Linux 多线程
目录
1 多线程的概念
1.1 再次理解进程的地址空间和页表
1.2 线程
2 线程控制
2.1 创建线程 pthread_create
2.2终止线程
2.3 线程等待
2.4 线程取消
2.5 线程分离
3 原生线程库
4 互斥 (锁)
pthread_mutex_t
pthread_mutex_init
pthread_mutex_destroy
pthread_mutex_lock
pthread_mutex_unlock
死锁
5 线程同步
6 生产消费模型
7 条件变量
pthread_cond_t
pthread_cond_init
pthread_cond_destroy
pthread_cond_wait
pthread_cond_signal
8 基于阻塞队列的生产消费模型
9 信号量
sem_t
sem_init
sem_destroy
sem_wait
sem_post
10 基于环形队列的生产消费模型
11 线程池
12 线程安全的单例模式
13 STL,智能指针和线程安全
14 其他常见的锁概念
15 读者写者模型
1 多线程的概念
1.1 再次理解进程的地址空间和页表
在页表中,除了保存映射的物理地址,其实还有一些其他的属性,比如是否命中,rwx权限,其实该地址所需要的运行级别(用户态或者内核态)。而我们的用户级页表和内核级页表用的其实还是一个数据结构类型,只不过他们的页表项中的运行级别一个是用户态一个是内核态,不同的运行级别代表了映射的是内核的空间还是用户空间

页表中的每一行数据表示一个条目,每个条目其实就是一个数据结构,保存了物理地址以及物理地址的属性字段。而如果我们要进行的地址的操作是非法的,那么MMU就会引发硬件异常,转换为操作系统给对应进程发送信号。 这是我们的之前的一些理解。
但是我们之前也还是有一个疑惑,就拿我们的32位机器来说,一共就有2^32个地址,那么如果在页表中给每一个地址都用一个条目来映射的话,那么就需要2^32次方个条目,就算我们只存储上面的图中的这些重要的属性(页表中存储的肯定不止这四条属性,我们只是把这四条我们能理解的拿出来),物理地址就是一个4字节的整型,而其它三个属性我们就算只需要一个字节,那么内存对齐一下,一个条目也需要8个字节来存储,那么2^32次方个条目就需要32G内存来存储,而我们的32位机器的内存一共才4G,存的下吗?存不下的,所以我们的虚拟地址到物理地址的映射其实远没有我们理解的这么简单。
那么真实的页表映射是怎么样的呢?
首先,我们的物理内存也是分区域的,也就是我们之前讲过的 页框 的概念,操作系统管理物理内存其实不是一个字节一个字节划分,而是把物理内存划分为 4KB 大小的数据块,每一个4KB大小的数据块我们也称之为数据页,Page ,操作系统管理每一个数据页就是用一个内核数据结构struct Page{ } 来管理的,而要对这么多个数据页做管理,要有这么多的数据结构,那么这个数据结构的体积就不能很大,所以struct Page 中存储的字段每一个都非常小,他的总体积也十分小,每一个struct Page结构体中描述的就是一个数据页的所有属性。而操作系统进行管理要先描述再组织,描述就是用struct Page来描述,而组织就很简单了,只需要用合适的数据结构比如用数据或者链表来将所有的struct Page组织在一起管理就行了,操作系统管理内存的时候,会用到的管理算法叫做伙伴系统。
而我们申请内存的时候也是以4KB为基本单位来申请的,我们也把每一个数据页称之为页框。我们知道,编译器编译形成我们的可执行程序的时候,也是按照虚拟地址的划分来编译的,同时他分配虚拟地址空间的时候也是以4KB为单位来分配的。那么磁盘中的可执行程序的虚拟地址空间的使用也是以4KB为单位的,我们把可执行程序中的预先分配好的4KB大小的空间称为页帧。
当我们的操作系统加载可执行程序到内存的时候,可不是一个字节一个字节的加载的,而是按照4KB为单位来加载的,IO的基本单位就是4KB。 那么加载的时候就相当于将程序中已经排布好的页帧直接放到了物理内存中的一个页框中,映射到地址空间中,在虚拟内存中连续的两个数据块在物理内存上可能是离散的,是通过页表的映射才使得在虚拟内存中是连续的。
同时,我们的虚拟地址其实也并不是当作一个整体来转换的。 以32位的地址来举例,其实我们的虚拟地址是以 10 10 12 的方法来使用这32个比特位的,因为我们的页表其实不只是一级页表,而是采用二级页表映射的方式。
首先拿着虚拟地址的前十个比特位在我们的 页目录 中去索引对应的页表。
怎么理解呢?页目录中其实放的是我们的页表的地址,将虚拟地址的前10个比特位作为相对于页目录的起始地址的偏移量。 简单理解就是,我们将这是个比特位转换为整数,作为一个下标,把页目录当成是一个数组,数组中的数据是页表的起始地址。
而通过前十个比特位找到需要的页表的起始地址之后,我们就能通过中间十个比特位来作为页表的索引,页表中存的就是物理内存的数据页的起始地址,那么就可以理解为把中间十个比特位转换为整数当作页表的下标,从而或者我们的页框的起始地址。
这时候我们已经找到虚拟地址映射到的页框了,也就是一个4KB大小的数据块的起始地址。那么虚拟地址的后12个比特位就能够作为在页框内的偏移量,找到我们虚拟地址所映射的物理地址。怎么找呢?我们只需要拿着这个页框的起始地址,然后再加上我们的后12个比特位就行了。 我们知道,10个比特位就是一个字节,也就是1024 ,那么12个比特位就能表示 0~ 4095 的所有的值,而一个数据页就是 4096个字节,所以12个比特位就能在一个页框中定位到其中的每个字节。

那么按这样算我们的页目录一共有多少个条目?2^10也就是1024个条目,每个条目按8个字节算就是8KB的空间。而每个页表的大小也是8KB,最多就是1024个页表,也就是 8M内存。这是否解决了各位关于页表如何映射所有地址的困惑?
这三次的索引都是很快的,时间复杂度都是O(1),因为都是直接算出结果然后去对应的偏移量拿起始地址,不需要遍历。
最终我们把虚拟地址经过一系列转换找到了虚拟地址对应的物理地址,这就已经完成了页表的映射。比如虚拟地址是一个int类型的指针,那么我们只需要从对应的物理地址开始取4个字节就能达到对应的值。
同时,我们的进程有没有可能只用到了页目录和一张页表呢?一般我们的进程是不可能用到1024张页表的,只会用自己所需要的页表的数量。而进程需要几张页表,那么加载进程的时候就只需要加载几张页表到内存就行了,没必要将不需要的页表也加载进来,这样一来,页表所需的空间就再度减少了。
我们上面所用到的从虚拟地址转换到物理地址的是一套页表的逻辑,也就是操作系统给我们维护的软件的逻辑,而虚拟地址转换的时候,不仅仅需要软件的参与,还需要我们的硬件的参与,也就是MMU内存管理单元以及CPU内的一些寄存器,在我们的计算机中,硬件的速度是远大于软件的,因为软件还需要将数据等加载到cpu这样的来回加载数据的操作,而硬件则不需要加载到寄存器,而是直接根据其内部的硬件电路的逻辑来完成,但是这也就导致了硬件的可扩展性差,维护成本高。
操作系统是使用的软硬件结合的方式,由软件来维护页表,硬件来完成虚拟到物理的转换,从而将虚拟地址映射到物理地址的。
1.2 线程
回顾一下我们之前所有的进程,进程=内核数据结构 + 进程对应的代码和数据 。这是我们以前所总结的进程。
当我们听到线程这个名称的时候,我们无可避免会想到进程,那么线程和进程之间有什么关系呢?我们在下面都会揭晓。
一般在我们的教材中都说:线程是进程内的一个执行流。
可是执行流又是什么呢?我们目前连执行流的概念都还不是很明确。我们当初描述进程的时候称进程为加载到内存中的一个执行流。
我们难以理解上面的概念是因为教材上的线程的概念一定是一种宏观的概念,他是适用于所有的操作系统的,也就是在所有的操作系统中,他的概念都没有错。但是过于宏观的东西对于我们这样的初学者就会显得抽象难以理解,以为我们不好找到具体的案例来帮助我们理解它。所以在我们这里,重点谈Linux的线程实现,要注意,其他的操作系统实现线程的方式不一定和我们的Linux一样,但是不管怎么说,不管是我们的Linux还是其他的操作系统,都肯定是满足上面的宏观的概念的。
在正式谈到线程之前,我们再来聊一下如何看待虚拟内存的问题。首先我们知道,虚拟内存其实就是一个为进程创建的数据结构,我们的进程的所有数据,在进程看来,都是存在自己的虚拟内存中的,且在进程看来是连续存储的,但是它实际存在物理内存中就不一定是连续的了。 进程的虚拟内存以及页表就决定了进程所拥有或者所能看到的资源,我们的进程想要拿到虚拟内存中的数据,实际上还是要通过页表去真实的物理内存中取数据,而在页表中没有映射的虚拟的地址,进程就无法访问其数据,强行访问就会出现硬件异常。 而在虚拟内存中,进程认为自己的独占的,但是实际上,它所对应的物理内存的数据则不一定是该进程所独占的,最典型的就是我们使用fork来创建一个子进程,而子进程要执行的代码就是父进程代码和数据的一部分,而父子进程是两个不同的执行流,那么是不是可以理解为,一个进程能够将自己的数据和代码划分出一部分,让另一个进程访问或者共享。
而子进程的创建我们也很熟悉,子进程要拷贝父进程的pcb,地址空间,页表等内核数据结构

那么从本质上来将,子进程和父进程用的地址空间和(用户级)页表不是同一个,而是各自独有的一份。
但是,我们是想要新创建的执行流来执行父进程的代码的一部分,也就是本身就要用到父进程的代码和数据,那么有没有一种可能,就是,我们创建一个新的执行流的时候,只创建一个新的pcb,然后pcb指向原来的进程的地址空间和页表。

也就是如图中,我们只为新的执行流创建一个新的pcb,而其他的诸如地址空间页表之类的资源直接用进程的,这样一来是不是代价就比创建一个完整的子进程的代价要小得多?
我们的进程或者说我们的main函数的执行流是整个虚拟地址空间和页表的所有者,而我们新创建的执行流,虽然用的是main执行流的地址空间和页表,但是我们要求新的执行流只访问一部分一部分的代码和数据,这能做到吗?肯定是能做到了,我们能够使用虚拟地址空间和页表来对一些资源进行划分,或者说为我们的新的执行流分配一部分的页表的权限,但是不一定完全放开,这样我们的新的执行流不就能访问到他所要执行的代码和所需要的数据了吗,或者我们直接理解为页表是分开的,每个这样的PCB只能访问指定的部分页表内容。那么我们将整块的资源划分一部分给新的执行流去执行,我们的新的执行流的执行粒度肯定是要比原来的进程要细的,力度我们可以简单理解为代码的量。
那么像我们现在这样只为新进程创建一个pcb,而地址空间和页表则不独立创建,用我们原来的进程大的地址空间,这是不是就叫线程了呢? 其实已经快接触到我们的线程了,只不过其中我们还有一些知识没讲到。
我们先站在CPU的角度,调度的时候怎么看待这些PCB呢?其实和原来的进程没上面两样,CPU要调度他只看进程控制块也就是PCB,而我们上面新创建的PCB也有自己的数据和要执行的代码,虽然是和原来的进程中共享的,但是CPU不关心是不是共享的,他只负责取指令和读数据,同时只要页表能够映射找到物理内存,那么在cpu看来就都是一样的。当然,在我们的上帝视角,我们能明确看到我们新创建的“进程”和原来的进程并不是一个量级的,但是在cpu看来,只要有进程空间块,能通过虚拟内存和页表读到指令和数据,那么就都是一样的,执行谁不是执行?
那么如果我们的操作系统中要为这样的执行流设计一个“线程“的概念,那么在未来我们的操作系统中一定同时存在许多这样的”线程“,操作系统就必须要管理这些线程。以前我们说了,CPU调度的基本单位是进程,但是目前看来,这句话是不太准确的,因为进程之下还有线程,那么cpu在调度的时候,就要有意识的区分目前调度的是进程还是线程,以此来判断这次调度是以进程为单位还是以线程为单位来执行,因为如果要设计线程的概念,那么cpu在调度的时候,进程和线程的执行肯定是要有所差异的。同时,我们也能看到,一个进程内部是可以有多个线程的,在操作系统中也一定会同时存在多个线程,那么操作系统就要就需要以先组织在描述的逻辑来管理这些线程。
如果有线程的概念,那么操作系统就需要为其创建类似于进程控制块PCB的内核数据结构来管理,它里面的很多字段肯定也与PCB类似,同时,由于线程是在进程内部的,那么每一个线程的内核数据结构内也一定要保存他所属的进程的一些关系。这样的结构体就叫做TCB(Thread Control Block),线程控制块。同时,我们的进程的PCB内部也需要维护一个类似于链表的结构,来组织管理内部的线程的控制块。而CPU如果要调度一个线程,首先需要找到他所在的进程,然后再找到该执行流进行调度。
上面的描述是建立在我们的操作系统确实存在线程的概念的假设上,那么操作系统需要设置专门的数据结构以及一整套管理运行的方案。而操作系统如果设计这一样一套线程的方案,那么我们的进程和线程的相关的数据结构就会有很高的耦合度,对于我们的进程,不仅要维护父子进程与兄弟进程的关系,还需要维护内部的线程之间的,同时内部的线程与线程之间也需要维护一定的关系。不管怎么说,这样设计出来的话,进程和线程的相关的内核数据结构以及管理的方案就会十分复杂,不好维护。 有些操作系统确实是这样设计的,这种是常规的设计,比如我们的windows,windows就为线程设计了专门的一套解决方案。
但是我们仔细想一想,线程被创建出来的根本目的是什么?不就是像进程一样,执行我们所编写的代码吗。他的目的就是执行代码,那么他就需要能够被调度,那么也一定会存在所谓的线程id,状态,优先级上下文,栈等等概念,那么这是不是就跟进程相差不大了。
既然线程和我们以前学习的进程的区别不是很大,他们的属性几乎都是类似的,那么我们是不是可以不用为线程设计专门的数据结构,直接使用PCB来描述管理线程。Linux内部就是复用PCB来表示我们的”线程“的。
我们把这一批只创建了PCB,而使用进程的地址空间和页表的执行流称为Linux的”线程“。
线程在进程内部运行,准确来说是在进程的地址空间内运行,共享进程的一部分资源和数据
那么这样一来,我们把main函数的执行流称为进程是不是就不太合适了?他好像和我们上面所说的”线程“没什么区别啊?或者说,我们以前学习的进程的概念在这一部分是不是不适用了?
因为我们以前说一个PCB描述的就是一个进程,而现在我们的PCB描述的可不一定是进程,也有可能是更轻量级的线程。
我们以前说 : 进程 = 内核数据结构 + 进程对应的代码和数据
这个概念还是适用的,只不过以前我们所讲的进程是一个PCB,进程地址空间和页表等数据结构,以及所拥有的物理内存和其中的代码数据 , 那么如今我们所讲的进程就是 一个或一个以上PCB,进程地址空间和页表等数据结构,以及所拥有的物理内存和其中的代码和数据。
以前所讲的进程相当于我们现在所讲的进程的一个子集,他并没有错,只是它描述的是单个执行流的进程,而我们现在要学习的是内部有多个执行流的进程。
那么我们为了更好地理解进程,可以转变一下看待进程的视角,假设我们以操作系统或者内核的角度来看,进程就是承担系统资源分配的基本实体,也就是我们把操作系统分配给它的所有资源的集合成为进程。

那么进程是怎么承担系统资源以及如何分配系统资源的呢?
承担系统资源无非就是将进程申请的系统分配的资源保存管理起来,自然就是通过虚拟地址空间和页表等数据结构来承担我们的系统资源,在计算机中,资源无非就是数据以及cpu资源。 那么进程是如何分配系统资源的呢?无非就是通过虚拟内存和页表将我们的部分资源分配给进程内部的线程。
那么在Linux中,cpu调度的基本单位就不再是进程了,而是我们所谓的“线程”。
因为调度的时候,cpu只需要认准一个pcb就行了,至于她所要执行的代码和数据是否是整个进程全部的数据不重要,也有可能是执行整个进程的一部分的代码和数据。
我们以前学习的进程他只有一个执行流,也就是main执行流,所以我们以前的进程和如今的线程的概念是一样的,因为只有一个执行流那么进程的所有资源就都是我们的单个线程的。而从现在开始我们可能就要开始学习多个执行流的线程了,那么就一定要分清楚线程和进程的概念,进程是所有的资源的集合,而线程是进程中的一个执行流以及分配给他的代码和数据。
总之,如今我们的cpu拿到的pcb并不一定是一个进程,也有可能是一个线程,我们如今讲的pcb的量级一定是<= 之前讲的pcb的量级的。我们以前讲一个pcb以及管理的资源就是一个进程,但是这只适用于单个执行流的进程,而对于多个执行流的进程,是多个pcb以及各自所拥有的资源,所有资源的和才是进程。但是还是那句话,对于cpu而言并没有什么不同的,cpu就是一个天命打工人,给他代码,他执行就行了,出错顶多报个异常给操作系统来处理。既然我们如今的一个执行流的量级是小于进程的,但是它又是依托进程的pcb来模拟实现,所以我们一般把进程执行流成为一个轻量级进程。
从上面一套分析下来,我们能够得到以下的一些结论:
1 Linux内核中并没有所谓的线程,Linux使用进程来模拟实现线程的,是一种完全属于自己的一套独特的方案,我们一般把Linux中 进程内的执行流称之为轻量级进程。
2 站在cpu的角度,每一个被在她手上的pcb都可以称之为一个轻量级进程。那么pcb中的许多的属性比如优先级,描述的就不是一整个进程的属性,而是该pcb所描述的轻量级进程的属性。
3 Linux中cpu调度的基本单位是线程,或者说是轻量级进程,而进程则是承担系统资源分配的基本单位。
4 进程用来像操作系统整体申请资源,而线程则是向进程申请资源。当然你在线程内申请的资源,比如你使用malloc申请的堆空间,其实不是以线程的身份来获取的,而是以进程的身份获取的。
5 Linux没有真正意义上的线程,Linux中线程是用进程模拟的。 那么真正意义上的线程是这样的:有线程专门的数据结构,创建线程的时候是创建真正的线程,并与进程进行关联。 虽然Linux中没有真正的线程,但是并不代表他没有线程的概念,Linux的轻量级进程虽然不是线程,虽无线程之名,却有线程之实。
用pcb模拟实现线程的优缺点
优点:简单,维护成本低,可靠高效。
在操作系统中并不是说越复杂的东西就越好的,越复杂就代表维护他的成本越高,那么就意味着很容易出错,可靠性不高。而我们使用pcb来模拟实现下线程的话,可以复用为进程编写的一系列的数据结构以及管理的算法,进程的那一套的东西都适合线程。同时进程与线程之间的关系的维护也变得简单起来,因为他们用了同一个数据结构,管理起来更方便。
缺点:由于没有真正意义上的线程,那么Linux操作系统就无法直接给用户提供创建线程的系统调用接口,它只能提供创建轻量级进程的接口。
我们宏观的操作系统是有线程的概念的,而不管你是用什么方法实现的,总之操作系统必须实现线程。那么我们的用户也只认线程,而不会要你给我提供的轻量级进程,用户也需要一个tcb来刮管理线程,而不是所谓的pcb。
那么怎么解决呢?
在操作系统与上层应用之间添加一层软件层,也就是我们Linux的原生线程库。什么叫做原生呢?就是不管你是哪个版本的Linux,只要是Linux的操作系统,那么就必须默认自带这个库。虽然他不是系统级别或者内核级别的库,是一个第三方库,但是其实它相当于行使了系统调用的职能,在用户层面,可以用这个库里面封装出来的线程的接口,然后由我们的线程库的底层来用Linux的轻量级进程来封装成为一个用户眼中的线程。
我们如何证明线程在进程的内部执行,他的量级比进程低呢?
只能靠编写代码来理解。 那么要证明上面的观点,我们就需要使用线程库里面的函数来实现线程。
我们的原生线程库就是 pthread.h
如何创建一个线程?
pthread_create

int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
四个参数,第一个参数就是进程的 tid ,这是一个输出型参数,数据类型就是pthread_t 其实就是一个unsigned long int 长整型 ,我们需要讲外部的一个变量传给该函数,创建成功后,会将创建的线程的 tid 填充到我们所传的参数上。
第二个参数是 attr ,也就是设置线程的属性,我们一般不需要自己设置也一般不会自己设置,直接传nullptr默认属性就行了
第三个参数 start_routine是一个函数指针,他的的返回值和参数类型都是 void* ,这就是我们创建的线程要执行的函数,我们称之为线程函数或者入口函数,当该函数执行完,我们的线程也就退出了。
第四个参数arg是一个 void* 类型的 ,他就是我们线程函数在执行的时候给他传的参数。

创建线程也可能失败,成功或者失败我们通过该函数的返回值来判断 。如果返回 0 .就是创建成功,如果返回的不是 0 ,就说明创建失败,返回的数字就是我们的错误的类型或者说是错误码,只不过这个错误码和我们的C语言的errno 不一样,他是在线程库里自己定义的错误俺么。同时如果创建失败,那么我们传的 tid 自然也就无效。
我们可以创建一个简单的线程来看一下:
#include<iostream>
#include<unistd.h>
#include<pthread.h>
#include<cassert>void* start_routine (void* arg)
{const char*name = static_cast<const char*>(arg);while(1){std::cout<<name <<"is running "<<std::endl; //新线程不断打印sleep(1);}
}int main()
{pthread_t tid;int ret=pthread_create(&tid,nullptr,start_routine,(void*)"thread 1");assert(ret==0);while(1) //主线程不退出,观察新线程{std::cout<< "main thread is running" << std::endl;sleep(1);}return 0;
}当我们编译的时候就会发现会有报错
报错原因我们在动静态库中也有将,就是因为编译器找不到我们的库,因为原生线程库虽然在系统默认路径下,但是毕竟是第三方库,我们需要加上 -l 选项 指明库名 。同时以后我们需要用到线程库的话,编译的时候都需要加上 -lpthread 来指明线程库。、



我们一般把main函数的执行流程为主执行流或者主线程,把新创建的线程称为新线程。
我们上面之所以让主执行流也死循环打印,是为了不让主执行流退出,因为主执行流推出的话整个进程就会退出,资源会被回收。
程序运行之后。我们的新线程就去执行对应的线程函数了,而我们的主执行流则继续往下执行他的代码。所以我们能够看到两个执行流都能够执行我们的死循环。
同时我们也发现上面的打印的时候有一些打印出错的地方,是因为我们的主线程和新线程使用的是同一个显示器内核缓冲区,那么他们之间可能会出现冲突。
我们将这个进程跑起来之后,如果使用ps ajx 去查看进程信息,发现只能看到一个进程

这是正常的,因为我们创建的是新线程,而不是一个新进程,我们的主线程和新线程都是在进程内部运行的。
那么我们要怎么查看线程呢?
ps - aL
L就是light的意思

我们发现,这两个线程的pid是一样的,这也在我们的意料之中,毕竟本来就是同一个进程,而pid是用来标识进程的。 而我们发现了他们的 LWP 不一样,LWP就是 Light Weight Process 轻量级进程的意思,LWP就是cpu调度线程的唯一标识,或者说就是线程的标识符。 而其中第一个线程的 LWP和我们的进程的pid 是一样的,这就是我们的main函数主执行流。
我们以前所讲的cpu调度的时候是以 pid 来标识的,这其实也并不算错了,因为当时我们学习的是单执行流的进程,而单执行流的话,他的主线程的 lwp 和pid的值是一样的。同时这也更加坚定了 主执行流也就是一个线程而已,他也是一个pcb加上进程分配给他的资源
 那么现在我们就明确了,cpu调度的时候其实是看lwp来调度的。
那么现在我们就明确了,cpu调度的时候其实是看lwp来调度的。
那么我们的信号呢?我们的信号发送的目标到底是线程还是进程呢?
当然是进程,我们称信号为 进程信号,自然就是给进程发的,操作系统再给一个进程发送信号的时候,其实会将该进程的每一个轻量级进程的pcb的信号位图置1。 当然我们在逻辑上就直接理解为发送给了进程,进程退出自然所有的线程也要退出。

可是我们说线程的标识是 LWP ,那么我们传给pthread_create的tid给我们填充的值是干什么用的呢?我们可以把这个值打印出来看一下。
printf("tid:%d ,%x\n",tid,tid);

我们发现打印出来的跟我们命令行看到的LWP不是一个东西,它的值很大,可能转换成地址来看更合理?tid的含义我们后续会讲清楚。
目前我们就得出了一个结论,操作系统进行调度的时候根本就不关心pid,而是看lwp,而pid只是一个划分资源的统一的方式,进程划分资源给每个线程就是给每个线程的pcb
从上面的代码我们也能看到进程对代码区的资源的划分,那么地址空间的其他的区域的资源呢?
首先我们先说一个结论:
线程被创建出来,几乎大部分资源都是所有线程共享的。
比如我们的代码区,我们写的函数既能够被新线程调用,也能被主线程调用。
又比如我们的全局数据,我么可以看一下新线程和主线程看到的是否是同一个全局变量。


我们发现,在外面新线程中对全局变量进行修改确实也会影响到主线程,因为他们看到的是同一个变量,他们的打印出来地址也是一样的,因为他们共用同一个地址空间。
就算我们在线程内部申请一块堆空间,这个堆空间也不是线程私有的,而是整个进程的所有线程所共享的,只不过其他的线程需要拿到这块空间的指针才能进行操作。如果我们把这个指针定义成全局的,那么所有线程都能够对这块堆空间进行操作。
所以,线程之间想要互相交换数据很简单,不像我们的进程间通信,需要一系列的操作去让不同的进程看到同一份资源。
两个线程之间想要通信,直接使用一个全局缓冲区就能十分方便快速地完成。
但是线程之间也并不是所有的资源都是共享的,有些资源是线程私有或者说独立的,那么什么资源是线程私有的呢?
每个线程要能够独立运行,那么就必须要有自己独立的栈,那么线程的栈区的资源就是自己私有的。
那么线程的栈空间是否如堆空间一样,别的线程拿到栈区的地址就能随意操作了呢?不能,栈是每个线程的自留地,其他的线程是没权限访问别的线程的私有栈空间的,我们可以写一个程序来验证一下。
#include<iostream>
#include<unistd.h>
#include<cstdio>
#include<pthread.h>
#include<cassert>int* pa;void* start_routine(void*args)
{int a=10;pa=&a;while(1){std::cout<<"a:"<<a<<" &a:"<<&a<<std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;int ret=pthread_create(&tid,nullptr,start_routine,nullptr);assert(ret==0);(void)ret;while(1){std::cout<<"main pa:"<<pa<<"a:"<< *pa <<std::endl; //如果 *pa 不报错,就说明能够访问,如果报错就说明不能访问,读取都不能了,那写入就更不用说了sleep(1);}return 0;
}

直接出现段错误了,也就是越界访问,这说明每个线程的栈区都是自己独立或者说私有的。
当然,主线程的栈就是地址空间的栈区,地址空间的栈是所有线程共享的。
其次,线程的上下文数据也必须是线程私有的,每个执行流都需要有自己的上下文,线程切换时加载到寄存器或者或者从寄存器中保存下来。
同时,线程的id、优先级、状态等,pcb中的属性有许多是线程所独立的。
这时候我们会有一个疑问?我们的地址空间只有一个栈区,这么多个线程是怎么做到每个线程都有自己独立的栈区的? 这个问题我们也会在后面讲到。
学到了这里,我们基本已经能够知道线程的概念了,心里大概有了一个线程的基本框架了,只不过一些具体的操作方法以及细节可能还不懂。
那么我们来总结一下一些相关概念:
1 什么是线程?
线程就是一个程序里的执行流。
一个进程至少有一个执行流,也就是至少有一个线程。
线程在进程的内部运行,本质上是在进程的地址空间中运行。
在Linux中,cpu看到的pcb比我们传统的进程更加轻量化
透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理的分配给每个执行流,就形成了现场执行流。
同时我们也可以来讲一下线程的优点:
1 创建一个新线程的代价比创建一个新进程要小得多。
这一点很好理解,因为创建一个新线程只需要创建一个一个pcb就行了,而创建一个新进程则需要拷贝一系列的内核数据结构以及地址空间。
2 与进程之间的切换相比,线程之间(同一个进程内的)的切换需要操作系统做的工作要少得多
这一点要怎么理解呢?
首先,进程之间的切换需要切换 pcb,上下文数据,页表,地址空间,页表的切换其实很简单,就是修改一下cpu中的寄存器的指针就行了,地址空间的切换其实就是随着pcb的切换而切换了。
而线程之间切换则只需要切换上下文和pcb,而不需要切换地址空间和页表。
可是我们说了,地址空间和页表的切换其实代价很小,那么为什么说线程切换代价要小得多呢?
上面的数据的切换其实差距不大,最大的差距体现在cpu中cache中数据的更新上。
我们曾经讲过cpu的三级缓存,以及计算机领域的局部性原理。缓存的速度是十分快的,比内存快的多,当cpu要去读数据时,首先会在缓存中去找,如果缓存中没有的话,也就是我们说的cpu没有命中,会先将内存中的数据加载到缓存中,cpu再从缓存中进行读取。同时由于局部性原理。cpu要读取内存中的数据,再将内存中的数据加载到缓存的时候,并不是就只将要读取的数据加载进去,而是会将该数据以及周围的一块内存都加载进程,因为我们认为,当前要访问的数据的周围的数据也有很大可能会被访问,这是局部性原理,局部性原理也是计算机设计哲学之一,这样能够大大提高计算机的效率,这些被加载到缓存中的数据叫做热点数据,热点数据顾名思义就是线程很可能需要用到的数据。
那么当cpu运行一个线程时,在cache中肯定已经存储了相当多的热点数据,那么当切换到同一个进程内的线程时,由于我们说了线程之间大部分数据是共享的,那么我们的缓存就不需要进行切换,就算需要更新也不会全部更新,也只是更新一些私有数据上去。
但是当进程之间进行切换的时候,那代价就很大了,因为进程之间是独立的,那么一个进程的热点数据对于另一个进程而言是没有用的,同时,由于不同进程之间的独立,我们也不会把上一个进程的热点数据给新进程共享。那么就意味着, 当一个进程被切换走的时候,缓存中的数据就全部失效了,那么我们就需要讲cache全部更新,而全部更新的代价是很大的,因为要去内存中读取数据来加载进来,内存是很慢的,那么在执行新进程初期,cache还没有加载进来新进程的热点数据的时候,cpu的命中率就很低,每次都需要在内存中将数据加载进缓存中才能从缓存中取数据,这样相比线程间切换就大大降低了效率了。
3 线程占用的资源比进程占用的资源要少很多。
因为线程的资源都是进程给的,这个不难理解
4 线程能充分利用多处理器的可并行数量
这个其实进程也能做到,但是不如线程效率高,因为线程在切换执行的时候不需要更新缓存
5 在等待慢速io操作时,程序可执行其他的计算任务
也就是阻塞等待外设时可以切换线程去执行其他的任务
6 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
7 io密集型应用,为了提高性能,将io操作重叠,线程可以同时执行不同的io操作。
线程的缺点:
1 性能损失
一个很少被外部事件阻塞的计算密集型县城往往无法与其他线程共享一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步与调度的开销,而可用资源不变。
2 健壮性降低
在进程之间,一个进程挂了不会影响其他的进程。而如果在进程内的其中一个线程出异常被终止了,那么整个进程都会受其影响而终止。在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,也就是说线程之间是缺乏保护的,不安全。
3 缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些系统调用会对整个进程造成影响。同时对资源也缺乏访问控制,比如全局变量的访问,他虽然能够降低通信的成本,但是也可能造成数据不一致的问题,比如两个线程同时访问一个变量,一个读取一个写入,那么写入的线程可能会影响到读取的线程。
4 编程难度变高
线程之间共享的数据:线程之间共享同一地址空间,所以他们的代码段和数据段是共享的。其次页表、每种信号的处理方式、当前工作目录、用户id和组id都是共享的。
线程的私有的数据:线程id,一组寄存器(上下文数据),栈,errno,信号屏蔽字,调度优先级
我们的线程与进程间的模型有四种
单进程单线程 , 单进程多线程 ,多个单线程的进程(这对应我们以前的多进程) , 多个多线程的进程
2 线程控制
在真正的学习线程的接口之前,我们首先来见识一下Linux给我们提供的关于轻量级进程的接口,因为我们说了,Linux不直接提供线程的接口,只会提供轻量级进程的接口,而我们的原生现场库就是封装了轻量级进程来给我们需要的所谓的线程的。
最底层的接口叫做 clone
 clone的功能就是创建一个进程,他会拷贝内核数据结构,而我们以前学习过的fork叫做创建一个子进程,fork的底层就是调用的clone来完成内核数据的拷贝。
clone的功能就是创建一个进程,他会拷贝内核数据结构,而我们以前学习过的fork叫做创建一个子进程,fork的底层就是调用的clone来完成内核数据的拷贝。
同时我们也能发现,clone允许我们创建一个进程来共享调用它的进程的一部分资源。这不就是创建一个轻量级进程吗?也就是我们Linux中的线程,所以创建线程的底层的接口就是clone 。
我们发现 clone 有一个参数叫做 child_stack ,子栈,为什么我们的线程的栈是私有的?肯定是和这里传的地址有关。
与fork相对的,还有一个接口叫做 vfork

vfork就是用来创建子进程,只不过他创建出来的子进程和父进程是共享地址空间和页表的,只不过他能保证子进程先运行,并且只有子进程结束了父进程才会继续往下执行,他底层调用的也是clone。vfork创建出来的并不是我们的线程所需要的轻量级进程。
clone我们一般都不用,而是直接使用线程库提供的接口来使用线程。
下面就进入我们的线程库的学习
首先声明一个点,就是我们的原生线程库是遵循 POSIX 标准的,我们未来用到的这个库里面的所有接口都是以 pthread 开头的,同时是采用单词或者缩写中间加上 _ 下划线的命名方式,函数的命名都是统一的。
在线程控制这部分内容,我们主要学习现成的创建,线程终止,线程等待和线程分离。
2.1 创建线程 pthread_create

这个接口没什么好说的,上面已经讲过了他的参数和错误返回了。
为什么调用出错不设置errno而是直接返回一个线程库中定义的错误码呢?因为我们说了,在多线程的情况下,我们的全局变量是缺乏访问控制的,而errno就是我们的C库提供的一个全局的错误码,由于缺乏访问控制,被设置的错误码不一定是主线程调用pthread_create出错设置的错误码,因为可能中间发生线程切换了, 别的线程也发生了错误码的设置,这时候errno就被覆盖了。这就是为什么我们不是用errno的原因。
同时,就如同创建进程一样,我们的主线程和新创建的线程谁先执行我们是不知道的,这完全取决于CPU的调度策略
我们既可以创建一个新线程,也可以创建多个新线程,多个执行流执行我们的同一个函数或者不同的函数。
但是在初学阶段我们可能会见到一些很奇怪的现象,比如我们写了下面这样一份看似普普通通的代码:
void* start_routine(void*arg)
{const char* name=static_cast<const char*> (arg);while(1){std::cout<<name<<std::endl;sleep(1);}return nullptr;
}int main()
{std::vector<pthread_t> tids(5,0);for(int i=0;i<5;++i){char name[64];snprintf(name,sizeof name , "this is Thread %d",i+1);pthread_create(&tids[i],nullptr,start_routine,(void*)name);}while(1){std::cout<<"this is main thread"<<std::endl;sleep(1);}return 0;
}
我们这段程序也很简单,就是创建五个新线程,给每个线程都传一个字符串作为他们的名字,而线程中就执行打印名字的逻辑就完了。 那么我们运行一下,看是否如我们所料。

怎么跑出来是这样的呢?我们明明传的是不同的名字,为什么打印出来的都是 5 呢?
其实主要就是因为我们传给每一个新线程的参数都是同一个地址,都是在地址空间的栈上的 name 数组,由于我们的循环中没有分支语句,每次进循环执行的都是一样的指令,同时每次出循环我们的循环中的局部变量都会销毁,所以其实每一次循环中创建的name数组,用的都是同一块空间,那么随着循环的进行,后续往name中填充数据其实也是在覆盖之前的填充的数据。于是我们就看到所有线程最后打印出来的都是最后填充进去的数据。其实这里有一点点越界的意思了,只不过由于他还是在地址空间内,或者说还是在我们的函数栈帧内,所以没有越过栈帧的边界,也并不会报错。

那么正确的写法应该是要使用堆上的空间来进行传参,而不是在栈上存放数据。


同时我们也能发现这些线程的执行时是无序的,因为调度完全取决于cpu和操作系统,我们无法决定调度的顺序。
如果我们既想要将线程的 tid 作为参数传给线程,也想将名字传给线程,我们给怎么做呢?
要记住,我们的参数是void*的,这说明我们可以是任意类型的参数的指针,强转为void*就能够进行传参,并没有规定必须是内置类型,只不过我们在线程函数内部需要自己做有些强转的处理。
那么我们是不是可以直接搞一个类来传参,然后new一个类对象,将指针传给新线程呢?当然可以。


同时,我们还可以传函数指针,以此来相信线程派发任务,这一点也很容易做到。
那么向上面这种,多个执行流同时调用 start_routine 函数,为什么没问题呢?因为他们都是在自己的私有栈上执行的。
这种情况就是我们之前讲过的重入的概念,那么我们上面的start_routine函数是可重入函数还是不可重入函数呢? 显而易见是不可重入的,这么大的问题都怼我们脸上了,主要还是因为函数内部调用了 IO 接口,像显示器上打印数据了,而向显示器上打印数据其实就是想缓冲区中写数据,显示器的内核缓冲区只有一个,我们就可以理解为对全局数据的访问不够安全导致了上面的问题。
2.2终止线程
我们能够创建线程了,但是怎么来终止线程呢?
首先最简单的就是线程的函数走到了结尾的 return ,线程函数执行完了,那么线程也就自然终止了。
可是就好比我们上面的线程函数,内部是一个死循环,就注定了他走不到结尾的return,这时候要怎么终止线程呢?
我们线程库提供了一个函数叫做 pthread_exit ,

pthread_exit 函数用于终止调用该函数的线程,也就是哪个线程调用它,就终止哪个线程,那么线程都被终止了,自然也就不需要返回值了。
但是我们发现,该函数调用的时候需要一个参数,不是tid,而是一个 void* 的指针,这就跟我们的线程函数的返回值是一样的,表示的是线程的退出结果或者说是要从线程中带回去的数据,他有什么用呢?我们后续会等待线程,那会就有用了。目前我们可以直接传nullptr来调用。
void* start_routine(void* arg)
{int cnt=0;while(1){std::cout<<"New Thread : "<<cnt++<<std::endl;sleep(1);if(cnt==5){std::cout<<"New Thread Exit!";pthread_exit(nullptr); // 出口} }return nullptr; // 出口
}
int main()
{pthread_t tid;pthread_create(&tid,nullptr,start_routine,nullptr);sleep(10);std::cout << "10秒一到,主线程要退出喽!"<<std::endl;return 0;
}
记住,我们不能使用信号或者exit这样的方式让线程退出,他们是终止进程的方式,一调用,整个进程都退出了。
2.3 线程等待
进程等待其实就挺让我们头疼的了,这会又来一个线程等待。不过线程等待很简单,
线程等待的接口是 pthread_join 
线程等待要传的参数一个是要等待的线程的id,这个很好理解,但是第二个参数是一个二级指针,这我们怎么理解呢? 其实很简单,就是一个输出型参数。
我们的return或者pthread_exit ,在终止线程的时候,会返回一个 void* 的返回值或者我们称之为退出结果,这个结果在线程退出时拷贝到了线程库的特定位置,直到我们调用join去回收,如果我们需要拿到退出结果的话,我们就需要传一个 void* 的变量的指针去接收,于是就需要传一个void**的参数。 就好比我们需要接受进程的退出状态status一样,他是一个int类型的值,那么我们需要传一个int对象的指针去接收返回值,都是作为一个输出型参数。
我们可以接收一下线程函数的退出结果
void* start_routine(void* arg)
{sleep(5);return (void*) 66;
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,start_routine,nullptr);void* ret=nullptr;pthread_join(tid,&ret);std::cout<<"线程推出结果:"<<(long long)ret<<std::endl;return 0;
}
我们也可以去接收pthread_exit 的退出结果,都是一样的。
同时,我们的返回值不一定是一个自定义类型,我们也可以返回一个自定义类型,只不过这个返回的自定义类型我们需要在堆上开辟,因为pthread库接收的返回值是一个void*的指针,他只会帮我们保存这个指针的值(地址的值),而不会保存指针指向的数据或者空间。


线程退出的时候也是不会自动回收pcb的,而是等待其他线程去回收,只有被回收之后,他的pcb才会被释放,有点类似于僵尸进程的问题,都是内存泄漏。
同时我们也发现,线程的等待不需要关注信号的,因为等待线程我们只关心正常退出,如果是异常引起的操作系统发送信号而退出的话,那么整个进程都退出了,不会有我们去等待线程的机会,等不等待都没有意义了。
任何一个线程都可以去回收已经退出的线程,只要他能拿到该线程的tid,因为调用pthread_join必须要传要回收的现成的tid。
2.4 线程取消
线程取消也是一种线程退出的方式,不过他不是自己调用取消自己,而是由别的线程取消

线程取消也是需要知道要取消的线程的tid , 当然我们一般是主线程调用来取消新线程,那么线程可以自己取消自己吗?我们可以试一下。


我们发现自己取消自己并没有成功终止,而是继续往后执行到了我们的return。
那么我们再来试一下由主线程来取消它。


主线程取消成功。 同时如果是被取消的线程,他的退出结果就是 (void*) -1 ,也就是 PTHREAD_CANCELED这个宏的值。
2.5 线程分离
在默认情况下。我们创建一个新线程他的状态是 joinable ,也就是该线程退出之后需要被join,否则无法释放资源,造成内存泄露。
但是我们也说了,pthread_join 只能阻塞式的等待线程,那么join 对于主线程来说就是一种负担,那么能不能不需要主线程来join,而是线程退出之后就自动释放资源呢? 这种策略就叫做线程分离
线程分离的接口是 pthread_detach ,

该函数需要一个参数,就是要分离的线程的 tid ,同时要求传的 tid 所代表的线程必须是 joinable 的,否则就出错。
线程可以自己将自己分离,也可以由其他线程诸如主线程来将某个线程分离。
就算线程分离了,他用的资源还是我们的进程的资源,分离的作用就是退出之后自动回收。
那么我们来试一下线程调用函数来分离自己
我们可以使用 pthread_self 函数来获取自己的tid
void* start_routine(void* arg)
{pthread_detach(pthread_self());return (void*) 66;
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,start_routine,(void*)&tid);void* ret;int n=pthread_join(tid,&ret);if(n!=0){std::cout<<"等待失败,错误码是:"<<n<<std::endl;exit(1);}(void)n;std::cout<<"线程退出结果:"<<(long long)ret<<std::endl;return 0;
}
那么为什么我们的主线程去等待的时候还是等待到了该线程的退出结果呢?不是说线程分离之后就不可以join了吗?
注意我们上面的程序并没有让sleep休眠或者什么的,所以说,我们的主线程和新线程谁先被调度是不确定的,那么就有可能先执行我们的主线程,然后我们的主线程并没有休眠或者其他的什么行为,直接就调用 join 进行等待了,注意这时候新线程还没有将自己分离,那么他的状态还是 joinable的,那么主线程这时候调用 join 是不会出错的。 然后主线程就阻塞了,cpu调度我们的新线程,这时候新线程再将自己分离,可是他不影响我们的主线程的join,因为这时候主线程已经在阻塞式的等待新线程的退出了,知道新线程退出,我们的主线程才会被唤醒去回收新线程的退出结果。
那么我们如果让主线程先 sleep 一下,那么就能看到我们想要的结果了。

这就告诉我们一个道理,我们让新线程自己去取消自己是不靠谱的,因为我们不知道新线程调用分离和主线程调用join哪个顺序在前面。
那么如果我们要保证新线程分离在主线程join之前要怎么做呢? 这还不简单?我们直接在主线程来调用 detach 分离新线程,这样我们是能够确保 detach 在join前面的,因为我们可以通过代码的顺序来控制。
以上就是线程的控制相关的常用接口了,那么接下来我们来谈一下Linux的原生线程库
3 原生线程库
任何语言要在Linux中实现多线程,必定要使用到原生线程库。当然一般的语言的线程库还是会封装一层pthread库的,就比如我们的C++,C++的线程库中也对pthread库进行了封装,不过我们的重点不在这里。
我们主要是要学习线程库的一些知识来搞清楚创建线程返回的tid和我们的lwp有没有关系,以及怎么实现每个线程都有自己的独立栈?
虽然我们的操作系统没有提供创建线程的接口,但是提供了一个原生线程库,能够让我们像使用真正的线程一样使用它所提供的轻量级进程。 虽然Linux用pcb模拟实现了线程,但是pcb毕竟是为进程天然设计的,而我们的线程还有一些进程所不具备的属性比如私有栈,是否分离以及线程id这样的字段,而pcb中是没有的,总不能强行塞进去。 因此 ,线程库中就必须为我们维护一些线程所特有的属性的集合,其实就是维护一类数据结构,不过这里的数据结构相比pcb或者专门为线程设计的数据结构肯定是要简单的多的。
同时,我们的操作系统中可能同时存在多个线程,那么我们的线程库就需要维护多个线程的属性的数据结构,需要对他们进行管理。我们也可以是用 ps -aL 命令发现,我们就算没有自己创建线程,操作系统内也是有线程的存在的,这就说明了我们的原生线程库一般都会加载进内存中,当然是动态库版本,那么他是有能力做着一些与操作系统类似的工作,也就是管理这些线程。
那么线程库所维护的线程属性的数据结构类型是什么呢?他的其中一个子集我们在pthread_create中就已经见过了,就是 pthread_attr_t ,他其实是一个联合体。当然她肯定不是线程库中描述线程的所有的属性,让用户设置的肯定是一部分属性

它里面就是一段固定大小的空间加一个 ,long int 的字段, 数组的大小一般是56字节,线程的属性字段会按照特定的要求填充到这个数组中, 每一个字段都有其对应的含义,这时在线程库中规定好的。
那么,每次创建一个线程,在线程库中就会相应创建一个描述线程的结构体,然后再调用clone来完成创建一个pcb,来提供线程的调度属性,这样完成对线程的控制与管理。
也就是说,每一个线程的数据结构对应一个系统中的轻量级进程,也就是一个执行流,而我们的线程的数据结构又不是由操作系统管理,而是由我们的线程库管理,所以Linux的线程也被称为用户级线程,用户关心的线程属性在库中,而内核数据结构提供执行流的调度属性。
那么在Linux中 用户级线程:内核轻量级进程 = 1:1 ,属于一 一 对应的关系,每一个用户级线程都是用轻量级进程模拟实现的,而内核轻量级进程本身就是为了模拟线程,自然就是1:1.
那么用户级线程的 tid 到底是什么呢?跟我们轻量级进程的lwp有什么关系?
我们知道,地址空间中有一段区域是共享区,而我们的线程 动态库加载到内存之后就是映射在共享区的。
关于线程的 关键属性有三个,分别是 struct ptherad 结构体,它里面描述的就是线程的属性,然后还有一个就是线性局部存储,这个我们一会也会讲到,还有一个重要的就是线程的私有栈 ,我们把线程的控制块称为tcb

我们每创建一个线程,就需要在线程库中创建一个这样的数据结构,而所有的线程的数据结构肯定是要以特定的数据结构来管理的,我们就假设他们以数组的形式保存

而我们要对一个线程进行控制,只需要找到对应的库中的tcb就行了,那么如何找到对应线程的数据结构呢?当然最简单的就是拿到他的起始地址啊,而我们的 tid 就是我们的线程tcb的起始地址,当然我们所拿到的地址都是虚拟地址,这也就是为什么我们的 tid 的值都很大,因为我们的共享区的地址本来就很大,同时也证明了为什么我们拿到 tid 就能够对线程进行一系列的操作了。那么这个 tid 和我们的轻量级进程 lwp有什么关系呢? 其实关系不大,因为我们们的轻量级进程是用来描述一个执行流的,在Linux中的表现就是一个轻量级进程,他是cpu调度的基本单位。但是我们的tid 是线程库中用来描述线程的 ,就好比我们的struct FILE 和文件描述符 fd 一样,他们一个是语言层面或者库层面,一个是操作系统内核层面的东西。不过也不用担心,tcb中一定也会有他的pcb的联系方式。
同时,我们说线程退出之后要在库里面保存他的退出结果,其实准确来说就是在对应线程的 tcb 中保存,而当我们使用 join 去等待线程的时候,就是通过 tid 找到对应的 tcb ,然后等其退出之后拿到退出结果,同时释放掉线程的tcb。
同时,我们也在tcb中看到了线程的私有栈,我们每一个线程都有自己的私有栈,而私有栈就是保存在tcb中的,当然主线程是直接用地址空间的栈,由操作系统维护。而其他的线程的栈结构就由我们的线程库所维护了,虽然主线程用地址空间的栈,但是也会在tcb'中体现出来,同时主线程也会由structp thread 和线程局部存储等结构
那么是怎么让操作系统看到我们的线程私有栈的呢?
原因就在于 clone 传的child stack 参数,底层创建轻量级进程还是由操作系统创建的,但是我们的库封装了clone ,在调用clone的时候就指明了我们所创建的轻量级进程 要用的栈空间的起始地址。那么后续我们的cpu在执行新线程的时候,用的就不是地址空间的栈,而是使用线程的私有的栈,也就是我们的tcb中的栈空间。
那么完整的逻辑就是: 我们创建新线程,首先线程库中会创建对应的tcb,tcb的起始地址就是返回给我们的 tid ,同时在tcb中为我们要创建的轻量级进程分配一块栈空间,以及设置好我们传入进去的回调方法和参数,然后用这些作为 clone 的参数创建一个轻量级。
所以线程的独立栈其实是在线程库里,也就是我们的动态库,那么他映射到的就是地址空间的共享区。而我们所有的tid就是线程的tcb映射到共享区的起始地址。
谈一谈线程的局部存储
我们说过全局变量是被所有线程共享的,所有线程访问的时候访问到的都是同一块空间,所以我们也说他缺乏访问控制。


这时候全局变量是共享的。
但是当我们如果在定义全局变量的时候加上一个 __thread 来修饰,那么程序结果就是这样的:
__thread int cnt=0;

这时候我们能够发现两个现象,首先主执行流的 cnt 不再随着新线程的操作而改变了,他们已经不是同一块空间了,也就是我们的线程不再共享一个cnt了,而是各自都存储了一份cnt。 其次,不管是新线程还是主线程,这次取出来的cnt的地址的值都很大。
添加了__thread 之后,可以将一个内置类型设置为先行局部存储
什么是线性局部存储呢?就是变量依旧是可以说变量,只不过编译的时候给每个线程都来了一份,线程自己用自己的,而不会影响别的线程。
为什么地址会变大呢?
我们的局部存储是在共享区的,而原来的全局变量是存在已初始化数据段的,地址自然就变大了。
接下来我们可以是用C++的语法,来封装一下原生线程库,也就是封装一个类类似于原生线程库的概念,但是是以面向对象的方式来操作。
那么首先这个类的成员就至少有 3 个,因为我们之后要传给 pthread_creat 的参数也要三个。构造函数我们只需要传两个参数就行了,因为tid没必要让用户传。
class Thread
{using function<void*(void*)> func_t;
public:Thread(func_t func,void*arg):_func(func),_arg(arg){}private:pthread_t _tid;func_t _func;void* _arg = nullptr;
};那么类似于C++的线程库,我们提供一个start和一个join接口,用来创建线程和等待线程。
正常来说,我们直接这样写就行了
void start(){int n = pthread_create(&_tid,nullptr,func,_arg);assert(n==0);(void)n;}void join(void** ret){ int n = pthread_join(_tid,ret);assert(n==0);(void)n;}但是,我们编译的时候就会发现一个问题。

问题就出在了start,我们调用pthread_create的时候,本来是要传一个函数指针的,可是我们传了一个 function 的类型,我们的接口是C语言的接口,解析不了 C++ 的function ,但是由于C++中我们可能用的就是function,function也可以接收C语言的函数指针的参数,是用function更符合C\C++的混编,所以我们要进行一层转换,怎么转换呢?无非就是在类内部再写一个函数,间接去执行func就行了。但是还是会有一个问题,就是内成员函数是会自动传一个this指针的,而我们的线程函数则不需要额外的参数,同时必须是void* 类型的,那么我们就需要设置为静态成员函数。
void start(){int n = pthread_create(&_tid,nullptr,mystart,this);assert(n==0);(void)n;}
private:static void* mystart(void* pt){Thread* t=static_cast<Thread*>(pt);return t->_func(t->_arg);}我们进行了这样一层封装之后就能顺利传给create,并且执行用户传的线程函数了。

4 互斥 (锁)
多线程环境中,共享资源缺乏保护,具体有什么场景呢?如下的一段抢票的逻辑
int tickets=100;void* buyticket(void*arg)
{const char*name=static_cast<const char*>(arg);while(1){if(tickets>0){usleep(10000);tickets--;std::cout<<name <<"抢到了第"<<tickets<<"张票"<<std::endl; usleep(10000);}elsebreak;}delete[] name;return nullptr;
}我们一共创建四个线程来完成上面的抢票,我们会发现可能会出现以下的问题:

我们抢票抢着抢着就抢到负数去了,这是为什么呢?
问题就出现在了我们的共享资源没有被保护,那么直接原因是什么?我们想象一个极端场景,当票数为1时,我们的第一个线程进到了循环里面,然后if判断为真,也进来了,但是接着他可能由于一些其他原因,可能被阻塞或者挂起,然后第一个线程就被切换走了。接着我们的第二个线程第三个线程和第四个现场都是如此,每一个都进来了if判断,然后被切走了。最后当调度器又调度到了第一个线程,这时候线程继续执行后面的 减减操作和打印的操作,把票数减为 0 了,然后再次循环判断为假 ,那么1hao线程就退出了。这时候2号线程被切换回来也要继续往后执行,还是执行减减和打印操作,这时候票数就已经是负数了,线程3和线程4被切回来之后还是会进来这个判断,还是会对票数进行减减操作,于是就出现了我们的票数为负数的结果。
导致问题的直接原因就是线程在进入if判断之后,在执行减减操作之前被切换走了。虽然我们上面是用了 sleep 来模拟线程被切换的清空,但是有没有可能,就算没有休眠,我们的线程执行完if的判断之后,刚好时间片到了或者来了一个优先级更高的线程,导致他被挤走了,都是有可能的,所以我们这里的根本原因不是在休眠这里,而是在于我们的数据没有被保护起来。
在我们多个线程同时对一个共享变量进行修改的操作也是不安全的。就拿我们的++或者- -来说,虽然他在我们看来只是一条语句,但是转换为 汇编之后确是三条语句,1 将数据从内存中加载到寄存器,2 在寄存器上对数据进行加加或减减,3将寄存器的数据写回内存, 而在这三步之间,我们的线程是随时都有可能被切换走的,那么就会导致数据不一致的问题。典型的,我们假设线程A和线程B都是要对一个全局变量做减减操作,当我们的线程A执行到变量为1000的时候,这时候对其进行减减,刚执行完减减的第一步或者第二步,这时候线程A由于时间片到了被切走了,这时候,寄存器中保存的变量值就作为了线程A的上下文数据,在A被切换走的时候被A带走了。这时候线程B被调度起来继续执行减减操作,线程B我们就懒得考虑这种情况了,加入线程B将变量减到了1的时候被切走了,假设他的上下文数据中没有保存该变量的值也就是他并不是在减减的三步操作中间被切走的。之后线程A被切换回来了,那么线程A会接着之前的操作继续往后执行,也就是减减的第二步或者第三步,这时候对寄存器的数据进行减减之后,再将其写回内存,可是我们寄存器中存的可是 999 ,这时候写回内存,那么该全局变量的值又从1变成了 999 ,那么线程B做的事就白做了。
当然这种情况我们不好模拟,我们只能从原理和逻辑上将该案例将其出,总之,由于多个线程对同一个全局变量进行并发式的访问操作,最终导致了线程A和线程B的数据不一致问题或者数据安全问题。
那么要怎么解决呢? 加锁
在学习锁之前,我们先复习一下以前讲过的几个概念:
1 临界资源:被多个执行流进行安全访问的共享资源就叫做临界资源。也就是被保护起来的共享资源
2 多个执行流当中访问临界资源的代码称为临界区。
3 互斥:任何时刻,保证只有一个执行流进入临界区,这就叫做互斥访问
4 原子性:不会被任何调度机制大段的操作,只有两态,没有任何中间态,要么完成,要么未完成。
我们上面的加加和减减的操作就是典型的不是原子性的操作,因为它转换为汇编代码之后需要三条语句才能完成操作,那么加加和减减的操作就不止两种状态。
我们现在可以用一个简单的方式来理解一个操作是否是原子性,就看他的汇编代码是否只有一条语句。 这是我们目前最容易理解的原子性的判断,但是这只是为了当前阶段方便理解,他并不是原子性的完整概念。
我们要加锁,锁是什么呢?
pthread_mutex_t
这就是我们要加的锁,说白了他就是线程库给我们提供的一个数据类型,我们也把他称作互斥锁或者互斥量。
他的相关接口:
首先一个自定义类型被定义出来,我们要对其进行初始化,初始化的接口:
pthread_mutex_init

我们有两种初始化的方式,如果定义的是局部的锁,那么我们就需要调用函数来进行初始化,调用函数的时候传该锁的地址就行了,属性我们可以传nullptr,默认属性就够了。
其实,如果我们定义为全局变量,那么我们可以直接使用PTHREAD_MUTEX_INITIALIZER 来初始化,当然也可以调用函数来初始化,只不过在定义的时候直接给初始值更加方便,这种方式只限于全局的锁。
同时。我们的锁用完之后也需要被销毁,销毁的接口就是上图中的
pthread_mutex_destroy
这个结构也没什么好讲的,传要销毁的锁的指针就行了。
全局的锁如果是直接用PTHREAD_MUTEX_INITIALIZER来初始化,那么我们就不需要关心他的销毁,他会在程序结束时自动销毁
要对一个公共资源进行加锁的解锁,我们也需要一定的接口,首先,加锁的接口为
pthread_mutex_lock

加锁其实不恰当,更确切地说是申请锁资源然后加锁,因为如果我们的锁已经被别人占用了,那么我们调用该函数就会阻塞在申请锁资源这里,被挂起,直到锁资源被释放,我们的现场再去与其他线程竞争这个锁
而加锁访问完公共资源之后,我们不能一直占有锁,用完了就把锁给释放掉,给别的线程用,那么对应的操作就是解锁对应的接口如下:
pthread_mutex_unlock
解锁就是将锁资源归还,那么该资源就有可以被其他线程访问了。
其实,我们把临界区的范围理解为一扇门,而我们的锁就是一把钥匙,只有拿到了锁的线程,才能进到临界区去执行临界区的代码,访问临界资源,而其他线程由于没有拿到锁,那么他们就只能在临界区之外干瞪眼,就是进不去临界区。而当我们拿到锁的线程访问完临界资源之后,就可以把所归还,也就是解锁,这时候其他需要锁的线程再被唤醒来竞争这把锁。
那么我们将上面的抢票程序修改一下逻辑,加个锁将我们的资源保护起来,如下:
int tickets=100;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;void* buyticket(void*arg)
{const char*name=static_cast<const char*>(arg);while(1){//临界区的开始pthread_mutex_lock(&mutex);if(tickets>0){//usleep(10000);tickets--;std::cout<<name <<"抢到了第"<<tickets<<"张票"<<std::endl; usleep(10000);//访问完解锁pthread_mutex_unlock(&mutex);}else{ //运行到这里也说明前面肯定拿到锁了,那么也需要解锁pthread_mutex_unlock(&mutex); break;}}delete[] name;return nullptr;
}
这时候我们发现了不管怎么样,我们的票数到0都会退出,不会再出现上面的票数减到负数的情况。
而我们运行程序的时候会发现,这次运行起来的速度比我们加锁之前的速度要慢的多,这就是我们加了锁之后的特点。
临界区被加上锁之后,只有拿到锁的线程才能进去执行,而其他线程就只能被阻塞或者挂起等待锁资源被释放。那么不管怎么样,我们的共享区在同一时刻最多只有一个线程在访问,也就是加了锁的临界区必须是被线程串行访问的,而不能够并行或者说同时访问。
同时,我们也发现了,上面的程序运行出来的结果有一点不合理,几乎都是一个线程把票抢完了,其他线程一直是处于阻塞等待锁资源的状态,虽然他的结果并没有出错,但是我们认为他很不合理,这是为什么呢?
因为我们的线程被调度之后,只有拿到锁才能去访问临界区。而在我们上面写的多线程抢票的代码中,第一个拿到锁的线程,在抢完票之后,释放锁,然后立马就又进入循环来竞争锁资源了,也就是说,第一个被cpu调度的抢票的线程是竞争力最强的。那么我们要怎么办才能让其他的线程也有机会抢票呢?正确的做法我们是要实现同步的,但是由于我们目前还没有学到同步,那么我们这里也可以用一个简单的法子,就是释放完所之后,先休眠一下,让该线程不能释放完后立马又去抢锁,那么其他线程就会在他休眠的时候去竞争锁了。

这时候我们就发现他们按照一定的顺序来抢票了。只不过这个顺序只是因为休眠而导致的。比如第一个线程抢完票之后,陷入休眠了,然后第二个线程竞争到了锁,然后抢完票也休眠,第三个第四个线程也是一样,当地四个线程也抢完票之后,这时候第一个抢票的线程还在休眠,我们四个抢票线程都在休眠,所以后面的顺序就都是第一轮抢票的顺序了。
我们的锁资源是线程库给我们维护的。
我们发现上面的代码,有一个分支语句,导致我么需要在两个地方都调用 解锁的函数,我们如果嫌麻烦,可以直接将整个临界区封装成一个代码块,那么在这个代码块的其实和结束位置加锁解锁就行了。
while(1){//将临界区封装成代码块{//临界区的开始pthread_mutex_lock(&mutex);if(tickets>0){//usleep(10000);tickets--;std::cout<<name <<"抢到了第"<<tickets<<"张票"<<std::endl; usleep(10000);//访问完解锁//pthread_mutex_unlock(&mutex);usleep(10000);}else{ //运行到这里也说明前面肯定拿到锁了,那么也需要解锁//pthread_mutex_unlock(&mutex); break;}pthread_mutex_unlock(&mutex); }}我们的锁只能够保证多线程互斥访问临界区代码和临界资源,并不能保证先后顺序,那么就只是谁竞争能力强,谁就先拿到锁。
当我们的一个线程拿到锁之后,只有该线程自愿释放锁,而不能被其他线程强迫释放。
锁的使用,除了定义成全局的和局部的,还能够定义成静态的,静态的锁如过定义成全局的也可以直接使用PTHREAD_MUTEX_INITIALIZER来初始化,程序结束时也会自动销毁。
如果是调用pthread_mutex_inti来初始化的话,就需要手动调用pthread_mutex_destroy来销毁。
我们也可以封装一个类,来完成锁的申请与释放。如下:
class Mutex
{
public:Mutex(pthread_mutex_t* mutex):_mutex(mutex){//构造的时候就直接加锁pthread_mutex_lock(_mutex);}~Mutex(){//析构的时候就解锁pthread_mutex_unlock(_mutex);}private:pthread_mutex_t* _mutex;
}封装成这样的优势是什么呢?我们可以将前面的加锁解锁的代码变成这样:
while(1){//将临界区封装成代码块{Mutex m(mutex);if(tickets>0){tickets--;std::cout<<name <<"抢到了第"<<tickets<<"张票"<<std::endl; usleep(10000);}else{ break;}}}我们只需要创建一个局部对象,就能够完成加锁的过程,而出了我们的作用域,局部对象自动调用析构函数,就完成了我们的解锁的动作,那么我们就不需要写那一长串的函数名了,只需要创建一个局部对象就能解决问题,很方便。这就有点像是我们的C++的智能指针,我们也把这类加锁和解锁的方式称为RAII风格的加锁。

那么我们从上面的一些案例和代码已经能摸清楚 锁 该如何使用了,但是,我们好像只是知道如何使用,对于他的一些理解还不够深。
首先来一个最直观的问题,如何看待加锁和解锁呢?
多个线程范围访问临界资源的时候,只有申请到锁的线程才能够进入临界区进行访问,那么其他的线程呢?我们上面说了是会阻塞或者挂起,也就是说,我们的线程还是在的,只是陷入了一种类似于休眠的状态,在加锁的逻辑中,如果申请锁失败了,那么就会调用一些指令将我们的线程设置为阻塞,那么我们的线程就肯定要被放到线程库的某个阻塞队列中。当然这些底层的我们也不关系,我们只关心,如何证明申请不到锁的线程就会陷入休眠呢?
我们可以用代码来验证,比如我们直接连续申请两次同一把锁,那么第二次申请肯定就不成功了,那么按照上面所说,就会阻塞住,而由于该线程是带着锁去休眠的,那么其他的所有线程也申请不到锁,那么我们看到的结果就是所有的线程都陷入休眠了。


因为我们的锁资源只有一个或者很少,同时锁资源又是限制线程访问某一个代码块的关键要素,那么我们为了提升效率或者说避免线程推进太慢,我们要尽量把临界区的长度缩小,只把最关键的访问临界资源的代码保护起来,其他的代码能不加锁就不加锁。
那么如何看待加锁和解锁的过程呢?
假如我们定义了一个全局的锁,那么我们的所有线程都能够访问到这个锁,那么锁本身就是一个共享资源,那么锁是如何保证他自己的安全的呢?
线程对锁的操作无非就是加锁和解锁这两个,那么只需要保证了这两个操作的原子性,我们就能保证锁的安全。
最简单的原子性就是保证拿到锁的过程是一条汇编语句,这样就不会存在中间态。当我们把锁拿到之后,就算我们的 pthread_mutex_lock 还没执行完返回,该线程被切走了,由于他已经把锁拿到了,那么其他的线程申请锁的时候也会阻塞在lock中。
那么对于加锁或者申请锁资源这个操作,我们的线程就只有两种状态,一种是锁是空闲的,那么我们的的状态就是拿到锁。另外一种就是锁已经被别人拿走了,那么去申请锁的线程的状态就是拿不到锁,阻塞。
那么我们的线程库是如何保证加锁和解锁的过程是原子的呢?
首先我们要理解,锁其实就是一个数据,那么加锁就是拿到了一个数据,那么我们就能访问临界区,而解锁就是将数据放会锁mutex中,然后其他线程就能够继续来竞争这个数据了。
我们的锁里面有一个int字段,叫做lock,如果该字段为1,就说明锁资源可以被申请,那么就可以成功加锁。如果该字段为 0 ,那么就意味着所正在被其他线程占用,那么就阻塞。
现在的关键就变成了如何保证 lock 字段 从0变1 (解锁)和 从1变0 (加锁)这两个过程的原子性。
为了实现互斥锁操作,大部分体系结构都提供了 swap 或者 exchange 这样的指令,该指令的作用是把寄存器和内存单元的数据相交换,由于他是一条指令,它必然是原子的,即使是多处理器平台,访问内存的总线周期也有先后,一个处理器上的交换指令执行时,另一个处理器的交换指令只能等待总线周期。
怎么理解呢?有了swap或者exchange就能保证加锁和解锁的原子性了?
我们知道,CPU的寄存器只有一套,被所有线程共享,但是寄存器中的数据是线程私有的,属于他的上下文数据。
而我们的锁是线程库里面定义的一种数据结构,我们就单独聊聊他的lock字段,因为是否有锁的关键就是该字段为1还是为0,那么我们就暂且将pthread_mutex_t当作int来看
首先我们的锁是在内存中保存的,而申请锁的过程其实有两条汇编指令

第一条指令的作用就是 寄存器的值置为 0 ,或者说把0拷贝到寄存器中。 这一步就是在为了exchange做准备。
第二条指令则是使用exchange指令,将寄存器的值与锁的值交换。

这一步有什么作用呢?exchange就相当于将锁拿到了我们的寄存器中,也就是拿到了当前线程的上下文中,如果锁的值是 1 ,那么exchange之后,锁的值就变成了0,而我们的寄存器的值就变成了 1 。在交换完之后,我们有一个if else 的判断,如果线程拿到的值是 1 的话,就说明我们的现场拿到了锁,那么就返回,执行我们的临界区的代码,这其实就是一个申请锁和加锁的过程。就算我们在执行完 exchange 之后被切走了,我们的上下文数据最关键的就是我们该寄存器中的 1 也被保存了,那么下次被切换回来的时候首先会恢复上下文,那么我们的寄存器中的1就被恢复了,于是线程会进入 if 的判断,也就是会拿到锁成功返回。而在这期间,如果其他线程也来竞争锁,他们的前两个指令执行下来,寄存器中的值还是 0 ,那么就会直接走 else,也就是会阻塞挂起。
通过exchange的原子性,就保证了多线程并发执行的时候,锁的安全性,锁不会被两个线程同时拿到,也就保证了锁实现互斥的功能。
那么解锁呢?解锁的过程对原子性的要求就没有加锁这么严格了,因为解锁的前提是拿到锁,而拿到锁的线程同一时间只有一个,那么这已经保证了解锁的安全性。当然为了保证真正的原子性,还是要通过具体的操作来保证。 解锁的操作就是直接将1写回内存 ,move 1 , mutex ,这一条汇编指令就完成了解锁的操作。解锁的时候,其实还会去做一件事,就是去唤醒在加锁时阻塞的线程,这样一来,解锁完马上就会被多线程竞争锁资源。
那么加锁和解锁的过程搞清楚之后,我们再来复习和学习几个概念。
首先我们之前讲过的重入,重入就是同一个函数被多个执行流调用,当一个执行流还没有执行完该函数,就在其他执行流中再次进入,这种清空就称之为重入
那么一个函数在重入的情况下,运行结果不会出现任何问题,这种函数我们称为可重入函数,反之我们就称为不可重入函数。
我们再来认识一个线程安全的概念
线程安全:多个线程并发执行同一段代码,不会出现不同界的结果,我们称之为线程安全。
我们常见的多个线程对全局变量或者静态变量进行操作,如果没有锁的保护,就会出现线程安全的问题。
这两个概念没有关系。函数的可重入与否描述的是函数的特征,而线程安全描述的是线程的特征,线程安全针对的是代码块,代码块不一定是函数。但是,我们的多线程出现的安全问题很多都是由于不可重入函数而导致的。
常见的线程安全的情况:
每个线程对全局变量或者静态变量只有读权限,而没有写入的权限,一般来说这些线程是安全的。
类或者接口对于线程来说都是原子操作,这种情况下线程是安全的。
多个线程之间的切换不会导致该接口的执行结果存在二义性。比如根本就没有访问共享资源
常见的线程不安全的情况:
不保护共享变量的函数
函数状态随着被调用,状态发生变化的函数,比如函数中用了静态或全局变量
返回指向静态变量指针的函数
调用线程不安全的函数
线程安全函数就是指的不会引发线程结果不同的线程函数,我们的可重入函数就是线程安全函数的一种。 反之,函数如果是不可重入的,如果被多个线程调用,可能会引发线程安全问题。如果函数中用到了全局变量,但是没有加锁保护起来,那么这个函数既不是线程安全也不是可重入的,如果加上锁,那就是线程安全的,但是只要使用了全局变量他就是不可重入的。因为可能会出现加上锁之后未释放锁就重入的情况。
常见的函数不可重入的情况:
调用了malloc/free函数,因为malloc是用全局链表来管理堆的。
调用了标准io函数,标准io库的很多实现都以不可重入的方式使用全局数据结构
可重入函数体内使用了静态的数据结构
总结起来就是,只要函数中使用了全局或者静态的数据,就是不可重入函数。
死锁
死锁是指在一组执行流(不管是线程还是进程),每个执行流在持有自己的锁资源的同时,还想方设法去申请对方的锁资源。 通俗来说,就是每个执行流都持有自己的锁,但是还想申请对方的锁,这种情况就会造成死锁 , 因为每个线程都在阻塞在了pthread_mutex_lock 上,都想着申请对方的锁资源。因为锁是不可抢占的,也就是申请下来锁之后,除非线程主动归还,否则锁资源永远在自己手上。
死锁会导致多执行流互相等待对方的锁,进而导致代码无法推进(永远等待)的问题。
最简单的案例就是 : 线程A和线程B都想拿到两把锁,锁1和锁2,线程A已经拿到了锁1 ,线程B已经拿到了 锁2 ,但是线程A和线程B都需要同时申请到两把锁才能访问某个共享区,这时候他们互相在等待对方释放手里的锁,但是显而易见,他们永远不会等待,这就导致了我们的代码无法推进。
死锁问题是程序员自己造成的,也就是说其实就是程序员写的bug。
我们可以总结出 死锁 出现的四个必要条件:
1 互斥 (这一点没什么好说的,互斥场景下才会需要用到锁)
2 请求与保持,请求就是申请对方的锁,而保持就是不释放自己手上的锁。
3 不剥夺,不剥夺就是保证锁资源不可抢占,只能够由线程自愿释放
4 环路等待条件,就是说自己的锁不释放的同时,等待对方的锁,这个等待关系形成了环路。
那么解决死锁我们只需要破坏其中一个条件就行了,第一个条件是无法破坏的。
第二个条件很好破坏,我们的线程在申请锁的时候,如果申请第一把所成功,但是申请第二把所失败,那么就把第一把锁释放了,然后再去休眠,而不是保持第一把锁。pthread_mutex_lock是阻塞式的等待,我们没有机会在申请失败的时候返回来释放第一把锁,那么我们需要换一个接口,也就是使用pthread_mutex_trylock ,从名字也可以看出来,他肯定不是阻塞式地申请锁,是非阻塞式的,如果返回

pthread_mutex_trylock只有在返回值为 0 的时候才是申请锁成功,其他情况下我们都认为不成功,这时候我们就可以先释放我们的当前手中的锁,然后主动去休眠一下再继续会来竞争锁
破坏第三个条件,也就是让我们的线程之间可以抢占式的争夺锁,毕竟线程的函数都是我们自己写的,我们可以制定一些策略比如优先级高的先拿到锁或者可以抢占别人的锁,不过这只是理论,实际上没有试过,或许可以通过设置锁的属性来实现?
破坏第四个条件就是我们不要出现环路等待,怎么保证了?我们让所有线程申请锁的顺序一样,那么只有申请到第一把所的线程才有资格去申请剩下的锁。
避免死锁的算法: 死锁检测算法和银行家算法 , 大家可以自行去查阅资料了解一下。
关于死锁检测:我们要了解一个概念,就是一个线程申请的锁另一个线程可以释放吗,可以。因为我们的锁的释放的汇编代码中,并不是将寄存器中保存的1写回内存,而是直接将 1 写回内存。而我们上面写的线程之所以释放不了锁,是因为我们上面的代码只有申请到了锁才能接着往下走,否则就永远阻塞在了申请锁的函数中,那么其他线程自然就走不到解锁的函数。
但是如果我们搞一个管理线程或者检测线程,专门用于监测我们的线程是否无效尺有所,比如我们检测到有一个线程持有锁,但是它的代码一直没有推进,这就说明她是无效持有锁,可能因为某些原因浪费了我们的锁资源,那么线程就会直接解锁,释放锁资源,让其他线程去竞争。
为了避免出现死锁,我们归根结底还是要避免使用锁,在实际工程中,我们的代码中能不用锁就不用,能用少量的锁达到目的就不要定义太多的锁。
5 线程同步
线程同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题。
就好比我们一开始写的抢票程序,每一个线程在抢完票之后解锁,马上就进入新一轮的抢票,这就导致了,自始自终可能只有一个线程能抢到票,因为每次他一释放锁资源立马又把锁资源申请了,而其他线程看了能刚被唤醒放到运行队列,但是他们还是申请不到锁,因为锁资源绝大多数情况下还是掌握在释放锁的线程上。 那么这就导致了其他线程的饥饿问题。
我们可以设定,在一个线程释放完锁资源之后,他无法立即申请锁资源,而是要在一个申请队列中排队,那么此时我们就在保证了数据安全的前提下,让我们的多线程按照一定的顺序进行临界资源的访问,避免了饥饿的问题,这就叫做线程同步。
线程同步在保证正确的前提下,让我们的多线程执行更加合理,并不会因为某一个现场竞争能力强,导致其他线程获取不到资源,产生饥饿问题。
那么为了支持线程同步,我们需要引入生产消费模型和条件变量。我们在这里只是讲了线程同步的概念,但是我们后面的内容中基本都是在实现线程的同步与互斥。 由于同步光讲概念,代码不好实现,必须结合后面的条件变量和生产消费模型才能有一个场景来完成同步,那么同步的代码基本都是整合在下面的。
6 生产消费模型
生产消费模型是什么?我们可以从我们的实际生活作为切入点来理解生产消费模型。比如我们去一个超市进行消费,那么我们就是消费者,生产这是谁呢?供货商或者说是厂家,而超市只是作为一个交易场所,方便消费者进行消费。 我们可以想象一下,如果没有超市,那么消费者只能够直接找工厂进行购买,而由于工厂一般不会囤货,所以只能在消费者去购买的时候才开始进行生产,一来这会浪费消费者的时间,因为在厂家在生产商品的时候,消费者只能阻塞式的等待。二来,这对于厂家来说不划算,因为单个的消费者的需求肯定不会太大,而厂家生产商则需要很大的成本,那么就会出现利润掩盖成本的问题,同时在消费者来消费之前,厂家也没事情干,浪费效率与资源。这种情况对于消费者和生产者而言都是不利的。那么我们就需要一个超市的角色,超市能够集中附近的消费者的需求,同一向供货商进货。同时由于需求一般很大, 那么厂商并不一定要在消费者购买的时候才开始生产,而是在任意时间,只要超时中的货物量已经很少的时候,工厂就可以开始生产商品,生产完商品时候直接交给超市,由超市将商品提供给消费者。 同时消费者也是直接在超市进行消费,直接拿现成的商品,而不需要等待商品的生产周期。在消费者在超时进行消费的时候,供货商可能在生产商品,也可能在休眠,他们两个没有必要的练习。同时,供货商在生产商品的时候,消费者也有可能在干其他的事,也有可能就是在消费。
因为有了交易场所超市的存在,那么生产和消费的过程在一定程度上解耦了。
如果超市中的商品一直是满的,没有人购买,那么供货商还需要继续生产吗?不需要了。 如果超市空了,那么消费者还能继续消费吗?也不能。 同时,由于超市既可以被消费者访问,也可以被生产者访问,那么超市就是一个公共资源,需要一定的互斥属性。 消费者与消费者,生产者与生产者必须是互斥的,否则超市的资源就会出现不一致的问题。同时,超市中生产者和消费者能够同时操作吗?不能,因为可能生产者在放货的时候,还没有计入超市的货物的总数,就被消费者拿走了,这时候也会出现数据不一致的问题。
最后,当超市货物空了之后,如果生产者由于一些原因无法补货,那么作为消费者有必要时时刻刻都前往超市查看是否有货物吗?可以,但是效率太低了,我们完全可以让超市在收到生产者的货物之后再通知消费者来消费。 同样,如果商品一直没人买,那么供货商还有必要一直生产商品,一直询问超市是否需要补货吗?也不需要,而是在货物量少了之后由超市通知生产者进行生产活动。总结下来就是,超时货物多了,联系消费者来消费,超市货物少了,联系生产者进行生产。让生产过程和消费过程协调起来。
上面的生活案例讲完了,我们再来总结一下生产消费模型的特点:
”321原则“
3:三个关系:生产者与生产者互斥关系,消费者与消费者互斥关系,生产者与消费者同步与互斥关系。
2种角色:生产者(线程),消费者(线程)
1个交易场所,缓冲区
为什么生产者与消费者要有同步关系呢?很简单,同步关系就是要按照特定的顺序。当我们的消费者和生产者都来访问资源时,如果资源是满的,那么就必须先由消费者进行消费之后,生产者才有空间放数据。当资源是空的时,就必须先由生产者进行生产数据,消费者才有数据消费。如果不是这两种特殊情况,那么就维持互斥关系就够了,按照各自的竞争力来争夺访问资源的先后顺序。
生产消费模型的特点:
1 生产者线程和消费者线程解耦
2 由于缓冲区的存在,能够支持生产和消费在一段时间的忙先不军的问题
3 提高效率(这一点我们在实现生产消费模型之后就会讲到,要通过具体的代码才能体现出来)
三个关系中,互斥的关系我们目前已经能够通过锁来实现了,而同步关系我们就需要以来下面的条件变量来完成。
7 条件变量
当一个线程互斥访问某一份共享资源时,假设就是 加锁 判断 操作 解锁 这样的逻辑,如果我们的生产者的竞争能力强,那么每次都是生产者拿到锁,而消费者一直申请不到。 那么就算生产者将我们的共享资源的空间都生产满了, 这时候加锁之后判断为假,然后解锁,继续申请锁,那么生产者就会一直 加锁 判断失败 解锁 这样的循环。但是我们知道,当判断失败之后,我们生产者的条件就已经不满足了,那么后面的加锁都是没有意义的了,浪费锁资源。 于此同时,我们的消费者线程却一直拿不到锁资源,导致了消费者线程的饥饿问题。所以我们光有互斥是不够的,还需要同步关系。
那么我们就需要,当某一个条件 不满足 时,我们就不再让我们的线程继续申请锁和释放锁,而是让线程去等待,把锁资源让给别的线程,直到条件又满足,再继续来竞争锁资源执行线程函数。
而完成这样的策略我们就需要条件变量?
什么叫做条件变量呢?和我们的互斥锁一样,无非就是一种线程库提供给我们的数据类型,以及提供的一系列使用的接口。
首先,条件变量的数据类型是
pthread_cond_t
我们只要知道条件变量是这种类型,每一个条件变量的底层由我们的线程库维护了一个类似于阻塞队列的队列就行了。
同时,条件变量也需要初始化和销毁
pthread_cond_init
pthread_cond_destroy

接口和锁的接口类似,都是POSIX标准的接口,头文件还是 pthread.h ,同时全局的条件变量我们可以直接使用 PTHREAD_COND_INITAIALIZER 来进行初始化,如果使用这种方式,我们就不需要手动释放。而如果采用的是调用 init 函数来初始化,那么需要我们手动去调用 destroy 来销毁。
在我们的生产消费模型中,线程申请到锁资源之后,首先是需要访问我们的共享资源来判断是否满足生产或者消费的条件的,如果满足,我们就继续执行线程的代码,如果不满足,就不能在往下执行了,而是应该在对应的条件变量下去进行阻塞等待。
那么如何将我们的线程放到条件变量的阻塞队列中呢?
pthread_cond_wait

pthread_cond_wait 就是将调用的线程放到指定的条件变量下去等待。 它需要两个参数,一个是指定条件变量的地址,而他还需要一个参数就是 锁 的地址。为什么需要锁的地址呢?我们在接下来的代码中就能理解。我们可以发现,这个接口是不需要传线程tid的,因为这个接口是把调用该函数的线程放到等待队列中。
也可以使用 timewait的接口,这个接口就是在等待的时候设定一个时间片,当时间片耗尽之后自动返回,而不需要主动唤醒。
而当我们的线程的某些条件又满足时,我们又需要将对应的条件变量下的线程唤醒,这时候我们需要使用
pthread_cond_signal

唤醒的时候有两个接口,一个是 signal ,这个接口是用来唤醒该条件变量下的一个线程,而如果是broadcast的话,就是唤醒该条件变量下的所有线程。
条件变量的基本的接口就是这几个,但是我们光了解接口还是不够,我们还需要对条件变量有一个更深的理解。
如何理解条件变量?
在我们的条件变量下,肯定是维护了一个PCB的队列,当某一个执行流申请某一个资源部就绪的时候,这个线程的PCB就放到该条件变量下的阻塞队列中,这就是为什么我们能够让一个线程阻塞等待。而当某些条件满足时,通过其他的线程调用 signal或者broadcast来唤醒来条件变量下的线程,本质上就是将他们的PCB放到CPU的运行队列中去继续运行,这就是唤醒的过程。
我们要让一个线程去条件变量下等待,wait的时候需要传一个锁的指针,也就是说我们的条件变量必须配合锁来使用,因为条件变量本身是不具备互斥的功能的,互斥是由锁来保证的。
那么我们的所有的线程或者说需要满足某些条件的线程都必须要能看到这个条件变量,也就是说,条件变量本身就需要是一个共享资源。我们一般把它设为全局的,当然也可以通过线程函数的参数传递。
比如我们可以把抢票的逻辑写成这样:
//新线程的while内部的逻辑//将临界区封装成代码块{pthread_mutex_lock(&mutex);//临界区的开始//不管怎么说,进入临界区都先去条件变量下等待,直到别的线程唤醒pthread_cond_wait(&cond,&mutex);if(tickets>0){tickets--;std::cout<<name <<"抢到了第"<<tickets<<"张票"<<std::endl; }else{ break;} pthread_mutex_unlock(&mutex);}那么我们可以设计让主线程每隔一段时间唤醒一个该条件变量下的线程来进行抢票的操作,
//主线程while(1){pthread_cond_signal(&cond); //主线程每隔一段时间唤醒一个该条件变量下的线程usleep(10000);}这时候,多线程抢票的时候就是按照一定的顺序来进行的了,按照他们第一轮被调度的顺序,循环式的进行抢票,就完成了多线程的同步。
8 基于阻塞队列的生产消费模型
我么需要一个实例设计来理解我们的生产消费模型和线程同步的概念,否则就光看上面的概念是不足以支撑我们理解的。
首先,阻塞队列 blockingqueue ,是一种在多线程中常用于实现生产消费模型的数据结构。
那么他有什么特点呢?
1 当队列为空时,从队列中获取元素的操作将会被阻塞,直到队列中放入数据。
2 当队列为满时,向队列中存放元素的操作将会被阻塞,直到有元素被从队列中取出。
简单来说,阻塞队列就是一个长度固定的队列,也就是我们的生产消费模型中的交易场所。当阻塞队列满了的时候,我们就需要限制生产的行为,因为已经没有位置让生产者继续放数据了。而当队列为空时,就需要限制消费的行为。
我们的消费者线程就只负责从队列中拿数据,生产者就只负责从队列中取数据。
那么实现生产消费模型,就需要保证他的 “321” 原则。
先从最简单的写起,我们先实现一个单生产者单消费者的模型,就是只有一个生产者线程和一个消费者线程,那么这时候我们只需要保证这个生产者和这个消费者之间的同步与互斥关系就行了。
不管怎么说,首先还是要将我么的阻塞队列以及他的操作封装成一个类。
那么它需要哪些成员呢?
首先对于消费者而言,需要一个条件变量,在消费的条件不满足的时候,消费线程需要在该条件变量下等待。 对于生产者而言,也需要一个条件变量,当生产的条件不满足的时候,生产线程需要到该条件变量下等待。
其次,我们的阻塞队列本身就是一个被生产者线程和消费者线程所共享的资源,交易场所,也需要保护起来,必须保证对他的互斥访问,那么还需要一个锁来保证互斥。
还需要一个队列来模拟实现阻塞队列,我们可以直接用C++的queue来实现。
最后还需要一个变量来保存我们的阻塞队列中所允许的最大数据个数,当然这个可以通过模板进行传参。
template<class T , size_t maxsize = 5 > //可以给缺省参数来给出最大容量
class BlcokQueue
{
public:BlcokQueue():_maxsize(maxsize){//对锁和条件变量进行初始化pthread_mutex_init(&_mutex,nullptr);pthread_cond_init(&_consumer_cond,nullptr);pthread_cond_init(&_productor_cond,nullptr);}~BlcokQueue(){//销毁锁和条件变量pthread_mutex_destroy(&_mutex);pthread_cond_destroy(&_consumer_cond);pthread_cond_destroy(&_productor_cond);}private:size_t _maxsize; std::queue<T> _bq;pthread_mutex_t _mutex;pthread_cond_t _consumer_cond; //消费者等待的条件变量pthread_cond_t _productor_cond; //生产者等待的条件变量
}有了基本的框架之后,我们就要考虑如何让生产者向我们的阻塞队列中放数据,我们肯定需要提供一个接口来实现。
在放数据的时候,我们只需要先判断一下队列是否为满,如果未满,我们的生产者就需要进入条件变量进行等待。 但是直接去等待就完了吗?他是不是应该先提醒我们的消费者线程来进行消费?如果我们的消费者线程也一直在等待呢?那么谁来唤醒消费线程呢? 所以我们必须在 生产条件不满足的时候,在生产者去等待之前,要试着唤醒在消费者条件变量下等待的消费线程。
//放数据void push(const T& data){//第一步就要拿锁, _bq 必须要被保护起来,互斥访问pthread_mutex_lock(&_mutex);//判断是否满足生产条件while(_bq.size()>=_maxsize){//不满足生产条件,首先唤醒消费者线程,然后再去等待pthread_cond_signal(&_consumer_cond);pthread_cond_wait(&_productor_cond,&_mutex);}//走到这里说明满足生产条件了_bq.push(data);pthread_mutex_unlock(&_mutex);}这里我们为什么要用 while 来判断呢? 这是为了避免消费者线程唤醒生产者线程时,如果是多生产多消费的情况,且采用的是brocast,那么就可能会唤醒一批的生产者线程。可是一个消费者进来之后只能消费一个数据,那么如果同时唤醒多个生产者线程,并不是这些生产者线程都能进行生产的,每一次要进行生产前都需要再次判断一下是个满足生产条件。
然后就是我们的消费者线程,消费者线程逻辑也很简单,参照上面的放数据的代码就行。
//拿数据void pop(T* data) //输出型参数{pthread_mutex_lock(&_mutex);while(_bq.size()==0) //判断是否满足消费条件{pthread_cond_signal(&_productor_cond);pthread_cond_wait(&_consumer_cond,&_mutex);}//进行消费行为*data=_bq.front();_bq.pop();pthread_mutex_unlock(&_mutex);}当然我们上面的唤醒策略也可以设置的更加合理,比如生产者在生产完之后,可以判断一下如果当前的数据个数超过最大数量的三分之二就去唤醒消费者。 同时消费者拿数据之后,在返回之前,可以判断一下当前数据个数如果小于最大个数的三分之一,就需要唤醒生产者来生产。不过我们这里就简单来搞了。
首先我们需要创建两个线程让他们进行生产和消费,创建线程的时候我们可以复杂一点,将传递给线程的参数尽可能详细一点,至少需要标识线程,我们可以使用一个结构体来传参,结构体中存的就是生产者和消费者需要看到的阻塞队列以及线程自己的编号或者名字。
template<class T , size_t maxsize=5>
struct Data //用于传给线程的数据
{Data(BlcokQueue<T , maxsize>* pbq,std::string name):_pbq(pbq),_name(name){}BlcokQueue<T , maxsize>* _pbq;std::string _name;
};int main()
{srand((unsigned int)time(nullptr)); //先用随机数模拟数据//首先我们需要有一个阻塞队列BlcokQueue<int>* bq =new BlcokQueue<int>; //然后创建两个线程pthread_t cons,prod;int connum=1;char conbuffer[64];snprintf(conbuffer,sizeof conbuffer,"consumer thread %d",connum++);Data<int>* condata=new Data<int>(bq,conbuffer);pthread_create(&cons,nullptr,consumer_start_routine,(void*)condata); //消费者线程int prodnum=1;char prodbuffer[64];snprintf(prodbuffer,sizeof prodbuffer,"productor thread %d",connum++);Data<int>* proddata=new Data<int>(bq,prodbuffer);pthread_create(&prod,nullptr,productor_start_routine,(void*)proddata); //消费者线程while(1) sleep(1); //主线程不退出pthread_join(cons,nullptr);pthread_join(prod,nullptr);return 0;
}
那么到此为止,我们的阻塞队列和主逻辑已经就绪了,剩下的就是要把生产者和消费者的线程函数的逻辑搞起来。
void* productor_start_routine(void* arg) //生产者
{Data<int>* pdata=(Data<int>*)arg;while(1) // 生产者需要做的就是不断生产数据{//先用简单的数据来模拟,测试一下生产消费的逻辑是否有问题int x = rand()%100; //生产数据 pdata->_pbq->push(x); //放数据std::cout<<pdata->_name<<" 生产了一个数据 : "<< x <<std::endl;//生产完一个休息一下usleep(100000);}return nullptr;
}void* consumer_start_routine(void* arg) //消费者
{Data<int>* pdata=(Data<int>*)arg;while(1) // 消费者需要做的就是不断消费数据{int x;pdata->_pbq->pop(&x); //放数据std::cout<<pdata->_name<<" 消费了一个数据 : "<< x <<std::endl;usleep(100000);}return nullptr;
}程序运行结果如下:

出现这种结果也在我们的预料之中,因为我们的阻塞队列中 push 和 pop 的逻辑就是只有为空或者未满时才去唤醒对方。 所以不管我们的cpu先调度哪个线程,最终都是生产者先生产 5 个数据,然后第6次生产的时候 ,由于队列满了,所以生产者会唤醒消费者,同时自身进入条件变量等待。而消费者也是如此,他是要消费到数据为空时才会去唤醒生产者。
那么如果我们想要他的逻辑更加合理,我们可以每次生产者生产完之后返回之前把消费者唤醒,消费者每次返回之前把生产者唤醒。

这时候就变成了生产一个消费一个。
我们如何证明这就是一个阻塞队列呢?可以让生产者和消费者的速度不同步,让生产者的速度大于消费的速度,看一下生产者生产满了是否还会继续生产。

我们能发现生产满了之后生产者就不会继续生产了,而是会唤醒消费线程,等他消费完在继续生产,如果此时消费者正在进行 sleep ,生产者也没办法,只能等待消费者醒来之后去消费。
上面的代码中我们可能会有一个疑惑?我们的生产者不是在临界区里面调用wait去条件变量下等待的吗?为什么消费者能拿到锁?这就是我们的pthread_cond_wait传锁的指针的意义了。
调用pthread_cond_wait函数的时候,首先会将线程传给他的锁以原子的方式,把锁释放,再将线程挂起。 而wait 结束,线程被唤醒的时候,并不是直接就能够回到临界区继续执行代码,而是在wait返回之前要申请锁,如果申请不到锁,那么wait还是会阻塞在这里,直到我们的线程拿到了锁,wait才调用返回。
我们的阻塞队列中除了能够放数据,还能够放任务,也就是相当于生产者生产任务然后将任务放进阻塞队列中,等待消费者拿走并执行任务,那么我们也可以实现以下生产者给消费者派发任务的阻塞队列。
我们就以简单的任务比如加减乘除取模这五个运算作为例子。
我们还是把任务封装成类,执行任务我们就以仿函数的形式执行。
#include<functional>
class Task
{
public:Task(){};typedef std::function<std::string(int,int,char)> func_t;Task(int x , int y , char op ,func_t func):_x(x),_y(y),_op(op),_func(func){}std::string operator()(){return _func(_x,_y,_op);}std::string tostring() //将我们的任务转换为字符串,方便提示{char buffer[64];snprintf(buffer,sizeof buffer ,"%d %c %d = ? ",_x,_op,_y);return buffer; }private:int _x;int _y;char _op;func_t _func;
};std::string mymath(int x ,int y ,char op) //数学计算的任务
{int result = -1;switch(op){case '+':{result=x+y;break;}case '-':{result=x-y;break;}case '*':{result=x*y;break;}case '/':{if(y==0){return "除0错误";}result=x/y;break;}case '%':{if(y==0){return "模0错误";}result=x%y;break;}}char buffer[64];snprintf(buffer,sizeof buffer,"%d %c %d = %d",x,op,y,result);return buffer;
}生产者可以通过随机数生成操作属于操作符,然后构造出一个任务,然后将任务推送到阻塞队列中。而我们的消费者可以在阻塞队列中拿任务,然后执行任务。
void* productor_start_routine(void* arg) //生产者
{Data<Task>* pdata=(Data<Task>*)arg;char ops[]="+-*\%";while(1) // 生产者需要做的就是不断生产数据{//先用简单的数据来模拟,测试一下生产消费的逻辑是否有问题int x = rand()%100; //生产数据 int y = rand()%100;char op = ops[rand()%5];Task t(x,y,op,mymath);pdata->_pbq->push(t); //放数据std::cout<<pdata->_name<<" 生产了一个任务 : "<< t.tostring() <<std::endl;//生产完一个休息一下usleep(1000);}return nullptr;
}void* consumer_start_routine(void* arg) //消费者
{Data<Task>* pdata=(Data<Task>*)arg;while(1) // 消费者需要做的就是不断消费数据{Task t;pdata->_pbq->pop(&t); //拿数据std::cout<<pdata->_name<<" 消费了一个任务,结果是: "<< t() <<std::endl;usleep(100000);}return nullptr;
}
这样一来我们就完成了生产者向消费者推送任务的生产消费模型。
目前还是但生产和但消费的模型,我们也可以将其改造成为多生产和多消费的模型,
我们将其改成多生产多消费需要什么工作吗? 什么都不需要,我们只需要创建多个生产线程和消费现场就行了,为什么呢?
我们思考一下, 改成多生产和多消费之后“321” 原则是否满足? 首先,生产者与消费者的同步与互斥是满足的,我们在单生产和单消费就是实现了这个工作。那么生产者与生产者之间以及消费者与消费者之间是互斥的吗?当然是,因为不管是生产者还是消费者,每一个线程要访问阻塞队列之前,都需要先申请锁才能进入临界区访问,而我们的所也只有一个,所以能保证同一时刻只有一个线程访问我们的临界区,那么他们的互斥关系其实我们都已经保证好了。

只不过上面的结果由于多线程访问输出缓冲区的原因,有些格式或者内容的错误。但是,我们能看出来,不会连续生产5个以上任务以及连续消费5个以上任务,我们的多生产和多消费的模型是保障了的。
那么如果我们还需要再创建一个线程,让该线程完成结果的存储的工作,这时候我们要怎么做?
也很简单,无非就是再创建一个阻塞队列,这个阻塞队列中放存储任务,由进行计算的线程计算完之后,将结果构建一个存储任务,然后推送到存储任务阻塞队列中,然后存储线程从存储阻塞队列中拿任务进行执行。
我们还是那单线程的模型来示范。
//存储任务
class storeTask
{
public:
typedef std::function<void(std::string)> func_t;storeTask(){};storeTask(std::string str,func_t func):_context(str),_func(func){}void operator()(){_func(_context);}private:std::string _context;func_t _func;
};void store_func(std::string str)
{const char* name ="log.txt";int fd = open(name,O_WRONLY|O_CREAT|O_APPEND,0777);write(fd,str.c_str(),str.size());close(fd);
}主逻辑
int main()
{srand((unsigned int)time(nullptr)); //先用随机数模拟数据BlcokQueue<Task>* bq =new BlcokQueue<Task>; BlcokQueue<storeTask>* storebq =new BlcokQueue<storeTask>; ;pthread_t cons,prod,store;int connum=1;char conbuffer[64];snprintf(conbuffer,sizeof conbuffer,"consumer thread %d",connum++);Data<Task,storeTask>* condata=new Data<Task,storeTask>(bq,storebq,conbuffer);pthread_create(&cons,nullptr,consumer_start_routine,(void*)condata); //消费者线程int prodnum=1;char prodbuffer[64];snprintf(conbuffer,sizeof prodbuffer,"consumer thread %d",prodnum++);Data<Task,storeTask>* proddata=new Data<Task,storeTask>(bq,storebq,prodbuffer);pthread_create(&prod,nullptr,productor_start_routine,(void*)proddata); //生产者线程int storenum=1;char stobuffer[64];snprintf(stobuffer,sizeof stobuffer,"store thread %d",storenum++);Data<Task,storeTask>* stodata = new Data<Task,storeTask>(bq,storebq,stobuffer);pthread_create(&store,nullptr,store_start_routine,(void*)stodata); //存储者线程while(1) sleep(1); //主线程不退出delete bq;return 0;
}
新Data
template<class T ,class T2 ,size_t maxsize=5>
struct Data //用于传给线程的数据
{Data(BlcokQueue<T,maxsize>* pbq,BlcokQueue<T2,maxsize>* sbq,std::string name):_pbq(pbq),_sbq(sbq),_name(name){}BlcokQueue<T , maxsize>* _pbq;std::string _name;BlcokQueue<T2 , maxsize>* _sbq;
};生产计算任务的线程逻辑:
void* productor_start_routine(void* arg) //生产者
{Data<Task,storeTask>* pdata=(Data<Task,storeTask>*)arg;BlcokQueue<Task>*bq=pdata->_pbq;BlcokQueue<storeTask>*sbq=pdata->_sbq;char ops[]="+-*\%";while(1) // 生产者需要做的就是不断生产数据{//先用简单的数据来模拟,测试一下生产消费的逻辑是否有问题int x = rand()%100; //生产数据 int y = rand()%100;char op = ops[rand()%5];Task t(x,y,op,mymath);bq->push(t); //放数据std::cout<<pdata->_name<<" 生产了一个任务 : "<< t.tostring() <<std::endl;//生产完一个休息一下usleep(1000);}return nullptr;
}消费计算任务以及生产存储任务的线程逻辑:
void* consumer_start_routine(void* arg) //消费者
{Data<Task,storeTask>* pdata=(Data<Task,storeTask>*)arg;BlcokQueue<Task>*bq=pdata->_pbq;BlcokQueue<storeTask>*sbq=pdata->_sbq;while(1) // 消费者需要做的就是不断消费数据{Task t;pdata->_pbq->pop(&t); //拿数据std::cout<<pdata->_name<<" 消费了一个任务,结果是: "<< t() <<std::endl;//构建一个存储任务storeTask st(t(),store_func);sbq->push(st);std::cout<<pdata->_name<<"推送了一个存储任务"<<std::endl;usleep(100000);}return nullptr;
}
存储线程逻辑:
void* store_start_routine(void* arg) //存储者
{Data<Task,storeTask>* pdata=(Data<Task,storeTask>*)arg;BlcokQueue<Task>*bq=pdata->_pbq;BlcokQueue<storeTask>*sbq=pdata->_sbq;while(1){ storeTask st;sbq->pop(&st);st();std::cout<<pdata->_name<<"完成了一个存储任务"<<std::endl;usleep(10000);}return nullptr;
}运行结果:


当然我们什么的代码还存在很多的小细节没有完善,比如:我们new出来的资源还未释放,这些资源我们都可以先用一个容器存起来,在主线程最后的时候释放。 同时,我们的存储的时候没有控制格式等等,还有一些小细节也没有完成,大家可以进一步完善一下。
那么我们所说的生产消费模型提高效率体现在了哪里呢?
好像我们看到的生产和消费还是互斥的啊,那里提升了效率呢?
我们的生产消费模型中,虽然访问阻塞队列的时候还是互斥的,在这一个方面并没有提升效率。
但是我们不要忘了,在实际中,我们的生产者生产任务并不是直接就有的,而是要从外部比如数据库以及网络等获取任务,然后还需要构建任务等,这些工作也是需要花费时间的,而我们的生产消费模型如果是多生产的情况下,我们的多个生产者线程就可以并行地从外界获取任务以及构建任务,那么这一些工作的效率是显著提高了的。
同时,我们的消费者虽然也是需要互斥的访问阻塞队列,但是拿到任务之后,消费者线程并不是就完了,还需要执行任务,执行任务也是耗时间的,那么在这个消费者正在执行任务的时候,其他的消费者线程也可以去阻塞队列获取任务以及执行任务,在这一方面也显著提高了我们的程序的效率。
生产消费模型提升效率并不是体现在对阻塞队列的操作上,而是体现在可以让多个线程并发的构建任务以及执行任务,线程在计算或者构建任务时,不影响其他线程对阻塞队列的操作(放任务,取任务)
虽然阻塞队列的push和pop时同步且互斥的,但是对于线程而言,其他的不在临界区得操作都是并行的
9 信号量
我们上面用阻塞队列实现了生产消费模型,他有什么不足吗?
它存在一个极大的问题,我们的生产和消费是需要满足一定条件才能进行的,但是要判断是否满足条件,首先需要拿到对应的锁,在没有拿到锁访问我们的阻塞队列之前,我们的线程是无法得知是否有生产或消费的条件的,我们检测是否满足条件的本质就是在访问临界资源。
但是申请锁的线程可是有很多的,我们的线程只能慢慢竞争到锁,如果判断条件不满足,那么有需要陷入等待队列,这有点扯,因为即使生产或消费条件不满足,我们的线程依旧需要申请锁,只有申请到锁之后才能得知条件是否满足,但是好不容易申请到锁,检测到条件不满足时,又要立马去条件变量进行等待,那么这锁不是白申请了吗?何况还有这么多线程要竞争这一把锁
最大的问题就是,线程无法提前得知公共资源的情况(可以理解为资源剩余数量)
有没有一种办法能够在访问公共资源之前就得知资源的状态呢?
信号量。
我们在进程间通信的章节就介绍过,信号量本质是一个计数器,他能够表征共享资源中剩余资源的多少。
那么我们只需要知道了剩余资源的多少,不就是知道了生产或者消费条件是否满足了吗?那么就不需要再煎熬的等待我们的锁。
我们的阻塞队列出现问题的最根本的原因就是:阻塞队列是整体加锁的。
只要我们对资源整体加锁,就默认了我们对这个资源整体使用,尽管你把资源进行了划分,但是同一时间只能有一个线程拿到锁,也就是只有一个线程能访问整份资源。
但是实际中我们是会对一份资源进行划分,同一时间允许不同线程访问不同的子资源的。
比如我们的生产者和消费者虽然都是要访问同一块资源,但是他们可能需要访问的不是同一个区域,生产者要生产的区域和消费者要消费的区域如果不是用一块,那么我们是可以让他们并发访问这一整块资源的各自一个小区域的,但是还是不能访问同一个位置,而生产者和消费者访问的问题是由我们程序员自己控制的。
这样一来,不管哪个线程要访问资源,首先要申请信号量,申请信号量成功,就意味着一定有一个位置给我们当前申请信号量的现场预留访问。
那么只要申请到了信号量,就在未来一定能够拥有临界资源的一部分,申请信号量的本质就是对临界资源的特定小块资源的预定机制。
同时,有了信号量的存在,我们就能在访问临界资源之前,就得知临界资源的使用情况。
因为现在我们的现场检测是否满足生产或消费条件并不需要真正访问临界资源,只需要申请信号量,如果信号量申请成功,就意味着一定能够进行消费或者生产。之要申请信号量失败,就说明当前不满足生产或者消费的条件,就需要阻塞。
我们就能用信号量的申请成功与否,来简介检测到临界资源的就绪与否,而不需要苦哈哈的等待锁,加锁然后检测,检测不满足就立马又滚蛋了。 也就是把检查的工作移除了临界区。
那么信号量需要什么操作呢?
信号量就是一把计数器,申请资源就是计数器减减,也就是我们说的 P操作
释放资源就是计数器加加,也就是我们的 V操作。
由于信号量本身就是需要被多线程同时访问的,所以信号量本身就是公共资源,那么信号量也许要被保护起来。如何保证信号量的安全呢?我们只需要保证PV操作的原子性就能够保证信号量的安全。
信号量的核心就是: PV原语 (原子语句)
那么接下来我们就看一下信号量相关的接口
首先,信号量的数据类型是
sem_t
POSIX的信号量需要包含头文件 semaphore.h,他也需要链接 pthread库来使用
信号量的初始化:
sem_init

三个参数,首先就是我们要初始化的信号量的指针,第二个是共享属性,传0表示进程内的线程间共享,传非0表示进程间共享 ,第三个参数就是信号量的初始值,这是由我们自己设定的共享资源的划分情况而定。
信号量的销毁:
sem_destroy

这个接口没什么好说的,和锁和条件变量的销毁没什么区别
信号量的PV操作
sem_wait

P操作有 3 个接口,我们大概也能看出来,sem_wait是阻塞式申请信号量,我们一般用这个就够了。sem_trywait是非阻塞式,sem_timewait是时间片式。
sem_post

V操作就是让计数器加加。
那么怎么使用信号量呢?下面我们就用一个具体的场景来使用一下
10 基于环形队列的生产消费模型
首先环形队列我们都应该认识,
环形队列中, 拿数据从对头拿,放数据往队尾放,在大多数情况下,放数据和那数据的位置都不是同一个。
但是环形队列会存在判空和判满的情况,也就是在 get 和 push 同一个位置的时候,既可能是 get 追上了push或者初始状态push还没开始放数据,这时候环形队列是空的 。 也可能是push追上了get,这时候环形队列是满的。
当环形队列为空时,我们要禁止从队列中拿数据的操作,当环形队列为满时,我们则要禁止向队列中放数据的操作。
我们把放数据的线程理解为生产者,消费数据的线程理解为消费者。那么在消费者和生产者指向同一个位置的时候,如果队列是空的,那么就必须要保证让生产者先生产数据之后,消费者才能从队列中拿数据,如果队列是满的,那么就必须要保证让消费者先消费数据,有了空位置之后生产者才能继续生产。那么就需要维护它们之间的同步关系。
而在其他的情况下,生产者和消费者都是各自访问一块区域,互不影响,是可以并发进行的。
那么要完成上面的逻辑,我们需要做的核心工作是什么?
无非就是判断生产条件是否满足和消费条件是否满足,只不过在这里由于我们是将资源划分为了不同的区域,那么我们就需要用信号量来衡量剩余资源的数量。
那么对于生产者和消费者而言,资源是什么呢?
对于生产者而言,资源就是队列中剩余的空位置,那么我们可以定义一个信号量来表示
对于消费者而言,资源就是队列中剩余的数据,我们也可以定义一个信号量来表示
这里当然可以只定义一个信号量,但是定义一个信号量我们又需要用数学计算来进行转换,而我们的数学计算都不是原子的,又要定义锁来保证计算的原子性,那么就又需要访问信号量以及计算的过程必须是互斥的,线程就无法并发推进了,不如直接使用两个信号量,让生产者和消费者能够各自访问各自的信号量,不需要进行转换,直接申请,申请成功就进去完成自己的任务就行了。
那么要把环形队列封装成一个类,它需要什么成员变量呢?
首先必须要有两个信号量,一个环形队列(用数组模拟实现),以及生产者和消费者各自要访问的位置,而队列最大容量也可以通过模板参数来传递。
template<class T,size_t maxsize = 10>
class RingQueue
{
public:RingQueue(){_rq.resize(maxsize);sem_init(&_consumer_sem,0,0);sem_init(&_productor_sem,0,maxsize);_consumer_index=0;_productor_index=0;} ~RingQueue(){sem_destroy(&_consumer_sem);sem_destroy(&_productor_sem);}private:std::vector<T> _rq;sem_t _consumer_sem; //消费者信号量sem_t _productor_sem; //生产者信号量int _consumer_index; //消费的位置int _productor_index; //生产的位置
};那么接下来就是生产的接口,push
首先要进行生产首先要申请信号量,P操作,申请成功就继续往后执行,但是向后执行就是访问资源,进行生产工作。如果申请信号量失败,那么线程就会阻塞在信号量维护的队列中,知道信号量大于0了,才会唤醒我们的生产线程。
但是生产完之后我么需要V操作来释放资源吗?生产者放完数据之后,并没有将该空间释放,并不会让剩余空间加回去,但是他会让数据多一个,也就是消费者所需要的资源会增多,那么我们要对消费者的信号量进行V操作。
void push(const T& data){//首先申请信号量sem_wait(&_productor_sem); //申请成功就继续往后执行,申请失败就阻塞,直到成功_rq[_productor_index++]=data; //放数据,同时需要更新下一次进来生产的位置_productor_index %= maxsize; //确保不会越界,因为我们是用数组来模拟环形队列的//对消费者信号量V操作sem_post(&_consumer_sem);}
如果只考虑单生产者线程的话,那么就已经写完了,但是如果是多线程场景,我们是需要保证生产者之间的互斥关系的,也就是生产者线程必须互斥访问资源,为什么呢?因为如果不保证互斥,那么多个生产者可能会将数据放在同一个地方,同时会导致我们的生产者的位置出现难以预料的结果。
所以,其实我们还需要为消费者和生产者定义锁,来保证生产者之间以及消费者之间的互斥。
那么增加锁之后的完整的代码如下
template<class T,size_t maxsize = 10>
class RingQueue
{
public:RingQueue(){_rq.resize(maxsize);sem_init(&_consumer_sem,0,0);sem_init(&_productor_sem,0,maxsize);_consumer_index=0;_productor_index=0;pthread_mutex_init(&_productor_mutex,nullptr);pthread_mutex_init(&_consumer_mutex,nullptr);} ~RingQueue(){sem_destroy(&_consumer_sem);sem_destroy(&_productor_sem);pthread_mutex_destroy(&_productor_mutex);pthread_mutex_destroy(&_consumer_mutex);}void push(const T& data){//首先申请信号量sem_wait(&_productor_sem); //申请成功就继续往后执行,申请失败就阻塞,直到成功//申请锁资源Mutex m(&_productor_mutex); //RAII风格的锁,也就是我们前面封装的一个类_rq[_productor_index++]=data; //放数据,同时需要更新下一次进来生产的位置_productor_index %= maxsize; //确保不会越界,因为我们是用数组来模拟环形队列的//对消费者信号量V操作sem_post(&_consumer_sem);}private:std::vector<T> _rq;sem_t _consumer_sem; //消费者信号量sem_t _productor_sem; //生产者信号量int _consumer_index; //消费的位置int _productor_index; //生产的位置pthread_mutex_t _consumer_mutex; //保证消费者之间互斥pthread_mutex_t _productor_mutex; //保证生产者之间互斥
};注意:加锁一定是在申请完信号量之后再加锁,因为我们的信号量的申请是可以并发执行的,我们加锁只是为了保证生产者之间访问生产位置时的互斥
消费过程我们依照生产的逻辑写就行了
void pop(T* data){sem_wait(&_consumer_sem);Mutex m(&_consumer_mutex);//拿数据*data = _rq[_consumer_index++];_consumer_index %= maxsize;sem_post(&_productor_sem);}那么接下来我们还是用Task数学计算类来测试,看一下生产者能否正确派发任务,以及消费能否正确拿到任务以及执行。
主逻辑
struct Data
{Data(string name,RingQueue<Task>* rq):_name(name),_rq(rq){}std::string _name;RingQueue<Task>* _rq;
};int main()
{RingQueue<Task>* rq=new RingQueue<Task>();pthread_t ctids[5]; //消费者pthread_t ptids[5]; //生产者 //创建生产者线程for(int i =0;i<5;++i){char* name = new char[64];snprintf(name ,64,"Productor Thread %d",i+1);Data* data = new Data(name,rq);delete[] name;pthread_create(ptids+i,nullptr,productor_start_routine,data);}//创建消费者线程for(int i = 0;i<5;++i){char* name = new char[64];snprintf(name ,64,"Consumer Thread %d",i+1);Data* data = new Data(name,rq);delete[] name;pthread_create(ctids+i,nullptr,consumer_start_routine,data);}while(1) sleep(1);//既然走不到这里,也懒得join了return 0;
}生产者:
void* productor_start_routine(void* arg)
{char ops[]="+-*\%";Data* pdata= (Data*)arg;RingQueue<Task>* rq = pdata->_rq;std::string name=pdata->_name;while(1){int x=rand()%10;int y=rand()%10;char op=ops[rand()%5];Task t(x,y,op,mymath);rq->push(t);std::cout<<name<<"推送了一个任务:"<<t.tostring()<<std::endl;//usleep(100000);}delete pdata;return nullptr;
}
消费者
void* consumer_start_routine(void* arg)
{Data* pdata= (Data*)arg;RingQueue<Task>* rq = pdata->_rq;std::string name=pdata->_name;while(1){Task t;rq->pop(&t);std::cout<<name<<"收到了一个任务,结果是:"<<t()<<std::endl;usleep(100000);}delete pdata;return nullptr;
}运行结果

我们可以看到,环形队列中任务的最大的数量是不会超过10的,一旦任务个数为0了,我们的生产者就在信号量下等待了,而不会继续生产,知道有空位置。
11 线程池
我们曾经借助管道写了一个进程池的设计,先创建好一批子进程,然后通过父进程来派发任务。
在这里我们也需要玩一个线程池的设计。
为什么需要池化技术呢?池化技术是什么?
池化技术就是我们在启动程序的时候,先创建一批线程或者说先把后续可能要用到的资源申请好,那么后续有任务来了的时候,我们就可以直接将任务交给线程执行,而不是收到任务再去创建线程。池化技术的本质就是预先使用更大的成本申请更大的资源,当我们要用的时候就直接是用而不需要再去申请资源,本质上是一种以空间换时间的方案。
在线程池中,我们也需要维护一个任务队列,用于将我们从外部获取的任务存储起来,等待我们的现场去读取并执行。我们预先创建好的线程,如果有任务就执行,没有任务就休眠。

那么线程池我们也可以看出来,它的本质就是一个生产消费模型,只不过生产者变成了外部的数据。
那么线程池如何设计呢?
首先我们的线程的创建可以使用在上面封装的Thread类,使用原生接口不够方便,同时由于我们要创建多个线程。
我们首先要升级一下之前的myThread类,至少让每个线程都有编号。在创建线程的时候自动计数,为线程编号名字,以便我们创建线程的时候将名字一并传给线程函数。
同时我们的start和构造函数也就要分开了,我们可以在start的时候再传线程函数和线程函数参数。
线程类:
class Thread
{typedef std::function<void*(void*)> func_t;
public:
static int num;Thread(){char name[64];snprintf(name,sizeof name,"Thread %d",num++);_name=name; //线程名字//设置线程函数的参数}std::string getname() //用于给返回名字{return _name; }void start(func_t func,void*arg = nullptr){_func=func;_arg=arg;int n = pthread_create(&_tid,nullptr,mystart,this);assert(n==0);(void)n;}void join(void** ret){ int n = pthread_join(_tid,ret);assert(n==0);(void)n;}private:static void* mystart(void* pt){Thread* t=static_cast<Thread*>(pt);return t->_func(t->_arg);}
private:pthread_t _tid;func_t _func;void* _arg;std::string _name;
};
int Thread:: num=1;那么接下来我们就开始封装线程池这个类。
首先明确它需要什么成员变量。首先需要一个变量来保存线程池中线程的个数,还需要一个数组来保存每个线程,一个队列用于放任务和取任务。然后多线程访问队列需要互斥,所以我们还需要一个锁。在队列为空的时候我们的线程需要等待,队列中有任务的时候我们需要唤醒线程,那么我们还需要一个条件变量,目前就先定义这些,如果不够再加。
我们的主要的难点其实就不在推送任务和那任务了,因为拿任务是直接由对象中创建的线程拿,可以直接访问对象内的任务队列,只不过我们还是要加锁保证安全。
线程池类设计:
{//每个线程需要知道自己的名字以及任务队列Data(std::string name ,std::queue<Task>* q,pthread_mutex_t * mutex,pthread_cond_t * cond ) //每个线程还需要拿到所和条件变量:_name(name),_q(q),_mutex(mutex),_cond(cond){}std::string _name;std::queue<Task>* _q;pthread_mutex_t * _mutex;pthread_cond_t * _cond;
};//线程需要执行的方法
void* start_routine(void* arg)
{Data* pdata= (Data*)arg;std::string name =pdata->_name;std::queue<Task>* pq=pdata->_q; pthread_mutex_t * pmutex = pdata->_mutex;pthread_cond_t * pcond = pdata->_cond; //不管怎么样,刚运行肯定还没任务,直接去等待while(1){Task t;Mutex m(pmutex);while(pq->empty())pthread_cond_wait(pcond,pmutex);t=pq->front();pq->pop();std::cout<<name<<"拿到了一个任务,执行结果:"<<t()<<std::endl;usleep(100000);} }class ThreadPool
{
public:
typedef std::function<void*(void*)> func_t;//构造ThreadPool(size_t num = 5) //只需要传线程个数:_thread_count(num){pthread_mutex_init(&_mutex,nullptr);pthread_cond_init(&_cond,nullptr);_threads.resize(num);for(int i=0;i<num;++i) //将现场的对象创建好{_threads[i]=new Thread();}}void start() //创建线程{for(auto& th:_threads){Data* data=new Data(th->getname(),&_q , &_mutex,&_cond);th->start(start_routine,(void*)data);}}void push(const Task&t){Mutex m(&_mutex);_q.push(t);//唤醒线程来拿任务pthread_cond_signal(&_cond);}void pop(Task*pt){Mutex t(&_mutex);*pt=_q.front();_q.pop();}private:std::queue<Task> _q;std::vector<Thread*> _threads;size_t _thread_count;pthread_mutex_t _mutex;pthread_cond_t _cond;
};测试的主逻辑:
int main()
{ThreadPool tp;tp.start();while(1){int x,y;std::cout<<"请输入第一个操作数-->";std::cin>>x;std::cout<<"请输入第二个操作数-->";std::cin>>y;char op;std::cout<<"请输入要进行的运算-->";std::cin>>op;Task t(x,y,op,mymath);std::cout<<"你要推送的任务是: "<<t.tostring()<<".... .... 已推送完成"<<std::endl;tp.push(t);usleep(100000);}return 0;
}
测试结果:

我们的线程池基本是没什么问题的。
其实这个线程池的设计过于简单,还比不上上面的阻塞队列以及环形队列,如果大家想提高一下难度,可以自己设计一下,比如再多来几类任务,提供一个任务选择器等等,或者在线程函数中不要直接使用内部成员,封装接口来调用对应的方法。
12 线程安全的单例模式
单例模式的特点:某些类,之应该具有一个对象(实例),就称之为单例
在很多服务器的开放场景中,经常需要让服务器加载很多的数据到内存中,此时往往需要用一歌单例来管理这些数据。
单例怎么写呢?
比如我们上面的线程池,如果要改成单例模式,那么首先 ,我们就应该要禁止外部随意创建对象,我们要保证只能有一个实例,那么我们可以将构造函数私有,这样外部就无法创建对象了。
那么外部如何调用这一个单例的方法?
很简单,我们可以提供一个静态的接口和一个静态的单例指针,接口肯定是要设为共有的,这是外部唯一能够拿到这个单例对象的方法,而我们的静态的指针变量设为私有,防止滥用。
比如我们设计的一个简单的类:
class A
{
public:static A* getsingleton(){if (single == nullptr) //说明还没有创建实例single = new A;return single;}int& geta(){return _a;}
private:A(){}int _a = 999;static A* single;
};
A* A::single = nullptr;int main()
{int a=A::getsingleton()->geta(); //利用返回单例对象指针的接口来调用单例类的公有成员方法std::cout << a << std::endl;return 0;
}由于获取单例的接口是公有且是静态的,那么我们就可以直接通过指定类域来调用该方法来获取唯一实例,通过该方法返回的唯一实例来调用类的其他公有方法。
我们也可以把我们的线程池改成单例模式,无非就是加两个静态成员,再把构造函数设为私有就行了。但是在获取单例的时候我们要注意,由于是多线程场景,那么可能会并发调用该函数,那么我们就需要在 判断是否为创建以及 new 这一条语句加上锁,防止由于数据不一致到只创建了多个单例,还导致了内存泄漏,我们的锁也必须是静态的锁。
ThreadPool* getsingleton() //获取单例{if(ptp==nullptr){Mutex(&stamutex);if(ptp!=nullptr)ptp=new ThreadPool();}return ptp;} 为什么要加两层判断呢?为了提高效率吧,我们把锁加载第二个判断前,因为如果判断ptp不为空要申请锁的话,那么每个线程调用单例的时候都需要排队申请。那么其他的地方其实差距不大,把调用该类的方法都改成通过这个单例的指针来调用就行了。
单例模式有两种实现方式,懒汉和饿汉
饿汉就是:在服务器启动的时候就把单例创建出来。
那么饿汉有什么缺点嘛?加入我们的单例很大,那么就会拖延启动的速度。
而懒汉则是先不创建对象,等到我们调用单例的时候再创建。
懒汉的优势就是加快服务器启动速度,它的核心就是延时加载。
我们上面的对线程池的单例改造就是饿汉的方式,只有外部要调用getsingleton方法获取单例的时候我们才真正去创建这个单例。
这种类似于延时加载的方式其实跟我们的new和malloc有点像。我们平时是用new和malloc的时候,不要去并不是说你一调用就立马给你开好物理空间,为什么呢?因为内存资源是有限的,而我们的操作系统要保证这些有效的资源能够得到最大化的利用。而为什么操作系统不直接开辟物理空间呢?因为你可能申请下来这块空间之后未来一段时间都不会使用到这块空间,那么这就是一种浪费。所以其实在你new空间的时候,并没有分配物理空间,操作系统只是修改了你的页表,让你的堆空间向上扩大了一点,而没有在页表中用给你映射真正的物理空间,尽管在进程看来,以为进错只能看到虚拟内存,所以进程并不知道他其实没有真正的物理空间。 只有在你真正要用这块空间的时候,这时候我们去页表中查映射关系,发现没有分配有效的物理空间,这时候会触发缺页中断,操作系统才会去物理内存中找一个页框,再根据上下文把你的数据保存进去,然后将页表的映射关系也顺带搞好,这时候我们的进程或线程再去访问这块物理空间。
所以,new和malloc就是一种延时分配物理内存的方法。
13 STL,智能指针和线程安全
stl容器不是线程安全的,因为stl容器设计的初衷就是将性能挖掘到极致,而一旦涉及到加锁保证线程安全,就会有性能上的损失。所以在多线程使用stl容器时,要用户自己保证线程安全。对于不同的容器,加锁的方式的不同,对性能的影响也会有所差距,比如哈希表的锁表和锁桶。用户要自己根据场景选择加锁方式。
智能指针中,unique_ptr是线程安全的,因为他独占资源,不与其他的的对象共享管理权,同时因为RAII,他在出作用域时会自动释放资源。
shared_ptr我们也认为他是线程安全的,他的线程安全体现在引用计数的加加和减减是CAS原子操作。 但是它仅保证引用计数的安全或者说对象本身的安全,而不能保证资源的安全,多线程情况下我们对资源操作还是要加锁保护。
14 其他常见的锁概念
1 悲观锁:在每次读取数据时,总是担心数据被其他线程修改,所以在取数据前先加锁,那么其他线程想要访问数据的时候,需要加锁,会被阻塞。我们前面学的互斥锁和信号量就是悲观锁
2 乐观锁:每次取数据时,总是乐观认为数据不会被其他线程修改,因此不上锁。但是在更新数据前,会判断数据有没有被修改。 主要就是CAS操作。
CAS(compare and set/swap),比如我们的shared_ptr的引用计数加加和减减的安全,就是靠CAS来保证的,CAS会将数据额外拷贝一份到上下文中, 然后对寄存器中的数据进行操作,在将操作完的数据写内存之前,要先拿着上下文的原数据和内存中的数据比较,如果两者相同,就可以写入,否则就重新进行该操作,过程如下:

3 自旋锁:
自旋锁是相对于挂起等待锁来讲的,互斥锁就是一个典型的挂起等待锁,当锁资源不就绪时,等待锁的线程会被挂起等待。
那么能不能如果锁资源未就绪的时候,不被挂起,而是采用类似轮询的方式不断询问锁是否就绪呢?这就是自旋锁的特点,自选过程其实就是一个轮询过程。
那么是什么决定了到底要采用自旋方案还是用挂起等待方案呢? 要等待的时间长短。也就是已经申请到锁的线程,还会在临界区待多长时间才会释放锁。这个时间的长短就决定了我们应该采用阻塞挂起还是自旋。
当要等待的时间很长时,我们就需要采用挂起等待锁,因为如果采用自旋锁的话,会浪费CPU资源。而如果时间很短时,就可以采用自旋锁,如果采用挂起阻塞锁的话,由于要等待的时间很短,可能刚挂起就要被唤醒了,而挂起和唤醒也是需要时间的。
那么如何评估时间的长短呢?我们还是要根据具体的场景而定,比如我们的临界区有大量的IO操作,那么就需要采用挂起锁,而如果只是一个简单的内存操作,比如定义一个变量或者修改一个变量,那么采用自旋锁就很方便。
如果我们不确定哪种好,可以将两种方法做一下测试来决定用哪个。
自旋锁的数据类型是 :
pthread_spinlock_t
和互斥锁一样,他也需要初始化和销毁,但是他没有了全局的初始化列表来初始化的方式。
pthread_spin_init
pthread_spin_destroy

加锁和解锁的接口:
pthread_spin_lock

pthread_spin_unlcok

有了互斥锁的使用,自旋锁的使用就很简单了,他们的操作都类似,所以我们这里也就不做测试了。
15 读者写者模型
我们可能会遇到这种场景:我们的公共资源的数据被修改的机会很少,大多数线程以及大多数时间都是在进行数据的读取,而不作修改或者使数据失效,那么在这种场景下,使用生产消费模型就不太适合了,因为生产消费模型中,读取数据的生产者之间是互斥的,同时读取完数据是把数据拿走,也就是说读取一次之后数据就失效了,不能再去读取该数据。
同时,在这种场景下,读取数据的过程往往会伴随着查找或者搜索,这些操作也是会耗时间的,如果为这些代码加上锁,那么多线程的优势就体现不出来了,极大地降低了效率。
由于这种场景下读数据的操作不会对数据进行任何修改,那么读数据的线程之间就不应该是互斥的,而是可以并发进行。
而写数据的线程之间必须是要互斥的,这一点没什么好说的。
那么写数据的线程和读数据的线程之间需要互斥吗? 当然,如果不互斥,那么就会出现写数据的线程还没将数据写完,读线程就来读数据了,这时候就会出现数据不完整或者说数据不一致的问题,所以读写线程之间也是需要互斥的。当然也需要同步,比如共享资源中还没数据的时候,就必须是写者先进去,而如果是有数据的情况下,就需要看各自的竞争力来竞争锁资源了。
那么读者写者模型中的“321”原则就是这样的:
3 :三种关系,读者与读者之间(无关系,可以并发进行),写者与写者之间(互斥),读者与写者之间(互斥与同步)
2 :两种角色: 读者线程和写者线程
1 :一个交易场所
读者写者模型和生产消费模型出现差异的根本原因就是: 消费者会拿走数据,而读者不会
所以读者之间没有关系,而消费者之间需要互斥
那么什么时候适合用读者写者模型呢?
一般是在一次发布(写入)之后,很长时间不会做修改,大部分时间都是在读取的场景下。或者说大部分时间都是在读取,少部分时间进行写入,或者说读者线程远多于写者线程。
读写锁的数据类型:
pthread_rwlock_t
初始化和销毁:
pthread_rwlock_init
pthread_rwlock_destroy

读者加锁(申请读锁):
pthread_rwlock_rdlock

写者加锁:
pthread_rwlock_wrlock

不管是读锁解锁还是写锁解锁,用的是同一个接口
pthread_rwlock_unlock

在任何一个时刻,只允许一个写者进入,当写者加锁时,其他的线程都不能申请到,但是如果是读者申请到了锁,那么其他的读者还是可以继续申请锁。
他是怎么做到的呢?大致的原理是什么?
显然,读加锁和写加锁的时候会有一些身份的差别,但是具体是怎么做的呢?我们可以写一下能够完成该逻辑的伪代码。
首先读写锁的内部肯定不是一把互斥锁,如果只有一把锁,那就做不到多个读者能够同时进临界区。我们可以理解为读写锁中有两把锁,读锁和写锁,同时,由于读者线程可能有多个同时在临界区,那么我们还需要一个计数器来对临界区的读者线程进行计数。
那么最简单的读写锁的结构如下:

读加锁的过程:
首先,要申请到读锁,申请到读锁之后计数器加加。那么这里就有一个问题了,第一个读者线程申请到读锁之后,我们就不能让写者线程申请到锁了,所以如果是第一个读者线程,那么他还需要申请写者锁,将写锁锁上。同时,由于读的过程是不需要加锁的,那么在进行读的操作之前他要把读锁解锁,供别的读者线程申请。
当读线程读完之后,要对引用计数减减,这时候也要加锁保护引用计数。当引用计数减到0时,说明读线程都走了,这时候就可以把写锁也放开了。

那么写锁的加锁过程就很简单了,因为写加锁,其他所有线程都不能进来了,所以将两个锁都申请下来就好了。
但是我们会发现上面的逻辑会有一个 问题 ,就是当第一个读线程和写线程同时进来之后,读线程先申请到了 read 读锁, 而写线程先申请到了写锁,那么这时候两个线程都会阻塞在申请对方的锁上,也就形成了死锁。 所以我们上面的伪代码只是简单的对其原理进行粗略的解释,实际上的设计肯定是要比我们上面要复杂得多的。
我们上面的逻辑叫做读者优先,也就是只要持续不断的有读者线程进去读取,那么写线程就申请不到锁,并不会严格按照线程来的顺序来保证执行的顺序。
这会导致写者的饥饿问题,不过没关系,在这种场景下,写者本来就应该是饥饿的。
如果我们想要写者优先,也就是写者线程来了之后,比写者线程后来的读者线程也必须要等待写者线程执行完之后才能进去读取,当然这个写者线程也必须等待已经在临界区的读者线程读取完才能进行写入。我们这里就不模拟写者优先的伪代码了,肯定十分复杂,必然不可能单纯用互斥锁来实现的。
不管是读者优先还是写者优先,都是读写者之间的同步策略。
相关文章:
Linux 多线程
目录 1 多线程的概念 1.1 再次理解进程的地址空间和页表 1.2 线程 2 线程控制 2.1 创建线程 pthread_create 2.2终止线程 2.3 线程等待 2.4 线程取消 2.5 线程分离 3 原生线程库 4 互斥 (锁) pthread_mutex_t pthread_mutex_init pthread_mute…...

C语言编写三子棋游戏:从概念到思路到实现
目录 一.文章概述 二.游戏规则概述 三.理解思路 1. 定义游戏数据结构 2. 游戏搭建思路及其步骤 菜单选择列表: 初始化棋盘:所有位置均为空格 创建棋盘样式 设置玩家下棋 设置电脑下棋 检查游戏状态: 四.代码示例 一.game.c部分 …...

React.js如何使用Bootstrap
在 React.js 项目中使用 Bootstrap 有多种方法,主要包括直接引入 Bootstrap CSS 文件和使用 React Bootstrap 库。下面将详细介绍这两种方法。 方法一:直接引入 Bootstrap CSS 文件 这是最简单的方式,只需在项目中引入 Bootstrap 的 CSS 文…...
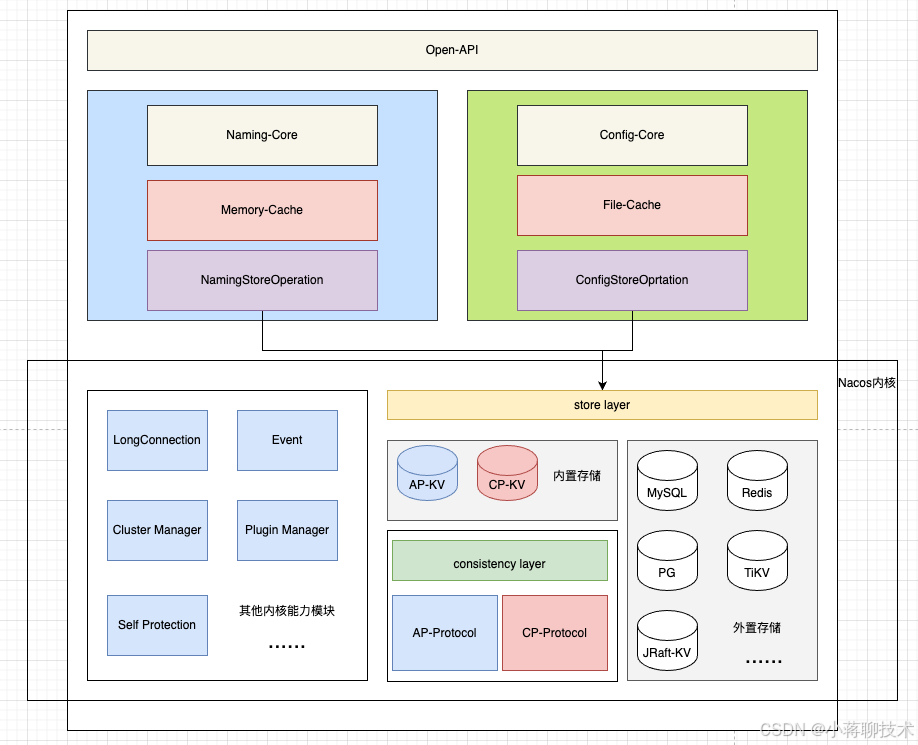
深入解析:Redis与Nacos分布式锁在业务中的具体应用
时间:2024年08月22日 作者:小蒋聊技术 邮箱:wei_wei10163.com 微信:wei_wei10 音频地址:https://xima.tv/1_HBPYxC?_sonic0 希望大家帮个忙!如果大家有工作机会,希望帮小蒋内推一下&#x…...
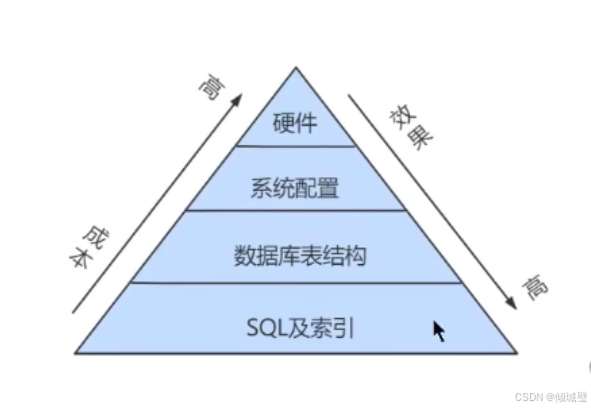
MySQL索引的性能优化
1.数据库服务器的优化步骤 在数据库调优中,我们的目标就是响应时间更快,吞吐量更大。利用宏观的监控工具和微观的日志分析可以帮我们快速找到调优的思路和方式 数据库服务器的优化步骤 当我们遇到数据库调优问题的时候,该如何思考呢…...

协方差详解及在日常生活中的应用实例——天气温度与冰淇淋销量的关系
协方差详解及在日常生活中的应用实例——天气温度与冰淇淋销量的关系 文章目录 协方差详解及在日常生活中的应用实例——天气温度与冰淇淋销量的关系引言协方差的概念与背景数学公式推导实例背景数据收集计算过程结果解释计算相关系数为什么使用协方差?结论商业启示…...
Spring Boot3.3.X整合Mybatis-Plus
前提说明: 项目的springboot版本为:<version>3.3.2</version> 需要整合的mybatis-plus版本:<version>3.5.7</version> 废话不多说,开始造吧 1.准备好数据库和表 2.配置全局文件application.properti…...
快速了解软件测试——测试用例的方法
测试用例的编写方法有八种,其中等价类、边界值、判定表、场景法、流程图重要且使用得多 ●等价类●边界值●判定表●因果图[了解]●正交法[了解]●场景法●流程图●错误推测法[了解] 1、等价类 为什么要用等价类划分法? ●从大量数据中划分范围(等价类),然后从每…...
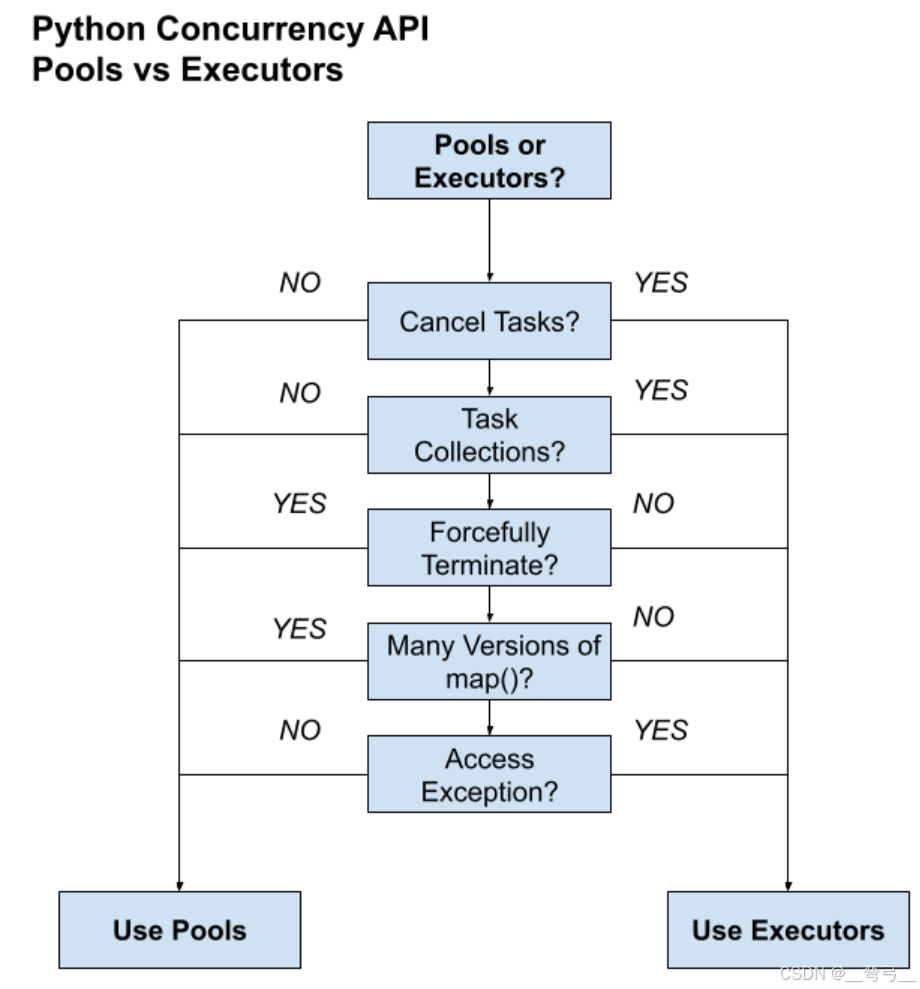
多线程、多进程,还是异步?-- Python 并发 API 如何选择
如何选择正确的 Python 并发 API模块 ? Python 标准库提供了三种并发 API , 如何知道你的项目应该使用哪个 API? 在本教程将带逐步了解各API的特性、区别以及各自应用场景,指导你选择最合适的并发 API。 多线程、多进程࿰…...
汽车服务管理系统 _od8kr
TOC springboot580汽车服务管理系统 _od8kr--论文 系统概述 该系统由个人管理员和员工管理,用户三部分组成。其中:用户进入系统首页可以实现首页,热销汽车,汽车配件,汽车资讯,后台管理,在线客…...
带你玩转小程序推广,实现短链接一键跳转
不知道各位有没有想过,短链接直接跳转到微信小程序到底该怎么操作呢?掌握这个小技能,能让你的推广效率大幅提升哦。今天就给大家分享一个全新方法,教你如何从短链接直接跳转到微信小程序,实现高效的一键式跨越。 一、…...
OpenDDS的Rtps_Udp传输协议可靠性QoS收发基本流程
OpenDDS中,实现了Rtps_Udp传输协议(非纯udp)的可靠性传输。传输的线程包括: 1)发送方线程主要线程和定时器 《1》应用线程 《2》网络异步发送线程 《3》Heartbeat定时器 《4》Nak_response定时器 2)接收方主要线程和定时器 《1》网络异步接收线程 《2》heartbeat_respons…...

体育数据API纳米奥运会数据API:高阶数据包接口文档API示例⑦
纳米体育数据的数据接口通过JSON拉流方式获取200多个国家的体育赛事实时数据或历史数据的编程接口,无请求次数限制,可按需购买,接口稳定高效;覆盖项目包括足球、篮球、网球、电子竞技、奥运等专题、数据内容。 纳米数据API2.0版本…...

【中项第三版】系统集成项目管理工程师 | 第 15 章 组织保障
前言 本章的知识点预计上午会考1-2分,下午可能会考,一般与其他管理领域进行结合考查。学习要以教材为主。 目录 15.1 信息和文档管理 15.1.1 信息和文档 15.1.2 信息(文档)管理规则和方法 15.2 配置管理 15.2.1 基本概念 …...
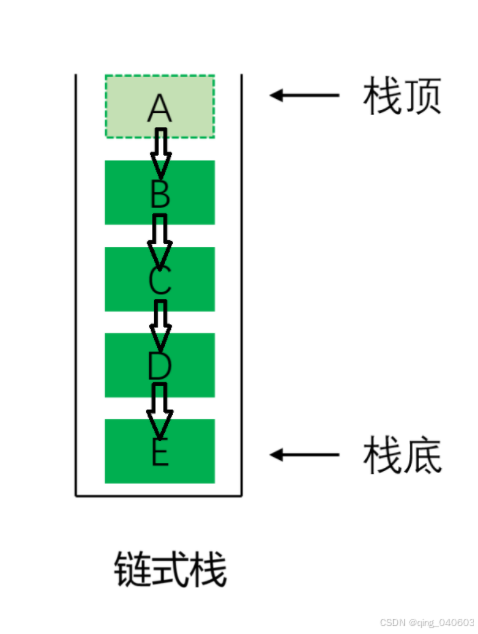
数据结构——顺序栈和链式栈
目录 引言 栈的定义 栈的分类 栈的功能 栈的声明 1.顺序栈 2.链式栈 栈的功能实现 1.栈的初始化 (1)顺序栈 (2)链式栈 (3)复杂度分析 2.判断栈是否为空 (1)顺序栈 (2)链式栈 (3)复杂度分析 3.返回栈顶元素 (1)顺序栈 (2)链式栈 (3)复杂度分析 4.返回栈的大…...

PHP轻创推客集淘客地推任务平台于一体的综合营销平台系统源码
🚀轻创推客,营销新纪元 —— 集淘客与地推任务于一体的全能平台🌐 🌈【开篇:营销新潮流,轻创推客引领未来】 在瞬息万变的营销世界里,你还在为寻找高效、全面的营销渠道而烦恼吗?&…...

three.js实现 加载3dtiles ,瓦片 ,倾斜摄影,功能
预览:https://z2586300277.github.io/three-cesium-examples/#/codeMirror?navigationThreeJS&classifyexpand&idloadTiles 部署站点预览:http://threehub.cn/ 开源地址:https://z2586300277.github.io/three-cesium-examples/#/e…...

Qt QTextEdit调用append数据重复的问题
使用QTextEdit写了个串口工具, 当串口有数据时通过一个signal传给slot,在 slot中调用QTextEdit的append(text)来增量显示串口数据,当串口关闭时调用clear()来清空显示。 结果发现append调用后显示的数据会有重复。 分析 分析代码࿰…...

数学基础(二)
一、导数 导数计算: 偏导数: 方向导数: 梯度: 函数在某点的梯度是一个向量,它的方向余方向导数最大值取得的方向一致。其大小正好是最大的方向导数 二、微积分 面积由来: 切线: 定积分&#x…...

Java设计模式原则及中介者模式研究
在软件开发过程中,设计模式作为解决常见设计问题的有效工具,对于提升代码质量、促进团队协作具有重要意义。本文系统地阐述了Java设计模式的六大基本原则——单一职责原则、开放封闭原则、里氏替换原则、依赖倒置原则、接口隔离原则以及迪米特法则&#…...

网络协议深度解析:从OSI七层模型到TCP/IP实战应用
1. OSI七层模型:网络世界的通用语言 第一次接触OSI七层模型时,我完全被那些专业术语搞晕了。直到后来在实际项目中调试网络问题,才真正理解这个模型的精妙之处。简单来说,OSI模型就像是一本网络通信的"使用说明书"&…...

SteamShutdown终极指南:让Steam下载完成后自动关机的完整解决方案
SteamShutdown终极指南:让Steam下载完成后自动关机的完整解决方案 【免费下载链接】SteamShutdown Automatic shutdown after Steam download(s) has finished. 项目地址: https://gitcode.com/gh_mirrors/st/SteamShutdown 还在为Steam大型游戏下载而熬夜等…...

OWL ADVENTURE应用场景解析:如何用AI助手提升工作效率
OWL ADVENTURE应用场景解析:如何用AI助手提升工作效率 1. 为什么选择OWL ADVENTURE作为AI助手 在当今快节奏的工作环境中,我们每天都要处理大量视觉信息——从产品图片到数据图表,从设计稿到文档扫描件。传统的工作流程往往需要人工逐一查看…...

大麦抢票神器:3分钟快速上手,轻松搞定热门演出门票
大麦抢票神器:3分钟快速上手,轻松搞定热门演出门票 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 你是一个文章写手&#x…...

连续使用 OpenClaw 50 天后,我总结了 3 个核心工作流和 5 个血泪教训
🔥 连续使用 OpenClaw 50 天后,我总结了 3 个核心工作流和 5 个血泪教训AI 不会取代你,但会用 AI 的人会取代你——这句话说烂了,但 50 天后我才真正明白它的意思。01 上周五下午 5 点,同事都在加班,我先走…...
)
避坑指南:RK3588 SD卡刷机时FAT32转EXT4的完整流程(含工具包)
RK3588大容量镜像烧写实战:突破FAT32限制的EXT4全流程解决方案 当你在RK3588开发板上尝试烧写超过4GB的Ubuntu或Debian镜像时,是否遇到过SD卡工具报错?这不是你的操作问题,而是FAT32文件系统的天然限制。本文将带你深入理解这一技…...

LightOnOCR-2-1B部署指南:快速搭建你的私有OCR识别服务
LightOnOCR-2-1B部署指南:快速搭建你的私有OCR识别服务 1. 认识LightOnOCR-2-1B 你是否遇到过需要从大量图片中提取文字的场景?比如扫描的合同、拍照的会议记录,或者历史档案数字化?传统的OCR解决方案要么识别准确率不高&#x…...

如何掌握Node-lru-cache的fetchMethod:异步数据获取的终极指南
如何掌握Node-lru-cache的fetchMethod:异步数据获取的终极指南 【免费下载链接】node-lru-cache A fast cache that automatically deletes the least recently used items 项目地址: https://gitcode.com/gh_mirrors/no/node-lru-cache Node-lru-cache是一个…...
的时序特征提取进阶)
Granite TimeSeries FlowState R1实战:基于卷积神经网络(CNN)的时序特征提取进阶
Granite TimeSeries FlowState R1实战:基于卷积神经网络(CNN)的时序特征提取进阶 你是不是也遇到过这样的问题?面对一长串传感器读数、股票价格波动或者服务器监控数据,感觉信息量巨大,却不知道从哪里入手…...
)
51单片机+DAC0832信号发生器实战:从硬件搭建到波形调试全记录(附避坑指南)
51单片机DAC0832信号发生器实战:从硬件搭建到波形调试全记录(附避坑指南) 在电子设计领域,信号发生器是工程师和爱好者不可或缺的工具。传统商用设备虽然功能强大,但对于学习嵌入式系统和数模转换原理而言,…...