Tensorflow2如何读取自制数据集并训练模型?-- Tensorflow自学笔记13
一. 如何自制数据集?
1. 目录结构
以下是自制数据集-手写数字集, 保存在目录 mnist_image_label 下

2. 数据存储格式
2.1. 目录mnist_train_jpeg_60000 下存放的是 60000张用于测试的手写数字
如 : 0_5.jpg, 表示编号为0,标签为5的图片
6_1.jpg, 表示编号为6,标签为1的图片

2.2. 目录mnist_test_jpeg_10000 下存放的是10000张用于测试的手写数字
图片存储格式与1.1相同
2.3. txt文件 mnist_train_jpg_60000.txt,里面存放的是

比如,第一行 28755_0.jpg 0 前面表示图片名称,后面的0表示该图片对应的标签,这里表示该图片是手写数字0.
2.4. txt文件 mnist_test_jpg_10000.txt , 存放的是测试数据集的标签
二. 如何读取自制数据集并输入神经网络
以下是test.py 如何读取自制数据集代码
1. 导入需要的库
import tensorflow as tf
from PIL import Image
import numpy as np
import os
2.设置数据集所在文件目录
(test.py, 需和mnist_image_label 目录在同一级目录下)
train_path = './mnist_image_label/mnist_train_jpg_60000/'train_txt = './mnist_image_label/mnist_train_jpg_60000.txt'x_train_savepath = './mnist_image_label/mnist_x_train.npy'y_train_savepath = './mnist_image_label/mnist_y_train.npy'test_path = './mnist_image_label/mnist_test_jpg_10000/'test_txt = 'v/mnist_image_label/mnist_test_jpg_10000.txt'x_test_savepath = './mnist_image_label/mnist_x_test.npy' #训练集输入特征存储文件npy,y_test_savepath = './mnist_image_label/mnist_y_test.npy' #训练集标签存储文件3.定义读取数据的函数
def generateds(path, txt):f = open(txt, 'r') # 以只读形式打开txt文件contents = f.readlines() # 读取文件中所有行f.close() # 关闭txt文件x, y_ = [], [] # 建立空列表for content in contents: # 逐行取出value = content.split() # 以空格分开,图片路径为value[0] , 标签为value[1] , 存入列表img_path = path + value[0] # 拼出图片路径和文件名print('image path....: '+img_path)img = Image.open(img_path) # 读入图片img = np.array(img.convert('L')) # 图片变为8位宽灰度值的np.array格式img = img / 255. # 数据归一化 (实现预处理)x.append(img) # 归一化后的数据,贴到列表xy_.append(value[1]) # 标签贴到列表y_print('loading : ' + content) # 打印状态提示x = np.array(x) # 变为np.array格式y_ = np.array(y_) # 变为np.array格式y_ = y_.astype(np.int64) # 变为64位整型return x, y_ # 返回输入特征x,返回标签y_
4.调用定义的函数
if os.path.exists(x_train_savepath) and os.path.exists(y_train_savepath) and os.path.exists(x_test_savepath) and os.path.exists(y_test_savepath):print('-------------Load Datasets-----------------')x_train_save = np.load(x_train_savepath)y_train = np.load(y_train_savepath)x_test_save = np.load(x_test_savepath)y_test = np.load(y_test_savepath)x_train = np.reshape(x_train_save, (len(x_train_save), 28, 28))x_test = np.reshape(x_test_save, (len(x_test_save), 28, 28))else:print('-------------Generate Datasets-----------------')x_train, y_train = generateds(train_path, train_txt)x_test, y_test = generateds(test_path, test_txt)print('-------------Save Datasets-----------------')x_train_save = np.reshape(x_train, (len(x_train), -1))x_test_save = np.reshape(x_test, (len(x_test), -1))np.save(x_train_savepath, x_train_save)np.save(y_train_savepath, y_train)np.save(x_test_savepath, x_test_save)np.save(y_test_savepath, y_test)5. 搭建神经网络训练数据
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(10, activation='softmax')
])model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
相关文章:
Tensorflow2如何读取自制数据集并训练模型?-- Tensorflow自学笔记13
一. 如何自制数据集? 1. 目录结构 以下是自制数据集-手写数字集, 保存在目录 mnist_image_label 下 2. 数据存储格式 2.1. 目录mnist_train_jpeg_60000 下存放的是 60000张用于测试的手写数字 如 : 0_5.jpg, 表示编号为0,标签为5的图片 6_1.jpg, 表示…...
JVM系列(七) -对象的内存分配流程
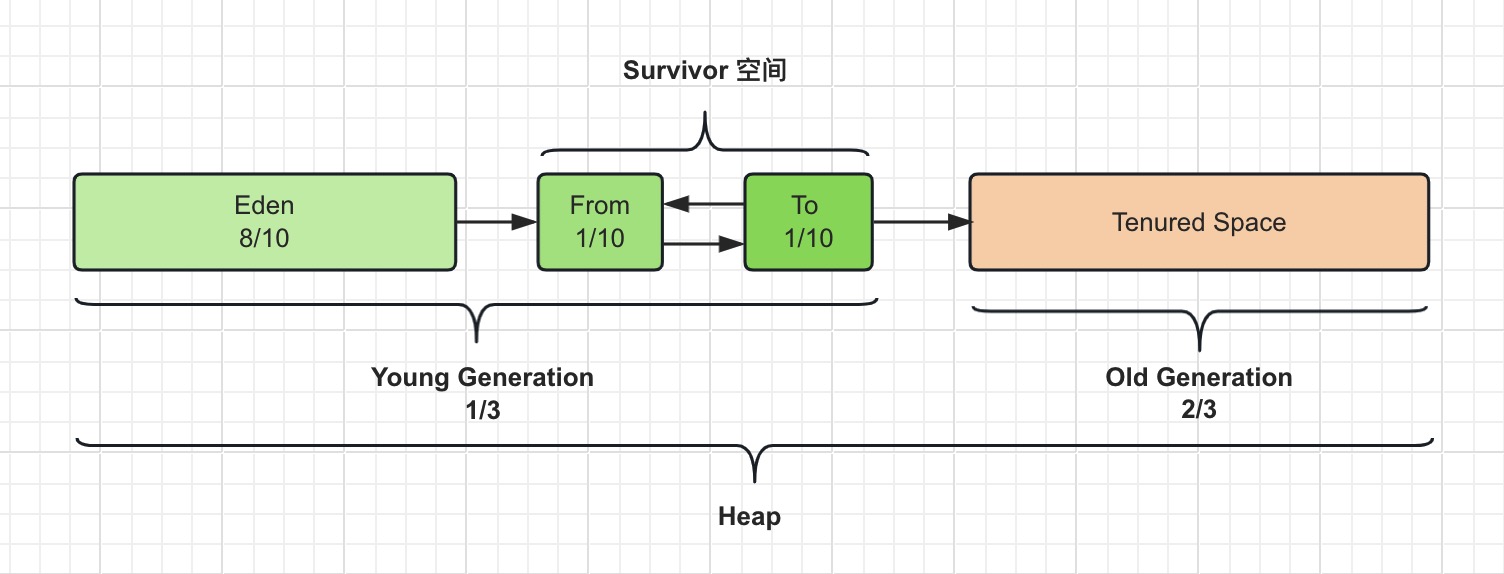
一、摘要 在之前的文章中,我们介绍了类加载的过程、JVM 内存布局和对象的创建过程相关的知识。 本篇综合之前的知识,重点介绍一下对象的内存分配流程。 二、对象的内存分配原则 在之前的 JVM 内存结构布局的文章中,我们介绍到了 Java 堆的内存布局,由 年轻代 (Young Ge…...

Apache Ignite 在处理大规模数据时有哪些优势和局限性?
Apache Ignite 在处理大规模数据时的优势和局限性可以从以下几个方面进行分析: 优势 高性能:Ignite 利用内存计算的优势,实现了极高的读写性能,通过分布式架构,它可以将数据分散到多个节点上,从而实现了并…...
怎么利用NodeJS发送视频短信
随着5G时代的来临,企业的数字化转型步伐日益加快,视频短信作为新兴的数字营销工具,正逐步展现出其大的潜力。视频群发短信以其独特的形式和内容,将图片、文字、视频、声音融为一体,为用户带来全新的直观感受࿰…...

WebAPI(三)、 DOM 日期对象Date;获取事件戳;根据节点关系查找节点
文章目录 DOM1. 日期对象(1)、日期对象方法(2)、时间戳(3)、下课倒计时 2. 节点操作(1)、 查找节点(根据节点关系找)(2)、 增加节点:创建create、追加append、克隆clone(3)、 删除节点remove DOM 1. 日期对象 日期对象就是用来表示时间的对…...

012.Oracle-索引
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈 入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈 虚 拟 环 境 搭 建 :👉&…...

SSL 证书 | 免费获取与自动续期全攻略
前言 随着互联网的不断发展,网站的安全性越来越受到人们的关注。 SSL证书 作为一种保障网站安全的重要手段,已经成为了许多网站的必备配置。 以前阿里云每个账号能生成二十个期限 1 年的免费 SSL 证书,一直用,还挺香࿰…...
)
达梦数据库管理员常用SQL(一)
达梦数据库管理员常用SQL(一) 数据库基本信息数据库参数信息表空间信息日志文件信息进程和线程信息会话连接信息SQL执行信息等待事件信息事务和锁信息数据库基本信息 --查询数据库内部版本号 select id_code; select build_version from v$instance; select * from v$versi…...
OKHttpClient使用详细教程)
HttpUtils工具类(三)OKHttpClient使用详细教程
OkHttpClient 是一个由 Square 公司开发的 HTTP 客户端库,用于在 Android 和 Java 应用中进行网络请求。它支持同步和异步请求、连接池、超时设置、拦截器等功能,适合用于高性能网络请求,特别是在需要处理复杂的网络操作时。 一、OKHttpClien…...

重生奇迹MU老大哥剑士职业宝刀未老
重生奇迹MU中,老大哥剑士职业一直以来备受玩家们的喜爱。这个职业不仅拥有强大的攻击力、防御力和战斗技巧,而且还能够通过使用各种宝刀来增强自身的战斗能力。即便经过了多年的沉淀,老大哥剑士依然是一名宝刀未老的男人,仍然能够…...

关于Netty详细介绍,Netty原理架构解析
Netty 是什么 1)Netty 是 JBoss 开源项目,是异步的、基于事件驱动的网络应用框架,它以高性能、高并发著称。所谓基于事件驱动,说得简单点就是 Netty 会根据客户端事件(连接、读、写等)做出响应,…...

在Unity环境中使用UTF-8编码
为什么要讨论这个问题 为了避免乱码和更好的跨平台 我刚开始开发时是使用VS开发,Unity自身默认使用UTF-8 without BOM格式,但是在Unity中创建一个脚本,使用VS打开,VS自身默认使用GB2312(它应该是对应了你电脑的window版本默认选取了国标编码,或者是因为一些其他的原因)读取脚本…...

零工市场小程序:自由职业者的日常工具
零工市场小程序多功能且便捷,提供了前所未有的灵活性和工作效率。这类小程序不仅改变了自由职业者的工作方式,也重塑了劳动力市场的格局。 一、零工市场小程序的特点 即时匹配:利用先进的数据算法,零工市场小程序能够快速匹配自由…...

【Http 每日一问,访问服务端的鉴权Token放在header还是cookie更合适?】
结论先行: token静态的,不变的,放在header里面。 典型场景 ,每次访问时需要带个静态token请求服务端,向服务端表明是谁请求,此时token也可以认为是个固定的access-key。token动态的,会失效&…...

vue2+ueditor集成秀米编辑器
一、百度富文本编辑器 1.首先下载 百度富文本编辑器 下载地址:GitHub - fex-team/ueditor: rich text 富文本编辑器 2.把下载好的文件整理好 放在图片目录下 3. 安装插件vue-ueditor-wrap npm install vue-ueditor-wrap 4.在你所需要展示的页面 引入vue-uedito…...

[网络]HTTP协议 Cookie与Session
一、Cookie 1.1 定义 HTTP Cookie(也称为 Web Cookie、浏览器 Cookie 或简称 Cookie)是服务器发送到 用户浏览器并保存在浏览器上的一小块数据,它会在浏览器之后向同一服务器再次发 起请求时被携带并发送到服务器上。通常,它用于…...

安宝特科技 | AR眼镜在安保与安防领域的创新应用及前景
随着科技的不断进步,增强现实(AR)技术逐渐在多个领域展现出其独特的优势,尤其是在安保和安防方面。AR眼镜凭借其先进的功能,在机场、车站、海关、港口、工厂、园区、消防局和警察局等行业中为安保人员提供了更为高效、…...

2024 第十二届重庆国际植保双交会暨新型肥料农药产业博览会
2024 第十二届重庆国际植保双交会暨新型肥料农药产业博览会,引领农业新未来 农业,是人类生存的基石,是社会发展的保障。而肥料和农药,作为农业生产的重要投入品,其品质和技术的不断创新,直接关系着农业的可…...
用“说”智能控制灯具开关语音识别芯片NRK3603
用“说”智能控制灯具开关是一种基于语音识别技术的智能家居设备,它通过内置的语音识别芯片,利用离线识别算法,将用户的语音指令实现对灯具的控制,NRK3603语音识别芯片成为客户低成本的离线语音识别方案。 功能特性: …...
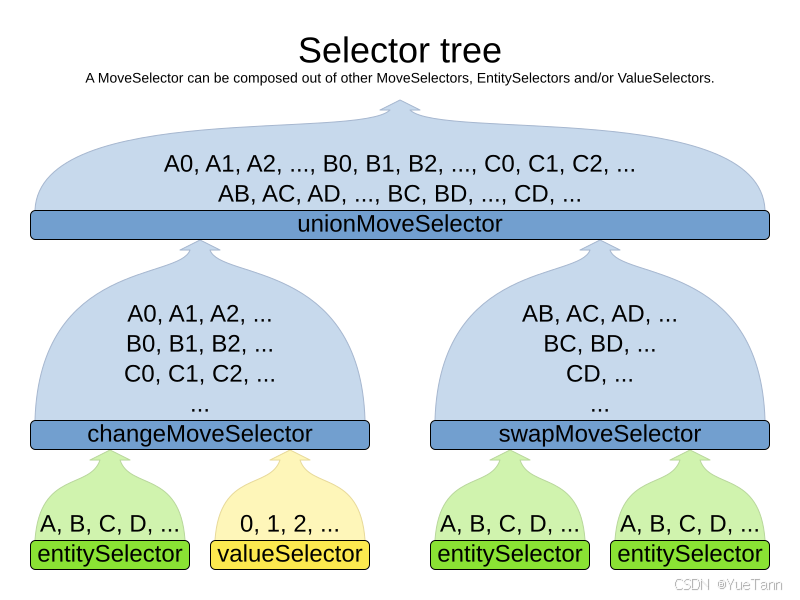
APS开源源码解读: 排程工具 optaplanner
抽象层次非常好,广义优化工具。用于排产没有复杂的落地示例 https://github.com/apache/incubator-kie-optaplanner/blob/main/optaplanner-examples/src/main/java/org/optaplanner/examples/projectjobscheduling/app/ProjectJobSchedulingApp.javahttps://github…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

2026年,本地精准营销高性价比服务商来袭,你还不了解一下?
在本地商业竞争日益激烈的2026年,实体店面临着诸多挑战,引流难、成本高、复购率低等问题困扰着众多商家。而中粤(广州)信息科技有限公司作为本地精准营销的高性价比服务商,正以其独特的优势和卓越的服务,为…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

机器学习赋能矩方法:破解稀薄气体强非平衡流动模拟难题
1. 项目概述:当矩方法遇见机器学习在计算流体力学领域,模拟稀薄气体动力学和强非平衡流动,一直是个让工程师和科学家们头疼的“硬骨头”。想象一下,你正在设计一架高超音速飞行器,当它以数倍音速在大气层边缘飞行时&am…...