深度学习-用神经网络NN实现足球大小球数据分析软件
文章目录
- 前言
- 一、 数据收集
- 1.1特征数据收集
- 代码实例
- 二、数据预处理
- 清洗数据
- 特征工程:
- 三、特征提取
- 四、模型构建
- 五、模型训练与评估
- 总结
前言
预测足球比赛走地大小球(即比赛过程中进球总数是否超过某个预设值)的深度学习模型是一个复杂但有趣的项目。这里,我将概述一个基本的实现流程,包括数据收集、特征提取、模型构建、训练和评估。由于直接编写完整的代码在这里不太现实,我将提供关键步骤的代码和概念说明。
一、 数据收集
1.1特征数据收集
首先,你需要收集大量的足球比赛数据,包括但不限于:
- 比赛结果(主队进球数、客队进球数)
- 比赛时间(全场、半场)
- 球队历史表现(近期胜率、进球率、失球率)
- 球队阵容(关键球员是否上场)
- 天气条件
- 球场信息
- 裁判因素(可选,可能影响比赛风格)
- 赛事类型(联赛、杯赛、友谊赛等)
- 球队间历史交锋记录
代码实例
这里用python实现足球赛事数据的收集,如果是走地数据分析的话,需要用定时任务即时采集,这里只是简单的爬取和入库
import requests
import sqlite3
import json # 国外赛事数据
api_url = 'https://xxxx.com/data' # 连接到SQLite数据库
# 如果数据库不存在,它会自动创建
conn = sqlite3.connect('football_data.db')
c = conn.cursor() # 创建一个表来存储数据
# 假设API返回的数据包含'team', 'goals', 'matches'等字段
c.execute('''CREATE TABLE IF NOT EXISTS teams (id INTEGER PRIMARY KEY AUTOINCREMENT, team TEXT NOT NULL, goals INTEGER, matches INTEGER)''') # 从API获取数据
def fetch_data(url): try: response = requests.get(url) response.raise_for_status() # 如果响应状态码不是200,将引发HTTPError异常 return response.json() except requests.RequestException as e: print(e) return None # 解析数据并插入到数据库中
def insert_data(data): for item in data: # 假设每个item都是一个包含'team', 'goals', 'matches'的字典 c.execute("INSERT INTO teams (team, goals, matches) VALUES (?, ?, ?)", (item['team'], item['goals'], item['matches'])) conn.commit() # 获取数据并插入
data = fetch_data(api_url)
if data: insert_data(data) # 关闭数据库连接
conn.close() print("数据已成功获取并入库。")
二、数据预处理
清洗数据
数据清洗通常涉及多个步骤,包括处理缺失值、异常值、重复数据、数据类型转换、数据格式标准化等,这里用pandas简单的进行数据处理。
import pandas as pd
import sqlite3 # 连接到SQLite数据库
conn = sqlite3.connect('football_data.db') # 使用Pandas的read_sql_query函数从数据库中读取数据
# 假设'matches'表包含'id', 'home_team', 'away_team', 'home_goals', 'away_goals'等字段
query = "SELECT * FROM matches"
df = pd.read_sql_query(query, conn) # 数据清洗步骤 # 1. 处理异常数据
# 假设进球数不可能为负数或超过某个合理值(如10个)
# 这里我们将进球数限制在0到10之间
df['home_goals'] = df['home_goals'].apply(lambda x: x if 0 <= x <= 10 else 0)
df['away_goals'] = df['away_goals'].apply(lambda x: x if 0 <= x <= 10 else 0) # 2. 处理缺失值
# 假设我们决定删除任何包含缺失值的行(这通常不是最佳实践,但在这里作为示例)
df.dropna(inplace=True) # 3. 检查并处理其他潜在问题(如重复数据等)
# 这里我们假设没有重复的比赛ID,但如果有,可以使用drop_duplicates()删除
# df.drop_duplicates(subset='id', keep='first', inplace=True) # 4. (可选)将清洗后的数据写回数据库或保存到新的CSV文件
# 如果要写回数据库,请确保表已存在或先创建表
# 如果要保存到CSV文件
df.to_csv('cleaned_football_data.csv', index=False) # 关闭数据库连接
conn.close() # 查看清洗后的数据(可选)
print(df.head())
特征工程:
这里简单的用下面几个关键信息作为特征数据
- 进球率:计算球队近期比赛的进球平均数。
- 失球率:计算球队近期比赛的失球平均数。
- 胜率:计算球队近期比赛的胜率。
- 主客场优势:考虑主队或客队的历史主场/客场胜率。
- 时间因素:考虑比赛进行的时间段(如开场、中场、结束前)对进球数的影响。
- 让球因素:转换为数值型特征,如让一球则主队进球数需减去一。
- 编码分类变量:如赛事类型、球场类型等。
三、特征提取
前面已经将特征数据都处理好了,下面开始对特征数据提取。
# 假设df是Pandas DataFrame,包含所有比赛数据 # 计算近期进球率(以最近5场为例)
def calculate_recent_goals(df, team_column, goals_column, window_size=5): df[f'{team_column}_recent_goals'] = df.groupby(team_column)[goals_column].rolling(window=window_size, min_periods=1).mean() # 类似地,可以计算失球率、胜率等 # 编码分类变量
df['venue'] = pd.Categorical(df['venue']).codes # 假设venue是主客场信息 # 提取特征
features = ['home_team_recent_goals', 'away_team_recent_goals', 'venue', 'match_time_segment', 'handicap']
X = df[features] # 提取标签
# 假设label_big_small是判断大小球的标签(0: 小球, 1: 大球)
# label_handicap_win是判断让球胜负的标签(0: 负, 1: 胜)
y_big_small = df['label_big_small']
y_handicap_win = df['label_handicap_win']
分析出球队的具体整体情况

四、模型构建
from keras.models import Sequential
from keras.layers import Dense # 构建模型
model = Sequential([ Dense(64, activation='relu', input_shape=(X.shape[1],)), Dense(64, activation='relu'), Dense(1, activation='sigmoid') # 二分类问题使用sigmoid
]) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])

五、模型训练与评估
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train_big_small, y_test_big_small = train_test_split(X, y_big_small, test_size=0.2, random_state=42) # 训练模型
model.fit(X_train, y_train_big_small, epochs=10, batch_size=32, validation_split=0.2) # 评估模型
loss, accuracy = model.evaluate(X_test, y_test_big_small)
print(f"Test Accuracy: {accuracy:.2f}") # 类似地,可以训练并评估让球胜负预测模型
得出预测结果

总结
上面只是简单的介绍了大模型的实现过程,实际过程比这个复杂很多,其中特征数据就包括了球队过去的进球数、失球数、射门次数、射正次数等统计数据,不同的球队有不同的战术风格,如攻势足球、防守反击等。攻势足球风格的球队通常进球较多,而防守反击的球队则可能更加注重控制球权和减少失球,球员的当前状态对比赛结果有直接影响。状态良好的球员在比赛中更有可能发挥出色,从而增加进球的可能性。
鸣谢:[AIAutoPrediction足球数据分析平台]提供的足球数据分析

相关文章:
深度学习-用神经网络NN实现足球大小球数据分析软件
文章目录 前言一、 数据收集1.1特征数据收集代码实例 二、数据预处理清洗数据特征工程: 三、特征提取四、模型构建五、模型训练与评估总结 前言 预测足球比赛走地大小球(即比赛过程中进球总数是否超过某个预设值)的深度学习模型是一个复杂但有…...

linux 9系统分区扩容
1.可以看到我的是9.2的系统,系统分区:/dev/mapper/rl-root 83G 8.0G 75G 10% / 2.接下来,我们新增一块新的硬盘,而不是直接对这个硬盘的基础上再扩容。 关机,加30G硬盘,再开机 fdisk -l fdisk /dev/…...

Solidity初体验
一、概念知识 什么是智能合约? 智能合约是仅在满足特定条件时才在区块链上部署和执行的功能,无需任何第三方参与。 由于智能合约本质上是不可变的和分布式的,因此它们在编写和部署后无法修改或更新。此外,分布式的意义在于任何…...

大模型笔记01--基于ollama和open-webui快速部署chatgpt
大模型笔记01--基于ollama和open-webui快速部署chatgpt 介绍部署&测试安装ollama运行open-webui测试 注意事项说明 介绍 近年来AI大模型得到快速发展,各种大模型如雨后春笋一样涌出,逐步融入各行各业。与之相关的各类开源大模型系统工具也得到了快速…...

html前段小知识点
1. 什么是HTML? 超文本标记语言是一种 用于创建网页的标准标记语言 HTML 文档包含了HTML 标签及文本内容 也叫文档1.什么是css? CSS (层叠样式表),是一种用来为结构化文档添加样式的计算机语言,CSS 文件扩展名为 .css。 可以设…...

AD7606工作原理以及FPGA控制验证(串行和并行模式)
文章目录 一、AD7606介绍二、AD7606采集原理2.1 AD7606功能框图2.2 AD7606管脚说明 三、AD7606并行模式时序分析以及实现3.1 并行模式时序图3.2 并行模式时序要求3.3 代码编写3.4 仿真观察 四、AD7606串行模式时序分析以及实现4.1 串行模式时序图4.2 串行模式时序要求4.3 代码编…...

如何查看Pod的Container资源占用情况
云原生学习路线导航页(持续更新中) 方法一:直接查看pod的资源占用 kubectl top pods ${pod-name} -n ${ns} 方法二:通过运行的进程,查看pod的某个容器资源占用 1.找到pod所在node容器号:kubectl descri…...

WordPress上可以内容替换的插件
插件下载地址:WordPress内容替换插件 – 果果开发 类型 替换的类型:文章、自定义文章类型、分类、标签、媒体库、页面、评论、数据库表,不同的类型可以替换不同的字段。 替换字段 替换的字段,哪些字段内容需要替换。除了数据库…...

C++ | Leetcode C++题解之第355题设计推特
题目: 题解: class Twitter {struct Node {// 哈希表存储关注人的 Idunordered_set<int> followee;// 用链表存储 tweetIdlist<int> tweet;};// getNewsFeed 检索的推文的上限以及 tweetId 的时间戳int recentMax, time;// tweetId 对应发送…...

构建并训练卷积神经网络(CNN)对CIFAR-10数据集进行分类
深度学习实践:构建并训练卷积神经网络(CNN)对CIFAR-10数据集进行分类 引言 在计算机视觉领域中,CIFAR-10数据集是一个经典的基准数据集,广泛用于图像分类任务。本文将介绍如何使用PyTorch框架构建一个简单的卷积神经…...

flowable 根据xml 字符串生成流程图
//获取xml InputStream stream repositoryService.getProcessModel(processDefinitionId); String result IOUtils.toString(stream, StandardCharsets.UTF_8); // 创建 XMLInputFactory XMLInputFactory factory XMLInputFactory.newInstance(); // 从字符…...

AI建模——AI生成3D内容算法产品介绍与模型免费下载
说明: 记录AI文生3D模型、图生3D模型的相关产品;记录其性能、功能、收费与免费方法 0.AI建模产品 Rodin MeshAnything Meshy 生成效果比较: Rodin效果最好、Meshy其次 1.Rodin 官网:gHyperHuman 支持:文生模型、…...
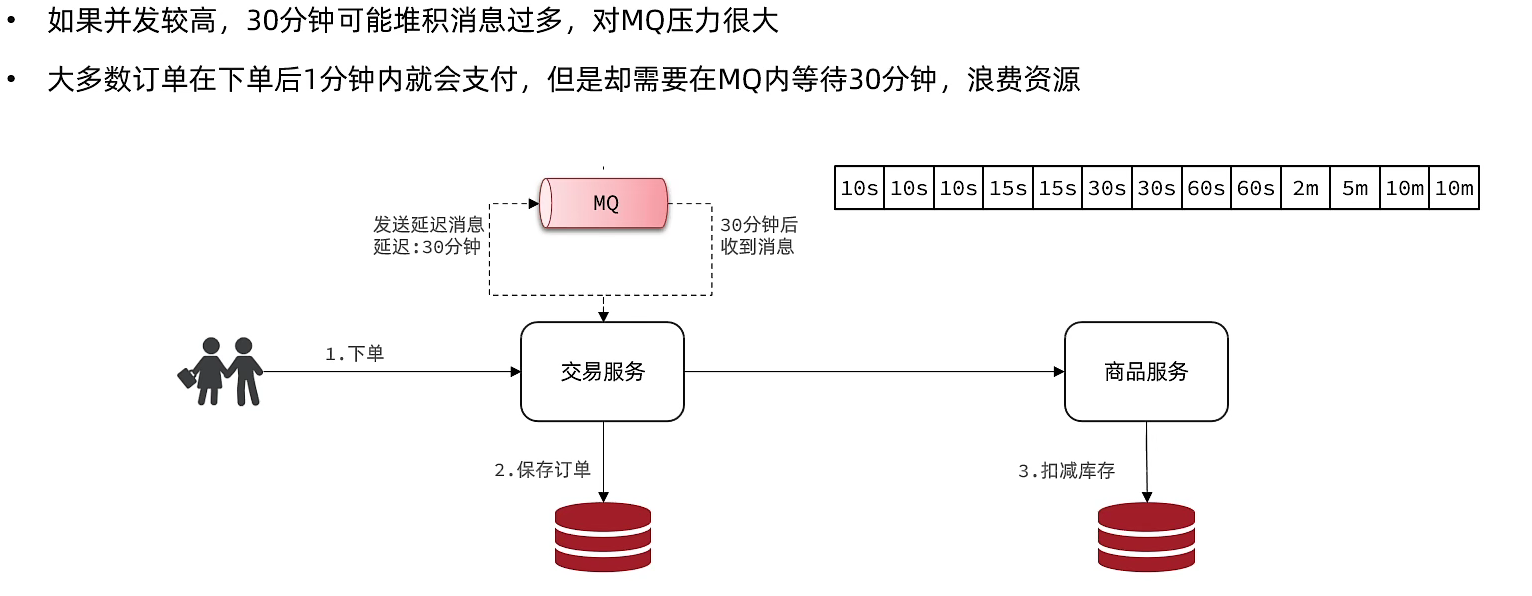
在Go中迅速使用RabbitMQ
文章目录 1 认识1.1 MQ分类1.2 安装1.3 基本流程 2 [Work模型](https://www.rabbitmq.com/tutorials/tutorial-two-go#preparation)3 交换机3.1 fanout3.2 direct3.3 [topic](https://www.rabbitmq.com/tutorials/tutorial-five-go) 4 Golang创建交换机/队列/Publish/Consume/B…...

Windows JDK安装详细教程
一、关于JDK 1.1 简介 Java是一种广泛使用的计算机编程语言,拥有跨平台、面向对象、泛型编程的特性,广泛应用于企业级Web应用开发和移动应用开发。 JDK(Java Development Kit)是用于开发 Java 应用程序的工具包。它由以下几个主要…...

Ribbon负载均衡底层原理
springcloude服务实例与服务实例之间发送请求,首先根据服务名注册到nacos,然后发送请求,nacos可以根据服务名找到对应的服务实例。 SpringCloudRibbon的底层采用了一个拦截器,拦截了openfeign发出的请求,对地址做了修…...

【C语言可变参数函数的使用与原理分析】
文章目录 1 前言2 实例2.1实例程序2.2程序执行结果2.3 程序分析 3 补充4 总结 1 前言 在编程过程中,有时会遇到需要定义参数数量不固定的函数的情况。 C语言提供了一种灵活的解决方案:变参函数。这种函数能够根据实际调用时的需求,接受任意…...

【笔记】Java EE应用开发环境配置(JDK+Maven+Tomcat+MySQL+IDEA)
一、安装JDK17 1.下载JDK17 https://download.oracle.com/java/17/archive/jdk-17.0.7_windows-x64_bin.zip 2.配置环境变量 下载后,解压到本地(目录中最好不要有中文或特殊字符) 打开【控制面板】-【系统和安全】-【系统】-【高级系统…...

一文讲懂扩散模型
一文讲懂扩散模型 扩散模型(Diffusion Models, DM)是近年来在计算机视觉、自然语言处理等领域取得显著进展的一种生成模型。其思想根源可以追溯到非平衡热力学,通过模拟数据的扩散和去噪过程来生成新的样本。以下将详细阐述扩散模型的基本原理…...

学习笔记八:基于Jenkins+k8s+Git+DockerHub等技术链构建企业级DevOps容器云平台
基于Jenkinsk8sGitDockerHub等技术链构建企业级DevOps容器云平台 测试jenkins的CI/CD在Jenkins中安装kubernetes插件安装blueocean插件配置jenkins连接到我们存在的k8s集群配置pod-template添加自己的dockerhub凭据测试通过Jenkins部署应用发布到k8s开发环境、测试环境、生产环…...

科研绘图系列:R语言柱状图分布(histogram plot)
文章目录 介绍加载R包读取数据画图介绍 柱状图(Bar Chart)是一种常用的数据可视化图表,用于展示和比较不同类别或组的数据。它通过在二维平面上绘制一系列垂直或水平的柱子来表示数据的大小,每个柱子的长度或高度代表一个数据点的数值。柱状图非常适合于展示分类数据的分布…...

比迪丽模型Python安装全指南:从环境配置到第一个艺术生成
比迪丽模型Python安装全指南:从环境配置到第一个艺术生成 1. 开篇:为什么选择比迪丽模型? 如果你对AI绘画感兴趣,可能已经听说过比迪丽模型。这是一个强大的文本生成图像模型,能够根据你的文字描述创作出令人惊艳的艺…...

Linux硬盘分区管理
硬盘分区管理 大容量的硬盘,分区使用:C盘系统盘,D盘办公,E盘娱乐。 类似于:买了一个房子100平方,隔断:主卧、次卧1、次卧2、厨房、卫生间。识别硬盘设备接口类型设备命名示例说明SATA/SAS/USB/S…...
)
【基于Python技术的智慧中医商业项目】后端应用Articles代码实现(三)
前后端分离场景中,序列化字段映射一旦写错,常见表现是接口返回字段缺失、层级字段解析失败、列表页展示异常;过滤器规则不稳定时,表现为列表查询条件无效、批量筛选失控、后台与接口筛选口径不一致。 本文围绕文章应用模块的 serializes.py 与 filters.py 拆解,聚焦序列化…...

【Nginx】前端项目开启 Gzip 压缩大幅提高页面加载速度
背景 Gzip 是一种文件压缩算法,减少文件大小,节省带宽从而提减少网络传输时间,网站会更快更丝滑。 // nginx roothcss-ecs-1d22:/etc/nginx# nginx -v nginx version: nginx/1.24.0// node ndde v18.20.1// dependencies "vue": &q…...
)
软考 系统架构设计师系列知识点之杂项集萃(117)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(116) 第214题 在磁盘上存储数据的排列方式会影响I/O服务的总时间。假设每磁道划分成10个物理块,每块存放1个逻辑记录。逻辑记录R1,R2,……,R10存放在同一个磁道上,记录的安排顺序如下表所示: 物理块 1 2 3 4 5…...

企业微信外部群自动化回复避坑指南:RPA如何稳定接管WebSocket连接不断线
企业微信外部群自动化回复的WebSocket稳定性实战:从心跳包到风控规避 当你的RPA机器人第三次在凌晨2点因为WebSocket连接断开而停止响应时,技术负责人发来的质问消息比企业微信的报警通知更让人心惊。这不是简单的技术故障,而是关乎业务流程连…...

阿里通义Z-Image-GGUF使用心得:小白也能玩转的高质量文生图
阿里通义Z-Image-GGUF使用心得:小白也能玩转的高质量文生图 1. 30秒快速上手:从零到第一张AI画作 你是不是也曾在社交媒体上看到那些惊艳的AI生成图片,心里想着"这一定很难操作"?今天我要告诉你一个好消息:…...

Ostrakon-VL-8B模型微调入门:使用自定义餐饮数据集
Ostrakon-VL-8B模型微调入门:使用自定义餐饮数据集 你是不是也遇到过这样的情况?看到一个很棒的视觉语言模型,它能识别各种通用物体,但当你拿一张特色地方菜或者自家餐厅的新品图片给它看时,它却常常“答非所问”&…...
)、expr三种方式全解析(附避坑指南))
Shell脚本中的算术运算:let、(())、expr三种方式全解析(附避坑指南)
Shell脚本算术运算深度指南:从基础到高阶实战 在自动化脚本编写和数据处理中,算术运算是最基础却最容易出错的部分。Shell作为字符串处理起家的脚本语言,其数值计算有着独特的语法规则和陷阱。本文将彻底解析三种主流算术运算方式,…...

产教融合共建失智老年人照护实训室实践路径
本文围绕产教融合模式,结合失智老年人照护岗位实际需求,从合作机制、空间布局、设备配置、教学实施、运营保障五个核心维度,给出可落地的失智老年人照护实训室共建实践路径,兼顾实用性与可操作性,助力院校与企业高效共…...