(17)ELK大型储存库的搭建
前言:
els是大型数据储存体系,类似于一种分片式存储方式。elasticsearch有强大的查询功能,基于java开发的工具,结合logstash收集工具,收集数据。kibana图形化展示数据,可以很好在大量的消息中准确的找到符合条件,人们想知道的信息。并且支持多种数据类型。
实验环境:
关掉selinux和防火墙,做时间同步
192.168.121.30 vm2.cluster.com elasticsearch
192.168.121.40 vm1.cluster.com logstash
192.168.121.50 vm3.cluster.com kibana
一、elasticsearch的安装
地址:https://www.elastic.co/cn/downloads
找到资源,下载,对应Linux的版本就行了

[root@vm2 ~]# vim /etc/hosts
写入三行数据
192.168.121.30 vm2.cluster.com elasticsearch
192.168.121.40 vm1.cluster.com logstash
192.168.121.50 vm3.cluster.com kibana
#scp /etc/hosts root@192.168.121.40:/etc/hosts
#scp /etc/hosts root@192.168.121.50:/etc/hosts 远程传到对应主机
# hostnamectl hostname vm2.cluster.com
# yum -y install lrzsz tar net-tools wget chrony
#timedatectl时间同步
# yum -y install java-1.8.0*
安装java,基于es是java开发
[root@vm2 ~]# java -version
openjdk version "1.8.0_422" 查看版本,是否下载
[root@vm2 ~]# rpm -ivh elasticsearch-6.5.2.rpm 安装es

[root@vm2 ~]# vim /etc/elasticsearch/elasticsearch.yml
定义集合的名字,打开9200端口,监听所有ip,所有主机,更改三个地方
cluster.name: elk-cluster 可以自定义一个集群名称,不配置的话默认会取名为elasticsearch
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0 打开注释,并修改为监听所有
http.port: 9200 打开注释,监听端口9200
[root@vm2 ~]# systemctl restart elasticsearch.service 重启服务
[root@vm2 ~]# systemctl enable elasticsearch.service
[root@vm2 ~]# ss -anlt
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 4096 *:9200 *:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 4096 *:9300 *:* 查看9200,9300端口启用,9200是数据传输,访问的端口,9300是集群的端口。
[root@vm2 ~]# curl http://192.168.121.30:9200/_cluster/health?pretty
查看到集群的名字为elk-cluster,只要一个节点


二、设置节点2,192.168.121.40为第二个节点,组成集群
# yum -y install lrzsz tar net-tools wget chrony
# yum -y install java-1.8.0*
# hostnamectl hostname vm1.cluster.com
[root@vm1 ~]# java -version
openjdk version "1.8.0_422"
[root@vm1 ~]# vim /etc/elasticsearch/elasticsearch.yml 设置节点2,不为主节点
/cluster.name: elk-cluster
/node.name: 192.168.21.40 本机IP或主机名
node.master: false 指定不为master节点,这一行写道node.name下面
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
/network.host: 0.0.0.0
/http.port: 9200 开启,去掉前面的#注释
/discovery.zen.ping.unicast.hosts: ["192.168.121.30", "192.168.121.40"]
填写两个节点的ip
[root@vm2 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluster
node.name: 192.168.121.30 本机IP或主机名
node.master: true 指定为master节点
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.121.30", "192.168.121.40"]
vm添加主节点,192.168.121.30为主
[root@vm1 ~]# systemctl restart elasticsearch.service //重启服务
[root@vm1 ~]# systemctl enable elasticsearch.service
[root@vm2 ~]# systemctl restart elasticsearch.service
[root@vm2 ~]# ss -anlt 查看9200和9300端口启用
[root@vm2 ~]# curl http://192.168.121.30:9200/_cluster/health?pretty
查看有两个节点


三、es集合的基本参数查询


索引是一个
Node(节点):运行单个ES实例的服务器
Cluster(集群):一个或多个节点构成集群
Index(索引):索引是多个文档的集合
Type(类型):一个Index可以定义一种或多种类型,将Document逻辑分组
Document(文档):Index里每条记录称为Document,若干文档构建一个Index
Field(字段):ES存储的最小单元
Shards(分片):ES将Index分为若干份,每一份就是一个分片 Replicas(副本):Index的一份或多份副本

[root@vm2 ~]# curl http://192.168.121.30:9200/_cat/nodes?v
在主机和网页都是可以查询的,主机前面加一个curl就行了。那是linux访问网站的命令

[root@vm2 ~]# curl -X PUT http://192.168.121.30:9200/nginx_access 上传索引nginx_access
[root@vm2 ~]# curl http://192.168.121.30:9200/_cat/indices?v 查看索引,只要一个


[root@vm2 ~]# curl -X DELETE http://192.168.121.30:9200/nginx_access 删除索引
索引类似于目录,更好的查询。


上传一个写有一千条数据的json文件,关于bank银行人员的,方便查询
[root@vm2 ~]# curl -H "Content-Type: application/json" -XPOST "192.168.121.30:9200/bank/_doc/_bulk?pretty&refresh" --data-binary "@accounts.json"

导入后,查看索引,有一个bank的索引

[root@vm2 ~]# curl -X GET "192.168.121.30:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": {"match_all": {} }
}
'
默认查询十条


[root@vm2 ~]# curl -X GET "192.168.121.30:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
{
"query": { "match_all": {} },
"from": 0
> ,
> "size": 2
> }
> '
查看两条数据

查看500到509的十条记录
[root@vm2 ~]# curl -X GET "192.168.121.30:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
{
"query": { "match_all": {} },
"from": 500,
"size": 10,
"sort": [
{ "account_number": "asc" }
]
}
' 2>/dev/null


四、安装elasticsearch-head,可视化管理数据和查看参数
安装es-head需要先安装nodejs
网上找对应安装包就行了

[root@vm2 ~]# tar -xf node-v10.24.1-linux-x64.tar.xz -C /usr/local/
[root@vm2 ~]# cd /usr/local/
[root@vm2 local]# mv node-v10.24.1-linux-x64/ nodejs
[root@vm2 local]# ln -s /usr/local/nodejs/bin/npm /bin/npm
[root@vm2 local]# ln -s /usr/local/nodejs//bin/node /bin/node
创建软连接,使系统能使用npm命令和node命令
[root@vm2 local]# cd
[root@vm2 ~]# yum -y install unzip
[root@vm2 ~]# unzip elasticsearch-head-master.zip 解压zip文件,使用unzip命令
[root@vm2 ~]# cd elasticsearch-head-master/
先使用npm安装grunt
到head目录下安装对应工具
[root@vm2 elasticsearch-head-master]# npm install -g grunt-cli --registry=http://registry.npm.taobao.org //后面接一个淘宝的仓库,下载更快
[root@vm2 elasticsearch-head-master]# npm install phantomjs-prebuilt@2.1.16 --ignore-script --registry=http://registry.npm.taobao.org
安装npm的时候报错了,安装这个
[root@vm2 elasticsearch-head-master]# npm install --registry=http://registry.npm.taobao.org
安装完成,没有报错就行,有报错就要解决了

[root@vm2 elasticsearch-head-master]# nohup npm run start & //在head目录下,后台启动npm
[root@vm2 ~]# ss -anlt //查看9100端口启用

[root@vm2 ~]# vim /etc/elasticsearch/elasticsearch.yml //两个节点都添加连接
http.cors.enabled: true后重启es服务
http.cors.allow-origin: "*"
[root@vm2 ~]# systemctl restart elasticsearch.service
[root@vm1 ~]# vim /etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
[root@vm1 ~]# systemctl restart elasticsearch.service

刷新网页,填写192.168.121.30的ip连接

40和30的IP都是一模一样的内容,都有bank索引,内容和数据

可以删除,操作相关内容

输入删除两个字就删除了,这里不删除,只是演示一下






不要更改/etc/hosts文件,能ping通192.168.121.30,和192.168.121.40就行了



一千多条数据,查询很快,这也是es的功能之一

五、安装logstash,结合es使用
logstash可以采集任何格式的数据,当然我们这里主要是讨论采集系统日志,服务日志等日志类型数据。主要是收集日志文件。
官方产品介绍:https://www.elastic.co/cn/products/logstash
input插件: 用于导入日志源 (配置必须)
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
filter插件: 用于过滤(不是配置必须的)
output插件: 用于导出(配置必须)
在vm3.cluster.com上,IP为192.168.121.50

[root@vm3 ~]# yum -y install java-1.8.0*
[root@vm3 ~]# java -version
openjdk version "1.8.0_422"
path.data: /var/lib/logstash
path.config: /etc/logstash/conf.d/ 打开注释,并加上配置目录路径
http.host: "192.168.121.50" //本地的IP地址
http.port:9600-9700 打开端口
[root@vm3 bin]# cd /usr/share/logstash/bin/
[root@vm3 bin]# ./logstash -e 'input {stdin {}} output {stdout {}}' 运行,看到端口9600和sucess就表示运行成功了,ctrl+c结束
回车自定义输出
hi





不要更etc/hosts文件,能ping通192.168.121.30和192.168.121.40就行了
[root@vm3 bin]# vim /etc/logstash/conf.d/test.conf
input{
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
elasticsearch{
hosts => ["192.168.121.30:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}

#cd /usr/share/logstash/bin
[root@vm3 bin]# ./logstash --path.settings /etc/logstash/ -r -f /etc/logstash/conf.d/test.conf &
后台启用

[root@vm3 bin]# ps -ef | grep java | grep -v grep
root 1750 1132 9 11:07 pts/0
[root@vm3 bin]# kill -9 1750 杀死进程
在/usr/share/logstash/bin执行logstash命令
[root@vm3 bin]# ./logstash --path.settings /etc/logstash/ -r -f /etc/logstash/conf.d/test.conf &

刷新es的网页,可以看到添加的

六、安装kibana
找到对应的版本6.5的,对应前面的es版本和logstash版本

[root@vm1 ~]# rpm -ivh kibana-6.5.2-x86_64.rpm
[root@vm1 ~]# vim /etc/kibana/kibana.yml
改四个地方
/server.port: 5601
/server.host: "0.0.0.0"
/elasticsearch.url: "http://192.168.121.30:9200"
/logging.dest: /var/log/kibana.log
[root@vm1 log]# cat /etc/kibana/kibana.yml |grep -v "#"
[root@vm1 ~]# cd /var/log/
[root@vm1 log]# touch kibana.log
[root@vm1 log]# chown kibana.kibana kibana.log
[root@vm1 log]# systemctl restart kibana.service
[root@vm1 log]# systemctl enable kibana.service
网页访问192.168.121.30:5601



系统监控,不知道英文的看图标,好吧
查看节点

多出来三个索引,是kibana的


添加yum*和bank*




扩展:
filebeat工具安装在vm1,vm2和vm3上面,收集数据给logstash,更高效更快速,最重要是节省logstash的资源,filebeat使用go语言编写,简单占用内存少。
大概步骤与上面一致,开启端口,改ip.
相关文章:
(17)ELK大型储存库的搭建
前言: els是大型数据储存体系,类似于一种分片式存储方式。elasticsearch有强大的查询功能,基于java开发的工具,结合logstash收集工具,收集数据。kibana图形化展示数据,可以很好在大量的消息中准确的找到符…...
)
每日一问:Kafka消息丢失与堆积问题分析(简化版)
Kafka 消息系统问题解析 在本篇博客中,我们将深入探讨 Kafka 中常见的两大问题:消息丢失和消息堆积。首先,我们将简要介绍 Kafka 的基本工作原理,随后分别分析消息丢失和堆积的原因,并提供针对性的解决方案。 关于其详…...

C语言中函数sizeof和strlen区别
sizeof和strlen是C语言中的两个常用函数,它们的作用和使用方式有所不同。 sizeof sizeof是一个运算符而非函数,用于计算数据类型或变量占用的字节数。它可以计算任意数据类型(包括基本类型、自定义结构体、数组等)的大小。例如&…...
---- Python + MinIO + Kafka进阶)
RAG与LLM原理及实践(14)---- Python + MinIO + Kafka进阶
目录 背景 根因分析 配置 构造 创建 network 构造 zookeeper 构造 kafka 参数构造 原理解析 图解 全过程解析 工具使用 kafkacat 查看 broker python 实现 python send + kafka recv python 代码 kafka recv 运行效果 python recv + kafka send python 代…...

接口自动化-代码实现
接口自动化基础 1、接口自动化测试 接口自动化:使用工具或代码代替人对接口进行测试的技术测试目的: 防止开发修改代码时引入新的问题测试时机: 开发进行系统测试转测前,可以先进行接口自动化脚本的编写开发进行系统测试转测后&…...

如何查看linux大文件
文章目录 一、查看存储情况二、查看指定路径下的文件大小查看临时文件和日志的大小 三、查找home目录下文件大小大于100M的大文件四、查看INNODE使用情况五、查看进程使用情况查看所有进程查看特定进程杀死相关进程 六、清除缓存操作七、 查看docker的硬盘占用情况详细查看 一、…...

生成式人工智能服务大模型备案答疑
问:大模型备案范围 答:利用生成式人工智能技术向中华人民共和国境内公众提供生成文本、图片、音频、视频等内容的服务,适用本办法。 未向境内公众提供生成式人工智能服务的,不适用本办法的规定。 ps:生成式人工智能…...
QT-贪吃蛇小游戏
QT-贪吃蛇小游戏 一、演示效果二、核心代码三、下载链接 一、演示效果 二、核心代码 #include "Food.h" #include <QTime> #include <time.h> #include "Snake.h"Food::Food(int foodSize):foodSize(foodSize) {coordinate.x -1;coordinate.…...

虚幻5|AI视力系统,听力系统,预测系统(1)视力系统
继宠物伴随系统初步篇后续 虚幻5|AI巡逻宠物伴随及定点巡逻—初步篇-CSDN博客 一,听力系统 1.打开宠物ai的角色蓝图 2.选中ai感知组件 右侧细节,找到ai感知,添加感知配置,我们需要的是ai视力配置 3.选中左侧创建的ai感知组件&…...

IC rankIC
IC IC衡量的是预测值和实际值之间的相关系数 计算公式为:IC Pearson(R(predicted),R(actual)) 取值范围:[-1, 1],其中1表示完全相关,也就是预测值和实际值完全一样。0表示完全不相关,-1表示,反向相关 ra…...

Windows服务器IIS7下如何查看真实报错原因
背景 IIS7默认为友好报错,或只报错代码。如500错误,401错误等。根据这些错误无法定位真实原因,故而需要显示真实的错误信息。 解决方案 以500错误为例说明。 1、打开IIS,点全局设置中的"错误页"(注意必须是全局网站)。 2、右击50…...

深度学习设计模式之策略模式
文章目录 前言一、介绍二、特点三、详细介绍1.核心组成2.代码示例3.优缺点优点缺点 4.使用场景 总结 前言 策略模式定义一系列算法,封装每个算法,并使它们可以互换。 一、介绍 策略模式(Strategy Pattern)是一种行为型设计模式&…...
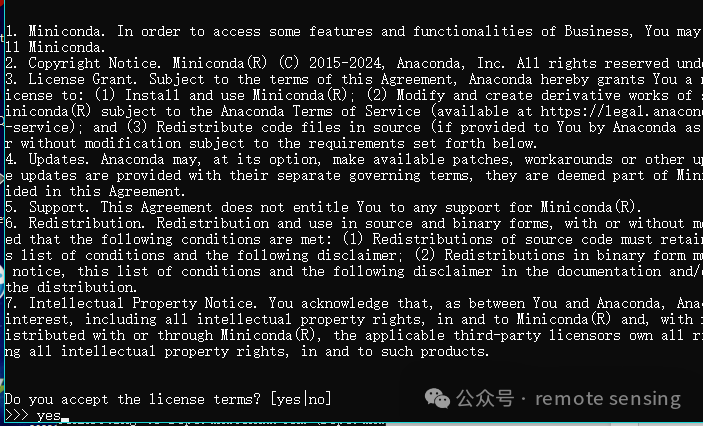
Linux 下安装miniconda(少走弯路)
Miniconda 和 Conda 都是用于管理 Python(及其他语言)环境和包的工具。 conda对于我来说是太臃肿了,很多的包我不会使用,所以选择安装miniconda是一个较好的选择。 下面是linux安装miniconda的实际操作。 在以下的网站…...

java ssl使用自定义证书
1.证书错误 Caused by: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target 2.生成客户端证书 openssl x509 -in <(openssl s_client -connect 192.168.11.19:8101 -prexit 2>/dev/null) -ou…...
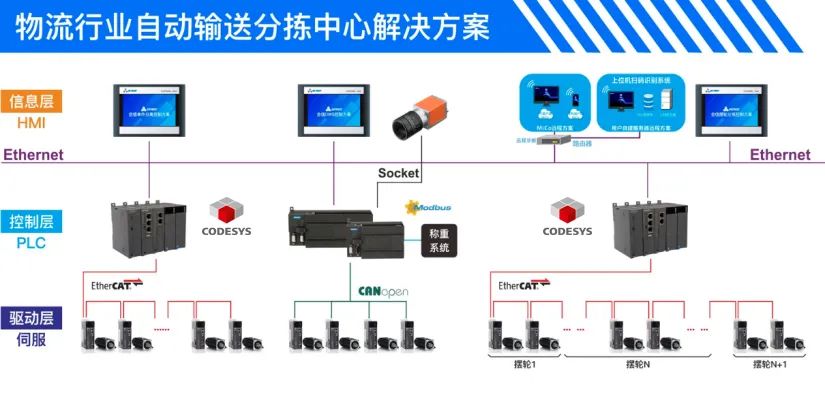
【ARM+Codesys 客户案例 】基于RK3568/A40i/STM32+CODESYS开发的控制器在自动输送分拣系统上的应用,支持定制
2021年“京东618” 累计下单金额超3438亿元,再次刷新纪录! 从下单到收货,各种货品均可在短短几天内通过四通八达的物流网络送达全国任何一个家庭。电子商务和快递物流的迅猛发展对仓储、分拣、配送效率和准确性均提出了更高的要求,加速了智能物流的发展。…...
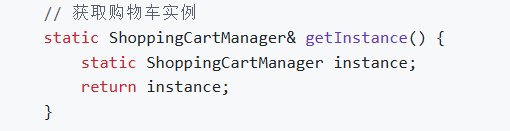
C++ 设计模式(1. 单例模式)
单例模式是一种创建型设计模式, 它的核心思想是保证一个类只有一个实例,并提供一个全局访问点来访问这个实例。 特点 全局访问点的意思是,为了让其他类能够获取到这个唯一实例,该类提供了一个全局访问点(通常是一个静态…...

算法笔记|Day31动态规划IV
算法笔记|Day31动态规划IV ☆☆☆☆☆leetcode 1049.最后一块石头的重量II题目分析代码 ☆☆☆☆☆leetcode 494.目标和题目分析代码 ☆☆☆☆☆leetcode 474.一和零题目分析代码 ☆☆☆☆☆leetcode 1049.最后一块石头的重量II 题目链接:leetcode 1049.最后一块石…...

CSS文字方向控制属性text-orientation
在CSS中,text-orientation 属性主要用于控制文本的方向,特别是当文本被设置为垂直排列时。这个属性主要用于东亚语言的排版,比如中文、日文和韩文,这些语言在垂直书写时,字符的排列方向可能与拉丁文字不同。 text-ori…...
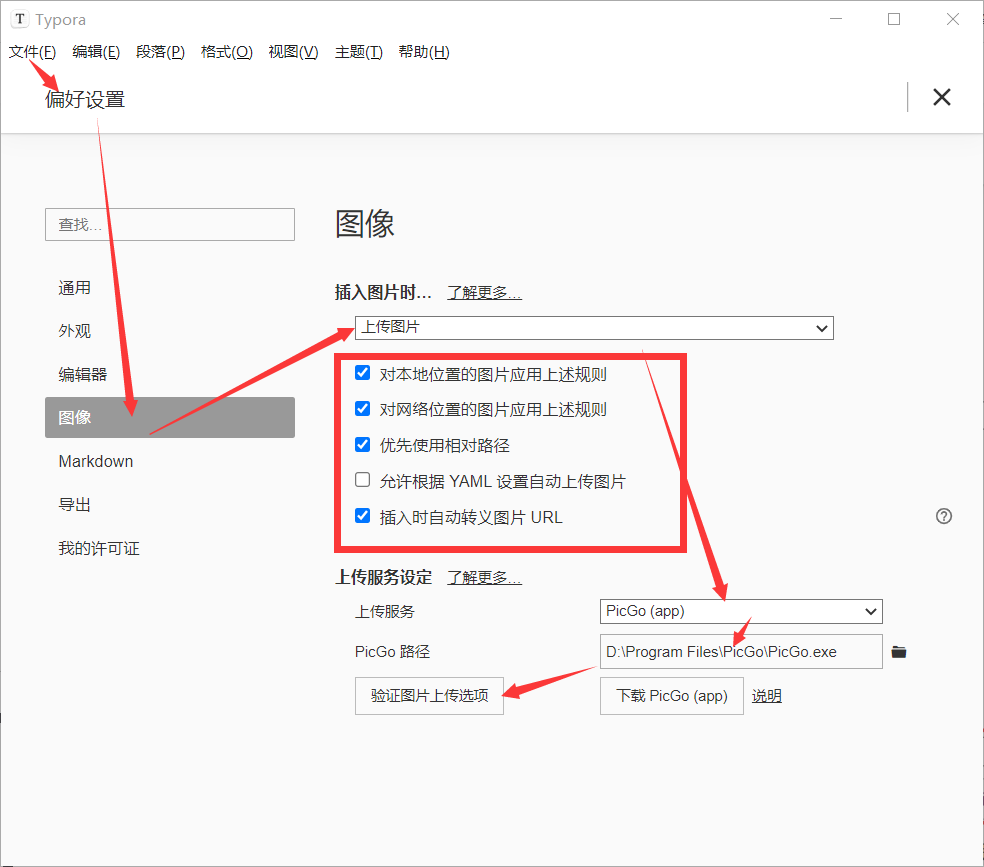
配置typora上传图片到Chevereto图床
目录 一、下载安装PicGo二、配置PicGo三、配置Typora 一、下载安装PicGo PicGo下载地址点击进入 进入官网后点击下载,会跳转到GitHub,如图,选择对应的操作系统版本下载 下载完成后单击安装(本文已windows系统为例) 二、配置PicGo 点击插件设…...

Java面试八股之如何保证消息队列中消息不重复消费
如何保证消息队列中消息不重复消费 要保证消息队列中的消息不被重复消费,通常需要从以下几个方面来着手: 消息确认机制: 对于像RabbitMQ这样的消息队列系统,可以使用手动确认(manual acknowledge)机制来…...

STM32嵌入式开发入门:从硬件配置到项目实战的完整学习路径
1. 项目概述:从零到一,如何构建你的STM32知识体系很多刚接触嵌入式开发的朋友,拿到一块STM32开发板,看着满屏的英文手册和复杂的库函数,第一反应往往是“从哪开始?”。这感觉就像面对一座零件齐全但没图纸的…...
)
Word分栏排版进阶:如何实现左右栏独立编辑与中英文对照排版(解决内容错乱问题)
Word分栏排版进阶:左右栏独立编辑与中英文对照排版实战指南 在专业文档制作中,双语对照排版是教师、翻译人员和外语学习者经常遇到的挑战。传统分栏功能虽然简单易用,但当我们需要左边显示英文原文、右边显示对应中文翻译时,直接分…...

5分钟轻松上手!DanmakuFactory弹幕神器让你的视频瞬间变有趣
5分钟轻松上手!DanmakuFactory弹幕神器让你的视频瞬间变有趣 【免费下载链接】DanmakuFactory 支持特殊弹幕的xml转ass格式转换工具 项目地址: https://gitcode.com/gh_mirrors/da/DanmakuFactory 你是否曾经遇到过这样的困扰:精心收集的B站弹幕在…...

从零到商用:用ElevenLabs打造粤语播客AI主播——12小时实测对比Azure/Coqui/TTS开源方案,成本降63%,交付提速4.8倍
更多请点击: https://intelliparadigm.com 第一章:从零到商用:用ElevenLabs打造粤语播客AI主播——12小时实测对比Azure/Coqui/TTS开源方案,成本降63%,交付提速4.8倍 粤语语音合成的三大瓶颈 传统方案在粤语TTS上长期…...

用STM32CubeMX和HAL库,5分钟搞定Nooploop TOFSense激光测距模块的串口通信
基于STM32CubeMX与HAL库的TOFSense激光测距快速开发指南 激光测距技术在工业自动化、机器人导航等领域应用广泛,而Nooploop的TOFSense模块凭借其高精度和小型化特点,成为许多嵌入式开发者的首选。本文将手把手带你使用STM32CubeMX和HAL库,在5…...

【linux应用开发】Linux树形结构与说明
一、文件结构1.1 运行流程 在终端中,执行如下指令: ./build.shbuild.sh源码#!/bin/bash #删除build文件夹 rm -rf build/ #新建build文件夹 mkdir build #切换到build文件夹 cd build #指定编译链 cmake -DCMAKE_TOOLCHAIN_FILE../toolchain-cortex-a7.c…...

2026年阿里云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这
2026年阿里云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token …...

i.MX6Q高温满负载压力测试:从散热原理到嵌入式产品可靠性设计
1. 项目概述与测试背景 在嵌入式产品的研发过程中,尤其是在工业控制、车载电子、户外设备等严苛应用场景下,系统的长期稳定性和可靠性是衡量产品成败的关键。其中,处理器作为系统的“大脑”,其在高负载、高温环境下的表现…...

基于Adafruit NeoTrellis M4打造自定义物理宏键盘:HID协议与CircuitPython实战
1. 项目概述:从通用键盘到专属启动台 如果你和我一样,每天要在电脑前处理大量任务,频繁地在不同应用间切换,或者需要执行一系列固定的快捷键操作,那么你肯定对“效率工具”有着执着的追求。我们习惯了通用键盘的“Ctrl…...

避坑指南:为什么你的PyTorch 1.8 + CUDA 10.1跑不了Grad-CAM?深入torch.fx模块依赖
避坑指南:为什么你的PyTorch 1.8 CUDA 10.1跑不了Grad-CAM?深入torch.fx模块依赖 当你兴致勃勃地准备用Grad-CAM可视化模型注意力时,终端突然抛出ModuleNotFoundError: No module named torch.fx——这个看似简单的报错背后,其实…...