数据仓库系列13:增量更新和全量更新有什么区别,如何选择?
你是否曾经在深夜加班时,面对着庞大的数据仓库,思考过这样一个问题:“我应该选择增量更新还是全量更新?” 这个看似简单的选择,却可能影响整个数据处理的效率和准确性。今天,让我们深入探讨这个数据仓库领域的核心问题,揭示增量更新和全量更新的秘密,帮助你在实际工作中做出明智的选择。

目录
- 引言:数据更新的重要性
- 增量更新vs全量更新:基本概念
- 增量更新的优势与挑战
- 优势
- 挑战
- 示例:增量更新实现
- 全量更新的优势与挑战
- 优势
- 挑战
- 示例:全量更新实现
- 如何选择更新策略:决策框架
- 决策树示例
- 实战案例:电商订单数据更新
- 场景分析
- 增量更新方案
- 全量更新方案
- 选择建议
- 性能优化技巧
- 1. 索引优化
- 2. 分区表
- 3. 批量处理
- 4. 并行处理
- 常见陷阱与解决方案
- 1. 死锁问题
- 2. 数据不一致
- 3. 性能瓶颈
- 未来趋势:实时数据更新
- 实时更新的优势
- 实现实时更新的技术
- 示例:使用Kafka实现实时更新
- 结论
引言:数据更新的重要性
在大数据时代,数据仓库已经成为企业决策的核心基础设施。而保持数据的及时性和准确性,则是数据仓库发挥作用的关键。无论是增量更新还是全量更新,都是为了实现这一目标的重要手段。选择合适的更新策略,不仅可以提高数据处理效率,还能确保数据质量,进而支持更好的业务决策。

增量更新vs全量更新:基本概念
在深入讨论之前,让我们先明确这两个概念:
- 增量更新(Incremental Update):只处理自上次更新以来发生变化的数据。
- 全量更新(Full Update):每次更新时处理整个数据集。
这两种方法各有优缺点,选择哪一种取决于多个因素,包括数据量、更新频率、系统资源等。

增量更新的优势与挑战
优势
- 效率高:只处理变化的数据,大大减少了处理时间和资源消耗。
- 实时性强:可以更频繁地进行更新,保持数据的新鲜度。
- 网络带宽友好:减少数据传输量,特别适合分布式系统。

挑战
- 复杂性:需要设计和维护变更跟踪机制。
- 一致性风险:如果增量更新失败,可能导致数据不一致。
- 历史数据管理:需要考虑如何处理和存储历史变更记录。
示例:增量更新实现
以下是一个简单的Python代码示例,展示了增量更新的基本逻辑:
import pandas as pd
from datetime import datetimedef incremental_update(existing_data, new_data, key_column, timestamp_column):# 合并现有数据和新数据combined_data = pd.concat([existing_data, new_data])# 根据key列和时间戳列去重,保留最新的记录updated_data = combined_data.sort_values(timestamp_column, ascending=False) \.drop_duplicates(subset=[key_column], keep='first')return updated_data# 示例使用
existing_data = pd.DataFrame({'id': [1, 2, 3],'value': [100, 200, 300],'last_updated': ['2023-01-01', '2023-01-02', '2023-01-03']
})new_data = pd.DataFrame({'id': [2, 4],'value': [250, 400],'last_updated': ['2023-01-04', '2023-01-04']
})result = incremental_update(existing_data, new_data, 'id', 'last_updated')
print(result)
这个例子展示了如何使用Pandas进行简单的增量更新。它合并现有数据和新数据,然后根据ID和时间戳去重,保留最新的记录。
全量更新的优势与挑战

优势
- 简单直接:实现逻辑简单,不需要复杂的变更跟踪机制。
- 数据一致性好:每次更新都是完整的数据集,降低了数据不一致的风险。
- 适合大规模重构:当数据模型发生重大变化时,全量更新更容易实现。
挑战
- 资源消耗大:每次都处理全部数据,对系统资源要求高。
- 更新时间长:特别是对于大型数据集,可能需要很长时间才能完成更新。
- 不适合频繁更新:由于更新时间长,难以实现高频率的数据刷新。
示例:全量更新实现

以下是一个全量更新的Python代码示例:
import pandas as pddef full_update(source_data, destination_table):# 清空目标表destination_table.truncate()# 将源数据全量写入目标表destination_table.append(source_data)print(f"Full update completed. {len(source_data)} records updated.")# 示例使用
source_data = pd.DataFrame({'id': [1, 2, 3, 4],'value': [100, 250, 300, 400],'last_updated': ['2023-01-01', '2023-01-04', '2023-01-03', '2023-01-04']
})destination_table = pd.DataFrame(columns=['id', 'value', 'last_updated'])full_update(source_data, destination_table)
print(destination_table)
这个例子展示了全量更新的基本逻辑:首先清空目标表,然后将源数据完整地写入。虽然实现简单,但对于大型数据集可能会非常耗时。
如何选择更新策略:决策框架

选择合适的更新策略是一个复杂的决策过程,需要考虑多个因素。以下是一个简单的决策框架:
-
数据量
- 大数据量(TB级以上):倾向于增量更新
- 小数据量:可以考虑全量更新
-
更新频率
- 高频更新(每小时或更频繁):增量更新
- 低频更新(每天或更少):全量更新可能更简单
-
数据变化率
- 高变化率(>30%数据经常变化):全量更新可能更简单
- 低变化率:增量更新更有效
-
系统资源
- 资源受限:增量更新
- 资源充足:可以考虑全量更新
-
数据一致性要求
- 极高一致性要求:可能需要全量更新
- 可以容忍短暂不一致:增量更新更灵活
-
数据模型复杂度
- 简单模型:两种方法都可以
- 复杂模型(多表关联、复杂转换):增量更新可能更具挑战性
-
历史数据需求
- 需要详细的历史记录:增量更新更适合
- 只关注当前状态:全量更新足够
-
技术栈和工具支持
- 某些工具可能更适合特定的更新策略
决策树示例
这个决策树可以帮助你快速判断应该选择哪种更新策略。但请记住,这只是一个简化的模型,实际决策可能需要考虑更多因素。
实战案例:电商订单数据更新
让我们通过一个实际的案例来深入理解增量更新和全量更新的应用。
假设我们在管理一个电商平台的订单数据仓库。每天,我们需要从交易系统中提取新的订单数据,更新到数据仓库中。订单数据包括订单ID、客户ID、订单状态、订单金额和下单时间等信息。
场景分析

- 数据量:每天约100万新订单
- 更新频率:每天一次
- 数据变化:新订单不断产生,已有订单状态可能发生变化
- 系统要求:需要支持实时报表和历史趋势分析
增量更新方案

import pandas as pd
from sqlalchemy import create_engine
from datetime import datetime, timedeltadef incremental_order_update(db_engine, last_update_time):# 从源系统获取新增和变更的订单数据query = f"""SELECT order_id, customer_id, order_status, order_amount, order_timeFROM source_ordersWHERE order_time >= '{last_update_time}'OR (order_status_update_time >= '{last_update_time}' AND order_status_update_time > order_time)"""new_orders = pd.read_sql(query, db_engine)# 更新数据仓库with db_engine.begin() as conn:# 插入新订单new_orders.to_sql('dw_orders', conn, if_exists='append', index=False)# 更新已存在的订单状态for _, row in new_orders.iterrows():conn.execute(f"""UPDATE dw_ordersSET order_status = '{row['order_status']}'WHERE order_id = {row['order_id']}""")print(f"Incremental update completed. {len(new_orders)} orders processed.")# 示例使用
db_engine = create_engine('postgresql://username:password@localhost:5432/datawarehouse')
last_update_time = datetime.now() - timedelta(days=1)
incremental_order_update(db_engine, last_update_time)
这个增量更新方案的优点是:
- 效率高:只处理新增和变更的订单
- 支持实时性要求:可以频繁执行以获取最新数据
- 保留历史记录:可以跟踪订单状态的变化
缺点是:
- 实现相对复杂:需要跟踪上次更新时间,处理状态变更
- 可能出现数据不一致:如果更新过程中断,可能导致部分数据未更新
全量更新方案
import pandas as pd
from sqlalchemy import create_enginedef full_order_update(db_engine):# 从源系统获取所有订单数据query = """SELECT order_id, customer_id, order_status, order_amount, order_timeFROM source_orders"""all_orders = pd.read_sql(query, db_engine)# 更新数据仓库with db_engine.begin() as conn:# 清空现有数据conn.execute("TRUNCATE TABLE dw_orders")# 插入所有订单all_orders.to_sql('dw_orders', conn, if_exists='append', index=False)print(f"Full update completed. {len(all_orders)} orders processed.")# 示例使用
db_engine = create_engine('postgresql://username:password@localhost:5432/datawarehouse')
full_order_update(db_engine)
全量更新方案的优点是:
- 实现简单:不需要跟踪变更
- 数据一致性好:每次都是完整的数据集
- 适合大规模重构:如果数据模型变化,容易适应
缺点是:
- 资源消耗大:每次都处理全部数据
- 更新时间长:特别是当订单数量巨大时
- 不适合频繁更新:难以满足实时性要求
选择建议
对于这个电商订单场景,增量更新可能是更好的选择,原因如下:
- 数据量大且持续增长:每天100万新订单,全量更新将变得越来越慢
- 需要支持实时报表:增量更新可以更频繁地执行,提供近实时的数据
- 历史趋势分析需求:增量更新便于保留和跟踪订单状态的历史变化
然而,我们也可以考虑结合两种方法:
- 日常使用增量更新保持数据的及时性
- 定然而,我们也可以考虑结合两种方法:
- 日常使用增量更新保持数据的及时性
- 定期(如每周或每月)执行一次全量更新,以确保数据的完整性和一致性
性能优化技巧

无论选择增量更新还是全量更新,优化性能都是至关重要的。以下是一些通用的优化技巧:
1. 索引优化
对于增量更新和全量更新,合理的索引设计都能显著提升性能。
-- 为订单表创建合适的索引
CREATE INDEX idx_order_time ON dw_orders(order_time);
CREATE INDEX idx_order_status ON dw_orders(order_status);
CREATE INDEX idx_customer_id ON dw_orders(customer_id);
2. 分区表
对于大型表,使用分区可以提高查询和更新效率。
-- 创建按日期分区的订单表
CREATE TABLE dw_orders (order_id INT,customer_id INT,order_status VARCHAR(20),order_amount DECIMAL(10,2),order_time TIMESTAMP
) PARTITION BY RANGE (order_time);-- 创建每月分区
CREATE TABLE dw_orders_y2023m01 PARTITION OF dw_ordersFOR VALUES FROM ('2023-01-01') TO ('2023-02-01');CREATE TABLE dw_orders_y2023m02 PARTITION OF dw_ordersFOR VALUES FROM ('2023-02-01') TO ('2023-03-01');-- ... 其他月份的分区
3. 批量处理
对于增量更新,采用批量处理可以减少数据库操作次数,提高效率。
def batch_incremental_update(db_engine, batch_size=1000):last_processed_id = 0while True:# 获取一批数据batch = pd.read_sql(f"""SELECT * FROM source_ordersWHERE order_id > {last_processed_id}ORDER BY order_idLIMIT {batch_size}""", db_engine)if batch.empty:break# 处理这批数据with db_engine.begin() as conn:batch.to_sql('dw_orders', conn, if_exists='append', index=False)last_processed_id = batch['order_id'].max()print(f"Processed batch up to order_id {last_processed_id}")
4. 并行处理
利用多线程或分布式计算框架可以显著提升处理速度,特别是对于全量更新。
from concurrent.futures import ThreadPoolExecutor
import pandas as pddef update_partition(partition_date, db_engine):query = f"""SELECT * FROM source_ordersWHERE order_time >= '{partition_date}' AND order_time < '{partition_date + timedelta(days=1)}'"""partition_data = pd.read_sql(query, db_engine)with db_engine.begin() as conn:partition_data.to_sql(f'dw_orders_{partition_date.strftime("%Y%m%d")}', conn, if_exists='replace', index=False)def parallel_full_update(db_engine, start_date, end_date):dates = pd.date_range(start_date, end_date)with ThreadPoolExecutor(max_workers=4) as executor:executor.map(lambda date: update_partition(date, db_engine), dates)# 使用示例
start_date = datetime(2023, 1, 1)
end_date = datetime(2023, 12, 31)
parallel_full_update(db_engine, start_date, end_date)
常见陷阱与解决方案

在实施增量更新和全量更新时,有一些常见的陷阱需要注意:
1. 死锁问题
陷阱:在高并发环境下,增量更新可能导致死锁。
解决方案:
- 使用乐观锁替代悲观锁
- 合理设置事务隔离级别
- 对大型更新操作进行分批处理
def safe_incremental_update(db_engine, data):with db_engine.begin() as conn:for _, row in data.iterrows():while True:try:conn.execute("""UPDATE dw_ordersSET order_status = %sWHERE order_id = %s AND update_time < %s""", (row['order_status'], row['order_id'], row['update_time']))breakexcept sqlalchemy.exc.OperationalError as e:if 'deadlock detected' in str(e):print(f"Deadlock detected for order {row['order_id']}, retrying...")time.sleep(0.1) # 短暂休眠后重试else:raise
2. 数据不一致
陷阱:增量更新过程中断可能导致数据不一致。
解决方案:
- 实现事务机制,确保更新的原子性
- 使用检查点机制,记录更新进度
- 定期进行全量校验
def incremental_update_with_checkpoint(db_engine, batch_size=1000):checkpoint = get_last_checkpoint() # 从某个存储中获取上次的检查点while True:batch = get_next_batch(checkpoint, batch_size) # 获取下一批数据if not batch:breaktry:with db_engine.begin() as conn:update_data(conn, batch) # 更新数据update_checkpoint(conn, batch[-1]['id']) # 更新检查点except Exception as e:print(f"Error occurred: {e}. Rolling back to last checkpoint.")# 错误发生时回滚到上一个检查点# 更新完成后进行全量校验validate_data_consistency(db_engine)
3. 性能瓶颈
陷阱:随着数据量增长,更新操作可能变得越来越慢。
解决方案:
- 优化数据库模式和索引
- 实现增量更新和全量更新的混合策略
- 考虑使用列式存储或其他适合大数据的存储方案
def hybrid_update_strategy(db_engine):current_time = datetime.now()# 每天执行增量更新if current_time.hour == 1: # 假设在每天凌晨1点执行incremental_update(db_engine)# 每周日执行全量更新if current_time.weekday() == 6 and current_time.hour == 2:full_update(db_engine)# 每月最后一天执行数据校验last_day_of_month = (current_time.replace(day=1) + timedelta(days=32)).replace(day=1) - timedelta(days=1)if current_time.date() == last_day_of_month.date() and current_time.hour == 3:validate_data_consistency(db_engine)
未来趋势:实时数据更新
随着技术的发展,实时数据处理正成为一种新的趋势。这种方法可以看作是增量更新的极致形式,它能够在数据生成的瞬间就进行处理和更新。
实时更新的优势
- 极低的延迟:数据几乎可以实时反映在报表和分析中。
- 资源利用更均匀:避免了传统批处理方式的资源使用峰值。
- 更好的用户体验:为基于数据的实时决策提供支持。
实现实时更新的技术
- 流处理框架:如Apache Kafka、Apache Flink等。
- 变更数据捕获(CDC):直接从数据库事务日志中捕获变更。
- 内存数据网格:如Apache Ignite,提供内存中的数据处理能力。
示例:使用Kafka实现实时更新
from kafka import KafkaConsumer
from json import loadsconsumer = KafkaConsumer('order_topic',bootstrap_servers=['localhost:9092'],auto_offset_reset='earliest',enable_auto_commit=True,group_id='order-processing-group',value_deserializer=lambda x: loads(x.decode('utf-8'))
)def process_order(order):# 处理订单数据with db_engine.begin() as conn:conn.execute("""INSERT INTO dw_orders (order_id, customer_id, order_status, order_amount, order_time)VALUES (%s, %s, %s, %s, %s)ON CONFLICT (order_id) DO UPDATESET order_status = EXCLUDED.order_status,order_amount = EXCLUDED.order_amount""", (order['order_id'], order['customer_id'], order['order_status'], order['order_amount'], order['order_time']))for message in consumer:order = message.valueprocess_order(order)
这个例子展示了如何使用Kafka消费者来实时处理订单数据。每当有新的订单或订单状态变更时,都会立即反映到数据仓库中。
然而,实时更新也带来了新的挑战:
- 系统复杂性增加:需要管理和维护实时处理管道。
- 一致性保证更困难:在分布式系统中确保数据一致性变得更加复杂。
- 错误处理和恢复:实时系统需要更健壮的错误处理机制。
因此,在决定是否采用实时更新策略时,需要权衡其带来的好处和增加的复杂性。
结论

选择增量更新还是全量更新,或是采用混合策略,没有一刀切的答案。这取决于你的具体业务需求、数据特征、系统资源和技术能力。
-
增量更新适合数据量大、变化频繁、需要近实时更新的场景。它能提供更好的性能和更低的资源消耗,但实现复杂度较高。
-
全量更新适合数据量较小、变化不频繁、对一致性要求高的场景。它实现简单,确保数据完整性,但对大型数据集可能效率较低。
-
混合策略结合了两者的优点,可以在日常使用增量更新,定期进行全量更新和数据校验。
-
实时更新是未来的趋势,适合对数据时效性要求极高的场景,但也带来了更高的系统复杂性。
在实际应用中,建议从以下几个方面来做出选择:
- 评估数据特征:包括数据量、更新频率、变化程度等。
- 分析业务需求:考虑数据时效性、一致性、历史追溯等需求。
- 权衡系统资源:评估可用的计算资源、存储容量和网络带宽。
- 考虑技术能力:评估团队实现和维护各种更新策略的能力。
- 进行性能测试:在实际或模拟环境中测试不同策略的性能。
- 制定监控和应急方案:无论选择哪种策略,都要有完善的监控和问题处理机制。
记住,选择更新策略不是一劳永逸的。随着业务的发展和技术的进步,你可能需要不断调整和优化你的数据更新策略。保持灵活性,定期评估和改进,才能确保你的数据仓库始终高效可靠地支持业务需求。
相关文章:
数据仓库系列13:增量更新和全量更新有什么区别,如何选择?
你是否曾经在深夜加班时,面对着庞大的数据仓库,思考过这样一个问题:“我应该选择增量更新还是全量更新?” 这个看似简单的选择,却可能影响整个数据处理的效率和准确性。今天,让我们深入探讨这个数据仓库领域…...
)
数据 结构(内核链表)
一、内核链表(是一个有头双向循环链表) 1.内核提供的两个宏 (1) offsetof : 获取结构体成员到结构体开头的偏移量; (2) contianer_of : 通过偏移量获取结构体首地址; 2.代码示例: truct passager *create_passage…...

学习node.js十三,文件的上传于下载
文件上传 文件上传的方案: 大文件上传:将大文件切分成较小的片段(通常称为分片或块),然后逐个上传这些分片。这种方法可以提高上传的稳定性,因为如果某个分片上传失败,只需要重新上传该分片而…...

【刷题笔记】删除并获取最大点数粉刷房子
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 题目一 题目链接:删除并获取最大点数 思路: 预处理状态表示 状态转移方程 代码如下: class Solution { public:int deleteAndEarn(vector<int>& nums) {int N1…...

【Linux 从基础到进阶】Elasticsearch 搜索服务安装与调优
Elasticsearch 搜索服务安装与调优 引言 Elasticsearch 是一个分布式的、基于 RESTful API 的搜索和分析引擎,专为快速处理大量数据而设计。它经常被用来进行全文搜索、日志和指标分析等操作。本文将介绍如何在 CentOS 和 Ubuntu 系统上安装 Elasticsearch,并进行必要的调优…...

IMU助力JAXA空间站机器人
近日,日本宇宙航空研究开发机构(JAXA)宣布,在国际空间站(ISS)实验舱“希望号”(Kibo)上部署的一款移动摄像机器人将采用Epson M-G370系列惯性测量单元(IMU)。…...

java开发,记录一些注解和架构
最近接了一个项目,说是项目其实也不算是项目,因为是把这个项目赛到其他项目中的。 熟悉一些这个项目的功能,梳理了一下,在代码开发中主要关心pojo、entity、respository、controller、service。 在这里主要记录前3个的流程与作用…...

【2024高教社杯全国大学生数学建模竞赛】B题 生产过程中的决策问题——解题思路 代码 论文
目录 问题 1:抽样检测方案的设计问题 2:生产过程中的决策问题 3:多工序、多零配件的生产决策问题 4:重新分析次品率题目难度分析1. 统计检测方案设计的复杂性(问题 1)2. 多阶段生产决策的复杂性(…...

JUnit 5和Mockito进行单元测试!
1. JUnit 5 基础 JUnit 5是最新的JUnit版本,它引入了许多新特性,包括更灵活的测试实例生命周期、参数化测试、更丰富的断言和假设等。 1.1 基本注解 Test:标记一个方法为测试方法。 BeforeEach:在每个测试方法之前执行。 AfterEac…...

LeetCode 算法:完全平方数 c++
原题链接🔗:完全平方数难度:中等⭐️⭐️ 题目 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的…...

深入CSS 布局——WEB开发系列29
CSS 页面布局技术允许我们拾取网页中的元素,并且控制它们相对正常布局流、周边元素、父容器或者主视口/窗口的位置。 一、正常布局流(Normal Flow) CSS的布局基础是“正常流”,也就是页面元素在没有特别指定布局方式时的默认排列…...

视频的容器格式和编码格式详解
视频的容器格式和编码格式是视频文件的两个核心概念,它们相互关联但具有不同的功能。以下是详细的解释: 1. 容器格式 (Container Format) 容器格式,又称封装格式,指的是视频文件的外壳或容器,它用于封装视频、音频、…...
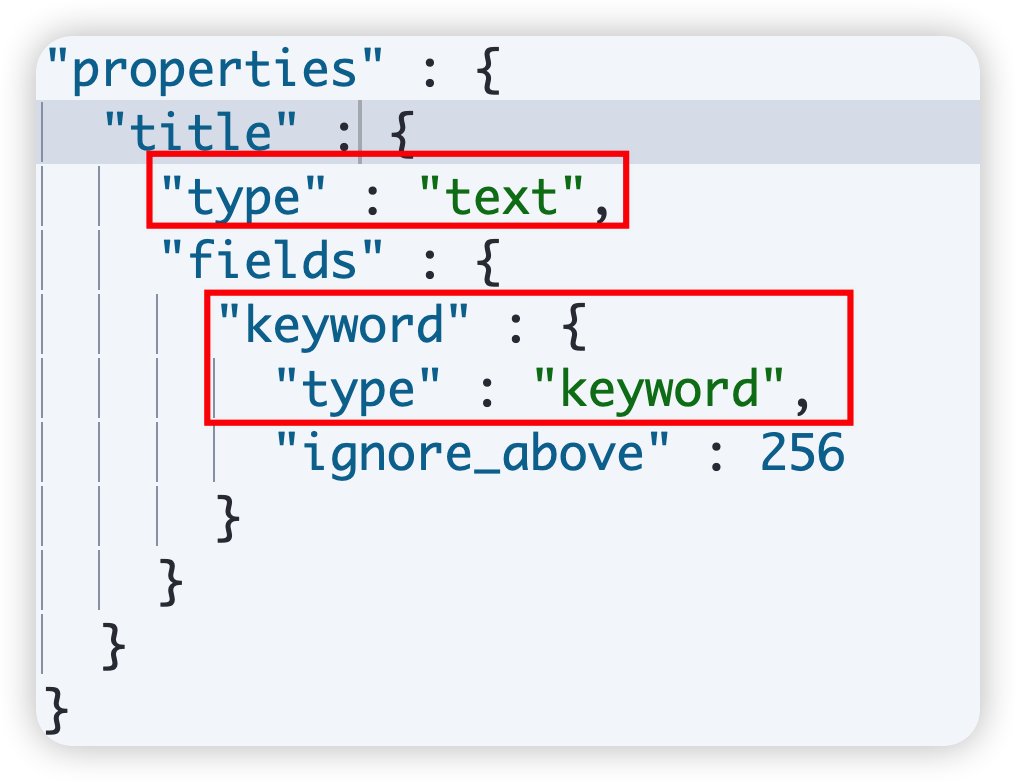
Elasticsearch Mapping 详解
1 概述 映射的基本概念 Mapping 也称之为映射,定义了 ES 的索引结构、字段类型、分词器等属性,是索引必不可少的组成部分。 ES 中的 mapping 有点类似与DB中“表结构”的概念,在 MySQL 中,表结构里包含了字段名称,字…...

WPF 利用视觉树获取指定名称对象、指定类型对象、以及判断是否有验证错误
1.利用视觉树获取指定名称对象 /// <summary> /// Finds a Child of a given item in the visual tree. /// </summary> /// <param name"parent">A direct parent of the queried item.</param> /// <typeparam name"T">T…...
`, `sub()`, `subn()`方法的作用)
了解`re`模块的`split()`, `sub()`, `subn()`方法的作用
在Python中,re模块(即正则表达式模块)提供了强大的字符串处理能力,允许你通过模式匹配来执行复杂的文本搜索、替换和分割等操作。其中,split(), sub(), 和 subn() 方法是re模块中非常实用的几个函数,它们各…...

机器学习交通流量预测实现方案
机器学习交通流量预测实现方案 实现方案 1. 数据预处理 2. 模型选择 3. 模型训练与评估 代码实现 代码解释 小结 🎈边走、边悟🎈迟早会好 交通流量预测是机器学习在智能交通系统中的典型应用,通常用于预测道路上的车辆流量、速度和拥…...

QNN:基于QNN+example重构之后的yolov8det部署
QNN是高通发布的神经网络推理引擎,是SNPE的升级版,其主要功能是: 完成从Pytorch/TensorFlow/Keras/Onnx等神经网络框架到高通计算平台的模型转换; 完成模型的低比特量化(int8),使其能够运行在高…...

Redis实战宝典:开发规范与最佳实践
目录标题 Key命名设计:可读性、可管理性、简介性Value设计:拒绝大key控制Key的生命周期:设定过期时间时间复杂度为O(n)的命令需要注意N的数量禁用命令:KEYS、FLUSHDB、FLUSHALL等不推荐使用事务删除大key设置合理的内存淘汰策略使…...

RPC的实现原理架构
RPC(Remote Procedure Call,远程过程调用)是一种允许程序调用位于不同地址空间或网络上的函数或方法的技术,尽管这些调用看起来像是本地调用。RPC 的实现极大地简化了分布式系统中的通信,避免了开发人员直接处理底层网…...

OpenXR Monado Hello_xr提交Frame
OpenXR Monado Hello_xr提交Frame @src/tests/hello_xr/openxr_program.cpp RenderFrame())xrWaitFrame(m_session, &frameWaitInfo, &frameState)xrBeginFrame(m_session, &frameBeginInfo)std::vector<XrCompositionLayerBaseHeader*> layers;std::vecto…...

Linux I/O 演进史:从管道到零拷贝,一篇串起个服务端核心原语孛
前言 在使用 kubectl get $KIND -o yaml 查看 k8s 资源时,输出结果中包含大量由集群自动生成的元数据(如 managedFields、resourceVersion、uid 等)。这些信息在实际复用 yaml 清单时需要手动清理,增加了额外的工作量。 使用 kube…...

2026 行李箱横评|5 款实测数据,百元到千元怎么选
行李箱是高频出行的 “移动小家”,但不少人都踩过坑:轮子异响推一路吵一路、拉杆晃动装满就晃悠、箱体开裂托运一次就报废。2026 年出行旺季将至,结合 5 款热门品牌实测数据,从材质、轮子、锁具 3 大核心维度拆解,帮你…...

Pebblebee Halo:追踪标签与个人安全的创新融合
兼具追踪与安全的多功能神器Pebblebee Halo 作为 Safe Haven 系列的首款产品,将追踪与个人安全功能完美融合。它不仅是一个传统的追踪标签,兼容 Apple 的 Find My 和 Google 的 Find Hub,能在地图上显示位置,蓝牙追踪范围在理想条…...

英伟达 Blackwell Ultra 正式量产:20 PFLOPS 单机柜算力
前言4月7日,英伟达正式宣布 Blackwell Ultra(GB300)量产出货。这条消息在技术圈炸开的速度,比很多人预期的快。简单说数字:单机柜 FP8 算力 20 PFLOPS,比 H100 提升约 8 倍,能效比提升 5 倍。这…...

终极MFE-starter缓存策略指南:Service Worker与浏览器缓存优化全解析
终极MFE-starter缓存策略指南:Service Worker与浏览器缓存优化全解析 【免费下载链接】MFE-starter MFE Starter 项目地址: https://gitcode.com/gh_mirrors/mf/MFE-starter MFE-starter作为现代前端微服务架构的开发利器,其缓存策略直接影响应用…...

揭秘书匠策AI:课程论文写作的“智慧魔法棒”
在学术的奇妙旅程中,课程论文宛如一座座等待攀登的小山峰,既充满挑战,又蕴含着成长的机遇。对于众多初涉学术领域的学生而言,从构思选题到搭建框架,再到填充内容与精心打磨,每一步都可能伴随着困惑与迷茫。…...

网络爬虫是自动从互联网上采集数据的程序网络爬虫是自动从互联网上采集数据的程序,Python凭借其丰富的库生态系统和简洁语法,成为了爬虫开发的首选语言。本文将全面介绍
网络爬虫是自动从互联网上采集数据的程序网络爬虫是自动从互联网上采集数据的程序,Python凭借其丰富的库生态系统和简洁语法,成为了爬虫开发的首选语言。本文将全面介绍如何使用Python构建高效、合规的网络爬虫。一、爬虫基础与工作原理 网络爬虫本质上是…...

FigmaCN实战指南:3步实现Figma界面全中文化,提升设计师工作效率70%
FigmaCN实战指南:3步实现Figma界面全中文化,提升设计师工作效率70% 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN FigmaCN是一款专为中文设计师打造的开源浏览器…...

QWEN-AUDIO语音合成教程:中文四声调建模对自然度的关键影响
QWEN-AUDIO语音合成教程:中文四声调建模对自然度的关键影响 你有没有遇到过这样的语音合成效果?文字念得都对,但听起来就是“怪怪的”,像机器人在念稿,没有真人说话的那种抑扬顿挫和情感起伏。尤其是在说中文的时候&a…...

开源能源管理实战指南:从零开始掌握OpenEMS系统应用
开源能源管理实战指南:从零开始掌握OpenEMS系统应用 【免费下载链接】openems OpenEMS - Open Source Energy Management System 项目地址: https://gitcode.com/gh_mirrors/op/openems OpenEMS(开源能源管理系统)作为一款模块化的能源…...