DataLoader使用
文章目录
- 一、认识dataloader
- 二、DataLoader整合数据集
- 三、使用DataLoader展示图片方法
- 四、去除结尾不满足batch_size设值图片的展示
一、认识dataloader
DataLoader 用于封装数据集,并提供批量加载数据的迭代器。它支持自动打乱数据、多线程数据加载等功能。dataset只是告诉我们数据集在一个什么位置,而dataloader则可以把数据加载到神经网络当中。dataloader就相当于在dataset当中去取数据,怎么取。

dataset就相当于一副牌,而dataloader就相当于每次从dataset这幅牌堆中怎么抽牌,是一次性抽5张牌,用左手抽还是右手抽。相对而言dataloader就是方法。
二、DataLoader整合数据集
将4个数据中的img 和 target 分别封装起来,称为imgs,targets

import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter#准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)#测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)for data in test_loader:imgs, targets = dataprint(imgs.shape)print(targets)
test_loader = DataLoader(
dataset=test_data, # 指定要加载的数据集
batch_size=4, # 指定每个批次的大小为4,4表示从数据集中取4个数据
shuffle=True, # 设置为True表示在每个epoch开始时打乱数据。一个epoch意味着数据加载器将整个数据集按照指定的顺序(可能是随机的,如果设置了shuffle=True)遍历一次。
num_workers=0, # 指定加载数据时使用的子进程数,0表示在主进程中加载数据
drop_last=False # 设置为False表示即使最后一个批次的数据量小于batch_size也会加载,True则不加载
)
print(imgs.shape)表示打印批次中图像张量的形状,例如(4, 3, 32, 32),表示有4张图像,每张图像有3个颜色通道,大小为32x32像素
运行结果:

在机器学习中,这样的张量通常用来表示分类任务中的标签。例如,在 CIFAR-10 数据集中,每个图像都有一个与之对应的标签,表示图像中物体的类别。CIFAR-10 数据集包含10个类别,每个类别用一个数字(0到9)来表示。
在这个例子中,tensor([3, 3, 7, 1]) 可能表示一个包含4张图像的批次,每张图像的标签分别是:
第一张图像的标签是 3
第二张图像的标签也是 3
第三张图像的标签是 7
第四张图像的标签是 1
三、使用DataLoader展示图片方法
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter#准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)#测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter("dataloader")# 初始化一个变量step,用于记录当前的步骤或批次编号
step = 0# 使用add_images方法将当前批次的图像写入TensorBoard日志
# "test_data"是图像在TensorBoard中的标签,imgs是要记录的图像张量,step是当前的步骤编号
for data in test_loader:imgs, targets = datawriter.add_images("test_data", imgs, step)# 每次迭代后,步骤编号增加1step = step + 1writer.close()
运行结果:

四、去除结尾不满足batch_size设值图片的展示
将drop_last 设置为True,就可以去除末尾不满足batch_size设值的照片
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter#准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())test_loader = DataLoader(dataset=test_data, batch_size=64,shuffle=True,num_workers=0,drop_last=True)#测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter("dataloader")# 初始化一个变量step,用于记录当前的步骤或批次编号
step = 0
# 使用add_images方法将当前批次的图像写入TensorBoard日志
# "test_data"是图像在TensorBoard中的标签,imgs是要记录的图像张量,step是当前的步骤编号
for data in test_loader:imgs, targets = datawriter.add_images("test_data_drop_last", imgs, step)# 每次迭代后,步骤编号增加1step = step + 1writer.close()
运行结果:

如下面的照片,刚好满足batch_size设值。
相关文章:
DataLoader使用
文章目录 一、认识dataloader二、DataLoader整合数据集三、使用DataLoader展示图片方法四、去除结尾不满足batch_size设值图片的展示 一、认识dataloader DataLoader 用于封装数据集,并提供批量加载数据的迭代器。它支持自动打乱数据、多线程数据加载等功能。datas…...

CSS学习11--版心和布局流程以及几种分布的例子
版心和布局流程 一、版心二、布局流程三、一列固定宽度且居中四、两列左窄右宽五、通栏平均分布型 一、版心 版心:是指网页主题内容所在的区域。一般在浏览器窗口水平居中位置,常见的宽度值为960px、980px、1000px、1200px等。 二、布局流程 为了提高…...

NetSuite AI 图生代码
去年的ChatGPT热潮期间,我们写过一篇文章说GTP辅助编程的事。 NetSuite GPT的辅助编程实践_如何打开netsuite: html script notes的视图-CSDN博客文章浏览阅读2.2k次,点赞4次,收藏3次。作为GPT综合症的一种表现,我们今朝来探究下…...

Java - BigDecimal计算中位数
日常开发中,如果使用数据库来直接查询一组数据的中位数,就比较简单,直接使用对应的函数就可以了,例如: SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(目标列名 ORDER BY 目标列名),,,Count(1)/2),,,-1) AS 目标列名_…...

Tensorflow2如何读取自制数据集并训练模型?-- Tensorflow自学笔记13
一. 如何自制数据集? 1. 目录结构 以下是自制数据集-手写数字集, 保存在目录 mnist_image_label 下 2. 数据存储格式 2.1. 目录mnist_train_jpeg_60000 下存放的是 60000张用于测试的手写数字 如 : 0_5.jpg, 表示编号为0,标签为5的图片 6_1.jpg, 表示…...
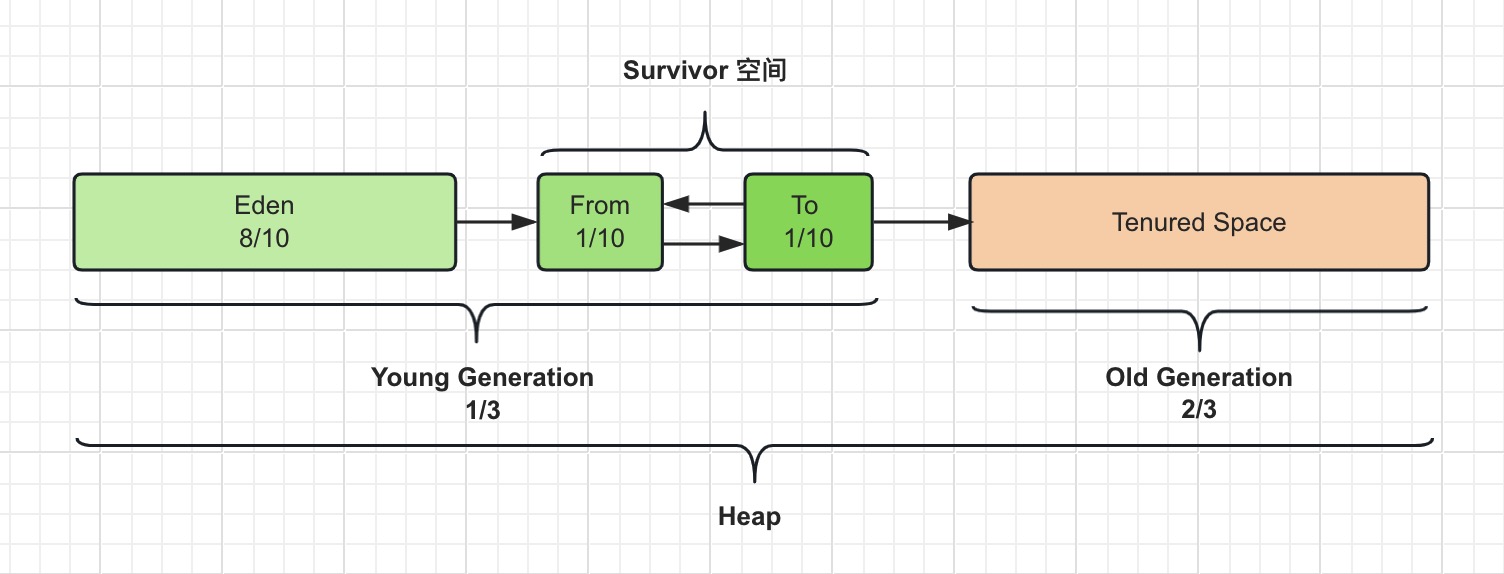
JVM系列(七) -对象的内存分配流程
一、摘要 在之前的文章中,我们介绍了类加载的过程、JVM 内存布局和对象的创建过程相关的知识。 本篇综合之前的知识,重点介绍一下对象的内存分配流程。 二、对象的内存分配原则 在之前的 JVM 内存结构布局的文章中,我们介绍到了 Java 堆的内存布局,由 年轻代 (Young Ge…...

Apache Ignite 在处理大规模数据时有哪些优势和局限性?
Apache Ignite 在处理大规模数据时的优势和局限性可以从以下几个方面进行分析: 优势 高性能:Ignite 利用内存计算的优势,实现了极高的读写性能,通过分布式架构,它可以将数据分散到多个节点上,从而实现了并…...
怎么利用NodeJS发送视频短信
随着5G时代的来临,企业的数字化转型步伐日益加快,视频短信作为新兴的数字营销工具,正逐步展现出其大的潜力。视频群发短信以其独特的形式和内容,将图片、文字、视频、声音融为一体,为用户带来全新的直观感受࿰…...

WebAPI(三)、 DOM 日期对象Date;获取事件戳;根据节点关系查找节点
文章目录 DOM1. 日期对象(1)、日期对象方法(2)、时间戳(3)、下课倒计时 2. 节点操作(1)、 查找节点(根据节点关系找)(2)、 增加节点:创建create、追加append、克隆clone(3)、 删除节点remove DOM 1. 日期对象 日期对象就是用来表示时间的对…...

012.Oracle-索引
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈 入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈 虚 拟 环 境 搭 建 :👉&…...

SSL 证书 | 免费获取与自动续期全攻略
前言 随着互联网的不断发展,网站的安全性越来越受到人们的关注。 SSL证书 作为一种保障网站安全的重要手段,已经成为了许多网站的必备配置。 以前阿里云每个账号能生成二十个期限 1 年的免费 SSL 证书,一直用,还挺香࿰…...
)
达梦数据库管理员常用SQL(一)
达梦数据库管理员常用SQL(一) 数据库基本信息数据库参数信息表空间信息日志文件信息进程和线程信息会话连接信息SQL执行信息等待事件信息事务和锁信息数据库基本信息 --查询数据库内部版本号 select id_code; select build_version from v$instance; select * from v$versi…...
OKHttpClient使用详细教程)
HttpUtils工具类(三)OKHttpClient使用详细教程
OkHttpClient 是一个由 Square 公司开发的 HTTP 客户端库,用于在 Android 和 Java 应用中进行网络请求。它支持同步和异步请求、连接池、超时设置、拦截器等功能,适合用于高性能网络请求,特别是在需要处理复杂的网络操作时。 一、OKHttpClien…...

重生奇迹MU老大哥剑士职业宝刀未老
重生奇迹MU中,老大哥剑士职业一直以来备受玩家们的喜爱。这个职业不仅拥有强大的攻击力、防御力和战斗技巧,而且还能够通过使用各种宝刀来增强自身的战斗能力。即便经过了多年的沉淀,老大哥剑士依然是一名宝刀未老的男人,仍然能够…...

关于Netty详细介绍,Netty原理架构解析
Netty 是什么 1)Netty 是 JBoss 开源项目,是异步的、基于事件驱动的网络应用框架,它以高性能、高并发著称。所谓基于事件驱动,说得简单点就是 Netty 会根据客户端事件(连接、读、写等)做出响应,…...

在Unity环境中使用UTF-8编码
为什么要讨论这个问题 为了避免乱码和更好的跨平台 我刚开始开发时是使用VS开发,Unity自身默认使用UTF-8 without BOM格式,但是在Unity中创建一个脚本,使用VS打开,VS自身默认使用GB2312(它应该是对应了你电脑的window版本默认选取了国标编码,或者是因为一些其他的原因)读取脚本…...

零工市场小程序:自由职业者的日常工具
零工市场小程序多功能且便捷,提供了前所未有的灵活性和工作效率。这类小程序不仅改变了自由职业者的工作方式,也重塑了劳动力市场的格局。 一、零工市场小程序的特点 即时匹配:利用先进的数据算法,零工市场小程序能够快速匹配自由…...

【Http 每日一问,访问服务端的鉴权Token放在header还是cookie更合适?】
结论先行: token静态的,不变的,放在header里面。 典型场景 ,每次访问时需要带个静态token请求服务端,向服务端表明是谁请求,此时token也可以认为是个固定的access-key。token动态的,会失效&…...

vue2+ueditor集成秀米编辑器
一、百度富文本编辑器 1.首先下载 百度富文本编辑器 下载地址:GitHub - fex-team/ueditor: rich text 富文本编辑器 2.把下载好的文件整理好 放在图片目录下 3. 安装插件vue-ueditor-wrap npm install vue-ueditor-wrap 4.在你所需要展示的页面 引入vue-uedito…...

[网络]HTTP协议 Cookie与Session
一、Cookie 1.1 定义 HTTP Cookie(也称为 Web Cookie、浏览器 Cookie 或简称 Cookie)是服务器发送到 用户浏览器并保存在浏览器上的一小块数据,它会在浏览器之后向同一服务器再次发 起请求时被携带并发送到服务器上。通常,它用于…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

AMLP:基于大语言模型的自动化机器学习势函数构建平台
1. 项目概述:当AI遇见原子模拟,AMLP如何重塑机器学习势函数构建在计算材料科学和化学物理领域,分子动力学模拟是我们窥探微观世界动态行为的“显微镜”。无论是研究新材料的相变过程,还是探索生物大分子的折叠机制,其核…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

为什么92%的数据库重构失败?Claude设计辅助如何在48小时内规避反范式陷阱?
更多请点击: https://codechina.net 第一章:为什么92%的数据库重构失败?——反范式陷阱的本质溯源 数据库重构失败率高达92%,其核心症结并非技术能力不足,而是对“反范式”这一设计策略的误读与滥用。许多团队在性能压…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...