MyBatis常见面试题
文章目录
- 说说 MyBatis 执行流程?
- 1. 加载配置文件和映射文件
- 2. 构建 `SqlSessionFactory`
- 3. 创建 `SqlSession`
- 4. 调用 Mapper 方法
- 5. 处理参数和结果映射
- 6. 事务管理
- 7. 释放资源
- 简化流程图:
- MyBatis 和 Hibernate 有什么不同?
- 1. **对象关系映射层次**
- 2. **SQL 控制**
- 3. **开发复杂度**
- 4. **性能**
- 5. **缓存机制**
- 6. **数据库无关性**
- 7. **适用场景**
- 8. **学习曲线**
- 总结
- ${} 和 #{} 有什么区别?
- 1. **`${}`(字符串拼接)**
- 2. **`#{}`(预编译处理)**
- 3. **对比总结**
- **什么时候用哪个?**
- 示例
- 什么是 SQL 注入?
- SQL 注入示例
- SQL 注入的常见类型
- SQL 注入的危害
- 防止 SQL 注入的最佳实践
- 如何解决实体类属性和表中字段不一致的问题?
- 解决方案
- 1. **使用注解映射**
- 2. **使用 XML 配置映射(适用于 MyBatis)**
- MyBatis 中如何实现分页?
- 1. **手动编写分页 SQL**
- 2. **使用 MyBatis-Plus 的分页插件**
- 1) 引入 MyBatis-Plus 依赖
- 2) 配置分页插件
- 3) 使用分页查询
- 3. **使用 PageHelper 插件**
- 1) 引入 PageHelper 依赖
- 2) 配置 PageHelper
- 3) 使用 PageHelper 进行分页
- HashMap 和 Hashtable 可以作为查询结果吗?
- `HashMap` 和 `Hashtable` 作为查询结果
- 1. **HashMap**
- 2. **Hashtable**
- 3. **推荐使用 HashMap 而非 Hashtable**
- 何时使用 `HashMap` 而不是实体类
- 总结
- 说一说动态SQL
- 动态 SQL 的作用
- 动态 SQL 标签
- 1. **`<if>` 标签**
- 2. **`<choose>`、`<when>` 和 `<otherwise>` 标签**
- 3. **`<where>` 标签**
- 4. **`<trim>` 标签**
- 5. **`<set>` 标签**
- 6. **`<foreach>` 标签**
- 7. **`<bind>` 标签**
- 动态 SQL 的优势
- 说一下 MyBatis 的缓存机制?
- 1. 一级缓存(Local Cache)
- 2. 二级缓存(Global Cache)
- 缓存实现
- 缓存策略
- 缓存的注意事项
- 总结
- MyBatis 中有哪些设计模式?
- 1. **单例模式(Singleton Pattern)**
- 2. **代理模式(Proxy Pattern)**
- 3. **工厂模式(Factory Pattern)**
- 4. **适配器模式(Adapter Pattern)**
- 5. **模板方法模式(Template Method Pattern)**
- 6. **建造者模式(Builder Pattern)**
- 7. **责任链模式(Chain of Responsibility Pattern)**
- 总结
说说 MyBatis 执行流程?
MyBatis 是一个优秀的持久层框架,支持自定义 SQL、存储过程和高级映射。它的执行流程大致如下:
1. 加载配置文件和映射文件
- 加载核心配置文件(
mybatis-config.xml):
MyBatis 会读取核心配置文件以初始化环境信息,比如数据库连接池、事务管理、映射器等。 - 加载映射文件(Mapper XML 文件):
MyBatis 读取每个映射文件中的 SQL 语句定义,并将其映射到相应的 Java 接口或类的方法上。
2. 构建 SqlSessionFactory
- 创建 SqlSessionFactory:
通过SqlSessionFactoryBuilder构建SqlSessionFactory对象。SqlSessionFactory是 MyBatis 的核心对象之一,它负责创建SqlSession对象。
3. 创建 SqlSession
- 获取 SqlSession:
SqlSessionFactory创建SqlSession对象。SqlSession是 MyBatis 与数据库交互的关键对象,用来执行 SQL 查询、插入、更新和删除操作。
4. 调用 Mapper 方法
-
获取 Mapper 接口的代理对象:
MyBatis 会为每个 Mapper 接口生成代理对象,当你调用接口方法时,实际上是调用代理对象的方法。 -
执行 SQL 操作:
代理对象根据 Mapper 文件中的 SQL 映射信息,动态构建 SQL 语句,发送到数据库执行。
5. 处理参数和结果映射
-
参数处理:
MyBatis 将传入的参数进行处理,根据 Mapper 中的配置(如#{}和${}占位符)将参数嵌入到 SQL 语句中。 -
执行 SQL 并获取结果:
MyBatis 通过 JDBC 执行构建的 SQL 语句,并将返回的结果集转换为 Java 对象。 -
结果映射:
如果结果需要映射到自定义对象(例如 POJO),MyBatis 会根据配置将数据库字段映射到 Java 对象的属性。
6. 事务管理
- 事务控制:
SqlSession提供了事务控制的方法,如commit()和rollback()。如果操作成功,需要手动提交事务(或者使用自动提交),否则可以回滚。
7. 释放资源
- 关闭 SqlSession:
当操作完成后,需要关闭SqlSession以释放数据库连接等资源。这可以通过手动关闭或者使用 try-with-resources 来自动关闭。
简化流程图:
- 加载配置 ->
- 构建 SqlSessionFactory ->
- 创建 SqlSession ->
- 获取 Mapper 代理 ->
- 调用 Mapper 方法 ->
- 执行 SQL 并映射结果 ->
- 事务管理 ->
- 关闭 SqlSession
这个执行流程展现了 MyBatis 如何在配置、动态 SQL 映射和事务管理之间无缝衔接,以简化与数据库的交互。
MyBatis 和 Hibernate 有什么不同?
MyBatis 和 Hibernate 都是 Java 的 ORM(对象关系映射)框架,尽管它们都处理数据库交互,但其实现方式和适用场景有很大差异。
1. 对象关系映射层次
-
MyBatis:
MyBatis 是 半自动化的 ORM 框架,它的核心在于 SQL 语句的控制。开发者需要手动编写 SQL 语句,MyBatis 提供了丰富的映射配置,用于将 SQL 查询结果映射到 Java 对象上。因此,它提供了对 SQL 更大的控制和灵活性,但需要开发者自己编写 SQL。 -
Hibernate:
Hibernate 是 全自动化的 ORM 框架,基于 POJO(Plain Old Java Objects)和映射元数据,它自动生成 SQL 并处理对象与数据库表之间的映射。开发者通常不需要手动编写 SQL,Hibernate 会根据实体类和数据库之间的映射关系来生成并执行 SQL 语句。
2. SQL 控制
-
MyBatis:
MyBatis 允许开发者完全控制 SQL 语句,这意味着你可以编写自定义的、优化的 SQL 语句,包括复杂的查询、插入、更新和删除操作。对于需要高度优化的 SQL 场景,MyBatis 更合适。 -
Hibernate:
Hibernate 尽可能屏蔽了底层的 SQL 细节,它基于 HQL(Hibernate Query Language)或 Criteria API 进行查询,并自动将 HQL 翻译成 SQL。如果开发者希望直接编写 SQL,Hibernate 也支持原生 SQL 查询,但通常不推荐频繁使用。
3. 开发复杂度
-
MyBatis:
MyBatis 对 SQL 的控制力高,但这意味着开发者需要对 SQL 和数据库有深入的了解,尤其是需要手动维护 SQL 语句和结果映射,这可能在项目规模增大时带来额外的复杂性。 -
Hibernate:
Hibernate 通过自动化映射和对象持久化减少了手动编写 SQL 的需求,对于数据模型简单或业务逻辑与数据关系明确的项目,开发难度较低。然而,由于 Hibernate 隐藏了 SQL 细节,复杂的查询可能不容易优化。
4. 性能
-
MyBatis:
因为 SQL 是手动编写的,MyBatis 提供了对 SQL 语句的完全控制,因此可以编写高效的 SQL 并优化性能。然而,性能优化的责任完全在开发者身上。 -
Hibernate:
Hibernate 有自己的缓存机制(一级缓存、二级缓存)和自动化的批量操作优化。Hibernate 的自动生成 SQL 在一些简单场景下可以提高开发效率和性能,但对于复杂查询,生成的 SQL 可能不够高效,导致性能问题。
5. 缓存机制
-
MyBatis:
MyBatis 支持一级和二级缓存。一级缓存是基于SqlSession的本地缓存,而二级缓存是跨SqlSession的全局缓存。但缓存机制不像 Hibernate 那么自动化和丰富,更多依赖开发者的手动配置。 -
Hibernate:
Hibernate 具有更强大的缓存机制,默认开启一级缓存,并且可以很方便地使用二级缓存插件(如 EHCache、Infinispan)。它自动化的缓存管理能显著提升性能,特别是在读取频繁的场景中。
6. 数据库无关性
-
MyBatis:
MyBatis 并没有内置的数据库无关性支持,开发者需要为不同数据库编写不同的 SQL 语句,因此在跨数据库操作时需要更多的工作。 -
Hibernate:
Hibernate 通过自动生成 SQL 实现了较好的数据库无关性,开发者不需要为不同数据库编写不同的 SQL,它会根据底层数据库方言自动生成合适的 SQL 语句。
7. 适用场景
-
MyBatis:
适用于对 SQL 控制要求高、需要复杂查询或多表联合查询、或已有复杂的数据库设计的项目。MyBatis 的灵活性非常适合对 SQL 优化要求高的场景。 -
Hibernate:
适用于简单的数据模型或 CRUD 操作比较多的应用场景。对于需要较多的数据库自动化管理和面向对象设计的项目,Hibernate 是一个不错的选择。Hibernate 的自动化机制可以帮助开发者快速开发原型和减少代码量。
8. 学习曲线
-
MyBatis:
对开发者的 SQL 和数据库知识要求较高。由于它不完全是 ORM 解决方案,开发者必须在 SQL 和 Java 对象映射中找到平衡。 -
Hibernate:
虽然 Hibernate 提供了许多自动化功能,简化了数据库操作,但它的学习曲线较陡,尤其是在复杂场景下(如优化、缓存管理、批量操作等)。开发者需要理解其底层原理和行为,以避免潜在的问题。
总结
- MyBatis: 灵活、可控性强,适合对 SQL 有较高要求和复杂查询的项目。
- Hibernate: 自动化程度高、面向对象映射良好,适合 CRUD 操作较多且开发者希望避免直接与 SQL 打交道的场景。
两者各有优缺点,选择使用哪一个框架需要根据项目需求、团队技能和对 SQL 控制的需求来权衡。
${} 和 #{} 有什么区别?
${} 和 #{} 是 MyBatis 中用来在 SQL 语句中引用参数的两种方式,它们的区别主要体现在 SQL 解析、参数处理、安全性和性能等方面。
1. ${}(字符串拼接)
- 作用: 直接将参数的值拼接到 SQL 语句中,类似于字符串替换。
- 解析方式:
${}在 MyBatis 执行 SQL 时,参数不会被预处理,它会将传入的参数直接嵌入到生成的 SQL 语句中。 - 使用场景: 适用于动态生成 SQL 语句的场景,例如动态表名、列名或某些 SQL 关键字。
SELECT * FROM ${tableName};
在这里,tableName 的值将直接替换 ${tableName}。如果 tableName = "users",最终生成的 SQL 将是:
SELECT * FROM users;
- 优点: 灵活,适用于动态 SQL 生成。
- 缺点: 存在 SQL 注入风险,参数不会被 MyBatis 进行预处理和转义。
2. #{}(预编译处理)
- 作用: 将参数作为预编译 SQL 语句的占位符(类似于 JDBC 的
?),MyBatis 会将#{}中的参数值传递给 JDBC 处理,并将其安全地设置为 SQL 语句的参数。 - 解析方式:
#{}在 MyBatis 中会被解析为?,并使用PreparedStatement将参数值绑定到这个占位符。参数会被自动转义,以防止 SQL 注入攻击。 - 使用场景: 适用于传递普通的 SQL 参数,如查询条件、插入值等。
SELECT * FROM users WHERE id = #{userId};
在这里,#{userId} 会被解析为 ?,MyBatis 会将 userId 的值绑定到这个占位符上。如果 userId = 1,最终生成的 SQL 是:
SELECT * FROM users WHERE id = ?;
然后 MyBatis 会通过 PreparedStatement 绑定参数,将 1 传递给 SQL。
- 优点: 安全性高,防止 SQL 注入。MyBatis 会自动处理数据类型和转义。
- 缺点: 不适用于动态生成 SQL 语句的场景(如动态表名、列名等)。
3. 对比总结
| 特性 | ${} | #{} |
|---|---|---|
| 工作原理 | 直接将参数值拼接到 SQL 中 | 使用占位符 ? 预编译处理 |
| 适用场景 | 动态 SQL(如表名、列名等) | 普通 SQL 参数传递 |
| 安全性 | 存在 SQL 注入风险 | 防止 SQL 注入 |
| 性能 | 每次执行都重新编译 SQL | 预编译后重复执行,效率高 |
| 转义处理 | 无自动转义 | 自动转义(避免特殊字符问题) |
什么时候用哪个?
- 使用
#{}主要是为了传递普通参数,特别是对于用户输入的数据,这样可以避免 SQL 注入问题。 - 使用
${}主要用于拼接 SQL 动态部分,比如表名、列名等,不能用于传递用户输入的数据,因为这种方式不会进行转义和预处理。
示例
假设你有一段 SQL 查询代码:
SELECT * FROM ${tableName} WHERE name = #{name};
- 如果
tableName = "users"且name = "John",生成的 SQL 会是:
SELECT * FROM users WHERE name = ?;
然后 MyBatis 会安全地将 name 的值 "John" 绑定到 ? 处。
在这种组合场景下,${} 用于动态表名,而 #{} 用于安全的参数传递。
什么是 SQL 注入?
SQL 注入(SQL Injection)是一种网络攻击技术,攻击者通过在输入字段中插入恶意的 SQL 代码,使应用程序生成恶意的 SQL 查询,从而操纵数据库的执行行为。SQL 注入可以导致严重的安全问题,包括数据泄露、数据篡改、删除数据甚至获取系统控制权。
SQL 注入示例
假设有一个登录功能,接受用户名和密码并在数据库中验证用户凭证。SQL 查询可能是这样写的:
SELECT * FROM users WHERE username = 'admin' AND password = 'password123';
如果这个查询中的 username 和 password 直接来自用户的输入,并且没有适当的处理,那么攻击者可以输入恶意的 SQL 代码。
假设攻击者在用户名字段输入 ' OR '1' = '1,而在密码字段随意输入数据,那么生成的 SQL 查询可能会变成:
SELECT * FROM users WHERE username = '' OR '1' = '1' AND password = 'whatever';
这段 SQL 会返回所有用户的数据,因为 '1' = '1' 始终为真,导致 SQL 查询条件总是成立。攻击者因此可以绕过登录验证,并以系统管理员或其他用户的身份登录。
SQL 注入的常见类型
-
基于错误的注入(Error-Based Injection):
攻击者通过故意输入错误的数据来获取数据库错误信息,进而推断数据库结构和内容。 -
联合查询注入(Union-Based Injection):
攻击者利用UNION语句,将恶意查询与原查询合并,获取数据库的额外信息。 -
盲注入(Blind SQL Injection):
当数据库不会返回错误信息时,攻击者通过逐步测试布尔条件或时间延迟来推测数据库信息。 -
基于时间的注入(Time-Based Injection):
通过让数据库查询执行时间延迟的方式,推断数据库是否执行了某条 SQL 语句,进而获取数据。
SQL 注入的危害
- 数据泄露: 攻击者可以读取敏感数据,例如用户信息、财务数据等。
- 数据篡改: 攻击者可以修改数据库中的信息,如更改密码、篡改记录。
- 删除数据: 攻击者可以执行
DELETE操作,删除数据库中的数据。 - 执行系统命令: 在某些情况下,攻击者可以通过 SQL 注入执行数据库系统命令,甚至接管整个服务器。
防止 SQL 注入的最佳实践
-
使用预编译语句和参数化查询:
避免直接拼接 SQL 字符串,使用像PreparedStatement或其他框架(如 MyBatis 中的#{})来处理参数。这可以有效防止 SQL 注入。String sql = "SELECT * FROM users WHERE username = ? AND password = ?"; PreparedStatement stmt = connection.prepareStatement(sql); stmt.setString(1, username); stmt.setString(2, password); ResultSet rs = stmt.executeQuery(); -
使用 ORM 框架:
使用 Hibernate、MyBatis 等 ORM 框架,它们通常会自动处理参数化查询,减少 SQL 注入的风险。
如何解决实体类属性和表中字段不一致的问题?
在开发中,数据库表的字段名和实体类的属性名不一致是常见的问题。为了解决这种不一致性,常见的 ORM 框架(如 MyBatis、Hibernate 等)提供了多种机制来将数据库字段与实体类的属性进行映射。
解决方案
1. 使用注解映射
如果使用的是基于注解的 ORM 框架,可以通过注解明确地指定实体类属性与数据库表字段之间的映射。
-
在 MyBatis 中:
可以使用@Results和@Result注解来指定属性和数据库字段的映射关系。@Select("SELECT id, user_name FROM users WHERE id = #{id}") @Results({@Result(property = "id", column = "id"),@Result(property = "username", column = "user_name") }) User selectUserById(int id);在这个例子中,
username是实体类的属性,而user_name是数据库中的字段名,通过@Result注解将它们对应起来。 -
在 Hibernate 中:
使用@Column注解来指定实体类属性和数据库字段之间的映射。@Entity public class User {@Idprivate Long id;@Column(name = "user_name")private String username;// getter, setter }@Column(name = "user_name")表示实体类的username属性与数据库表中的user_name字段对应。
2. 使用 XML 配置映射(适用于 MyBatis)
MyBatis 还支持使用 XML 来配置实体类属性与数据库字段的映射。
<resultMap id="userMap" type="com.example.User"><result property="id" column="id"/><result property="username" column="user_name"/>
</resultMap><select id="selectUserById" resultMap="userMap">SELECT id, user_name FROM users WHERE id = #{id}
</select>
这里的 resultMap 定义了实体类属性与数据库字段之间的映射,property 是实体类的属性,column 是数据库表的字段。
MyBatis 中如何实现分页?
在 MyBatis 中实现分页可以有多种方式,常见的方法包括手动编写分页 SQL、使用分页插件等。下面介绍几种实现分页的常见方式。
1. 手动编写分页 SQL
分页的原理是通过 SQL 的 LIMIT 和 OFFSET 子句来实现的,这些子句通常用于 MySQL、PostgreSQL 等数据库。你可以手动编写分页 SQL,将分页参数(如页码和每页大小)传递到 SQL 语句中。
<select id="selectUsers" resultType="com.example.User">SELECT * FROM usersLIMIT #{limit} OFFSET #{offset}
</select>
在 Mapper 中可以定义如下方法:
List<User> selectUsers(@Param("limit") int limit, @Param("offset") int offset);
在实际调用时,可以根据当前页数和每页条目数计算出 limit 和 offset:
int page = 1; // 当前页码
int pageSize = 10; // 每页大小
int limit = pageSize;
int offset = (page - 1) * pageSize;List<User> users = userMapper.selectUsers(limit, offset);
2. 使用 MyBatis-Plus 的分页插件
MyBatis-Plus 是 MyBatis 的增强工具,提供了丰富的功能,分页就是其中之一。MyBatis-Plus 提供了分页插件 PageHelper,可以自动生成分页 SQL,开发者只需要传递分页参数即可。
1) 引入 MyBatis-Plus 依赖
在 pom.xml 中添加 MyBatis-Plus 依赖:
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version> <!-- 版本号可以根据需要调整 -->
</dependency>
2) 配置分页插件
在 Spring Boot 项目中,通常通过配置类来启用分页插件:
@Configuration
public class MybatisPlusConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); // 指定数据库类型return interceptor;}
}
3) 使用分页查询
使用 MyBatis-Plus 提供的 Page 对象来进行分页查询:
public IPage<User> selectUserPage(Page<User> page) {return userMapper.selectPage(page, null);
}
调用分页查询时:
Page<User> page = new Page<>(1, 10); // 第 1 页,每页 10 条
IPage<User> userPage = userService.selectUserPage(page);
List<User> users = userPage.getRecords();
long total = userPage.getTotal(); // 总条数
MyBatis-Plus 自动会根据分页参数生成 LIMIT 和 OFFSET 的 SQL 语句。
3. 使用 PageHelper 插件
PageHelper 是 MyBatis 的一个常用分页插件,提供了分页功能的自动处理。
1) 引入 PageHelper 依赖
在 pom.xml 中添加 PageHelper 依赖:
<dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId><version>1.4.6</version>
</dependency>
2) 配置 PageHelper
PageHelper 的配置可以通过 application.yml 来完成:
pagehelper:helper-dialect: mysqlreasonable: truesupport-methods-arguments: true
3) 使用 PageHelper 进行分页
在 Mapper 方法中调用分页逻辑:
PageHelper.startPage(1, 10); // 第 1 页,每页 10 条
List<User> users = userMapper.selectUsers();
PageInfo<User> pageInfo = new PageInfo<>(users); // 封装分页信息
PageHelper.startPage(pageNum, pageSize) 会拦截并修改 SQL,自动添加分页参数。PageInfo 对象可以获取分页的详细信息,如总条数、总页数等。
HashMap 和 Hashtable 可以作为查询结果吗?
在 MyBatis 或其他类似的 ORM 框架中,HashMap 和 Hashtable 可以用作查询结果的返回类型,但它们在使用中有一些区别和限制,取决于具体的使用场景和框架支持情况。
HashMap 和 Hashtable 作为查询结果
1. HashMap
HashMap 是常用的集合类,它允许存储键值对,并且线程不安全。HashMap 作为查询结果返回时,通常用于结果集中包含动态或非结构化数据(比如表的字段名作为键,字段值作为值)。
常见场景:
- 当查询结果的字段与实体类无法直接对应时,可以使用
HashMap来存储结果。 - 查询结果中字段是动态的,无法确定字段名时,使用
HashMap是一个可行的解决方案。
示例:
<select id="selectUserAsMap" resultType="hashmap">SELECT id, username, email FROM users WHERE id = #{id}
</select>
在 Mapper 接口中,返回类型可以是 HashMap:
Map<String, Object> selectUserAsMap(int id);
查询后,结果会以键值对的形式存储在 HashMap 中,键是数据库字段名,值是对应的字段值。
2. Hashtable
Hashtable 和 HashMap 类似,也是一个存储键值对的集合类,不过 Hashtable 是线程安全的。尽管如此,Hashtable 在现代 Java 开发中较少使用,因为 HashMap 提供了更好的性能,且一般不需要对每个操作进行同步。
在 MyBatis 中,理论上你也可以将查询结果存储在 Hashtable 中,但是这种用法比较少见,且不推荐。Hashtable 的线程安全性和旧式设计使得它不如 HashMap 高效,而且大部分场景下并不需要如此严格的线程安全保障。
示例:
<select id="selectUserAsHashtable" resultType="hashtable">SELECT id, username, email FROM users WHERE id = #{id}
</select>
在 Mapper 接口中,返回类型可以是 Hashtable:
Hashtable<String, Object> selectUserAsHashtable(int id);
3. 推荐使用 HashMap 而非 Hashtable
大多数情况下,建议使用 HashMap 而不是 Hashtable。HashMap 在查询操作中更为高效,并且在 MyBatis 或其他框架中使用更为广泛和灵活。只有在极特殊的情况下,才会考虑使用 Hashtable 作为查询结果类型。
何时使用 HashMap 而不是实体类
- 动态查询结果:如果查询的字段无法确定,或者查询的列不固定(如动态 SQL),使用
HashMap可以很好地处理这些情况。 - 简化数据处理:如果数据处理逻辑很简单,且不需要进行复杂的对象映射操作,使用
HashMap可以避免定义实体类。
总结
HashMap:在 MyBatis 中广泛使用,可以用来存储动态的、非结构化的查询结果。它适合大多数场景,尤其是字段名和字段数动态变化的情况下。Hashtable:尽管可以作为查询结果类型,但现代开发中很少使用,HashMap更具效率优势。除非有特别的线程安全需求,一般不推荐使用Hashtable。
说一说动态SQL
动态 SQL 的作用
动态 SQL 的主要目的是根据业务逻辑条件动态拼接 SQL 语句,避免在代码中手动拼接 SQL,提高代码的可读性、可维护性,并减少 SQL 重复。动态 SQL 常用于以下场景:
- 根据不同条件生成不同的查询。
- 动态添加
WHERE条件、ORDER BY排序、GROUP BY聚合等。 - 动态更新、插入或删除操作。
动态 SQL 标签
MyBatis 提供了一些常见的动态 SQL 标签,以下是这些标签的使用方式和示例。
1. <if> 标签
<if> 标签用于根据条件动态生成 SQL 片段。
示例:
<select id="findUsers" parameterType="map" resultType="User">SELECT * FROM users<where><if test="username != null">AND username = #{username}</if><if test="email != null">AND email = #{email}</if></where>
</select>
这个查询会根据传入的 username 或 email 动态生成带有不同 WHERE 条件的 SQL 语句。
2. <choose>、<when> 和 <otherwise> 标签
这些标签可以模拟 switch-case 逻辑,根据多个条件选择执行哪个 SQL 片段。
示例:
<select id="findUsers" parameterType="map" resultType="User">SELECT * FROM users<where><choose><when test="username != null">AND username = #{username}</when><when test="email != null">AND email = #{email}</when><otherwise>AND status = 'active'</otherwise></choose></where>
</select>
在这个例子中,如果 username 不为空,则使用 username 条件;否则,如果 email 不为空,则使用 email 条件;如果都不满足,则使用默认的 status 条件。
3. <where> 标签
<where> 标签可以自动处理 SQL 语句中的 WHERE 和 AND 等条件拼接问题。它会智能地处理条件,确保 SQL 语句的正确性。
示例:
<select id="findUsers" parameterType="map" resultType="User">SELECT * FROM users<where><if test="username != null">username = #{username}</if><if test="email != null">AND email = #{email}</if></where>
</select>
<where> 会自动处理 WHERE 和 AND,如果条件存在,它会自动添加 WHERE 关键字;如果有多个条件,它会自动在这些条件之间添加 AND。
4. <trim> 标签
<trim> 标签允许手动控制 SQL 的前后缀内容,比如去掉多余的 AND、OR 等,或者添加特定的前后缀。
示例:
<select id="findUsers" parameterType="map" resultType="User">SELECT * FROM users<trim prefix="WHERE" prefixOverrides="AND | OR"><if test="username != null">AND username = #{username}</if><if test="email != null">AND email = #{email}</if></trim>
</select>
在这个例子中,<trim> 标签会自动去掉前面多余的 AND 或 OR,并确保 SQL 语句的前缀为 WHERE。
5. <set> 标签
<set> 标签专门用于 UPDATE 语句中,它会自动处理逗号分隔的问题,确保 SQL 语句的正确性。
示例:
<update id="updateUser" parameterType="User">UPDATE users<set><if test="username != null">username = #{username},</if><if test="email != null">email = #{email},</if><if test="status != null">status = #{status}</if></set>WHERE id = #{id}
</update>
<set> 标签会自动处理逗号问题,确保生成的 SQL 语句在最后一个字段后不会出现多余的逗号。
6. <foreach> 标签
<foreach> 标签用于处理集合类型的参数,比如 List、Set 或数组,常用于批量插入或 IN 查询等场景。
示例:
<select id="findUsersByIds" parameterType="list" resultType="User">SELECT * FROM users WHERE id IN<foreach item="id" collection="list" open="(" separator="," close=")">#{id}</foreach>
</select>
<foreach> 标签会根据传入的集合自动生成 IN 子句。
7. <bind> 标签
<bind> 标签允许将表达式结果绑定到一个变量中,并在后续 SQL 语句中使用该变量。
示例:
<select id="findUsersLike" parameterType="string" resultType="User"><bind name="pattern" value="'%' + username + '%'"/>SELECT * FROM users WHERE username LIKE #{pattern}
</select>
<bind> 标签将 username 拼接为一个模糊查询的字符串,并绑定到 pattern 变量中。
动态 SQL 的优势
- 灵活性:能够根据不同的业务逻辑条件动态生成 SQL,避免大量重复代码。
- 可维护性:将复杂 SQL 的拼接逻辑交由 MyBatis 动态处理,开发者无需手动拼接 SQL 字符串,减少了拼写错误的可能性。
- 效率:可以避免不必要的查询条件,从而提升查询效率。
说一下 MyBatis 的缓存机制?
MyBatis 的缓存机制用于提高数据库操作的效率,通过缓存查询结果来减少对数据库的访问。MyBatis 提供了一级缓存和二级缓存两种缓存机制,分别适用于不同的场景和需求。
1. 一级缓存(Local Cache)
基本概念:
- 一级缓存是
SqlSession级别的缓存,也称为本地缓存。它用于缓存当前SqlSession会话中的查询结果。 - 一级缓存的生命周期与
SqlSession一致,即在同一SqlSession中的查询会使用一级缓存。
特点:
- 默认启用:一级缓存是 MyBatis 默认启用的,不需要额外配置。
- 作用范围:缓存的作用范围限定在单个
SqlSession会话内。不同SqlSession会话之间的缓存是不共享的。 - 缓存刷新:在
SqlSession会话中,如果执行了insert、update或delete操作,这些操作会导致缓存被刷新,保证缓存中的数据与数据库一致。
示例:
try (SqlSession session = sqlSessionFactory.openSession()) {User user1 = session.selectOne("com.example.UserMapper.selectUser", 1);User user2 = session.selectOne("com.example.UserMapper.selectUser", 1);// user1 和 user2 会从一级缓存中读取相同的数据
}
2. 二级缓存(Global Cache)
基本概念:
- 二级缓存是
SqlSessionFactory级别的缓存,也称为全局缓存。它在多个SqlSession之间共享。 - 二级缓存的作用范围是跨
SqlSession的,所有使用同一个SqlSessionFactory的SqlSession都可以访问二级缓存。
特点:
- 需要配置:二级缓存默认是关闭的,需要在配置文件中显式启用。
- 缓存实现:MyBatis 支持多种缓存实现,包括内存缓存(如 EHCache、Redis)和自定义缓存。
- 缓存刷新:在对数据进行修改后(例如
insert、update、delete),缓存会被刷新,以确保数据一致性。
配置示例:
-
启用二级缓存
在映射文件中配置<cache>标签以启用二级缓存。<mapper namespace="com.example.UserMapper"><cache/><!-- 其他映射配置 --> </mapper> -
配置二级缓存
可以在mybatis-config.xml文件中配置二级缓存的全局设置。<configuration><settings><setting name="cacheEnabled" value="true"/></settings> </configuration>自定义缓存实现:
<configuration><cache type="com.example.MyCustomCache"/> </configuration>
缓存实现
-
内存缓存
- EHCache:MyBatis 可以集成 EHCache 作为二级缓存的实现,提供强大的缓存管理功能。
- Redis:可以使用 Redis 作为二级缓存,实现分布式缓存。
-
自定义缓存
- 可以通过实现
org.apache.ibatis.cache.Cache接口,创建自定义的缓存实现。
示例:
public class MyCustomCache implements Cache {// 实现缓存接口的方法 } - 可以通过实现
缓存策略
-
缓存失效
- 在进行
insert、update、delete操作时,相关的缓存会被刷新,确保缓存中的数据与数据库一致。 - 可以通过配置映射文件中的
flushCache属性来控制缓存的刷新策略。
- 在进行
-
缓存配置
- 可以在映射文件中配置缓存的大小、过期时间等属性,以优化缓存性能。
示例:
<cache eviction="LRU" flushInterval="60000" size="512" readOnly="true"/>eviction:缓存淘汰策略(如 LRU、FIFO)。flushInterval:缓存刷新间隔(毫秒)。size:缓存的最大大小。readOnly:缓存是否为只读。
缓存的注意事项
-
N+1 查询问题
- 延迟加载可能导致 N+1 查询问题,即在加载集合时会执行 N 次查询。可以通过优化 SQL 语句和使用批量加载来减少查询次数。
-
缓存一致性
- 二级缓存可能会存在缓存一致性问题,尤其在分布式环境下。需要确保缓存的更新和失效机制正确,以避免脏读问题。
-
性能影响
- 不合理的缓存配置或过度缓存可能会导致性能下降。需要根据实际需求合理配置缓存策略和大小。
总结
MyBatis 的缓存机制通过一级缓存和二级缓存提高了数据库操作的效率。一级缓存是 SqlSession 级别的缓存,用于缓存单个会话中的查询结果。二级缓存是 SqlSessionFactory 级别的缓存,用于跨会话共享缓存。二级缓存需要显式配置,支持多种缓存实现和自定义缓存策略。合理使用缓存可以显著提高性能,但需要注意缓存一致性和性能影响。
MyBatis 中有哪些设计模式?
MyBatis 中使用了多种设计模式来实现其功能和优化性能。以下是一些关键的设计模式在 MyBatis 中的应用:
1. 单例模式(Singleton Pattern)
应用场景:
SqlSessionFactory是 MyBatis 中的核心工厂,用于创建SqlSession对象。通常一个应用只需要一个SqlSessionFactory实例,以避免重复创建和配置。
实现方式:
SqlSessionFactory的实例通常是通过单例模式来管理的。SqlSessionFactoryBuilder类负责创建SqlSessionFactory实例,确保应用中只有一个SqlSessionFactory实例。
示例:
public class MyBatisUtil {private static SqlSessionFactory sqlSessionFactory;static {try {InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);} catch (IOException e) {throw new RuntimeException(e.getMessage(), e);}}public static SqlSessionFactory getSqlSessionFactory() {return sqlSessionFactory;}
}
2. 代理模式(Proxy Pattern)
应用场景:
- MyBatis 使用代理模式来实现 Mapper 接口的动态代理。Mapper 接口的方法在运行时被动态代理生成,实现了对 SQL 语句的调用和映射。
实现方式:
- MyBatis 通过 JDK 动态代理或 CGLIB 库生成 Mapper 接口的代理对象。这些代理对象会在调用方法时执行对应的 SQL 语句。
示例:
public interface UserMapper {User selectUser(int id);
}
UserMapper接口的代理对象会执行selectUser方法并发起 SQL 查询。
3. 工厂模式(Factory Pattern)
应用场景:
- 工厂模式用于创建
SqlSession和SqlSessionFactory实例。它使得对象创建与使用分离,提高了代码的灵活性和可维护性。
实现方式:
SqlSessionFactoryBuilder和SqlSessionFactory是工厂模式的具体实现。SqlSessionFactoryBuilder负责创建SqlSessionFactory实例,而SqlSessionFactory负责创建SqlSession实例。
示例:
public class SqlSessionFactoryBuilder {public SqlSessionFactory build(InputStream inputStream) {// 创建 SqlSessionFactory 实例的逻辑}
}
4. 适配器模式(Adapter Pattern)
应用场景:
- 适配器模式用于将 MyBatis 的功能与不同的数据源或缓存系统进行适配。例如,将 MyBatis 与 EHCache 或 Redis 进行集成。
实现方式:
- MyBatis 提供了接口和适配器,允许开发者将第三方库或自定义实现集成到 MyBatis 中,从而实现对不同缓存系统或数据源的支持。
示例:
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
5. 模板方法模式(Template Method Pattern)
应用场景:
- 模板方法模式用于定义一个操作的算法骨架,将一些步骤延迟到子类中实现。在 MyBatis 中,这种模式用于封装数据库操作的常见步骤。
实现方式:
SqlSession类提供了数据库操作的模板方法,例如selectOne、selectList、insert、update和delete。这些方法封装了常见的数据库操作步骤,用户只需关注具体的 SQL 语句和参数。
示例:
public interface SqlSession {<T> T selectOne(String statement, Object parameter);<E> List<E> selectList(String statement, Object parameter);int insert(String statement, Object parameter);int update(String statement, Object parameter);int delete(String statement, Object parameter);
}
6. 建造者模式(Builder Pattern)
应用场景:
- 建造者模式用于构建复杂的对象,在 MyBatis 中主要用于构建
SqlSessionFactory实例。
实现方式:
SqlSessionFactoryBuilder类实现了建造者模式,允许通过链式调用配置不同的设置选项,然后构建SqlSessionFactory实例。
示例:
public class SqlSessionFactoryBuilder {public SqlSessionFactory build(InputStream inputStream) {// 配置和创建 SqlSessionFactory 实例}
}
7. 责任链模式(Chain of Responsibility Pattern)
应用场景:
- 责任链模式用于处理请求的传递和处理,MyBatis 中的拦截器机制就是这种模式的应用。
实现方式:
- MyBatis 的拦截器可以在 SQL 执行的各个阶段插入自定义逻辑,例如请求拦截、结果处理等。多个拦截器可以按顺序链式处理请求。
示例:
public class ExampleInterceptor implements Interceptor {@Overridepublic Object intercept(Invocation invocation) throws Throwable {// 处理请求的逻辑}
}
总结
MyBatis 采用了多种设计模式来实现其功能和优化性能,包括单例模式、代理模式、工厂模式、适配器模式、模板方法模式、建造者模式和责任链模式。这些设计模式帮助 MyBatis 实现了对象管理、SQL 映射、缓存管理、数据库操作封装等功能,提高了系统的灵活性、可维护性和性能。
相关文章:

MyBatis常见面试题
文章目录 说说 MyBatis 执行流程?1. 加载配置文件和映射文件2. 构建 SqlSessionFactory3. 创建 SqlSession4. 调用 Mapper 方法5. 处理参数和结果映射6. 事务管理7. 释放资源简化流程图: MyBatis 和 Hibernate 有什么不同?1. **对象关系映射层…...

Swift 运算符
Swift 运算符 Swift 是一种强类型编程语言,由苹果公司开发,用于iOS、macOS、watchOS和tvOS应用程序的开发。Swift 运算符是其核心特性之一,它允许开发者执行各种数学和逻辑操作。本文将详细介绍 Swift 中的运算符,包括它们的功能、用法和类型。 Swift 运算符概述 Swift …...

PDF转PPT神器揭秘!3步操作,轻松打造2024年会议爆款PPT
现在是数字化的时代,PDF 和 PPT 对职场的人来说可重要了。PDF 文件格式稳,也好分享,所以大家都爱用。PPT 演示起来很厉害,在开会、讲座的时候特别管用。不过呢,要是有好多 PDF 文件,咋能快点把它们变成好看…...

✨机器学习笔记(一)—— 监督学习和无监督学习
1️⃣ 监督学习(supervised learning) ✨ 两种主要类型的监督学习问题: 回归(regression):predict a number in infinitely many possible outputs. 分类(classification)࿱…...

【Netty】实战:基于Http的Web服务器
目录 一、实现ChannelHandler 二、实现ChannelInitializer 三、实现服务器启动程序 四、测试 本文来实现一个简单的Web服务器,当用户在浏览器访问Web服务器时,可以返回响应的内容给用户。很简单,就三步。 一、实现ChannelHandler pack…...
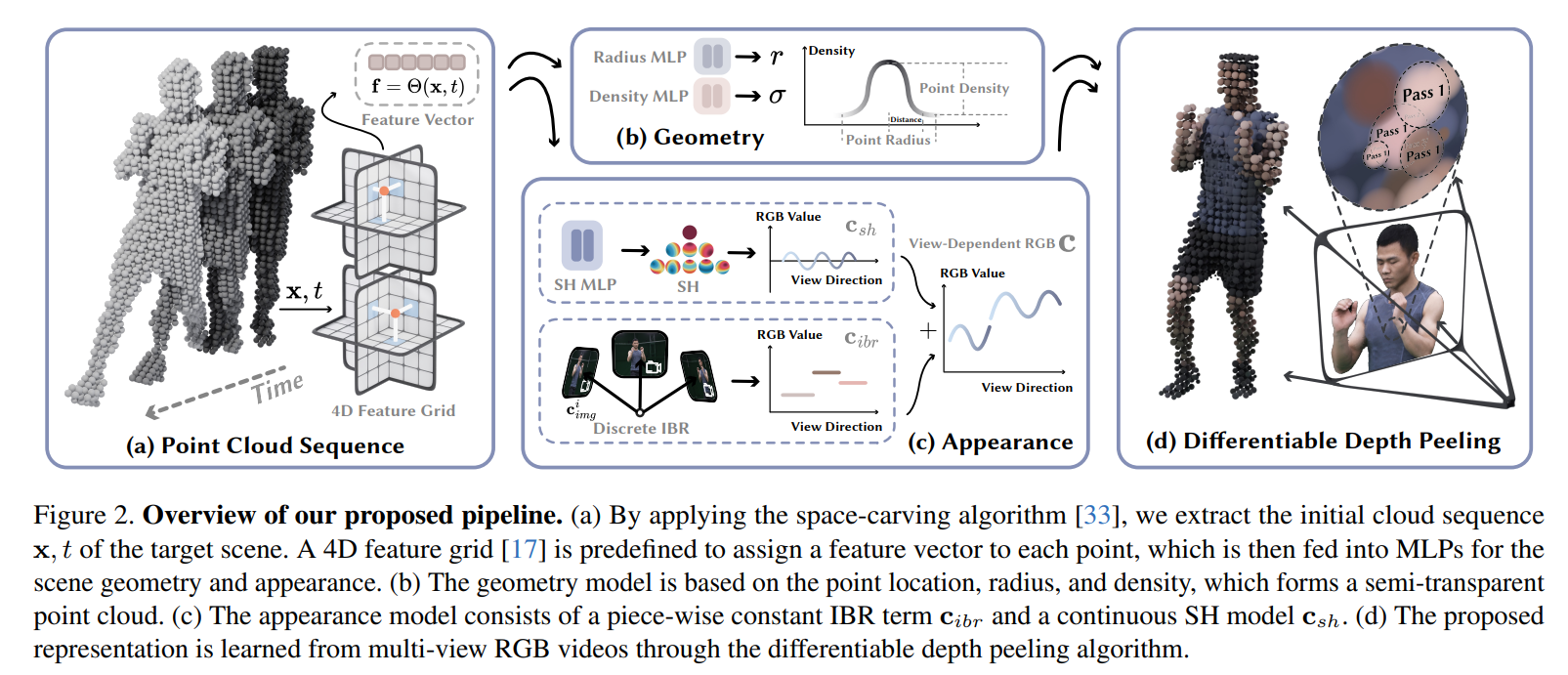
4K4D: Real-Time 4D View Synthesis at 4K Resolution 学习笔记
本文是学习4K4D的笔记记录 Project Page:https://zju3dv.github.io/4k4d/ 文章目录 1 Pipeline1.1 特征向量的计算1.2 几何建模1.3 外观建模⭐1) 球谐函数SH模型2) 图像融合技术 1.4 可微分深度剥离渲染 2 Train(loss)…...

2024年 Biomedical Signal Processing and Control 期刊投稿经验最新分享
期刊介绍 《Biomedical Signal Processing and Control 》期刊旨在为临床医学和生物科学中信号和图像的测量和分析研究提供一个跨学科的国际论坛。重点放在处理在临床诊断,患者监测和管理中使用的方法和设备的实际,应用为主导的研究的贡献。 生物医学信…...

【C++】关于类的public、protected 、private
public、protected、private是访问控制修饰符,决定了类成员的可访问性,特性如下: public: 可以被类内部和类外部直接访问 可以被派生类访问 protected: 可以被类内部访问 可以被派生类访问 不能被类的外部直接访问 p…...

使用 POST 方法与 JSON 格式进行 HTTP 请求的最佳实践
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱…...

学习笔记--Java基础核心知识
方法重载 请记住下面重载的条件 方法名称必须相同。参数列表必须不同(个数不同、或类型不同、参数类型排列顺序不同等)。方法的返回类型可以相同也可以不相同。仅仅返回类型不同不足以成为方法的重载。重载是发生在编译时的,因为编译器可以根…...

SAP学习笔记 - 开发01 - BAPI是什么?通过界面和ABAP代码来调用BAPI
BAPI作为SAP中的重要概念,在SAP系统的开发中几乎是必须的。 本章来学习一下BAPI 的直观印象,以及在ABAP代码中的调用。 目录 1, BAPI概述 1,从画面角度来直观体验一下BAPI 1-1,MM:購買依頼変更BAPI - …...

mysql笔记3(数据库、表和数据的基础操作)
文章目录 一、数据库的基础操作1. 显示所有的仓库(数据库)2. 创建数据库注意(命名规范): 3. 删除数据库4. 查看创建数据库的SQL5. 创建数据库时跟随字符编码6. 修改数据库的字符编码 二、表的基础操作1. 引入表的思维2. 引用数据库3. 查看该数据库下面的表4. 创建表…...

计算机毕业设计选题-基于python的企业人事管理系统【源码+文档+数据库】
💖🔥作者主页:毕设木哥 精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻 实战项目 文章目录 实战项目 一、基于python的企业人事管理系…...

科研绘图系列:R语言折线图(linechart plots)
文章目录 介绍加载R包导入数据数据预处理画图组合图形介绍 在R语言中,折线图(Line Plot)是一种常用的数据可视化类型,用于展示数据随时间或有序类别变化的趋势。折线图通过连接数据点来形成一条或多条线,这些线条可以清晰地表示数据的变化方向、速度和模式。 加载R包 k…...

Opencv中的直方图(5)计算EMD距离的函数EMD()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 计算两个加权点配置之间的“最小工作量”距离。 该函数计算地球搬运工距离(Earth Mover’s Distance)和/或两个加权点配…...

KDD 2024 时空数据(Spatio-temporal) ADS论文总结
2024 KDD( ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 知识发现和数据挖掘会议)在2024年8月25日-29日在西班牙巴塞罗那举行。 本文总结了KDD2024有关时空数据(Spatial-temporal) 的相关论文,如有疏漏,欢迎大…...

uniapp+vue3实现小程序和h5解压线上压缩包以及如何访问解压后的视频地址
安装jszip插件 npm install jszip 对应功能实现和逻辑处理: <script setup>import { onMounted, reactive, ref } from vueimport { onHide, onUnload } from dcloudio/uni-appimport JSZip from jsziplet videoSrc ref() // 视频地址// 创建JSZip实例con…...

探索 Zed 编辑器:速度与协作的巅峰之作
Zed 是一款备受瞩目的代码编辑器,专为现代开发者打造。本文将深入介绍 Zed 的独特优势,以及如何快速上手使用这款编辑器,助你在编程工作中大幅提升效率。 一:Zed 编辑器的优势 Zed 是近年来崭露头角的一款代码编辑器,迅速赢得了众多开发者的青睐。以下是 Zed 的几大核心优…...

文心快码前端工程师观点分享:人机协同新模式的探索之路(三)
本系列视频来自百度工程效能部的前端研发经理杨经纬,她在由开源中国主办的“AI编程革新研发效能”OSC源创会杭州站105期线下沙龙活动上,从一款文心快码(Baidu Comate)前端工程师的角度,分享了关于智能研发工具本身的研…...

Qt基础类03-直线类QLine
Qt基础类03-直线类QLine 摘要基本信息成员函数程序全貌QLine::QLine()QLine::QLine(const QPoint &p1, const QPoint &p2)QLine::QLine(int x1, int y1, int x2, int y2)QPoint QLine::p1() constQPoint QLine::p2() constint QLine::x1() constint QLine::x2() consti…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

如何在macOS上免费解锁QQ音乐加密文件:完整指南
如何在macOS上免费解锁QQ音乐加密文件:完整指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

Claude Code用户告别封号与Token焦虑,无缝切换至Taotoken平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code用户告别封号与Token焦虑,无缝切换至Taotoken平台 对于依赖Claude Code进行编程辅助的开发者而言ÿ…...