OceanBase 4.x 存储引擎解析:如何让历史库场景成本降低50%+
据国际数据公司(IDC)的报告显示,预计到2025年,全球范围内每天将产生高达180ZB的庞大数据量,这一趋势预示着企业将面临着更加严峻的海量数据处理挑战。随着数据日渐庞大,一些存储系统会出现诸如存储空间扩展难、性能下降甚至卡顿的情况,影响业务系统的正常运转,增加企业的数据处理成本。众多企业已经开始积极寻求如何在保证处理效率的同时,进一步降低数据处理成本。特别是在历史库(冷数据)场景中,这种需求显得尤为普遍。
那么,作为一款帮助企业在历史库场景下成本至少降低50%的数据库,OceanBase 的核心技术是什么?本文将详细解读OceanBase 存储引擎技术。
一套存储引擎支持业务全阶段,极致节约资源成本
在传统数据库选型过程中(见下图),起初单机小规格的 MySQL 即可支撑业务需要。但随着业务的发展,MySQL 逐渐在数据增长的过程中无法满足性能和存储需求。这时,将系统升级为高规格机器的 Oracle 成为众多企业的选择,当高规格单机 Oracle 也无法满足的数据量时,则会考虑使用 RAC 共享存储,甚至为核心业务更换数据库类型,如 Db2。然而众所周知,数据系统作为“底座”和“心脏”,在更替时不仅要将对业务的影响降至最低,还必须考虑替换成本,因此一套顺滑可扩展的系统会大大降低成本和风险。那么,有没有一套系统可以应对客户不同业务规模下的数据管理需求呢?
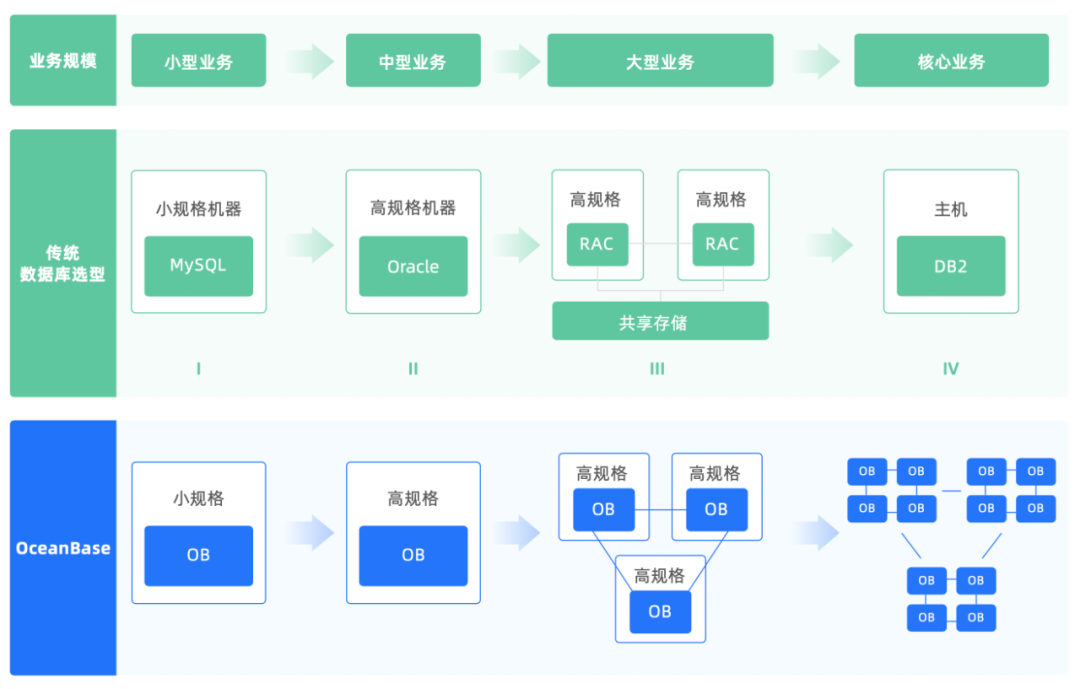
OceanBase 4.0提出的单机分布式一体化设计就能够满足业务不同阶段的需求。其兼具分布式的扩展性和集中式数据库的功能与单机性能。通过动态日志流的方式,实现了系统静态下的单机高性能,以及动态调整日志流平滑快速扩展的目的。对于存储引擎,则通过资源开销的小型化轻量化,使得同一个引擎支持不同部的署形态,支持轻松从小数据量到海量数据的平滑增长。
因此,在小型业务小数据量场景下,一个小规格 OceanBase单机实例便可支撑。随着业务数据量的缓慢增长,通过最简单的垂直扩容,即租户配置升级到高规格即可满足。当业务发展需要有容灾或者负载均衡时,OceanBase可轻松切换至三副本,每个副本的数据存储仍然保证高压缩比,用以降低多副本带来的成本增长。对于大型业务,则可通过在集群内水平扩容的方式来满足需求。这就是OceanBase 单机分布式一体化的重要意义和作用。
另外,在OceanBase 4.x 版本,存储引擎在资源管理方面更加轻量化、小型化和可扩展,使企业更充分、更合理地使用资源,节约资源使用成本。
单机百万分区支持,元数据小型化,按需加载,提高资源使用效率
OceanBase 创新地提出了日志流概念,用以降低海量数据分区下的网络、CPU 开销。每个数据分区的多副本都是一个Paxos成员组,用以保证数据的多副本的一致性。为了降低多分区或是小规格下的一致性协议开销,将相同成员组的数据分区日志聚集在一起,即所谓的单日志流。只需要一个日志流负责同步或选举即可实现一组分区副本的容灾及 Paxos 高可用。
而对于海量数据下的内存,OceanBase 存储引擎设计了元数据按需加载,智能区分冷热分区和必要的元数据,极大降低内存占用。
如下图所示,日志流下面有很多 Tablet ,即数据分片,可以理解为用户表的一个分区。它是分布式系统负载均衡和容灾恢复等最基础的单位。Tablet 的数量 与 Log Stream 相比是指数级的,原因在于一个集群里的可用区的拓扑关系是有限和少量的。但是对分区来说,其数量是会根据业务需求来调整,分区数量可能上万。
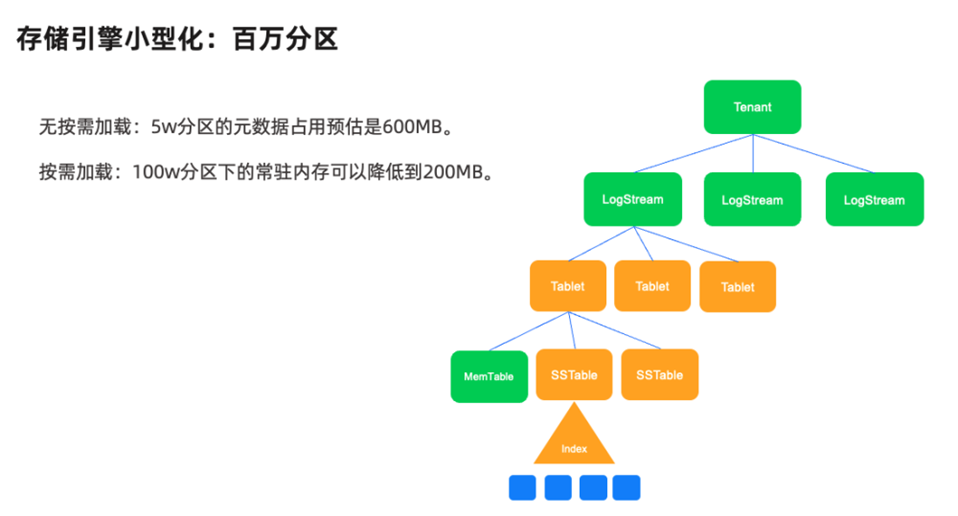
在OceanBase 4.x版本中,存储引擎不再将用户的所有分区下的元数据常驻在内存里,而是按需加载。所谓元数据,是指分区副本的一些基本属性,用以支持数据的增删改查、LSM-Tree的变更、负载均衡、容灾恢复等单机和分布式功能。所谓按需加载,是指将热分区下的元数据保持在内存里,不加载不经常访问的冷分区或是其元数据。通过冷热分离手段,使内存的使用效率发挥到极致。在老版本中,5W 分区的元数据占用预估 600MB内,而4.x 版本中100w 分区下的常驻内存可以降低到 200MB。小规格机器下,就能支持更多的分区。类似历史库按时间分区的场景,就能在不升级机器规格的情况下,存储更久远的历史数据。
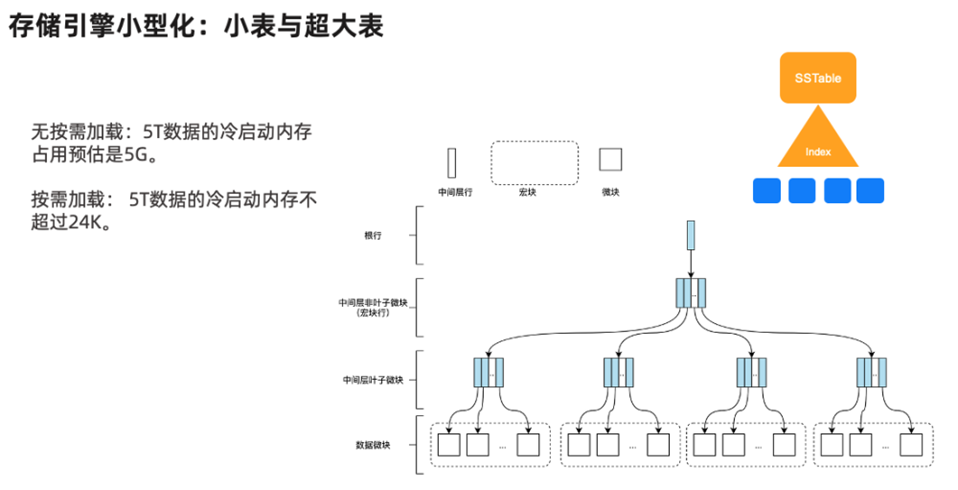
此外,在OceanBase 老版本中,无论是冷数据还是热数据,查询这些数据依赖的数据块元数据都会常驻在内存里。预计一张 5TB 容量的表的冷启动内存占用是 5GB 内存,但是,随着单表或单分区内的数据量增加,有限内存下很难做到同步扩展用以支撑数据查询。
对于历史库的场景而言,其特点往往是写多、读极少,单表体量极大,企业用户在配置历史库时更关注成本,往往使用小内存、大磁盘的机型。因此,在OceanBase 4.X 版本中,存储引擎对磁盘上的 SSTable 存储格式做了重构,将原本根据数据主键定位宏块的索引层(元数据的一种),从一层换成了树状结构。用于数据查询的元数据不再会常驻内存,而是动态地根据请求负载加载那些查询路径上有关的微块。同等对比下,一张 5TB 容量的表的冷启动内存不超过 24KB,不论数据规模如何膨胀,也不影响单机内存的使用。进一步在历史库的机型选择上降低了对内存的要求成本。
更灵活的磁盘I/O隔离策略,更安全、更充分地使用资源
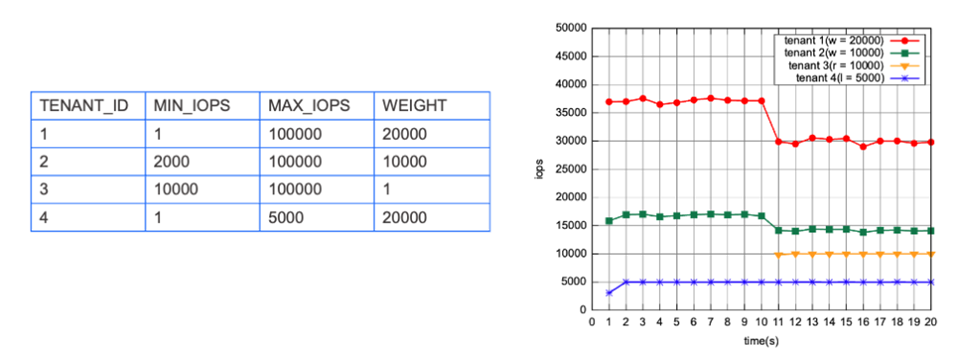
OceanBase 存储引擎提供一套完整的语法支持,为每个租户配置最大或最小 IOPS 及权重的能力。让用户能灵活调配租户所使用的I/O资源,进一步均衡流量高低峰间对磁盘的性能要求,降低成本。
如下图,4 号租户(蓝线,可以限制 IOPS)要求最大 IOPS 不超过 5000 ,在业务上可以防止并发流量过大影响其他租户, 1 号(红线)、2 号(绿线)租户本身 IOPS 量比较大,配置上限是 10 万,权重比可以控制流量比较大的租户之间的关系,比如永远保持 2:1 的关系。如果 3 号(黄线)租户新加入这个集群,会对集群产生什么冲击呢?由于 4 号租户有限制,因此不受影响,3 号租户的 IOPS 可以向 1 号、2 号租户借,1 号、2 号租户按照比例下降权重,这样就可以起到租户间的隔离作用。
除了租户间的隔离外,还有租户内的隔离。为什么要做租户内的隔离呢?
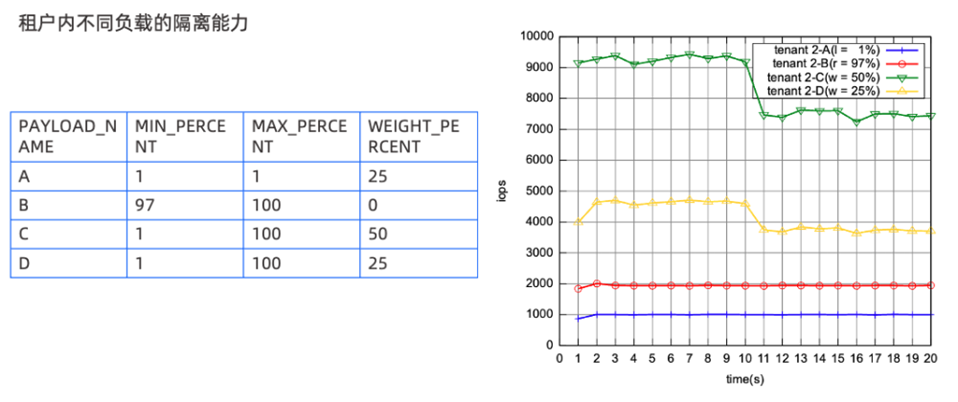
从两个场景来看:第一,HTAP 场景,比如同时需要承担 TP 和 AP 业务流量的情况下,避免对于延迟敏感的TP型请求受到干扰,影响正常业务流量的稳定性;第二,前台流量和后台流量隔离,如果后台资源隔离做不好,则会影响前台的查询请求,进而产生用户可感知的抖动。租户内隔离可以做到不同负载混合场景下都能安全有效地使用资源,举个例子,下图中ABCD 可以是不同的负载,B 的 Min Percent 设置 97%,意味着虽然 B 是最小的 IOPS,但希望能保证最小的 IOPS 不至于跌的很低(蓝线),A 和 C 本身的权重是 50:25,从图中也可以看到保持着 2:1 的关系,去保证不同的负载能够拿到相应的 IOPS 。
Compaction优化,降低空间放大和磁盘开销
作为存储引擎中另一个对系统资源依赖比较重的领域,Compaction 一直是基于LSM-Tree架构的系统里最值得深入研究和探索的核心技术热点之一。各家厂商都在解决读放大、写放大和空间放大间上的权衡问题上,有着这各自的优化。Compaction 的技术掌控力,关系到能不能为用户节省下更多的计算资源,投入到处理更多的业务请求,达到更佳的性价比。OceanBase 存储引擎经过十多年的自研探索,在 compaction 的计算性能提升和磁盘空间等资源成本降低方面应用了许多有效的优化方法。
OceanBase 存储引擎的 Compaction 整体采用的是业内熟知的Tiered & Leveled Policy,在此基础上,根据事务特性、数据特征、资源依赖等因素,设计不同类型的compaction。
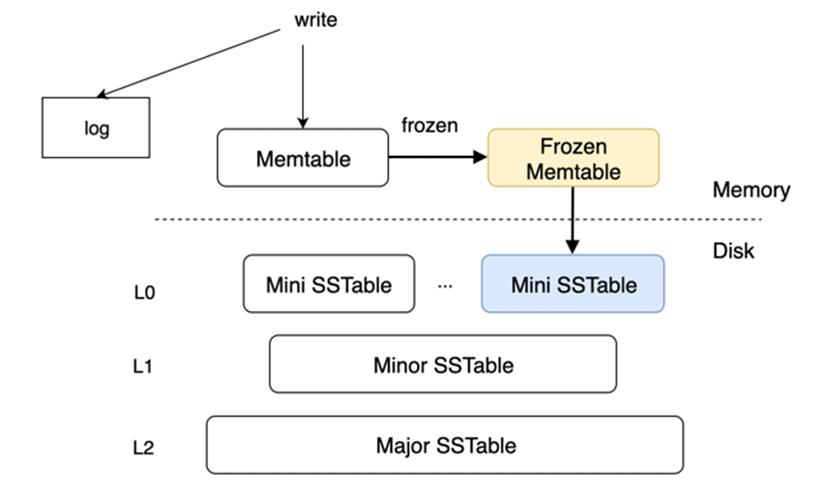
如下图,整个LSM-Tree的持久化SSTable只有三层,有别于RocksDB、Cassandra和一些其他系统的多层优化。虽然层数不多,但每一层SSTable都有其设计目的。L0 层目的在于尽快释放内存,其中对于数据的处理逻辑必须是低耗且快速的;L1 层则是尽可能地消除读放大,因为数据之间可能出现交叉,包括空间上的数据冗余及时间是多版本间的冗余,还需要考虑磁盘开销;L2层不仅要彻底解决空间放大的问题,还要做到数据校验、回收和压缩等较复杂且带有事务和分布式特性的功能点。
基于数据处理和系统资源两方面的深入分析,OceanBase 存储引擎在4.x版本中设计了多类型的 compaction (mini、minior、medium、major),能够依据系统内资源的实时状况,结合统计采样,自动调用相应的compaction,达到动态平衡缓解资源瓶颈、提高系统稳定性的目的。其中:
- Mini Compaction 负责生成L0层的SSTable,磁盘格式上采用高效的稠密格式,不采用耗时较大的压缩技术,在最大化iops的同时,对CPU消耗最小。
- Minor Compaction 负责生成L1层,合并多个L0和L1层SSTable。其功能是重新整理同一主键上的多版本数据,提高查询性能,自动探测增量数据间的重叠范围,做宏块级别的数据块重用,降低空间放大。未来,还会支持数据编码和压缩,进一步降低磁盘开销。
- Major Compaction 产生L2层的基线数据。在降本方面,major是主要的贡献者。除了进一步回收增量数据中的老版本数据、磁盘格式根据用户的表格属性会采用高级压缩技术降低存储成本以外,4.x版本中还对于离散插入导致的数据空洞做重整和压缩,对于不同类型的数据更新模型有好的支持。另外,major还负责多副本间的数据校验,保证数据存储的安全可靠。
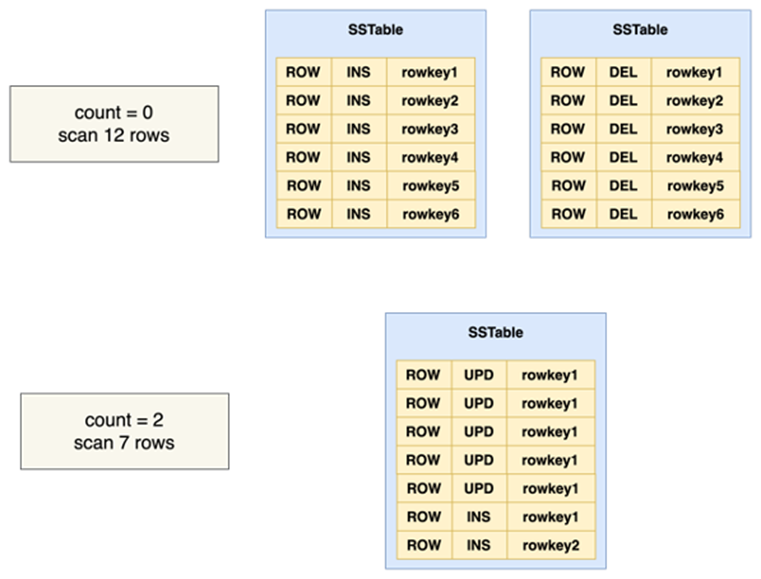
而Medium Compaction,作用之一是解决LSM-Tree 架构中著名的queuing表问题。举个例子,如下图中用户插入 6 行数据,随后又删除这 6 行数据。从逻辑上来说,Table 是空的,但实际查询扫描的物理行数仍然是12 行。再例如 update 和 inset 交互的场景,也会出现聚合count为2行,但实际扫描代价为7行的问题。这类现象归结为物理行数与逻辑行数的巨大差异造成了查询性能的不及预期。
在 OceanBase 的老版本中,用户在建表时需要显式指定 buffer 表属性,以提示存储引擎发现行数比较多的buffer表,尽快触发特殊的 compaction 动作把一些行压缩掉。OceanBase 4.1 版本里,存储引擎在每次生成 SSTable 时,会智能地对数据做统计信息收集。对于每个SSTable,通过一组向量来表示这组数据的更新特征,当发现符合queuing表的特征时,系统会自动发起medium compaction,消除冗余数据。这一过程对于用户是无感的,不需要用户在建表前感知业务特性,也不会在系统上线后被迫做一次DDL,降低了使用OceanBase 的门槛,提高业务切流后的稳定性。
编码与压缩,存储空间极致降本
除了在资源利用、磁盘占用、内存占用方面降低整体成本外,还有一个关键在于降低存储成本,其中的核心技术在于存储引擎。尤其是在海量数据的历史库场景中,越是好的存储引擎带来的降本收益越是可观。
很直白地说,OceanBase 存储引擎在降成本方面有着传统数据库不具备的架构优势。一般而言,基于 B+ Tree 的传统数据库,由于是in place update,底层的 block 又是定长的,因此在存储压缩后会有写放大的碎片问题需要解决,同时会对查询性能造成一定影响。OceanBase使用LSM-Tree 存储架构,为数据库压缩提供了更多可能。首先,消除了传统 B+Tree 的磁盘随机写瓶颈和存储空间碎片化问题,相比传统实时更新数据块的方式,拥有更高的写入性能。其次,可以将数据更新(增删改)与压缩动作解耦,数据更新路径中没有压缩动作,对性能影响更小。同时,在批量落盘的过程中,数据库可以自适应地调整数据块中的数据量,并在连续对数据块进行压缩的过程中,利用上一个块的压缩率等先验知识对下一个块进行更好地压缩。
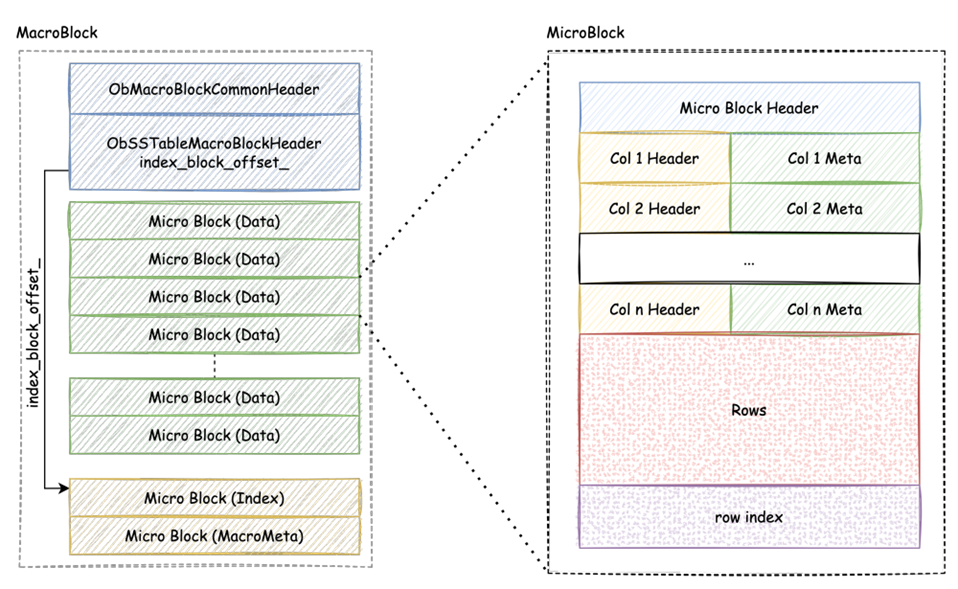
如下图所示,OceanBase 存储引擎针对高压缩比的磁盘格式,采用行列混存模式。区别于行存模式,微块内的数据不再是一条条铺平的行,而是按列先组织在一起。Compaction生成SStable期间,对于微块的编码和压缩是分两步进行的。第一步会利用某一列上相邻行的数据特征,挑选比较合适的算法进行编码,经过第一层编码后的压缩率往往能够达到 50%,第二步再对编码后的微块进行一次通用压缩,最终甚至能达到平均30%更极致的压缩率。
OceanBase 存储引擎在选择编码算法时,会自动分析数据类型、值域、NDV 等特征,参考相邻微块的编码压缩历史,是自适应启发式的算法。例如,对于用小范围的字符串像车辆牌照等,支持 Bit-packing 和 HEX 编码,能够有效降低存储的位宽,达到编码压缩的效果;对于列数据重复率高的例如性别、星座等,会采用字典编码和 RLE 编码做单列数据去重;对于字符串或值域相近的采用差值编码;当数据列与列之间存在关联或者前缀相近时,如商品大类之间的条形码,采用列间编码减小多列数据冗余。
对于编码数据的查询是不需要解码的,除了直接查询以外,还支持聚合与过滤的下压、支持 SIMD 向量化运算。后续OceanBase 将发布真正的列存版本,能对数据编码特征做探测和自适应调整,支持更高级的skip index功能,对 AP 的查询性能会有非常明显的提升。
总结:OceanBase 存储引擎低成本、高效管理数据的秘诀
OceanBase的存储引擎经过多年全自研探索,从数据流入到流出的各个环节都对资源开销成本做了极致优化,形成一套统一的高效、可扩展的数据存储架构。
- 在数据组织上,对各层元数据采用了按需加载的方式,使系统的内存资源服务于访问更频繁的热点数据,进一步降低单机规格依赖,提升小规格场景的收益。
- 在数据写入路径,多层次、多类型compaction策略,在保证高效写入性能的同时,又能保证平滑不抖动,自动压缩数据空洞,高压缩比基线数据,降低存储成本。
- 在数据查询方面,不同格式均支持聚合和过滤下推、SIMD向量化以及未来的skip index,提升了大查询和AP性能。
- 在资源管控中,租户间CPU、内存和I/O等资源隔离逐步完善,使同一套集群服务于多业务系统,降低系统整体成本。
以上只是存储引擎中的冰山一角,希望后续有更多机会立足用户的实际体验和场景,与大家交流存储引擎的技术内幕和细节。
相关文章:
OceanBase 4.x 存储引擎解析:如何让历史库场景成本降低50%+
据国际数据公司(IDC)的报告显示,预计到2025年,全球范围内每天将产生高达180ZB的庞大数据量,这一趋势预示着企业将面临着更加严峻的海量数据处理挑战。随着数据日渐庞大,一些存储系统会出现诸如存储空间扩展…...

js 如何写构造函数 ,构造函数和普通函数有什么区别
在 JavaScript 中,构造函数是一种特殊的函数,用于初始化一个新创建的对象。构造函数通常用来创建具有相似属性和方法的对象实例。构造函数的主要特点是在调用时使用 new 关键字,这样就会创建一个新对象,并将其原型设置为构造函数的…...

MySQL-进阶篇-锁(全局锁、表级锁、行级锁)
文章目录 1. 锁概述2. 全局锁2.1 介绍2.2 数据备份2.3 使用全局锁造成的问题 3. 表级锁3.1 表锁3.1.1 语法3.1.2 读锁3.1.3 写锁3.1.4 读锁和写锁的区别 3.2 元数据锁(Meta Data Lock,MDL)3.3 意向锁3.3.1 案例引入3.3.2 意向锁的分类 4. 行级…...
多种实现方式及最优比较)
c++懒汉式单例模式(Singleton)多种实现方式及最优比较
前言 关于C懒汉式单例模式的写法,大家都很熟悉。早期的设计模式中有代码示例。比如: class Singleton {private: static Singleton *instance;public: static Singleton *getInstance() {if (NULL instance)instance new Singleton();return instanc…...

Gartner《2024中国安全技术成熟度曲线》AI安全助手代表性产品:开发者安全助手D10
海云安关注到,近日,国际权威研究机构Gartner发布了《2024中国安全技术成熟度曲线》(Hype Cycle for Security in China,2024)报告。 在此次报告中,安全技术成熟度曲线将安全周期划分为技术萌芽期(Innovation Trigger)…...

奇安信椒图--服务器安全管理系统(云锁)
奇安信椒图–服务器安全管理系统(云锁) 椒图 奇安信服务器安全管理系统是一款符合Gartner定义的CWPP(云工作负载保护平台)标准、EDR(终端检测与响应)、EPP终端保护平台(终端保护平台ÿ…...

pointer-events,添加水印的一个小小点
场景:平平无奇一个水印图,这类功能实现:就是覆盖在整个可视div后,又加了一个div(使用定位canvas画一个水印图充当背景),可时我好奇的是,我使用控制台,选择对应的元素时&a…...

微服务--认识微服务
微服务架构的演变 1. 单体架构(Monolithic) 阶段描述:在单体应用时代,整个应用程序被设计为一个项目,并在一个进程内运行。这种架构方式开发简单,便于集中管理,但随着应用的复杂化,…...

【docker】docker 镜像仓库的管理
Docker 仓库( Docker Registry ) 是用于存储和分发 Docker 镜像的集中式存储库。 它就像是一个大型的镜像仓库,开发者可以将自己创建的 Docker 镜像推送到仓库中,也可以从仓库中拉取所需的镜像。 Docker 仓库可以分为公共仓…...
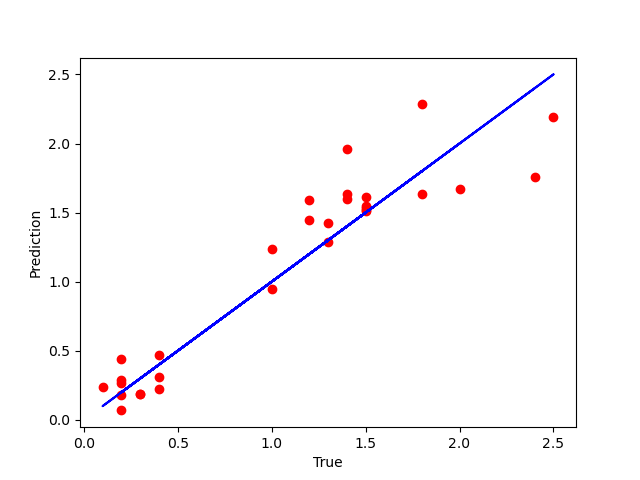
第L2周:机器学习-线性回归
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目标: 学习简单线性回归模型和多元线性回归模型通过代码实现:通过鸢尾花花瓣长度预测花瓣宽度 具体实现: (一&…...

SpringMVC拦截器深度解析与实战
引言 Spring MVC作为Spring框架的核心模块之一,主要用于构建Web应用程序和RESTful服务。在Spring MVC中,拦截器(Interceptor)是一种强大的机制,它允许开发者在请求处理流程的特定点插入自定义代码,实现诸如…...

直线上最多的点数
优质博文:IT-BLOG-CN 题目 给你一个数组points,其中points[i] [xi, yi]表示X-Y平面上的一个点。求最多有多少个点在同一条直线上。 示例 1: 输入:points [[1,1],[2,2],[3,3]] 输出:3 示例 2: 输入&am…...

经济管理专业数据库介绍
本文介绍了四个经济管理专业数据库:国研网全文数据库、EPS数据平台、中经网、Emerald全文期刊库(管理学)。 一、国研网全文数据库 国研网是国务院发展研究中心主管、北京国研网信息有限公司承办的大型经济类专业网站。国研网教育版”是国研…...

【C++ Primer Plus习题】11.1
问题: 解答: main.cpp #include <iostream> #include <fstream> #include "Vector.h" #include <time.h> using namespace std; using namespace VECTOR;int main() {ofstream fout;fout.open("randwalk.txt");srand(time(0));double d…...

[数据库][oracle]ORACLE EXP/IMP的使用详解
导入/导出是ORACLE幸存的最古老的两个命令行工具,其实我从来不认为Exp/Imp是一种好的备份方式,正确的说法是Exp/Imp只能是一个好的转储工具,特别是在小型数据库的转储,表空间的迁移,表的抽取,检测逻辑和物理…...

中国各银行流动性比例数据(2000-2022年)
介绍中国银行业2000年至2022年间的流动性比例数据,涵盖500多家银行,包括城市商业银行、城镇银行、大型商业银行、股份制银行、民营银行、农村合作银行、农村商业银行、农村信用社等。这些数据对于理解中国银行业的流动性状况至关重要,有助于投…...

MACOS安装配置前端开发环境
官网下载安装Mac版本的谷歌浏览器以及VS code代码编辑器,还有在App Store中直接安装Xcode(里面自带git); node.js版本管理器nvm的下载安装如下: 参考B站:https://www.bilibili.com/video/BV1M54y1N7fx/?sp…...
Docker 配置国内镜像源
由于 GFW 的原因,在下载镜像的时候,经常会出现下载失败的情况,此时就可以使用国内的镜像源。 什么是镜像源:简单来说就是某个组织(学校、公司、甚至是个人)先通过某种手段将国外的镜像下载下来,…...

AI模块在人工智能中扮演着什么样的角色
AI模块在人工智能(AI)中扮演着核心和关键的角色。它们是构成AI系统的基础单元,负责实现AI系统的各种智能功能。以下是AI模块在人工智能中扮演的具体角色: 功能实现的核心:AI模块集成了实现特定智能功能所需的算法、数据…...
VM Workstation虚拟机AlmaLinux 9.4操作系统安装(桌面版安装详细教程)(宝塔面板的安装),填补CentOS终止支持维护的空白
目录 AlmaLinux介绍 AlmaLinux操作系统的安装 1、下载镜像文件 2、新建虚拟机 (1)点击创建新的虚拟机 (2)打开虚拟机向导后,选择“自定义”安装,然后点击“下一步” (3)选择虚…...

Simulink电气系统建模遇阻?一文详解powergui模块缺失报错与修复
1. 为什么你的Simulink电气模型总是报错? 最近在技术论坛上看到不少电气工程师吐槽:"明明是按照教程搭建的Simscape电机模型,一运行就弹出红色报错框,说什么必须包含powergui模块..." 这让我想起自己刚接触Simulink电气…...

ADC前端模拟电路设计
对自己工作的一个总结...
)
从LevelDB到自研PoolEngine:金融C++内存池测试演进史(2003–2024,12次重大架构迭代中的3次致命教训)
第一章:从LevelDB到自研PoolEngine:金融C内存池测试演进史(2003–2024,12次重大架构迭代中的3次致命教训)在高频交易系统与实时风控引擎的严苛场景下,内存分配延迟的微秒级波动即可能引发订单错配或熔断失效…...

数据安全守护:QQ空间历史说说备份工具全攻略
数据安全守护:QQ空间历史说说备份工具全攻略 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字记忆日益珍贵的今天,QQ空间承载着无数人的青春回忆与生活印记…...

OpenClaw技能扩展实战:用Qwen3-14B镜像自动生成技术文档
OpenClaw技能扩展实战:用Qwen3-14B镜像自动生成技术文档 1. 为什么需要自动化文档生成 作为一个经常需要编写技术文档的开发者,我长期被两个问题困扰:一是文档写作耗时太长,二是维护成本太高。每次代码更新后,文档版…...

Tessent测试流程文件里的Tcl魔法:用if/else让你的扫描测试配置更灵活
Tessent测试流程文件里的Tcl魔法:用if/else让你的扫描测试配置更灵活 在芯片测试领域,Tessent Shell作为业界领先的测试解决方案,其Test Procedure File(测试流程文件)的灵活运用往往能决定测试效率的高低。今天我们要…...

Arroyo分布式流处理引擎的完整测试策略指南:单元测试、集成测试与SQL测试框架详解
Arroyo分布式流处理引擎的完整测试策略指南:单元测试、集成测试与SQL测试框架详解 【免费下载链接】arroyo Distributed stream processing engine in Rust 项目地址: https://gitcode.com/gh_mirrors/ar/arroyo Arroyo是一个用Rust编写的分布式流处理引擎&a…...
C 语言(第二天)核心语法:运算符与流程控制(超详细笔记))
嵌入式Linux学习(Day05)C 语言(第二天)核心语法:运算符与流程控制(超详细笔记)
本文整理 C 语言运算符和流程控制语句核心知识点,结合表格梳理语法规则、搭配代码示例 实战练习,零基础友好,适合入门巩固、刷题备考,可直接用于 C 语言基础学习参考。一、运算符补充C 语言运算符是编程基础,本节重点…...

2026应届生面试避坑指南:避开这些致命细节,求职成功率翻倍
文章目录前言一、简历不是自传,而是广告文案第一个大坑:把简历做成PPT艺术展。第二个大坑:把简历写成流水账。第三个大坑:一份简历海投百家。二、八股文背得溜,场景题一到就露馅丢分细节一:只会背概念&…...

BERT文本分割-中文-通用领域一文详解:为什么它比传统规则分段更准?
BERT文本分割-中文-通用领域一文详解:为什么它比传统规则分段更准? 你有没有遇到过这种情况?拿到一份长长的会议记录或者讲座文稿,从头到尾密密麻麻全是字,没有段落,没有结构,读起来特别费劲&a…...