【Python时序预测系列】高创新模型:基于xlstm模型实现单变量时间序列预测(案例+源码)
这是我的第351篇原创文章。
一、引言
LSTM在1990年代被提出,用以解决循环神经网络(RNN)的梯度消失问题。LSTM在多种领域取得了成功,但随着Transformer技术的出现,其地位受到了挑战。如果将LSTM扩展到数十亿参数,并利用现代大型语言模型(LLM)的技术,同时克服LSTM的已知限制,我们能在语言建模上走多远?
论文介绍了两种新的LSTM变体:sLSTM(具有标量记忆和更新)和mLSTM(具有矩阵记忆和协方差更新规则),并将它们集成到残差块中,形成xLSTM架构。
sLSTM:引入了指数门控和新的存储混合技术,允许LSTM修订其存储决策。
mLSTM:将LSTM的记忆单元从标量扩展到矩阵,提高了存储容量,并引入了协方差更新规则,使得mLSTM可以完全并行化。
xLSTM架构:通过将sLSTM和mLSTM集成到残差块中,构建了xLSTM架构。
二、实现过程
2.1 加载数据
data = pd.read_csv('data.csv', usecols=[1], engine='python')
dataset = data.values.astype('float32')2.2 归一化处理
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)2.3 划分数据集
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]trainX, trainY = create_dataset(train, seq_len)
testX, testY = create_dataset(test, seq_len)# Create data loaders
train_dataset = TensorDataset(trainX, trainY)
test_dataset = TensorDataset(testX, testY)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)2.4 构建模型
models = {"xLSTM": xLSTM(input_size, head_size, num_heads, batch_first=True, layers='msm'),"LSTM": nn.LSTM(input_size, head_size, batch_first=True, proj_size=input_size),"sLSTM": sLSTM(input_size, head_size, num_heads, batch_first=True),"mLSTM": mLSTM(input_size, head_size, num_heads, batch_first=True)
}2.5 训练模型
定义训练函数:
def train_model(model, model_name, epochs=20, learning_rate=0.01):criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)train_losses = []for epoch in tqdm(range(epochs), desc=f'Training {model_name}'):model.train()epoch_loss = 0for i, (inputs, targets) in enumerate(train_loader):optimizer.zero_grad()outputs, _ = model(inputs)outputs = outputs[:, -1, :]loss = criterion(outputs, targets)loss.backward()optimizer.step()epoch_loss += loss.item()train_losses.append(epoch_loss / len(train_loader))plt.plot(train_losses, label=model_name)plt.title(f'Training Loss for {model_name}')plt.xlabel('Epochs')plt.ylabel('MSE Loss')plt.legend()plt.show()return model, train_losses开始训练:
trained_models = {}
all_train_losses = {}
for model_name, model in models.items():trained_models[model_name], all_train_losses[model_name] = train_model(model, model_name)绘制所有模型的损失函数曲线:
plt.figure()
for model_name, train_losses in all_train_losses.items():plt.plot(train_losses, label=model_name)# Plot all model losses compared
plt.title('Training Losses for all Models')
plt.xlabel('Epochs')
plt.ylabel('MSE Loss')
plt.legend()
plt.show()
2.6 预测评估
预测:
def evaluate_model(model, data_loader):model.eval()predictions = []with torch.no_grad():for inputs, _ in data_loader:outputs, _ = model(inputs)predictions.extend(outputs[:, -1, :].numpy())return predictionstest_predictions = {}
for model_name, model in trained_models.items():test_predictions[model_name] = evaluate_model(model, test_loader)预测结果可视化:
# Plot predictions for each model
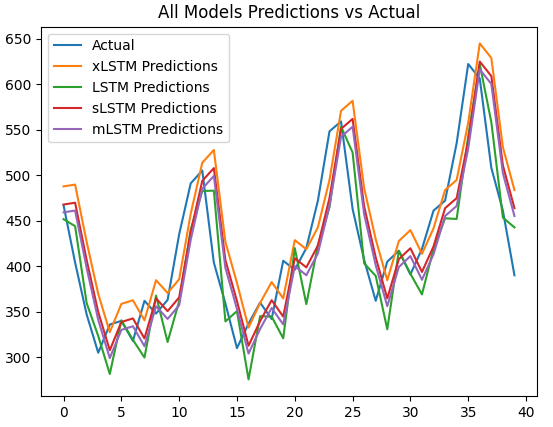
for model_name, preds in test_predictions.items():# Inverse transform the predictions and actual valuespreds = scaler.inverse_transform(np.array(preds).reshape(-1, 1))actual = scaler.inverse_transform(testY.numpy().reshape(-1, 1))plt.figure()plt.plot(actual, label='Actual')plt.plot(preds, label=model_name + ' Predictions')plt.title(f'{model_name} Predictions vs Actual')plt.legend()plt.show()# Plot all model predictions compared
plt.figure()
plt.plot(actual, label='Actual')
for model_name, preds in test_predictions.items():# Inverse transform the predictionspreds = scaler.inverse_transform(np.array(preds).reshape(-1, 1))plt.plot(preds, label=model_name + ' Predictions')plt.title('All Models Predictions vs Actual')
plt.legend()
plt.show()结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
相关文章:
【Python时序预测系列】高创新模型:基于xlstm模型实现单变量时间序列预测(案例+源码)
这是我的第351篇原创文章。 一、引言 LSTM在1990年代被提出,用以解决循环神经网络(RNN)的梯度消失问题。LSTM在多种领域取得了成功,但随着Transformer技术的出现,其地位受到了挑战。如果将LSTM扩展到数十亿参数&#…...

Ubuntu 22.04 系统中 ROS2安装
Ubuntu 22.04 系统中 ROS2安装 ROS2安装 # 多窗口终端工具 sudo apt update sudo apt install tilix打开软件,点击右上角图标进入设置 -> General -> size120, columns:48Command -> 勾选第一个 Run command as login shellColor -> Theme Color 选择…...

Vue内置指令v-once、v-memo和v-pre提升性能?
前言 Vue的内置指令估计大家都用过不少,例如v-for、v-if之类的就是最常用的内置指令,但今天给大家介绍几个平时用的比较少的内置指令。毕竟这几个Vue内置指令可用可不用,不用的时候系统正常跑,但在对的地方用了却能提升系统性能&…...

OpenHarmony轻松玩转GIF数据渲染
OpenAtom OpenHarmony(以下简称“OpenHarmony”)提供了Image组件支持GIF动图的播放,但是缺乏扩展能力,不支持播放控制等。今天介绍一款三方库——ohos-gif-drawable三方组件,带大家一起玩转GIF的数据渲染,搞…...

torch.clip函数介绍
PyTorch 中,torch.clip函数用于对张量中的元素进行裁剪,将其值限制在指定的范围内。 一、函数语法及参数解释 torch.clip(input, min=None, max=None, out=None) input:输入张量,即要进行裁剪的张量。min(可选):裁剪的下限。如果未指定,则不进行下限裁剪。max(可选)…...

西北工业大学oj题-兔子生崽
题目描述: 兔子生崽问题。假设一对小兔的成熟期是一个月,即一个月可长成成兔,每对成兔每个月可以生一对小兔,一对新生的小兔从第二个月起就开始生兔子,试问从一对兔子开始繁殖,一年以后可有多少对兔子&…...

【Go语言成长之路】 模糊测试
文章目录 模糊测试一、前提二、创建项目三、添加待测试代码四、添加单元测试五、添加模糊测试 模糊测试 本教程介绍了 Go 中模糊测试的基础知识。通过模糊测试,随机数据会针对您的测试运行,以尝试找到漏洞或导致崩溃的输入。可以通过模糊测试发现的漏…...

异或运算的高级应用和Briankernighan算法
本篇文章主要回顾一下计算机的位运算,处理一些位运算的巧妙操作。 特别提醒:实现位运算要注意溢出和符号扩展等问题。 先看一个好玩的问题: $Problem1 $ 黑白球概率问题 袋子里一共a个白球,b个黑球,每次从袋子里拿…...

音视频入门基础:WAV专题(9)——FFmpeg源码中计算WAV音频文件每个packet的duration和duration_time的实现
一、引言 从文章《音视频入门基础:WAV专题(6)——通过FFprobe显示WAV音频文件每个数据包的信息》中我们可以知道,通过FFprobe命令可以显示WAV音频文件每个packet(也称为数据包或多媒体包)的信息࿰…...

AI写的论文查重率高吗?分享6款实测AI论文生成免费网站
在当今学术研究和论文写作领域,AI技术的迅猛发展为研究人员提供了极大的便利。特别是AI论文自动生成助手,它们不仅能够提高写作效率,还能帮助生成高质量的论文内容。以下是六款经过实测且免费的AI论文生成网站推荐: 一、千笔-AIP…...
【专题】2024年8月中国企业跨境、出海、国际化、全球化行业报告汇总PDF合集分享(附原数据表)
原文链接: https://tecdat.cn/?p37584 在全球化浪潮汹涌澎湃的当下,中国企业积极探索海外市场,开启了出海跨境的新征程。本报告合集旨在全面梳理出海跨境全球化行业的发展态势,涵盖多个领域的深度洞察。 从游戏、快消品、医疗器…...

[算法]单调栈解法
目录 739. 每日温度 - 力扣(LeetCode) 42. 接雨水 - 力扣(LeetCode) 84. 柱状图中最大的矩形 - 力扣(LeetCode) 739. 每日温度 - 力扣(LeetCode) 解法: 通常是一维数…...

构建数据安全防线:MySQL数据备份策略的文档化实践
在数据驱动的商业环境中,数据备份策略是确保数据安全和业务连续性的关键。MySQL,作为广泛使用的数据库管理系统,其数据备份策略的文档化对于规范备份流程、提高恢复效率和满足合规要求至关重要。本文将深入探讨如何在MySQL中实现数据备份的策…...

4. GIS前端工程师岗位职责、技术要求和常见面试题
本系列文章目录: 1. GIS开发工程师岗位职责、技术要求和常见面试题 2. GIS数据工程师岗位职责、技术要求和常见面试题 3. GIS后端工程师岗位职责、技术要求和常见面试题 4. GIS前端工程师岗位职责、技术要求和常见面试题 5. GIS工程师岗位职责、技术要求和常见面试…...

软件测试-Selenium+python自动化测试
目录 会用到谷歌浏览器Chrome测试,需要下载一个Chromedriver(Chrome for Testing availability)对应自己的浏览器版本号选择。 一、元素定位 对html网页中的元素进行定位,同时进行部分操作。 1.1一个简单的模板 from selenium import webdriver from selenium.webdrive…...

SpringBoot与Minio的极速之旅:解锁文件切片上传新境界
目录 一、前言 二、对象存储(Object Storage)介绍 (1)对象存储的特点 (2)Minio 与对象存储 (3)对象存储其他存储方式的区别 (4)对象存储的应用场景 三、…...

Java 7.3 - 分布式 id
分布式 ID 介绍 什么是 ID? ID 就是 数据的唯一标识。 什么是分布式 ID? 分布式 ID 是 分布式系统中的 ID,它不存在于现实生活,只存在于分布式系统中。 分库分表: 一个项目,在上线初期使用的是单机 My…...

144. 腾讯云Redis数据库
文章目录 一、Redis 的主要功能特性二、Redis 的典型应用场景三、Redis 的演进过程四、Redis 的架构设计五、Redis 的数据类型及操作命令六、腾讯云数据库 Redis七、总结 Redis 是一种由 C 语言开发的 NoSQL 数据库,以其高性能的键值对存储和多种应用场景而闻名。本…...

基于单片机的自动浇花控制写设计任务书
一、内容要求: 任务 随着社会的进步,人们的生活质量越来越高。在家里养养盆花可以陶冶情操,丰富生活。同时盆花可以通过光合作用吸收二氧化碳,净化室内空气,在有花木的地方空气中阴离子聚集较多,所以空气…...

从零到精通:用C++ STL string优化代码
目录 1:为什么要学习string类 2:标准库中的string类 2.1:string类(了解) 2.2:总结 3:string类的常用接口 3.1:string类对象的常见构造 3.1.1:代码1 3.1.2:代码2 3.2:string类对象的遍历操作 3.2.1:代码1(begin end) 3.2.2:代码2(rbegin rend) 3.3:string类对象的…...

Qt桌面应用开发:构建跨平台MogFace-large模型测试工具
Qt桌面应用开发:构建跨平台MogFace-large模型测试工具 最近在做人脸检测相关的项目,经常需要在不同环境下测试MogFace-large模型的效果。每次都要写脚本、调参数、看结果,过程挺繁琐的。我就想,能不能做个简单好用的桌面工具&…...

从视频流量到搜索权重:一份素材如何驱动多平台内容复用
在2025年之前,许多SaaS团队将内容策略的重心放在视频平台。YouTube教程、TikTok快速演示、LinkedIn行业洞察——这些内容确实带来了可观的观看量和互动。但到了2026年,一个越来越明显的问题浮现出来:视频流量虽然即时,却像流水一样…...

ComfyUI BrushNet终极指南:如何快速实现高质量AI图像修复与扩展
ComfyUI BrushNet终极指南:如何快速实现高质量AI图像修复与扩展 【免费下载链接】ComfyUI-BrushNet ComfyUI BrushNet nodes 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-BrushNet ComfyUI BrushNet 是一款革命性的AI图像修复和扩展插件࿰…...

做自媒体一年,我靠这3个方法解决了“选题荒”
刚开始做自媒体的时候,我最怕的不是写稿,而是“今天写什么”。每天早上打开文档,脑子里一片空白。上周写了什么?前天写了什么?今天该写什么?完全没方向。有时候坐一个小时,标题都没憋出来。后来…...

Qwen3-ASR-0.6B在会议记录场景落地:本地化语音转写提升企业数据安全合规性
Qwen3-ASR-0.6B在会议记录场景落地:本地化语音转写提升企业数据安全合规性 1. 项目背景与价值 在企业日常运营中,会议记录是必不可少的工作环节。传统的会议记录方式要么依赖人工记录效率低下,要么使用云端语音识别服务存在数据安全风险。特…...

免费获取全球900+语言支持的Noto字体库:设计师与开发者的终极解决方案
免费获取全球900语言支持的Noto字体库:设计师与开发者的终极解决方案 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts Noto字体库是谷歌开发的开源字体项目,旨在为全…...

Rust 异步 ORM 新选择:Toasty 初探
Rust 异步 ORM 新选择:Toasty 初探 2026年4月,Rust 生态迎来了一款新异步 ORM 框架 Toasty。为什么它如此收到 Rust 开发者的广泛关注呢?因为它是来自于鼎鼎大名的 Tokio 团队,该团队研发的 tokio(异步运行时…...

一阶谓词逻辑入门:命题、谓词、量词与知识表达
在知识表示的发展过程中,逻辑表示法一直占有重要位置。其中,一阶谓词逻辑(First-Order Predicate Logic)是最常见、最基础的一种形式。它比日常语言更精确,比单纯的命题逻辑更有表达能力,能够较清楚地表示对…...

Tusky测试策略分析:单元测试与集成测试在Android应用中的实践
Tusky测试策略分析:单元测试与集成测试在Android应用中的实践 【免费下载链接】Tusky An Android client for the microblogging server Mastodon 项目地址: https://gitcode.com/gh_mirrors/tu/Tusky Tusky作为一款流行的Mastodon Android客户端,…...

单调队列优化多重背包 学习笔记 详解蔷
背景 StreamJsonRpc 是微软官方维护的用于 .NET 和 TypeScript 的 JSON-RPC 通信库,以其强大的类型安全、自动代理生成和成熟的异常处理机制著称。在 HagiCode 项目中,为了通过 ACP (Agent Communication Protocol) 与外部 AI 工具(如 iflow …...