NLP从零开始------16.文本中阶处理之序列到序列模型(1)
1. 序列到序列模型简介
序列到序列( sequence to sequence, seq2seq) 是指输入和输出各为一个序列(如一句话) 的任务。本节将输入序列称作源序列,输出序列称作目标序列。序列到序列有非常多的重要应用, 其中最有名的是机器翻译( machine translation), 机器翻译模型的输入是待翻译语言(源语言) 的文本,输出则是翻译后的语言(目标语言) 的文本。
此外, 序列到序列的应用还有: 改写( paraphrase), 即将输入文本保留原意, 用意思相近的词进行重写; 风格迁移( style transfer), 即转换输入文本的风格(如口语转书面语、负面评价改为正面评价、现代文改为文言文等); 文本摘要( summarization), 即将较长的文本总结为简短精练的短文本; 问答( question answering), 即为用户输入的问题提供回答;对话( dialog),即对用户的输入进行回应。这些都是自然语言处理中非常重要的任务。另外,还有许多任务,尽管它们并非典型的序列到序列任务,但也可以使用序列到序列的方法解决,例如后面章节将要提到的命名实体识别任务,即识别输入句子中的人名、地名等实体,既可以使用后面章节将要介绍的序列标注方法来解决,也可以使用序列到序列方法解决,举例如下:
源序列: 小红在上海旅游。
目标序列:[小红|人名]在[上海|地名]旅游。
类似地,后续章节将要介绍的成分句法分析( constituency parsing)、语义角色标注( semantic role labeling, SRL)、共指消解( coreference resolution) 等任务也都可以使用序列到序列的方法解决。值得一提的是,虽然前面提到的这些任务可以利用序列到序列的方式解决,但是许多情况下效果不如其最常用的方式(如利用序列标注方法解决命名实体识别)。
对于像机器翻译这一类经典的序列到序列任务,采用基于神经网络的方法具有非常大的优势。在早期的相关研究被提出后不久,基于神经网络序列到序列的机器翻译模型效果就迅速提升并超过了更为传统的统计机器翻译模型,成为主流的机器翻译方案。因此,本节主要介绍基于神经网络的序列到序列方法,包括模型、学习和解码。随后介绍序列到序列模型中常用的指针网络与拷贝机制。最后介绍序列到序列任务的一些延伸和扩展。
2. 基于神经网络的序列到序列模型
序列到序列模型与上个章节介绍的语言模型十分类似,都需要在已有文字序列的基础上预测下一个词的概率分布。其区别是,语言模型只需建模一个序列, 而序列到序列模型需要建模两个序列,因此需要包含两个模块:一个编码器用于处理源序列,一个解码器用于生成目标序列。本小节将依次介绍基于循环神经网络、注意力机制以及 Transformer的序列到序列模型。
2.1 循环神经网络
如下图所示, 基于循环神经网络(包括长短期记忆等变体)的序列到序列模型与前几个章节介绍的循环神经网络非常相似,但是按输入不同分成了编码器、解码器两部分, 其中编码器依次接收源序列的词,但不计算任何输出。编码器最后一步的隐状态成为解码器的初始隐状态,这个隐状态向量有时称作上下文向量( context vector),它编码了整个源序列的信息。解码器在第一步接收特殊符号“< sos>”作为目标序列的起始符, 并预测第一个词的概率分布,从中解码出第一个词(解码方法将在下面讨论);随后将第一个词作为下一步的输入, 继续解码第二个词,以此类推, 直到最后解码出终止符“< oos>”,意味着目标序列已解码完毕。这种方式即前面所介绍的自回归过程。

下面介绍基于循环神经网络的编码器和解码器的代码实现。首先是作为编码器的循环神经网络。
import torch
import torch.nn as nnclass RNNEncoder(nn.Module):def __init__(self, vocab_size, hidden_size):super(RNNEncoder, self).__init__()# 隐层大小self.hidden_size = hidden_size# 词表大小self.vocab_size = vocab_size# 词嵌入层self.embedding = nn.Embedding(self.vocab_size,\self.hidden_size)self.gru = nn.GRU(self.hidden_size, self.hidden_size,\batch_first=True)def forward(self, inputs):# inputs: batch * seq_len# 注意门控循环单元使用batch_first=True,因此输入需要至少batch为1features = self.embedding(inputs)output, hidden = self.gru(features)return output, hidden接下来是作为解码器的另一个循环神经网络的代码实现。
class RNNDecoder(nn.Module):def __init__(self, vocab_size, hidden_size):super(RNNDecoder, self).__init__()self.hidden_size = hidden_sizeself.vocab_size = vocab_size# 序列到序列任务并不限制编码器和解码器输入同一种语言,# 因此解码器也需要定义一个嵌入层self.embedding = nn.Embedding(self.vocab_size, self.hidden_size)self.gru = nn.GRU(self.hidden_size, self.hidden_size,\batch_first=True)# 用于将输出的隐状态映射为词表上的分布self.linear = nn.Linear(self.hidden_size, self.vocab_size)# 解码整个序列def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):batch_size = encoder_outputs.size(0)# 从<sos>开始解码decoder_input = torch.empty(batch_size, 1,\dtype=torch.long).fill_(SOS_token)decoder_hidden = encoder_hiddendecoder_outputs = []# 如果目标序列确定,最大解码步数确定;# 如果目标序列不确定,解码到最大长度if target_tensor is not None:seq_length = target_tensor.size(1)else:seq_length = MAX_LENGTH# 进行seq_length次解码for i in range(seq_length):# 每次输入一个词和一个隐状态decoder_output, decoder_hidden = self.forward_step(\decoder_input, decoder_hidden)decoder_outputs.append(decoder_output)if target_tensor is not None:# teacher forcing: 使用真实目标序列作为下一步的输入decoder_input = target_tensor[:, i].unsqueeze(1)else:# 从当前步的输出概率分布中选取概率最大的预测结果# 作为下一步的输入_, topi = decoder_output.topk(1)# 使用detach从当前计算图中分离,避免回传梯度decoder_input = topi.squeeze(-1).detach()decoder_outputs = torch.cat(decoder_outputs, dim=1)decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)# 为了与AttnRNNDecoder接口保持统一,最后输出Nonereturn decoder_outputs, decoder_hidden, None# 解码一步def forward_step(self, input, hidden):output = self.embedding(input)output = F.relu(output)output, hidden = self.gru(output, hidden)output = self.out(output)return output, hidden
2.2 注意力机制
在序列到序列循环神经网络上加入注意力机制的方式同样与上一章节介绍的方式非常相似,区别在于,注意力机制在这里仅用于解码时建模从目标序列到源序列的依赖关系。具体而言,在解码的每一步,将解码器输出的隐状态特征作为查询,将编码器计算的源序列中每个元素的隐状态特征作为键和值,从而计算注意力输出向量; 这个输出向量会与解码器当前步骤的隐状态特征一起用于预测目标序列的下一个元素。
序列到序列中的注意力机制使得解码器能够直接“看到”源序列,而不再仅依赖循环神经网络的隐状态传递源序列的信息。此外,注意力机制提供了一种类似于人类处理此类任务时的序列到序列机制。人类在进行像翻译这样的序列到序列任务时,常常会边看源句边进行翻译,而不是一次性读完源句之后记住它再翻译, 而注意力机制模仿了这个过程。最后,注意力机制为序列到序列模型提供了一些可解释性: 通过观察注意力分布,可以知道解码器生成每个词时在注意源句中的哪些词,这可以看作源句和目标句之间的一种“软性”对齐。
下面介绍基于注意力机制的循环神经网络解码器的代码实现。我们使用一个注意力层来计算注意力权重,其输入为解码器的输入和隐状态。这里使用 Bahdanau注意力( Bahdanau attention) , 这是序列到序列模型中应用最广泛的注意力机制,特别是对于机器翻译任务。该注意力机制使用一个对齐模型( alignment model) 来计算编码器和解码器隐状态之间的注意力分数,具体来讲就是一个前馈神经网络。相比于点乘注意力, Bahdanau注意力利用了非线性变换。
import torch.nn.functional as Fclass BahdanauAttention(nn.Module):def __init__(self, hidden_size):super(BahdanauAttention, self).__init__()self.Wa = nn.Linear(hidden_size, hidden_size)self.Ua = nn.Linear(hidden_size, hidden_size)self.Va = nn.Linear(hidden_size, 1)def forward(self, query, keys):# query: batch * 1 * hidden_size# keys: batch * seq_length * hidden_size# 这一步用到了广播(broadcast)机制scores = self.Va(torch.tanh(self.Wa(query) + self.Ua(keys)))scores = scores.squeeze(2).unsqueeze(1)weights = F.softmax(scores, dim=-1)context = torch.bmm(weights, keys)return context, weightsclass AttnRNNDecoder(nn.Module):def __init__(self, vocab_size, hidden_size):super(AttnRNNDecoder, self).__init__()self.hidden_size = hidden_sizeself.vocab_size = vocab_sizeself.embedding = nn.Embedding(self.vocab_size, self.hidden_size)self.attention = BahdanauAttention(hidden_size)# 输入来自解码器输入和上下文向量,因此输入大小为2 * hidden_sizeself.gru = nn.GRU(2 * self.hidden_size, self.hidden_size,\batch_first=True)# 用于将注意力的结果映射为词表上的分布self.out = nn.Linear(self.hidden_size, self.vocab_size)# 解码整个序列def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):batch_size = encoder_outputs.size(0)# 从<sos>开始解码decoder_input = torch.empty(batch_size, 1, dtype=\torch.long).fill_(SOS_token)decoder_hidden = encoder_hiddendecoder_outputs = []attentions = []# 如果目标序列确定,最大解码步数确定;# 如果目标序列不确定,解码到最大长度if target_tensor is not None:seq_length = target_tensor.size(1)else:seq_length = MAX_LENGTH# 进行seq_length次解码for i in range(seq_length):# 每次输入一个词和一个隐状态decoder_output, decoder_hidden, attn_weights = \self.forward_step(decoder_input, decoder_hidden, encoder_outputs)decoder_outputs.append(decoder_output)attentions.append(attn_weights)if target_tensor is not None:# teacher forcing: 使用真实目标序列作为下一步的输入decoder_input = target_tensor[:, i].unsqueeze(1)else:# 从当前步的输出概率分布中选取概率最大的预测结果# 作为下一步的输入_, topi = decoder_output.topk(1)# 使用detach从当前计算图中分离,避免回传梯度decoder_input = topi.squeeze(-1).detach()decoder_outputs = torch.cat(decoder_outputs, dim=1)decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)attentions = torch.cat(attentions, dim=1)# 与RNNDecoder接口保持统一,最后输出注意力权重return decoder_outputs, decoder_hidden, attentions# 解码一步def forward_step(self, input, hidden, encoder_outputs):embeded = self.embedding(input)# 输出的隐状态为1 * batch * hidden_size,# 注意力的输入需要batch * 1 * hidden_sizequery = hidden.permute(1, 0, 2)context, attn_weights = self.attention(query, encoder_outputs)input_gru = torch.cat((embeded, context), dim=2)# 输入的隐状态需要1 * batch * hidden_sizeoutput, hidden = self.gru(input_gru, hidden)output = self.out(output)return output, hidden, attn_weights
2.3 Transformer
Transformer模型同样也可以用于序列到序列任务。编码器与上一章介绍的 Transformer结构几乎相同,仅有两方面区别。一方面,由于不需要像语言模型那样每一步只能看到前置序列,而是需要看到完整的句子, 因此掩码多头自注意力模块中去除了注意力掩码。另一方面,由于编码器不需要输出,因此去掉了顶层的线性分类器。
解码器同样与上一章介绍的 Transformer结构几乎相同,但在掩码多头自注意力模块之后增加了一个交叉多头注意力模块,以便在解码时引入编码器所计算的源序列的信息。交叉注意力模块的设计与上面介绍的循环神经网络上的注意力机制是类似的。具体而言,交叉注意力模块使用解码器中自注意力模块的输出计算查询,使用编码器顶端的输出计算键和值,不使用任何注意力掩码, 其他部分与自注意力模块一样。
基于 Transformer的序列到序列模型通常也使用自回归的方式进行解码, 但 Transformer不同位置之间的并行性,使得非自回归方式的解码成为可能。非自回归解码器的结构与自回归解码器类似,但解码时需要先预测目标句的长度,将该长度对应个数的特殊符号作为输入,此外自注意力模块不需要掩码,所有位置的计算并行执行。有关具体细节这里不再展开。
接下来我们复用上一章的代码,实现基于 Transformer的编码器和解码器。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import sys
sys.path.append('./code')
from transformer import *class TransformerEncoder(nn.Module):def __init__(self, vocab_size, max_len, hidden_size, num_heads,\dropout, intermediate_size):super().__init__()self.embedding_layer = EmbeddingLayer(vocab_size, max_len,\hidden_size)# 直接使用TransformerLayer作为编码层,简单起见只使用一层self.layer = TransformerLayer(hidden_size, num_heads,\dropout, intermediate_size)# 与TransformerLM不同,编码器不需要线性层用于输出def forward(self, input_ids):# 这里实现的forward()函数一次只能处理一句话,# 如果想要支持批次运算,需要根据输入序列的长度返回隐状态assert input_ids.ndim == 2 and input_ids.size(0) == 1seq_len = input_ids.size(1)assert seq_len <= self.embedding_layer.max_len# 1 * seq_lenpos_ids = torch.unsqueeze(torch.arange(seq_len), dim=0)attention_mask = torch.ones((1, seq_len), dtype=torch.int32)input_states = self.embedding_layer(input_ids, pos_ids)hidden_states = self.layer(input_states, attention_mask)return hidden_states, attention_maskclass MultiHeadCrossAttention(MultiHeadSelfAttention):def forward(self, tgt, tgt_mask, src, src_mask):"""tgt: query, batch_size * tgt_seq_len * hidden_sizetgt_mask: batch_size * tgt_seq_lensrc: keys/values, batch_size * src_seq_len * hidden_sizesrc_mask: batch_size * src_seq_len"""# (batch_size * num_heads) * seq_len * (hidden_size / num_heads)queries = self.transpose_qkv(self.W_q(tgt))keys = self.transpose_qkv(self.W_k(src))values = self.transpose_qkv(self.W_v(src))# 这一步与自注意力不同,计算交叉掩码# batch_size * tgt_seq_len * src_seq_lenattention_mask = tgt_mask.unsqueeze(2) * src_mask.unsqueeze(1)# 重复张量的元素,用以支持多个注意力头的运算# (batch_size * num_heads) * tgt_seq_len * src_seq_lenattention_mask = torch.repeat_interleave(attention_mask,\repeats=self.num_heads, dim=0)# (batch_size * num_heads) * tgt_seq_len * \# (hidden_size / num_heads)output = self.attention(queries, keys, values, attention_mask)# batch * tgt_seq_len * hidden_sizeoutput_concat = self.transpose_output(output)return self.W_o(output_concat)# TransformerDecoderLayer比TransformerLayer多了交叉多头注意力
class TransformerDecoderLayer(nn.Module):def __init__(self, hidden_size, num_heads, dropout,\intermediate_size):super().__init__()self.self_attention = MultiHeadSelfAttention(hidden_size,\num_heads, dropout)self.add_norm1 = AddNorm(hidden_size, dropout)self.enc_attention = MultiHeadCrossAttention(hidden_size,\num_heads, dropout)self.add_norm2 = AddNorm(hidden_size, dropout)self.fnn = PositionWiseFNN(hidden_size, intermediate_size)self.add_norm3 = AddNorm(hidden_size, dropout)def forward(self, src_states, src_mask, tgt_states, tgt_mask):# 掩码多头自注意力tgt = self.add_norm1(tgt_states, self.self_attention(\tgt_states, tgt_states, tgt_states, tgt_mask))# 交叉多头自注意力tgt = self.add_norm2(tgt, self.enc_attention(tgt,\tgt_mask, src_states, src_mask))# 前馈神经网络return self.add_norm3(tgt, self.fnn(tgt))class TransformerDecoder(nn.Module):def __init__(self, vocab_size, max_len, hidden_size, num_heads,\dropout, intermediate_size):super().__init__()self.embedding_layer = EmbeddingLayer(vocab_size, max_len,\hidden_size)# 简单起见只使用一层self.layer = TransformerDecoderLayer(hidden_size, num_heads,\dropout, intermediate_size)# 解码器与TransformerLM一样,需要输出层self.output_layer = nn.Linear(hidden_size, vocab_size)def forward(self, src_states, src_mask, tgt_tensor=None):# 确保一次只输入一句话,形状为1 * seq_len * hidden_sizeassert src_states.ndim == 3 and src_states.size(0) == 1if tgt_tensor is not None:# 确保一次只输入一句话,形状为1 * seq_lenassert tgt_tensor.ndim == 2 and tgt_tensor.size(0) == 1seq_len = tgt_tensor.size(1)assert seq_len <= self.embedding_layer.max_lenelse:seq_len = self.embedding_layer.max_lendecoder_input = torch.empty(1, 1, dtype=torch.long).\fill_(SOS_token)decoder_outputs = []for i in range(seq_len):decoder_output = self.forward_step(decoder_input,\src_mask, src_states)decoder_outputs.append(decoder_output)if tgt_tensor is not None:# teacher forcing: 使用真实目标序列作为下一步的输入decoder_input = torch.cat((decoder_input,\tgt_tensor[:, i:i+1]), 1)else:# 从当前步的输出概率分布中选取概率最大的预测结果# 作为下一步的输入_, topi = decoder_output.topk(1)# 使用detach从当前计算图中分离,避免回传梯度decoder_input = torch.cat((decoder_input,\topi.squeeze(-1).detach()), 1)decoder_outputs = torch.cat(decoder_outputs, dim=1)decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)# 与RNNDecoder接口保持统一return decoder_outputs, None, None# 解码一步,与RNNDecoder接口略有不同,RNNDecoder一次输入# 一个隐状态和一个词,输出一个分布、一个隐状态# TransformerDecoder不需要输入隐状态,# 输入整个目标端历史输入序列,输出一个分布,不输出隐状态def forward_step(self, tgt_inputs, src_mask, src_states):seq_len = tgt_inputs.size(1)# 1 * seq_lenpos_ids = torch.unsqueeze(torch.arange(seq_len), dim=0)tgt_mask = torch.ones((1, seq_len), dtype=torch.int32)tgt_states = self.embedding_layer(tgt_inputs, pos_ids)hidden_states = self.layer(src_states, src_mask, tgt_states,\tgt_mask)output = self.output_layer(hidden_states[:, -1:, :])return output相关文章:
NLP从零开始------16.文本中阶处理之序列到序列模型(1)
1. 序列到序列模型简介 序列到序列( sequence to sequence, seq2seq) 是指输入和输出各为一个序列(如一句话) 的任务。本节将输入序列称作源序列,输出序列称作目标序列。序列到序列有非常多的重要应用, 其中最有名的是机器翻译( machine translation), 机…...

【匈牙利汽车产业考察,开启新机遇】
匈牙利汽车工业发展历史悠久,拥有发达的基础设施和成熟的产业基础,全球20大汽车制造厂商中,有超过14家在匈牙利建立整车制造工厂和汽车零部件生产基地,比亚迪、宁德时代、欣旺达、蔚来等企业纷纷入驻。匈牙利位于东西方交汇处&…...

并行程序设计基础——动态进程管理
目录 一、组间通信域 二、动态创建新的MPI进程 1、MPI_COMM_SPAWN 2、MPI_COMM_GET_PARENT 3、MPI_COMM_SPAWN_MULTIPLE 三、独立进程间的通信 1、MPI_OPEN_PORT 2、MPI_COMM_ACCEPT 3、MPI_CLOSE_PORT 4、MPI_COMM_CONNECT 5、MPI_COMM_DISCONNECT 6、MPI_PUBLISH…...
使用教程)
C# 字符串(String)使用教程
在 C# 中,您可以使用字符数组来表示字符串,但是,更常见的做法是使用 string 关键字来声明一个字符串变量。string 关键字是 System.String 类的别名。 创建 String 对象 您可以使用以下方法之一来创建 string 对象: 通过给 Str…...

django之ForeignKey、OneToOneField 和 ManyToManyField
在Django中,ForeignKey、OneToOneField 和 ManyToManyField 是用于定义模型之间关系的字段类型。 ForeignKey ForeignKey 用于定义多对一的关系。例如,一个Employee可以属于一个Department,一个Department可以有多个Employee。 from djang…...

java.lang.IndexOutOfBoundsException: setSpan ( 0...x ) ends beyond length X
1,可能是EditText,setSelection(x)时超过了 输入框内容的实际长度导致的。 2,手机开启“拼写检查功能”,EditText设置了最大长度,选择提示的某一项文案时超过设置的最大长度限制,导致崩溃。 针对情况2 开…...

技术进展:CH-90树脂在去除硫酸钠柠檬酸钠溶液中铁锰离子上的应用
随着环境保护法规的日趋严格,以及工业生产中对产品纯度要求的不断提高,去除废水中的重金属离子已成为一个亟待解决的问题。铁和锰作为常见的杂质离子,在电池制造等行业中,对溶液纯度的影响不容忽视。 三元前驱体废水中通常含有硫…...
录屏时摄像头无法识别?如何录屏时打开摄像头,解决方案及录屏软件推荐
在数字时代,无论是游戏玩家、在线教育者还是企业培训师,录屏软件都已成为日常工作和娱乐中不可或缺的工具。但有时候想录制人物摄像头画面的时候,当录屏软件无法识别到摄像头时,这无疑会给用户带来不小的困扰。本文将提供一系列解…...

达梦数据库-DM8 企业版安装指南
一、DM8 企业版简介 达梦数据库(DM8)是中国自主研发的一款高性能数据库管理系统,广泛应用于企业级应用场景。DM8 企业版具备高可用性、强一致性和高性能等特点,支持多种操作系统和硬件平台。本文将详细介绍如何在 Kylin 操作系统上安装达梦数据库 DM8 企业版。 二、安装前…...

心脑血管科董田林医生:心律失常患者饮食,调养秘诀,助你找回健康心跳
在纷繁复杂的健康议题中,心律失常作为一种常见的心脏疾病,不仅影响着患者的生活质量,更牵动着每一个家庭的神经。幸运的是,通过科学合理的饮食调养,心律失常患者可以在很大程度上改善病情,逐步找回健康的心…...
)
期权杂记(一)
2024年9月5日: 切忌裸奔!如果你想暴富,押注期权还不如去澳门;做任何策略都可以多多关注希腊字母;对冲也是又方向性的,可以偏购,也可以偏沽,通过Delta Money来尝试计算;单…...
【MATLAB源码-第163期】基于matlab的BPSK+瑞利(rayleigh)信道下有无波束成形误码率对比仿真。
操作环境: MATLAB 2022a 1、算法描述 在通信系统中,波束成形(Beamforming)技术是一种广泛使用的信号处理技术,通过调整天线阵列中各个元素的相位和幅度,使得信号在特定方向上增强,在其他方向…...
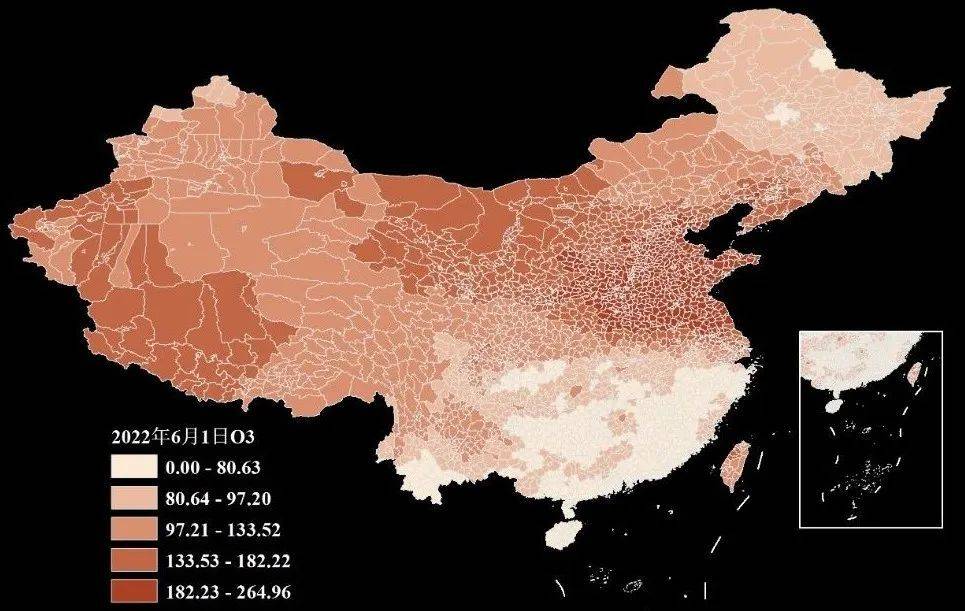
【数据分享】2000-2022年我国省市县三级的逐日O3数据(免费获取\excel\shp格式)
空气质量数据是在我们日常研究中经常使用的数据!之前我们给大家分享了2000-2022年的省市县三级的逐日PM2.5数据、2013-2022年的省市县三级的逐日CO数据、2013-2022年的省市县三级的逐日SO2数据、2008-2022年我国省市县三级的逐日NO2数据和2000-2022年我国省市县三级…...

Python 的http.server库详细介绍
http.server 是 Python 标准库中的一个模块,用于创建基本的 HTTP 服务器。这个模块非常适合用于开发、测试、以及在本地网络中共享文件。以下是对 http.server 模块的详细介绍。 Python 官方文档:http.server — HTTP 服务器 模块概述 http.server 提…...

使用ffmpeg在视频中绘制矩形区域
由于项目需要对视频中的人脸做定位跟踪, 我先使用了人脸识别算法,对视频中的每个帧识别人脸、通过人脸库比对,最终记录坐标等信息。 然后使用ffmpeg中的 drawbox 滤镜功能,选择性的绘制区域。从而实现人脸定位跟踪 1、drawbox …...

计算机,数学,AI在社会模拟中的应用
这些模型通常属于社会模拟的范畴,利用计算机技术和复杂系统理论来模拟和预测社会动态。以下是几种常见的社会模拟模型: 1. 系统动力学模型 系统动力学模型通过建立数学方程来描述社会系统中的各种变量及其相互关系。这种模型适用于宏观层面的社会变化分…...

【数据结构】排序算法系列——插入排序(附源码+图解)
插入排序 算法思想 插入排序的算法思想其实很容易理解,它秉持着一个不变的循环:比较->交换->比较->交换…因为我们排序最终的目的是要得到递增或者递减的数据,那么在原有的数据中,我们可以将数据依次两两进行比较&…...

TOMATO靶机漏洞复现
步骤一,我们来到tomato页面 什么也弄不了只有一番茄图片 弱口令不行,xxs也不行,xxe还是不行 我们来使用kali来操作... 步骤二,使用dirb再扫一下, dirb http://172.16.1.133 1.发现这个文件可以访问.我们来访问一下 /antibot_i…...

高基数 GroupBy 在 SLS SQL 中的查询加速
作者:顾汉杰(执少) 什么是高基数 GroupBy 简单来说,想要分析的数据,拥有超多的“唯一值计数”(Distinct Count),而我们需要对这些数据进行分组分析(如统计次数、排名、…...

TP5队列和TP5 使用redis 等相关
TP5.thinkphp之门面(facade类)面试_thinkphp facade-CSDN博客 TP5中的消息队列_tp 5.0 队列 release 时间单位-CSDN博客 thinkphp-queue自带的队列包使用分析_php think queue:listen-CSDN博客TP5 使用redis_tp5 redis-CSDN博客...

SmolVLA企业级应用:基于.NET框架的智能业务系统集成
SmolVLA企业级应用:基于.NET框架的智能业务系统集成 最近和几个做企业级开发的朋友聊天,他们都在头疼一件事:公司业务系统越来越复杂,每天要处理大量审批、报表和客户沟通,人工操作效率低还容易出错。他们问我&#x…...

【Blazor 2026技术前瞻白皮书】:一线架构师亲授3步极速接入现代Web开发栈
第一章:Blazor 2026技术演进全景图与战略定位Blazor 在 2026 年已全面完成从客户端渲染(WebAssembly)到混合执行模型的范式跃迁,其核心定位演变为“统一全栈组件化平台”——既可原生驱动边缘 IoT 设备上的轻量 UI,亦能…...

Acunetix WVS 13实战:如何高效扫描企业网站漏洞并生成专业报告
Acunetix WVS 13企业级漏洞扫描实战:从策略优化到报告生成 在数字化转型浪潮中,企业网站作为对外展示和业务交互的核心窗口,其安全性直接关系到企业声誉和用户信任。一次成功的渗透测试可能发现数十个潜在漏洞,但如何系统化地识别…...

生态环评实战指南:遥感解译、生物多样性建模与景观格局分析技术全流程
1. 生态环评技术框架解析 生态环评就像给地球做体检,需要一套系统化的检查流程。我参与过多个复合型项目评估,发现最关键的环节往往在前期框架搭建。最新技术导则要求采用"陆域-水域"一体化评估模式,这意味着我们需要同时关注森林、…...

HakcMyVM-Nebula
信息搜集 主机发现 ┌──(kali㉿kali)-[~] └─$ nmap -sn 192.168.2.0/24 Starting Nmap 7.95 ( https://nmap.org ) at 2026-04-10 00:30 EDT Nmap scan report for laboratoryuser (192.168.2.2) Host is up (0.00029s latency). MAC Address: 08:00:27:DD:5D:00 (PCS S…...

分布式锁的实现,选Redis还是ZooKeeper?
一、问题场景:为什么测试工程师需要关注分布式锁?在分布式系统中,库存超卖、定时任务重复执行、数据覆盖等典型缺陷,往往源于分布式锁失效。例如:测试环境中,两个服务节点同时判定库存为1并完成扣减定时任务…...

C# 实现异步非阻塞式定时关闭消息弹窗
1. 为什么需要异步非阻塞式消息弹窗 在日常开发中,MessageBox.Show()可能是我们最先接触到的弹窗方式。但用过几次就会发现,这个看似方便的方法存在两个致命缺陷:一是必须等待用户点击确认按钮,二是会阻塞当前线程的执行。想象一下…...

C++ P1151 子数整数
文章目录一、题目链接二、参考代码一、题目链接 链接: link 二、参考代码 #include <iostream> #include <string> #include <algorithm> #include <math.h> using namespace std;int main() {int num;cin >> num;int key 0;for (int i 1000…...

Python数据可视化指南
Python数据可视化指南 后端转 Rust 的萌新,ID "第一程序员"——名字大,人很菜(暂时)。正在跟所有权和生命周期死磕,日常记录 Rust 学习路上的踩坑经验和"啊哈时刻",代码片段保证能跑。…...

FreakStudio锰
环境安装 pip install keystone-engine capstone unicorn 这3个工具用法极其简单,下面通过示例来演示其用法。 Keystone 示例 from keystone import * CODE b"INC ECX; ADD EDX, ECX" try:ks Ks(KS_ARCH_X86, KS_MODE_64)encoding, count ks.asm(CODE)…...