基于BiLSTM-CRF的医学命名实体识别研究(下)模型构建
一.生成映射字典
接下来需要将每个汉字、边界、拼音、偏旁部首等映射成向量。所以,我们首先需要来构造字典,统计多少个不同的字、边界、拼音、偏旁部首等,然后再构建模型将不同的汉字、拼音等映射成不同的向量。
在prepare_data.py中自定义函数get_dict()生成映射字典。
为了训练时保证每个批次输入样本长度一致,这里补充了PAD标记变量,用于填充。同时,每个批次数据在进行填充时是以本批次中最长的句子作为标准,因此需要将句子按长度排序,每个批次数据的长度接近从而提升运算速度。
思考
在机器学习和深度学习中,测试集很可能出现新的特征,这些特征在训练集中从未出现过。比如该数据集的某个汉字、拼音或偏旁部首,在测试集中很可能第一次出现。那么,这种情况怎么解决呢?这种未登录词可以设置为低频Unknown,从而解决该问题。
此时的完整代码如下所示:
- prepare_data.py
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #进度条 pip install tqdm
#词性标注
import jieba.posseg as psg
#获取字的偏旁和拼音
from cnradical import Radical, RunOption
#删除目录
import shutil
#随机划分训练集和测试集
from random import shuffle
#遍历文件包
from glob import globtrain_dir = "train_data"#----------------------------功能:文本预处理---------------------------------
def process_text(idx, split_method=None, split_name='train'):"""功能: 读取文本并切割,接着打上标记及提取词边界、词性、偏旁部首、拼音等特征param idx: 文件的名字 不含扩展名param split_method: 切割文本方法param split_name: 存储数据集 默认训练集, 还有测试集return"""#定义字典 保存所有字的标记、边界、词性、偏旁部首、拼音等特征data = {}#--------------------------------------------------------------------# 获取句子#--------------------------------------------------------------------if split_method is None:#未给文本分割函数 -> 读取文件with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示文件路径texts = f.readlines()else:#给出文本分割函数 -> 按函数分割with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:outfile = f'data/train_data_pro/{idx}_pro.txt'print(outfile)texts = f.read()texts = split_method(texts, outfile)#提取句子data['word'] = textsprint(texts)#--------------------------------------------------------------------# 获取标签(实体类别、起始位置)#--------------------------------------------------------------------#初始时将所有汉字标记为Otag_list = ['O' for s in texts for x in s] #双层循环遍历每句话中的汉字#读取ANN文件获取每个实体的类型、起始位置和结束位置tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas读取 分隔符为tab键#0 T1 Disease 1845 1850 1型糖尿病for i in range(tag.shape[0]): #tag.shape[0]为行数tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割#print(tag_item)#存在某些实体包括两段位置区间 仅获取起始位置和结束位置cls, start, end = tag_item[0], int(tag_item[1]), int(tag_item[-1])#print(cls,start,end)#对tag_list进行修改tag_list[start] = 'B-' + clsfor j in range(start+1, end):tag_list[j] = 'I-' + cls#断言 两个长度不一致报错assert len([x for s in texts for x in s])==len(tag_list)#print(len([x for s in texts for x in s]))#print(len(tag_list))#--------------------------------------------------------------------# 分割后句子匹配标签#--------------------------------------------------------------------tags = []start = 0end = 0#遍历文本for s in texts:length = len(s)end += lengthtags.append(tag_list[start:end])start += length print(len(tags))#标签数据存储至字典中data['label'] = tags#--------------------------------------------------------------------# 提取词性和词边界#--------------------------------------------------------------------#初始标记为Mword_bounds = ['M' for item in tag_list] #边界 M表示中间word_flags = [] #词性#分词for text in texts:#带词性的结巴分词for word, flag in psg.cut(text): if len(word)==1: #1个长度词start = len(word_flags)word_bounds[start] = 'S' #单个字word_flags.append(flag)else:start = len(word_flags)word_bounds[start] = 'B' #开始边界word_flags += [flag]*len(word) #保证词性和字一一对应end = len(word_flags) - 1word_bounds[end] = 'E' #结束边界#存储bounds = []flags = []start = 0end = 0for s in texts:length = len(s)end += lengthbounds.append(word_bounds[start:end])flags.append(word_flags[start:end])start += lengthdata['bound'] = boundsdata['flag'] = flags#--------------------------------------------------------------------# 获取拼音和偏旁特征#--------------------------------------------------------------------radical = Radical(RunOption.Radical) #提取偏旁部首pinyin = Radical(RunOption.Pinyin) #提取拼音#提取拼音和偏旁 None用特殊符号替代UNKradical_out = [[radical.trans_ch(x) if radical.trans_ch(x) is not None else 'UNK' for x in s] for s in texts]pinyin_out = [[pinyin.trans_ch(x) if pinyin.trans_ch(x) is not None else 'UNK' for x in s] for s in texts]#赋值data['radical'] = radical_outdata['pinyin'] = pinyin_out#--------------------------------------------------------------------# 存储数据#--------------------------------------------------------------------#获取样本数量num_samples = len(texts) #行数num_col = len(data.keys()) #列数 字典自定义类别数 6print(num_samples)print(num_col)dataset = []for i in range(num_samples):records = list(zip(*[list(v[i]) for v in data.values()])) #压缩dataset += records+[['sep']*num_col] #每处理一句话sep分割#records = list(zip(*[list(v[0]) for v in data.values()]))#for r in records:# print(r)#最后一行sep删除dataset = dataset[:-1]#转换成dataframe 增加表头dataset = pd.DataFrame(dataset,columns=data.keys())#保存文件 测试集 训练集save_path = f'data/prepare/{split_name}/{idx}.csv'dataset.to_csv(save_path,index=False,encoding='utf-8')#--------------------------------------------------------------------# 处理换行符 w表示一个字#--------------------------------------------------------------------def clean_word(w):if w=='\n':return 'LB'if w in [' ','\t','\u2003']: #中文空格\u2003return 'SPACE'if w.isdigit(): #将所有数字转换为一种符号 数字训练会造成干扰return 'NUM'return w#对dataframe应用函数dataset['word'] = dataset['word'].apply(clean_word)#存储数据dataset.to_csv(save_path,index=False,encoding='utf-8')#return texts, tags, bounds, flags#return texts[0], tags[0], bounds[0], flags[0], radical_out[0], pinyin_out[0]#----------------------------功能:预处理所有文本---------------------------------
def multi_process(split_method=None,train_ratio=0.8):"""功能: 对所有文本尽心预处理操作param split_method: 切割文本方法param train_ratio: 训练集和测试集划分比例return"""#删除目录if os.path.exists('data/prepare/'):shutil.rmtree('data/prepare/')#创建目录if not os.path.exists('data/prepare/train/'):os.makedirs('data/prepare/train/')os.makedirs('data/prepare/test/')#获取所有文件名idxs = set([file.split('.')[0] for file in os.listdir('data/'+train_dir)])idxs = list(idxs)#随机划分训练集和测试集shuffle(idxs) #打乱顺序index = int(len(idxs)*train_ratio) #获取训练集的截止下标#获取训练集和测试集文件名集合train_ids = idxs[:index]test_ids = idxs[index:]#--------------------------------------------------------------------# 引入多进程#--------------------------------------------------------------------#线程池方式调用import multiprocessing as mpnum_cpus = mp.cpu_count() #获取机器CPU的个数pool = mp.Pool(num_cpus)results = []#训练集处理for idx in train_ids:result = pool.apply_async(process_text, args=(idx,split_method,'train'))results.append(result)#测试集处理for idx in test_ids:result = pool.apply_async(process_text, args=(idx,split_method,'test'))results.append(result)#关闭进程池pool.close()pool.join()[r.get for r in results]#----------------------------功能:生成映射字典---------------------------------
#统计函数:列表、频率计算阈值
def mapping(data,threshold=10,is_word=False,sep='sep'):#统计列表data中各种类型的个数count = Counter(data)#删除之前自定义的sep换行符if sep is not None:count.pop(sep)#判断是汉字 未登录词处理 出现频率较少 设置为Unknownif is_word:#设置下列两个词频次 排序靠前count['PAD'] = 100000001 #填充字符 保证长度一致count['UNK'] = 100000000 #未知标记#降序排列data = sorted(count.items(),key=lambda x:x[1], reverse=True)#去除频率小于threshold的元素data = [x[0] for x in data if x[1]>=threshold]#转换成字典id2item = dataitem2id = {id2item[i]:i for i in range(len(id2item))}else:count['PAD'] = 100000001data = sorted(count.items(),key=lambda x:x[1], reverse=True)data = [x[0] for x in data]id2item = dataitem2id = {id2item[i]:i for i in range(len(id2item))}return id2item, item2id#生成映射字典
def get_dict():#获取所有内容all_w = [] #汉字all_bound = [] #边界all_flag = [] #词性all_label = [] #类别all_radical = [] #偏旁all_pinyin = [] #拼音#读取文件for file in glob('data/prepare/train/*.csv') + glob('data/prepare/test/*.csv'):df = pd.read_csv(file,sep=',')all_w += df['word'].tolist()all_bound += df['bound'].tolist()all_flag += df['flag'].tolist()all_label += df['label'].tolist()all_radical += df['radical'].tolist()all_pinyin += df['pinyin'].tolist()#保存返回结果 字典map_dict = {} #调用统计函数map_dict['word'] = mapping(all_w,threshold=20,is_word=True)map_dict['bound'] = mapping(all_bound)map_dict['flag'] = mapping(all_flag)map_dict['label'] = mapping(all_label)map_dict['radical'] = mapping(all_radical)map_dict['pinyin'] = mapping(all_pinyin)#字典保存内容return map_dict#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':#print(process_text('0',split_method=split_text,split_name='train'))#多线程处理文本#multi_process(split_text)#生成映射字典print(get_dict())
输出结果如下图所示:

至此,成功输出结果,包括字、边界、标记、类别、偏旁、拼音六类数据及对应的下标。比如边界共包括PAD、S、B、E、M五种,实体类型包括31种。

如果需要对生成的数据进行存储和调用,则使用如下核心代码:

输出结果为:
- ([‘PAD’, ‘S’, ‘B’, ‘E’, ‘M’], {‘PAD’: 0, ‘S’: 1, ‘B’: 2, ‘E’: 3, ‘M’: 4})
二.数据增强
接下来我们需要将这些下标转换成对应的数值,再映射成向量,模型根据向量进行训练。
第一步,创建文件data_utils.py。
- data_utils.py
我们将文件中的三个句子合并成一个句子,从而实现数据增强。同时,拼接文件前获取汉字、边界、词性、类别、偏旁、拼音对应的下标,再进行后续句子拼接操作。注意,这里的三个句子拼接在一定程度能让整个文本保持一个均匀的长度,从而分批训练的词向量长度一致,增强数据并提升运算性能。
第二步,编写相关代码。
#encoding:utf-8
import pandas as pd
import pickle
import numpy as np
from tqdm import tqdm
import os#功能:获取值对应的下标 参数为列表和字符
def item2id(data,w2i):#x在字典中直接获取 不在字典中返回UNKreturn [w2i[x] if x in w2i else w2i['UNK'] for x in data]#----------------------------功能:拼接文件---------------------------------
def get_data_with_windows(name='train'):#读取prepare_data.py生成的dict.pkl文件 存储字典{类别:下标}with open(f'data/dict.pkl', 'rb') as f:map_dict = pickle.load(f) #加载字典#存储所有数据results = []root = os.path.join('data/prepare/'+name)files = list(os.listdir(root))print(files)#['10.csv', '11.csv', '12.csv',.....]#获取所有文件 进度条for file in tqdm(files):all_data = []path = os.path.join(root, file)samples = pd.read_csv(path,sep=',')max_num = len(samples)#获取sep换行分隔符下标 -1 20 40 60sep_index = [-1]+samples[samples['word']=='sep'].index.tolist()+[max_num]#print(sep_index)#[-1, 83, 92, 117, 134, 158, 173, 200,......]#----------------------------------------------------------------------# 获取句子并将句子全部都转换成id#----------------------------------------------------------------------for i in range(len(sep_index)-1):start = sep_index[i] + 1 #0 (-1+1)end = sep_index[i+1] #20data = []#每个特征进行处理for feature in samples.columns: #访问每列#通过函数item2id获取下标 map_dict两个值(列表和字典) 获取第二个值data.append(item2id(list(samples[feature])[start:end],map_dict[feature][1]))#将每句话的列表合成all_data.append(data)#----------------------------------------------------------------------# 数据增强#----------------------------------------------------------------------#前后两个句子拼接 每个句子六个元素(汉字、边界、词性、类别、偏旁、拼音)two = []for i in range(len(all_data)-1):first = all_data[i]second = all_data[i+1]two.append([first[k]+second[k] for k in range(len(first))]) #六个元素three = []for i in range(len(all_data)-2):first = all_data[i]second = all_data[i+1]third = all_data[i+2]three.append([first[k]+second[k]+third[k] for k in range(len(first))])#返回所有结果results.extend(all_data+two+three)return results #-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':print(get_data_with_windows('train'))
此时的输出如下图所示,可以看到tqdm打印的进度条。
0%| | 0/290 [00:00<?, ?it/s]1%| | 2/290 [00:02<06:36, 1.38s/it]3%|▎ | 9/290 [00:11<06:51, 1.46s/it]13%|█▎ | 38/290 [01:08<07:01, 1.67s/it]27%|██▋ | 79/290 [03:08<11:06, 3.16s/it]45%|████▌ | 131/290 [06:39<11:56, 4.51s/it]61%|██████ | 177/290 [11:41<15:11, 8.07s/it]

三.数据准备
继续完善代码,将结果输出至文件,并定义类分批管理。
- 1.先执行get_data_with_windows(‘train’)函数拼接文件
- 2.再执行train_data = BatchManager(10, ‘train’)函数分批处理
- 3.用函数get_data_with_windows(‘test’)处理测试集数据
该部分最终完整代码如下:
- data_utils.py
#encoding:utf-8
import pandas as pd
import pickle
import numpy as np
from tqdm import tqdm
import os
import math#功能:获取值对应的下标 参数为列表和字符
def item2id(data,w2i):#x在字典中直接获取 不在字典中返回UNKreturn [w2i[x] if x in w2i else w2i['UNK'] for x in data]#----------------------------功能:拼接文件---------------------------------
def get_data_with_windows(name='train'):#读取prepare_data.py生成的dict.pkl文件 存储字典{类别:下标}with open(f'data/dict.pkl', 'rb') as f:map_dict = pickle.load(f) #加载字典#存储所有数据results = []root = os.path.join('data/prepare/'+name)files = list(os.listdir(root))print(files)#['10.csv', '11.csv', '12.csv',.....]#获取所有文件 进度条for file in tqdm(files):all_data = []path = os.path.join(root, file)samples = pd.read_csv(path,sep=',')max_num = len(samples)#获取sep换行分隔符下标 -1 20 40 60sep_index = [-1]+samples[samples['word']=='sep'].index.tolist()+[max_num]#print(sep_index)#[-1, 83, 92, 117, 134, 158, 173, 200,......]#----------------------------------------------------------------------# 获取句子并将句子全部都转换成id#----------------------------------------------------------------------for i in range(len(sep_index)-1):start = sep_index[i] + 1 #0 (-1+1)end = sep_index[i+1] #20data = []#每个特征进行处理for feature in samples.columns: #访问每列#通过函数item2id获取下标 map_dict两个值(列表和字典) 获取第二个值data.append(item2id(list(samples[feature])[start:end],map_dict[feature][1]))#将每句话的列表合成all_data.append(data)#----------------------------------------------------------------------# 数据增强#----------------------------------------------------------------------#前后两个句子拼接 每个句子六个元素(汉字、边界、词性、类别、偏旁、拼音)two = []for i in range(len(all_data)-1):first = all_data[i]second = all_data[i+1]two.append([first[k]+second[k] for k in range(len(first))]) #六个元素three = []for i in range(len(all_data)-2):first = all_data[i]second = all_data[i+1]third = all_data[i+2]three.append([first[k]+second[k]+third[k] for k in range(len(first))])#返回所有结果results.extend(all_data+two+three)#return results#数据存储至本地 每次调用时间成本过大with open(f'data/'+name+'.pkl', 'wb') as f:pickle.dump(results, f)#----------------------------功能:批处理---------------------------------
class BatchManager(object):def __init__(self, batch_size, name='train'):#调用函数拼接文件#data = get_data_with_windows(name)#读取文件with open(f'data/'+name+'.pkl', 'rb') as f:data = pickle.load(f)print(len(data)) #265455句话print(len(data[0])) #6种类别print(len(data[0][0])) #第一句包含字的数量 83print("原始数据:", data[0])#数据批处理self.batch_data = self.sort_and_pad(data, batch_size)self.len_data = len(self.batch_data)def sort_and_pad(self, data, batch_size):#计算总批次数量 26546num_batch = int(math.ceil(len(data) / batch_size))#按照句子长度排序sorted_data = sorted(data, key=lambda x: len(x[0]))batch_data = list()#获取一个批次的数据for i in range(num_batch):batch_data.append(self.pad_data(sorted_data[i*int(batch_size) : (i+1)*int(batch_size)]))print("分批输出:", batch_data[1000])return batch_data@staticmethoddef pad_data(data_):#定义变量chars = []bounds = []flags = []radicals = []pinyins = []targets = []#print("每个批次句子个数:", len(data_)) #10#print("每个句子包含元素个数:", len(data_[0])) #6#print("输出data:", data_)max_length = max([len(sentence[0]) for sentence in data_]) #值为1#print(max_length)#每个批次共有十组数据 每组数据均为六个元素for line in data_:char, bound, flag, target, radical, pinyin = linepadding = [0] * (max_length - len(char)) #计算补充字符数量#注意char和chars不要写错 否则造成递归循环赋值错误chars.append(char + padding)bounds.append(bound + padding)flags.append(flag + padding)targets.append(target + padding)radicals.append(radical + padding)pinyins.append(pinyin + padding)return [chars, bounds, flags, radicals, pinyins, targets]#每次使用一个批次数据def iter_batch(self, shuffle=False):if shuffle:random.shuffle(self.batch_data)for idx in range(self.len_data):yield self.batch_data[idx]#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':#1.拼接文件(第一次执行 后续可注释)#get_data_with_windows('train')#2.分批处理 train_data = BatchManager(10, 'train')#3.接着处理下测试集数据#get_data_with_windows('test')
原始数据及处理后的数据如下图所示:

某些Python工具能看到中间输出结果,可以看到我们的data_utils.py脚本成功将句子分批次补齐,每个批次处理为对应的10个句子 x 6个数据类型。

注:该部分老师丢失了视频,是作者结合源码进行还原,哈哈!泪奔~
四.模型构建
此时我们项目的结构图如下所示,包括:
- data:数据文件夹,prepare为预处理数据,由很多包含六元组的CSV文件组成
- train.pkl:训练集句子六元组下标
- test.pkl:测试集句子六元组下标
- data_process.py:获取实体类别及个数、BIO数据标注、长短句分割
- prepare_data.py:获取数据标签、提取六元组(字、边界、词性、类别、偏旁、拼音)
- data_utils.py:获取六元组对应的下标并进行对齐处理,后续转换词向量训练

接着让我们开始创建BiLSTM模型。
1.BiLSTM模型构建
第一步,创建模型构建脚本。
- model.py
核心代码如下,大家可以先熟悉Model类中基本的函数、变量组成。
#encoding:utf-8
"""
Created on Thu Jan 7 12:56:40 2021
@author: xiuzhang
"""
import tensorflow as tf
import numpy as np#---------------------------功能:预测计算函数-----------------------------
def network(char,bound,flag,radical,pinyin,shapes,initializer=tf.truncated_normal_initializer):"""功能:接收一个批次样本的特征数据,计算网络的输出值:param char: int, id of chars a tensor of shape 2-D [None,None]:param bound: int, a tensor of shape 2-D [None,None]:param flag: int, a tensor of shape 2-D [None,None]:param radical: int, a tensor of shape 2-D [None,None]:param pinyin: int, a tensor of shape 2-D [None,None]:param shapes: 词向量形状字典:param initializer: 初始化函数:return"""#--------------------------------------------------#特征嵌入:将所有特征的id转换成一个固定长度的向量embedding = []#五类特征转换成词向量再拼接with tf.variable_scope('char_embedding'):#获取汉字信息char_lookup = tf.get_variable(name = 'char_embedding', #名称shape = ['char'], #[num,dim] 行数(个数)*列数(向量维度)initializer = initializer)#词向量映射embedding.append(tf.nn.embedding_lookup(char_lookup,char))#-----------------------------功能:定义模型类---------------------------
class Model(object):#初始化def __init__(self, dict_):#通过dict.pkl计算各个特征数量self.num_char = len(dict_['word'][0])self.num_bound = len(dict_['bound'][0])self.num_flag = len(dict_['flag'][0])self.num_radical = len(dict_['radical'][0])self.num_pinyin = len(dict_['pinyin'][0])self.num_entity = len(dict_['label'][0])#字符映射成向量的维度self.char_dim = 100self.bound_dim = 20self.flag_dim = 50self.radical_dim = 50self.pinyin_dim = 50#shape表示为[num,dim] 行数(个数)*列数(向量维度)#定义网络 接收批次样本def get_logits(self,char,bound,flag,radical,pinyin):"""功能:接收一个批次样本的特征数据,计算网络的输出值:param char: int, id of chars a tensor of shape 2-D [None,None]:param bound: int, a tensor of shape 2-D [None,None]:param flag: int, a tensor of shape 2-D [None,None]:param radical: int, a tensor of shape 2-D [None,None]:param pinyin: int, a tensor of shape 2-D [None,None]:return"""#定义字典传参shapes = {}shapes['char'] = [self.num_char,self.char_dim]shapes['bound'] = [self.num_bound,self.bound_dim]shapes['flag'] = [self.num_flag,self.flag_dim]shapes['radical'] = [self.num_radical,self.radical_dim]shapes['pinyin'] = [self.num_pinyin,self.pinyin_dim]return network(char,bound,flag,radical,pinyin,dict_input)
第二步,我们尝试编写一个test.py脚本理解词嵌入相关知识。
- test.py
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 7 12:56:40 2021
@author: xiuzhang
"""
import tensorflow as tf
import numpy as npmatrix = np.array([[1,1,1,1,1,1],[2,2,2,2,2,2],[3,3,3,3,3,3],[4,4,4,4,4,4]
])x = np.array([[0,2,1,1,2],[3,2,0,2,2]
])#词向量转换
result = tf.nn.embedding_lookup(matrix,x)
with tf.Session() as sess:print(sess.run(result))
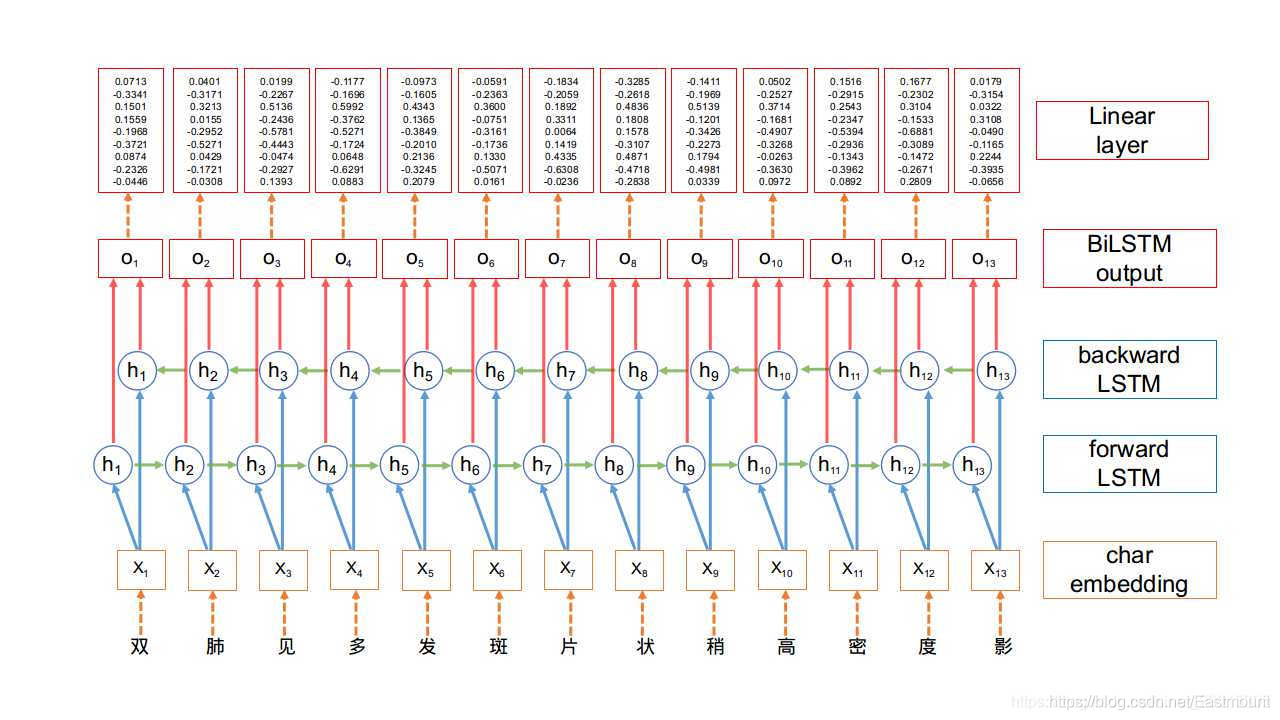
其输出结果如下图所示,它通过embedding_lookup函数将x矩阵按matrix进行词向量映射,比如[0,2,1,1,2]在matrix分别对应第一行、第三行、第二行、第二行和第四行,相当于每一个id对应一个向量,最终得到如下结果。

同样下面这个函数将char汉字进行词向量映射。
- embedding.append(tf.nn.embedding_lookup(char_lookup,char))
第三步,继续完善model.py代码。
我们尝试对参数进行修改,多个参数传递并调用同一规则函数时,可以将参数插入至字典中,从而优化代码。比如:
- 优化前
def network(char,bound,flag,radical,pinyin,shapes,initializer=…) - 优化后
def network(inputs,shapes,initializer=…)
接着定义双向LSTM神经网络,为了提高运算效率,我们需要计算输入Inputs句子的实际长度,而填充数据PAD(下标0)不计算。
完整代码如下,它将词向量输入后处理,最终返回三维矩阵,每个词做一个多分类(31种实体类别),核心函数相当于一个编码器。
- get_logits(self,char,bound,flag,radical,pinyin)
- network(inputs,shapes,num_entity,lstm_dim=100, initializer)
- [batch_size,max_length,num_entity]
#encoding:utf-8
"""
Created on Thu Jan 7 12:56:40 2021
@author: xiuzhang
"""
import tensorflow as tf
import numpy as np
from tensorflow.contrib import rnn#---------------------------功能:预测计算函数-----------------------------
def network(inputs,shapes,num_entity,lstm_dim=100,initializer=tf.truncated_normal_initializer):"""功能:接收一个批次样本的特征数据,计算网络的输出值:param char: int, id of chars a tensor of shape 2-D [None,None] 批次数量*每个批次句子长度:param bound: int, a tensor of shape 2-D [None,None]:param flag: int, a tensor of shape 2-D [None,None]:param radical: int, a tensor of shape 2-D [None,None]:param pinyin: int, a tensor of shape 2-D [None,None]:param shapes: 词向量形状字典:param lstm_dim: 神经元的个数:param num_entity: 实体标签数量 31种类型:param initializer: 初始化函数:return"""#--------------------------------------------------#特征嵌入:将所有特征的id转换成一个固定长度的向量#--------------------------------------------------embedding = []keys = list(shapes.keys())#循环将五类特征转换成词向量 后续拼接for key in keys:with tf.variable_scope(key+'_embedding'):#获取汉字信息lookup = tf.get_variable(name = key + '_embedding', #名称shape = [key], #[num,dim] 行数(个数)*列数(向量维度)initializer = initializer)#词向量映射 汉字结果[None,None,100]embedding.append(tf.nn.embedding_lookup(lookup,inputs[key]))#拼接词向量 shape[None,None,char_dim+bound_dim+flag_dim+radical_dim+pinyin_dim]embed = tf.concat(embedding,axis=-1) #最后一个维度上拼接 -1#lengths: 计算输入inputs每句话的实际长度(填充内容不计算)#填充值PAD下标为0 因此总长度减去PAD数量即为实际长度 从而提升运算效率sign = tf.sign(tf.abs(inputs[keys[0]])) #字符长度lengths = tf.reduce_sum(sign, reduction_indices=1)#获取填充序列长度 char的第二个维度num_time = tf.shape(inputs[keys[0]])[1]#--------------------------------------------------#循环神经网络编码: 双层双向网络#--------------------------------------------------#第一层with tf.variable_scope('BiLSTM_layer1'):lstm_cell = {}#第一层前向 后向for name in ['forward','backward']:with tf.varibale_scope(name): #设置名称lstm_cell[name] = rnn.BasicLSTMCell(lstm_dim, #神经元的个数initializer = initializer) #运行LSTMoutputs1,finial_states1 = tf.nn.bidirectional_dynamic_run(lstm_cell['forward'],lstm_cell['backward'],embed,dtype = tf.float32,sequence_length = lengths #序列实际长度(该参数可省略))#拼接前向LSTM和后向LSTM输出outputs1 = tf.concat(outputs1,axis=-1) #b,L,2*lstm_dim#第二层with tf.variable_scope('BiLSTM_layer2'):lstm_cell = {}#第一层前向 后向for name in ['forward','backward']:with tf.varibale_scope(name): #设置名称lstm_cell[name] = rnn.BasicLSTMCell(lstm_dim, #神经元的个数initializer = initializer)#运行LSTMoutputs,finial_states = tf.nn.bidirectional_dynamic_run(lstm_cell['forward'],lstm_cell['backward'],embed, #是否利用第一层网络dtype = tf.float32,sequence_length = lengths #序列实际长度(该参数可省略))#最终结果 [batch_size,maxlength,2*lstm_dim] 即200result = tf.concat(outputs,axis=-1)#--------------------------------------------------#输出映射#--------------------------------------------------#转换成二维矩阵 [batch_size*maxlength,2*lstm_dim]result = tf.reshape(result, [-1,2*lstm_dim])#第一层映射 矩阵乘法with tf.variable_scope('project_layer1'):#权重w = tf.get_variable(name = 'w',shape = [2*lstm_dim,lstm_dim], #转100维initializer = initializer)#biasb = tf.get_variable(name = 'w',shape = [lstm_dim],initializer = tf.zeros_initializer())#运算 激活函数reluresult = tf.nn.relu(matmul(result,w)+b)#第二层映射 矩阵乘法with tf.variable_scope('project_layer2'):#权重w = tf.get_variable(name = 'w',shape = [lstm_dim,num_entity], #31种实体类别initializer = initializer)#biasb = tf.get_variable(name = 'w',shape = [num_entity],initializer = tf.zeros_initializer())#运算 激活函数relu 最后一层不激活result = matmul(result,w)+b#形状转换成三维result = tf.reshape(result, [-1,num_time,num_entity])#[batch_size,max_length,num_entity]return result#-----------------------------功能:定义模型类---------------------------
class Model(object):#初始化def __init__(self, dict_):#通过dict.pkl计算各个特征数量self.num_char = len(dict_['word'][0])self.num_bound = len(dict_['bound'][0])self.num_flag = len(dict_['flag'][0])self.num_radical = len(dict_['radical'][0])self.num_pinyin = len(dict_['pinyin'][0])self.num_entity = len(dict_['label'][0])#字符映射成向量的维度self.char_dim = 100self.bound_dim = 20self.flag_dim = 50self.radical_dim = 50self.pinyin_dim = 50#shape表示为[num,dim] 行数(个数)*列数(向量维度)#设置LSTM的维度 神经元的个数self.lstm_dim = 100#定义网络 接收批次样本def get_logits(self,char,bound,flag,radical,pinyin):"""功能:接收一个批次样本的特征数据,计算网络的输出值:param char: int, id of chars a tensor of shape 2-D [None,None]:param bound: int, a tensor of shape 2-D [None,None]:param flag: int, a tensor of shape 2-D [None,None]:param radical: int, a tensor of shape 2-D [None,None]:param pinyin: int, a tensor of shape 2-D [None,None]:return: 返回3-d tensor [batch_size,max_length,num_entity]"""#定义字典传参shapes = {}shapes['char'] = [self.num_char,self.char_dim]shapes['bound'] = [self.num_bound,self.bound_dim]shapes['flag'] = [self.num_flag,self.flag_dim]shapes['radical'] = [self.num_radical,self.radical_dim]shapes['pinyin'] = [self.num_pinyin,self.pinyin_dim]#输入参数定义字典inputs = {}inputs['char'] = charinputs['bound'] = boundinputs['flag'] = flaginputs['radical'] = radicalinputs['pinyin'] = pinyin#return network(char,bound,flag,radical,pinyin,shapes)return network(inputs,shapes,lstm_dim=self.lstm_dim,num_entity=self.num_entity)
下面我们补充一张该图的算法流程图,基本流程:
- 首先将汉字、边界、词性、偏旁和拼音转换成词向量
- 词嵌入拼接成270维输入
- 经过两个双向LSTM,转换成200维输出结果,做31种实体类别的分类处理

模型之间的参数计算如下图所示(源自白老师),LSTM有4个门控,31是输出实体标签的数量,100表示LSTM的神经元数。

注意,我们可以查看BILSTM源码帮助学习,比如其返回值包括输出(前向&后向)和状态。

2.CRF模型融合
最终得到31个值(实体类别数)后,我们接下来需要做Softmax吗?
我们不做Softmax,我们不是要每个时刻概率最大,而是需要序列概率最大。因此接下来通过条件随机场计算损失。此时,我们每个时刻有31种选择,假设存在一个10长度的序列,它有31的10次方个组合,而真实的序列只有一种,我们的目标是让真实序列的概率在整个序列所有概率中最大。因此采用CRF模型。
下面开始撰写代码:
- model.py
重点:下面总结希望大家认真阅读
传统CRF++是通过统计学方法计算每个时刻隐状态的分值,而现在我们是通过模型network来完成的。因此该模型称为BiLSTM-CRF模型。同时,调用crf_log_likelihood()函数计算条件随机场的对数似然,如下图所示,初始时刻状态为31个概率为0(log-1000)和Start概率为1(log0)。
- BiLSTM:负责提取特征(结合上下文),每个时刻输出31个值
- CRF:负责计算隐状态分值
- 该模型与隐马尔可夫模型本质区别是计算分数方法不同,一种是基于统计学方法P(y|x),一种是基于神经网络实现(BiLSTM)。
- 最后的结果就是真实概率值在所有概率值中最大,因此条件随机场是序列归一化,对整个序列的分值做归一化处理。


此时model.py的完整代码如下:
#encoding:utf-8
"""
Created on Thu Jan 7 12:56:40 2021
@author: xiuzhang
"""
import tensorflow as tf
import numpy as np
from tensorflow.contrib import rnn
#计算条件随机场的对数似然
from tensorflow.contrib.crf import crf_log_likelihood#---------------------------功能:预测计算函数-----------------------------
def network(inputs,shapes,num_entity,lstm_dim=100,initializer=tf.truncated_normal_initializer):"""功能:接收一个批次样本的特征数据,计算网络的输出值:param char: int, id of chars a tensor of shape 2-D [None,None] 批次数量*每个批次句子长度:param bound: int, a tensor of shape 2-D [None,None]:param flag: int, a tensor of shape 2-D [None,None]:param radical: int, a tensor of shape 2-D [None,None]:param pinyin: int, a tensor of shape 2-D [None,None]:param shapes: 词向量形状字典:param lstm_dim: 神经元的个数:param num_entity: 实体标签数量 31种类型:param initializer: 初始化函数:return"""#--------------------------------------------------#特征嵌入:将所有特征的id转换成一个固定长度的向量#--------------------------------------------------embedding = []keys = list(shapes.keys())#循环将五类特征转换成词向量 后续拼接for key in keys:with tf.variable_scope(key+'_embedding'):#获取汉字信息lookup = tf.get_variable(name = key + '_embedding', #名称shape = [key], #[num,dim] 行数(个数)*列数(向量维度)initializer = initializer)#词向量映射 汉字结果[None,None,100]embedding.append(tf.nn.embedding_lookup(lookup,inputs[key]))#拼接词向量 shape[None,None,char_dim+bound_dim+flag_dim+radical_dim+pinyin_dim]embed = tf.concat(embedding,axis=-1) #最后一个维度上拼接 -1#lengths: 计算输入inputs每句话的实际长度(填充内容不计算)#填充值PAD下标为0 因此总长度减去PAD数量即为实际长度 从而提升运算效率sign = tf.sign(tf.abs(inputs[keys[0]])) #字符长度lengths = tf.reduce_sum(sign, reduction_indices=1)#获取填充序列长度 char的第二个维度num_time = tf.shape(inputs[keys[0]])[1]#--------------------------------------------------#循环神经网络编码: 双层双向网络#--------------------------------------------------#第一层with tf.variable_scope('BiLSTM_layer1'):lstm_cell = {}#第一层前向 后向for name in ['forward','backward']:with tf.varibale_scope(name): #设置名称lstm_cell[name] = rnn.BasicLSTMCell(lstm_dim, #神经元的个数initializer = initializer) #运行LSTMoutputs1,finial_states1 = tf.nn.bidirectional_dynamic_run(lstm_cell['forward'],lstm_cell['backward'],embed,dtype = tf.float32,sequence_length = lengths #序列实际长度(该参数可省略))#拼接前向LSTM和后向LSTM输出outputs1 = tf.concat(outputs1,axis=-1) #b,L,2*lstm_dim#第二层with tf.variable_scope('BiLSTM_layer2'):lstm_cell = {}#第一层前向 后向for name in ['forward','backward']:with tf.varibale_scope(name): #设置名称lstm_cell[name] = rnn.BasicLSTMCell(lstm_dim, #神经元的个数initializer = initializer)#运行LSTMoutputs,finial_states = tf.nn.bidirectional_dynamic_run(lstm_cell['forward'],lstm_cell['backward'],embed, #是否利用第一层网络dtype = tf.float32,sequence_length = lengths #序列实际长度(该参数可省略))#最终结果 [batch_size,maxlength,2*lstm_dim] 即200result = tf.concat(outputs,axis=-1)#--------------------------------------------------#输出映射#--------------------------------------------------#转换成二维矩阵 [batch_size*maxlength,2*lstm_dim]result = tf.reshape(result, [-1,2*lstm_dim])#第一层映射 矩阵乘法with tf.variable_scope('project_layer1'):#权重w = tf.get_variable(name = 'w',shape = [2*lstm_dim,lstm_dim], #转100维initializer = initializer)#biasb = tf.get_variable(name = 'w',shape = [lstm_dim],initializer = tf.zeros_initializer())#运算 激活函数reluresult = tf.nn.relu(matmul(result,w)+b)#第二层映射 矩阵乘法with tf.variable_scope('project_layer2'):#权重w = tf.get_variable(name = 'w',shape = [lstm_dim,num_entity], #31种实体类别initializer = initializer)#biasb = tf.get_variable(name = 'w',shape = [num_entity],initializer = tf.zeros_initializer())#运算 激活函数relu 最后一层不激活result = matmul(result,w)+b#形状转换成三维result = tf.reshape(result, [-1,num_time,num_entity])#[batch_size,max_length,num_entity]return result,lengths#-----------------------------功能:定义模型类---------------------------
class Model(object):#初始化def __init__(self, dict_):#通过dict.pkl计算各个特征数量self.num_char = len(dict_['word'][0])self.num_bound = len(dict_['bound'][0])self.num_flag = len(dict_['flag'][0])self.num_radical = len(dict_['radical'][0])self.num_pinyin = len(dict_['pinyin'][0])self.num_entity = len(dict_['label'][0])#字符映射成向量的维度self.char_dim = 100self.bound_dim = 20self.flag_dim = 50self.radical_dim = 50self.pinyin_dim = 50#shape表示为[num,dim] 行数(个数)*列数(向量维度)#设置LSTM的维度 神经元的个数self.lstm_dim = 100#定义网络 接收批次样本def get_logits(self,char,bound,flag,radical,pinyin):"""功能:接收一个批次样本的特征数据,计算网络的输出值:param char: int, id of chars a tensor of shape 2-D [None,None]:param bound: int, a tensor of shape 2-D [None,None]:param flag: int, a tensor of shape 2-D [None,None]:param radical: int, a tensor of shape 2-D [None,None]:param pinyin: int, a tensor of shape 2-D [None,None]:return: 返回3-d tensor [batch_size,max_length,num_entity]"""#定义字典传参shapes = {}shapes['char'] = [self.num_char,self.char_dim]shapes['bound'] = [self.num_bound,self.bound_dim]shapes['flag'] = [self.num_flag,self.flag_dim]shapes['radical'] = [self.num_radical,self.radical_dim]shapes['pinyin'] = [self.num_pinyin,self.pinyin_dim]#输入参数定义字典inputs = {}inputs['char'] = charinputs['bound'] = boundinputs['flag'] = flaginputs['radical'] = radicalinputs['pinyin'] = pinyin#return network(char,bound,flag,radical,pinyin,shapes)return network(inputs,shapes,lstm_dim=self.lstm_dim,num_entity=self.num_entity)#--------------------------功能:定义loss CRF模型-------------------------#参数: 模型输出值 真实标签序列 长度(不计算填充)def loss(self,result,targets,lengths):#获取长度b = len(lengths) #真实长度num_steps = tf.shape(result)[1] #含填充#转移矩阵with tf.variable_scope('crf_loss'):#取log相当于概率接近0small = -1000.0#初始时刻状态 两个矩阵在最后一个维度合并start_logits = tf.concat(#前31个-1000概率为0 最后一个start为0取log为1[small*tf.ones(shape=[b,1,self.num_entity]),tf.zeros(shape=[b,1,1])],axis = -1)#X值拼接 每个时刻加一个状态pad_logits = tf.cast(small*tf.ones([b,num_steps,1]),tf.float32)logits = tf.concat([result, pad_logits], axis=-1)logits = tf.concat([start_logits,logits], axis=1) #第二个位置拼接#Y值拼接targets = tf.concat([tf.cast(self.num_entity*tf.ones([b,1]),tf.int32),targets],axis = -1)#计算self.trans = tf.get_variable(name = 'trans',#初始概率start加1 最终32个shape = [self.num_entity+1,self.num_entity+1],initializer = tf.truncated_normal_initializer())#损失 计算条件随机场的对数似然 每个样本计算几个值log_likehood, self.trans = crf_log_likelihood(inputs = logits, #输入tag_indices = targets, #目标transition_params = self.trans,sequence_lengths = lengths #真实样本长度)#返回所有样本平均值 数加个负号损失最小化return tf.reduce_mean(-log_likehood)
3.初始化函数完善
继续修改Model类,在初始化init函数中增加如下功能:
- 定义接收数据的placeholder
- 调用get_logits计算模型输出结果及句子真实长度
- 调用loss计算损失值
- 定义优化器,采用梯度截断技术处理,如果导数值过大会导致步子迈得过大,造成梯度爆炸,因此限制在某个范围内(如[-5,5])
- 保存模型参数
该模型最终将270维的向量(字、边界、词性、偏旁、拼音)映射成31维向量。核心代码如下:
class Model(object):#---------------------------------------------------------#初始化def __init__(self, dict_, lr=0.0001):#通过dict.pkl计算各个特征数量self.num_char = len(dict_['word'][0])self.num_bound = len(dict_['bound'][0])self.num_flag = len(dict_['flag'][0])self.num_radical = len(dict_['radical'][0])self.num_pinyin = len(dict_['pinyin'][0])self.num_entity = len(dict_['label'][0])#字符映射成向量的维度self.char_dim = 100self.bound_dim = 20self.flag_dim = 50self.radical_dim = 50self.pinyin_dim = 50#shape表示为[num,dim] 行数(个数)*列数(向量维度)#设置LSTM的维度 神经元的个数self.lstm_dim = 100#学习率self.lr = lr#---------------------------------------------------------#定义接收数据的placeholder [None,None] 批次 句子长度self.char_inputs = tf.placeholder(dtype=tf.int32,shape=[None,None],name='char_inputs')self.bound_inputs = tf.placeholder(dtype=tf.int32,shape=[None,None],name='bound_inputs')self.flag_inputs = tf.placeholder(dtype=tf.int32,shape=[None,None],name='flag_inputs')self.radical_inputs = tf.placeholder(dtype=tf.int32,shape=[None,None],name='radical_inputs')self.pinyin_inputs = tf.placeholder(dtype=tf.int32,shape=[None,None],name='pinyin_inputs')self.targets = tf.placeholder(dtype=tf.int32,shape=[None,None],name='targets') #目标真实值self.global_step = tf.Variable(0,trainable=False) #不能训练 用于计数#---------------------------------------------------------#传递给网络 计算模型输出值#参数:输入的字、边界、词性、偏旁、拼音下标 -> network转换词向量并计算#返回:网络输出值、每句话的真实长度self.logits,self.lengths = self.get_logits(self.char_inputs,self.bound_inputs,self.flag_inputs,self.radical_inputs,self.pinyin_inputs)#---------------------------------------------------------#计算损失 #参数:模型输出值、真实标签序列、长度(不计算填充)#返回:损失值self.cost = self.loss(self.logits,self.targets,self.lengths)#---------------------------------------------------------#优化器优化 采用梯度截断技术with tf.variable_scope('optimizer'):opt = tf.train.AdamOptimizer(self.lr) #学习率#计算所有损失函数的导数值grad_vars = opt.compute_gradients(self.cost)#梯度截断-导数值过大会导致步子迈得过大 梯度爆炸(因此限制在某个范围内)#grad_vars记录每组参数导数和本身clip_grad_vars = [[tf.clip_by_value(g,-5,5),v] for g,v in grad_vars]#使用截断后的梯度更新参数 该方法每应用一次global_step参数自动加1self.train_op = opt.apply_gradients(clip_grad_vars,self.global_step)#模型保存 保留最近5次模型self.saver = tf.train.Saver(tf.global_variables(),max_to_keep=5)
4.模型训练
新建 train.py 文件,并撰写训练代码。
- 第一步,首先引入BatchManager类。我们可以用之前data_utils.py脚本定义的BatchManager直接调用处理好的训练集和测试集。
- 第二步,自定义函数读取字典dict.pkl内容,该文件存储了实体六元组。
- 第三步,引入model类搭建模型。
核心代码如下图所示,我们先尝试运行下代码:

在调试程序时,我们可以增加断点单步调试,也可以print打桩输出。比如:

(1) network模型分析
重点是观察network函数(model.py)的参数变化情况。神经网络的输出结果如下,核心功能包括:
- 调用tf.nn.embedding_lookup函数完成词向量映射
- 调用rnn.BasicLSTMCell构建LSTM网络
- 调用tf.nn.bidirectional_dynamic_rnn组合BiLSTM,两层BiLSTM
- 两层全连接层将维度转换成31,相当于做31分类(对应实体类别)
– result = tf.nn.relu(tf.matmul(result,w)+b)
– result = tf.matmul(result,w)+b
计算六元组个数
字: 1663
边界: 5
词性: 56
偏旁: 227
拼音: 989
类别: 31 """"初始化操作"""
model init: 1663 5 56 227 989 31
shapes: {'char': [1663, 100], 'bound': [5, 20], 'flag': [56, 50], 'radical': [227, 50], 'pinyin': [989, 50]}
Network Shape: ['char', 'bound', 'flag', 'radical', 'pinyin']"""词向量映射 每个字映射100维向量 [None,None,100]"""
Network Input: {'char': <tf.Tensor 'char_inputs:0' shape=(?, ?) dtype=int32>,...
Network Embedding: [<tf.Tensor 'char_embedding' shape=(?, ?, 100) dtype=float32>, <tf.Tensor 'bound_embedding' shape=(?, ?, 20) dtype=float32>, <tf.Tensor 'flag_embedding' shape=(?, ?, 50) dtype=float32>, <tf.Tensor 'radical_embedding' shape=(?, ?, 50) dtype=float32>, <tf.Tensor 'pinyin_embedding' shape=(?, ?, 50) dtype=float32>
]"""合并270维度"""
Network Embed: Tensor("concat:0", shape=(?, ?, 270), dtype=float32) """"神经网络 2个LSTM组织(各100个神经元)"""
Network BiLSTM-1: Tensor("concat_1:0", shape=(?, ?, 200), dtype=float32)
Network BiLSTM-2: Tensor("concat_2:0", shape=(?, ?, 200), dtype=float32)
Dense-1: Tensor("project_layer1/Relu:0", shape=(?, 100), dtype=float32)
Dense-2: Tensor("project_layer2/add:0", shape=(?, 31), dtype=float32)"""二维转三维输出最终结果"""
Result: Tensor("Reshape_1:0", shape=(?, ?, 31), dtype=float32)
(2) loss计算
核心功能包括:
- 获取真实长度、输入数据集 [批次大小, 序列长度, 31个实体类别]、真实标签
- 计算损失
-用crf_log_likelihood计算条件随机场的对数似然
Loss lengths: Tensor("strided_slice_1:0", shape=(), dtype=int32)
Loss Inputs: Tensor("Reshape_1:0", shape=(?, ?, 31), dtype=float32)
Loss Targets: Tensor("targets:0", shape=(?, ?), dtype=int32)
Loss Logits: Tensor("crf_loss/concat_2:0", shape=(?, ?, 32), dtype=float32)Loss Targets: Tensor("crf_loss/concat_3:0", shape=(?, ?), dtype=int32)
Loss loglikehood: Tensor("crf_loss/sub:0", dtype=float32)
Loss Trans: <tf.Variable 'crf_loss/trans:0' shape=(32, 32) dtype=float32_ref>
Cost: Tensor("crf_loss/Mean:0", shape=(), dtype=float32)Optimizer: name: "optimizer/Adam"
op: "AssignAdd"
input: "Variable"
input: "optimizer/Adam/value"
attr {key: "T"value {type: DT_INT32}
}
attr {key: "_class"value {list {s: "loc:@Variable"}}
}
attr {key: "use_locking"value {b: false}
}
最后构造优化器,采用梯度截断技术及保存模型。
注意,可能报错“AttributeError: module ‘tensorflow._api.v1.nn’ has no attribute ‘bidirectional_dynamic_run’”,注意版本问题,百度修改成对应的函数即可,作者是tensorflow1.15。
五.模型预测
1.输出训练误差
上面将模型建立好之后,我们尝试调用模型进行误差训练,train.py代码如下,这里的喂数据操作可以封装到类中实现。
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 7 18:57:23 2021
@author: xiuzhang
"""
import tensorflow as tf
from data_utils import BatchManager
import pickle
from model import Model#-----------------------------功能:读取字典---------------------------
dict_file = 'data/dict.pkl'
def get_dict(path):with open(path, 'rb') as f:data = pickle.load(f)return data#-----------------------------功能:训练函数---------------------------
batch_size = 20
def train():#调用已定义的方法获取处理好的数据集train_manager = BatchManager(batch_size, name='train')print('train:', type(train_manager)) #<class 'data_utils.BatchManager'>#读取字典mapping_dict = get_dict(dict_file)print('train:', len(mapping_dict)) #6print('计算六元组个数')print('字:', len(mapping_dict['word'][0])) #1663print('边界:', len(mapping_dict['bound'][0])) #5print('词性:', len(mapping_dict['flag'][0])) #56print('偏旁:', len(mapping_dict['radical'][0])) #227print('拼音:', len(mapping_dict['pinyin'][0])) #989print('类别:', len(mapping_dict['label'][0]),'\n') #31#-------------------------搭建模型---------------------------#实例化模型 执行init初始化方法model核心函数:# 1.get_logits:传递给网络 计算模型输出值 # 2.loss:计算损失值#-----------------------------------------------------------model = Model(mapping_dict)print("---------------模型构建成功---------------------\n")#初始化训练init = tf.global_variables_initializer()with tf.Session() as sess:sess.run(init)for i in range(10):#调用iter_batch函数 迭代过程可以让梯度下降在不断尝试找到最优解for batch in train_manager.iter_batch(shuffle=True): #乱序#print(len(batch)) #6个类型#print(len(batch[0]),len(batch[1]),len(batch[2])) #20个 #每次获取一个批次的数据 feed_dict喂数据 placeholder用于接收神经网络数据_,loss = sess.run([model.train_op,model.cost],feed_dict={model.char_inputs : batch[0],model.bound_inputs : batch[2],model.flag_inputs : batch[3],model.radical_inputs : batch[4],model.pinyin_inputs : batch[5],model.targets : batch[1] #注意顺序})print('loss:{}'.format(loss))#---------------------------功能:主函数---------------------------------
if __name__ == '__main__':train()
输出结果如下图示,可以看到loss从大到小。
loss:545.8291625976562
loss:901.7841796875
loss:442.2290954589844
loss:876.3251953125
loss:332.58746337890625
loss:674.8977661132812
loss:409.48663330078125
loss:220.19033813476562
.....
loss:31.463674545288086
loss:45.567161560058594
loss:98.6595458984375
loss:72.75428009033203
loss:52.30353927612305

问题:
这里需要注意一个问题,如下所示。该问题通常是词向量映射错误导致,但这个问题困扰了我两天,调试了很长时间代码。终于解决,泪奔~
- InvalidArgumentError: indices[0,2] = 7 is not in [0, 5)
- embedding.append(tf.nn.embedding_lookup(lookup,inputs[key]))
原因:
我们最终生成的CSV文件格式是word、label、bound、flag、radical、pinyin顺序,但是后面写入dict.pkl文件及feed_dict喂入数据训练的顺序不一致。这导致最终映射的词向量不一致,造成了“InvalidArgumentError: indices[0,2] = 7 is not in [0, 5)”。

解决方法:
由于之前预处理CSV文件按照char, target, bound, flag, radical, pinyin这个顺序,所以生成的dict.pkl也需要按照这个顺序读写,而feed_dict时读取dict.pkl顺序也需要按照这个顺序,标签是第2列。因此,修改方法:
- 所有顺序需要一致,重新按char, target, bound, flag, radical, pinyin生成dict.pkl文件;
– data_utils.py: char, target, bound, flag, radical, pinyin = line - feed_dict顺序调整
– model.targets:batch[1] - 建议包含target(label)的操作,如读取、赋值、写入均按照统一的顺序执行,除非是字典按照关键词调用(如shapes[‘char’])。

2.预测数据
- 在Model类中定义run_step函数分批处理数据
- 在Model类中定义decode函数解码,通过模型输出和转义矩阵预测
- 在Model类中定义predict函数预测
- 在train.py中分配输出
输出结果如下图所示:

七.总结
写到这里,这篇文章就介绍结束了,希望对您有所帮助。文章虽然很冗余,但还是能学到知识,尤其是数据预处理和BiLSTM构建知识,后续随着作者深入,会分享更简洁的命名实体识别代码,继续加油~

相关文章:
基于BiLSTM-CRF的医学命名实体识别研究(下)模型构建
一.生成映射字典 接下来需要将每个汉字、边界、拼音、偏旁部首等映射成向量。所以,我们首先需要来构造字典,统计多少个不同的字、边界、拼音、偏旁部首等,然后再构建模型将不同的汉字、拼音等映射成不同的向量。 在prepare_data.py中自定义…...

5.sklearn-朴素贝叶斯算法、决策树、随机森林
文章目录 环境配置(必看)头文件引用1.朴素贝叶斯算法代码运行结果优缺点 2.决策树代码运行结果决策树可视化图片优缺点 3.随机森林代码RandomForestClassifier()运行结果总结 本章学习资源 环境配置(必看) Anaconda-创建虚拟环境…...

VMWARE VCENTER6.7 VCSA通过Web5480进行版本升级
VCENTER当前版本如下图 操作前先给VCENTER打一个快照,出问题可以立即回退 1、先下载VCSA镜像,并将VCSA镜像上传至DataStore中; 2、选中VCSA虚拟机,编辑配置 3、挂载新上传的VCSA镜像,一定要勾选“已连接”和“打开电源…...

GIT使用常见问题
如何安装Git? 在Windows操作系统中,可以从Git官方网站(https://git-scm.com)下载最新的Git安装程序,然后按照提示进行安装。在Mac操作系统中,可以使用Homebrew或者直接从Git官方网站下载安装程序进行安装。…...

内核链表
一、特点 灵活性 内核链表可以连接各种不同类型的数据结构,因为它只包含指向下一个和上一个节点的指针,不依赖特定的数据类型,这使得内核开发者可以根据不同的需求灵活地使用它。你可以将不同类型的结构体通过内核链表连接起来,实…...
行空板上YOLO和Mediapipe视频物体检测的测试
Introduction 经过前面三篇教程帖子(yolov8n在行空板上的运行(中文),yolov10n在行空板上的运行(中文),Mediapipe在行空板上的运行(中文))的介绍,…...

【Spring Boot 3】【Web】ProblemDetail
【Spring Boot 3】【Web】ProblemDetail 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...

市占率最高的显示器件,TFT_LCD的驱动系统设计--Part 1
目录 一、简介 二、TFT-LCD驱动系统概述 (一)系统概述 (二)设计要点 二、扫描驱动电路设计 (一)概述 扫描驱动电路的功能 扫描驱动电路的组成部分 设计挑战 驱动模式 (二)…...

Linux基础 -- 获取CPU负载信息
Linux Kernel 获取当前负载情况 本文档介绍了如何在 Linux 内核中获取系统的负载情况。我们将从用户态程序、内核模块开发等角度展示相关方法。 1. 通过 /proc/loadavg 文件获取负载 /proc/loadavg 文件包含了系统的负载信息,通常包括过去 1 分钟、5 分钟和 15 分…...

Django 中的用户界面 - 创建速度计算器
在 Django 中创建一个用户界面来计算速度,可以通过以下步骤完成。这个速度计算器将允许用户输入距离和时间,计算并显示速度。 一、问题背景 一位 Django 新手希望使用 Django 构建一个用户界面,以便能够计算速度(速度 距离/时间…...
spring security 如何解决跨域的
一、什么是 CORS CORS(Cross-Origin Resource Sharing) 是由 W3C制定的一种跨域资源共享技术标准,其目就是为了解决前端的跨域请求。在JavaEE 开发中,最常见的前端跨域请求解决方案是早期的JSONP,但是JSONP 只支持 GET 请求,这是一…...

日志系统前置知识
日志:程序运行过程中所记录的程序运行状态信息。通过这些信息,以便于程序员能够随时根据状态信息,对系统的运行状态进行分析。功能:能够让用户非常简便的进行日志的输出以及控制。 同步写日志 同步日志是指当输出日志时ÿ…...

【Spring Boot 3】【Web】全局异常处理
【Spring Boot 3】【Web】全局异常处理 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花费…...

Dcoker 运行es
1,创建network docker network create my-network 2,docker运行es容器 docker run -d --name es-container --net my-network -p 9200:9200 -p 9300:9300 -e "discovery.typesingle-node" docker.elastic.co/elasticsearch/elasticsearch:7…...

7系列FPGA HR/HP I/O区别
HR High Range I/O with support for I/O voltage from 1.2V to 3.3V. HP High Performance I/O with support for I/O voltage from 1.2V to 1.8V. UG865:Zynq-7000 All Programmable SoC Packaging and Pinout...

sqli-labs靶场通关攻略(五十一到六十关)
sqli-labs-master靶场第五十一关 步骤一,尝试输入?sort1 我们发现这关可以报错注入 步骤二,爆库名 ?sort1 and updatexml(1,concat(0x7e,database(),0x7e),1)-- 步骤三,爆表名 ?sort1 and updatexml(1,concat(0x7e,(select group_conc…...
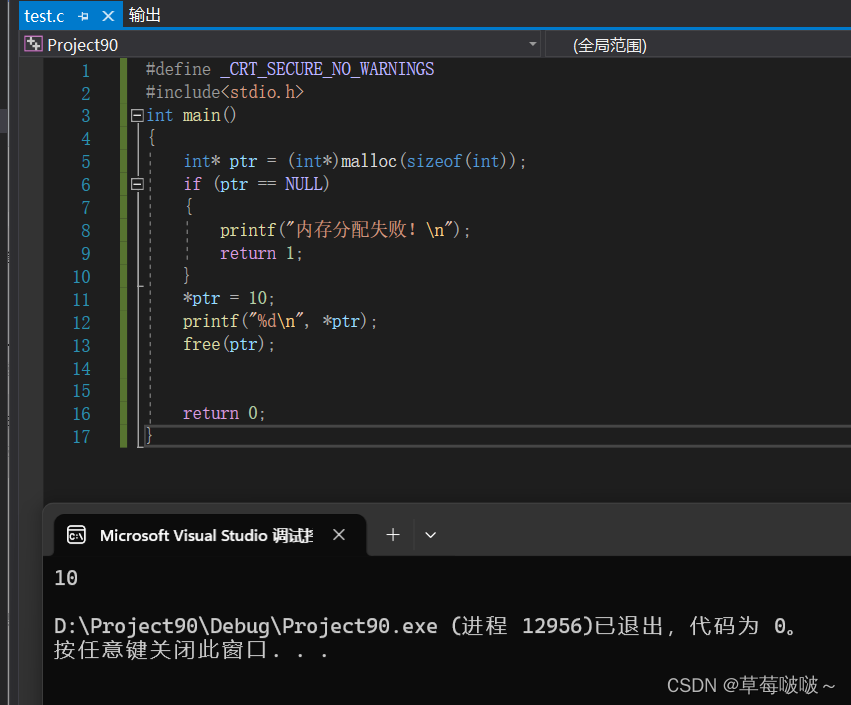
c语言中的动态内存管理
在 C 语言中,动态内存管理主要通过以下几个函数实现: 一、malloc 函数 功能: malloc 函数用于在内存的动态存储区中分配一块长度为 size 字节的连续区域。函数返回一个指向分配区域起始地址的指针,如果分配失败则回 NULL 示例: …...
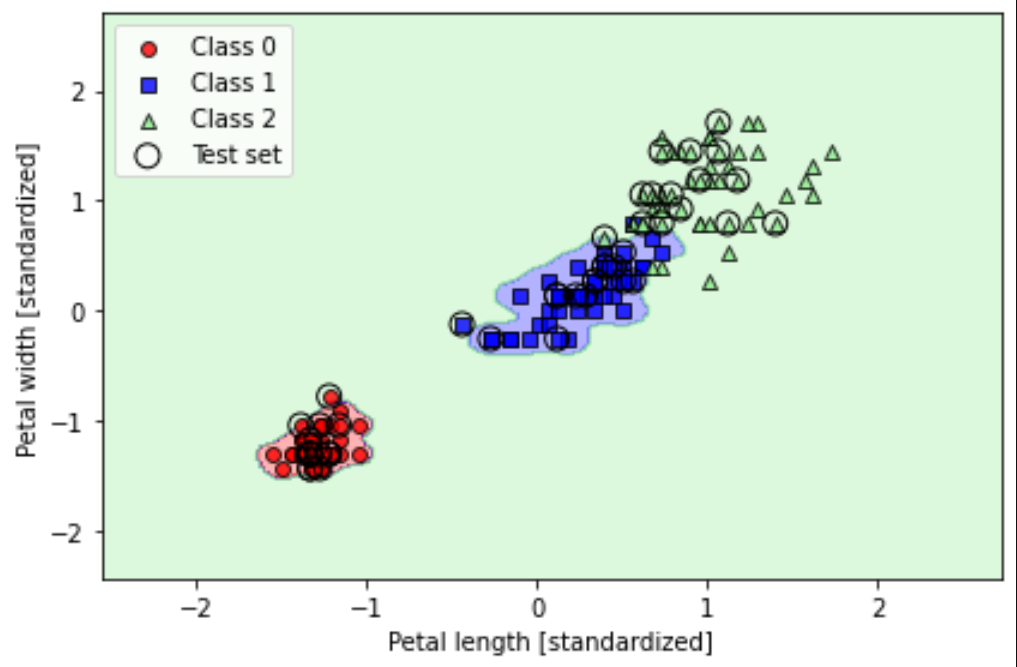
生信机器学习入门4 - scikit-learn训练逻辑回归(LR)模型和支持向量机(SVM)模型
通过逻辑回归(logistic regression)建立分类模型 1.1 逻辑回归可视化和条件概率 激活函数 (activation function): 一种函数(如 ReLU 或 S 型函数),用于对上一层的所有输入进行求加权和,然后生…...

COD论文笔记 Adaptive Guidance Learning for Camouflaged Object Detection
论文的主要动机、现有方法的不足、拟解决的问题、主要贡献和创新点如下: 动机: 论文的核心动机是解决伪装目标检测(COD)中的挑战性任务。伪装目标检测旨在识别和分割那些在视觉上与周围环境高度相似的目标,这对于计算…...

9.5LeetCode
80.删除有序数组重复项II 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的…...

如何快速掌握gh_mirrors/sc/screencasts中的D3.js数据可视化
如何快速掌握gh_mirrors/sc/screencasts中的D3.js数据可视化 【免费下载链接】screencasts Code that goes along with my screencasts. 项目地址: https://gitcode.com/gh_mirrors/sc/screencasts gh_mirrors/sc/screencasts是一个包含丰富D3.js教程和实例代码的项目&a…...
芯片,具备精准计时、低功耗运行和工业级可靠性等核心优势,广泛应用于工业控制、嵌入式系统、智能仪表等领域)
现货库存DS1305EN+TR 是ADI推出的一款高集成度实时时钟(RTC)芯片,具备精准计时、低功耗运行和工业级可靠性等核心优势,广泛应用于工业控制、嵌入式系统、智能仪表等领域
DS1305ENT&R 是ADI推出的一款高集成度实时时钟(RTC)芯片,具备精准计时、低功耗运行和工业级可靠性等核心优势,广泛应用于工业控制、嵌入式系统、智能仪表等领域。产品核心性能高精度时间管理:支持秒、分钟、…...

VMware macOS解锁终极实战指南:5步让Windows/Linux完美运行苹果系统
VMware macOS解锁终极实战指南:5步让Windows/Linux完美运行苹果系统 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 在虚拟化技术日益普及的今天,许多开发者和技术爱好者都希望能…...

如何使用HS2-HF_Patch优化Honey Select 2游戏体验:完整指南
如何使用HS2-HF_Patch优化Honey Select 2游戏体验:完整指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是一款专为《Honey Select …...

别再数据线了!用FastAPI 分钟搭个局域网文件+剪贴板神器伊
为 HagiCode 添加 GitHub Pages 自动部署支持 本项目早期代号为 PCode,现已正式更名为 HagiCode。本文记录了如何为项目引入自动化静态站点部署能力,让内容发布像喝水一样简单。 背景/引言 在 HagiCode 的开发过程中,我们遇到了一个很现实的问…...

终极指南:如何用PoeCharm中文版轻松规划你的《流放之路》角色构建
终极指南:如何用PoeCharm中文版轻松规划你的《流放之路》角色构建 【免费下载链接】PoeCharm Path of Building Chinese version 项目地址: https://gitcode.com/gh_mirrors/po/PoeCharm 还在为《流放之路》复杂的角色构建系统感到头疼吗?面对海量…...

为什么你的C# 14 AOT Dify客户端启动慢3秒?——基于CoreRT底层源码的6层初始化链路剖析
第一章:C# 14 AOT编译与Dify客户端启动性能的底层关联性C# 14 引入的原生AOT(Ahead-of-Time)编译能力,正深刻重构.NET应用的启动行为模型。当Dify官方客户端(基于MAUI或WPF构建的桌面前端)启用AOT编译时&am…...

STM32F103移相全桥PWM寄存器级配置实战
1. STM32F103移相全桥PWM控制的核心原理 移相全桥拓扑在DCDC电源设计中非常常见,它通过调节两个桥臂之间的相位差来控制功率传输。STM32F103的高级定时器TIM1和TIM8正好可以完美实现这个功能。我做过好几个电源项目,发现直接操作寄存器比用库函数效率高得…...

用Qwen3-Embedding-0.6B做文本分类:实战教程与代码分享
用Qwen3-Embedding-0.6B做文本分类:实战教程与代码分享 1. 引言 文本分类是自然语言处理中最基础也最实用的任务之一。无论是新闻分类、情感分析,还是垃圾邮件识别,都需要将文本准确地归入预定义的类别。传统的文本分类方法依赖人工特征工程…...

镭神智能C32激光雷达实战:从开箱到点云可视化全流程解析
1. 开箱与硬件连接 第一次拿到镭神智能C32激光雷达时,包装箱里会有这些关键部件:雷达主机、电源适配器、网线、HDMI线(可选)和说明书。我建议先找个宽敞的工作台,把所有配件摊开检查一遍,避免遗漏。 连接步…...