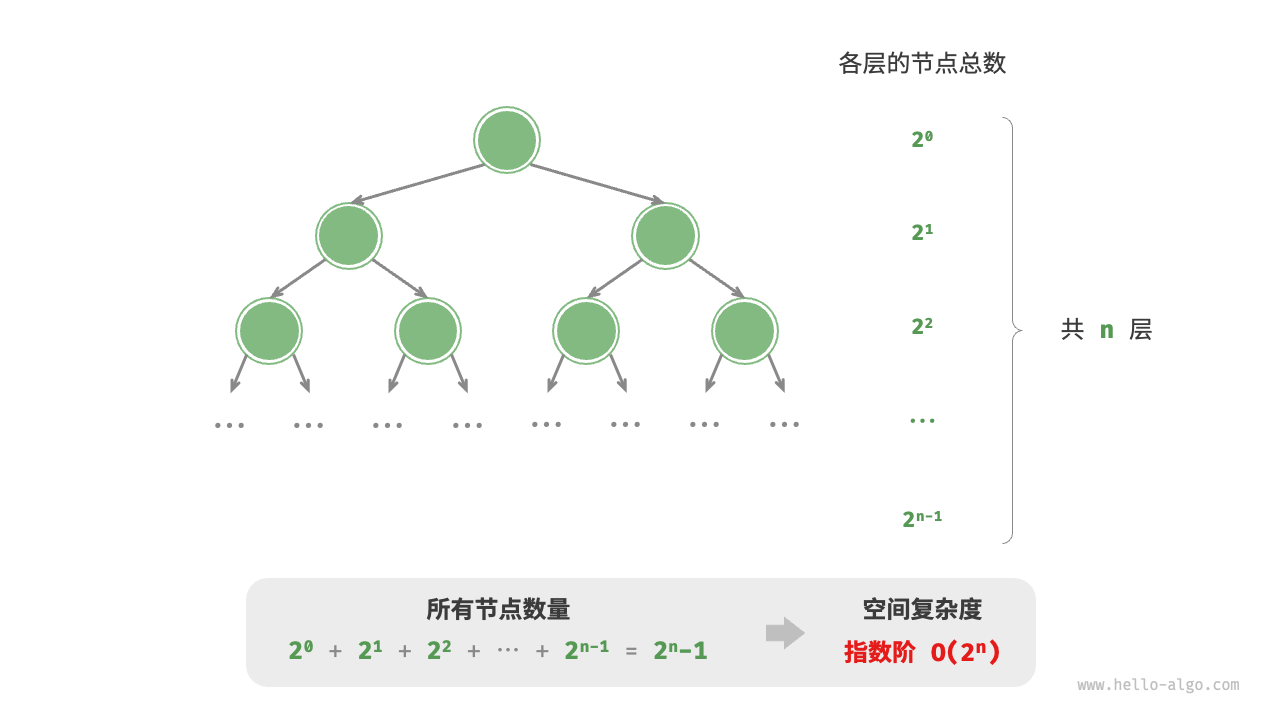
2.复杂度分析
2.1 算法效率评估 在算法设计中,我们先后追求以下两个层面的目标。 找到问题解法:算法需要在规定的输入范围内可靠地求得问题的正确解。寻求最优解法:同一个问题可能存在多种解法,我们希望找到尽可能高效的算法。 也就是说&a…...

ensp小实验(ospf+dhcp+防火墙)
前言 今天给大家分享一个ensp的小实验,里面包含了ospf、dhcp、防火墙的内容,如果需要文件的可以私我。 一、拓扑图 二、实训需求 某学校新建一个分校区网络,经过与校领导和网络管理员的沟通,现通过了设备选型和组网解决方案&…...

Web服务器——————nginx篇
一.What is Web服务器 Web服务器介绍 Web服务器(Web Server)是指驻留于因特网上某种类型计算机的程序,该程序可以向Web浏览器(如Chrome、Firefox、Safari等)等客户端提供文档,也可以放置网站文件&#…...

【实战教程】一键升级CentOS 7.9.2009至OpenSSL 1.0.2u:加固你的Linux服务器安全防线!
文章目录 【实战教程】一键升级CentOS 7.9.2009至OpenSSL 1.0.2u:加固你的Linux服务器安全防线!一、 背景二、 升级步骤2.1 检查 OpenSSL 版本2.2 安装 OpenSSL 依赖包2.3 下载 OpenSSL 的新版本2.4 解压缩下载的文件2.5 编译并安装 OpenSSL2.5.1 切换到…...

React 使用ref属性调用子组件方法(也可以适用于父子传参)
注意:①需使用hooks函数组件 ②使用了antDesign组件库(可不用) 如何使用 父组件代码 import React, { useState, useRef, useEffect } from react; import { Button } from antd; import Child from ./components/child;export defau…...

Linux CentOS java JDK17
1. 下载 cd /usr/local/ wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.tar.gz 2. 解压 tar -zxf jdk-17_linux-x64_bin.tar.gz 3.配置环境变量 vim /etc/profile // 在末尾处添加 export JAVA_HOME/usr/local/jdk-17.0.12 #你安装jdk的路径&…...
迭代与递归
算法中会经常遇见重复执行某个任务,那么如何实现呢,本文将详细介绍两种实现方式,迭代与递归。 本文基于 Java 语言。 一、迭代 迭代(iteration),就是说程序会在一定条件下重复执行某段代码,直…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

GARbro:跨平台视觉小说游戏资源解析与提取工具
GARbro:跨平台视觉小说游戏资源解析与提取工具 【免费下载链接】GARbro Visual Novels resource browser 项目地址: https://gitcode.com/gh_mirrors/ga/GARbro GARbro是一款专门用于解析和提取视觉小说游戏资源文件的跨平台开源工具,支持数百种游…...

避坑指南:Unity热重载插件内存占用高?可能是Windows Defender在搞鬼
Unity热重载性能优化:解决Windows Defender导致的资源占用问题 当你在Unity开发过程中频繁修改C#代码时,热重载(Hot Reload)功能无疑是提升效率的利器。它能让你在游戏运行状态下即时看到代码修改效果,避免反复重启带来的时间浪费。然而&…...

3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验
3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验 【免费下载链接】TaskbarX Center Windows taskbar icons with a variety of animations and options. 项目地址: https://gitcode.com/gh_mirrors/ta/TaskbarX 你是否厌倦了Windows任务栏图标总是靠左…...

深度学习图像风格迁移:从Gatys算法到PyTorch工程实践
1. 项目概述:一个基于深度学习的图像风格迁移应用最近在GitHub上闲逛,发现了一个名为“aristoapp/DDalkkak”的项目。单看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于图像风格迁移(Image S…...

AI智能体GUI交互实战:从原理到实现,让AI玩转桌面应用
1. 项目概述:一个能“玩”游戏的AI智能体最近在AI智能体(Agent)的圈子里,一个名为“ChattyPlay-Agent”的开源项目引起了我的注意。乍一看名字,你可能会觉得它又是一个基于大语言模型(LLM)的聊天…...

Navis:开源项目标准化开发环境与工具链配置框架实践
1. 项目概述:一个为开发者打造的“导航星图”如果你和我一样,常年混迹在开源项目的海洋里,那么你一定对这种感觉不陌生:面对一个全新的、功能强大的开源工具,兴奋地克隆了仓库,然后……就卡在了第一步。REA…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

大语言模型与多模态生成融合:架构、工具与实践指南
1. 项目概述:当大语言模型遇见多模态生成最近两年,AI领域最激动人心的进展,莫过于大语言模型(LLMs)和多模态生成模型的“双向奔赴”。前者以ChatGPT、GPT-4为代表,展现了惊人的语言理解、推理和生成能力&am…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...