Python实战项目:天气数据爬取+数据可视化(完整代码)_python爬虫实战

一、选题的背景
- 随着人们对天气的关注逐渐增加,天气预报数据的获取与可视化成为了当今的热门话题,天气预报我们每天都会关注,天气情况会影响到我们日常的增减衣物、出行安排等。每天的气温、相对湿度、降水量以及风向风速是关注的焦点。通过Python网络爬虫爬取天气预报让我们快速获取和分析大量的天气数据,并通过可视化手段展示其特征和规律。这将有助于人们更好地理解和应用天气数据,从而做出更准确的决策和规划
二、主题式网络爬虫设计方案
①主题式网络爬虫名称:天气预报爬取数据与可视化数据
②主题式网络爬虫爬取的内容与数据特征分析:
③爬取内容:天气预报网站上的历史天气数据 包括(日期,最高温度,最低温度,天气,风向)等信息
④数据特征分析:时效性,完整性,结构化,可预测性等特性
⑤主题式网络爬虫设计方案概述
- 实现思路:本次设计方案首先分析网站页面主要使用requests爬虫程序,实现网页的请求、解析、过滤、存储等,通过pandas库对数据进行分析和数据可视化处理。
- 该过程遇到的难点:动态加载、反爬虫、导致爬虫难以获取和解析数据,数据可视化的效果和美观性
三、主题页面的结构特征分析

(1) 导航栏位于界面顶部
(2) 右侧热门城市历史天气
(3) 中间是内容区海口气温走势图以及风向统计
(4) 页面底部是网站信息和网站服务
2. Htmls 页面解析
class="tianqi_pub_nav_box"顶部导航栏
class="tianqi_pub_nav_box"右侧热门城市历史天气
3.节点(标签)查找方法与遍历方法
for循环迭代遍历
温馨提示:篇幅有限,完整代码已打包文件夹,获取方式在:

四、网络爬虫程序设计
数据来源:查看天气网:http://www.tianqi.com.cn。访问海口市的历史天气网址:https://lishi.tianqi.com/haikou/202311.html,利用Python的爬虫技术从网站上爬取东莞市2023-11月历史天气数据信息。
Part1: 爬取天气网历海口史天气数据并保存未:"海口历史天气【2023年11月】.xls"文件


1 import requests 2 from lxml import etree 3 import xlrd, xlwt, os 4 from xlutils.copy import copy 5 6 class TianQi(): 7 def \_\_init\_\_(self):8 pass9 10 #爬虫部分11 def spider(self): 12 city\_dict = { 13 "海口": "haikou"14 }15 city = '海口'16 city = city\_dict\[f'{city}'\]17 year = '2023'18 month = '11'19 start\_url = f'https://lishi.tianqi.com/{city}/{year}{month}.html'20 headers = { 21 'authority': 'lishi.tianqi.com',22 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,\*/\*;q=0.8,application/signed-exchange;v=b3;q=0.7',23 'accept-language': 'zh-CN,zh;q=0.9',24 'cache-control': 'no-cache',25 # Requests sorts cookies= alphabetically26 'cookie': 'Hm\_lvt\_7c50c7060f1f743bccf8c150a646e90a=1701184759; Hm\_lvt\_30606b57e40fddacb2c26d2b789efbcb=1701184793; Hm\_lpvt\_30606b57e40fddacb2c26d2b789efbcb=1701184932; Hm\_lpvt\_7c50c7060f1f743bccf8c150a646e90a=1701185017',27 'pragma': 'no-cache',28 'referer': 'https://lishi.tianqi.com/ankang/202309.html',29 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A\_Brand";v="24"',30 'sec-ch-ua-mobile': '?0',31 'sec-ch-ua-platform': '"Windows"',32 'sec-fetch-dest': 'document',33 'sec-fetch-mode': 'navigate',34 'sec-fetch-site': 'same-origin',35 'sec-fetch-user': '?1',36 'upgrade-insecure-requests': '1',37 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',38 }39 response = requests.get(start\_url,headers=headers).text40 tree = etree.HTML(response) 41 datas = tree.xpath("/html/body/div\[@class='main clearfix'\]/div\[@class='main\_left inleft'\]/div\[@class='tian\_three'\]/ul\[@class='thrui'\]/li")42 weizhi = tree.xpath("/html/body/div\[@class='main clearfix'\]/div\[@class='main\_left inleft'\]/div\[@class='inleft\_tian'\]/div\[@class='tian\_one'\]/div\[@class='flex'\]\[1\]/h3/text()")\[0\]43 self.parase(datas,weizhi,year,month)44 45 46 #解析部分47 def parase(self,datas,weizhi,year,month): 48 for data in datas: 49 #1、日期50 datetime = data.xpath("./div\[@class='th200'\]/text()")\[0\]51 #2、最高气温52 max\_qiwen = data.xpath("./div\[@class='th140'\]\[1\]/text()")\[0\]53 #3、最低气温54 min\_qiwen = data.xpath("./div\[@class='th140'\]\[2\]/text()")\[0\]55 #4、天气56 tianqi = data.xpath("./div\[@class='th140'\]\[3\]/text()")\[0\]57 #5、风向58 fengxiang = data.xpath("./div\[@class='th140'\]\[4\]/text()")\[0\]59 dict\_tianqi = { 60 '日期':datetime,61 '最高气温':max\_qiwen,62 '最低气温':min\_qiwen,63 '天气':tianqi,64 '风向':fengxiang65 }66 data\_excel = { 67 f'{weizhi}【{year}年{month}月】':\[datetime,max\_qiwen,min\_qiwen,tianqi,fengxiang\]68 }69 self.chucun\_excel(data\_excel,weizhi,year,month)70 print(dict\_tianqi)71 72 73 #储存部分74 def chucun\_excel(self, data,weizhi,year,month): 75 if not os.path.exists(f'{weizhi}【{year}年{month}月】.xls'):76 # 1、创建 Excel 文件77 wb = xlwt.Workbook(encoding='utf-8')78 # 2、创建新的 Sheet 表79 sheet = wb.add\_sheet(f'{weizhi}【{year}年{month}月】', cell\_overwrite\_ok=True)80 # 3、设置 Borders边框样式81 borders = xlwt.Borders() 82 borders.left = xlwt.Borders.THIN 83 borders.right = xlwt.Borders.THIN 84 borders.top = xlwt.Borders.THIN 85 borders.bottom = xlwt.Borders.THIN 86 borders.left\_colour = 0x4087 borders.right\_colour = 0x4088 borders.top\_colour = 0x4089 borders.bottom\_colour = 0x4090 style = xlwt.XFStyle() # Create Style91 style.borders = borders # Add Borders to Style92 # 4、写入时居中设置93 align = xlwt.Alignment() 94 align.horz = 0x02 # 水平居中95 align.vert = 0x01 # 垂直居中96 style.alignment = align 97 # 5、设置表头信息, 遍历写入数据, 保存数据98 header = ( 99 '日期', '最高气温', '最低气温', '天气', '风向')
100 for i in range(0, len(header)):
101 sheet.col(i).width = 2560 \* 3
102 #行,列, 内容, 样式
103 sheet.write(0, i, header\[i\], style)
104 wb.save(f'{weizhi}【{year}年{month}月】.xls')
105 # 判断工作表是否存在
106 if os.path.exists(f'{weizhi}【{year}年{month}月】.xls'):
107 # 打开工作薄
108 wb = xlrd.open\_workbook(f'{weizhi}【{year}年{month}月】.xls')
109 # 获取工作薄中所有表的个数
110 sheets = wb.sheet\_names()
111 for i in range(len(sheets)):
112 for name in data.keys():
113 worksheet = wb.sheet\_by\_name(sheets\[i\])
114 # 获取工作薄中所有表中的表名与数据名对比
115 if worksheet.name == name:
116 # 获取表中已存在的行数
117 rows\_old = worksheet.nrows
118 # 将xlrd对象拷贝转化为xlwt对象
119 new\_workbook = copy(wb)
120 # 获取转化后的工作薄中的第i张表
121 new\_worksheet = new\_workbook.get\_sheet(i)
122 for num in range(0, len(data\[name\])):
123 new\_worksheet.write(rows\_old, num, data\[name\]\[num\])
124 new\_workbook.save(f'{weizhi}【{year}年{month}月】.xls')
125
126 if \_\_name\_\_ == '\_\_main\_\_':
127 t=TianQi()
128 t.spider()Part2:根据海口历史天气【2023年11月】.xls生成海口市天气分布图

1 import pandas as pd2 from pyecharts.charts import Pie 3 from pyecharts import options as opts 4 from pyecharts.globals import ThemeType 5 6 def on(gender\_counts): 7 total = gender\_counts.sum() 8 percentages = {gender: count / total \* 100 for gender, count in gender\_counts.items()} 9 analysis\_parts = \[\]
10 for gender, percentage in percentages.items():
11 analysis\_parts.append(f"{gender}天气占比为{percentage:.2f}%,")
12 analysis\_report = "天气比例饼状图显示," + ''.join(analysis\_parts)
13 return analysis\_report
14
15 df = pd.read\_excel("海口历史天气【2023年11月】.xls")
16 gender\_counts = df\['天气'\].value\_counts()
17 analysis\_text = on(gender\_counts)
18 pie = Pie(init\_opts=opts.InitOpts(theme=ThemeType.WESTEROS,bg\_color='#e4cf8e'))
19
20 pie.add(
21 series\_name="海口市天气分布",
22 data\_pair=\[list(z) for z in zip(gender\_counts.index.tolist(), gender\_counts.values.tolist())\],
23 radius=\["40%", "70%"\],
24 rosetype="radius",
25 label\_opts=opts.LabelOpts(is\_show=True, position="outside", font\_size=14,
26 formatter="{a}<br/>{b}: {c} ({d}%)")
27 )
28 pie.set\_global\_opts(
29 title\_opts=opts.TitleOpts(title="海口市11月份天气分布",pos\_right="50%"),
30 legend\_opts=opts.LegendOpts(orient="vertical", pos\_top="15%", pos\_left="2%"),
31 toolbox\_opts=opts.ToolboxOpts(is\_show=True)
32 )
33 pie.set\_series\_opts(label\_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)"))
34 html\_content = pie.render\_embed()
35
36 # 生成HTML文件
37 complete\_html = f"""
38 <html>
39 <head>
40 <title>天气数据分析</title>
41
42 </head>
43 <body style="background-color: #e87f7f">
44 <div style='margin-top: 20px;background-color='#e87f7f''>
45 <div>{html\_content}</div>
46 <h3>分析报告:</h3>
47 <p>{analysis\_text}</p>
48 </div>
49 </body>
50 </html>
51 """
52 # 保存到HTML文件
53 with open("海口历史天气【2023年11月】饼图可视化.html", "w", encoding="utf-8") as file:
54 file.write(complete\_html)Part3:根据海口历史天气【2023年11月】.xls生成海口市温度趋势

1 import pandas as pd 2 import matplotlib.pyplot as plt 3 from matplotlib import font\_manager 4 import jieba 5 6 # 中文字体7 font\_CN = font\_manager.FontProperties(fname="C:\\Windows\\Fonts\\STKAITI.TTF")8 9 # 读取数据
10 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
11
12 # 使用 jieba 处理数据,去除 "C"
13 df\['最高气温'\] = df\['最高气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
14 df\['最低气温'\] = df\['最低气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
15 # 开始绘图
16 plt.figure(figsize=(20, 8), dpi=80)
17 max\_tp = df\['最高气温'\].tolist()
18 min\_tp = df\['最低气温'\].tolist()
19 x\_day = range(1, 31)
20 # 绘制30天最高气温
21 plt.plot(x\_day, max\_tp, label = "最高气温", color = "red")
22 # 绘制30天最低气温
23 plt.plot(x\_day, min\_tp, label = "最低气温", color = "skyblue")
24 # 增加x轴刻度
25 \_xtick\_label = \["11月{}日".format(i) for i in x\_day\]
26 plt.xticks(x\_day, \_xtick\_label, fontproperties=font\_CN, rotation=45)
27 # 添加标题
28 plt.title("2023年11月最高气温与最低气温趋势", fontproperties=font\_CN)
29 plt.xlabel("日期", fontproperties=font\_CN)
30 plt.ylabel("温度(单位°C)", fontproperties=font\_CN)
31 plt.legend(prop = font\_CN)
32 plt.show()Part4:根据海口历史天气【2023年11月】.xls生成海口市词汇图

1 from pyecharts.charts import WordCloud 2 from pyecharts import options as opts 3 from pyecharts.globals import SymbolType 4 import jieba 5 import pandas as pd 6 from collections import Counter 7 8 # 读取Excel文件9 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
10 # 提取商品名
11 word\_names = df\["风向"\].tolist() + df\["天气"\].tolist()
12 # 提取关键字
13 seg\_list = \[jieba.lcut(text) for text in word\_names\]
14 words = \[word for seg in seg\_list for word in seg if len(word) > 1\]
15 word\_counts = Counter(words)
16 word\_cloud\_data = \[(word, count) for word, count in word\_counts.items()\]
17
18 # 创建词云图
19 wordcloud = (
20 WordCloud(init\_opts=opts.InitOpts(bg\_color='#00FFFF'))
21 .add("", word\_cloud\_data, word\_size\_range=\[20, 100\], shape=SymbolType.DIAMOND,
22 word\_gap=5, rotate\_step=45,
23 textstyle\_opts=opts.TextStyleOpts(font\_family='cursive', font\_size=15))
24 .set\_global\_opts(title\_opts=opts.TitleOpts(title="天气预报词云图",pos\_top="5%", pos\_left="center"),
25 toolbox\_opts=opts.ToolboxOpts(
26 is\_show=True,
27 feature={
28 "saveAsImage": {},
29 "dataView": {},
30 "restore": {},
31 "refresh": {}
32 }
33 )
34
35 )
36 )
37
38 # 渲染词图到HTML文件
39 wordcloud.render("天气预报词云图.html")爬虫课程设计全部代码如下:
1 import requests2 from lxml import etree3 import xlrd, xlwt, os4 from xlutils.copy import copy5 6 class TianQi():7 def \_\_init\_\_(self):8 pass9 10 #爬虫部分11 def spider(self):12 city\_dict = {13 "海口": "haikou"14 }15 city = '海口'16 city = city\_dict\[f'{city}'\]17 year = '2023'18 month = '11'19 start\_url = f'https://lishi.tianqi.com/{city}/{year}{month}.html'20 headers = {21 'authority': 'lishi.tianqi.com',22 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,\*/\*;q=0.8,application/signed-exchange;v=b3;q=0.7',23 'accept-language': 'zh-CN,zh;q=0.9',24 'cache-control': 'no-cache',25 # Requests sorts cookies= alphabetically26 'cookie': 'Hm\_lvt\_7c50c7060f1f743bccf8c150a646e90a=1701184759; Hm\_lvt\_30606b57e40fddacb2c26d2b789efbcb=1701184793; Hm\_lpvt\_30606b57e40fddacb2c26d2b789efbcb=1701184932; Hm\_lpvt\_7c50c7060f1f743bccf8c150a646e90a=1701185017',27 'pragma': 'no-cache',28 'referer': 'https://lishi.tianqi.com/ankang/202309.html',29 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A\_Brand";v="24"',30 'sec-ch-ua-mobile': '?0',31 'sec-ch-ua-platform': '"Windows"',32 'sec-fetch-dest': 'document',33 'sec-fetch-mode': 'navigate',34 'sec-fetch-site': 'same-origin',35 'sec-fetch-user': '?1',36 'upgrade-insecure-requests': '1',37 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',38 }39 response = requests.get(start\_url,headers=headers).text40 tree = etree.HTML(response)41 datas = tree.xpath("/html/body/div\[@class='main clearfix'\]/div\[@class='main\_left inleft'\]/div\[@class='tian\_three'\]/ul\[@class='thrui'\]/li")42 weizhi = tree.xpath("/html/body/div\[@class='main clearfix'\]/div\[@class='main\_left inleft'\]/div\[@class='inleft\_tian'\]/div\[@class='tian\_one'\]/div\[@class='flex'\]\[1\]/h3/text()")\[0\]43 self.parase(datas,weizhi,year,month)44 45 46 #解析部分47 def parase(self,datas,weizhi,year,month):48 for data in datas:49 #1、日期50 datetime = data.xpath("./div\[@class='th200'\]/text()")\[0\]51 #2、最高气温52 max\_qiwen = data.xpath("./div\[@class='th140'\]\[1\]/text()")\[0\]53 #3、最低气温54 min\_qiwen = data.xpath("./div\[@class='th140'\]\[2\]/text()")\[0\]55 #4、天气56 tianqi = data.xpath("./div\[@class='th140'\]\[3\]/text()")\[0\]57 #5、风向58 fengxiang = data.xpath("./div\[@class='th140'\]\[4\]/text()")\[0\]59 dict\_tianqi = {60 '日期':datetime,61 '最高气温':max\_qiwen,62 '最低气温':min\_qiwen,63 '天气':tianqi,64 '风向':fengxiang65 }66 data\_excel = {67 f'{weizhi}【{year}年{month}月】':\[datetime,max\_qiwen,min\_qiwen,tianqi,fengxiang\]68 }69 self.chucun\_excel(data\_excel,weizhi,year,month)70 print(dict\_tianqi)71 72 73 #储存部分74 def chucun\_excel(self, data,weizhi,year,month):75 if not os.path.exists(f'{weizhi}【{year}年{month}月】.xls'):76 # 1、创建 Excel 文件77 wb = xlwt.Workbook(encoding='utf-8')78 # 2、创建新的 Sheet 表79 sheet = wb.add\_sheet(f'{weizhi}【{year}年{month}月】', cell\_overwrite\_ok=True)80 # 3、设置 Borders边框样式81 borders = xlwt.Borders()82 borders.left = xlwt.Borders.THIN83 borders.right = xlwt.Borders.THIN84 borders.top = xlwt.Borders.THIN85 borders.bottom = xlwt.Borders.THIN86 borders.left\_colour = 0x4087 borders.right\_colour = 0x4088 borders.top\_colour = 0x4089 borders.bottom\_colour = 0x4090 style = xlwt.XFStyle() # Create Style91 style.borders = borders # Add Borders to Style92 # 4、写入时居中设置93 align = xlwt.Alignment()94 align.horz = 0x02 # 水平居中95 align.vert = 0x01 # 垂直居中96 style.alignment = align97 # 5、设置表头信息, 遍历写入数据, 保存数据98 header = (99 '日期', '最高气温', '最低气温', '天气', '风向')
100 for i in range(0, len(header)):
101 sheet.col(i).width = 2560 \* 3
102 # 行,列, 内容, 样式
103 sheet.write(0, i, header\[i\], style)
104 wb.save(f'{weizhi}【{year}年{month}月】.xls')
105 # 判断工作表是否存在
106 if os.path.exists(f'{weizhi}【{year}年{month}月】.xls'):
107 # 打开工作薄
108 wb = xlrd.open\_workbook(f'{weizhi}【{year}年{month}月】.xls')
109 # 获取工作薄中所有表的个数
110 sheets = wb.sheet\_names()
111 for i in range(len(sheets)):
112 for name in data.keys():
113 worksheet = wb.sheet\_by\_name(sheets\[i\])
114 # 获取工作薄中所有表中的表名与数据名对比
115 if worksheet.name == name:
116 # 获取表中已存在的行数
117 rows\_old = worksheet.nrows
118 # 将xlrd对象拷贝转化为xlwt对象
119 new\_workbook = copy(wb)
120 # 获取转化后的工作薄中的第i张表
121 new\_worksheet = new\_workbook.get\_sheet(i)
122 for num in range(0, len(data\[name\])):
123 new\_worksheet.write(rows\_old, num, data\[name\]\[num\])
124 new\_workbook.save(f'{weizhi}【{year}年{month}月】.xls')
125
126 if \_\_name\_\_ == '\_\_main\_\_':
127 t=TianQi()
128 t.spider()
129 import pandas as pd
130 import jieba
131 from pyecharts.charts import Scatter
132 from pyecharts import options as opts
133
134 from scipy import stats
135
136 # 读取数据
137 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
138
139 # 使用 jieba 处理数据,去除 "C"
140 df\['最高气温'\] = df\['最高气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
141 df\['最低气温'\] = df\['最低气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
142
143 # 创建散点图
144 scatter = Scatter()
145 scatter.add\_xaxis(df\['最低气温'\].tolist())
146 scatter.add\_yaxis("最高气温", df\['最高气温'\].tolist())
147 scatter.set\_global\_opts(title\_opts=opts.TitleOpts(title="最低气温与最高气温的散点图"))
148 html\_content = scatter.render\_embed()
149
150 # 计算回归方程
151 slope, intercept, r\_value, p\_value, std\_err = stats.linregress(df\['最低气温'\], df\['最高气温'\])
152
153 print(f"回归方程为:y = {slope}x + {intercept}")
154
155 analysis\_text = f"回归方程为:y = {slope}x + {intercept}"
156 # 生成HTML文件
157 complete\_html = f"""
158 <html>
159 <head>
160 <title>天气数据分析</title>
161 </head>
162 <body style="background-color: #e87f7f">
163 <div style='margin-top: 20px;background-color='#e87f7f''>
164 <div>{html\_content}</div>
165 <p>{analysis\_text}</p>
166 </div>
167 </body>
168 </html>
169 """
170 # 保存到HTML文件
171 with open("海口历史天气【2023年11月】散点可视化.html", "w", encoding="utf-8") as file:
172 file.write(complete\_html)
173
174 import pandas as pd
175 from flatbuffers.builder import np
176 from matplotlib import pyplot as plt
177 from pyecharts.charts import Pie
178 from pyecharts import options as opts
179 from pyecharts.globals import ThemeType
180
181 def on(gender\_counts):
182 total = gender\_counts.sum()
183 percentages = {gender: count / total \* 100 for gender, count in gender\_counts.items()}
184 analysis\_parts = \[\]
185 for gender, percentage in percentages.items():
186 analysis\_parts.append(f"{gender}天气占比为{percentage:.2f}%,")
187 analysis\_report = "天气比例饼状图显示," + ''.join(analysis\_parts)
188 return analysis\_report
189
190 df = pd.read\_excel("海口历史天气【2023年11月】.xls")
191 gender\_counts = df\['天气'\].value\_counts()
192 analysis\_text = on(gender\_counts)
193 pie = Pie(init\_opts=opts.InitOpts(theme=ThemeType.WESTEROS,bg\_color='#e4cf8e'))
194 pie.add(
195 series\_name="海口市天气分布",
196 data\_pair=\[list(z) for z in zip(gender\_counts.index.tolist(), gender\_counts.values.tolist())\],
197 radius=\["40%", "70%"\],
198 rosetype="radius",
199 label\_opts=opts.LabelOpts(is\_show=True, position="outside", font\_size=14,
200 formatter="{a}<br/>{b}: {c} ({d}%)")
201 )
202 pie.set\_global\_opts(
203 title\_opts=opts.TitleOpts(title="海口市11月份天气分布",pos\_right="50%"),
204 legend\_opts=opts.LegendOpts(orient="vertical", pos\_top="15%", pos\_left="2%"),
205 toolbox\_opts=opts.ToolboxOpts(is\_show=True)
206 )
207 pie.set\_series\_opts(label\_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)"))
208 html\_content = pie.render\_embed()
209
210 # 生成HTML文件
211 complete\_html = f"""
212 <html>
213 <head>
214 <title>天气数据分析</title>
215
216 </head>
217 <body style="background-color: #e87f7f">
218 <div style='margin-top: 20px;background-color='#e87f7f''>
219 <div>{html\_content}</div>
220 <h3>分析报告:</h3>
221 <p>{analysis\_text}</p>
222 </div>
223 </body>
224 </html>
225 """
226
227 import pandas as pd
228 import matplotlib.pyplot as plt
229 from matplotlib import font\_manager
230 import jieba
231
232 # 中文字体
233 font\_CN = font\_manager.FontProperties(fname="C:\\Windows\\Fonts\\STKAITI.TTF")
234
235 # 读取数据
236 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
237
238 # 使用 jieba 处理数据,去除 "C"
239 df\['最高气温'\] = df\['最高气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
240 df\['最低气温'\] = df\['最低气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
241 # 开始绘图
242 plt.figure(figsize=(20, 8), dpi=80)
243 max\_tp = df\['最高气温'\].tolist()
244 min\_tp = df\['最低气温'\].tolist()
245 x\_day = range(1, 31)
246 # 绘制30天最高气温
247 plt.plot(x\_day, max\_tp, label = "最高气温", color = "red")
248 # 绘制30天最低气温
249 plt.plot(x\_day, min\_tp, label = "最低气温", color = "skyblue")
250 # 增加x轴刻度
251 \_xtick\_label = \["11月{}日".format(i) for i in x\_day\]
252 plt.xticks(x\_day, \_xtick\_label, fontproperties=font\_CN, rotation=45)
253 # 添加标题
254 plt.title("2023年11月最高气温与最低气温趋势", fontproperties=font\_CN)
255 plt.xlabel("日期", fontproperties=font\_CN)
256 plt.ylabel("温度(单位°C)", fontproperties=font\_CN)
257 plt.legend(prop = font\_CN)
258 plt.show()
259
260 from pyecharts.charts import WordCloud
261 from pyecharts import options as opts
262 from pyecharts.globals import SymbolType
263 import jieba
264 import pandas as pd
265 from collections import Counter
266
267 # 读取Excel文件
268 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
269 # 提取商品名
270 word\_names = df\["风向"\].tolist() + df\["天气"\].tolist()
271 # 提取关键字
272 seg\_list = \[jieba.lcut(text) for text in word\_names\]
273 words = \[word for seg in seg\_list for word in seg if len(word) > 1\]
274 word\_counts = Counter(words)
275 word\_cloud\_data = \[(word, count) for word, count in word\_counts.items()\]
276
277 # 创建词云图
278 wordcloud = (
279 WordCloud(init\_opts=opts.InitOpts(bg\_color='#00FFFF'))
280 .add("", word\_cloud\_data, word\_size\_range=\[20, 100\], shape=SymbolType.DIAMOND,
281 word\_gap=5, rotate\_step=45,
282 textstyle\_opts=opts.TextStyleOpts(font\_family='cursive', font\_size=15))
283 .set\_global\_opts(title\_opts=opts.TitleOpts(title="天气预报词云图",pos\_top="5%", pos\_left="center"),
284 toolbox\_opts=opts.ToolboxOpts(
285 is\_show=True,
286 feature={
287 "saveAsImage": {},
288 "dataView": {},
289 "restore": {},
290 "refresh": {}
291 }
292 )
293
294 )
295 )
296
297 # 渲染词图到HTML文件
298 wordcloud.render("天气预报词云图.html")五、总结
1.根据散点图的显示回归方:y = 0.6988742964352719x + 10.877423389618516来获取海口市11月份温度趋势
2.根据饼状图可以了解海口市11月份的天气比例,多云天气占比为53.33%,晴天气占比为26.67%,阴天气占比为13.33%,小雨天气占比为6.67%,
3.根据折线图了解海口市11月份的最高温度和最低温度趋势。
4.根据词云图的显示,可以了解当月的天气质量相关内容。
- 综述:是通过Python爬虫技术获取天气预报数据,_数据爬取方面,通过Python编写爬虫程序,利用网络爬虫技术从天气网站上获取天气预报数据,并进行数据清洗和处理。_数据可视化方面,利用数据可视化工具,将存储的数据进行可视化展示,以便用户更直观地了解天气情况_因此用户更好地理解和应用天气数据,从而做出更准确的决策和规划。____

相关文章:
Python实战项目:天气数据爬取+数据可视化(完整代码)_python爬虫实战
一、选题的背景 随着人们对天气的关注逐渐增加,天气预报数据的获取与可视化成为了当今的热门话题,天气预报我们每天都会关注,天气情况会影响到我们日常的增减衣物、出行安排等。每天的气温、相对湿度、降水量以及风向风速是关注的焦点。通过…...

FFmpeg源码:compute_frame_duration函数分析
一、compute_frame_duration函数的定义 compute_frame_duration函数定义在FFmpeg源码(本文演示用的FFmpeg源码版本为7.0.1)的源文件libavformat/demux.c中: /*** Return the frame duration in seconds. Return 0 if not available.*/ stat…...

ARM 异常处理(21)
异常的流程: 首先: 在硬件上阶段: 这里是4大步3小步 然后是 异常处理: 这里主要是保存现场,进行异常处理 然后是 异常返回: 主要指 恢复现场, 再跳转回去。 首先硬件上ÿ…...

我开源了我的新闻网站项目
🎉 前言 暑假时写了一个Web项目,感觉做的还是有模有样的,不仅做了前端,还加了后端并连了数据库。最近也是将它开源了,一来是为了熟悉一下Github流程和Git使用命令,二来也是想和大家分享一下自己的成果&…...

LlamaIndex 使用 RouterOutputAgentWorkflow
LlamaIndex 中提供了一个 RouterOutputAgentWorkflow 功能,可以集成多个 QueryTool,根据用户的输入判断使用那个 QueryEngine,在做查询的时候,可以从不同的数据源进行查询,例如确定的数据从数据库查询,如果…...

设计模式学习-责任链模式
概念 使多个对象都有机会处理请求,从而避免了请求的发送者和接受者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它为止. 代码编写 using UnityEngine; using System.Collections; public class ChainOfResp…...

【全网最全】2024年数学建模国赛B题31页完整建模过程+成品论文+matlab/python代码等(后续会更新
您的点赞收藏是我继续更新的最大动力! 一定要点击如下的卡片,那是获取资料的入口! 2024数学建模国赛B题 【全网最全】2024年数学建模国赛B题31页完整建模过程成品论文matlab/python代码等(后续会更新「首先来看看目前已有的资料…...
第二十一届华为杯数学建模经验分享之资料分享篇
今天给大家分享一些数学建模的资料,通过这些资料的学习相信你们一定在比赛中获得好的成绩。今天分享的资料包括美赛和国赛的优秀论文集、研赛的优秀论文集、推荐数学建模的相关书籍、智能算法的学习PPT、python机器学习的书籍和数学建模经验分享与总结,其…...

使用 OpenSSL 创建自签名证书
mkdir -p /etc/nginx/conf.d/cert #2、创建私钥 openssl genrsa -des3 -out https.key 1024 提示输入字符: 输入字符:rancher [rootocean-app-1a-01 cert]# openssl genrsa -des3 -out https.key 1024 Generating RSA private key, 1024 bit long modulu…...

EmguCV学习笔记 VB.Net 9.1 VideoCapture类
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 EmguCV是一个基于OpenCV的开源免费的跨平台计算机视觉库,它向C#和VB.NET开发者提供了OpenCV库的大部分功能。 教程VB.net版本请访问…...
Rspack 1.0 发布了!
文章来源|Rspack Team 项目地址|https://github.com/web-infra-dev/rspack Rspack 是基于 Rust 编写的下一代 JavaScript 打包工具, 兼容 webpack 的 API 和生态,并提供 10 倍于 webpack 的构建性能。 在 18 个月前,我…...

【全网最全】2024年数学建模国赛E题超详细保奖思路+可视化图表+成品论文+matlab/python代码等(后续会更新
您的点赞收藏是我继续更新的最大动力! 一定要点击如下的卡片,那是获取资料的入口! 【全网最全】2024年数学建模国赛E题成品论文超详细保奖思路可视化图表matlab/python代码等(后续会更新「首先来看看目前已有的资料,还…...

数智转型,看JNPF如何成为企业的必备工具
随着数字化转型的浪潮席卷全球,企业面临着前所未有的挑战与机遇。在这一过程中,低代码开发平台作为一种创新的软件开发方式,正逐渐成为企业实现快速迭代和敏捷开发的关键工具。JNPF作为一款领先的低代码开发平台,凭借其强大的功能…...

ArcGIS Pro 发布松散型切片
使用ArcGIS Pro发布松散型切片问题,有时候会出现切片方案写了松散型,但是自动切片完成后依然是紧凑型的问题,这时候可以采用手动修改然后再切片的方式。 1. 发布切片服务 选择手动切片方式 2. 手动修改服务的切片方案文件 修改cache服务…...
奖项再+1!通义灵码智能编码助手通过可信 AI 智能编码工具评估,获当前最高等级
阿里云的通义灵码智能编码助手参与中国信通院组织的可信AI智能编码工具首轮评估,最终获得 4 级评级,成为国内首批通过该项评估并获得当前最高评级的企业之一。 此次评估以《智能化软件工程技术和应用要求 第 2 部分:智能开发能力》为依据&…...

如何使用 yum 在 CentOS 6 上安装 nginx
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 状态 状态: 已弃用 本文涵盖的 CentOS 版本已不再受支持。如果您目前正在运行 CentOS 6 服务器,我们强烈建议升…...
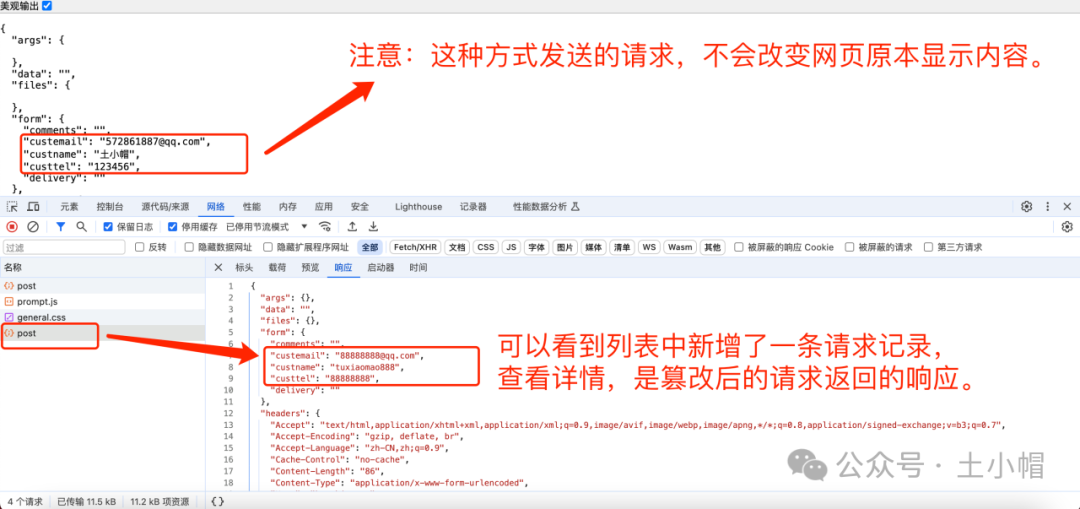
F12抓包05:Network接口测试(抓包篡改请求)
课程大纲 使用线上接口测试网站演示操作,浏览器F12检查工具如何进行简单的接口测试:抓包、复制请求、篡改数据、发送新请求。 测试地址:https://httpbin.org/forms/post ① 抓包:鼠标右键打开“检查”工具(F12…...
计算一个旋转矩形的四个顶点的函数boxPoints()的使用)
OPenCV结构分析与形状描述符(4)计算一个旋转矩形的四个顶点的函数boxPoints()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 找到一个旋转矩形的四个顶点。对于绘制旋转矩形很有用。 该函数找到一个旋转矩形的四个顶点。这个函数对于绘制矩形很有帮助。在C中,…...

【Matplotlib】利用Python进行绘图!(python数据分析与可视化)
文章开始前打个小广告——分享一份Python学习大礼包(激活码安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程)点击领取,100%免费! 【Matplotlib】 教程&…...

第二百二十节 JPA教程 - JPA 实体管理器删除示例
JPA教程 - JPA 实体管理器删除示例 我们可以使用JPA中的EntityManager来删除一个实体。 在下面的代码中,我们首先通过使用EntityManager中的find方法从数据库获取person对象,然后调用remove方法并传递person对象引用。 Person emp em.find(Person.cla…...

如何监控和分析自己网站的顶级SEO效果
如何监控和分析自己网站的顶级SEO效果 在当今数字化时代,网站的顶级SEO效果直接关系到网站的流量和用户参与度。了解如何有效监控和分析自己网站的SEO效果,对于提升网站的搜索排名和用户体验至关重要。本文将详细介绍如何监控和分析自己网站的顶级SEO效…...

从教程到产品:基于cursor实战案例,用快马一键生成可部署的管理后台
最近在跟着cursor教程学习React实战开发,发现很多教程虽然步骤详细,但学完后总感觉离实际产品还差一口气。于是尝试用InsCode(快马)平台把教程案例快速转化为可部署的原型,效果意外地好。这里以博客管理后台为例,分享从学习到落地…...

效率革命:用快马平台统一管理python项目,告别重复环境配置
效率革命:用快马平台统一管理python项目,告别重复环境配置 作为一名长期使用PyCharm进行Python开发的程序员,我经常遇到一个令人头疼的问题:每次新建数据分析项目,都要重复配置Python环境、安装依赖包、设置虚拟环境。…...

LeetCode Hot Code——合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。示例 1:输入:intervals [[1,3],[…...

OpenClaw技能开发入门:为Qwen3-14b_int4_awq定制自动化模块
OpenClaw技能开发入门:为Qwen3-14b_int4_awq定制自动化模块 1. 为什么需要自定义Skill 去年冬天,当我第一次尝试用OpenClaw自动整理电脑上的技术文档时,发现现有的通用技能无法完美匹配我的需求——我需要一个能理解Qwen3-14b_int4_awq模型…...
)
别让Liquid Glass拖慢你的App!给uni-app开发者的iOS 26动画优化清单(含代码示例)
别让Liquid Glass拖慢你的App!给uni-app开发者的iOS 26动画优化清单(含代码示例) 最近在开发者社区里,不少同行都在吐槽iOS 26的动画性能问题。特别是那些采用了新Liquid Glass设计的应用,在旧款iPhone上运行时&#x…...

网络信息安全技术术语对照表
类别术语中文术语英文术语说明基础技术类加密encryption将明文数据通过特定算法和密钥转换为密文数据的过程,目的是确保数据在存储、传输过程中不被未授权方获取和理解。基础技术类解密decryption将加密后的密文数据,通过对应的算法和密钥还原为原始明文…...
)
保姆级教程:在Ubuntu 22.04上从源码编译安装Micro XRCE-DDS Agent(附虚拟机环境配置)
从零构建嵌入式通信桥梁:Ubuntu 22.04源码编译Micro XRCE-DDS Agent全指南 当AURIX Tricore这类嵌入式设备需要与复杂系统对话时,XRCE-DDS就像一位专业翻译官。想象一下,你的开发板是个只会说方言的本地向导,而云端服务是个讲标准…...

零基础入门:借助快马平台生成你的第一份单元测试代码
作为一个刚接触软件测试的新手,我最近在InsCode(快马)平台上完成了一个Python单元测试的入门项目,整个过程比想象中顺利很多。这个"计算器单元测试示例"特别适合零基础学习者,我来分享一下具体的学习路径和收获。 理解单元测试的基…...
)
仅限核心架构师查阅:Python无锁GIL环境下的并发成本熔断机制(含实时监控脚本+自动降级策略)
第一章:Python无锁GIL环境下的并发模型成本控制策略全景概览在标准 CPython 解释器中,全局解释器锁(GIL)本质限制了多线程对 CPU 密集型任务的并行执行能力。然而,“无锁 GIL 环境”并非指移除 GIL 本身,而…...