ElasticSearch - SpringBoot整合ES:实现搜索结果排序 sort
文章目录
- 00. 数据准备
- 01. Elasticsearch 默认的排序方式是什么?
- 02. Elasticsearch 支持哪些排序方式?
- 03. ElasticSearch 如何指定排序方式?
- 04. ElasticSearch 如何按照相关性排序?
- 05. ElasticSearch 查询结果如何不按照相关性排序?
- 06. ElasticSearch 如何按照字段的值排序?
- 07. ElasticSearch 排序字段的类型?
- 08. ElasticSearch 如何对文本类型的字段进行排序?
- 09. ElasticSearch 如何按照多个字段排序?
- 10. EalsticSearch 如何实现分页排序?
- 11. SpringBoot整合ES实现:按相关度排序
- 12. SpringBoot整合ES实现:按字段值排序
- 13. SpringBoot整合ES实现:按文本类型字段排序
- 14. SpringBoot整合ES实现:按多字段值排序
00. 数据准备
PUT /my_index/_doc/1
{"title": "金都时尚情侣浪漫主题酒店","content": "青岛","price": 556
}PUT /my_index/_doc/2
{"title": "金都嘉怡假日酒店","content": "北京","price": 337
}PUT /my_index/_doc/3
{"title": "金都欣欣24小时酒店","content": "天津","price": 200
}PUT /my_index/_doc/4
{"title": "金都自如酒店","content": "上海","price": 300
}
01. Elasticsearch 默认的排序方式是什么?
ElasticSearch 默认的排序方式是相关性排序。相关性排序是根据查询条件与文档的匹配程度来计算每个文档的相关性得分,然后按照得分从高到低进行排序。相关性排序是 ElasticSearch 中最常用的排序方式,因为它可以根据查询条件与文档的匹配程度来确定文档的排序位置,从而提高查询结果的准确性。
在相关性排序中,ElasticSearch 使用一种称为 TF-IDF 的算法来计算每个查询条件与文档的匹配程度。TF-IDF 算法可以有效地确定查询条件与文档的匹配程度,从而计算出每个文档的相关性得分。具体来说,TF-IDF 算法会根据查询条件中每个词的词频(TF)和文档集合中包含该词的文档数的倒数(IDF)来计算每个查询条件与文档的匹配程度,然后将所有查询条件的匹配程度加权求和,得到文档的相关性得分。
需要注意的是,相关性排序并不一定是最优的排序方式,因为它只考虑了查询条件与文档的匹配程度,而没有考虑其他因素,例如文档的时间戳、文档的重要性等。在某些情况下,其他排序方式可能更适合。在这种情况下,可以通过在查询语句中指定排序方式来实现其他排序方式。
在 Elasticsearch 中, 相关性得分由一个浮点数进行表示,并在搜索结果中通过 _score 参数返回, 默认排序是 _score 降序:
POST /my_index/_search
{"query": {"match": {"title": "金都酒店"}}
}
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 0.48362204,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "4","_score" : 0.48362204,"_source" : {"title" : "金都自如酒店","content" : "上海","price" : 300}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 0.4367569,"_source" : {"title" : "金都嘉怡假日酒店","content" : "北京","price" : 337}},{"_index" : "my_index","_type" : "_doc","_id" : "3","_score" : 0.41657305,"_source" : {"title" : "金都欣欣24小时酒店","content" : "天津","price" : 200}},{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.36585158,"_source" : {"title" : "金都时尚情侣浪漫主题酒店","content" : "青岛","price" : 556}}]}
}
02. Elasticsearch 支持哪些排序方式?
Elasticsearch 支持多种排序方式,包括按照相关度得分排序、按照字段值排序、按照多个字段排序等。
03. ElasticSearch 如何指定排序方式?
可以在查询语句中使用 “sort” 参数来指定排序方式,可以指定排序字段、排序方式等。
04. ElasticSearch 如何按照相关性排序?
默认情况下,Elasticsearch 会根据文档与查询的相关度得分进行排序,得分越高的文档排在越前面。
{"query": {"match": {"title": "金都酒店"}},"sort": [{"_score": {"order": "desc"}}]
}
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 0.48362204,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "4","_score" : 0.48362204,"_source" : {"title" : "金都自如酒店","content" : "上海","price" : 300}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 0.4367569,"_source" : {"title" : "金都嘉怡假日酒店","content" : "北京","price" : 337}},{"_index" : "my_index","_type" : "_doc","_id" : "3","_score" : 0.41657305,"_source" : {"title" : "金都欣欣24小时酒店","content" : "天津","price" : 200}},{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.36585158,"_source" : {"title" : "金都时尚情侣浪漫主题酒店","content" : "青岛","price" : 556}}]}
}
05. ElasticSearch 查询结果如何不按照相关性排序?
Elasticsearch的过滤器(Filter)不会计算相关性得分,它们只是根据指定的条件来过滤文档,而不会影响文档的相关性得分。相比之下,查询(Query)会计算相关性得分,它们会根据查询条件来计算文档的相关性得分,并将得分作为文档的排序依据。因此,如果您需要根据相关性对文档进行排序,应该使用查询(Query)而不是过滤器(Filter)。
Elasticsearch的过滤器(Filter)可以用来过滤文档,以便于在查询时只返回符合条件的文档。以下是使用过滤器的一些常见方法:
使用布尔过滤器(Boolean Filter):布尔过滤器可以将多个过滤器组合起来,以实现复杂的过滤逻辑。例如,可以使用must、should、must_not等关键字来组合多个过滤器。
使用范围过滤器(Range Filter):范围过滤器可以根据指定的范围来过滤文档。例如,可以使用range关键字来指定字段的范围。
使用存在过滤器(Exists Filter):存在过滤器可以过滤出指定字段存在或不存在的文档。例如,可以使用exists关键字来指定字段是否存在。
使用缓存过滤器(Cache Filter):缓存过滤器可以将过滤结果缓存起来,以提高查询性能。例如,可以使用cache关键字来指定是否缓存过滤结果。
GET /my_index/_search
{"query": {"bool": {"should": [{"term": {"price": "300"}}]}}
}
06. ElasticSearch 如何按照字段的值排序?
Elasticsearch可以按照字段的值进行排序,可以使用sort参数来指定排序方式。
GET /my_index/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}]
}
{"took" : 17,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "3","_score" : null,"_source" : {"title" : "金都欣欣24小时酒店","content" : "天津","price" : 200},"sort" : [200]},{"_index" : "my_index","_type" : "_doc","_id" : "4","_score" : null,"_source" : {"title" : "金都自如酒店","content" : "上海","price" : 300},"sort" : [300]},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : null,"_source" : {"title" : "金都嘉怡假日酒店","content" : "北京","price" : 337},"sort" : [337]},{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : null,"_source" : {"title" : "金都时尚情侣浪漫主题酒店","content" : "青岛","price" : 556},"sort" : [556]}]}
}
07. ElasticSearch 排序字段的类型?
在Elasticsearch中,排序字段的类型非常重要,因为不同类型的字段可能会导致排序结果不同。以下是一些常见的排序字段类型及其特点:
文本类型(text):文本类型的字段通常用于全文搜索,它们会被分词器处理成多个词条,因此在排序时可能会出现意外的结果。如果要按照文本类型的字段进行排序,通常需要使用keyword类型的子字段,或者使用fielddata特性来将文本类型的字段转换为可排序的类型(ES新版本不支持了)。
数字类型(numeric):数字类型的字段通常用于存储数字,它们可以按照数值大小进行排序。在Elasticsearch中,数字类型的字段包括整数类型(integer、long、short、byte)和浮点数类型(float、double)。如果要按照数字类型的字段进行排序,通常不需要进行额外的配置。
日期类型(date):日期类型的字段通常用于存储日期和时间,它们可以按照时间顺序进行排序。在Elasticsearch中,日期类型的字段可以使用多种格式进行存储,例如ISO-8601格式、UNIX时间戳等。如果要按照日期类型的字段进行排序,通常需要使用日期格式化字符串来指定日期格式。
需要注意的是,如果要按照非文本类型的字段进行排序,需要将字段的类型设置为相应的数据类型,否则可能会出现排序错误的情况。同时,如果要按照文本类型的字段进行排序,需要使用keyword类型的子字段或者使用fielddata特性来进行排序。
08. ElasticSearch 如何对文本类型的字段进行排序?
可以使用keyword类型的字段进行排序,查看索引的字段映射类型:
GET /my_index/_mapping
{"my_index" : {"mappings" : {"properties" : {"content" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"price" : {"type" : "long"},"title" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}
}
字段 title 和 content 都是keyword类型,因此可以排序:
GET /my_index/_search
{"query": {"match_all": {}},"sort": [{"title.keyword": {"order": "asc"}}]
}
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : null,"_source" : {"title" : "金都嘉怡假日酒店","content" : "北京","price" : 337},"sort" : ["金都嘉怡假日酒店"]},{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : null,"_source" : {"title" : "金都时尚情侣浪漫主题酒店","content" : "青岛","price" : 556},"sort" : ["金都时尚情侣浪漫主题酒店"]},{"_index" : "my_index","_type" : "_doc","_id" : "3","_score" : null,"_source" : {"title" : "金都欣欣24小时酒店","content" : "天津","price" : 200},"sort" : ["金都欣欣24小时酒店"]},{"_index" : "my_index","_type" : "_doc","_id" : "4","_score" : null,"_source" : {"title" : "金都自如酒店","content" : "上海","price" : 300},"sort" : ["金都自如酒店"]}]}
}
09. ElasticSearch 如何按照多个字段排序?
可以在 “sort” 参数中指定多个排序字段,可以指定每个字段的排序方式。
GET /my_index/_search
{"query": {"match_all": {}},"sort": [{"title.keyword": {"order": "asc"}},{"price": {"order": "desc"}}]
}
我们使用 sort 参数指定按照 title 字段进行升序排序,如果 title 字段相同,则按照 price 字段进行降序排序。
10. EalsticSearch 如何实现分页排序?
可以使用 “from” 和 “size” 参数来实现分页,可以使用 “sort” 参数来指定排序方式。
11. SpringBoot整合ES实现:按相关度排序
{"query": {"match": {"title": "金都酒店"}},"sort": [{"_score": {"order": "desc"}}]
}
@Slf4j
@Service
public class ElasticSearchImpl {@Autowiredprivate RestHighLevelClient restHighLevelClient;public void searchUser() throws IOException {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// query 查询MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("title","金都酒店");searchSourceBuilder.query(matchQueryBuilder);// 设置排序字段searchSourceBuilder.sort(SortBuilders.scoreSort().order(SortOrder.DESC));SearchRequest searchRequest = new SearchRequest(new String[]{"my_index"},searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);System.out.println(searchResponse);}
}
12. SpringBoot整合ES实现:按字段值排序
GET /my_index/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}]
}
@Slf4j
@Service
public class ElasticSearchImpl {@Autowiredprivate RestHighLevelClient restHighLevelClient;public void searchUser() throws IOException {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// query 查询MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("title","金都酒店");searchSourceBuilder.query(matchQueryBuilder);// 设置排序字段searchSourceBuilder.sort(SortBuilders.fieldSort("price").order(SortOrder.ASC));SearchRequest searchRequest = new SearchRequest(new String[]{"my_index"},searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);System.out.println(searchResponse);}
}
13. SpringBoot整合ES实现:按文本类型字段排序
GET /my_index/_search
{"query": {"match_all": {}},"sort": [{"title.keyword": {"order": "asc"}}]
}
@Slf4j
@Service
public class ElasticSearchImpl {@Autowiredprivate RestHighLevelClient restHighLevelClient;public void searchUser() throws IOException {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// query 查询MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("title","金都酒店");searchSourceBuilder.query(matchQueryBuilder);// 设置排序字段searchSourceBuilder.sort(SortBuilders.fieldSort("title.keyword").order(SortOrder.ASC));SearchRequest searchRequest = new SearchRequest(new String[]{"my_index"},searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);System.out.println(searchResponse);}
}
我们使用SortBuilders.fieldSort方法来构建排序条件,其中name.keyword表示要排序的字段,.keyword表示要使用keyword类型的子字段进行排序,SortOrder.ASC表示升序排序。
14. SpringBoot整合ES实现:按多字段值排序
GET /my_index/_search
{"query": {"match_all": {}},"sort": [{"title.keyword": {"order": "asc"}},{"price": {"order": "desc"}}]
}
@Slf4j
@Service
public class ElasticSearchImpl {@Autowiredprivate RestHighLevelClient restHighLevelClient;public void searchUser() throws IOException {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// query 查询MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("title","金都酒店");searchSourceBuilder.query(matchQueryBuilder);// 设置排序字段searchSourceBuilder.sort(SortBuilders.fieldSort("title.keyword").order(SortOrder.ASC)).sort(SortBuilders.fieldSort("price").order(SortOrder.DESC));SearchRequest searchRequest = new SearchRequest(new String[]{"my_index"},searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);System.out.println(searchResponse);}
}
相关文章:

ElasticSearch - SpringBoot整合ES:实现搜索结果排序 sort
文章目录00. 数据准备01. Elasticsearch 默认的排序方式是什么?02. Elasticsearch 支持哪些排序方式?03. ElasticSearch 如何指定排序方式?04. ElasticSearch 如何按照相关性排序?05. ElasticSearch 查询结果如何不按照相关性排序…...

IDEA的全新UI可以在配置里启用了,快来试试吧!
刚看到IDEA官方昨天发了这样一条推:IDEA的新UI可以在2022.3版本上直接使用了!开启方法如下:打开IDEA的Setting界面,在Appearance & Behavior下有个被标注为Beta标签的New UI菜单,具体如下图:勾选Enable…...

第九章 镜像架构和规划 - 备份处于活动状态时自动进行故障转移
文章目录第九章 镜像架构和规划 - 备份处于活动状态时自动进行故障转移备份处于活动状态时自动进行故障转移备份不活动时的自动故障转移对各种中断场景的镜像响应响应主要中断场景的自动故障转移第九章 镜像架构和规划 - 备份处于活动状态时自动进行故障转移 备份处于活动状态…...

Barra模型因子的构建及应用系列七之Liquidity因子
一、摘要 在前期的Barra模型系列文章中,我们构建了Size因子、Beta因子、Momentum因子、Residual Volatility因子、NonLinear Size因子和Book-to-Price因子,并分别创建了对应的单因子策略,其中Size因子和NonLinear Siz因子具有很强的收益能力…...
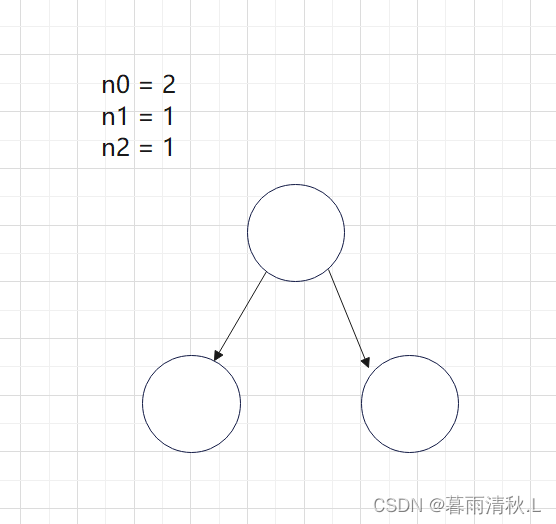
走进二叉树的世界 ———性质讲解
二叉树的性质和证明前言1.二叉树的概念和结构特殊的二叉树:二叉树的性质前言 本篇博客主要讲述的是有关二叉树的一些概念,性质以及部分性质的相关证明,如果大伙发现了啥错误,可以在评论区指出😘😘 1.二叉树…...

【SSM】Spring + SpringMVC +MyBatis 框架整合
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ SSM框架整合一、导入相关依赖二、配置web.xml文…...

【算法基础】一篇文章彻底弄懂Dijkstra算法|多图解+代码详解
博主简介:努力学习的大一在校计算机专业学生,热爱学习和创作。目前在学习和分享:算法、数据结构、Java等相关知识。博主主页: 是瑶瑶子啦所属专栏: 算法 ;该专栏专注于蓝桥杯和ACM等算法竞赛🔥近期目标&…...

第二十三天01MySQL多表查询与事务
目录 1. 多表查询 1.1 概述 1.1.1 数据准备 1.1.2 介绍 1.1.3 分类 1.2 内连接 1.2.1 语法 1.2.2 案例演示 1.3 外连接 1.3.1 语法 1.3.2 案例演示 1.4 子查询 1.4.1 介绍 1.4.2 标量子查询 1.4.3 列子查询 1.4.4 行子查询 1.4.5 表子查询 1.5 案例 1.5.1 介…...
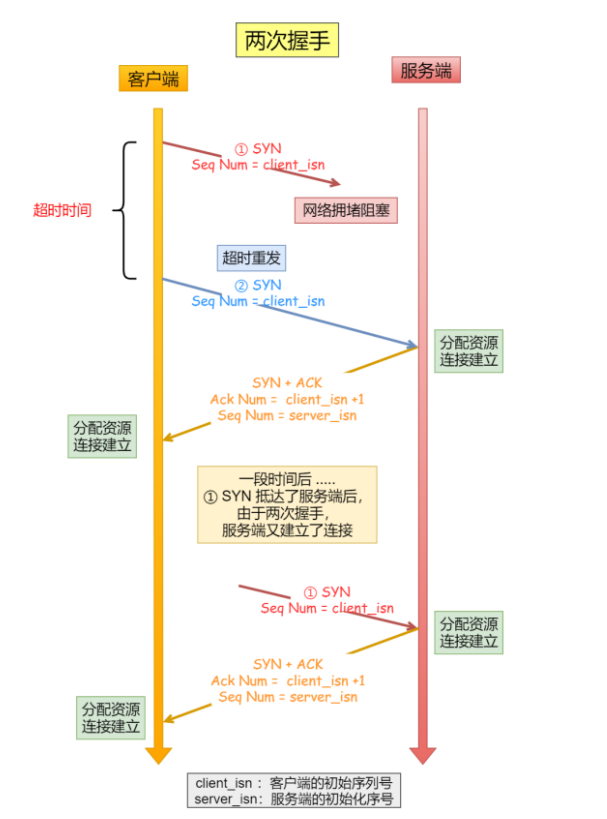
TCP协议详解
1.TCP的准备条件在古代的时候,古人们经常写书信进行交流,写书信的前提是你要知道这份信是要寄给谁在网络中,我们通过ip端口号找对目标对象,但是现在网站一般会对ip端口注册一个域名,所以我们一般就是对域名进行查找&am…...
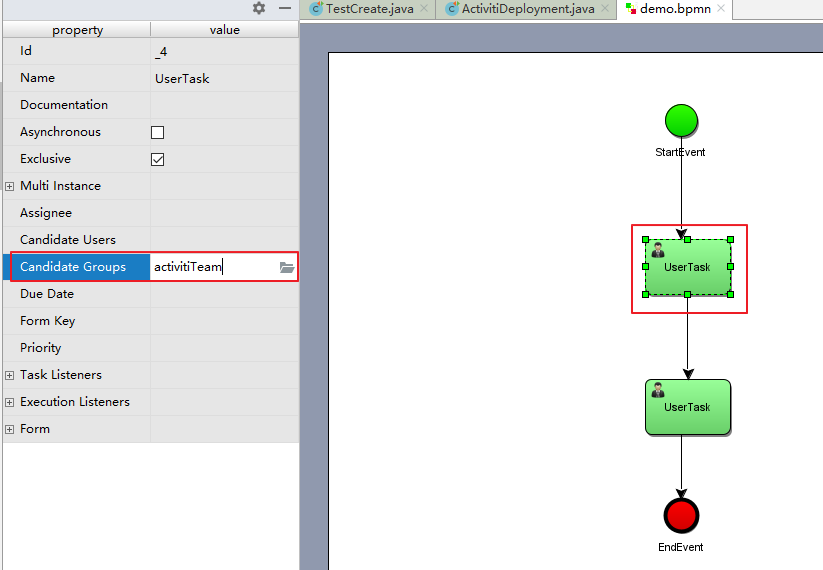
Activiti7与Spring、Spring Boot整合开发
Activiti整合Spring 一、Activiti与Spring整合开发 1.1 Activiti与Spring整合的配置 1)、在pom.xml文件引入坐标 如下 <properties><slf4j.version>1.6.6</slf4j.version><log4j.version>1.2.12</log4j.version> </properties> <d…...
基于SpringBoot实现冬奥会运动会科普平台【源码+论文】
基于SpringBoot实现冬奥会科普平台演示开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包&#…...

一文吃透SpringBoot整合mybatis-plus(保姆式教程)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
编程练习答案 第4章 复合类型)
C++ primer plus(第六版)编程练习答案 第4章 复合类型
一、程序清单 arrayone.cpp // arrayone.cpp -- small arrays of integers #include <iostream> int main() {using namespace std;int yams[3]; // creates array with three elementsyams[0] = 7; // assign value to first elementyams[1] = 8;yams[2] = 6;i…...
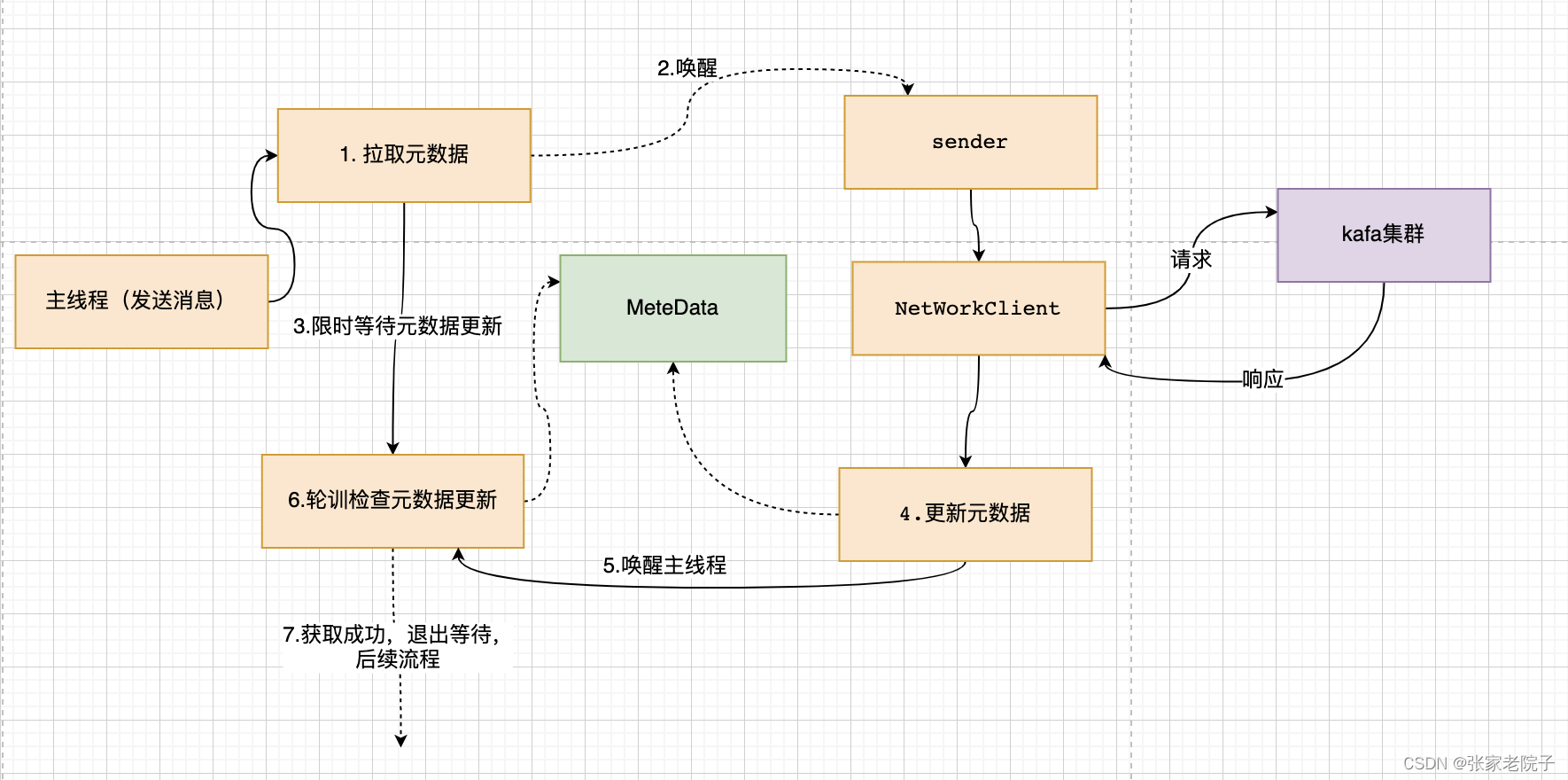
Kafka源码分析之Producer(一)
总览 根据kafka的3.1.0的源码example模块进行分析,如下图所示,一般实例代码就是我们分析源码的入口。 可以将produce的发送主要流程概述如下: 拦截器对发送的消息拦截处理; 获取元数据信息; 序列化处理;…...

springboot校友社交系统
050-springboot校友社交系统演示录像开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:e…...

python flask项目部署
flask上传服务器pyhon安装下载Anacondasudo wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh可根据需要安装对应的版本https://repo.anaconda.com/archive/解压anaconda压缩包bash Anaconda3-5.3.1-Linux-x86_64.sh解压过程中会…...
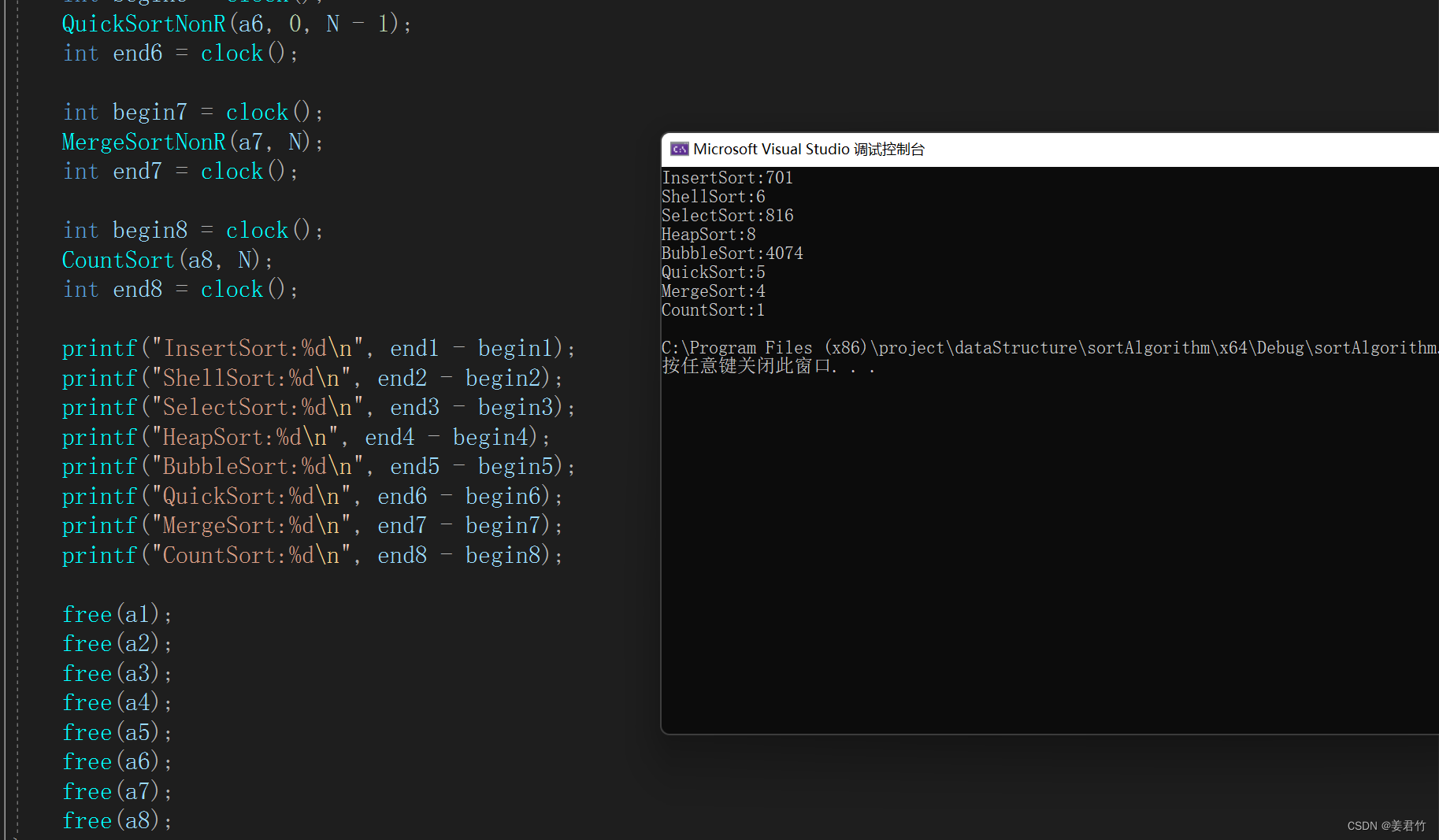
常见排序算法(C语言实现)
文章目录排序介绍插入排序直接插入排序希尔排序选择排序选择排序堆排序交换排序冒泡排序快速排序递归实现Hoare版本挖坑法前后指针版本非递归实现Hoare版本挖坑法前后指针版本快排的优化三值取中小区间优化归并排序递归实现非递归实现计数排序排序算法复杂度及稳定性分析不同算…...

基于jsp+ssm+springboot的小区物业管理系统【设计+论文+源码】
摘 要随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于小区物业管理系统当然也不能排除在外,随着网络技术的不断成熟,带动了小区物业管理系统,它彻底改变了过去…...

Elasticsearch 学习+SpringBoot实战教程(三)
需要学习基础的可参照这两文章 Elasticsearch 学习SpringBoot实战教程(一) Elasticsearch 学习SpringBoot实战教程(一)_桂亭亭的博客-CSDN博客 Elasticsearch 学习SpringBoot实战教程(二) Elasticsearch …...

try-with-resource
try-with-resource是Java 7中引入的新特性,它可以方便地管理资源,自动关闭资源,从而避免了资源泄漏的问题。 作用 使用try-with-resource语句可以简化代码,避免了手动关闭资源的繁琐操作,同时还可以保证资源的正确关闭…...

不止于上传预览:在若依框架中构建一个轻量级企业文档管理模块
若依框架下的企业级文档中心设计与实战 在数字化转型浪潮中,企业文档管理正从简单的文件存储向智能化协作平台演进。基于若依微服务框架构建文档中心模块,不仅能满足基础的PDF上传预览需求,更能为企业提供版本控制、权限管理、全文检索等进阶…...

开源音乐解锁工具:浏览器端全平台音频解密解决方案
开源音乐解锁工具:浏览器端全平台音频解密解决方案 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://…...

Windows 10 PL-2303串口驱动终极修复指南:告别老旧芯片兼容性问题
Windows 10 PL-2303串口驱动终极修复指南:告别老旧芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10系统下PL-2303串口适配器…...

开源证书工具故障排查:ACME协议证书续期问题从现象到本质的深度解析
开源证书工具故障排查:ACME协议证书续期问题从现象到本质的深度解析 【免费下载链接】win-acme Automate SSL/TLS certificates on Windows with ease 项目地址: https://gitcode.com/gh_mirrors/wi/win-acme 问题诊断:NginxCertbot环境下的证书续…...

ComfyUI-Florence2深度配置指南:如何高效解决视觉语言模型加载与文档问答难题
ComfyUI-Florence2深度配置指南:如何高效解决视觉语言模型加载与文档问答难题 【免费下载链接】ComfyUI-Florence2 Inference Microsoft Florence2 VLM 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-Florence2 在人工智能视觉处理领域,F…...

GPU Burn:多GPU压力测试的终极解决方案
GPU Burn:多GPU压力测试的终极解决方案 【免费下载链接】gpu-burn Multi-GPU CUDA stress test 项目地址: https://gitcode.com/gh_mirrors/gp/gpu-burn 在高性能计算与深度学习领域,GPU的稳定性直接决定了系统的可靠性。作为一款专注于NVIDIA显卡…...

Proxy最佳实践:企业级C++项目中如何正确使用多态库
Proxy最佳实践:企业级C项目中如何正确使用多态库 【免费下载链接】proxy Proxy: Next Generation Polymorphism in C 项目地址: https://gitcode.com/gh_mirrors/pr/proxy 在当今的企业级C开发中,运行时多态性是构建可扩展、可维护系统的关键。传…...

QML与QWidget混合开发:实现高效UI集成的实战指南
1. 为什么需要QML与QWidget混合开发 在Qt开发中,QML和QWidget是两种完全不同的UI构建方式。QML凭借其声明式语法和强大的动画效果,在现代UI开发中越来越受欢迎。但现实情况是,很多成熟的功能模块都是基于QWidget开发的,比如一些第…...

告别手动刷课!智慧树网课助手让你的学习效率提升50%
告别手动刷课!智慧树网课助手让你的学习效率提升50% 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 你是否厌倦了在智慧树平台上频繁点击"下一集"…...
)
实测Claude 4.5 Opus重构“屎山”代码:手把手教你用AI给遗留项目做外科手术(附前后对比与单元测试生成)
实测Claude 4.5 Opus重构“屎山”代码:手把手教你用AI给遗留项目做外科手术(附前后对比与单元测试生成) 接手一个满是"祖传代码"的老旧项目,就像被丢进一座迷宫——变量命名像密码,函数逻辑像意大利面&…...