基于云原生向量数据库 PieCloudVector 的 RAG 实践
近年来,人工智能生成内容(AIGC)已然成为最热门的话题之一。工业界出现了各种内容生成工具,能够跨多种模态产生多样化的内容。这些主流的模型能够取得卓越表现,归功于创新的算法、模型规模的大幅扩展,以及海量的高质量数据集。然而 AIGC 依然面临一系列挑战,检索增强生成(RAG)技术作为 LLM 的一项重要补充被提出。本文将结合实例演示,和大家一起探索基于 PieCloudVector 的 RAG 实践。
AIGC 强调内容是通过先进的生成模型,而非人类或基于规则的方法来产生的。近年来,AIGC 技术飞速发展,序列到序列的任务,已经从依赖长短期记忆网络(LSTM)转变为采用基于 Transformer 的模型,而图像生成任务,也从生成对抗网络(GANs)转向了潜在扩散模型(LDMs)。
基础模型的架构,最初由数百万参数构成,现在已经扩展到数十亿甚至数万亿参数。这些进步得益于丰富且高质量的数据集,它们为模型参数的全面优化提供了充足的训练样本。
信息检索是计算机科学中的另一个核心应用,它与内容生成不同,其目标是在海量资源中定位相关的现有对象。目前,高效的信息检索系统能够处理达到数十亿数量级的文档集合,检索技术也被应用于多种不同的模态。
尽管 AIGC 取得了巨大进步,但仍面临一些挑战,如保持知识更新、整合长尾知识以及防止私人训练数据泄露等。为了应对这些挑战,检索增强生成(RAG)的概念被提出。RAG 通过其灵活的数据存储库,可以作为非参数记忆,容易修改,能够广泛地整合长尾知识,并且能够安全地编码敏感数据。此外,RAG 还能够降低生成成本,比如减小大型生成模型的规模,支持长文本的生成,并简化某些生成步骤。
1 什么是 RAG?
检索增强生成(RAG)技术是对大型语言模型(LLM)的一项重要补充,它允许 LLM 在生成响应之前,访问超出其训练数据范围的特定领域或组织内部的权威知识库,优化 LLM 的输出,这一过程无需对模型进行重新训练,从而提供了一种成本效益高且灵活的方式来提升 LLM 的性能。通过这种方式,可以将通用的大型语言模型“定制化”,使其更好地适应特定的业务需求和用例场景。
在没有 RAG 的情况下,用户输入会直接传递给 LLM,模型将基于其训练数据或已知信息生成输出。而 RAG 的引入,为这一过程增加了一个关键的信息检索组件,当接收到用户输入时,RAG 首先利用信息检索组件,根据输入内容提取相关信息,这些信息随后作为上下文信息,与用户查询一起提供给 LLM。
LLM 结合提供的上下文信息和其训练数据,共同作用于输出的生成过程。这种结合了检索和生成的方法,不仅提高了输出的相关性和准确性,还增强了模型对特定领域知识的利用。也就是说,相比于模型重新训练和微调,RAG 会展现出以下显著优势:
-
成本效益: 与传统的模型重新训练相比,RAG 提供了一种更为经济高效的方式来引入新数据。它避免了高昂的硬件成本和计算资源消耗,使得生成式人工智能技术更加普及和易于获取。
-
实时更新: RAG 能够实现 LLM 与社交媒体、新闻网站等实时数据源的连接,确保模型能够基于最新信息为用户提供推理结果。这种能力显著提升了模型输出内容的时效性和相关性。
-
增强可信度: 通过 RAG,LLM 的输出可以包含对权威数据源的引用,这不仅提高了结果的可信度,也允许用户追溯至原始文档以验证信息。这种透明度有助于增强用户对生成式人工智能的信任。
-
输入控制: RAG 允许根据任务需求和权限级别,精确控制模型的输入信息。这种灵活性确保了敏感数据的安全性,同时允许模型在保护隐私的前提下,处理不同敏感度的数据。
2 什么是 PieCloudVector?
云原生向量数据库 PieCloudVector 作为拓数派大模型数据计算系统的核心计算引擎之一,是大模型时代分析型数据库的升维之作,专为多模态大模型 AI 应用而生。
PieCloudVector 的技术路线是将业界成熟开源算法实现与自研的基于 postgres 内核的关系型数据库对接起来,拥有完整的 ACID 数据管理能力,支持标量与向量的混合查询。PieCloudVector 支持主流的近似最近邻(ANN)算法和向量编码或压缩算法,支持 SIMD/GPU 加速,并兼容 LangChain 等大模型工具生态。相较于传统数据库,PieCloudVector 实现了向量化存储和计算资源的弹性扩缩,提高了易用性和性能,增强了元数据变更功能,解决了数据一致性问题,并克服了安全性、可靠性和在线性方面的技术难题。
在架构设计方面,PieCloudVector 的每个执行器(Executor)对应一个 PieCloudVector 实例,从而实现向量存储和相似性搜索服务的高性能、可扩展性和可靠性。借助 PieCloudVector,用户不仅可以存储和管理原始数据对应的向量,还可以调用 PieCloudVector 相关工具进行模糊搜索,与全局搜索相比,牺牲了一定的精度来实现毫秒级的搜索,进一步提高了查询效率。
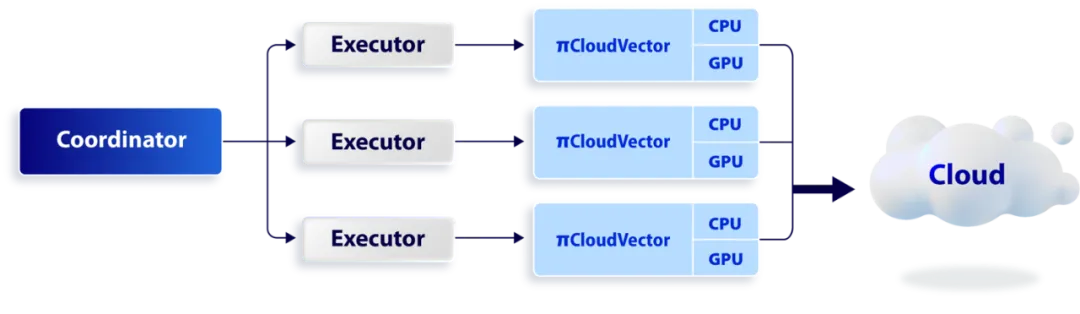
PieCloudVector 架构设计
在 RAG 的应用实践中,PieCloudVector 展示了一种高效的方法来结合用户查询和相关数据,以生成精确且权威的响应。以下是其 RAG 工作流程的详细步骤:
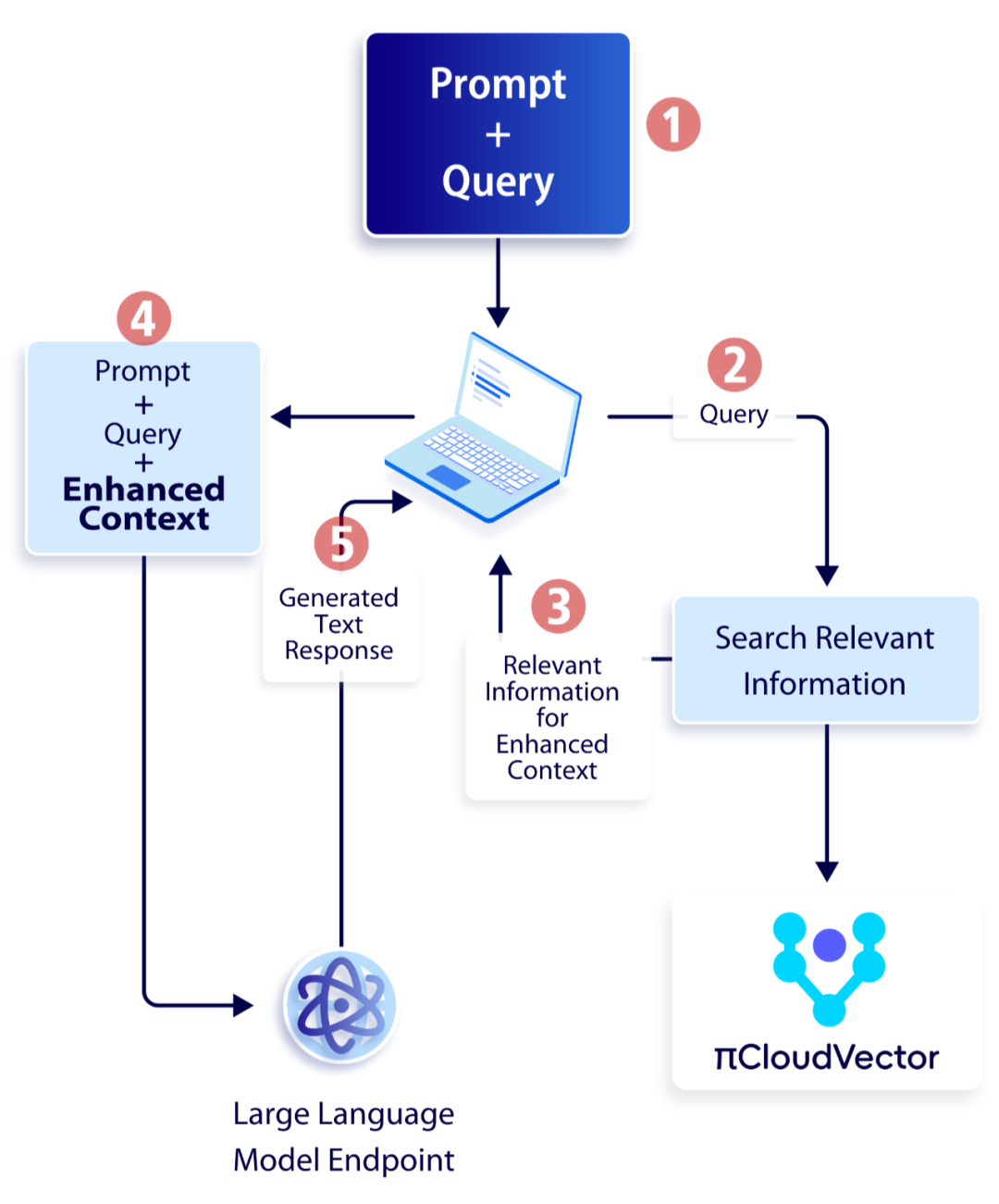
RAG 工作流程
-
外部数据源的创建: 首先识别并集成了位于 LLM 原始训练数据集之外的新数据,这些被称为外部数据。它们可能来源于 API、数据库或文档存储库,并且可能以多种格式存在,如文件、数据库记录或文本,以及向量形式的嵌入。这些外部数据被存储在 PieCloudVector 中,其中既保留了原始文本,也保存了对应的文本嵌入信息。
-
用户输入的处理: 对于用户提出的查询(Query),在查询外部数据源之前,对其进行预处理。这可能包括提取用户的查询文本的嵌入表示,以便通过向量相似性搜索在外部数据源中检索相关上下文数据。
-
执行相关性搜索: 一旦用户输入被转换为嵌入向量,就可以利用这些向量在外部数据源中执行相关性搜索。PieCloudVector 支持多种高效的向量索引技术,如 HNSW、IVFFLAT、IVFQD 等,以加速这一过程。
-
构建模型输入上下文: 利用从外部数据源检索到的与用户查询相似的数据,构建了模型的输入上下文。例如,可以选择最相似的 top k 条数据的原始文本,以此构建模型的输入上下文。
-
模型输入: 将用户的原始查询和检索到的相关上下文信息一并作为输入提供给模型。
-
模型输出: 模型结合用户提供的查询和检索到的上下文信息,生成响应。
接下来,我们通过一个实例,以 PieCloudVector 来存放外部数据,语言模型使用 Llama2, 基于 LangChain 实现一个完整的 RAG 工作流程。
3 基于 PieCloudVector 的 RAG 实例演示
3.1 准备外部数据源和模型
本实例所使用的外部数据来源于拓数派官网发布的一系列博客文章,这些数据已被我们整理并构建成一个内部数据集。该数据集中的每一条记录仅包含了一段独立的英文文本,其格式如下所示:
Openpie is dedicated to "Data Computing for New Discoveries" and has successfully completed three rounds of strategic financing....OpenPie's flagship product, PieCloudDB realizes cutting-edge data warehouse virtualization technology ....With continuous innovation of artificial intelligence (AI) technology, we can observe its increasingly widespread applications ...
我们采用 LangChain 提供的 VectorStore 接口对 PieCloudVector 进行了封装,将其封装为 VectorStore 的一个实现类,以便于与 PieCloudVector 进行交互。通过使用 Langchain 的 API,我们对外部数据进行了必要的预处理,包括文本切分和提取 embedding 等步骤。处理后的数据,包括原始文本数据和对应的 embedding 数据,被存储到 PieCloudVector 中。同时,为了提高相似向量检索的效率,我们还创建了 HNSW 索引。以下是实现这一功能的核心代码:
raw_doc_path = "./RAG-data/context-text"
loader = DirectoryLoader(raw_doc_path)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
doc_splits = text_splitter.split_documents(docs)
model_name = "BAAI/bge-base-en"
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
embedding_function = HuggingFaceBgeEmbeddings(model_name=model_name,model_kwargs={'device': 'cuda'},encode_kwargs=encode_kwargs
)
CONNECTION_STRING = "postgresql+psycopg2://openpie@xx.xx.xx.xx:5432/openpie"
vectordb = PieCloudVector.from_documents(documents=doc_splits, # text data that you want to embed and storeembedding=embedding_function, # used to convert the documents into embeddingsconnection_string=CONNECTION_STRING,collection_name="docs_v1"
)
vectordb.create_hnsw_index(dims=768, index_key="HNSW32", ef_construction=40, ef_search=16)
外部数据被成功写入到 PieCloudVector 后,每条记录都由两个重要字段:embedding 和 document, 格式如下所示:
{ "embedding": [-0.0087991655,-0.027009273,0.0033726105,0.018299054,0549,0.045432627,-0.038479857,...],"document": "Openpie is dedicated to 'Data Computing for New Discoveries' and ... ",
}
使用 huggingface 的 transformers 库加载 Llama2 模型,并构造任务流水线:
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME,trust_remote_code=True,use_fast=True,add_eos_token=True,
)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,use_safetensors=True,trust_remote_code=True,device_map='auto',load_in_8bit=True,
)
pipe = pipeline("text-generation",model=model,tokenizer=tokenizer,max_new_tokens=512,temperature=0.7,top_p=0.95,repetition_penalty=1.15,
)llm = HuggingFacePipeline(pipeline=pipe)
3.2 推理过程
LangChain 定义了一个 Retriever 接口,对于给定的用户查询,其封装了检索相似文档的逻辑。推理阶段中,首先将基于 PieCloudVector 实现的 vectordb 实例转换为一个 Retriever 对象 。针对每个查询,该 Retriever 会在 PieCloudVector 中进行检索,返回最相似的三条数据。接着,整合大模型,外部数据源构造问答任务链。最后,输入问题执行推理任务。
retriever = vectordb.as_retriever(search_kwargs={"k": 3})
retrieval_qa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,return_source_documents=True
)query = "What is PieCloudVector? and any advantages of PieCloudVector? please describe in short words"
response = retrieval_qa_chain(query)
使用了 RAG 后,对于问题 :
“What is PieCloudVector? and any advantages of PieCloudVector? please describe in short words”
模型的输入不仅包含了问题信息, 必要的提示,还包含了从外部数据源检索到的问题的上下文信息,具体形式如下所示:
{
"Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know,don't try to make up an answer.",'PieCloudVector vector database has the capability to perform fast queries on trillion-scale vector databases. It supports single-node multi-threaded index creation, effectively utilizing all available hardware computational resources.This results in a five-fold improvement in index creation performance, a six-fold improvement in retrieval performance, and a three-fold improvement in interactive response speed.PieCloudVector, in conjunction with Soochow Securities Xiucai GPT, forms the overall RAG architecture. PieCloudVector primarily stores the embedded vector data while also supporting storage of scalar data for applications. Additionally, ....', 'Question: What is PieCloudVector? and any advantages of PieCloudVector? please describe in short words',
}
3.3 推理结果
使用了 RAG 后, 对于问题:
“What is PieCloudVector? and any advantages of PieCloudVector? please describe in short words”
输出如下所示。可见 Llama2 模型根据输入的上下文信息,基本可以输出一个正确结果。
'Helpful Answer:
PieCloudVector is a distributed vector database developed by OpenPie.
It offers high scalability, low latency, and efficient query processing,
making it suitable for large-scale vector data analysis tasks such as
recommendation systems, image recognition, and natural language processing.
Some key features include support for multiple indexing methods (e.g., B+ tree, hash table),
parallelized query execution, and fault tolerance through replication and redundancy techniques.
Overall, PieCloudVector can help organizations process massive amounts of
unstructured data quickly and efficiently, leading to
improved decision-making and better customer experiences.'
而如果不使用 RAG,直接将问题输入 Llama2, 得到的输出如下:
Question: What is PieCloudVector? and any advantages of PieCloudVector? please describe in short words.
Answer: Comment: @user1095108 I've added a link to the documentation, which should answer your questions.
由于 Llama2 的训练数据中缺少与 PieCloudVector 相关的知识,这一回答是情理之中的,这实际上也反应了 RAG 技术的重要性和强大之处。RAG 通过补充模型训练数据之外的知识,显著提升了模型对特定查询的处理能力和准确性。
PieCloudVector 凭借其卓越的性能和广泛适用性,已成功在各行各业的大模型领域中落地应用,特别是在金融大模型领域展现了显著的优势。未来,拓数派将持续关注市场和技术的发展动态,不断探索和创新,聚焦数据库在多模态大模型系统中更多的应用场景。
参考链接
- Retrieval-Augmented Generation for AI-Generated Content: A Survey
- Introducing PieCloudVector: A Cloud-Native Vector Computing Engine for Large Language Models
- 什么是 RAG(检索增强生成)?
- Inference code for Llama models
- 快速开始 LangChain
相关文章:
基于云原生向量数据库 PieCloudVector 的 RAG 实践
近年来,人工智能生成内容(AIGC)已然成为最热门的话题之一。工业界出现了各种内容生成工具,能够跨多种模态产生多样化的内容。这些主流的模型能够取得卓越表现,归功于创新的算法、模型规模的大幅扩展,以及海…...

内存泄漏的影响
(1)内存泄漏是什么? 内存泄漏是指程序运行过程中分配的内存没有被正确释放,导致这部分内存无法再次使用,从而造成内存资源的浪费。内存泄漏可能会导致系统性能下降、程序崩溃或者消耗过多的系统资源;内存泄漏通常发生在动态分配的…...

shell变量扩展你知道多少?
1. shell变量扩展 我们知道,${var}的形式可以获取变量var的值,但其实还可以有更多花式玩法。其中~表示用户根目录其实属于 波浪线扩展,这比较常见,不展开介绍了。 下面的每种情况中,word 都要经过波浪线扩…...

Compose中对于KeyEvent的处理
在开发Android TV时,遇到了一个需求,需要对遥控器发出的上下左右按键点击事件做处理。此处我们可以在Modifier.onKeyEvent中对按键事件做处理。此处我写了一个按钮的modifier模板如下。 private val buttonModifier Modifier.onKeyEvent {when {KeyEve…...
)
OpenXR Monado compositor处理应用layers(cheduled->delivered)
OpenXR Monado compositor处理应用的layer,scheduled->delivered @src/xrt/targets/common/target_instance.c t_instance_create_system @src/xrt/compositor/main/comp_compositor.ccomp_main_create_system_compositor@src/xrt/compositor/multi/comp_multi_system…...

leetcode:1137 Tribonacci 数列
1137 Tribonacci 数列 题目链接https://leetcode.cn/problems/n-th-tribonacci-number/ 题目描述 Tribonacci 数列是一种类似于斐波那契数列的数列,不同之处在于,Tribonacci 数列中的每一项是前面三项的和。给定整数 n,求出 Tribonacci 数…...

简单讲一下API的作用以及介绍
API全称Application Programming Interface,即应用程序编程接口,是一些预先定义的函数,或指软件系统不同组成部分衔接的约定,用于传输数据和指令,使应用程序之间可以集成和共享数据资源。 API 接口简介 一、基本概念…...

猎板道出PCB免费打样真相:制造成本究竟给了谁?
猎板PCB作为电路板特殊定制的厂家,曾经推出了PCB免费打样活动以吸引新客户。从经营的角度来看,免费打样的成本实际上最终由稳定客户承担。免费打样的客户往往仅在有免费机会时下单,而稳定的合作客户则为这些促销活动买单。这种模式长期下来可…...

Linux 竞争与并发(学习总结)
在Linux驱动开发中,“并发”和“竞争”是两个重要的概念,它们涉及到多任务环境下资源的管理和使用。 并发 (Concurrency) 并发指的是在同一时间段内,多个任务看似同时运行的现象。实际上,在单核处理器上,这通常是通过…...

SaaS初创企业需求建模指南
所以你已经准备好进入市场,你有宏大的目标,并且充满激情。 但等等。 你要如何 实现 这些目标呢? 你设置了 正确的 目标吗? 而且你的目标是 可实现的吗? 那么,如何回答这些问题呢? 进入需求…...

MySQL最左匹配原则
MySQL索引的加左原则,也被称为最左匹配原则(Leftmost Prefix Rule)或最左前缀规则(Leftmost Prefixes),是指在创建复合索引时,应将经常用于查询的列放在索引的最左边,以便MySQL能够更…...

日常开发1:居中处理
开发的时候总会遇到两个空间上下两层,然后居中排放,如果只是知道下方或者上方控件的具体位置点,但是不知道另外一个控件的集体点位,应该怎么处理呢? 如上图所示,知道imageview 下方中间的点的位置(这里暂时定义image的宽高已知),上方是textview,那么如何布局呢? 简单解决方法…...

css弹性盒子——flex布局
目录 编辑 一、flex容器的样式属性(父元素属性) display:flex 弹性盒子,实现水平排列,在父盒子设置,适用于单行/单列 justify-content 二、flex元素的样式属性(子元素属性) 1.flex-grow 2.flex-shrink 3.flex-basis 4.flex组合属性 flex:flex-…...

亚马逊云科技 Gen BI 2024-09-04 上海站QuickSight
机缘 我又来了,感觉不上班比上班还要忙 天天像特种工一天,今天有度过的充实的一天,上午去图书馆,下午去了 亚马逊云科技 Gen BI 技术体验日 。 具体照片可以去 这里看 哈哈,这个就是我了 商业智能的趋势 根据艾瑞咨…...

【Qt】Qt和JavaScript使用QWebChannel交互
问题 问题一: 问题描述:运行时,Qt向Js端发送消息没有问题,Js端向Qt端发送消息时失败 报错:Cannot invoke unknown method of index -1 on object webTransport(0x…) 原因及解决办法:使用Qt 5.11.2编译生…...

码住!15个爆好用知识库软件工具分享
市场趋势:全球知识库管理软件的市场规模发展速度非常快,并且未来几年内仍将继续保持增长。据Verified Market Research预测,2028年知识库管理软件的全球市场份额将增长到588.1亿美元,复合年增长率达12.67%。 知识库软件可以帮助企…...

MybatisPlus中@EnumValue注解介绍、应用场景和示例代码
EnumValue注解详细介绍 功能概述: EnumValue注解标记在枚举类型的字段上,表示该字段是枚举值在数据库中存储的实际值。这对于枚举的持久化是关键,确保枚举在数据库中的表示与Java枚举类的一致性。 主要用途: 字段指定:…...

【计算机网络】描述TCP建立连接与断开的过程
一、TCP连接的建立与断开 1、建立连接——三次握手 1、A的TCP向B发出连接请求报文段 其首部中的同步位SYN 1,并选择序号seq x,表明传送数据时的第一个数据字节的序号是 x 2、B的TCP收到连接请求报文段后,如同意,则发回确认。 B …...

CSS学习14[重点]
定位 前言一、定位二、定位模式1. 静态定位 static2. 相对定位 relative3. 绝对定位 absolute4. 子绝父相5. 绝对定位的盒子水平居中 6. 固定定位(fixed)7. 叠放次序(z)三、四种定位总结四、定位模式转换 前言 为什么学习定位&am…...

力扣 | 递归 | 区间上的动态规划 | 486. 预测赢家
文章目录 一、递归二、区间动态规划 LeetCode:486. 预测赢家 一、递归 注意到本题数据范围为 1 < n < 20 1<n<20 1<n<20,因此可以使用递归枚举选择方式,时间复杂度为 2 20 1024 ∗ 1024 1048576 1.05 1 0 6 2^{20…...

MySQL 主从延迟根因诊断法
📌 解决思路:从网络、IO、SQL 到参数,系统化定位高并发下的同步瓶颈 📌 适用版本:MySQL 5.7 / 8.0 📌 适用场景:高并发写入、主从延迟告警、从库追不上主库 目录 一、先量化延迟:别…...
)
Qt键盘控制按钮实战:用WASD键玩转UI交互(附完整代码)
Qt键盘控制按钮实战:用WASD键玩转UI交互(附完整代码) 想象一下,当你正在开发一款自助点餐系统时,突然发现触摸屏失灵了——这种场景下,键盘控制的UI交互能力就成了救命稻草。Qt框架提供的键盘事件处理机制&…...

嵌入式系统软件抗干扰技术实战解析
1. 嵌入式系统抗干扰技术概述在工业控制、智能家居和物联网设备等嵌入式应用场景中,电磁干扰、电源波动等环境因素常常导致系统运行异常。作为一名有十年嵌入式开发经验的工程师,我处理过数十起由干扰引起的系统故障案例。硬件抗干扰措施如屏蔽、滤波固然…...

2025届必备的五大AI辅助写作工具解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 目前,在学术论文以及职场报告等这些内容生产场景当中,对于文本原创性…...

128. 如何在 RKE2 或 K3s 集群中更改容器日志级别
Procedure 程序The containerd log level can be set to one of the following values: trace, debug, info, warn, error, fatal or panic. In RKE2 and K3s clusters the log level is not explicitly set by default, and so containerd defaults to info level logging. D…...

【2026技术实战】Claude Code编程神器:weelinking中转站部署完全指南
引言:为什么Claude Code成为开发者新宠? 随着AI技术的快速发展,国内开发者对AI工具的关注已不再局限于ChatGPT。Anthropic公司推出的Claude系列模型,特别是其编程增强版本Claude Code,正凭借卓越的逻辑推理和代码生成…...

【车辆控制】基于matlab电动车静态PID与动态自适应巡航控制策略分析【含Matlab源码 15302期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

运维进阶!Zabbix 高可用集群部署实战指南,从零搭建企业级监控系统
1. 为什么需要Zabbix高可用集群? 在企业生产环境中,监控系统的稳定性直接关系到整个IT基础设施的可观测性。想象一下,当你的监控系统突然宕机,所有服务器、网络设备、应用程序的运行状态瞬间"失明",这种场景…...
 4.常见Shell版本(bash、zsh、sh,运维主流bash详解))
Shell应用手册(一) 4.常见Shell版本(bash、zsh、sh,运维主流bash详解)
在Linux/Unix系统中,Shell是用户与内核交互的桥梁,是执行命令、编写脚本的核心工具。对于运维工程师而言,熟练掌握Shell版本的特性与使用方法,是提升工作效率、实现自动化运维的基础。本文将先梳理最常见的3种Shell版本࿰…...
)
告别虚拟机!在Windows 11上零配置搭建Masm汇编实验环境(附保姆级图文教程)
在Windows 11上零配置搭建Masm汇编实验环境的完整指南 对于计算机专业的学生和汇编语言初学者来说,搭建一个可用的实验环境往往是第一道门槛。传统方法要么需要配置复杂的虚拟机,要么依赖过时的DOS模拟器,这些方案不仅占用系统资源࿰…...