深度学习 --- VGG16能让某个指定的feature map激活值最大化图片的可视化(JupyterNotebook实战)
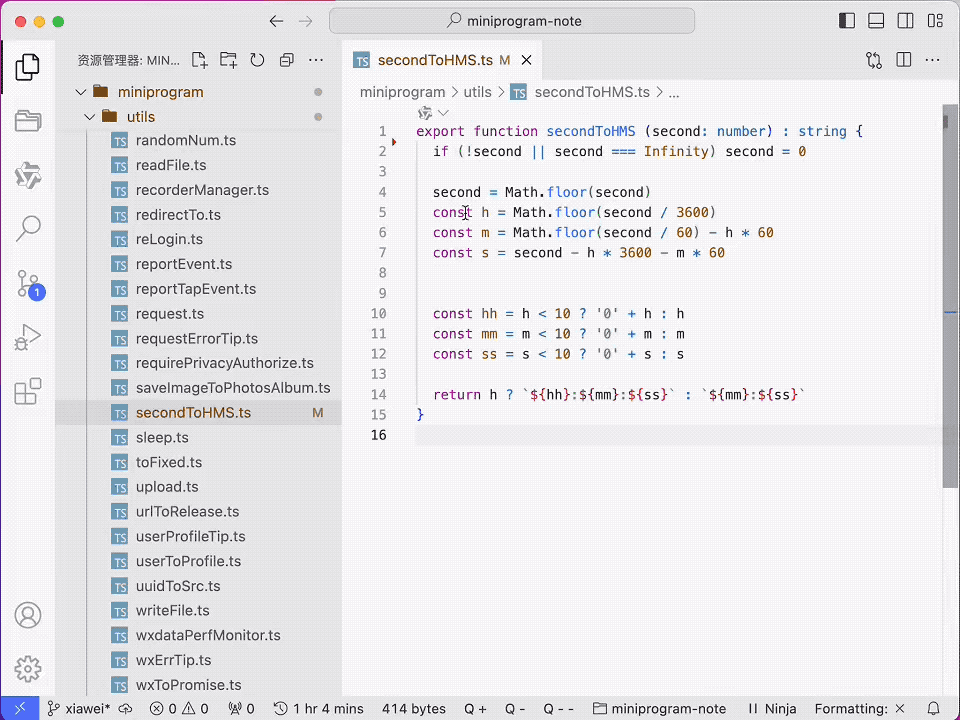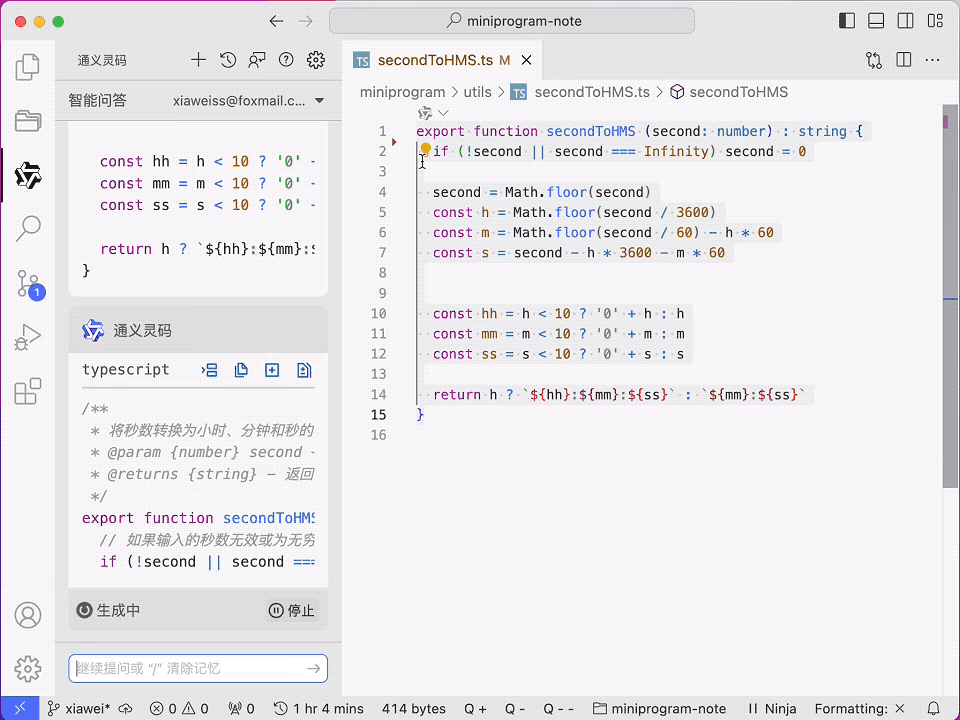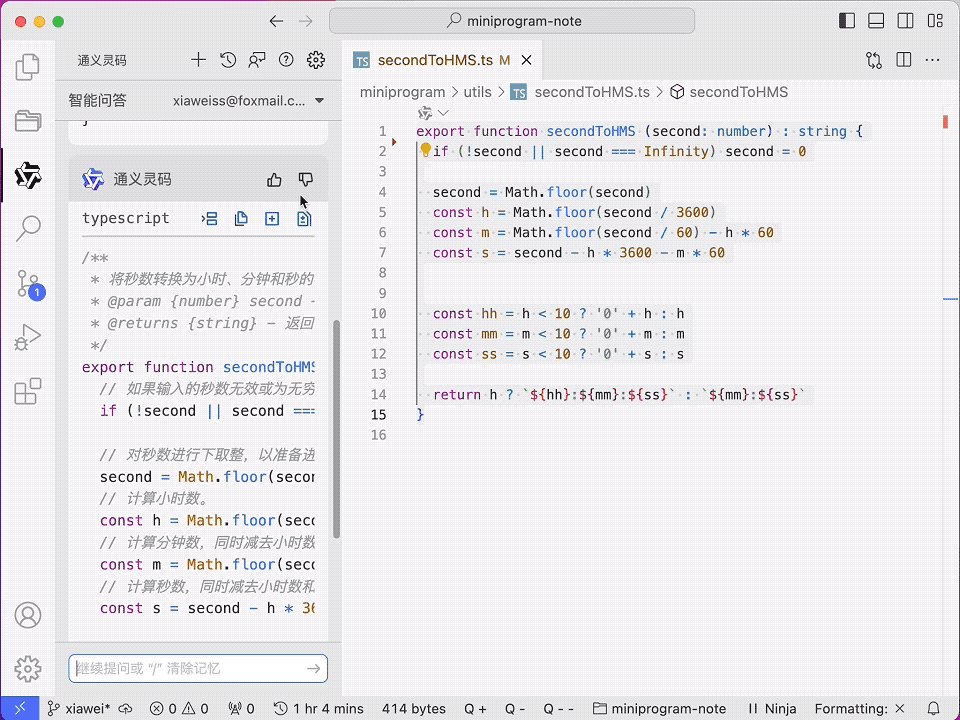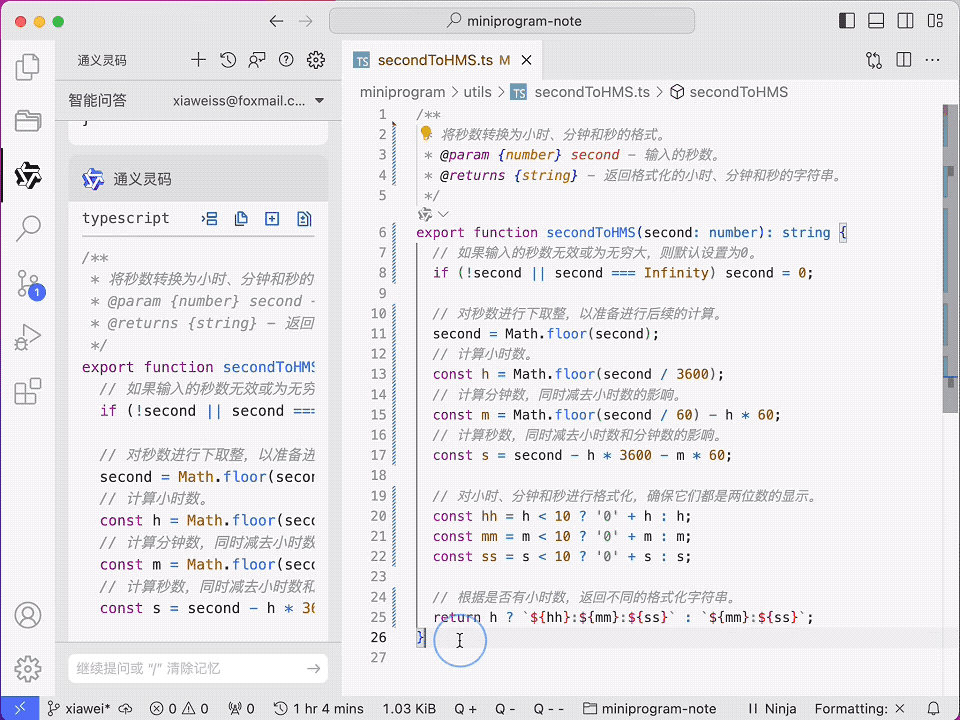
VGG16能让某个指定的feature map激活值最大化图片的可视化
在前面的文章中,我用jupyter notebook分别实现了,预训练好的VGG16模型各层filter权重的可视化和给VGG16输入了一张图像,可视化VGG16各层的feature map。深度学习 --- VGG16卷积核的可视化(JupyterNotebook实战)-CSDN博客文章浏览阅读653次,点赞11次,收藏8次。本文是基于JupyterNotebook的VGG16卷积核的可视化实战,有代码也有详细说明https://blog.csdn.net/daduzimama/article/details/141460156
深度学习 --- VGG16各层feature map可视化(JupyterNotebook实战)-CSDN博客文章浏览阅读1k次,点赞16次,收藏24次。在VGG16模型中输入任意一张图片VGG16模型就能给出预测结果,但为什么会得到这个预测结果,通过观察每层的feature map或许有助于我们更好的理解模型。https://blog.csdn.net/daduzimama/article/details/140279255
在这篇文章中需要可视化的是看看究竟什么的图像会令众多feature map/activation map中的某个activation map的激活值最大化。例如,看看什么样的图像会让block2_conv2中的第123个feature map的激活值最大化。
这个算法的整体思路如下:
1,利用已有的不包含顶层的VGG16模型创建一个输出为指定层指定feature map的新模型
2,创建一个图像尺寸和模型输入层维度相同的随机噪声图,并假设他就是那个能够令指定feature map激活最大化的输入图像作为初值。
3,定义损失函数,这个损失函数的输入是刚才创建随机噪声图像,输出为指定feature map的激活值总和。
4,创建优化器使用梯度上升的反向传播方式,使得损失函数的函数值最大化。逐步迭代,最终把原始的随机噪声图像变成我们想要的能够最大化feature map的输入图像。
1,导入需要用到的库函数
import tensorflow as tf
print(tf.__version__)
print(tf.keras.__version__)from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input
import numpy as np
import matplotlib.pyplot as plt2,加载不包括顶层VGG16的模型
model=VGG16(weights='imagenet',include_top=False)
model.summary()# 获取该模型的总层数
total_layers = len(model.layers)# 输出总层数
print(f"模型的总层数为: {total_layers}")# 输出每一层所对应的名字便于后续选择feature map时使用
for i in range(total_layers):print(f"第{i}层是{model.layers[i].name}")
3,定义损失函数
定义损失函数也就是定义feature map关于输入图像的函数。因此,损失函数的输入是我们后面自定义的模型model,输入图像和指定feature map的index。输出是整张指定feature map值的均值。
# 损失函数的输入为你所使用的model,输入图像和指定feature map的index,输出是指定层的某个卷积核的激活值的均值
def loss_function(model,input_image,feature_map_num):activations = model(input_image)#获得input_image在新模型中产生的所有特征图'''activations 是一个四维张量,其维度如下:第一个维度 (batch size): 代表输入批次的大小。通常情况下,如果只输入了一张图像,这个维度的值为 1。第二个维度 (height): 代表特征图的高度。随着网络层数的增加,通常由于池化层(Pooling Layer)的作用,这个维度会逐渐减小。第三个维度 (width): 代表特征图的宽度。和高度一样,宽度通常也会随着网络的加深而减小。第四个维度 (channels/filters): 代表特征图的通道数,或者说在当前层中使用的滤波器的数量。这个维度表示在每一层中所提取的不同特征的数量。'''loss = tf.reduce_mean(activations[:, :, :, feature_map_num])return loss”activations = model(input_image)“这句话的意思是:把随机生成的输入图像喂给新建的模型计算,输出相应层所有的output,output即feature map。并且把指定层所有的feature map保存在activations中。
“loss = tf.reduce_mean(activations[:, :, :, feature_map_num])”这句话的意思是:根据函数输入的feature_map_num,在activations选择当前层指定的feature map,也就是我们需要最大化的那个feature map,并计算这个张量的均值。
最终把整张feature map的均值通过loss函数传出去。
上述过程如果用数学模型来表示的话大致可写成(这里不一定严谨,仅供参考):
这样看来,损失函数L是input image的复合函数,feature map是input image的函数。
4,定义计算梯度的函数
梯度是用于反向传播的,这里所计算的梯度是损失函数相对于输入图像的梯度。
def gradient_function(model,image,feature_map_num):#创建 tf.GradientTape 对象:#TensorFlow 的 tf.GradientTape 是一个自动微分工具,它可以记录运算过程中涉及的所有变量,并计算这些变量相对于某个损失函数的梯度。with tf.GradientTape() as tape:#监视输入图像:这里明确告诉 GradientTape 需要监视 image 这个张量,确保后续可以计算相对于 image 的梯度。tape.watch(image)#计算损失函数loss = loss_function(model,image,feature_map_num)#通过 tape.gradient() 计算损失 loss 相对于输入图像 image 的梯度。#这会返回一个张量 gradient,表示如何调整输入图像以最大化或最小化损失。 gradient = tape.gradient(loss, image)return loss,gradient计算损失函数相对于输入图像的梯度的目的是为了通过反向传播,也就是梯度上升,不断地优化输入图像。这一过程也可以用数学公式简单的表示如下:
因此,第一步是调用先前定义的损失函数计算loss。

第二步就调用tensorflow自带的计算梯度的函数tf.GradientTape去计算梯度。其中,tape.gradient的第一个输入是损失函数的值loss,第二个要输入的变量是损失函数相对于谁的梯度,比如说在本例中要计算损失函数相对于输入图像input image的梯度,所以这里输入的就是随机初始化的input image。

5,定义用于优化图像显示效果的函数
通过梯度上升反向传播得到的能够令某个feature map最大化的input image无法直接通过imshow函数显示,因此,这里定义了一个专门针对无法显示问题的优化函数。
def proc_img(input_image):# input_image.numpy(): 将 TensorFlow 张量转换为 NumPy 数组。# .squeeze(): 移除数组中维度为1的条目。例如,(1, 224, 224, 3) 会变成 (224, 224, 3)。这一步是为了去除批量维度,使图像的形状更适合显示。input_image = input_image.numpy().squeeze()#print(f"range of result image:[{input_image.min(),input_image.max()}]")# np.clip(optimized_image, 0, 255): 将图像像素值限制在 0 到 255 的范围内。优化过程中,像素值可能会超出这个范围,这一步将其剪切回有效范围。# .astype('uint8'): 将数组数据类型转换为 uint8,这是图像数据的标准类型,确保图像可以正确显示。input_image = np.clip(input_image, 0, 255).astype('uint8')return input_image优化显示图像主要分四步:
1,通过梯度上升优化后的图像是一个tensorflow张量,tensorflow张量是无法通过imshow直接显示的。这里的第一步是把tensorflow张量转换成Numpy数组。
2,我们之前创建的tensorflow张量是一个1x224x224x3的4维向量,四维向量是无法显示的,因此在这里通过squeeze函数,去掉第一个维度,得到224x224x3的向量。
3,把图像像素值的范围限制到0~255之间。
4,将图像的数据类型改成uint8。
6,创建输出层为feature map的新模型
#从model_without_top中选择新模型的输出层
layer_num=1#获得指定层的全部输出/feature map
layer_output=model_without_top.layers[layer_num].output
print(layer_output.shape)# 创建一个新的模型,这个模型的输入层等同于 VGG16 模型的输入层,而输出是指定层的所有特征图
activation_model = tf.keras.Model(inputs=model_without_top.input, outputs=layer_output)
activation_model.name="activation model"
activation_model.summary()# 获取该模型的总层数
total_layers = len(activation_model.layers)# 输出总层数
print(f"模型的总层数为: {total_layers}\n")使用keras的Model函数构建自定义模型,这个模型的输入层和前面已经创建好的,不带顶层的,VGG16模型的输入层一样。这个模型的输出则是指定层的feature map,同样也是来自于前面创建好的VGG16模型"model without top"。这就是说,如果使用该模型进行计算,你是无法访问中间层的中间结果的。你指定的是哪层,就
熟练了以后,上述代码可简写为:
#从model_without_top中选择新模型的输出层
layer_num=1# 创建一个新的模型,这个模型的输入层等同于 VGG16 模型的输入层,而输出是指定层的所有特征图
activation_model = tf.keras.Model(inputs=model_without_top.input, outputs=model_without_top.layers[layer_num].output)
activation_model.name="activation model"
activation_model.summary()# 获取该模型的总层数
total_layers = len(activation_model.layers)# 输出总层数
print(f"模型的总层数为: {total_layers}\n")
新模型被命名为activation model。

7,获得能够令当前层指定feature map最大化的输入图像
# 固定随机化种子
np.random.seed(42)
tf.random.set_seed(42)# 在指定层中选择指定的feature map
feature_map_num=4# 用随机数初始化图像,初始值的范围为 [108, 148]。
random_InputImg = tf.Variable(np.random.random((1, 224, 224, 3)) * 20 + 128, dtype=tf.float32)#学习率
lr=5.1# 创建优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr)# 迭代次数
its = 30# 开始梯度上升优化
for i in range(its):loss,gradients = gradient_function(activation_model,random_InputImg,feature_map_num)# apply_gradients的主要功能是将梯度应用到相应的变量上,以更新这些变量的值,从而在训练过程中最小化或最大化目标函数。optimizer.apply_gradients([(-gradients, random_InputImg)])# 打印每轮的损失值print(f"Epoch {i+1}/{its}, Loss: {loss.numpy()}")# 改进显示效果后的图像
MaxActivation_Img=proc_img(random_InputImg)# 显示结果
plt.figure(figsize=(8, 8))
plt.imshow(MaxActivation_Img)
plt.title(f'MaxActivation Image for Filter {feature_map_num} in Layer {activation_model.layers[layer_num].name}')
plt.show() 这里选择能够让block1_conv1层的64个feature map中的第0个feature map激活值最大化的图像长什么样?
需要输入的参数有三个,一是用“feature_map_num”选择你希望让该模型的哪个feature map的值最大化?二是学习率“lr”,它可以控制梯度上升算法的迭代速度。学习率越高,迭代速度越快,但太快了也有可能引发别的问题。三是迭代次数"its",迭代次数越多,模型学习和迭代的次数就越多。

这里用到了前面定义好的三个函数gradient_function(计算梯度),loss_function(计算损失函数的函数值)和proc_img(优化),最后用keras自带的优化器Adam中的apply_gradients函数使用前面计算好的gradient更新random_InputImg。
若令feature_map_num=0,lr=5.1,its=30,则会得到如下的迭代结果:

可见,每次迭代损失函数的值Loss都在持续增长,经过30次迭代后,从最开始的8.1一直增长到290。对图像可视化后得到如下结果:

这就是说,如果输入图像长的像上面这个样子,则能使得block1_conv1层的第0个feature map的激活值最大化。
8,测试图像
通过前面一系列的操作,已经得到了能够令block1_conv1层的第0个feature map的激活值最大的图像。现在,我打算把这个刚刚得到的这个图像喂到模型中,看看在所有的64个feature map中,第0个filter所产生的feature map是足够大?如果相应feature map的激活值够大,那他的激活值是最大的吗?其他的feature map表现又当如何呢?
# 把生成的图像喂给模型进行预测
result_features=activation_model.predict(random_InputImg)# 设置字体为 SimHei (黑体)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 避免中文字体显示不正常
plt.rcParams['axes.unicode_minus'] = False# 绘制前8x8个特征图
N=64
plt.figure(figsize=(35,35))
for i in range(N):plt.subplot(N//8+1, 8, i+1) plt.imshow(result_features[0, :, :, i]) # 显示特征图mean_feature=np.mean(result_features[0, :, :, i])# 计算当前feature map的均值#plt.title(f"当前feature map的mean={mean_feature}")if mean_feature>=770:plt.title(f"当前feature map的mean={mean_feature}")plt.axis('off') # 隐藏坐标轴
plt.show()以下是具体的计算结果:

(这是64个feature map及其对应的feature map的均值)
下图为放大后的前两行feature map局部,其中用红框框出来的就是index=0的第0个feature map及其均值。 图中所显示的均值为300,这和前面经过多次迭代后的loss=290接近。

至于其他各个feature map的mean究竟是什么样的,大家可以自己看看。就我自己这边的观察,我发现其他feature map的均值并不都是很小的,也有一些是200多的,这一点让我个人觉得似乎不太理想,也就是说实际上各个feature map之间还是有一定相关性的。
为了看看第0个feature map的均值是不是这64个中最大的,以及,如果有比他大的,还有哪些呢?可以对之前code中的注释部分做如下修改,这段if语句的目的是在subplot的时候,只在均值大于300个子图上显示title。

最终得到如下结果,可见在64个feature map中,index为0的feature map确实是最大的。注意,并不是说前面生成的input image必须要让预先指定feature map是所有feature map中最大才行,只要指定位置的feature map够大就好了。

事实上,上面的那个例子还是比较特殊的,我这里说的特殊主要是指经过梯度上升迭代后产生的图像使得第0个feature map的值是64个中最大的。实际上,更为普遍的现象是,经过迭代所产生的图像只会使得指定位置的feature map最大化,至于其他feature map的值究竟是大还是小,这两件事是相互独立的。下面我再多举两个例子说明。
例1:block1_conv1,feature map index=4

修改参数feature_map_num为4,并全部重新运行所有的cell,得到如下结果。

经过30次梯度上升迭代后,损失函数的值增加到了90。相应的图像如下图所示:

打印所有feature map的均值,并查看对应位置的均值。

当前feature map的均值为93.5和前面计算的90比较接近。

但如果我如法炮制,通过if语句,只让均值大于93的feature map显示title会怎么样呢?还是只有index为4的feature map上才会显示title吗?让我们拭目以待。

可以看到,大量feature map都显示了title,这说明他们的均值都大于93.有的甚至比93要大很多,比如说用在下图中用红色方框框出来的图。

他们两个一个的feature map是265,另一个更是高达355。

这恰好从另一个角度说明了我们最大化指定feature map的实验目的:
那就是只保证程序中指定的feature map最大化,至于当前层的其他feature map则不在我们的考虑范围之内。因为,很有可能能够令index=4的feature map最大化的输入图像,能够令index=12,30...的feature map也很大! 这里index=4的feature map并不是个例,下面我们再多看一个例子。
例2:block1_conv1,feature map index=8
其他条件不变,把feature map num改成8。

经过30次梯度上升迭代后,损失函数的值增加到了730。相应的图像如下图所示:


通过显示所有feature map的title,并打印所有feature map所对应的mean可知,把前面计算好的图像喂给model后,在对应位置的feature map=310。

现在把if函数显示title的阈值改为310,得到如下结果:

可见,依然激活了多个不同位置的feature map,且均值都在310以上。
9,定义能够令多个位置的feature map最大化的批处理函数
def activation_max_images(model,layer_num,lr,its):# 创建一个新的模型,这个模型的输入是 VGG16 模型的输入,而输出是指定层的特征图Activation_model = tf.keras.Model(inputs=model.input, outputs=model.layers[layer_num].output)Activation_model.summary()# 创建用于保存output image的列表MaxActivation_Imgs=[]# 创建用于保存loss的列表Final_Loss=[]for feature_map_num in range(N):# 初始化图像np.random.seed(42) # 固定随机种子random_InputImg = tf.Variable(np.random.random((1, 224, 224, 3)) * 20 + 128, dtype=tf.float32)print(f"process image:{feature_map_num}")# 创建优化器对象optimizer = tf.keras.optimizers.Adam(learning_rate=lr)for i in range(its):loss,gradients = gradient_function(Activation_model,random_InputImg,feature_map_num)optimizer.apply_gradients([(-gradients, random_InputImg)])# 梯度上升使用的是负的gradients,因为优化器本身是基于梯度下降的逻辑。# 打印每轮的损失值print(f"Epoch {i+1}/{its}, Loss: {loss.numpy()}")Final_Loss.append(loss.numpy())print(f"process image:{feature_map_num},done!")# 改进显示效果MaxActivation_Img=proc_img(random_InputImg)MaxActivation_Imgs.append(MaxActivation_Img)return MaxActivation_Imgs,Activation_model,Final_Lossactivation_max_images函数能够同时处理多个指定位置的feature map,主要是能够一次性处理整个layer的feature map,并返回能够让这些feature map最大化的图像。
你需要输入模型类型model,指定层layer_num,学习率lr和迭代次数its。该函数所返回的是能够令指定feature map最大化的图像包。
10,输出能够令block1conv1中前8x8个activation map激活值最大化的输入图像
生成图像:
N=64
layer_num=1# 选择需要最大化的层
iter_num=20#迭代次数
lr=2.5#学习率MaxAct_imgs,New_model,LossList=activation_max_images(model_without_top,layer_num,lr,iter_num)
显示图像:
fig,axs=plt.subplots(N//8,8,figsize=(15,15))
for i in range(N):row=i//8col=i%8axs[row,col].imshow(MaxAct_imgs[i])axs[row,col].axis('off')axs[row,col].set_title(f"Loss={LossList[i]:0.2f}")plt.suptitle(f'Input images that maximize the feature map for Layer: {New_model.layers[layer_num].name}',fontsize=36)
block1conv1:

注意:这里有几个feature map无法通过反向传播得到我们想要的图像,通过观察发现这些图像的初始损失函数为0,且梯度也为0。 这可能是因为初始图像无法激活该特征图,如果特征图在初始图像上没有激活(激活值为0),那么即使经过多次迭代,损失函数仍然可能保持为0,因为输入图像不包含能够激活该特征图的显著特征。
11,输出能够令block1conv2中前8x8个activation map激活值最大化的输入图像
layer_num=2MaxAct_imgs,New_model,LossList=activation_max_images(model_without_top,layer_num,lr,iter_num)注意,这里layer的index可以参考之前打印的log。


显示图像:
fig,axs=plt.subplots(N//8,8,figsize=(15,15))
for i in range(N):row=i//8col=i%8axs[row,col].imshow(MaxAct_imgs[i])axs[row,col].axis('off')axs[row,col].set_title(f"Loss={LossList[i]:0.2f}")plt.suptitle(f'Input images that maximize the feature map for Layer:{New_model.layers[layer_num].name}',fontsize=36)block1conv2:

值得注意的是,由于所有feature map的迭代都使用了同一个学习率和相同的迭代次数,使得有些图像的loss长的很大,比如1000+,相应的图像也很清晰。而有的loss比较小,或者说针对这个feature map还不够大,只能生成部分的输出图像(例如我用红框框出来的第63幅图)。这一现象在后续层的处理中会更为明显。
Tips:
block1之所以分成两层,主要是因为多加一次3x3的卷积,感受野要几乎能扩大一倍。一个 3x3 的卷积层的感受野是 3x3。两个堆叠的 3x3 卷积层的感受野是 5x5。三个堆叠的 3x3 卷积层的感受野是 7x7。
12,输出能够令block2conv2中前8x8个activation map激活值最大化的输入图像
为了避免前面遇到的因为loss涨的不够多导致图像无法完整显示的问题,我在这里预先把学习率从原来的2.5涨到了6.5。
layer_num=5
lr=6.5MaxAct_imgs,New_model,LossList=activation_max_images(model_without_top,layer_num,lr,iter_num)
fig,axs=plt.subplots(N//8,8,figsize=(15,15))
for i in range(N):row=i//8col=i%8axs[row,col].imshow(MaxAct_imgs[i])axs[row,col].axis('off')axs[row,col].set_title(f"Loss={LossList[i]:0.2f}")plt.suptitle(f'Input images that maximize the feature map for Layer:{New_model.layers[layer_num].name}',fontsize=36)block2conv2:
从结果上看,虽然增大了学习率,可依然无法满足部分feature map梯度上升的需求。部分无法完全显示的图像我已用红框在下图中框出。

为了克服这个问题,我在又重新定义了一个新的批处理函数。与原来的批处理不同的是,我在新函数迭代的for循环过程中,我增加了一个if判断,并设置了一个用于判断loss的阈值。这个设计的出发点有两个,(在相同的迭代次数和学习率下)一个是能够保证原来能够正常显示的图像提前结束循环,另一个是给不能正常显示的图像的损失函数loss有足够的增长空间。
改进后的批处理函数:
def activation_max_images_th(model,layer_num,lr,its,th):# 创建一个新的模型,这个模型的输入是 VGG16 模型的输入,而输出是指定层的特征图Activation_model = tf.keras.Model(inputs=model.input, outputs=model.layers[layer_num].output)Activation_model.summary()# 创建用于保存output image的列表MaxActivation_Imgs=[]# 创建用于保存loss的列表Final_Loss=[]for feature_map_num in range(N):# 初始化图像np.random.seed(42) # 固定随机种子random_InputImg = tf.Variable(np.random.random((1, 224, 224, 3)) * 20 + 128, dtype=tf.float32)print(f"process image:{feature_map_num}")# 创建优化器对象optimizer = tf.keras.optimizers.Adam(learning_rate=lr)for i in range(its):loss,gradients = gradient_function(Activation_model,random_InputImg,feature_map_num)optimizer.apply_gradients([(-gradients, random_InputImg)])# 梯度上升使用的是负的gradients,因为优化器本身是基于梯度下降的逻辑。# 打印每轮的损失值print(f"Epoch {i+1}/{its}, Loss: {loss.numpy()}")if loss >=th:breakelif loss<=0.:breakFinal_Loss.append(loss.numpy())print(f"process image:{feature_map_num},done!")# 改进显示效果MaxActivation_Img=proc_img(random_InputImg)MaxActivation_Imgs.append(MaxActivation_Img)return MaxActivation_Imgs,Activation_model,Final_Loss调用新批处理函数,并设置很大的学习率和很高的阈值。这里的学习率lr和损失函数阈值th需要反复观看结果,反复调试才有了下面code中的值。推荐读者自行摸索!
layer_num=5
lr=52.5
iter_num=50
th=30000MaxAct_imgs,New_model,LossList=activation_max_images_th(model_without_top,layer_num,lr,iter_num,th)下面是处理结果,为了能让那些loss增长很慢的feature map的损失函数增加的足够高,我所使用的策略是在维持一个比较大学习率基础上(保证了损失函数的增长速度),尽可能的增加迭代次数(保证了增加次数),通过不断调试最终得到了下面的结果,虽然,乍一眼看上去图像显示的比较夸张!
在后面的文章中,我会优先选择视觉上稍微看起来比较舒服的结果,而不是这种看起来特别极端的效果。

block2conv1:
为了比对在同一层中,conv1与conv2的差异,这里顺便把block2conv1的结果也画出来。可以看到的是相对于block2conv2层,block2conv1层中有很多没有被激活的feature map,这说明这些这些位置所关注的特征/或者说是希望提取的特征,不在随机初始化的输入图像中。

13,输出能够令block3conv3中前8x8个activation map激活值最大化的输入图像
使用传统批处理函数,lr=2.5,iter_num=20。
By the way,随着网络层数深度的增加,计算所花费的时间也会越来越多。
layer_num=9
lr=2.5
iter_num=20
th=80000MaxAct_imgs,New_model,LossList=activation_max_images(model_without_top,layer_num,lr,iter_num)
#MaxAct_imgs,New_model,LossList=activation_max_images_th(model_without_top,layer_num,lr,iter_num,th)
block3conv3:
计算结果如下:同样的,由于对所有的feature map使用了同样的迭代次数和相同的学习率,使得有些学习速度慢,损失函数较小的图像只显示了部分内容。

使用带有阈值判断的批处理函数,lr=22.5,iter_num=30,th=18000。看看下面这些能够令feature map激活最大的图像们是不是很美?!

block3conv1 :


block3conv2:


14,输出能够令block4conv1中前8x8个activation map激活值最大化的输入图像
layer_num=11
lr=15.5
iter_num=50
th=6000MaxAct_imgs,New_model,LossList=activation_max_images_th(model_without_top,layer_num,lr,iter_num,th)

block4conv2:


block4conv3:


实验进行到这里可以看到,随着希望最大化feature map的层数进行的越来越深,就会有越来越多的feature map的没有被激活,这通常是由于以下这些原因:
1. 深层卷积层的特征选择性
深层卷积层的特征图通常是对较高阶特征的响应,比如复杂的形状、纹理或对象的组合。在这些深层中,卷积核学会了识别特定的复杂特征,而这些特征在随机初始化的图像中可能并不存在或难以被识别出来。因此,这些特征图可能无法对初始图像作出响应,导致激活值为零。
2. 特征图的稀疏性
随着网络的加深,卷积层的特征图通常会变得更加稀疏。也就是说,特征图中非零激活的区域会变得越来越少,因为深层卷积核倾向于只对某些特定的复杂特征有强烈响应。对于一个随机初始化的图像,深层特征图可能没有足够的信息来激活,这导致激活值为零。
15,输出能够令block5conv1中前8x8个activation map激活值最大化的输入图像
layer_num=15
lr=25.5
iter_num=30
th=6000MaxAct_imgs,New_model,LossList=activation_max_images_th(model_without_top,layer_num,lr,iter_num,th)
block5conv2:

block5conv3:

(全文完)
--- 作者,松下J27
参考文献(鸣谢):
1,代码实战-可视化使VGG16各卷积层激活最大的原始图像_哔哩哔哩_bilibili
2,Stanford University CS231n: Deep Learning for Computer Vision
3,可视化卷积神经网络_哔哩哔哩_bilibili
(配图与本文无关)
版权声明:所有的笔记,可能来自很多不同的网站和说明,在此没法一一列出,如有侵权,请告知,立即删除。欢迎大家转载,但是,如果有人引用或者COPY我的文章,必须在你的文章中注明你所使用的图片或者文字来自于我的文章,否则,侵权必究。 ----松下J27
相关文章:
深度学习 --- VGG16能让某个指定的feature map激活值最大化图片的可视化(JupyterNotebook实战)
VGG16能让某个指定的feature map激活值最大化图片的可视化 在前面的文章中,我用jupyter notebook分别实现了,预训练好的VGG16模型各层filter权重的可视化和给VGG16输入了一张图像,可视化VGG16各层的feature map。深度学习 --- VGG16卷积核的可…...

1990-2022年各地级市gdp、一二三产业gdp及人均gdp数据
1990-2022年各地级市gdp、一二三产业gdp及人均gdp数据 1、时间:1990-2022年 2、来源:城市统计年鉴 3、指标:年度、城市名称、城市代码、城市类别、省份标识、省份名称、国内生产总值/亿元、第一产业占GDP比重(%)、第二产业占GDP比重(%)、第…...

c++ 原型模式
文章目录 什么是原型模式为什么要使用原型模式使用场景示例 什么是原型模式 用原型实例指定创建对象的种类,并通过拷贝这些原型创建新的对象,简单理解就是“克隆指定对象” 为什么要使用原型模式 原型模式(Prototype Pattern)是…...

论tomcat线程池和spring封装的线程池
Tomcat 中的线程池是什么? 内部线程池:Tomcat 确实有一个内部的线程池,用于处理 HTTP 请求,通常是org.apache.tomcat.util.threads.ThreadPoolExecutor 类的实例。这个线程池专门用于处理进入的 HTTP 请求和发送响应。可以通过 T…...

阿里P7大牛整理自动化测试高频面试题
最近好多粉丝咨询我,有没有软件测试方面的面试题,尤其是Python自动化测试相关的最新面试题,所以今天给大家整理了一份,希望能帮助到你们。 接口测试基础 1、公司接口测试流程是什么? 从开发那边获取接口设计文档、分…...

vue如何实现路由缓存
(以下示例皆是以vue3vitets项目为例) 场景一:所有路由都可以进行缓存 在渲染路由视图对应的页面进行缓存设置,代码如下: <template><router-view v-slot"{ Component, route }"><transiti…...

基于Openjdk容器打包运行jar程序
文章目录 应用场景基于Openjdk容器打包运行jar程序1.编译项目成jar包2.构建Dockerfile文件精简版-含jar包精简版-不含jar包带注释版-含jar包 3.编译Dockerfile成镜像。4.运行镜像: 应用场景 部署多版本jdk的应用程序。 基于Openjdk容器打包运行jar程序 1.编译项目…...

DNN学习平台(GoogleNet、SSD、FastRCNN、Yolov3)
DNN学习平台(GoogleNet、SSD、FastRCNN、Yolov3) 前言相关介绍1,登录界面:2,主界面:3,部分功能演示如下(1)识别网络图片(2)GoogleNet分类…...
)
HTTP协议(超文本传输协议)
HTTP请求消息 http请求消息组成: 请求行 :包含请求的方法 操作资源的地址 协议的版本号 http请求方法: GET:从服务器获取资源 POST:添加资源信息 PUT:请求服务器更新资源信息 DELETE:请…...
)
FFmpeg的日志系统(ubuntu 环境)
1. 新建.c文件 vim ffmpeg_log.c2. 输入文本 #include<stdio.h> #include<libavutil/log.h> int main() {av_log_set_level(AV_LOG_DEBUG);av_log(NULL,AV_LOG_INFO,"hello world");return 0; }当log level < AV_LOG_DEBUG 都可以印出来 #define A…...

浅析VO、DTO、DO、PO
一、概念介绍 POJO(plain ordinary java object) : 简单java对象,个人感觉POJO是最常见最多变的对象,是一个中间对象,也是我们最常打交道的对象。一个POJO持久化以后就是PO,直接用它传递、传递…...

android kotlin基础复习 enum
1、kotlin中,关键字enum来定义枚举类型。枚举类型可以包含多个枚举常量,并且每个枚举常量可以有自己的属性和方法。 2、测试代码: enum class Color{RED,YELLOW,BLACK,GOLD,BLUE,GREEN,WHITE }inline fun <reified T : Enum<T>>…...

个股场外期权怎么交易?场外期权交易流程是怎样的?
今天带你了解个股场外期权怎么交易?场外期权交易流程是怎样的?个股场外期权是一种非标准化的期权合约,通常在场外市场(OTC市场)由金融机构和投资者之间进行交易。 场外个股期权主要功能 风险管理: 帮助投…...

企业选ETL还是ELT架构?
作为数据处理的重要工具,ETL工具被广泛使用,同时ETL也是数据仓库中的重要环节。本文将从解释ETL工具是怎么处理数据,同时介绍ELT和ETL工具在企业搭建数据仓库的重要优势。 一、什么是ETL? ETL是Extract-Transform-Load的缩写,将…...

【Spring Boot 3】【Web】同时启用 HTTP 和 HTTPS
【Spring Boot 3】【Web】同时启用 HTTP 和 HTTPS 背景介绍开发环境开发步骤及源码工程目录结构背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是…...

【Android】最好用的网络库:Retrofit
最好用的网络库:Retrofit 文章目录 最好用的网络库:RetrofitRetrofit的基本用法Retrofit的使用逻辑Retrofit的基本操作处理复杂的接口地址类型进阶删除提交header中指定参数 Retrofit构建器的最佳写法Retrofit的使用封装 用户网络请求的接口配置繁琐&…...

SpringBoot自动化配置原理
SpringBoot自动化配置原理 01-SpringBoot2高级-starter依赖管理机制 目的:通过依赖能了解SpringBoot管理了哪些starter 讲解: 通过依赖 spring-boot-dependencies 搜索 starter- 发现非常多的官方starter,并且已经帮助我们管理好了版本。 …...

2024级新生数组字符串专题题解
一、题解: 1.A-[NOIP2005]校门外的树_24级新生数组字符串训练题 (nowcoder.com) 这题常见的解法有两种: 第一种是这道题我们可以直接按照题目意思枚举 #include<bits/stdc.h> #define int long long using namespace std;int road[10010];sig…...

C++学习 虚函数,容器
一、虚函数 虚函数是C中的一种函数,允许子类重写父类中的函数,以便在运行时通过基类指针或引用调用子类的函数实现。虚函数的主要作用是实现多态性,这使得基类指针或引用可以根据实际指向的对象类型调用不同的函数实现。具体用法 虚函数的声…...
MacTalk 测评通义灵码,如何实现“微信表情”小功能?
作者:池建强,墨问西东创始人 前段时间,我写了篇墨问研发团队放弃 GitHub Copilot 的文章,没想到留言区一些读者推荐我们试试通义灵码,说它效果很不错。我呢,一直没腾出时间折腾。 直到月中时,…...

ComfyUI-AnimateDiff-Evolved技术指南:从静态图像到动态视频的AI创作全流程
ComfyUI-AnimateDiff-Evolved技术指南:从静态图像到动态视频的AI创作全流程 【免费下载链接】ComfyUI-AnimateDiff-Evolved Improved AnimateDiff for ComfyUI and Advanced Sampling Support 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-AnimateDiff-E…...

lora-scripts应用案例:电商主图自动生成,快速训练商品风格模型
LoRA-Scripts应用案例:电商主图自动生成,快速训练商品风格模型 1. 电商主图生成的痛点与解决方案 电商运营每天面临大量商品主图制作需求,传统方式存在三个核心痛点: 人力成本高:专业设计师单张主图制作成本50-200元…...

Nucleus Co-Op:如何让单机游戏秒变本地多人分屏神器?
Nucleus Co-Op:如何让单机游戏秒变本地多人分屏神器? 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为找不到合适的本…...

OBS-Multi-RTMP:多平台直播高效同步解决方案
OBS-Multi-RTMP:多平台直播高效同步解决方案 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp OBS-Multi-RTMP作为一款专注于多平台直播同步的开源插件,能够帮助直…...

程序员效率工具:Yi-Coder-1.5B部署与真实任务测试报告
程序员效率工具:Yi-Coder-1.5B部署与真实任务测试报告 还在为写一个简单的文件处理脚本而翻遍搜索引擎吗?或者面对一段陌生的遗留代码,需要花半小时去理解它的逻辑?对于程序员来说,日常开发中充斥着大量重复、琐碎但必…...

mbeduino:Arduino语法兼容层实现RTOS级嵌入式开发
1. 项目概述mbeduino是一个面向嵌入式开发者的桥接型开源库,其核心目标是将 Arduino 生态中高度抽象、易上手的编程范式(如setup()/loop()结构、digitalWrite()/analogRead()等语义化 API)无缝移植至 ARM mbed OS 平台。它并非 Arduino IDE 的…...

5分钟搞定OpenClaw安装:Phi-3-vision-128k-instruct镜像一键部署指南
5分钟搞定OpenClaw安装:Phi-3-vision-128k-instruct镜像一键部署指南 1. 为什么选择星图平台部署Phi-3模型 上周我在本地尝试部署Phi-3-vision-128k-instruct模型时,被各种依赖冲突折磨得够呛。CUDA版本不匹配、vLLM编译失败、Python环境污染...这些问…...

嵌入式系统中联合体的高效数据管理实践
1. 联合体在嵌入式系统中的高效数据管理实践在嵌入式系统开发中,如何高效地管理和传输数据一直是个值得深入探讨的话题。最近我在一个智能家居控制项目中遇到了一个典型场景:需要同时管理7个用电器的开关状态和4组电源线参数(电压、电流、有功…...

SparkFun I2C GPIO扩展库:Arduino兼容的PCA/TCA系列驱动
1. SparkFun I2C Expander Arduino 库概述SparkFun I2C Expander Arduino 库是一个专为嵌入式系统设计的轻量级、高兼容性 GPIO 扩展驱动库,面向基于 Arduino 架构(含 ESP32、RP2040、STM32 Core for Arduino 等兼容平台)的硬件开发场景。该库…...

Microsoft Agent Framework + Kimi API 实战:控制台应用跑通单次与多轮 Agent 对话
使用 Kimi 的 OpenAI 兼容接口实现单次对话实现多轮对话(基于 Session 保留上下文)你把代码复制后,只要配置好 KIMI_API_KEY 就能跑起来。环境准备.NET SDK 9.0Kimi API Key一个控制台项目创建项目并安装依赖:dotnet new console …...