行空板上YOLO和Mediapipe视频物体检测的测试
Introduction
经过前面三篇教程帖子(yolov8n在行空板上的运行(中文),yolov10n在行空板上的运行(中文),Mediapipe在行空板上的运行(中文))的介绍,我们对如何使用官方代码在行空板上运行物体检测的AI模型有了基本的概念,并对常见的模型进行了简单的测试和对比。
在行空板上YOLO和Mediapipe图片物体检测的测试(中文)中我们对于行空板上使用YOLO和Mediapipe进行图片物体检测进行了测试。
进一步的,本文将
- 对不同模型的视频物体检查进行详细的对比分析;
- 进行针对在行空板上的视频物体检测进行代码编写和优化;
- 对不同模型的帧率对比测试。
Note: 因为视频物体检测和图片物体检测用的是相同的模型,所以在检测准确性上不会有区别,所以检测结果的准确性可以直接参考以行空板上YOLO和Mediapipe图片物体检测的测试(中文)所做的测试。
yolo视频物体检测
不同onnx模型导出设置的表现对比
设置和代码
导出onnx模型的官方代码为:
from ultralytics import YOLO# Load a pretrained YOLOv10n model
model = YOLO("yolov10n.pt")#export onnx
model.export(format='onnx')
yolo系列模型在使用官方代码导出onnx格式模型的时候,有几个不同的选项:
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| imgsz | int or tuple | 640 | 模型输入所需的图像大小。对于正方形图像可以是整数,对于特定尺寸可以是元组(高度,宽度)。 |
| half | bool | False | 支持FP16(半精度)量化,减少模型尺寸,并可能加快对支持硬件的推理。 |
| dynamic | bool | False | 允许ONNX和TensorRT导出的动态输入大小,增强处理不同图像尺寸的灵活性。 |
| simplify | bool | False | 简化ONNX导出的模型图,潜在地提高性能和兼容性。 |
- 其中,dynamic与imgsz不兼容;dynamic与half不兼容。
我们将分别对这几个选项的不同组合进行对比测试,分辨率都采用640。共包括以下模型:
| 设置 | 代码 |
|---|---|
| 默认 | model.export(format=‘onnx’, imgsz=640) |
| dynamic | model.export(format=‘onnx’, dynamic=True) |
| simplify | model.export(format=‘onnx’, simplify=True, imgsz=640) |
| simplify和dynamic | model.export(format=‘onnx’, simplify=True, dynamic=True) |
| half | model.export(format=‘onnx’, half=True, imgsz=640) |
| simlify和half | model.export(format=‘onnx’, simplify=True, half=True, imgsz=640) |
测试结果
对不同设置的模型进行行空板+USB摄像头的视频物体检测测试,结果如下:
| 模型大小 | simplify | half | dynamic | imgsz | 帧率 | |
|---|---|---|---|---|---|---|
| YOLOv10n | 8.99MB | × | × | × | 640 | 0.3029 |
| YOLOv10n | 8.86MB | × | × | √ | × | 0.3002 |
| YOLOv10n | 8.95MB | √ | × | × | 640 | 0.3009 |
| YOLOv10n | 8.95MB | √ | × | √ | × | 0.3011 |
| YOLOv10n | 8.99MB | × | √ | × | 640 | 0.2999 |
| YOLOv10n | 8.95MB | √ | √ | × | 640 | 0.3017 |
分析
通过测试结果的统计,可以分析得到以下特点:
- dynamic设置可以略微减小模型大小,也会略微降低运行速度;
- simplify也可以略微减小模型大小,但极不显著,也会略微降低运行速度;
- 如果simplify和dynamic同时开启,不如值开启dynamic在模型尺寸上减少的明显;
- half设置并没有速度上的提升,反而有降低,这是因为行空板没有半精度优化的硬件支持。
小结
- 如果能事先知道输入图片的尺寸,就不要使用任何参数设置,只用imgsz设置图片尺寸;
- 如果实现不知道图片输入的尺寸,就使用dynamic=True;
- 不要设置half=True和simplify=True
不同尺寸输入的表现对比
yolo的测试结果
| 模型 | 模型大小 | dynamic | imgsz | 帧率 |
|---|---|---|---|---|
| YOLOv10n | 8.99MB | × | 640 | 0.30 |
| YOLOv10n | 8.91MB | × | 448 | 0.59 |
| YOLOv10n | 8.87MB | × | 320 | 1.07 |
| YOLOv10n | 8.86MB | × | 256 | 1.70 |
| YOLOv10n | 8.84MB | × | 128 | 5.01 |
| YOLOv8n | 12.2MB | × | 640 | 0.26 |
| YOLOv8n | 12.1MB | √ | 448 | 0.53 |
| YOLOv8n | 12.1MB | √ | 320 | 0.99 |
| YOLOv8n | 12.0MB | √ | 256 | 1.59 |
| YOLOv8n | 12.0MB | √ | 128 | 4.80 |
| YOLOv8n | 12.0MB | √ | 64 | 9.17 |
分析
可以看出,随着输入尺寸的减小,帧率显著提高。
yolov10n的帧率比yolov8n略高10%左右,同时模型大小减少25%。
小结
- 对于视频检测,在行空板上以128的分辨率运行勉强可以使用;
- 建议选择yolov10n,相较v8,内存占用和速度方面都有优势。
Mediapipe视频物体检测
设置
针对Mediapipe中的三个模型,我们分别测试了非量化和int8量化下的不同分辨率。
分辨率包括:
640、448、320、256、128
测试结果
| 模型\分辨率 | 640 | 448 | 320 | 256 | 128 | 64 |
|---|---|---|---|---|---|---|
| efficientdet_lite0 | 0.42 | 0.42 | 0.42 | 0.42 | 0.42 | 0.43 |
| efficientdet_lite0_int8 | 0.85 | 0.85 | 0.85 | 0.85 | 0.85 | 0.86 |
| efficientdet_lite2 | 0.13 | 0.13 | 0.13 | 0.13 | 0.13 | 0.13 |
| efficientdet_lite2_int8 | 0.27 | 0.27 | 0.27 | 0.27 | 0.27 | 0.27 |
| ssd_mobilenet_v2 | 0.61 | 0.61 | 0.61 | 0.61 | 0.61 | 0.61 |
| ssd_mobilenet_v2_int8 | 0.61 | 0.61 | 0.61 | 0.61 | 0.61 | 0.62 |
小结
- 与图片的目标检测结果类似,不同的分辨率对这些模型而言没有影响;
- 对于efficientdet_lite0和efficientdet_lite2,int8量化可以显著提速;int8量化对于ssd_mobilenet_v2没有影响
视频物体检测总结
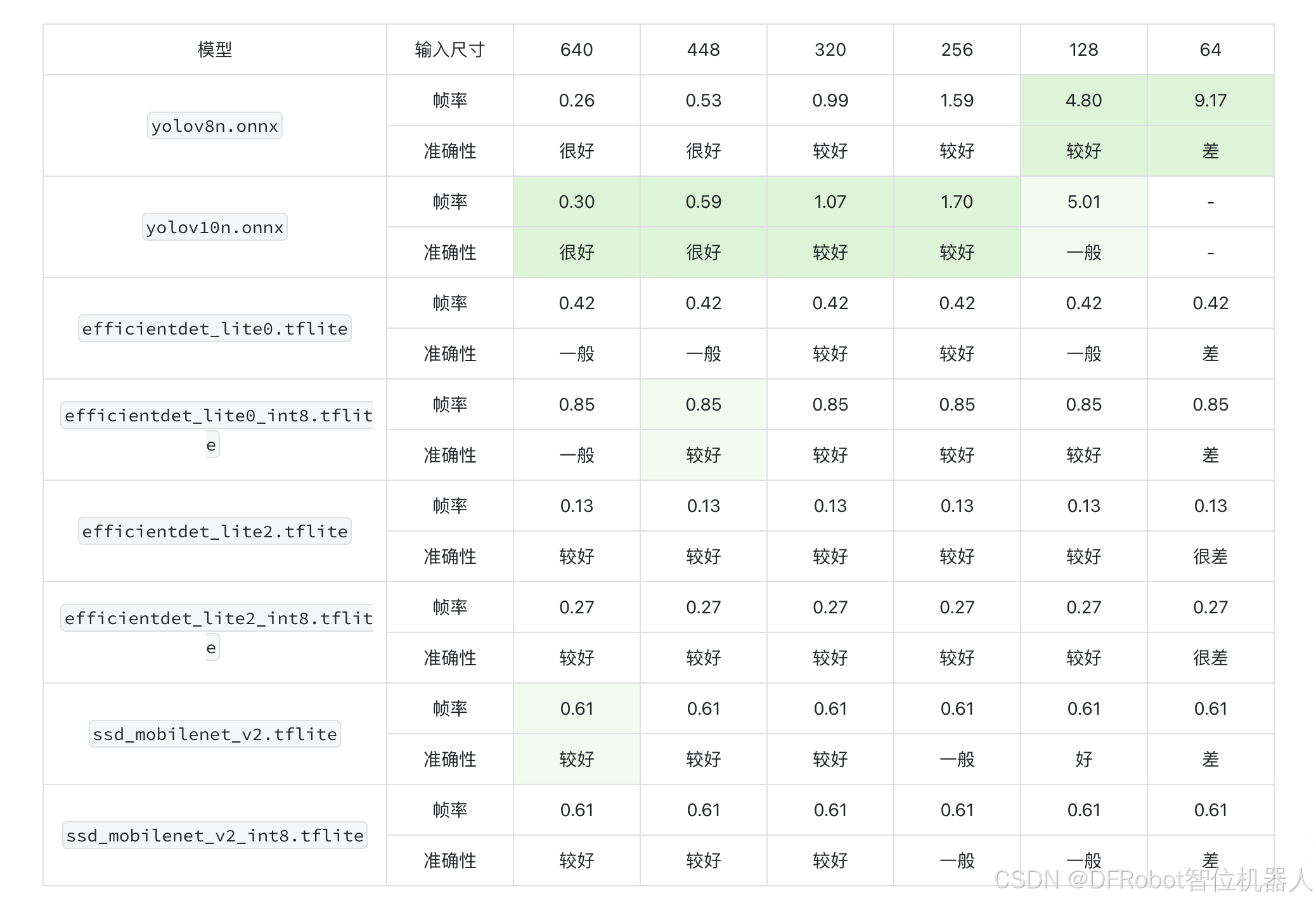
我们在统计测试后发现了以下特点:
- yolo系列随着图片分辨率下调,检测耗时显著减少;而Mediapipe不明显。这说明在小分辨率图片检测中,yolo系列有显著的速度优势;
- det的两个模型进行int8量化之后速度显著提升,几乎不会损失准确性;
- Mediapipe的模型在较大分辨率的时候相比yolo有显著的速度优势,但是准确性略低一点。在应用的时候,需要在准确性和速度上进行权衡。
模型选择建议
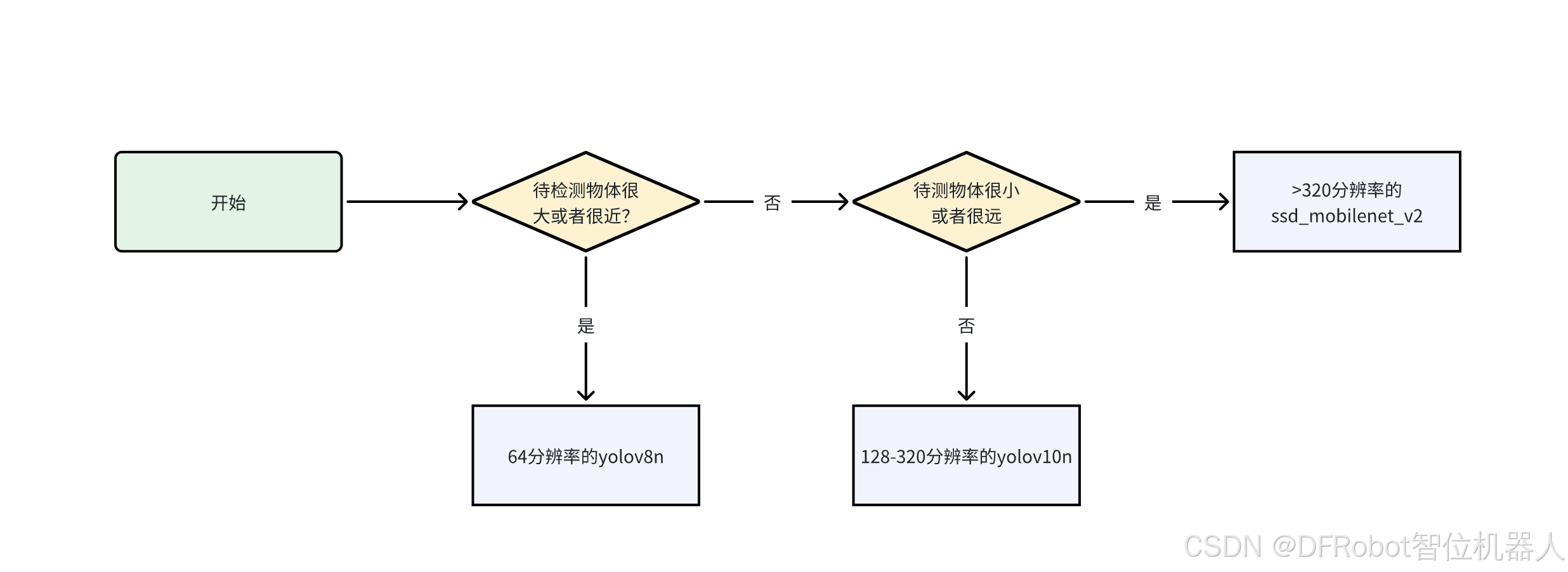
- 限于视频帧率问题,我们认为最多使用320分辨率,使帧率达到1;
- 如果物体较近或者较大,在低分辨率图片上也可以方便地提取特征,这种情况下推荐使用较低分辨率而速度较快的模型,如64帧率的
yolov8n; - 如果物体较远或者物体较小,则需要分辨率更高才能提取到足够的特征,这种情况下推荐选择
yolov10n。如果需要更高分辨率的图片,而且可以接收帧率较低,可以采用ssd_mobilenet_v2.tflite模型。可以参考下面的流程来选取模型:
附录
使用yolov10n视频检测的代码
行空板+USB摄像头使用yolov10n进行物体检测的代码代码如下:
import cv2
import numpy as np
import onnxruntime as ort
import yaml
import time def preprocess(frame, input_size):#这里的resize使用nearest,可以提速大约0.3-0.5帧image = cv2.resize(frame, input_size,interpolation=cv2.INTER_NEAREST)# 转换图片到数组image_data = np.array(image).transpose(2, 0, 1) # 转换成CHWimage_data = image_data.astype(np.float32)image_data /= 255.0 # 归一化image_data = np.expand_dims(image_data, axis=0) # 增加batch维度return image_datadef postprocess(output, image, input_size, show_size, classes):for detection in output:x1, y1, x2, y2, conf , class_id = detectionif conf > 0.4:x1 = int(x1 / input_size[0] * show_size[0])x2 = int(x2 / input_size[0] * show_size[0])y1 = int(y1 / input_size[1] * show_size[1])y2 = int(y2 / input_size[1] * show_size[1])class_id = int(class_id) cv2.rectangle(image, (x1, y1), (x2, y2), (255, 0, 0), 2) # 画框class_name = classes[class_id]cv2.putText(image, class_name, (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)return imagedef main():input_size = (128, 128)with open('ultralytics/cfg/datasets/coco.yaml', 'r', encoding='utf-8') as f:data = yaml.safe_load(f)classes = data['names']window_name = 'FullScreen Image'cv2.namedWindow(window_name, cv2.WINDOW_NORMAL) cv2.setWindowProperty(window_name, cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)# 加载模型session = ort.InferenceSession('yolov10n.onnx')input_name = session.get_inputs()[0].name# 打开摄像头。cap = cv2.VideoCapture(0)if not cap.isOpened():print("Cannot open camera")exit()prev_time = 0while True:ret, frame = cap.read()show_size = [320,240]if not ret:print("Can't receive frame (stream end?). Exiting ...")breakcurrent_time = time.time()# 预处理图像input_tensor = preprocess(frame, input_size)# 进行推理outputs = session.run(None, {input_name: input_tensor})output = outputs[0][0]# 后处理show_image = postprocess(output, frame, input_size, show_size, classes)fps = 1.0 / (current_time - prev_time)prev_time = current_time # 更新前一帧的时间cv2.putText(show_image, f"FPS: {fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)# 显示结果cv2.imshow(window_name, show_image)if cv2.waitKey(1) == ord('q'):break# 释放资源cap.release()cv2.destroyAllWindows()if __name__ == '__main__':main()
使用Mediapipe视频检测的代码
行空板+USB摄像头使用Mediapipe进行物体检测的代码代码如下:
import numpy as np
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
import cv2
import timeinput_size = (640,640)
# STEP 1: Import the necessary modules.
base_options = python.BaseOptions(model_asset_path='efficientdet_lite0.tflite')
options = vision.ObjectDetectorOptions(base_options=base_options,score_threshold=0.5)
detector = vision.ObjectDetector.create_from_options(options)# STEP 2: Create an ObjectDetector object.
MARGIN = 10 # pixels
ROW_SIZE = 10 # pixels
FONT_SIZE = 1
FONT_THICKNESS = 1
TEXT_COLOR = (255, 0, 0) # reddef visualize(image, detection_result) -> np.ndarray:"""Draws bounding boxes on the input image and return it.Args:image: The input RGB image.detection_result: The list of all "Detection" entities to be visualize.Returns:Image with bounding boxes."""for detection in detection_result.detections:# Draw bounding_boxbbox = detection.bounding_boxstart_point = bbox.origin_x, bbox.origin_yend_point = bbox.origin_x + bbox.width, bbox.origin_y + bbox.heightcv2.rectangle(image, start_point, end_point, TEXT_COLOR, 3)# Draw label and scorecategory = detection.categories[0]category_name = category.category_nameprobability = round(category.score, 2)result_text = category_name + ' (' + str(probability) + ')'text_location = (MARGIN + bbox.origin_x,MARGIN + ROW_SIZE + bbox.origin_y)cv2.putText(image, result_text, text_location, cv2.FONT_HERSHEY_PLAIN,FONT_SIZE, TEXT_COLOR, FONT_THICKNESS)return image# STEP 3: Initialize the video capture from the webcam.
cap = cv2.VideoCapture(0)
prev_time = 0while cap.isOpened():ret, frame = cap.read()if not ret:breakframe = cv2.resize(frame, input_size, interpolation=cv2.INTER_NEAREST)# Convert the frame to the format required by MediaPipe.image = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame)# STEP 4: Detect objects in the frame.detection_result = detector.detect(image)# STEP 5: Process the detection result. In this case, visualize it.annotated_frame = visualize(frame, detection_result)# Calculate and display the frame ratecurrent_time = time.time()fps = 1 / (current_time - prev_time)prev_time = current_timefps_text = f'FPS: {fps:.2f}'print(fps_text)cv2.putText(annotated_frame, fps_text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)cv2.imshow('Object Detection', annotated_frame)# Break the loop if the user presses 'q'.if cv2.waitKey(1) & 0xFF == ord('q'):break# Release the resources.
cap.release()
cv2.destroyAllWindows()
相关文章:
行空板上YOLO和Mediapipe视频物体检测的测试
Introduction 经过前面三篇教程帖子(yolov8n在行空板上的运行(中文),yolov10n在行空板上的运行(中文),Mediapipe在行空板上的运行(中文))的介绍,…...

【Spring Boot 3】【Web】ProblemDetail
【Spring Boot 3】【Web】ProblemDetail 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...

市占率最高的显示器件,TFT_LCD的驱动系统设计--Part 1
目录 一、简介 二、TFT-LCD驱动系统概述 (一)系统概述 (二)设计要点 二、扫描驱动电路设计 (一)概述 扫描驱动电路的功能 扫描驱动电路的组成部分 设计挑战 驱动模式 (二)…...

Linux基础 -- 获取CPU负载信息
Linux Kernel 获取当前负载情况 本文档介绍了如何在 Linux 内核中获取系统的负载情况。我们将从用户态程序、内核模块开发等角度展示相关方法。 1. 通过 /proc/loadavg 文件获取负载 /proc/loadavg 文件包含了系统的负载信息,通常包括过去 1 分钟、5 分钟和 15 分…...

Django 中的用户界面 - 创建速度计算器
在 Django 中创建一个用户界面来计算速度,可以通过以下步骤完成。这个速度计算器将允许用户输入距离和时间,计算并显示速度。 一、问题背景 一位 Django 新手希望使用 Django 构建一个用户界面,以便能够计算速度(速度 距离/时间…...
spring security 如何解决跨域的
一、什么是 CORS CORS(Cross-Origin Resource Sharing) 是由 W3C制定的一种跨域资源共享技术标准,其目就是为了解决前端的跨域请求。在JavaEE 开发中,最常见的前端跨域请求解决方案是早期的JSONP,但是JSONP 只支持 GET 请求,这是一…...

日志系统前置知识
日志:程序运行过程中所记录的程序运行状态信息。通过这些信息,以便于程序员能够随时根据状态信息,对系统的运行状态进行分析。功能:能够让用户非常简便的进行日志的输出以及控制。 同步写日志 同步日志是指当输出日志时ÿ…...

【Spring Boot 3】【Web】全局异常处理
【Spring Boot 3】【Web】全局异常处理 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花费…...

Dcoker 运行es
1,创建network docker network create my-network 2,docker运行es容器 docker run -d --name es-container --net my-network -p 9200:9200 -p 9300:9300 -e "discovery.typesingle-node" docker.elastic.co/elasticsearch/elasticsearch:7…...

7系列FPGA HR/HP I/O区别
HR High Range I/O with support for I/O voltage from 1.2V to 3.3V. HP High Performance I/O with support for I/O voltage from 1.2V to 1.8V. UG865:Zynq-7000 All Programmable SoC Packaging and Pinout...

sqli-labs靶场通关攻略(五十一到六十关)
sqli-labs-master靶场第五十一关 步骤一,尝试输入?sort1 我们发现这关可以报错注入 步骤二,爆库名 ?sort1 and updatexml(1,concat(0x7e,database(),0x7e),1)-- 步骤三,爆表名 ?sort1 and updatexml(1,concat(0x7e,(select group_conc…...
c语言中的动态内存管理
在 C 语言中,动态内存管理主要通过以下几个函数实现: 一、malloc 函数 功能: malloc 函数用于在内存的动态存储区中分配一块长度为 size 字节的连续区域。函数返回一个指向分配区域起始地址的指针,如果分配失败则回 NULL 示例: …...
生信机器学习入门4 - scikit-learn训练逻辑回归(LR)模型和支持向量机(SVM)模型
通过逻辑回归(logistic regression)建立分类模型 1.1 逻辑回归可视化和条件概率 激活函数 (activation function): 一种函数(如 ReLU 或 S 型函数),用于对上一层的所有输入进行求加权和,然后生…...

COD论文笔记 Adaptive Guidance Learning for Camouflaged Object Detection
论文的主要动机、现有方法的不足、拟解决的问题、主要贡献和创新点如下: 动机: 论文的核心动机是解决伪装目标检测(COD)中的挑战性任务。伪装目标检测旨在识别和分割那些在视觉上与周围环境高度相似的目标,这对于计算…...

9.5LeetCode
80.删除有序数组重复项II 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的…...

数据仓库系列13:增量更新和全量更新有什么区别,如何选择?
你是否曾经在深夜加班时,面对着庞大的数据仓库,思考过这样一个问题:“我应该选择增量更新还是全量更新?” 这个看似简单的选择,却可能影响整个数据处理的效率和准确性。今天,让我们深入探讨这个数据仓库领域…...
)
数据 结构(内核链表)
一、内核链表(是一个有头双向循环链表) 1.内核提供的两个宏 (1) offsetof : 获取结构体成员到结构体开头的偏移量; (2) contianer_of : 通过偏移量获取结构体首地址; 2.代码示例: truct passager *create_passage…...

学习node.js十三,文件的上传于下载
文件上传 文件上传的方案: 大文件上传:将大文件切分成较小的片段(通常称为分片或块),然后逐个上传这些分片。这种方法可以提高上传的稳定性,因为如果某个分片上传失败,只需要重新上传该分片而…...

【刷题笔记】删除并获取最大点数粉刷房子
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 题目一 题目链接:删除并获取最大点数 思路: 预处理状态表示 状态转移方程 代码如下: class Solution { public:int deleteAndEarn(vector<int>& nums) {int N1…...

【Linux 从基础到进阶】Elasticsearch 搜索服务安装与调优
Elasticsearch 搜索服务安装与调优 引言 Elasticsearch 是一个分布式的、基于 RESTful API 的搜索和分析引擎,专为快速处理大量数据而设计。它经常被用来进行全文搜索、日志和指标分析等操作。本文将介绍如何在 CentOS 和 Ubuntu 系统上安装 Elasticsearch,并进行必要的调优…...

【限时技术内参】EF Core团队内部测试报告流出:向量搜索启用后DbContext并发吞吐量下降41%的根因与热修复补丁
第一章:Entity Framework Core 10 向量搜索扩展 避坑指南Entity Framework Core 10 原生未提供向量搜索能力,需依赖第三方扩展(如 EFCore.Vector 或数据库原生支持)实现相似性检索。开发者常因忽略底层向量存储格式、索引策略或查…...

Cursor Pro免费使用终极指南:绕过试用限制的完整解决方案
Cursor Pro免费使用终极指南:绕过试用限制的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your …...

foss_photo_libraries移动端功能详解:从自动上传到多平台支持的终极指南
foss_photo_libraries移动端功能详解:从自动上传到多平台支持的终极指南 【免费下载链接】foss_photo_libraries Free and Open Source Photo Libraries 项目地址: https://gitcode.com/gh_mirrors/fo/foss_photo_libraries 在当今移动优先的时代,…...

Windows系统苹果USB驱动安装全攻略:告别iTunes臃肿安装
Windows系统苹果USB驱动安装全攻略:告别iTunes臃肿安装 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mi…...

OpenClaw硬件加速:在NVIDIA显卡上优化Kimi-VL-A3B-Thinking推理速度
OpenClaw硬件加速:在NVIDIA显卡上优化Kimi-VL-A3B-Thinking推理速度 1. 从CPU到GPU的性能跃迁之旅 去年冬天,当我第一次在本地部署Kimi-VL-A3B-Thinking模型时,那个漫长的等待过程至今记忆犹新。一个简单的图文问答任务,在16核C…...
)
线程同步与互斥(下)
线程同步与互斥(中)https://blog.csdn.net/Small_entreprene/article/details/147003513?fromshareblogdetail&sharetypeblogdetail&sharerId147003513&sharereferPC&sharesourceSmall_entreprene&sharefromfrom_link我们学习了互斥…...
GPU算力优化实践:Pixel Epic智识终端显存配额与逻辑发散调参详解
GPU算力优化实践:Pixel Epic智识终端显存配额与逻辑发散调参详解 1. 引言:当像素冒险遇上AI研究 在科研领域,我们常常面临一个两难选择:要么追求严谨性而牺牲创造力,要么放飞思维却失去逻辑性。Pixel Epic智识终端通…...

OpenClaw新手避坑指南:Qwen3-14B镜像部署的5个常见失误
OpenClaw新手避坑指南:Qwen3-14B镜像部署的5个常见失误 1. 为什么需要这份避坑指南 第一次在本地部署OpenClaw对接Qwen3-14B镜像时,我踩遍了所有能想到的坑。从CUDA版本冲突到显存溢出,从端口占用到凭证失效,整个过程就像在玩&q…...

AI入门必看|一文搞懂人工智能是什么,小白也能秒懂
前言:随着ChatGPT、自动驾驶、AI绘画的普及,人工智能已经从“高大上的科技概念”走进了我们的日常生活,但很多小白面对“人工智能”四个字,还是会感到迷茫——它到底是什么?能做什么?和我们普通人有什么关系…...

告别AI幻觉!WeKnora知识库系统实测:严格依据文本,回答100%可靠
告别AI幻觉!WeKnora知识库系统实测:严格依据文本,回答100%可靠 1. 项目介绍 WeKnora是一款革命性的知识库问答系统,它彻底解决了传统大语言模型"胡说八道"的问题。通过创新的技术架构和严格的回答约束机制,…...