SIRA-PCR: Sim-to-Real Adaptation for 3D Point Cloud Registration 论文解读
目录
一、导言
二、 相关工作
1、三维点云配准工作
2、无监督域适应
三、SIRA-PCR
1、FlyingShape数据集
2、Sim-to-real自适应方法
3、配准
4、损失函数
一、导言
该论文来自于ICCV2023,论文提出了一种新的方法SIRA-PCR,通过利用合成数据FlyingShapes解决现有数据稀缺问题。
数据稀缺原因:现有的基于数据驱动的深度学习方法一般依赖于两类数据,一是单一物体级别如ModelNet40,ShapeNet,二是对于室内场景水平如3DMatch。虽然单一物体级别数据集有较强的几何形状,但很难推广到真实的室内场景,室内场景的数据集来训练性能很好,但捕获真实的室内场景十分耗时且估计的相机姿态存在错误标签。所以针对场景级的合成数据集仍然数据稀缺,所以本文创建了一个合成场景数据集FlyingShapes。
(1)构建了第一个大规模的室内合成数据集FlyingShapes,使用基于物理和随机的策略将ShapeNet对象插入3D-FRONT场景中。
(2)设计了一个称为SIRA的管道,包括一个自适应重采样模块,目的是缓解合成数据和真实数据之间的域差距(分布差异),从而提高点云配准的性能。

二、 相关工作
1、三维点云配准工作
一种是直接配准,一种是基于对应的方法(与以前的博文类似)
2、无监督域适应
无监督自适应是一种解决源域(合成数据)与目标域(真实数据)之间分布差异的方法,旨在利用源域的标注数据和目标域的无标注数据,学习一个可以将源域数据映射到目标域的模型,从而提高目标域任务的性能,通过这样的方式,利用合成数据集来解决真实数据集标注不足的问题。
对于以往的点云配准任务来说,一般通过利用GAN来执行域对抗训练,使得两个域的点云特征难以被鉴别器区分。还有方法通过自监督学习里解决域对齐。
三、SIRA-PCR
SIRA-PCR框架,首先通过SIRA结构基于FlyingShapes数据集来训练合成数据到真实数据的域自适应,之后基于3DMatch或3DLoMatch(实验工作)使用GeoTransformer来训练配准工作。
SIRA-PCR框架的目的:就是通过先训练一遍我们改进的合成数据集FlyingShape,来学习到一些真实数据集中应该有的特征,这样优化了真实数据集中由于标注错误,数据样本少而训练不足的问题,其实从本质上就是增加更多的样本量,完全可以把做合成数据集到合成2真实的域适应的工作看成一种增加样本量的方式。

1、FlyingShapes数据集
3D-FRONT数据集是一个由专业设计师设计的室内场景和家具布局的场景数据集,但由于结构过于简单,FlyingShape数据集从3D-FRONT场景数据集中添加一定的家具模型来模拟真实的场景。
FlyingShapes数据集考虑了三个因素进行优化:
(1)几何增强
由于现实场景中家具摆放不一定合理,可能存在一定的随机性。所以使用两种方式添加对象数据集(单一对象),分别是基于物理意义的(重力要求),随机放置(无视重力)。
由于3D-FRONT数据集中存在大量的地板、墙壁、天花板等简单的平面,对结构的泛化效果有限,从而也使得网络过分关注这些简单的平面结构,所以以50%的概率去除这些平坦平面,进而提高对于对象数据集中物体的几何结构平衡。
(2)高质量的视角选择
视角选择着重考虑,点云数据集中,每一团点云结构应该包含较为足够数量的对象(大于5个对象结构),并且视角保持人类视角,且移动保持人类转动行进的速度(设置高度为1.6m,水平视角360°,垂直方向仰角0到45°,以30°或15°来均匀采样视图)
(3)数据准备
为模拟RGB-D摄像机的深度信息,我们通过虚拟摄像机绘制深度图并转换为点云,保留重叠范围在30%以上的点云,提高模型的泛化能力。
2、Sim-to-real自适应方法
这一部分就是做无监督域适应工作,其实本质来说也是一个GAN网络。
生成器(ResampleGAN):
生成器采用Encoder-Decoder结构,Encoder部分是ResampleKPConvEncoder结构(KPConv+ARM自适应重采样模块+FPN,用于提取特征),Decoder部分是MLPDecoder结构(本质是三层1维卷积通过LeakyReLU激活函数相连,用于将特征转换为三维坐标)
Encoder部分又可以看做一个KPConv与FPN的结合,并且每一层都会添加一个ARM重采样结构。KPConv负责从顶到底提取特征,FPN部分负责多层次的特征再次提取。
ARM重采样:Adaptive Re-sample Module,实现了基于注意力机制的点的局部重采样,利用点的特征和邻点的信息来计算一个点的加权平均坐标,保证了每一步的卷积操作输出后都有针对邻点特征的优化。
ARM算法:输入所有点的坐标(坐标矩阵),构建每个点周围的一个局部patch,并得到该点的特征和该点邻点特征,并通过加权邻点特征和该点特征,得到新的坐标点,作为调整点位置。
对于论文图3的解释如下:
我们举点云中任何一个点为例子,实际是直接用点云的坐标矩阵来进行下面计算。
对于一个点的特征
(d维列向量)与
周围K个点的邻点特征
(K*d维矩阵)的转置相乘,并除以
进行归一化,之后通过Softmax函数得到权重系数
(K维列向量),
乘以K个邻近点坐标矩阵
(K*3维矩阵)得到重采样点
。
公式解释:(其中,就是将点运算转换为矩阵运算,可忽略看)

生成器代码如下:
#重采样代码
class PatchResampleBlock(nn.Module):def __init__(self, feat_channels) -> None:r"""Initialize a patch resample block.Args:feat_channels: dimension of input features"""super(PatchResampleBlock, self).__init__()self.feat_channels = feat_channelsself.feat_proj = nn.Linear(self.feat_channels, self.feat_channels)def forward(self, points, feats, neighbor_indices):point_num, neighbor_limit = neighbor_indices.shape# adjust neighbor_indices (stand still when the patch has few neighbors)point_indices = torch.arange(point_num,device=neighbor_indices.device).reshape((point_num, 1)).repeat((1, neighbor_limit)) # (N ,K)neighbor_indices = torch.where(neighbor_indices < point_num,neighbor_indices, point_indices)# feature projectionfeats = self.feat_proj(feats)neighbor_feats = feats[neighbor_indices] # (N, K, d)neighbor_points = points[neighbor_indices] # (N, K, 3)neighbor_weights = torch.einsum("nd,nkd->nk", feats,neighbor_feats) # (N, d) x (N, K, d) -> (N, K)neighbor_weights = nn.functional.softmax(neighbor_weights /self.feat_channels**0.5,dim=-1) # (N, K) -> (N, K)output_points = torch.einsum("nk,nkp->np", neighbor_weights,neighbor_points) # (N, K) x (N, K, 3) -> (N, 3)return output_points#KPconv+FPN+ARM作为Encoder
class ResampleKPConvEncoder(nn.Module):def __init__(self, input_dim, output_dim, init_dim, kernel_size,init_radius, init_sigma, group_norm):super(ResampleKPConvEncoder, self).__init__()self.encoder1_1 = ConvBlock(input_dim, init_dim, kernel_size,init_radius, init_sigma, group_norm)self.encoder1_2 = ResidualBlock(init_dim, init_dim * 2, kernel_size,init_radius, init_sigma, group_norm)self.encoder2_1 = ResidualBlock(init_dim * 2,init_dim * 2,kernel_size,init_radius,init_sigma,group_norm,strided=True)self.encoder2_2 = ResidualBlock(init_dim * 2, init_dim * 4,kernel_size, init_radius * 2,init_sigma * 2, group_norm)self.encoder2_3 = ResidualBlock(init_dim * 4, init_dim * 4,kernel_size, init_radius * 2,init_sigma * 2, group_norm)self.encoder3_1 = ResidualBlock(init_dim * 4,init_dim * 4,kernel_size,init_radius * 2,init_sigma * 2,group_norm,strided=True)self.encoder3_2 = ResidualBlock(init_dim * 4, init_dim * 8,kernel_size, init_radius * 4,init_sigma * 4, group_norm)self.encoder3_3 = ResidualBlock(init_dim * 8, init_dim * 8,kernel_size, init_radius * 4,init_sigma * 4, group_norm)self.encoder4_1 = ResidualBlock(init_dim * 8,init_dim * 8,kernel_size,init_radius * 4,init_sigma * 4,group_norm,strided=True)self.encoder4_2 = ResidualBlock(init_dim * 8, init_dim * 16,kernel_size, init_radius * 8,init_sigma * 8, group_norm)self.encoder4_3 = ResidualBlock(init_dim * 16, init_dim * 16,kernel_size, init_radius * 8,init_sigma * 8, group_norm)self.resample4 = PatchResampleBlock(feat_channels=init_dim * 16)self.decoder4 = UnaryBlock(init_dim * 16 + 3, init_dim * 16,group_norm)self.resample3 = PatchResampleBlock(feat_channels=init_dim * 8)self.decoder3 = UnaryBlock(init_dim * 24 + 3, init_dim * 8, group_norm)self.resample2 = PatchResampleBlock(feat_channels=init_dim * 4)self.decoder2 = UnaryBlock(init_dim * 12 + 3, init_dim * 4, group_norm)self.resample1 = PatchResampleBlock(feat_channels=init_dim * 2)self.decoder1 = UnaryBlock(init_dim * 6 + 3, output_dim, group_norm)self.outputlayer = LastUnaryBlock(output_dim, output_dim)def forward(self, data_dict):points_list = data_dict['points']neighbors_list = data_dict['neighbors']subsampling_list = data_dict['subsamples']upsampling_list = data_dict['upsamples']feats_s1 = torch.ones((points_list[0].shape[0], 1),dtype=torch.float32).to(points_list[0])feats_s1 = self.encoder1_1(feats_s1, points_list[0], points_list[0],neighbors_list[0])feats_s1 = self.encoder1_2(feats_s1, points_list[0], points_list[0],neighbors_list[0])feats_s2 = feats_s1feats_s2 = self.encoder2_1(feats_s2, points_list[1], points_list[0],subsampling_list[0])feats_s2 = self.encoder2_2(feats_s2, points_list[1], points_list[1],neighbors_list[1])feats_s2 = self.encoder2_3(feats_s2, points_list[1], points_list[1],neighbors_list[1])feats_s3 = feats_s2feats_s3 = self.encoder3_1(feats_s3, points_list[2], points_list[1],subsampling_list[1])feats_s3 = self.encoder3_2(feats_s3, points_list[2], points_list[2],neighbors_list[2])feats_s3 = self.encoder3_3(feats_s3, points_list[2], points_list[2],neighbors_list[2])feats_s4 = feats_s3feats_s4 = self.encoder4_1(feats_s4, points_list[3], points_list[2],subsampling_list[2])feats_s4 = self.encoder4_2(feats_s4, points_list[3], points_list[3],neighbors_list[3])feats_s4 = self.encoder4_3(feats_s4, points_list[3], points_list[3],neighbors_list[3])resampled_points4 = self.resample4(points_list[3], feats_s4,neighbors_list[3])latent_s4 = torch.cat([feats_s4, resampled_points4],dim=1) # (N4, 64*16+3)latent_s4 = self.decoder4(latent_s4)resampled_points3 = self.resample3(points_list[2], feats_s3,neighbors_list[2])latent_s3 = nearest_upsample(latent_s4, upsampling_list[2])latent_s3 = torch.cat([latent_s3, feats_s3, resampled_points3],dim=1) # (N3, 64*16+64*8+3)latent_s3 = self.decoder3(latent_s3)resampled_points2 = self.resample2(points_list[1], feats_s2,neighbors_list[1])latent_s2 = nearest_upsample(latent_s3, upsampling_list[1])latent_s2 = torch.cat([latent_s2, feats_s2, resampled_points2],dim=1) # (N2, 64*8+64*4+3)latent_s2 = self.decoder2(latent_s2) # (N1, 256)resampled_points1 = self.resample1(points_list[0], feats_s1,neighbors_list[0])latent_s1 = nearest_upsample(latent_s2, upsampling_list[0])latent_s1 = torch.cat([latent_s1, feats_s1, resampled_points1],dim=1) # (N1, 64*4+64*2+3)latent_s1 = self.decoder1(latent_s1) # (N1, 256)output = self.outputlayer(latent_s1) # (N1, 256)return output#三层卷积作为Decoder
class MLPDecoder(nn.Module):def __init__(self, dimoffeat=256):super(MLPDecoder, self).__init__()self.sharedmlp = nn.Sequential(nn.Conv1d(dimoffeat, int(dimoffeat / 2), 1),nn.LeakyReLU(negative_slope=0.2),nn.Conv1d(int(dimoffeat / 2), int(dimoffeat / 8), 1),nn.LeakyReLU(negative_slope=0.2),nn.Conv1d(int(dimoffeat / 8), 3, 1))def forward(self, feat):feat = feat.transpose(-1, -2) # (N, d) -> (d, N)feat = feat.unsqueeze(0) # (d, N) -> (batch, d, N)output = self.sharedmlp(feat) # (batch, d, N) -> (batch, 3, N)output = output.squeeze(0) # (batch, 3, N) -> (3, N)output = output.transpose(-1, -2) # (3, N) -> (N, 3)return output#生成器
class ResampleGAN(nn.Module):def __init__(self, input_dim, dimofbottelneck, init_dim, kernel_size,init_radius, init_sigma, group_norm):super(ResampleGAN, self).__init__()self.encoder = ResampleKPConvEncoder(input_dim, dimofbottelneck,init_dim, kernel_size,init_radius, init_sigma,group_norm)self.decoder = MLPDecoder(dimoffeat=dimofbottelneck)def forward(self, data_dict):feat = self.encoder(data_dict)points_recovered = self.decoder(feat)return points_recovered判别器(ResampleGAN):
判别器输入点云中的坐标矩阵和邻点坐标信息,考虑到生成器采用不同的ARM重采样自适应,会导致改变局部的密度,所以在多尺度下(小、中、大尺度,长度分别是5,10,20)进行特征提取(特征提取使用PointNet网络),并进行特征融合,判别器的目的是判断不同层次的点是真实还是合成的。
class MultiScalePointNet(nn.Module):def __init__(self, dimoffeat=256, multiscale=[5, 10, 20]) -> None:super(MultiScalePointNet, self).__init__()self.multiscale = multiscaleself.patchpointnets = nn.ModuleList()for scale in multiscale:self.patchpointnets.append(nn.Sequential(nn.Conv1d(3, dimoffeat // 4, kernel_size=1, stride=1),nn.LeakyReLU(negative_slope=0.2),nn.Conv1d(dimoffeat // 4,dimoffeat // 2,kernel_size=1,stride=1), nn.LeakyReLU(negative_slope=0.2),nn.Conv1d(dimoffeat // 2,dimoffeat,kernel_size=1,stride=1)))self.maxpool = nn.AdaptiveMaxPool1d(output_size=1)self.sharedmlp = nn.Sequential(nn.Conv1d(len(multiscale) * dimoffeat,dimoffeat,kernel_size=1,stride=1), nn.LeakyReLU(negative_slope=0.2),nn.Conv1d(dimoffeat, dimoffeat // 2, kernel_size=1, stride=1),nn.LeakyReLU(negative_slope=0.2),nn.Conv1d(dimoffeat // 2, dimoffeat // 4, kernel_size=1, stride=1),nn.LeakyReLU(negative_slope=0.2),nn.Conv1d(dimoffeat // 4, dimoffeat // 8, kernel_size=1, stride=1),nn.LeakyReLU(negative_slope=0.2),nn.Conv1d(dimoffeat // 8, 1, kernel_size=1, stride=1))def forward(self, points, neighbor_indices):patchfeats_list = []for idx in range(len(self.multiscale)):neighbors = points[neighbor_indices[:, :self.multiscale[idx]]] # shape (N, K, 3)neighbors = neighbors - points[:, None, :]neighbors = neighbors.transpose(1, 2) # (N, K, 3) -> (N, 3, K)feats = self.patchpointnets[idx](neighbors) # (N, 3, K) -> (N, d, K)patchfeats = self.maxpool(feats) # (N, d, K) -> (N, d, 1)patchfeats = patchfeats.squeeze(-1) # (N, d, 1) -> (N, d)patchfeats = patchfeats.transpose(0, 1) # (N, d) -> (d, N)patchfeats_list.append(patchfeats)multiscalefeats = torch.cat(patchfeats_list,dim=0) # m x (d, N) -> (md, N)multiscalefeats = multiscalefeats.unsqueeze(0) # (md, N) -> (batch, md, N)out = self.sharedmlp(multiscalefeats) # (batch, md, N) -> (batch, 1, N)out = out.squeeze(0) # (batch, 1, N) -> (1, N)out = out.squeeze(0)return out3、配准
配准工作backbone使用的是GeoTransformer结构作为配准模块,并且使用GeoTransformer中提到的局部到全局的配准策略LGR策略来替换RANSAC。
LGR可以利用所有的对应关系来估计变换矩阵,而不像RANSAC使用一部分内点而存在内点分布不均匀的影响,LGR可以更好地处理重复几何结构和低重叠比例情况。
4、损失函数
损失函数包含两个模块,对于SIRA和点云配准两个部分分别进行训练。
对于SIRA模块,使用倒角损失,生成器损失和判别器损失三部分来训练域自适应。
对于配准模块,使用重叠圆损失(点对应损失)和全局点对损失两部分训练(使用的就是Geotrans的配准模块,损失也一模一样)。
四、实验
1、对比不同框架
提前获得了一部分数据集(合成数据集)的情况下,其实效果相比GeoTransformer提升并没有很大,说明这个方法idea很好,但其实用在配准工作其实一般。

2、点云配准训练中,不同数量的数据集对性能指标的影响
在不同的backbone下,显然Samples越少,对其他backbone影响越来越明显,对SIRA-PCR影响则很微小。性能指标包括:特征匹配召回,离群比、配准召回。不得不说这不就是因为提前吃了一遍数据集,学到了特征的影响吗。

3、其他实验
对于FlyingShapes数据集的建立,引入structure3D效果提升,这个不太了解情况,证明了删除平面确实有效。
消融实验中对于SIRA的不同组件以及FlyingShapes的object data和scene data进行消融。
论文参考:ICCV 2023 Open Access Repository
相关文章:
SIRA-PCR: Sim-to-Real Adaptation for 3D Point Cloud Registration 论文解读
目录 一、导言 二、 相关工作 1、三维点云配准工作 2、无监督域适应 三、SIRA-PCR 1、FlyingShape数据集 2、Sim-to-real自适应方法 3、配准 4、损失函数 一、导言 该论文来自于ICCV2023,论文提出了一种新的方法SIRA-PCR,通过利用合成数据Flying…...

IDEA安装和使用(配图)
功能强大: 1、强大的整合能力,比如Git,Maven,Spring等 2、开箱即用(集成版本控制系统,多语言支持的框架随时可用) 3、符合人体工程学 1、高度智能 2、提示功能的快速,便捷,范围广 3、好用…...

leetcode67. 二进制求和,简单模拟
leetcode67. 二进制求和 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 1: 输入:a “11”, b “1” 输出:“100” 示例 2: 输入:a “1010”, b “1011” 输出:“10101” …...

Python:读写操作
一、读写txt 模式: rawx 【读、加写(add 无则创建)、覆盖写、新创建写(无则报错)】 bt【可以和上面四个组合使用,分别代表‘读写都行’、‘二进制’、‘文本模式’】 with open(药品数据.txt,r,encodingu…...

软体水枪在灭火工作中发挥什么作用_鼎跃安全
火灾,这一频繁侵袭我们日常生活的灾难性事件,以其迅猛之势对人类的生存环境与日常生活构成了极其严重的破坏与威胁。它不仅能够在瞬间吞噬财产,更可怕的是,它无情地剥夺了生命,破坏了家庭,给社会留下了难以…...

ES与MySQL数据同步实现方式
1.什么是数据同步: 1.Elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,Elasticsearch也必须跟着改变,这个就是Elasticsearch与mysql之间的数据同步 2.数据同步实现方式: 常见的数据同步方案有三种&#x…...

Prometheus 服务发现
一、基于文件的服务发现 基于文件的服务发现是仅仅略优于静态配置的服务发现方式,它不依赖于任何平台或第三方服务,因而也是最为简单和通用的实现方式。 Prometheus Server 会定期从文件中加载 Target 信息,文件可使用 YAML 和 JSON 格式&am…...
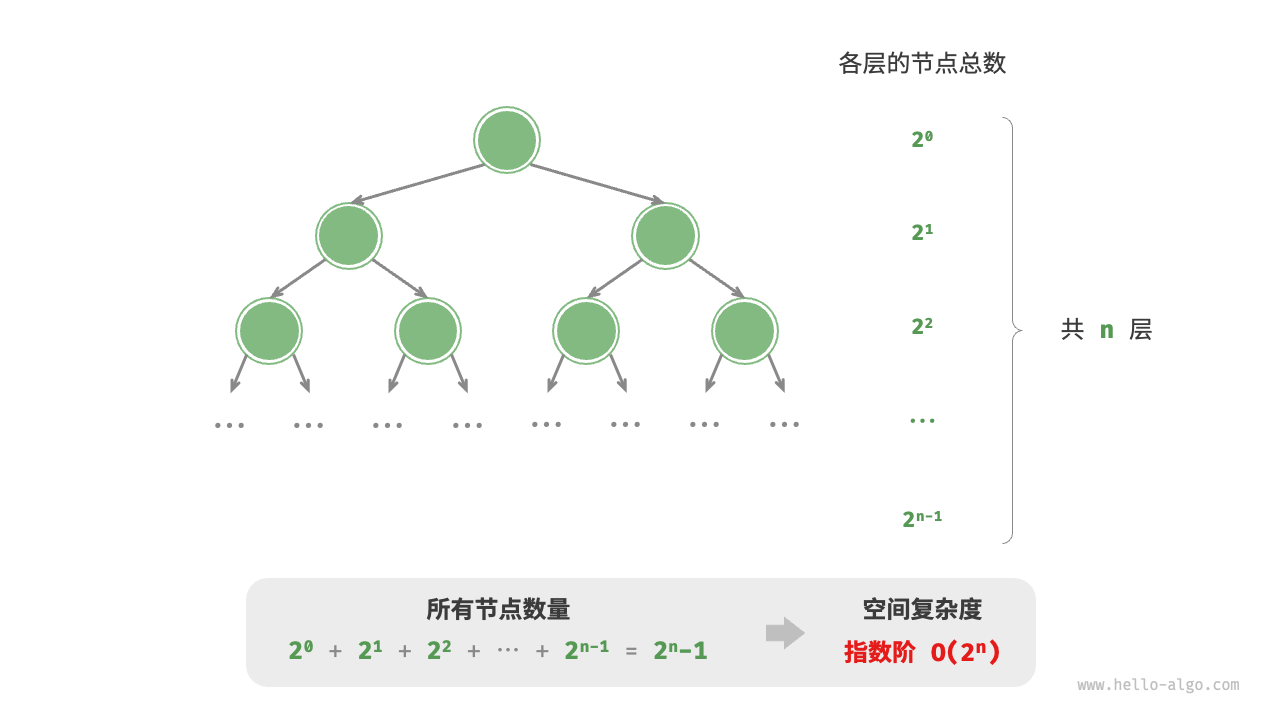
2.复杂度分析
2.1 算法效率评估 在算法设计中,我们先后追求以下两个层面的目标。 找到问题解法:算法需要在规定的输入范围内可靠地求得问题的正确解。寻求最优解法:同一个问题可能存在多种解法,我们希望找到尽可能高效的算法。 也就是说&a…...

ensp小实验(ospf+dhcp+防火墙)
前言 今天给大家分享一个ensp的小实验,里面包含了ospf、dhcp、防火墙的内容,如果需要文件的可以私我。 一、拓扑图 二、实训需求 某学校新建一个分校区网络,经过与校领导和网络管理员的沟通,现通过了设备选型和组网解决方案&…...

Web服务器——————nginx篇
一.What is Web服务器 Web服务器介绍 Web服务器(Web Server)是指驻留于因特网上某种类型计算机的程序,该程序可以向Web浏览器(如Chrome、Firefox、Safari等)等客户端提供文档,也可以放置网站文件&#…...

【实战教程】一键升级CentOS 7.9.2009至OpenSSL 1.0.2u:加固你的Linux服务器安全防线!
文章目录 【实战教程】一键升级CentOS 7.9.2009至OpenSSL 1.0.2u:加固你的Linux服务器安全防线!一、 背景二、 升级步骤2.1 检查 OpenSSL 版本2.2 安装 OpenSSL 依赖包2.3 下载 OpenSSL 的新版本2.4 解压缩下载的文件2.5 编译并安装 OpenSSL2.5.1 切换到…...

React 使用ref属性调用子组件方法(也可以适用于父子传参)
注意:①需使用hooks函数组件 ②使用了antDesign组件库(可不用) 如何使用 父组件代码 import React, { useState, useRef, useEffect } from react; import { Button } from antd; import Child from ./components/child;export defau…...

Linux CentOS java JDK17
1. 下载 cd /usr/local/ wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.tar.gz 2. 解压 tar -zxf jdk-17_linux-x64_bin.tar.gz 3.配置环境变量 vim /etc/profile // 在末尾处添加 export JAVA_HOME/usr/local/jdk-17.0.12 #你安装jdk的路径&…...
迭代与递归
算法中会经常遇见重复执行某个任务,那么如何实现呢,本文将详细介绍两种实现方式,迭代与递归。 本文基于 Java 语言。 一、迭代 迭代(iteration),就是说程序会在一定条件下重复执行某段代码,直…...

wo是如何克服编程学习中的挫折感的?
你是如何克服编程学习中的挫折感的? 编程学习之路上,挫折感就像一道道难以逾越的高墙,让许多人望而却步。然而,真正的编程高手都曾在这条路上跌倒过、迷茫过,却最终找到了突破的方法。你是如何在Bug的迷宫中找到出口的…...

vue3基础ref,reactive,toRef ,toRefs 使用和理解
文章目录 一. ref基本用法在模板中使用ref 与 reactive 的区别使用场景 二. reactive基本用法在模板中使用reactive 与 ref 的区别使用场景性能优化 三. toRef基本用法示例在组件中的应用主要用途对比 ref 和 toRef 四. toRefs基本用法示例在组件中的应用主要用途对比 ref 和 t…...

【Python机器学习】NLP的部分实际应用
自然语言处理在现实中非常多的应用,下表是其中的一些例子: 应用示例1示例2示例3搜索web文档自动补全编辑拼写语法风格对话聊天机器人助手行程安排写作索引用语索引目录电子邮件垃圾邮件过滤分类优先级排序文本挖掘摘要知识提取医学诊断法律法律断案先例…...

LLM 压缩之二: ShortGPT
0. 资源链接 论文: https://arxiv.org/pdf/2403.03853 项目代码: 待开源 1. 背景动机 现有的大语言模型 LLM 推理存在以下问题: LLM 模型因为 scale law 极大的提高模型的预测能力,但是同样带来较大的推理延时;对于 LLM 应用部署带来较大…...

EmguCV学习笔记 VB.Net 5.2 仿射变换
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 EmguCV是一个基于OpenCV的开源免费的跨平台计算机视觉库,它向C#和VB.NET开发者提供了OpenCV库的大部分功能。 教程VB.net版本请访问…...

Fink初识
文章目录 1. Flink核心组件2. Flink核心概念3. 执行应用程序的三种模式3.1 session mode3.2 per-job mode3.3 application mode 4. Job Manager4.1 Resource Manager4.2 Dispatcher4.3 Job Master 5. Watermark6. State7.时间属性7.1 处理时间 processing time7.2 事件时间 Eve…...
)
告别龟速采样!用DDIM加速你的扩散模型推理(附PyTorch代码)
加速扩散模型推理:DDIM核心原理与实战优化指南 在图像生成领域,扩散模型以其卓越的质量表现迅速成为研究热点,但传统DDPM(Denoising Diffusion Probabilistic Models)的致命缺陷在于其缓慢的采样速度——生成一张图片往…...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...

避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战
避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战 在医疗AI领域,癫痫脑电信号分析一直是个充满挑战的课题。许多开发者满怀信心地构建模型,却在验证阶段遭遇性能瓶颈——准确率停滞不前,误报率居…...
)
保姆级教程:在CentOS 7/8服务器上部署DrissionPage爬虫(含Chrome无头模式配置)
CentOS服务器上DrissionPage爬虫的工业级部署指南 1. 环境准备与Chrome浏览器安装 在CentOS服务器上部署基于DrissionPage的爬虫系统,首要任务是构建稳定可靠的浏览器运行环境。与个人开发环境不同,生产服务器通常需要面对无图形界面、资源受限等特殊场景…...
)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码) 科研图表的美观程度直接影响论文的第一印象,而三维柱状图在展示多维度数据时尤为常见。传统手动调整每个柱体的颜色、透明度、光照效果不仅耗时&#…...

火灾动力学模拟实战:如何用FDS构建精准的火灾预测系统
火灾动力学模拟实战:如何用FDS构建精准的火灾预测系统 【免费下载链接】fds Fire Dynamics Simulator 项目地址: https://gitcode.com/gh_mirrors/fd/fds 你是否曾面临这样的困境:当设计一栋大型商业建筑时,如何科学评估火灾时的人员疏…...

ARM处理器仿真技术:Cortex-R52与Neoverse实战解析
1. ARM处理器仿真技术概述在现代芯片设计和软件开发流程中,处理器仿真模型已成为不可或缺的关键工具。作为Arm生态系统的重要组成部分,Iris仿真组件提供了对Cortex-R52和Neoverse系列处理器的精确模拟能力。这些模型不仅能够模拟指令执行流程,…...

从零构建Next.js全栈应用:实战解析服务端渲染与API路由
1. 项目概述与核心价值最近在社区里看到不少朋友在讨论一个叫“panaverse/learn-nextjs”的项目,作为一个在Web开发领域摸爬滚打了十多年的老码农,我立刻来了兴趣。这个项目名直译过来就是“Panaverse的Next.js学习项目”,听起来像是一个学习…...

MySQL-MVCC核心原理-版本链ReadView与可见性判断
MVCC 全称是 Multi-Version Concurrency Control,也就是多版本并发控制。它的核心思想是:为同一行数据维护多个版本,让读写在很多情况下不用互相阻塞。 没有 MVCC 时,读写冲突通常要大量依赖锁。MVCC 让普通 select 可以读一个可见…...

桌面CNC木质游戏手柄外壳制作:从Fusion 360设计到实战加工全流程
1. 项目概述:从数字模型到木质手柄的旅程如果你和我一样,既痴迷于复古游戏的怀旧情怀,又享受亲手将数字设计变为实体物件的成就感,那么这个项目绝对能点燃你的热情。我们这次要做的,不是一个简单的3D打印外壳ÿ…...