Java中循环使用Stream应用场景
在JAVA中,涉及到对数组、Collection等集合类中的元素进行操作的时候,通常会通过循环的方式进行逐个处理,或者使用Stream的方式进行处理。
例如,现在有这么一个需求:
从给定句子中返回单词长度大于5的单词列表,按长度倒序输出,最多返回3个
在JAVA7及之前的代码中,我们会可以照如下的方式进行实现:
public List<String> sortGetTop3LongWords(@NotNull String sentence) {// 先切割句子,获取具体的单词信息String[] words = sentence.split(" ");List<String> wordList = newArrayList<>();// 循环判断单词的长度,先过滤出符合长度要求的单词for (String word : words) {if (word.length() > 5) {wordList.add(word);}}// 对符合条件的列表按照长度进行排序wordList.sort((o1, o2) -> o2.length() - o1.length());// 判断list结果长度,如果大于3则截取前三个数据的子list返回if (wordList.size() > 3) {wordList = wordList.subList(0, 3);}return wordList;
}复制代码在JAVA8及之后的版本中,借助Stream流,我们可以更加优雅的写出如下代码:
public List<String> sortGetTop3LongWordsByStream(@NotNull String sentence) {return Arrays.stream(sentence.split(" ")).filter(word -> word.length() > 5).sorted((o1, o2) -> o2.length() - o1.length()).limit(3).collect(Collectors.toList());
}复制代码直观感受上,Stream的实现方式代码更加简洁、一气呵成。很多的同学在代码中也经常使用Stream流,但是对Stream流的认知往往也是仅限于会一些简单的filter、map、collect等操作,但JAVA的Stream可以适用的场景与能力远不止这些。
那么问题来了:Stream相较于传统的foreach的方式处理,到底有啥优势?
这里我们可以先搁置这个问题,先整体全面的了解下Stream,然后再来讨论下这个问题。
笔者结合在团队中多年的代码检视遇到的情况,结合平时项目编码实践经验,对Stream的核心要点与易混淆用法、典型使用场景等进行了详细的梳理总结,希望可以帮助大家对Stream有个更全面的认知,也可以更加高效的应用到项目开发中去。
Stream初相识
概括讲,可以将Stream流操作分为3种类型:
创建Stream
Stream中间处理
终止Steam
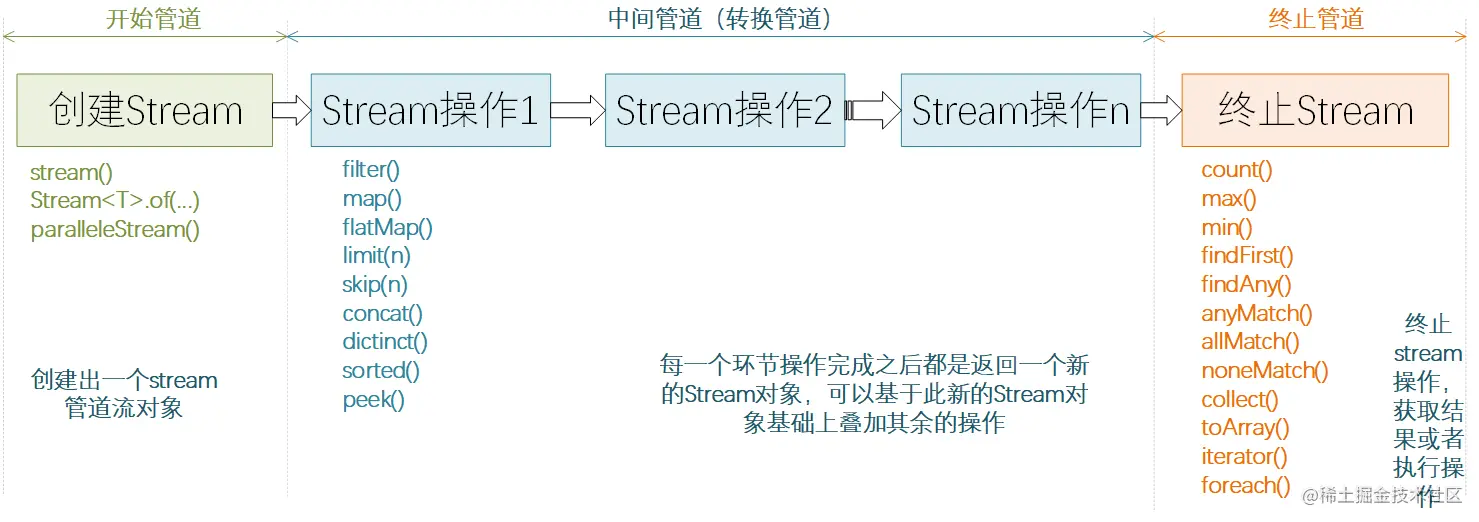
每个Stream管道操作类型都包含若干API方法,先列举下各个API方法的功能介绍。
开始管道
主要负责新建一个Stream流,或者基于现有的数组、List、Set、Map等集合类型对象创建出新的Stream流。
API | 功能说明 |
stream() | 创建出一个新的stream串行流对象 |
parallelStream() | 创建出一个可并行执行的stream流对象 |
Stream.of() | 通过给定的一系列元素创建一个新的Stream串行流对象 |
中间管道
负责对Stream进行处理操作,并返回一个新的Stream对象,中间管道操作可以进行叠加。
API | 功能说明 |
filter() | 按照条件过滤符合要求的元素, 返回新的stream流 |
map() | 将已有元素转换为另一个对象类型,一对一逻辑,返回新的stream流 |
flatMap() | 将已有元素转换为另一个对象类型,一对多逻辑,即原来一个元素对象可能会转换为1个或者多个新类型的元素,返回新的stream流 |
limit() | 仅保留集合前面指定个数的元素,返回新的stream流 |
skip() | 跳过集合前面指定个数的元素,返回新的stream流 |
concat() | 将两个流的数据合并起来为1个新的流,返回新的stream流 |
distinct() | 对Stream中所有元素进行去重,返回新的stream流 |
sorted() | 对stream中所有的元素按照指定规则进行排序,返回新的stream流 |
peek() | 对stream流中的每个元素进行逐个遍历处理,返回处理后的stream流 |
终止管道
顾名思义,通过终止管道操作之后,Stream流将会结束,最后可能会执行某些逻辑处理,或者是按照要求返回某些执行后的结果数据。
API | 功能说明 |
count() | 返回stream处理后最终的元素个数 |
max() | 返回stream处理后的元素最大值 |
min() | 返回stream处理后的元素最小值 |
findFirst() | 找到第一个符合条件的元素时则终止流处理 |
findAny() | 找到任何一个符合条件的元素时则退出流处理,这个对于串行流时与findFirst相同,对于并行流时比较高效,任何分片中找到都会终止后续计算逻辑 |
anyMatch() | 返回一个boolean值,类似于isContains(),用于判断是否有符合条件的元素 |
allMatch() | 返回一个boolean值,用于判断是否所有元素都符合条件 |
noneMatch() | 返回一个boolean值, 用于判断是否所有元素都不符合条件 |
collect() | 将流转换为指定的类型,通过Collectors进行指定 |
toArray() | 将流转换为数组 |
iterator() | 将流转换为Iterator对象 |
foreach() | 无返回值,对元素进行逐个遍历,然后执行给定的处理逻辑 |
Stream方法使用
map与flatMap
map与flatMap都是用于转换已有的元素为其它元素,区别点在于:
map 必须是一对一的,即每个元素都只能转换为1个新的元素
flatMap 可以是一对多的,即每个元素都可以转换为1个或者多个新的元素
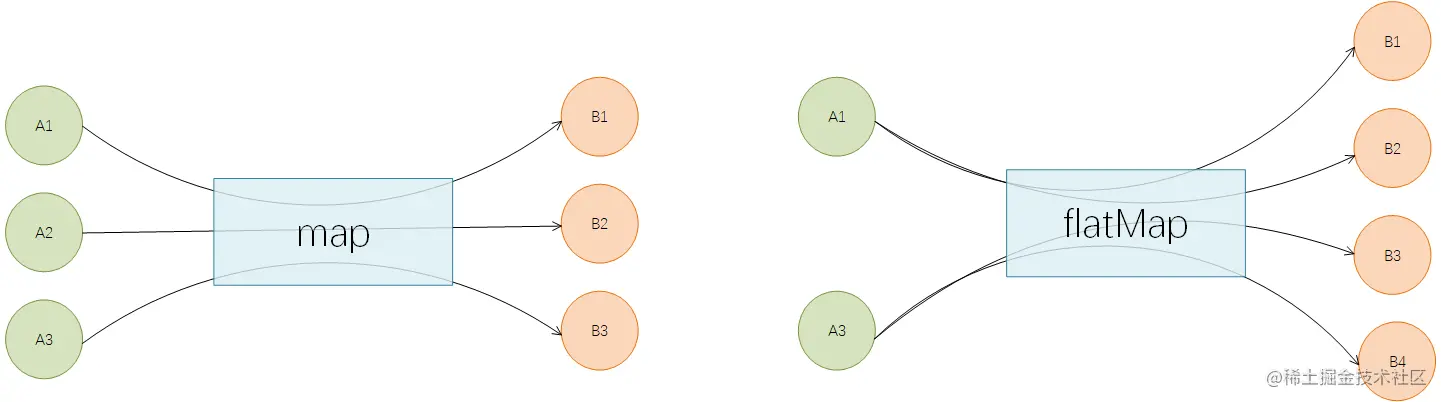
比如:有一个字符串ID列表,现在需要将其转为User对象列表。可以使用map来实现:
/*** 演示map的用途:一对一转换*/publicvoidstringToIntMap() {List<String> ids = Arrays.asList("205", "105", "308", "469", "627", "193", "111");// 使用流操作List<User> results = ids.stream().map(id -> {Useruser=newUser();user.setId(id);return user;}).collect(Collectors.toList());System.out.println(results);
}复制代码执行之后,会发现每一个元素都被转换为对应新的元素,但是前后总元素个数是一致的:
[User{id='205'}, User{id='105'},User{id='308'}, User{id='469'}, User{id='627'}, User{id='193'}, User{id='111'}]复制代码再比如:现有一个句子列表,需要将句子中每个单词都提取出来得到一个所有单词列表。这种情况用map就搞不定了,需要flatMap上场了:
publicvoidstringToIntFlatmap() {List<String> sentences = Arrays.asList("hello world","Jia Gou Wu Dao");// 使用流操作List<String> results = sentences.stream().flatMap(sentence -> Arrays.stream(sentence.split(" "))).collect(Collectors.toList());System.out.println(results);
}复制代码执行结果如下,可以看到结果列表中元素个数是比原始列表元素个数要多的:
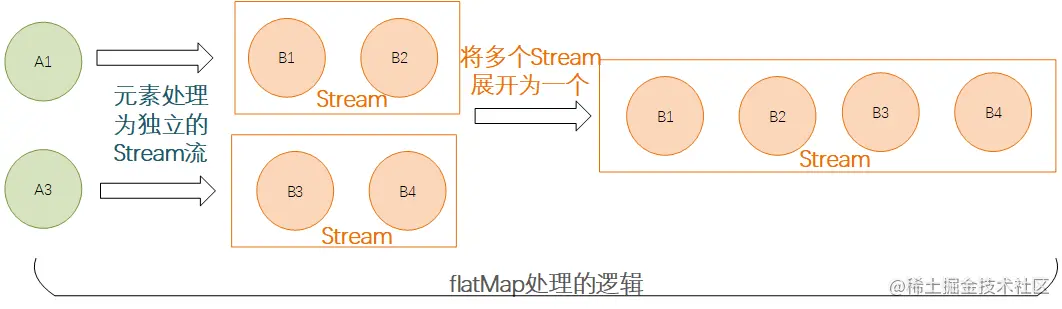
[hello, world, Jia, Gou, Wu, Dao]复制代码这里需要补充一句,flatMap操作的时候其实是先每个元素处理并返回一个新的Stream,然后将多个Stream展开合并为了一个完整的新的Stream,如下:
peek和foreach方法
peek和foreach,都可以用于对元素进行遍历然后逐个的进行处理。
但根据前面的介绍,peek属于中间方法,而foreach属于终止方法。这也就意味着peek只能作为管道中途的一个处理步骤,而没法直接执行得到结果,其后面必须还要有其它终止操作的时候才会被执行;而foreach作为无返回值的终止方法,则可以直接执行相关操作。
publicvoidtestPeekAndforeach() {List<String> sentences = Arrays.asList("hello world","Jia Gou Wu Dao");// 演示点1: 仅peek操作,最终不会执行System.out.println("----before peek----");sentences.stream().peek(sentence -> System.out.println(sentence));System.out.println("----after peek----");// 演示点2: 仅foreach操作,最终会执行System.out.println("----before foreach----");sentences.stream().forEach(sentence -> System.out.println(sentence));System.out.println("----after foreach----");// 演示点3: peek操作后面增加终止操作,peek会执行System.out.println("----before peek and count----");sentences.stream().peek(sentence -> System.out.println(sentence)).count();System.out.println("----after peek and count----");
}复制代码输出结果可以看出,peek独自调用时并没有被执行、但peek后面加上终止操作之后便可以被执行,而foreach可以直接被执行:
----before peek----
----after peek----
----before foreach----
hello world
Jia Gou Wu Dao
----after foreach----
----before peek and count----
hello world
Jia Gou Wu Dao
----after peek and count----复制代码filter、sorted、distinct、limit
这几个都是常用的Stream的中间操作方法,具体的方法的含义在上面的表格里面有说明。具体使用的时候,可以根据需要选择一个或者多个进行组合使用,或者同时使用多个相同方法的组合:
publicvoidtestGetTargetUsers() {List<String> ids = Arrays.asList("205","10","308","49","627","193","111", "193");// 使用流操作List<Dept> results = ids.stream().filter(s -> s.length() > 2).distinct().map(Integer::valueOf).sorted(Comparator.comparingInt(o -> o)).limit(3).map(id -> newDept(id)).collect(Collectors.toList());System.out.println(results);
}复制代码上面的代码片段的处理逻辑很清晰:
使用filter过滤掉不符合条件的数据
通过distinct对存量元素进行去重操作
通过map操作将字符串转成整数类型
借助sorted指定按照数字大小正序排列
使用limit截取排在前3位的元素
又一次使用map将id转为Dept对象类型
使用collect终止操作将最终处理后的数据收集到list中
输出结果:
[Dept{id=111}, Dept{id=193}, Dept{id=205}]复制代码简单结果终止方法
按照前面介绍的,终止方法里面像count、max、min、findAny、findFirst、anyMatch、allMatch、nonneMatch等方法,均属于这里说的简单结果终止方法。所谓简单,指的是其结果形式是数字、布尔值或者Optional对象值等。
publicvoidtestSimpleStopOptions() {List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193");// 统计stream操作后剩余的元素个数System.out.println(ids.stream().filter(s -> s.length() > 2).count());// 判断是否有元素值等于205System.out.println(ids.stream().filter(s -> s.length() > 2).anyMatch("205"::equals));// findFirst操作ids.stream().filter(s -> s.length() > 2).findFirst().ifPresent(s -> System.out.println("findFirst:" + s));
}复制代码执行后结果为:
6truefindFirst:205复制代码避坑提醒
这里需要补充提醒下,一旦一个Stream被执行了终止操作之后,后续便不可以再读这个流执行其他的操作了,否则会报错,看下面示例:
publicvoidtestHandleStreamAfterClosed() {List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193");Stream<String> stream = ids.stream().filter(s -> s.length() > 2);// 统计stream操作后剩余的元素个数System.out.println(stream.count());System.out.println("-----下面会报错-----");// 判断是否有元素值等于205try {System.out.println(stream.anyMatch("205"::equals));} catch (Exception e) {e.printStackTrace();}System.out.println("-----上面会报错-----");
}复制代码执行的时候,结果如下:
6
-----下面会报错-----
java.lang.IllegalStateException: stream has already been operated upon or closedat java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)at java.util.stream.ReferencePipeline.anyMatch(ReferencePipeline.java:449)at com.veezean.skills.stream.StreamService.testHandleStreamAfterClosed(StreamService.java:153)at com.veezean.skills.stream.StreamService.main(StreamService.java:176)
-----上面会报错-----复制代码因为stream已经被执行count()终止方法了,所以对stream再执行anyMatch方法的时候,就会报错stream has already been operated upon or closed,这一点在使用的时候需要特别注意。
结果收集终止方法
因为Stream主要用于对集合数据的处理场景,所以除了上面几种获取简单结果的终止方法之外,更多的场景是获取一个集合类的结果对象,比如List、Set或者HashMap等。
这里就需要collect方法出场了,它可以支持生成如下类型的结果数据:
一个集合类,比如List、Set或者HashMap等
StringBuilder对象,支持将多个字符串进行拼接处理并输出拼接后结果
一个可以记录个数或者计算总和的对象(数据批量运算统计)
生成集合
应该算是collect最常被使用到的一个场景了:
publicvoidtestCollectStopOptions() {List<Dept> ids = Arrays.asList(newDept(17), newDept(22), newDept(23));// collect成listList<Dept> collectList = ids.stream().filter(dept -> dept.getId() > 20).collect(Collectors.toList());System.out.println("collectList:" + collectList);// collect成SetSet<Dept> collectSet = ids.stream().filter(dept -> dept.getId() > 20).collect(Collectors.toSet());System.out.println("collectSet:" + collectSet);// collect成HashMap,key为id,value为Dept对象Map<Integer, Dept> collectMap = ids.stream().filter(dept -> dept.getId() > 20).collect(Collectors.toMap(Dept::getId, dept -> dept));System.out.println("collectMap:" + collectMap);
}复制代码结果如下:
collectList:[Dept{id=22}, Dept{id=23}]
collectSet:[Dept{id=23}, Dept{id=22}]
collectMap:{22=Dept{id=22}, 23=Dept{id=23}}复制代码生成拼接字符串
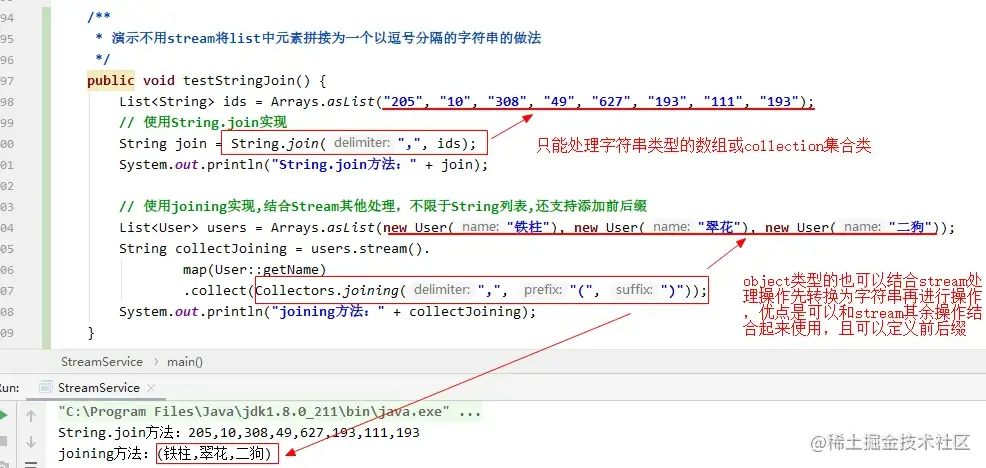
将一个List或者数组中的值拼接到一个字符串里并以逗号分隔开,这个场景相信大家都不陌生吧?
如果通过for循环和StringBuilder去循环拼接,还得考虑下最后一个逗号如何处理的问题,很繁琐:
publicvoidtestForJoinStrings() {List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193");StringBuilderbuilder=newStringBuilder();for (String id : ids) {builder.append(id).append(',');}// 去掉末尾多拼接的逗号builder.deleteCharAt(builder.length() - 1);System.out.println("拼接后:" + builder.toString());
}复制代码但是现在有了Stream,使用collect可以轻而易举的实现:
publicvoidtestCollectJoinStrings() {List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193");StringjoinResult= ids.stream().collect(Collectors.joining(","));System.out.println("拼接后:" + joinResult);
}复制代码两种方式都可以得到完全相同的结果,但Stream的方式更优雅:
拼接后:205,10,308,49,627,193,111,193复制代码📢 敲黑板:
关于这里的说明,评论区中很多的小伙伴提出过疑问,就是这个场景其实使用 String.join() 就可以搞定了,并不需要上面使用 stream 的方式去实现。这里要声明下,Stream的魅力之处就在于其可以结合到其它的业务逻辑中进行处理,让代码逻辑更加的自然、一气呵成。如果纯粹是个String字符串拼接的诉求,确实没有必要使用Stream来实现,毕竟杀鸡焉用牛刀嘛~ 但是可以看看下面给出的这个示例,便可以感受出使用Stream进行字符串拼接的真正魅力所在。
数据批量数学运算
还有一种场景,实际使用的时候可能会比较少,就是使用collect生成数字数据的总和信息,也可以了解下实现方式:
publicvoidtestNumberCalculate() {List<Integer> ids = Arrays.asList(10, 20, 30, 40, 50);// 计算平均值Doubleaverage= ids.stream().collect(Collectors.averagingInt(value -> value));System.out.println("平均值:" + average);// 数据统计信息IntSummaryStatisticssummary= ids.stream().collect(Collectors.summarizingInt(value -> value));System.out.println("数据统计信息: " + summary);
}复制代码上面的例子中,使用collect方法来对list中元素值进行数学运算,结果如下:
平均值:30.0
总和: IntSummaryStatistics{count=5, sum=150, min=10, average=30.000000, max=50}复制代码并行Stream
机制说明
使用并行流,可以有效利用计算机的多CPU硬件,提升逻辑的执行速度。并行流通过将一整个stream划分为多个片段,然后对各个分片流并行执行处理逻辑,最后将各个分片流的执行结果汇总为一个整体流。
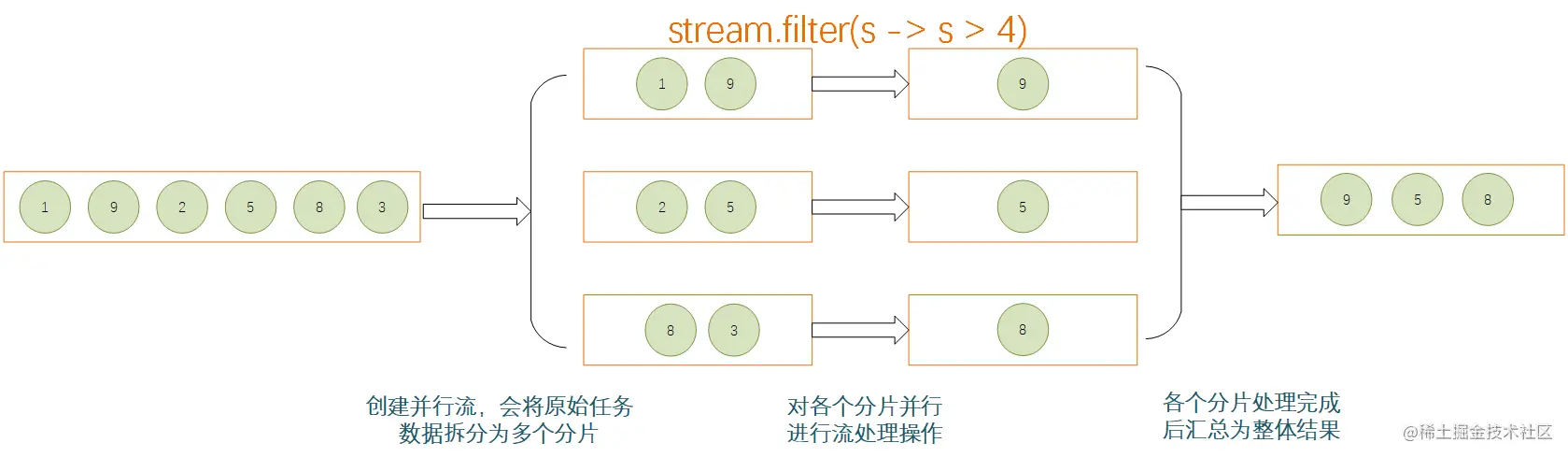
约束与限制
并行流类似于多线程在并行处理,所以与多线程场景相关的一些问题同样会存在,比如死锁等问题,所以在并行流终止执行的函数逻辑,必须要保证线程安全。
回答最初的问题
到这里,关于JAVA Stream的相关概念与用法介绍,基本就讲完了。我们再把焦点切回本文刚开始时提及的一个问题:
Stream相较于传统的foreach的方式处理stream,到底有啥优势?
根据前面的介绍,我们应该可以得出如下几点答案:
代码更简洁、偏声明式的编码风格,更容易体现出代码的逻辑意图
逻辑间解耦,一个stream中间处理逻辑,无需关注上游与下游的内容,只需要按约定实现自身逻辑即可
并行流场景效率会比迭代器逐个循环更高
函数式接口,延迟执行的特性,中间管道操作不管有多少步骤都不会立即执行,只有遇到终止操作的时候才会开始执行,可以避免一些中间不必要的操作消耗
当然了,Stream也不全是优点,在有些方面也有其弊端:
代码调测debug不便
程序员从历史写法切换到Stream时,需要一定的适应时间
相关文章:
Java中循环使用Stream应用场景
在JAVA中,涉及到对数组、Collection等集合类中的元素进行操作的时候,通常会通过循环的方式进行逐个处理,或者使用Stream的方式进行处理。例如,现在有这么一个需求:从给定句子中返回单词长度大于5的单词列表,…...
中国蚁剑AntSword实战
中国蚁剑AntSword实战1.基本使用方法2.绕过安全狗连接3.请求包修改UA特征伪造RSA流量加密4.插件使用1.基本使用方法 打开蚂蚁宝剑,右键添加数据: 输入已经上传马的路径和连接密码: 测试连接,连接成功! GetShell了&…...

C++ 直接初始化和拷贝初始化
首先我们介绍直接初始化:编译器使用普通的函数匹配来选择与我们提供的参数最匹配的构造函数。文字描述可能会让你们云里雾里,那我们直接看代码: //先设计这样的一个类 class A{ public:A(){ cout << "A()" << endl; }A…...
数据迁移工具
1.Kettle Kettle是一款国外开源的ETL工具,纯Java编写,绿色无需安装,数据抽取高效稳定 (数据迁移工具)。 Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。 Kettle 中文名称叫水壶,该项目的主程序…...
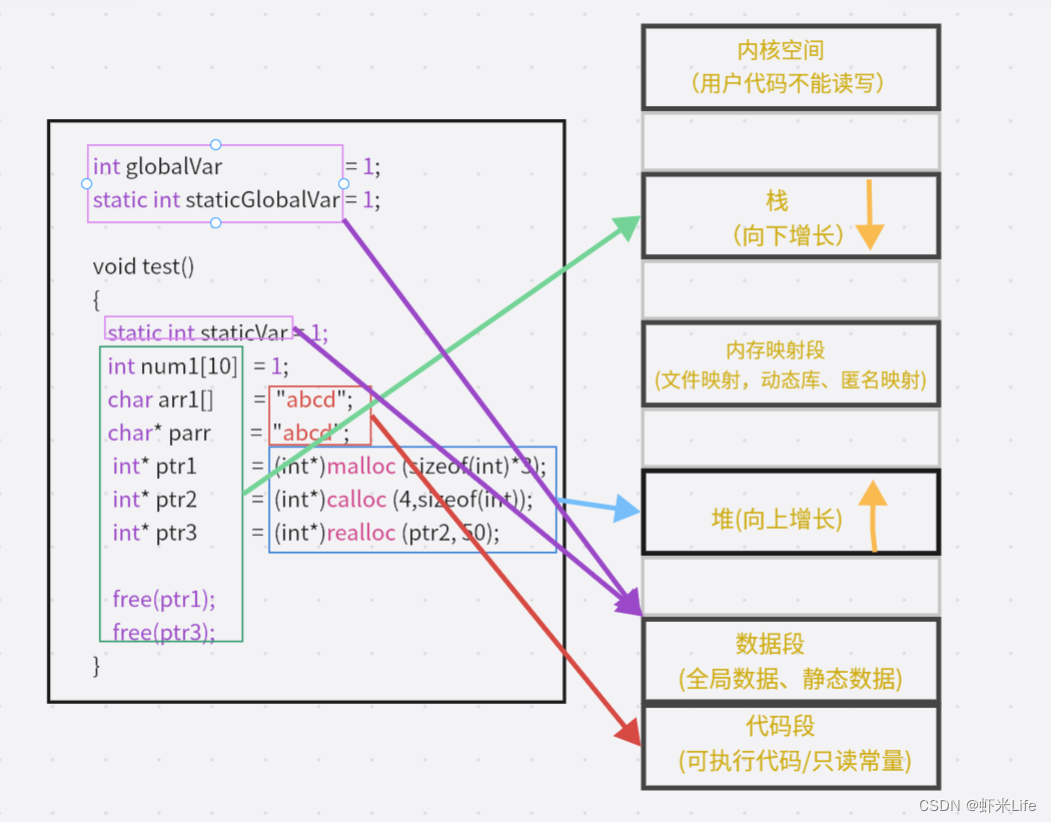
【C/C++】程序的内存开辟
在C/C语言中,不同的类型开辟的空间区域都是不一样的. 这节我们就简单了解下开辟不同的类型内存所存放的区域在哪里. 文章目录栈区(stack)堆区(heap)数据段(静态区)常量存储区内存开辟布局图栈区…...
全网最完整,接口测试总结彻底打通接口自动化大门,看这篇就够了......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 所谓接口࿰…...
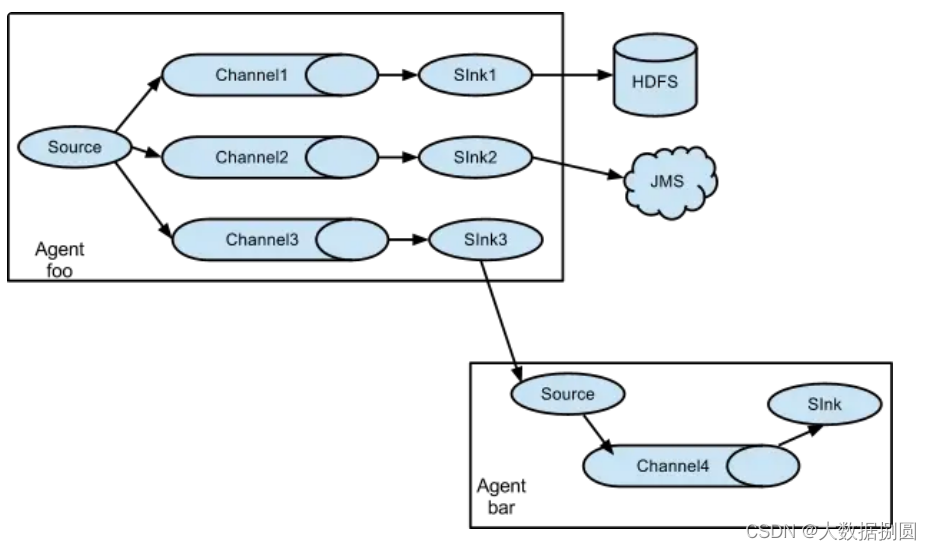
28-flume和kafka为什么要结合使用
一:flume和kafka为什么要结合使用 首先:Flume 和 Kafka 都是用于处理大量数据的工具,但它们的设计目的不同。Flume 是一个可靠地收集、聚合和移动大量日志和事件数据的工具,而Kafka则是一个高吞吐量的分布式消息队列,…...

STM32外设-定时器详解
0. 概述 本文针对STM32F1系列,主要讲解了其中的8个定时器的原理和功能 1. 定时器分类 STM32F1 系列中,除了互联型的产品,共有 8 个定时器,分为基本定时器,通用定时器和高级定时器基本定时器 TIM6 和 TIM7 是一个 16 位…...
史上最详细的改良顺序表讲解,看完不会你打我
目录 0.什么是顺序表 1.顺序表里结构体的定义 2.顺序表的初始化 3.顺序表的输入 4.增加顺序表的长度 5.1顺序表的元素查找(按位查找) 5.2顺序表的元素查找(按值查找)在顺序表进行按值查找,大概只能通过遍历的方…...

【Unity入门】资源包导入和导出
【Unity入门】资源包导入和导出 大家好,我是Lampard~~ 欢迎来到Unity入门系列博客,所学知识来自B站阿发老师~感谢 (1)资源目录 Unity的资源(模型,场景,脚本)等都保存在Assert目录下&…...
python条件语句与循环语句
目录 一、条件语句 1.1if 二、循环语句 2.1while 2.2for循环 2.3break和continue 三、test和总结 一、条件语句 1.1if Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。 Python程序语言指定: 任…...

【leetcode】链表(2)
目录 1. 环形链表 解题思路 2. 环形链表 II 解题思路 3. 删除排序链表中的重复元素 解题思路 4. 删除排序链表中的重复元素 II 解题思路 5. 移除链表元素 解题思路 6. 链表的中间结点 解题思路 1. 环形链表 OJ:环形链表 给你一个链表的头节点 head &am…...
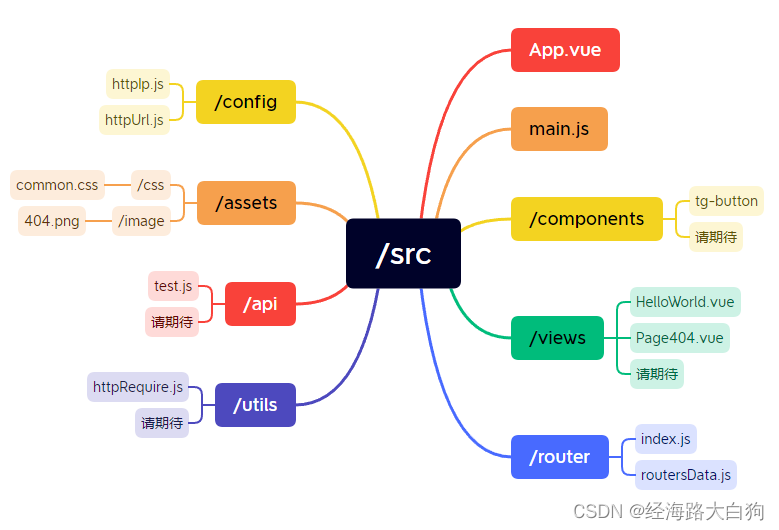
使用Vue+vue-router+路由守卫实现路由鉴权功能实战
目录 一、本节介绍和上节回顾 1. 上节介绍 2. Vue SpringBoot前后端分离项目实战的目录 3. 本小节介绍 二、Vue-router改造以及路由鉴权 1. 路由数据的拆分 2. 路由守卫 三、404错误页的实现 1. 创建全局css样式 2. 全局样式引入 3. 404页面的开发 4. el-button的…...
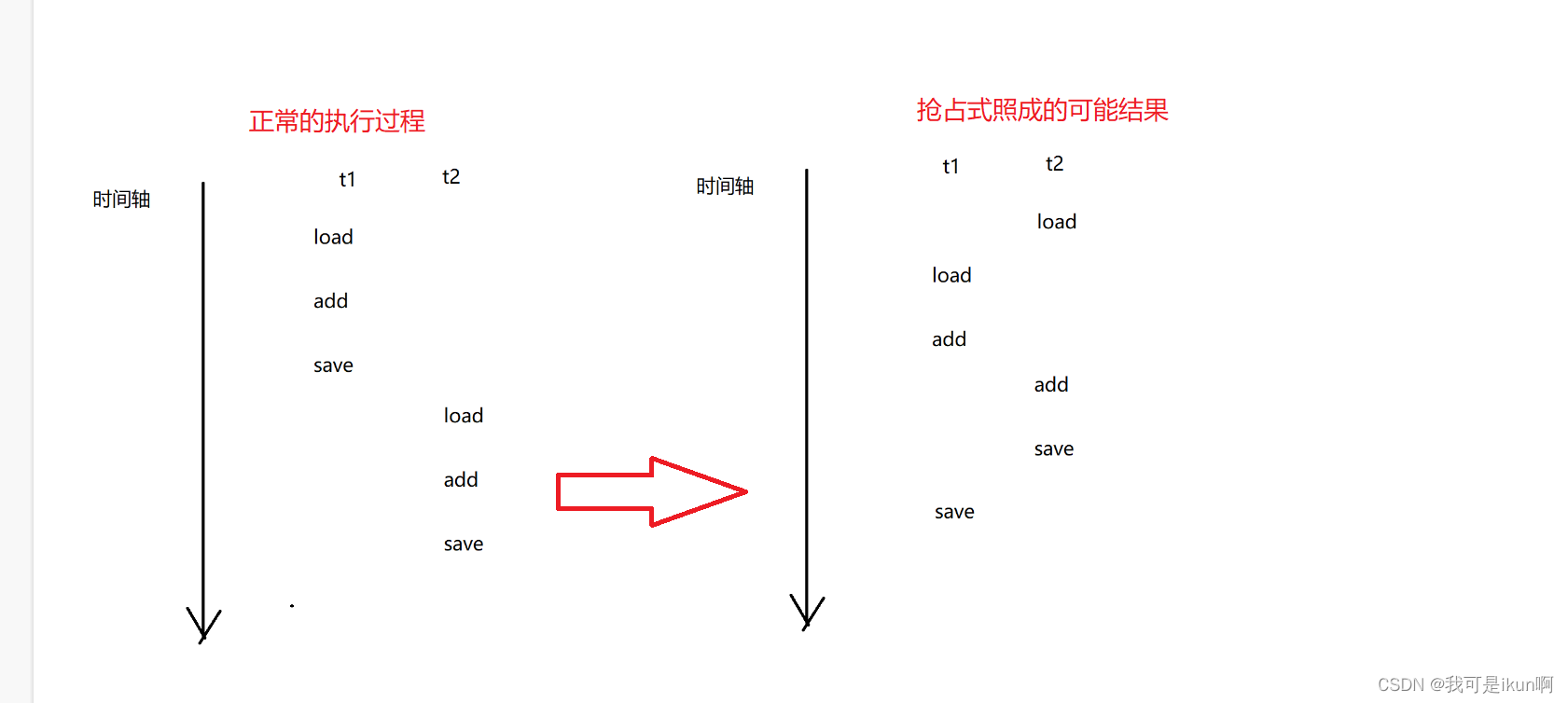
多线程(三):Thread 类的基本属性
上一个篇章浅浅了解了一下 线程的概念,进程与线程的区别,如何实现多线程编程。 而且上一章提到一个重要的面试点: start 方法和 run 方法的区别。 start 方法是从系统那里创建一个新的线程,这个线程会自动调用内部的run 方法&…...
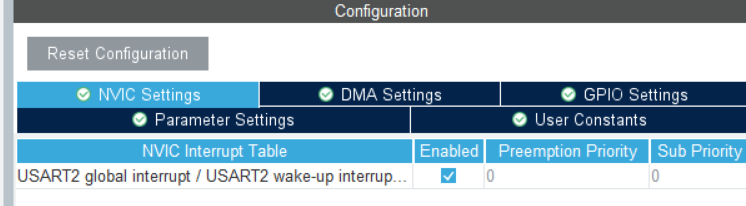
蓝桥杯嵌入式第六课--串口收发
前言串口作为一个考试中考察频率较高的考点,其套路比较固定,因此值得我们仔细把握。本节课主要着眼于快速配置实现 串口收发与串口的中断。CubeMX配置选择串口2配置异步收发模式基本参数设置(波特率、校验位等等)开启串口收发中断…...
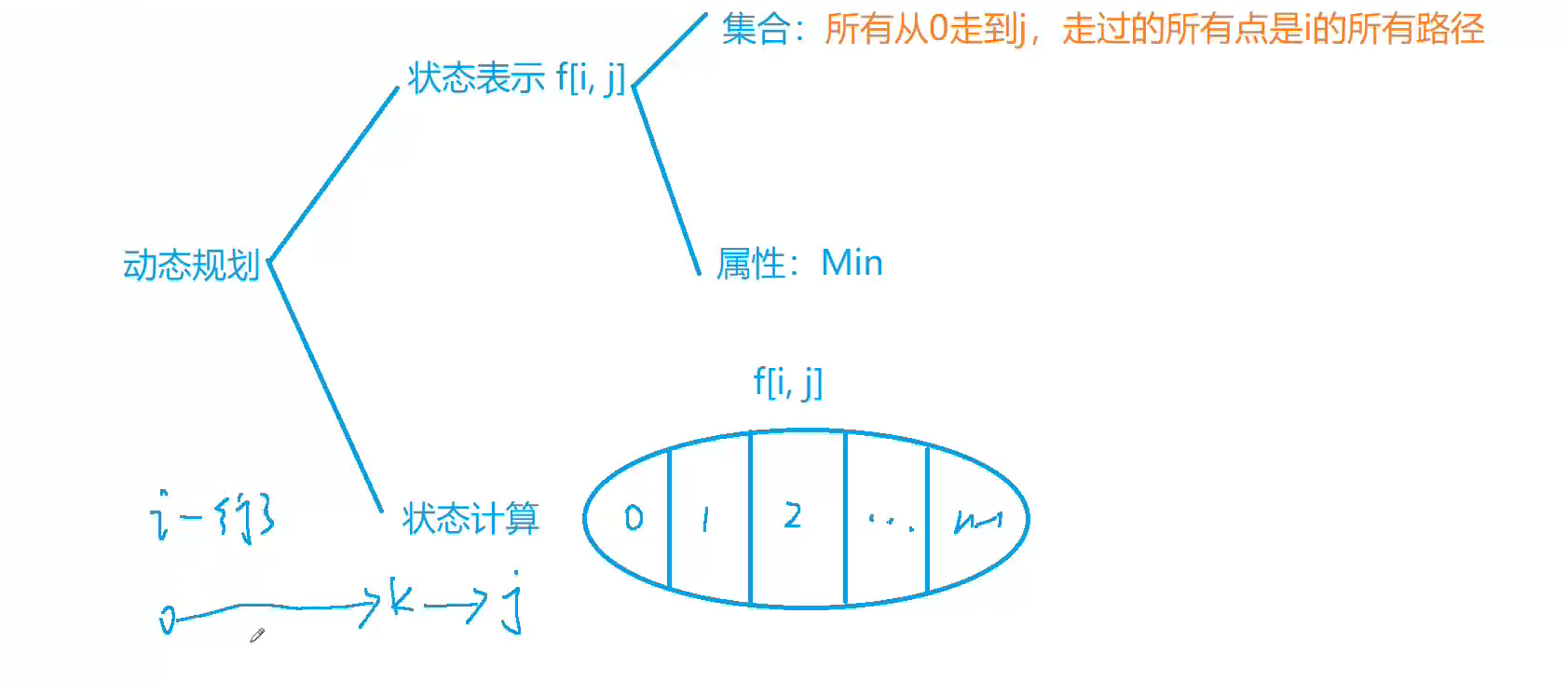
蓝桥杯冲刺 - Lastweek - 你离省一仅剩一步之遥!!!(掌握【DP】冲刺国赛)
文章目录💬前言🎯week3🌲day10-1背包完全背包多重背包多重背包 II分组背包🌲day2数字三角形 - 线性DP1015. 摘花生 - 数字三角形🌲day3最长上升子序列 - 线性DP1017. 怪盗基德的滑翔翼 - LIS1014.登山 - LIS最长公共子…...

C++ map与set的学习
1. 关联式容器在初阶阶段,我们已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。关联式容器也…...
【C语言初阶】函数
文章目录💐专栏导读💐文章导读🌷函数是什么?🌷函数的分类🌺库函数🌺自定义函数🌷函数的参数🌷函数的调用🌷函数的嵌套调用和链式访问🌺嵌套调用&a…...
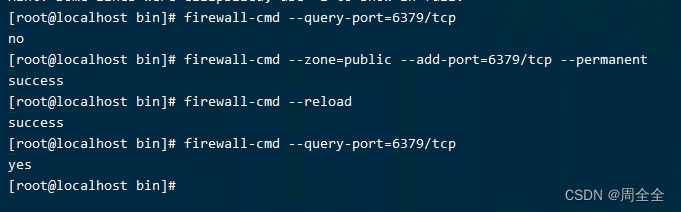
CentOS 7安装redis6.2.6(包括服务开机自启和开放端口)
CentOS 7安装redis6.2.61. 官网下载redis文件2. 校验安装依赖2.1 安装系统默认版本gcc2.2 升级gcc版本3. 解压编译安装4. 修改配置redis.conf4.2 设置密码4.3 绑定ip(可选)5. 启动redis服务并测试5.2 测试安装是否成功5.3 redis开机自启配置6.开放防火墙…...

基于注解的自动装配~
Autowired:实现自动装配功能的注解 Autowired注解能够标识的位置: 标识在成员变量上,此时不需要设置成员变量的set方法标识在成员变量对应的set方法上标识在为当前成员变量赋值的有参构造上使用注解进行自动装配,只要在其成员变量…...

国产车规芯片崛起,如何用东软睿驰NeuSAR或经纬恒润方案快速适配?
国产车规芯片与AUTOSAR方案融合实战:从芯驰MCU到NeuSAR/经纬恒润的适配指南 当一颗国产车规级MCU遇上自主AUTOSAR基础软件,这场"中国芯"与"中国魂"的相遇,正在重构汽车电子开发的成本结构与技术生态。去年某新能源车企的…...
步骤)
【文档编辑】打印小册子(一张A4纸4页内容)步骤
效果如下,使用“A4纸”打印变成“每一页是A5大小的翻页小册子”1、打开word格式说明书,另存为pdf格式(如果文件是pdf格式忽略步骤1) 2、用wps打开pdf文件 3、打印→打印方式:小册子→小册子子集:仅正面→装…...

毕业论文难写?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

5分钟上手:用VMagicMirror打造你的虚拟形象分身
5分钟上手:用VMagicMirror打造你的虚拟形象分身 【免费下载链接】VMagicMirror VRM Software for Windows to move avatar with minimal devices. 项目地址: https://gitcode.com/gh_mirrors/vm/VMagicMirror VMagicMirror是一款专为Windows设计的开源虚拟角…...

华为认证“以学代考”续证政策——伙伴篇
华为认证面向伙伴正式推出“以学代考”续证机制,支持华为中国区政企伙伴通过在线学习和在线考试后,即可获取续认证。当前,“以学代考”产品已上架伙伴TF基金产品兑换清单,伙伴可通过TF基金兑换相应课程,完成续认证。完…...

TikTokDownload:5分钟搞定抖音去水印批量下载终极方案
TikTokDownload:5分钟搞定抖音去水印批量下载终极方案 【免费下载链接】TikTokDownload 抖音去水印批量下载用户主页作品、喜欢、收藏、图文、音频 项目地址: https://gitcode.com/gh_mirrors/ti/TikTokDownload 想要轻松保存抖音上的精彩内容却苦于官方水印…...

Sunshine游戏串流服务器架构深度解析:5个高级性能调优技巧与源码设计实战
Sunshine游戏串流服务器架构深度解析:5个高级性能调优技巧与源码设计实战 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine作为一款开源的自托管游戏串流服务器…...

Navicat Mac终极重置指南:3种简单方法快速恢复试用期
Navicat Mac终极重置指南:3种简单方法快速恢复试用期 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 你是否正在使…...

PPTist免费在线演示文稿制作完全指南:从零到专业演示的终极教程
PPTist免费在线演示文稿制作完全指南:从零到专业演示的终极教程 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, al…...

零基础,能转行做网络安全架构师吗?一份写给“跨界者”的理性指南
零基础,能转行做网络安全架构师吗?一份写给“跨界者”的理性指南 拆解真实岗位需求,规划可达成的12个月学习路径 “我30岁了,学编程转行网络安全还来得及吗?”“非科班出身,能成为网络安全架构师吗&#…...