海山数据库(He3DB)+AI:(一)神经网络基础
文章目录
- 1 引言
- 2 基本结构
- 2.1 神经元
- 2.2 模型结构
- 3 训练过程
- 3.1 损失函数
- 3.2 反向传播
- 3.3 基于梯度的优化算法
- 4 总结
1 引言
神经网络可以被视为一个万能的拟合器,通过深层的隐藏层实现输入数据到输出结果的映射。神经网络的思想源于对大脑的模拟,在其发展过程中历了三大浪潮:感知器时代(1940s-1960s)、BP算法时代(1980-1995))和深度学习时代(2006-至今)。在深度学习时代,随着众多研究学者的投入和硬件的发展,从结构较为简单的前馈神经网络,到针对图像数据的卷积神经网络,到处理序列数据的循环神经网络,再到捕捉长距离依赖的transformer,神经网络在多个任务上展现出强大的生命力。2022年,基于transformer架构的ChatGPT的出现,掀起了一场大模型浪潮,在大数据、大参数量的训练下,模型产生了涌现现象,在语言理解、逻辑推理等能力上展现惊艳的能力。本文以最简单的前馈神经网络(Feed Forward Neural Network,FFNN)为例,首先介绍神经网络的基本框架,然后介绍模型的训练过程,为本系列奠定基础。
2 基本结构
2.1 神经元
神经元是构成前馈神经网络的基本组件,其基本原理是通过对输入进行加权、激活,实现信息的非线性处理和传递,一个神经元的结构如图1所示,其数学表达式如公式1所示。

h w , b ( x ) = f ( w T x + b ) (1) h_{w,b}(x)=f(w^Tx+b) \tag{1} hw,b(x)=f(wTx+b)(1)
加权:对于输入的多个信号,每个信号都关联了一个权重,该权重反映了输入信号对于输出的重要性。该权重在初始时被随机初始化,权重的值即模型训练的目的。对输入信号进行加权和偏置计算后,得到线性组合结果。
激活:激活将线性转化为非线性,使得能够拟合更复杂的函数。ReLu函数是最常用的激活函数之一,其数学表达式如公式2所示,当输入大于0时,输出不变,当输入小于0时,输出为0。ReLu函数以非常简单的方式增加了网络的非线性,具有易于求导的优点,使得模型在训练时具有较快的速度。
R e L u ( x ) = m a x ( 0 , x ) (2) ReLu(x) =max(0,x)\tag{2} ReLu(x)=max(0,x)(2)
2.2 模型结构
基于单个神经元,即可构建模型。前馈神经网络主要可分为三个部分:输入层、隐藏层和输出层,如图2为一个较简单的前馈神经网络:

输入层:与外界数据的直接接口,接收并传递数据到网络的下一层。
隐藏层:隐藏层可以有多层,每层中可以设置多个神经元。隐藏层实现对输入数据的特征提取,在学习过程中不断调整神经元的权重和偏置值,寻找输入数据到输出结果的最优表示。
输出层:网络的最后一层,给出最终的预测结果。输出层的结构与具体任务相关,在分类任务中,一般使用softmax函数得到概率分布,在回归任务中,可直接计算预测值。(分类任务对应离散,回归任务对应连续。)
从数学表达式来看,隐藏层的输出如公式3所示:
h i = σ ( w 1 i 1 × x 1 + w 2 i 1 × x 2 + b ) (3) h_i = \sigma (w_{1i}^1\times x_1 + w_{2i}^1\times x_2+b)\tag{3} hi=σ(w1i1×x1+w2i1×x2+b)(3)
输出层的输出公式如公式4所示:
y i = σ ( w 1 i 2 × h 1 + w 2 i 2 × h 2 + w 3 i 2 × h 3 + w 4 i 2 × h 4 + b ) (4) y_i = \sigma (w_{1i}^2\times h_1 + w_{2i}^2\times h_2+ w_{3i}^2\times h_3 + w_{4i}^2\times h_4 + b)\tag{4} yi=σ(w1i2×h1+w2i2×h2+w3i2×h3+w4i2×h4+b)(4)
公式3和公式4即模型前向计算的过程。
3 训练过程
训练过程即通过大量的数据样本,对模型中的权重及偏置参数进行学习,实现输入数据到输出结果的最优表示。
在模型的训练过程中,还包括三个部分:损失函数、反向传播算法和最优化方法。损失函数,又称为代价函数,反映了模型预测结果到目标结果之间的差值。反向传播算法基于损失函数计算网络中所有权重参数的梯度,这个梯度反馈给最优化方法,用来更新权重以最小化损失函数,使得预测结果不断接近目标结果。
3.1 损失函数
根据具体任务选择损失函数。在回归任务中,常用的损失函数有均方差损失函数,在分类任务中,常用的损失函数有交叉熵损失函数。
均方差损失函数: 计算预测值和目标值之间差值的平方和,来衡量预测的准确性,如公式5所示。
M S E = 1 N ∑ ( y i − y ^ i ) 2 (5) MSE = \frac{1}{N}\sum(y_i-\hat{y}_i)^2\tag{5} MSE=N1∑(yi−y^i)2(5)
其中, y i y_i yi为目标值, y ^ i \hat{y}_i y^i为预测值, N N N为样本数量。
交叉熵损失函数: 交叉熵损失函数衡量预测结果的概率分布和真实标签的的差异,如公式6所示。
C E = − 1 N ∑ i = 1 N [ y i ln y ^ i + ( 1 − y i ) ln ( 1 − y ^ i ) ] (6) CE=-\frac{1}{N} \sum_{i=1}^{N}\left[y_{i} \ln \hat{y}_i+\left(1-y_{i}\right) \ln (1-\hat{y}_i)\right]\tag{6} CE=−N1i=1∑N[yilny^i+(1−yi)ln(1−y^i)](6)
其中, y i y_i yi为真实标签, y ^ i \hat{y}_i y^i为预测的概率分布, N N N为样本数量。
3.2 反向传播
假设使用如图1所示的神经网络,损失函数为公式1,那么基于链式法则可以计算出神经网络中每一个参数的梯度。
(1)输出层的梯度
∂ C E ( W , b ) ∂ w ( 2 ) = ∂ C E ( W , b ) ∂ y ∂ y ∂ w ( 2 ) \frac{\partial CE(W, b)}{\partial w^{(2)}} = \frac{\partial CE(W, b)}{\partial y}\frac{\partial y}{\partial w^{(2)}} ∂w(2)∂CE(W,b)=∂y∂CE(W,b)∂w(2)∂y
(2)隐藏层的梯度
∂ C E ( W , b ) ∂ w ( 1 ) = ∂ C E ( W , b ) ∂ y ∂ y ∂ h ∂ h ∂ w ( 1 ) \frac{\partial CE(W, b)}{\partial w^{(1)}} = \frac{\partial CE(W, b)}{\partial y}\frac{\partial y}{\partial h}\frac{\partial h}{\partial w^{(1)}} ∂w(1)∂CE(W,b)=∂y∂CE(W,b)∂h∂y∂w(1)∂h
在更深的神经网络中,可通过递推由后一层的梯度计算出前一层的梯度,梯度从后往前进行计算,因此称为反向传播。
3.3 基于梯度的优化算法
在最优化问题中,可分为凸优化和非凸优化,其中凸优化可寻找到全局最优解,非凸优化问题复杂难以求解,只有通过各种策略和方法寻找近似解和局部最优解。神经网络的优化问题属于非凸优化问题,常用的优化算法有最速梯度下降法。由反向传播算法得到了每个参数的梯度,梯度反映了参数的调整方向,优化算法基于这些梯度,对权重值进行调整,使得损失值下降,预测值不断接近目标值。
最速下降法的步骤如下:
1.参数初始化:选择初始参数值 x ( 0 ) x(0) x(0),可以是随机的或根据问题特点进行初始化。设定终止精度ε>0,以及迭代次数;
2.计算梯度:由反向传播算法得到梯度;
3.更新参数:取负梯度为下降方向(正梯度为损失值增长的方向),设置步长 α \alpha α(或学习率),沿着该方向移动步长;
4.阈值判断:如果所有W,b的变化值都小于停止迭代阈值ϵ,则跳出迭代循环,否则进入步骤2;
4.输出结果:输出最终的权重参数。
4 总结
本文介绍了一种较为简单的前馈神经网络,介绍其基本组件、模型结构、前向计算流程,并简单介绍了模型的训练原理。前馈神经网络是大多数深度模型的基石,在此基础上演化出更加结构更加复杂的深度模型,如在前馈神经的网络的基础上根据图像数据的特征,使用稀疏交互、等变表示和参数共享的思想设计出卷积神经网络。在transformer中,前馈神经网络被用来实现用自注意力机制,捕捉输入序列中的长程依赖关系,并更好地理解输入序列中的语义信息。
相关文章:
海山数据库(He3DB)+AI:(一)神经网络基础
文章目录 1 引言2 基本结构2.1 神经元2.2 模型结构 3 训练过程3.1 损失函数3.2 反向传播3.3 基于梯度的优化算法 4 总结 1 引言 神经网络可以被视为一个万能的拟合器,通过深层的隐藏层实现输入数据到输出结果的映射。神经网络的思想源于对大脑的模拟,在…...
)
CSS中选择器有哪些?(史上最全选择器)
CSS选择器是用来选择和应用样式到HTML元素上的工具。以下是所有主要的CSS选择器的详细分类和描述: 1. 基本选择器 通配符选择器 (*):选择所有元素。例如,* { color: red; } 会将所有元素的文字颜色设置为红色。元素选择器:选择指…...
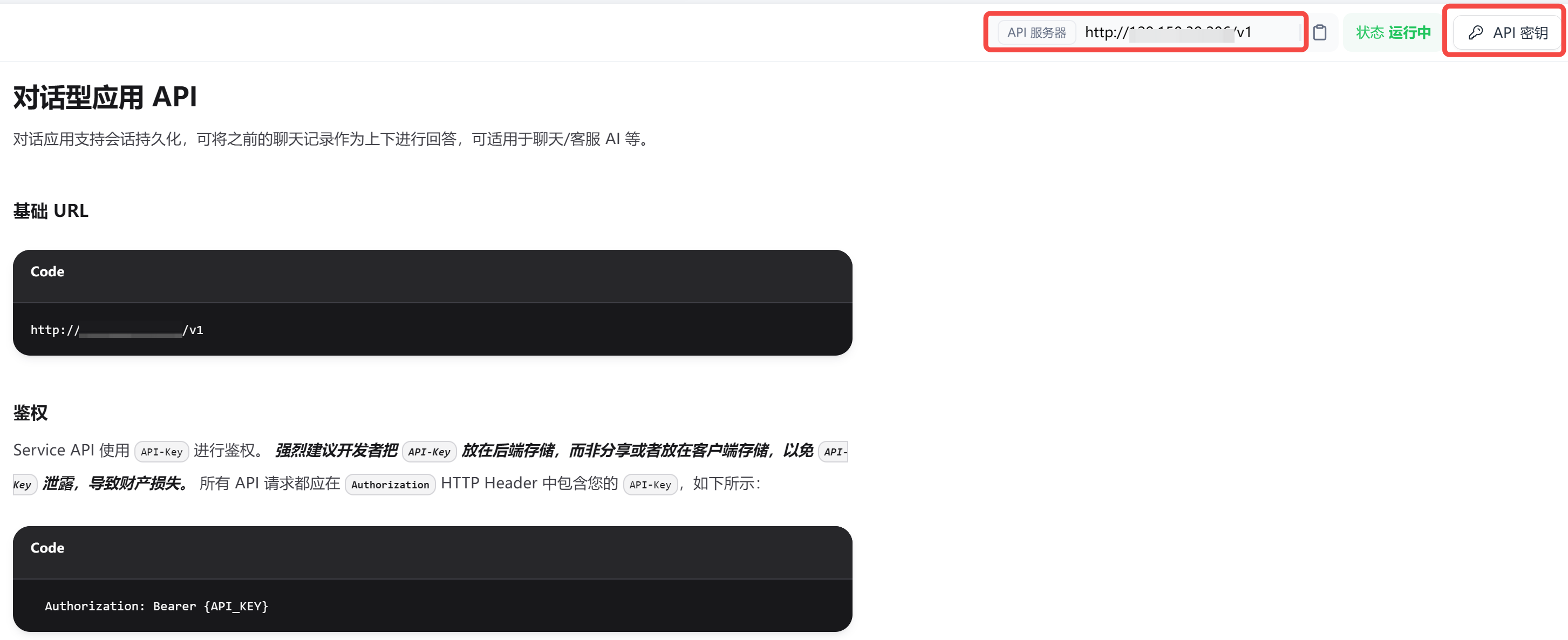
本地部署 AI 智能体,Dify 搭建保姆级教程(下):知识库 RAG + API 调用,我捏了一个红楼解读大师
话接上篇: 本地部署 AI 智能体,Dify 搭建保姆级教程(上):工作流 Agent,把 AI 接入个人微信 相信大家已经在本地搭建好 Dify 了。 今日分享,继续介绍 Dify 的另外两项重要功能: 知…...

HarmonyOS应用开发者高级认证,Next版本发布后最新题库 - 答案纯享版
这篇文章是高级题库答案纯享版,只有需要选择的选项。如果需要查看所有选项,可以点击下方链接跳转。以考代学,还是推荐点击下方链接,查看完整的题库,边看边学习鸿蒙应用开发。此题库已更新完毕,笔者将不继续…...

基于PHP的文件包含介绍
引言:在实际开发过程中,经常会遇到部分模块功能需要重复使用的情况,比如数据库的增删改查,文件包含通过将需要重复使用的功能模块代码引入其他文件的内容,实现重用代码、分离配置等。然而,如果文件包含操作…...

K7系列FPGA多重启动(Multiboot)
Xilinx 家的 FPGA 支持多重启动功能(Multiboot),即可以从多个 bin 文件中进行选择性加载,从而实现对系统的动态更新,或系统功能的动态调整。 这一过程可以通过嵌入在 bit 文件里的 IPROG 命令实现上电后的自动加载。而…...

关于武汉芯景科技有限公司的RS232通信接口芯片XJ3243EEUI开发指南(兼容MAX3243EEUI)
一、芯片引脚介绍 1.芯片引脚 2.引脚描述 二、典型应用电路 三、功能描述 1.Transmitter 通过T1,T2可以将TTL电平转换为RS232电平 2.Receiver 通过R1,R2可以将RS232电平转换为TTL电平 3.工作模式控制 4.INVALID引脚...
TreeSize Free:你的免费磁盘空间管理专家
TreeSize Free是一款专为Windows用户设计的磁盘空间分析工具。它能够帮助用户快速识别并管理那些占用大量空间的文件夹和文件。 功能亮点 快速扫描:TreeSize Free能够迅速扫描整个磁盘卷,展示所有文件夹及其子文件夹的大小,甚至可以细化到单…...

python办公自动化:初识`python-docx`
1.1 什么是python-docx python-docx是一个用于在Python中创建和操作Word文档的库。它提供了一组简洁的API,让开发者可以轻松地生成、修改、和读取Microsoft Word (.docx)文件,而不需要安装Microsoft Office。这使得python-docx成为办公自动化、报告生成…...

LeetCode 算法:划分字母区间 c++
原题链接🔗:划分字母区间难度:中等⭐️⭐️ 题目 给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。 注意,划分结果需要满足:将所有划分结果按顺序连接&#…...

PMP备考指南:策略、时间安排与心得分享
准备和时间安排,我是工作的时间把它顺便考了,大约花了一个月左右时间备考,前面的时间都在筹办婚礼,根本没时间,最后一个月都差点想放弃了,但想想还是冲一把就没有选择延考。 干货见下: ▌&…...

CentOS上通过frp实现HTTPS访问内网
要在CentOS上通过frp实现HTTPS访问内网,你需要按照以下步骤操作: 在外网服务器上安装frps(frp服务端)。 在外网服务器上配置frps,编辑配置文件frps.ini。 在frps服务器上启动frps服务。 在内网服务器上安装frpc&…...

短视频SDK解决方案,高效集成,助力商业变现
美摄科技,作为业界领先的多媒体技术服务商,其全面升级的短视频SDK解决方案,旨在为开发者与内容创作者提供一站式、高效能的创作工具,让每一个灵感都能瞬间转化为触动人心的视频作品。 【一站式解决方案,重塑短视频创作…...

C++系列-继承方式
继承方式 继承的语法继承方式:继承方式的特点继承方式的举例 继承可以减少重复的代码。继承允许我们依据另一个类来定义一个类,这使得创建和维护一个应用程序变得更容易。基类父类,派生类子类,派生类是在继承了基类的部分成员基础…...

web前端之选项卡的实现、动态添加类名、动态移除类名、动态添加样式、激活、间距、tabBar
MENU 原生(一)原生(二)vue(一) 原生(一) 效果图 html 代码 <div class"card"><div class"tab_bar"><div class"item" onclick"handleTabBar(this)">tabBar1</div><div class"item" onclick&qu…...

sql 优化,提高查询速度
文章目录 一、前言二、建议2.1 使用索引2.2 避免使用select *2.3. 使用表连接代替子查询2.4. 优化WHERE子句,减少返回结果集的大小2.5 用union all代替union2.6 使用合适的聚合策略2.7 避免在WHERE子句中使用函数2.8 使用EXPLAIN分析查询2.9 小表驱动大表2.10 使用窗…...

springboot后端开发-自定义参数校验器
背景 在使用springboot进行后端开发的时候,经常会遇到数据校验的问题, 有时候可能默认的校验器不足以满足自己的需求, 这个时候就需要开发一个自己的校验器 在 Spring Boot 中自定义参数校验器通常涉及以下几个步骤: 1. 定义注解…...
springboot社区帮扶对象管理系统论文源码调试讲解
第2章 开发环境与技术 社区帮扶对象管理系统的编码实现需要搭建一定的环境和使用相应的技术,接下来的内容就是对社区帮扶对象管理系统用到的技术和工具进行介绍。 2.1 MYSQL数据库 本课题所开发的应用程序在数据操作方面是不可预知的,是经常变动的&…...

EmguCV学习笔记 VB.Net 6.2 轮廓处理
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 EmguCV是一个基于OpenCV的开源免费的跨平台计算机视觉库,它向C#和VB.NET开发者提供了OpenCV库的大部分功能。 教程VB.net版本请访问…...
【Python的魅力】:利用Pygame实现游戏坦克大战——含完整源码
文章目录 一、游戏运行效果二、代码实现2.1 项目搭建2.2 加载我方坦克2.3 加载敌方坦克2.4 添加爆炸效果2.5 坦克大战之音效处理 三、完整代码 一、游戏运行效果 二、代码实现 坦克大战游戏 2.1 项目搭建 本游戏主要分为两个对象,分别是我方坦克和敌方坦克。用户可…...

终极指南:用TegraRcmGUI轻松解锁Nintendo Switch的无限潜力
终极指南:用TegraRcmGUI轻松解锁Nintendo Switch的无限潜力 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI 还在为Nintendo Switch的封闭系统感到…...

保姆级教程:用Qwen3-VL-8B搭建本地视觉问答工具,4090显卡轻松跑
保姆级教程:用Qwen3-VL-8B搭建本地视觉问答工具,4090显卡轻松跑 1. 为什么选择Qwen3-VL-8B? 想象一下,你正在开发一个智能相册应用,用户上传一张照片后,系统能自动回答"照片里有哪些人?&…...

Qwen3-ASR-0.6B镜像评测:轻量级语音识别模型,实测效果惊艳
Qwen3-ASR-0.6B镜像评测:轻量级语音识别模型,实测效果惊艳 1. 开箱即用的语音识别体验 第一次打开Qwen3-ASR-0.6B的Web界面时,我有点惊讶于它的简洁。整个界面只有三个核心区域:文件上传按钮、语言选择下拉框和识别结果展示区。…...

为什么AutoDL平台选择Ubuntu作为统一系统镜像?
1. 为什么AutoDL平台清一色选择Ubuntu? 第一次用AutoDL平台的朋友可能会发现一个有趣的现象:所有系统镜像清一色都是Ubuntu,从18.04到20.04再到22.04版本。这不禁让人好奇,为什么一个专业的AI计算平台会如此专一地选择Ubuntu&…...

Moe-Counter:让网站计数变得萌萌哒的终极解决方案
Moe-Counter:让网站计数变得萌萌哒的终极解决方案 【免费下载链接】Moe-Counter Moe counter badge with multiple themes! - 多种风格可选的萌萌计数器 项目地址: https://gitcode.com/gh_mirrors/mo/Moe-Counter Moe-Counter 是一款功能强大且风格多样的萌…...

在Windows 11上为Intel Iris Xe显卡配置PyTorch CPU环境:从Anaconda到成功验证
1. 为什么选择PyTorch CPU版本? 很多刚入门深度学习的同学可能会疑惑:为什么我的Intel Iris Xe显卡不能用GPU加速?其实这个问题涉及到硬件架构的差异。NVIDIA显卡之所以能加速深度学习计算,是因为它们内置了专门设计的CUDA核心&am…...

我的个人AI知识管家:用DeepSeek R1和ChromaDB给本地文档做个“搜索引擎”
我的个人AI知识管家:用DeepSeek R1和ChromaDB给本地文档做个"搜索引擎" 1. 为什么你需要一个私人知识库? 每天我们都在处理海量的信息——工作文档、学习笔记、技术资料、会议记录...这些散落在电脑各处的文件就像一座未经开采的金矿。你是否遇…...

40岁单身妈妈做装修监理16年:月入过万的真相与生活方式的选择
看到那个‘40岁单身妈妈扛楼16年月入过万’的新闻,我第一反应不是收入,是‘16年’。在这个行业里,能坚持16年,还是一位妈妈,她扛的绝对不是几袋水泥那么简单。我自己接触过不少从一线做起来的监理,尤其是女…...
,仅开放至本周日24点)
【限时解锁】2026奇点大会议程PDF+演讲PPT合集(含17场技术Demo实录链接),仅开放至本周日24点
第一章:2026奇点智能技术大会完整议程公布:50AI大咖齐聚上海 2026奇点智能技术大会(https://ml-summit.org) 由全球人工智能前沿研究机构与长三角AI产业联盟联合主办的2026奇点智能技术大会将于4月18日至20日在上海张江科学会堂举行。本届大会以“智能…...

论文降AI工具测评:10款对比后这款低至0.12%通过率极高
2026年国内学术圈AIGC检测规则全面更新,学生和科研人员对论文降AI工具的需求持续攀升,一季度用户规模已突破2000万。但市面上各类工具的技术能力差异极大,多数还停留在同义词替换、简单调整句式的浅层改写阶段,根本无法应对知网、…...