Spark2.x 入门:DStream 输出操作
在Spark应用中,外部系统经常需要使用到Spark DStream处理后的数据,因此,需要采用输出操作把DStream的数据输出到数据库或者文件系统中。
这里以《Spark2.1.0入门:DStream输出操作》中介绍的NetworkWordCountStateful.scala为基础进行修改。
把DStream输出到文本文件中
NetworkWordCountStateful.scala
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevelobject NetworkWordCountStateful {def main(args: Array[String]) {//定义状态更新函数val updateFunc = (values: Seq[Int], state: Option[Int]) => {val currentCount = values.foldLeft(0)(_ + _)val previousCount = state.getOrElse(0)Some(currentCount + previousCount)}StreamingExamples.setStreamingLogLevels() //设置log4j日志级别val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCountStateful")val sc = new StreamingContext(conf, Seconds(5))sc.checkpoint("file:///usr/local/spark/mycode/streaming/dstreamoutput/") //设置检查点,检查点具有容错机制val lines = sc.socketTextStream("localhost", 9999)val words = lines.flatMap(_.split(" "))val wordDstream = words.map(x => (x, 1))val stateDstream = wordDstream.updateStateByKey[Int](updateFunc)stateDstream.print()//下面是新增的语句,把DStream保存到文本文件中stateDstream.saveAsTextFiles("file:///usr/local/spark/mycode/streaming/dstreamoutput/output.txt")sc.start()sc.awaitTermination()}
}
把DStream写入到MySQL数据库中
mysql> use spark
mysql> create table wordcount (word char(20), count int(4));
mysql> select * from wordcount
//这个时候wordcount表是空的,没有任何记录
NetworkWordCountStateful.scala
import java.sql.{PreparedStatement, Connection, DriverManager}
import java.util.concurrent.atomic.AtomicInteger
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.storage.StorageLevelobject NetworkWordCountStateful {def main(args: Array[String]) {//定义状态更新函数val updateFunc = (values: Seq[Int], state: Option[Int]) => {val currentCount = values.foldLeft(0)(_ + _)val previousCount = state.getOrElse(0)Some(currentCount + previousCount)}val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCountStateful")val sc = new StreamingContext(conf, Seconds(5))sc.checkpoint("file:///usr/local/spark/mycode/streaming/dstreamoutput/") //设置检查点,检查点具有容错机制val lines = sc.socketTextStream("localhost", 9999)val words = lines.flatMap(_.split(" "))val wordDstream = words.map(x => (x, 1))val stateDstream = wordDstream.updateStateByKey[Int](updateFunc)stateDstream.print()//下面是新增的语句,把DStream保存到MySQL数据库中 stateDstream.foreachRDD(rdd => {//内部函数def func(records: Iterator[(String,Int)]) {var conn: Connection = nullvar stmt: PreparedStatement = nulltry {val url = "jdbc:mysql://localhost:3306/spark"val user = "root"val password = "hadoop" //笔者设置的数据库密码是hadoop,请改成你自己的mysql数据库密码conn = DriverManager.getConnection(url, user, password)records.foreach(p => {val sql = "insert into wordcount(word,count) values (?,?)"stmt = conn.prepareStatement(sql);stmt.setString(1, p._1.trim)stmt.setInt(2,p._2.toInt)stmt.executeUpdate()})} catch {case e: Exception => e.printStackTrace()} finally {if (stmt != null) {stmt.close()}if (conn != null) {conn.close()}}}val repartitionedRDD = rdd.repartition(3)repartitionedRDD.foreachPartition(func)})sc.start()sc.awaitTermination()}
}
对于stateDstream,为了把它保存到MySQL数据库中,我们采用了如下的形式:
stateDstream.foreachRDD(function)
其中,function就是一个RDD[T]=>Unit类型的函数,对于本程序而言,就是RDD[(String,Int)]=>Unit类型的函数,也就是说,stateDstream中的每个RDD都是RDD[(String,Int)]类型(想象一下,统计结果的形式是(“hadoop”,3))。这样,对stateDstream中的每个RDD都会执行function中的操作(即把该RDD保存到MySQL的操作)。
下面看function的处理逻辑,在function部分,函数体要执行的处理逻辑实际上是下面的形式:
def func(records: Iterator[(String,Int)]){……}val repartitionedRDD = rdd.repartition(3)repartitionedRDD.foreachPartition(func)
也就是说,这里定义了一个内部函数func,它的功能是,接收records,然后把records保存到MySQL中。到这里,你可能会有疑问?为什么不是把stateDstream中的每个RDD直接拿去保存到MySQL中,还要调用rdd.repartition(3)对这些RDD重新设置分区数为3呢?这是因为,每次保存RDD到MySQL中,都需要启动数据库连接,如果RDD分区数量太大,那么就会带来多次数据库连接开销,为了减少开销,就有必要把RDD的分区数量控制在较小的范围内,所以,这里就把RDD的分区数量重新设置为3。然后,对于每个RDD分区,就调用repartitionedRDD.foreachPartition(func),把每个分区的数据通过func保存到MySQL中,这时,传递给func的输入参数就是Iterator[(String,Int)]类型的records。如果你不好理解下面这种调用形式:
repartitionedRDD.foreachPartition(func) //这种形式func没有带任何参数,可能不太好理解,不是那么直观
实际上,这句语句和下面的语句是等价的,下面的语句形式你可能会更好理解:
repartitionedRDD.foreachPartition(records => func(records))
上面这种等价的形式比较直观,为func()函数传入了一个records参数,这就正好和 def func(records: Iterator[(String,Int)])定义对应起来了,方便理解。
相关文章:

Spark2.x 入门:DStream 输出操作
在Spark应用中,外部系统经常需要使用到Spark DStream处理后的数据,因此,需要采用输出操作把DStream的数据输出到数据库或者文件系统中。 这里以《Spark2.1.0入门:DStream输出操作》中介绍的NetworkWordCountStateful.scala为基础…...

Python爬虫——简单网页抓取(实战案例)小白篇
Python 爬虫是一种强大的工具,用于从网页中提取数据。这里,我将通过一个简单的实战案例来展示如何使用 Python 和一些流行的库(如 requests 和 BeautifulSoup)来抓取网页数据。 实战案例:抓取一个新闻网站的头条新闻标…...
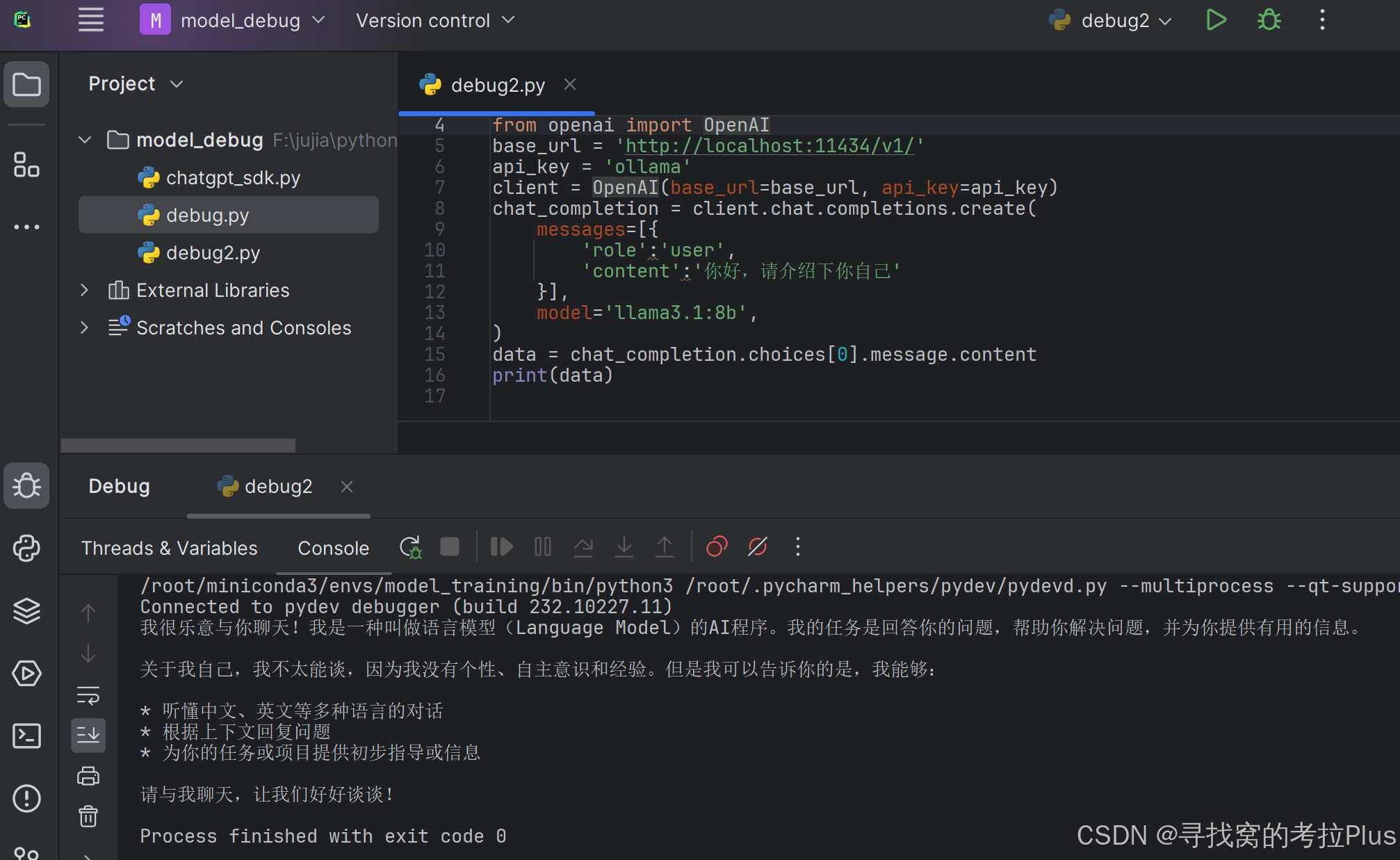
linux,ubuntu,使用ollama本地部署大模型llama3,模型通用,简易快速安装
文章目录 前言安装ollama启动ollama运行llama3模型查看ollama列表删除模型通过代码进行调用REST API 前言 在拥有了一条4090显卡后,那冗余的性能让你不得不去想着办法整花活,于是就想着部署个llama3,于是发现了ollama这个新大陆,…...

JS中的encodeURIComponent函数示例
JavaScript中的encodeURIComponent函数用于对字符串进行URL编码。它将字符串中的特殊字符转换为相应的编码形式,以确保字符串可以安全地嵌入到URL中。 使用encodeURIComponent函数时,它会将除了字母、数字、-、_、.、~以外的所有字符都进行编码。编码后…...

8.20 pre day bug
pre-bug1 分号省略 这些语句的分隔规则会导致一些意想不到的情形,如以下的一个示例; let m n f(bc).toString()但该语句最终会被解析为: let m n f(ab).toString();returntrue一定会被解析成 return;true;pre-bug2 Math.random()与Mat…...

位运算专题
分享丨【题单】位运算(基础/性质/拆位/试填/恒等式/思维) - 力扣(LeetCode) Leetcode 3133. 数组最后一个元素的最小值 我的答案与思路: class Solution { public: // 4 --> (100)2 7 --> (0111)2 // 5 --&g…...
)
HaProxy学习 —300K的TCP Socket并发连接实现(翻译)
HaProxy学习 —300K的TCP Socket并发连接实现(翻译) 1 原文链接2 原文翻译2.1 调整Linux系统参数2.2 调整HAProxy 1 原文链接 Use HAProxy to load balance 300k concurrent tcp socket connections: Port Exhaustion, Keep-alive and others࿰…...

92.WEB渗透测试-信息收集-Google语法(6)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于: 易锦网校会员专享课 上一个内容:91.WEB渗透测试-信息收集-Google语法(5) 监控的漏洞也有很多 打…...
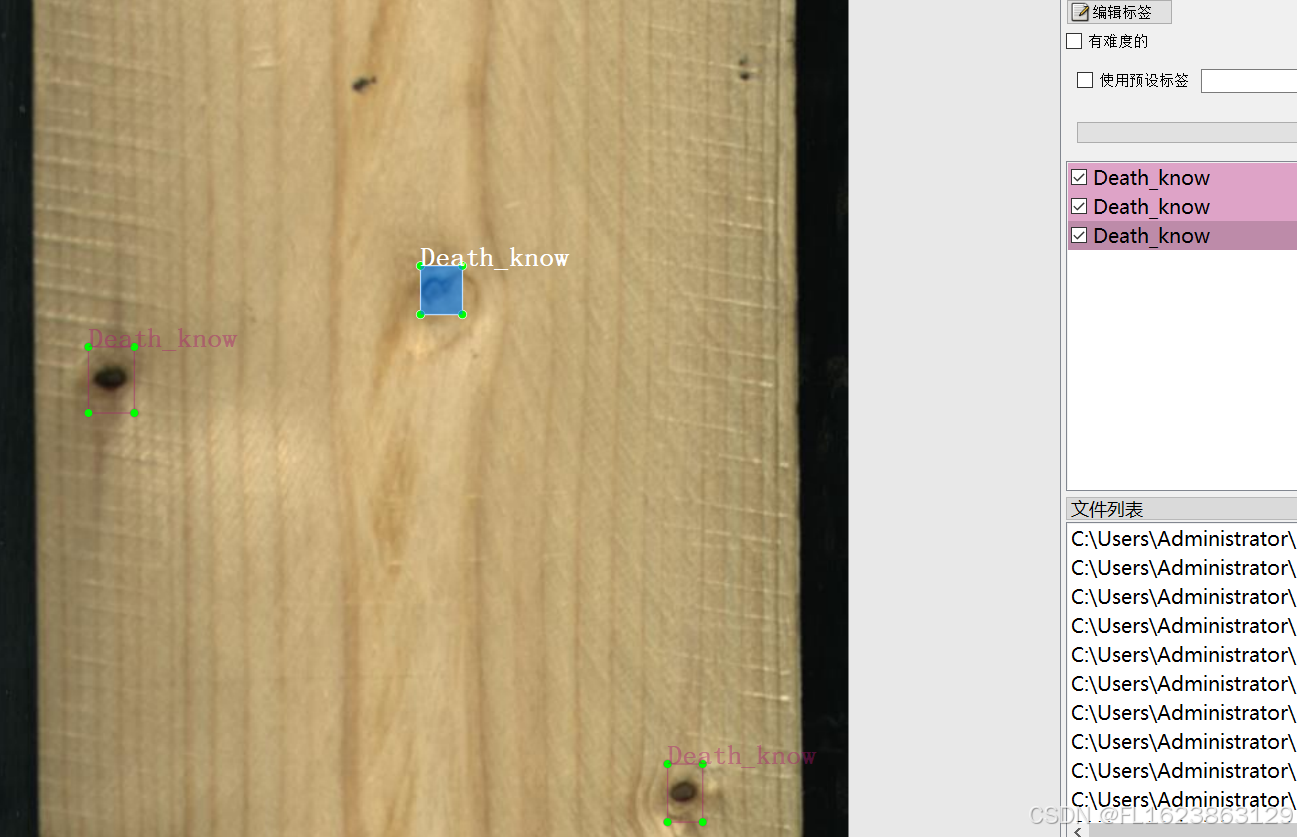
[数据集][目标检测]木材缺陷检测数据集VOC+YOLO格式2383张10类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2383 标注数量(xml文件个数):2383 标注数量(txt文件个数):2383 标注…...

【启明智显分享】智能音箱AI大模型一站式解决方案重塑人机交互体验,2个月高效落地
2010年左右,智能系统接入音箱市场,智能音箱行业在中国市场兴起。但大潮激荡,阿里、小米、百度三大巨头凭借自身强大的资本、技术、粉丝群强势入局,形成三足鼎立态势。经过几年快速普及,智能音箱整体渗透率极高…...

逻辑与集合论基础及其在编程中的应用
目录 第一篇文章:逻辑与集合论基础及其在编程中的深度应用 引言 命题逻辑与谓词逻辑在编程中的深入应用 集合论及其在编程中的深度运用 函数的概念及其与集合的结合 总结与应用 第一篇文章:逻辑与集合论基础及其在编程中的深度应用 引言 逻辑与集…...

【无标题】为什么 pg_rewind 在 PostgreSQL 中很重要?
文章目录 pg_rewind 的工作原理使用 pg_rewind 的要求Basic Usage of pg_rewind重要注意事项:为什么 pg_rewind 需要干净关闭?无法进行干净关闭的情况处理不正常关机结论 pg_rewind 是 PostgreSQL 中的一个实用程序,用于将一个数据库集群与另一个数据库集…...
hostapd生成beacon_ie
配置文件 /data/vendor/wifi/hostapd/hostapd_wlan0.conf 配置参数 AP启动过程:1.上层配置一些参数并根据参数生成配置文件 2.init的时候设置默认参数并加载配置文件上的参数(如果重复,以配置文件上的设置优先) 相关函数及结构…...

leetcode349:两个数组的交集
两个数组的交集 给定两个数组 nums1 和 nums2 ,返回 它们的 交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。 public int[] intersection(int[] nums1, int[] nums2) {ArrayList<Integer> list new ArrayList<>();Has…...
:MSF渗透测试 - PHPCGI漏洞利用实战)
Metasploit漏洞利用系列(八):MSF渗透测试 - PHPCGI漏洞利用实战
在本系列的第八篇文章中,我们将深入探索如何利用Metasploit Framework (MSF) 来针对PHPCGI (PHP Common Gateway Interface) 的漏洞进行渗透测试。PHPCGI作为一种将Web服务器与PHP脚本交互的方式,其不恰当的配置或老旧版本中可能存在的漏洞常被攻击者利用…...

基于python的主观题自动阅卷系统设计与实现
博主介绍: 大家好,本人精通Java、Python、C#、C、C编程语言,同时也熟练掌握微信小程序、Php和Android等技术,能够为大家提供全方位的技术支持和交流。 我有丰富的成品Java、Python、C#毕设项目经验,能够为学生提供各类…...
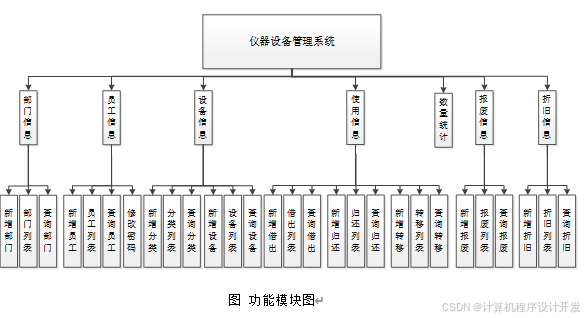
计算机毕业设计仪器设备管理系统-折旧-报废-转移-借出-归还
本文主要阐述如何采用利用网络数据库技术,在信息管理系统中合理的进行管理。在全面解析系统的设计理念以及设计手段,将系统进程中的所需的工具以及技术进行综合的设计,重点解析信息管理情况以及自动化管理进程,主要包括࿱…...

DAY37
零钱兑换 II public int change(int amount, int[] coins) {int []dpnew int[amount1];dp[0]1;for(int i0;i<coins.length;i){for(int jcoins[i];j<amount;j){dp[j]dp[j-coins[i]];}}return dp[amount];}组合总和 Ⅳ public int combinationSum4(int[] nums, int target)…...
将iso格式的镜像文件转化成云平台能安装的镜像格式(raw/vhd/QCOW2/VMDK )亲测--图文详解
1.首先,你将你的iso的文件按照正常的流程和需求安装到你的虚拟机中,我这里使用的是vmware,安装完成之后,关机。再次点开你安装好的那台虚拟机的窗口,如下图 选中要导出的镜像,镜像需要关机 2.点击工具栏的文件------选择 导出 整个工程到 ovf 格式—这里你可以选择你要导…...

Numba加速计算(CPU + GPU + prange)
文章目录 加速方法:Numba、CuPy、PyTorch、PyCUDA、Dask、Rapids一、Numba简介二、Numba类型:CPU GPU三、项目实战 —— 数组的每个元素加23.1、使用 python - range 循环计算 —— (时耗:137.37 秒)3.2、使用 python…...
)
实战指南 | 利用FRP与TOML配置实现高效内网穿透(含反向代理优化)
1. 为什么需要内网穿透? 想象一下这个场景:你家里有一台NAS存储设备,里面存满了家人照片和工作文档;或者你在本地开发了一个网站应用,想临时分享给异地同事测试。这时候你会发现——从外部网络根本无法访问这些服务&am…...

Harness与OpenClaw:当企业级DevOps遇见个人AI助手
EXCLUSIVE 深度调查Harness与OpenClaw:当企业级DevOps遇见个人AI助手两种AI Agent范式正在重塑软件交付与个人生产力AI日报2026年4月8日阅读约20分钟【核心提要ベ2026年,AI Agent领域出现了两种截然不同的范式:以Harness为代表的企业级DevOp…...

SO-ARM100机械臂Feetech舵机控制SDK独立封装实战
1. 为什么需要独立封装Feetech舵机控制SDK 当你第一次拿到SO-ARM100机械臂时,可能会直接使用LeRobot框架进行控制。这个框架确实提供了完整的解决方案,但就像带着整个工具箱去拧一颗螺丝——过度依赖框架会导致几个实际问题: 依赖臃肿&#x…...

如何在2025年完美访问Flash内容:CefFlashBrowser完整使用指南
如何在2025年完美访问Flash内容:CefFlashBrowser完整使用指南 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 你是否还在为无法访问那些经典的Flash网站、教育课件和网页游戏而…...

3个步骤实现Zotero笔记与Obsidian双向同步:告别手动复制粘贴
3个步骤实现Zotero笔记与Obsidian双向同步:告别手动复制粘贴 【免费下载链接】zotero-better-notes Everything about note management. All in Zotero. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-better-notes Zotero-Better-Notes的Markdown双向…...

Android Studio移动开发入门:构想集成Phi-3-vision模型的智能相机App
Android Studio移动开发入门:构想集成Phi-3-vision模型的智能相机App 1. 从零开始的智能相机构想 想象这样一个场景:当你用手机拍摄一朵花时,相机不仅能自动识别花的品种,还能告诉你它的生长习性和养护要点;当你扫描…...
:12项指标自评表+3个高危信号预警+1次免费基准评估入口)
大模型工程化成熟度测评指南(SITS2026官方适配版):12项指标自评表+3个高危信号预警+1次免费基准评估入口
第一章:SITS2026发布:大模型工程化成熟度模型 2026奇点智能技术大会(https://ml-summit.org) SITS2026(Software Intelligence & Trustworthiness Scale 2026)是首个面向大模型全生命周期的工程化成熟度评估框架,…...

高性能表单状态管理难题:Formily分布式架构如何实现毫秒级响应与99.9%可用性
高性能表单状态管理难题:Formily分布式架构如何实现毫秒级响应与99.9%可用性 【免费下载链接】formily 📱🚀 🧩 Cross Device & High Performance Normal Form/Dynamic(JSON Schema) Form/Form Builder -- Support React/Reac…...

龙芯k - 走马观碑组MPU驱动移植芯
先回顾:三次握手(建立连接)核心流程(实际版) 为了让挥手流程衔接更顺畅,咱们先快速回顾三次握手的实际核心,避免上下文脱节: 第一步(客户端→服务器)…...

kaishi啦啦啦啦
...