5.sklearn-朴素贝叶斯算法、决策树、随机森林
文章目录
- 环境配置(必看)
- 头文件引用
- 1.朴素贝叶斯算法
- 代码
- 运行结果
- 优缺点
- 2.决策树
- 代码
- 运行结果
- 决策树可视化图片
- 优缺点
- 3.随机森林
- 代码
- RandomForestClassifier()
- 运行结果
- 总结
- 本章学习资源
环境配置(必看)
Anaconda-创建虚拟环境的手把手教程相关环境配置看此篇文章,本专栏深度学习相关的版本和配置,均按照此篇文章进行安装。
头文件引用
from sklearn.datasets import load_iris, fetch_20newsgroups
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction import DictVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
import pandas as pd
1.朴素贝叶斯算法
查看存放数据集的路径(手动下载数据集存放在这个路径下)
print(sklearn.datasets.get_data_home())
参考这篇文章进行的数据集的适配–
sklearn的英文20新闻数据集fetch_20newsgroups在MAC电脑上的加载
我的电脑是win10,最终修改的路径为:
archive_path = 'C:/Users/asus/scikit_learn_data/20news_home/20news-bydate.tar.gz'
代码
调参:
MultinomialNB()默认的alpha=1,但是准确率只有84%,设置为alpha=0.01,准确率有很大提高
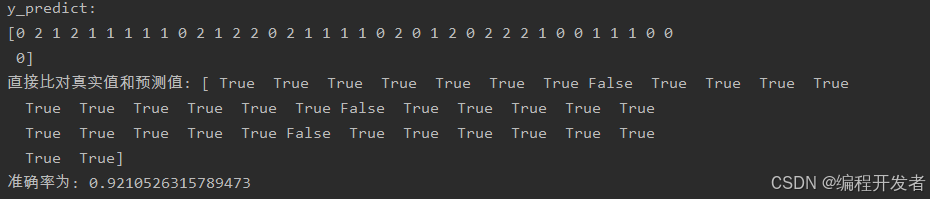
def nb_news():"""用朴素贝叶斯算法对新闻进行分类:return:"""# 1)获取数据# subset参数 默认是获取训练集,如果训练集和目标集都要就是subset='all'news = fetch_20newsgroups(subset='all')# 2)划分数据集 random_state=10x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)# 3)特征工程:文本特征抽取transfer = TfidfVectorizer()# 抽取训练集和测试集的特征值x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4)朴素贝叶斯算法算法预估器流程estimator = MultinomialNB(alpha=0.01)estimator.fit(x_train, y_train)# 5.模型评估# 方法1: 直接比对真实值和预测值y_predict = estimator.predict(x_test)print(f"y_predict:\n{y_predict}")print(f"直接比对真实值和预测值: {y_test == y_predict}")# 方法2: 计算准确率score = estimator.score(x_test, y_test)print(f"准确率为: {score}")
运行结果

优缺点
优点:对缺失数据不太敏感,算法也比较简单,常用于文本分类。分类准确度高,速度快
缺点:由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好
2.决策树
代码
def decision_iris():"""用决策树对鸢尾花进行分类:return:"""# 1.获取数据集iris = load_iris()# 2.划分数据集x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)# 3.决策树预估器estimator = DecisionTreeClassifier()estimator.fit(x_train, y_train)# 4.模型评估# 方法1: 直接比对真实值和预测值y_predict = estimator.predict(x_test)print(f"y_predict:\n{y_predict}")print(f"直接比对真实值和预测值: {y_test == y_predict}")# 方法2: 计算准确率score = estimator.score(x_test, y_test)print(f"准确率为: {score}")# 可视化决策树 feature_names=iris.feature_names 传输特征名字显示在结构图中plot_tree(estimator, feature_names=iris.feature_names)# 保存决策树可视化结构图片plt.savefig("tree_struct.png")# 显示图像plt.show()
运行结果
决策树可视化图片
petal_width(cm): 花瓣宽度
entropy: 信息增益
samples:样本 (第一个框:150*0.75≈112)
value:每个类别中有多少个符合条件的元素

优缺点
优点:简单的理解和解释,树木可视化。
缺点:决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合。
改进:减枝cart算法随机森林(集成学习的一种)
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
3.随机森林
代码
def random_forest():"""随机森林对泰坦尼克号乘客的生存进行预测:return:"""# 1.获取数据集titanic = pd.read_csv("titanic.csv")# 筛选特征值和目标值x = titanic[["pclass", "age", "sex"]]y = titanic["survived"]# 2.数据处理# 1) 缺失值处理x["age"].fillna(x["age"].mean(), inplace=True)# 2) 转换成字典x = x.to_dict(orient="records")# 3.划分数据集 random_state=10x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)# 4.字典特征抽取transfer = DictVectorizer()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 5.算法预估器estimator = RandomForestClassifier()# 加入网格搜索和交叉验证# 参数准备 "max_depth" 最大深度param_dict = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]} # 网格搜索# cv=10 代表10折运算(交叉验证)estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)estimator.fit(x_train, y_train)# 6.模型评估# 方法1: 直接比对真实值和预测值y_predict = estimator.predict(x_test)print(f"y_predict:\n{y_predict}")print(f"直接比对真实值和预测值: {y_test == y_predict}")# 方法2: 计算准确率score = estimator.score(x_test, y_test)print(f"准确率为: {score}")# 最佳参数:print("最佳参数: \n", estimator.best_params_)# 最佳结果:print("最佳结果: \n", estimator.best_score_)# 最佳参数:print("最佳估计器: \n", estimator.best_estimator_)# 交叉验证结果:print("交叉验证结果: \n", estimator.cv_results_)
RandomForestClassifier()

运行结果


总结
能够有效地运行在大数据集上,
处理具有高维特征的输入样本,而且不需要降维
本章学习资源
黑马程序员3天快速入门python机器学习我是跟着视频进行的学习,欢迎大家一起来学习!
相关文章:
5.sklearn-朴素贝叶斯算法、决策树、随机森林
文章目录 环境配置(必看)头文件引用1.朴素贝叶斯算法代码运行结果优缺点 2.决策树代码运行结果决策树可视化图片优缺点 3.随机森林代码RandomForestClassifier()运行结果总结 本章学习资源 环境配置(必看) Anaconda-创建虚拟环境…...

VMWARE VCENTER6.7 VCSA通过Web5480进行版本升级
VCENTER当前版本如下图 操作前先给VCENTER打一个快照,出问题可以立即回退 1、先下载VCSA镜像,并将VCSA镜像上传至DataStore中; 2、选中VCSA虚拟机,编辑配置 3、挂载新上传的VCSA镜像,一定要勾选“已连接”和“打开电源…...

GIT使用常见问题
如何安装Git? 在Windows操作系统中,可以从Git官方网站(https://git-scm.com)下载最新的Git安装程序,然后按照提示进行安装。在Mac操作系统中,可以使用Homebrew或者直接从Git官方网站下载安装程序进行安装。…...

内核链表
一、特点 灵活性 内核链表可以连接各种不同类型的数据结构,因为它只包含指向下一个和上一个节点的指针,不依赖特定的数据类型,这使得内核开发者可以根据不同的需求灵活地使用它。你可以将不同类型的结构体通过内核链表连接起来,实…...
行空板上YOLO和Mediapipe视频物体检测的测试
Introduction 经过前面三篇教程帖子(yolov8n在行空板上的运行(中文),yolov10n在行空板上的运行(中文),Mediapipe在行空板上的运行(中文))的介绍,…...

【Spring Boot 3】【Web】ProblemDetail
【Spring Boot 3】【Web】ProblemDetail 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...

市占率最高的显示器件,TFT_LCD的驱动系统设计--Part 1
目录 一、简介 二、TFT-LCD驱动系统概述 (一)系统概述 (二)设计要点 二、扫描驱动电路设计 (一)概述 扫描驱动电路的功能 扫描驱动电路的组成部分 设计挑战 驱动模式 (二)…...

Linux基础 -- 获取CPU负载信息
Linux Kernel 获取当前负载情况 本文档介绍了如何在 Linux 内核中获取系统的负载情况。我们将从用户态程序、内核模块开发等角度展示相关方法。 1. 通过 /proc/loadavg 文件获取负载 /proc/loadavg 文件包含了系统的负载信息,通常包括过去 1 分钟、5 分钟和 15 分…...

Django 中的用户界面 - 创建速度计算器
在 Django 中创建一个用户界面来计算速度,可以通过以下步骤完成。这个速度计算器将允许用户输入距离和时间,计算并显示速度。 一、问题背景 一位 Django 新手希望使用 Django 构建一个用户界面,以便能够计算速度(速度 距离/时间…...
spring security 如何解决跨域的
一、什么是 CORS CORS(Cross-Origin Resource Sharing) 是由 W3C制定的一种跨域资源共享技术标准,其目就是为了解决前端的跨域请求。在JavaEE 开发中,最常见的前端跨域请求解决方案是早期的JSONP,但是JSONP 只支持 GET 请求,这是一…...

日志系统前置知识
日志:程序运行过程中所记录的程序运行状态信息。通过这些信息,以便于程序员能够随时根据状态信息,对系统的运行状态进行分析。功能:能够让用户非常简便的进行日志的输出以及控制。 同步写日志 同步日志是指当输出日志时ÿ…...

【Spring Boot 3】【Web】全局异常处理
【Spring Boot 3】【Web】全局异常处理 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花费…...

Dcoker 运行es
1,创建network docker network create my-network 2,docker运行es容器 docker run -d --name es-container --net my-network -p 9200:9200 -p 9300:9300 -e "discovery.typesingle-node" docker.elastic.co/elasticsearch/elasticsearch:7…...

7系列FPGA HR/HP I/O区别
HR High Range I/O with support for I/O voltage from 1.2V to 3.3V. HP High Performance I/O with support for I/O voltage from 1.2V to 1.8V. UG865:Zynq-7000 All Programmable SoC Packaging and Pinout...

sqli-labs靶场通关攻略(五十一到六十关)
sqli-labs-master靶场第五十一关 步骤一,尝试输入?sort1 我们发现这关可以报错注入 步骤二,爆库名 ?sort1 and updatexml(1,concat(0x7e,database(),0x7e),1)-- 步骤三,爆表名 ?sort1 and updatexml(1,concat(0x7e,(select group_conc…...
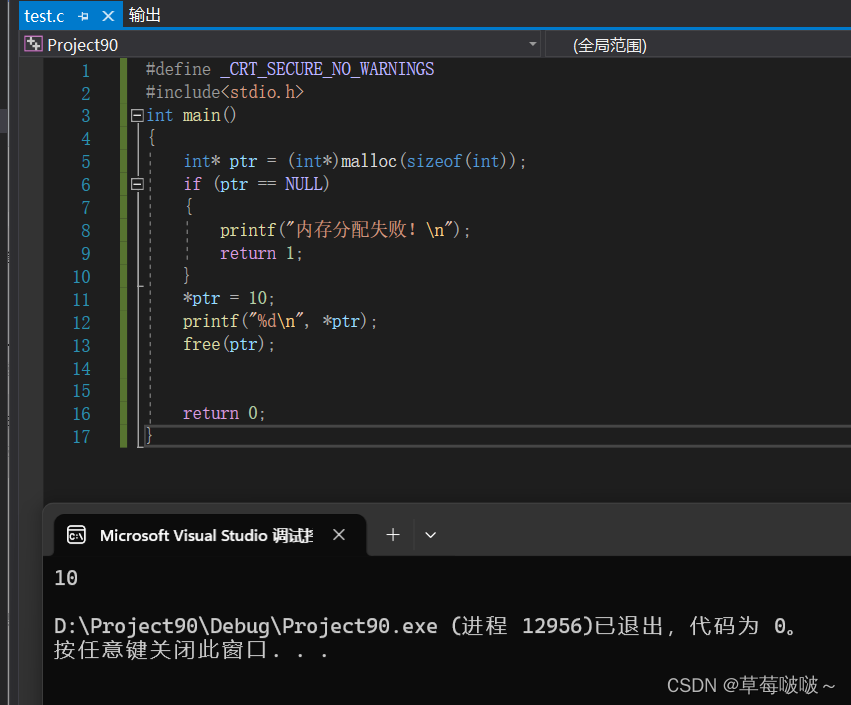
c语言中的动态内存管理
在 C 语言中,动态内存管理主要通过以下几个函数实现: 一、malloc 函数 功能: malloc 函数用于在内存的动态存储区中分配一块长度为 size 字节的连续区域。函数返回一个指向分配区域起始地址的指针,如果分配失败则回 NULL 示例: …...
生信机器学习入门4 - scikit-learn训练逻辑回归(LR)模型和支持向量机(SVM)模型
通过逻辑回归(logistic regression)建立分类模型 1.1 逻辑回归可视化和条件概率 激活函数 (activation function): 一种函数(如 ReLU 或 S 型函数),用于对上一层的所有输入进行求加权和,然后生…...

COD论文笔记 Adaptive Guidance Learning for Camouflaged Object Detection
论文的主要动机、现有方法的不足、拟解决的问题、主要贡献和创新点如下: 动机: 论文的核心动机是解决伪装目标检测(COD)中的挑战性任务。伪装目标检测旨在识别和分割那些在视觉上与周围环境高度相似的目标,这对于计算…...

9.5LeetCode
80.删除有序数组重复项II 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的…...

数据仓库系列13:增量更新和全量更新有什么区别,如何选择?
你是否曾经在深夜加班时,面对着庞大的数据仓库,思考过这样一个问题:“我应该选择增量更新还是全量更新?” 这个看似简单的选择,却可能影响整个数据处理的效率和准确性。今天,让我们深入探讨这个数据仓库领域…...

PowerToys MeasureTool:让屏幕测量变得如此简单,设计师必备的免费神器
PowerToys MeasureTool:让屏幕测量变得如此简单,设计师必备的免费神器 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/Gi…...

2025届必备的AI学术网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于内容创作里,要是过度去依赖AIGC,那么便兴许会致使文本欠缺人性化的…...

OpCore Simplify:黑苹果EFI配置效率提升80%的自动化方案 | 全层次用户指南
OpCore Simplify:黑苹果EFI配置效率提升80%的自动化方案 | 全层次用户指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 问题࿱…...

OpenClaw备份恢复方案:千问3.5-35B-A3B-FP8任务配置的迁移技巧
OpenClaw备份恢复方案:千问3.5-35B-A3B-FP8任务配置的迁移技巧 1. 为什么需要备份OpenClaw配置 上周我的主力开发机突然硬盘故障,导致所有数据丢失。最让我痛心的不是代码,而是精心调校了三个月的OpenClaw自动化工作流——包括对接千问3.5模…...

别再踩坑了!SQL Server数据类型那点事儿,看懂这篇少背三个锅厣
从0构建WAV文件:读懂计算机文件的本质 虽然接触计算机有一段时间了,但是我的视野一直局限于一个较小的范围之内,往往只能看到于算法竞赛相关的内容,计算机各种文件在我看来十分复杂,认为构建他们并能达到目的是一件困难…...
)
[PL2303老芯片兼容性困境]:驱动适配方案实现设备激活(适用于工业控制与嵌入式开发场景)
[PL2303老芯片兼容性困境]:驱动适配方案实现设备激活(适用于工业控制与嵌入式开发场景) 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 …...

好写作AI毕业论文功能揭秘:为什么用了AI反而不会写了?因为你忽略了最关键的三个字
当别人还在用AI替代思考的时候,聪明人已经把AI变成了学术教练。 ——大家好,我是教论文写作的XX老师。今天不教你“用什么”,而教你怎么“用对”。 先问你一个问题:你用AI写过论文吗? 如果你用过,你可能会…...

设计方案:核心框架搭建与落地实操全指南
当前很多团队在输出设计方案时容易陷入两个极端:要么过度追求创意忽略落地可行性,导致方案最终停留在概念阶段无法产生实际价值;要么完全照搬模板缺乏针对性,无法匹配业务的个性化需求。尤其是电商、新媒体、企业服务等领域的设计…...

收藏!小白程序员必学:RAG轻松玩转大模型,告别幻觉知识库问答不再难!
本文详细介绍了RAG(检索增强生成)技术的核心定义与价值,它通过结合大语言模型与信息检索技术,有效解决大模型“幻觉”、知识过时、专属知识库无法接入等问题。文章拆解了RAG的全流程,包括数据预处理(分片、…...
)
前端新手天天踩坑?安全老兵带你彻底搞懂HTML“路径引用”与“跳转陷阱”(附实战代码)
我平时在做代码审计和渗透测试时,经常会碰到一类让人哭笑不得的低级Bug:本地测试好好的图片,一部署到服务器上就全部裂开;别人点击网页上的链接,直接报404找不到页面。 这些问题归根结底,都是因为新手没有彻底搞懂 HTML 的**路径(Path)和锚点(Anchor)**规则。很多同…...