Python操作数据库的ORM框架SQLAlchemy快速入门教程
连接内存版SQLIte
from sqlalchemy import create_engineengine = create_engine('sqlite:///:memory:')
print(engine)连接文件版SQLite
from sqlalchemy import create_engineengine = create_engine('sqlite:///sqlite3.db')
print(engine)
连接MySQL数据库
from sqlalchemy import create_engineengine = create_engine('mysql+pymysql://root:zhangdapeng520@127.0.0.1:3306/fastzdp_sqlalchemy?charset=utf8')
print(engine)
根据模型自动创建表
import enum
from datetime import datetime
from decimal import Decimalimport sqlalchemy
from sqlalchemy import create_engine, DateTime, func, String
from sqlalchemy.orm import Mapped, DeclarativeBase, mapped_columnengine = create_engine('mysql+pymysql://root:zhangdapeng520@127.0.0.1:3306/fastzdp_sqlalchemy?charset=utf8')class BaseModel(DeclarativeBase):"""基础模型"""id: Mapped[int] = mapped_column(primary_key=True, autoincrement=True)create_time: Mapped[datetime] = mapped_column(DateTime, insert_default=func.now(), comment="创建时间")update_time: Mapped[datetime] = mapped_column(DateTime, insert_default=func.now(), onupdate=func.now(),comment="更新时间")class GenderEnum(enum.Enum):MALE = "男"FEMALE = "女"class Employee(BaseModel):"""员工模型,对应员工表"""__tablename__ = 'employee'name: Mapped[str] = mapped_column(String(36), index=True, nullable=False, comment="姓名")age: Mapped[int] = mapped_column(comment="年龄")salary: Mapped[Decimal] = mapped_column(sqlalchemy.DECIMAL, nullable=False, comment="薪资")bonus: Mapped[float] = mapped_column(sqlalchemy.FLOAT, default=0, comment="奖金")is_leave: Mapped[bool] = mapped_column(sqlalchemy.Boolean, default=False, comment="是否离职")gender: Mapped[GenderEnum] = mapped_column(sqlalchemy.String(6), default=GenderEnum.MALE, comment="性别")if __name__ == '__main__':BaseModel.metadata.drop_all(engine)BaseModel.metadata.create_all(engine)
通过session新增数据
with Session(engine) as session:session.begin()try:session.add(Employee(name="张三", age=23, salary=Decimal(30000),gender=GenderEnum.MALE.value))except:session.rollback()session.commit()
通过sessionmaker添加数据
with sessionmaker(engine).begin() as session:session.add(Employee(name="李四", age=23, salary=Decimal(30000), gender=GenderEnum.MALE.value))
批量新增数据
with sessionmaker(engine).begin() as session:employees = [Employee(name="张三1", age=23, salary=Decimal(30000), gender=GenderEnum.MALE.value),Employee(name="张三2", age=23, salary=Decimal(30000), gender=GenderEnum.MALE.value),Employee(name="张三3", age=23, salary=Decimal(30000), gender=GenderEnum.MALE.value),]session.add_all(employees)
根据ID查询
with sessionmaker(engine).begin() as session:employee = session.get(Employee, 1)print(employee.name)
查询所有的数据
with sessionmaker(engine).begin() as session:query = select(Employee)data = session.scalars(query).all()print(data)for employee in data:print(employee.name, employee.age)
查询指定字段
with sessionmaker(engine).begin() as session:query = select(Employee.id, Employee.name, Employee.age)data = session.execute(query).all()print(data)for employee in data: # rowprint(employee.name, employee.age)
执行原生SQL语句进行查询
with sessionmaker(engine).begin() as session:query = sqlalchemy.text("select id,name,age from employee")data = session.execute(query).all()print(data)for employee in data: # rowprint(employee.name, employee.age)
根据ID修改数据
with sessionmaker(engine).begin() as session:employee = session.get(Employee, 1)employee.name = "张三333"
执行update方法
with sessionmaker(engine).begin() as session:query = sqlalchemy.update(Employee).where(Employee.id == 1).values(name="张三", age=33)session.execute(query)
根据ID删除数据
with sessionmaker(engine).begin() as session:employee = session.get(Employee, 1)session.delete(employee)
执行delete方法
with sessionmaker(engine).begin() as session:query = sqlalchemy.delete(Employee).where(Employee.id == 2)session.execute(query)
执行is null查询
with sessionmaker(engine).begin() as session:query = select(Employee).where(Employee.salary.is_(None)) # is nullemployees = session.execute(query).scalars()print(employees)
执行is not null查询
with sessionmaker(engine).begin() as session:query = select(Employee).where(Employee.salary.isnot(None)) # is not nullemployees = session.execute(query).scalars()print(employees)for employee in employees:print(employee.name, employee.age, employee.salary, employee.bonus, employee.is_leave)
执行like模糊查询
with sessionmaker(engine).begin() as session:query = select(Employee).where(Employee.name.like("%3")) # like 模糊查询employees = session.execute(query).scalars()print(employees)for employee in employees:print(employee.name, employee.age, employee.salary, employee.bonus, employee.is_leave)
执行in查询
with sessionmaker(engine).begin() as session:query = select(Employee).where(Employee.id.in_([3, 5])) # in 查询employees = session.execute(query).scalars()print(employees)for employee in employees:print(employee.name, employee.age, employee.salary, employee.bonus, employee.is_leave)
执行or查询
with sessionmaker(engine).begin() as session:query = select(Employee).where(sqlalchemy.or_(Employee.age < 20, Employee.age > 30)) # or 查询employees = session.execute(query).scalars()print(employees)for employee in employees:print(employee.name, employee.age, employee.salary, employee.bonus, employee.is_leave)
求平均薪资
with sessionmaker(engine).begin() as session:query = select(func.avg(Employee.salary))avg = session.execute(query).first()print(avg)
统计表中的数据个数
with sessionmaker(engine).begin() as session:query = select(func.count(Employee.id))id_count = session.execute(query).first()print(id_count)
执行分页查询
with sessionmaker(engine).begin() as session:query = select(Employee).offset(2).limit(2)data = session.execute(query).scalars()for employee in data:print(employee.id, employee.name)
执行排序查询
with sessionmaker(engine).begin() as session:# query = select(Employee).order_by(Employee.age.desc()) # 降序query = select(Employee).order_by(Employee.age) # 升序data = session.execute(query).scalars()for employee in data:print(employee.id, employee.name, employee.age)
执行分组聚合查询
with sessionmaker(engine).begin() as session:query = select(Employee.gender, func.count(Employee.id)).group_by(Employee.gender)data = session.execute(query).all()for row in data:print(row.gender, row.count)
相关文章:

Python操作数据库的ORM框架SQLAlchemy快速入门教程
连接内存版SQLIte from sqlalchemy import create_engineengine create_engine(sqlite:///:memory:) print(engine)连接文件版SQLite from sqlalchemy import create_engineengine create_engine(sqlite:///sqlite3.db) print(engine)连接MySQL数据库 from sqlalchemy imp…...

提交MR这个词儿您知道是什么意思吗?
作为测试的同学,是不是经常会听研发同学说提交MR呢?那么究竟什么是提交MR呢?在这篇文章中会告诉大家! 在Git中,提交MR(Merge Request,合并请求)是在进行协作开发的一种常见方式&…...

Linux sentinel写法
在linux驱动里我们经常能看到类似下面的写法: static const struct of_device_id asensm6_of_match[] {{ .compatible DRIVER_COMPATIBLE },{ /* sentinel */ }, };static const struct of_device_id rockchip_pinctrl_dt_match[] {{ .compatible "rockch…...

顶级域名服务器 - TLD服务器
TLD服务器(顶级域名服务器)是负责管理互联网域名系统(DNS)中所有顶级域名(Top-Level Domains, TLDs)的DNS记录的服务器。顶级域名是域名层级结构中的最高级别,位于域名的最右侧,例如…...

【LeetCode】01.两数之和
题目要求 做题链接:1.两数之和 解题思路 我们这道题是在nums数组中找到两个两个数使得他们的和为target,最简单的方法就是暴力枚举一遍即可,时间复杂度为O(N),空间复杂度为O(1)。…...

便宜好用的云手机盘点
云手机作为一种新型远程计算服务,凭借其便利性、高效性和可扩展性,迅速成为了用户的热门选择。然而,面对市场上众多的云手机品牌,如何选择一款性价比高且体验良好的云手机?本文将为您盘点几款便宜好用的云手机产品。 雷…...
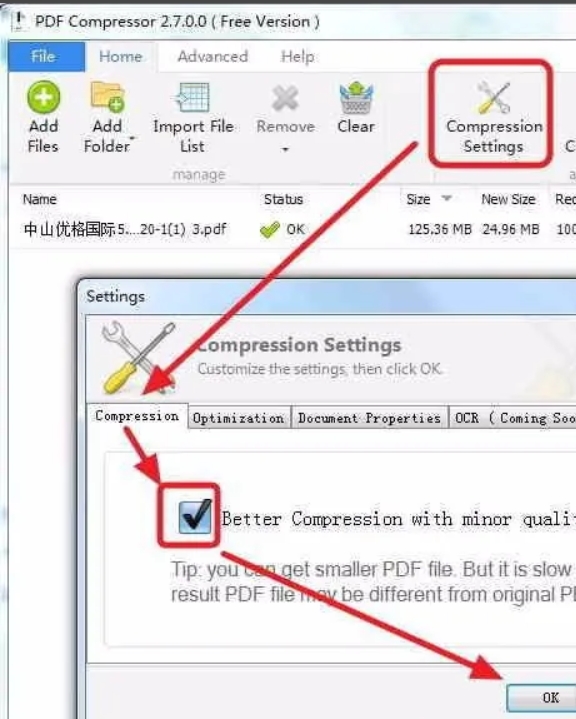
pdf怎么压缩小一些?推荐的几种PDF压缩方法
pdf怎么压缩小一些?在工作中,我们经常处理PDF文件。大文件不仅存储麻烦,还会拖慢传输速度。因此,我们通常希望将这些文件压缩成更小的尺寸。压缩后的文件更便于分享和管理,适用于云存储、社交媒体或其他在线平台&#…...

Linux终端简单配置(Vim、oh-my-zsh和Terminator)
文章目录 0. 概述1. 完整Vim配置2. Vim配置方案解释2.1 状态行与配色方案2.2 文件管理与缓存设置2.3 搜索与导航优化2.4 缩进与格式化设置2.5 粘贴模式快捷切换2.6 文件编码与格式2.7 性能优化 3. 安装 Oh My Zsh 及配置3.1 安装 Oh My Zsh3.2 Oh My Zsh 配置 3. Terminator终端…...

js模块化 --- commonjs规范 原理详解
什么是commonjs规范 commonjs是一种模块化规范(nodejs的默认模块化规范,新版的nodejs已经支持es6的模块化,但它默认任然使用的是commonjs),通俗的说它将代码分割成了一个一个的模块,让不同的模块拥有自己独…...

kubeadm部署 Kubernetes(k8s) 高可用集群【V1.28 】
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。 calico.yaml kubernertes-dashboard.yaml 1. 安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 10台机器,操作系统Openeuler22.03 LTS SP4硬件配置&…...

【MySQL】MySQL Workbench下载安装、环境变量配置、基本MySQL语句、新建Connection
1.MySQL Workbench 下载安装: 进入网址:MySQL :: MySQL Workbench Manual :: 2 Installation (1)点击“MySQL Workbench on Windows”(下载Windows版本)(2)点击“Installing” &…...

CrowdStrike 的失败如何凸显了左移测试的重要性
通过自动化软件测试并将其左移,组织可以显著降低 CrowdStrike 等事件发生的风险。继续阅读,了解采用左移测试方法的强大之处。 Parasoft下载 测试中偷工减料的风险 CrowdStrike 软件更新失败是一个重要的教训,它让我们认识到早期、自动…...

HarmonyOS开发实战( Beta5版)高负载组件的渲染实践规范
简介 在应用开发中,有的页面需要在列表中加载大量的数据,就会导致组件数量较多或者嵌套层级较深,从而引起组件负载加重,绘制耗时增长。虽然可以通过组件复用避免组件重复创建,但是如果每个列表项中包含的组件较多&…...

NLP从零开始------16.文本中阶处理之序列到序列模型(1)
1. 序列到序列模型简介 序列到序列( sequence to sequence, seq2seq) 是指输入和输出各为一个序列(如一句话) 的任务。本节将输入序列称作源序列,输出序列称作目标序列。序列到序列有非常多的重要应用, 其中最有名的是机器翻译( machine translation), 机…...

【匈牙利汽车产业考察,开启新机遇】
匈牙利汽车工业发展历史悠久,拥有发达的基础设施和成熟的产业基础,全球20大汽车制造厂商中,有超过14家在匈牙利建立整车制造工厂和汽车零部件生产基地,比亚迪、宁德时代、欣旺达、蔚来等企业纷纷入驻。匈牙利位于东西方交汇处&…...

并行程序设计基础——动态进程管理
目录 一、组间通信域 二、动态创建新的MPI进程 1、MPI_COMM_SPAWN 2、MPI_COMM_GET_PARENT 3、MPI_COMM_SPAWN_MULTIPLE 三、独立进程间的通信 1、MPI_OPEN_PORT 2、MPI_COMM_ACCEPT 3、MPI_CLOSE_PORT 4、MPI_COMM_CONNECT 5、MPI_COMM_DISCONNECT 6、MPI_PUBLISH…...
使用教程)
C# 字符串(String)使用教程
在 C# 中,您可以使用字符数组来表示字符串,但是,更常见的做法是使用 string 关键字来声明一个字符串变量。string 关键字是 System.String 类的别名。 创建 String 对象 您可以使用以下方法之一来创建 string 对象: 通过给 Str…...

django之ForeignKey、OneToOneField 和 ManyToManyField
在Django中,ForeignKey、OneToOneField 和 ManyToManyField 是用于定义模型之间关系的字段类型。 ForeignKey ForeignKey 用于定义多对一的关系。例如,一个Employee可以属于一个Department,一个Department可以有多个Employee。 from djang…...

java.lang.IndexOutOfBoundsException: setSpan ( 0...x ) ends beyond length X
1,可能是EditText,setSelection(x)时超过了 输入框内容的实际长度导致的。 2,手机开启“拼写检查功能”,EditText设置了最大长度,选择提示的某一项文案时超过设置的最大长度限制,导致崩溃。 针对情况2 开…...

技术进展:CH-90树脂在去除硫酸钠柠檬酸钠溶液中铁锰离子上的应用
随着环境保护法规的日趋严格,以及工业生产中对产品纯度要求的不断提高,去除废水中的重金属离子已成为一个亟待解决的问题。铁和锰作为常见的杂质离子,在电池制造等行业中,对溶液纯度的影响不容忽视。 三元前驱体废水中通常含有硫…...
,新手照做就能从0到1)
黑客入门3个月实战计划(附每日任务),新手照做就能从0到1
前言 新手学黑客,没有计划很容易“三天打鱼两天晒网”。本文给你制定一份3个月实战计划,分阶段拆解每日任务,从零基础到能独立做基础渗透测试,每天1-2小时,照做就能完成目标。全程合规,只在靶场练习。 一、…...
)
告别‘打架’的目标:用CMPSO算法轻松搞定多目标优化(Python代码实战)
告别‘打架’的目标:用CMPSO算法轻松搞定多目标优化(Python代码实战) 想象一下,你正在设计一款新型电动汽车,需要同时优化续航里程、制造成本和充电速度。这三个目标就像三个固执的谈判代表,各自坚持己见—…...

Go-multierror 实战案例:10个常见场景的错误处理优化
Go-multierror 实战案例:10个常见场景的错误处理优化 【免费下载链接】go-multierror A Go (golang) package for representing a list of errors as a single error. 项目地址: https://gitcode.com/gh_mirrors/go/go-multierror 在Go语言开发中,…...

CSS 渐变:创造绚丽的色彩效果
CSS 渐变:创造绚丽的色彩效果 掌握 CSS 渐变的高级技巧,创造绚丽而独特的色彩效果。 一、渐变概述 作为一名把代码当散文写的 UI 匠人,我对 CSS 渐变有着独特的见解。渐变是 CSS 的强大特性,它可以让我们创建从一种颜色到另一种颜…...

Metasploit 框架介绍
Metasploit 是全球最流行的渗透测试框架之一,由 Rapid7 维护开源版本(Metasploit Framework)和商业版(Metasploit Pro)。 📦 核心组件 组件 说明 msfconsole 交互式命令行界面,最主要的操作…...

Windows空间魔术师:FreeMove如何用符号链接为你的C盘减负30%
Windows空间魔术师:FreeMove如何用符号链接为你的C盘减负30% 【免费下载链接】FreeMove Move directories without breaking shortcuts or installations 项目地址: https://gitcode.com/gh_mirrors/fr/FreeMove 想象一下,你的C盘就像一个拥挤的储…...

omniMath:嵌入式轻量级数学表达式求值与单位转换库
1. omniMath 库深度解析:面向嵌入式系统的轻量级数学表达式求值与单位转换引擎1.1 库定位与工程价值omniMath 是一款专为 Arduino 及兼容平台(如 Raspberry Pi Pico、ESP32、STM32duino)设计的嵌入式数学计算库。其核心价值不在于替代浮点协处…...

SpringAI 1.0.0 实战:用阿里百炼平台免费额度,5分钟搞定你的第一个AI对话接口
SpringAI 1.0.0实战:零成本搭建AI对话接口的完整指南 最近在技术社区里看到不少开发者对AI应用开发跃跃欲试,但往往被高昂的API调用成本劝退。作为一个经历过同样困扰的开发者,我发现阿里百炼平台提供的免费额度简直是成本敏感型开发者的福音…...

fpga系列 HDL:跨时钟域同步 双触发器同步器
目录双触发器同步器(Two-Flip-Flop Synchronizer)示例代码:双触发器同步器的优缺点优点:缺点:适用场景:应用实例:同步来自spi_slave的单个使能信号跨时钟域的设计需要特别小心,以避免…...

SteamCleaner游戏空间清理完整指南:快速释放硬盘空间的终极解决方案
SteamCleaner游戏空间清理完整指南:快速释放硬盘空间的终极解决方案 【免费下载链接】SteamCleaner :us: A PC utility for restoring disk space from various game clients like Origin, Steam, Uplay, Battle.net, GoG and Nexon :us: 项目地址: https://gitco…...