Spark-序列化、依赖关系、持久化
序列化
闭包检查
序列化方法和属性
依赖关系
RDD 血缘关系
RDD 窄依赖
RDD 宽依赖
RDD 任务划分
RDD 持久化
RDD Cache 缓存
RDD CheckPoint 检查点
缓存和检查点区别
序列化
闭包检查
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就 形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor 端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列 化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变
序列化方法和属性
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。
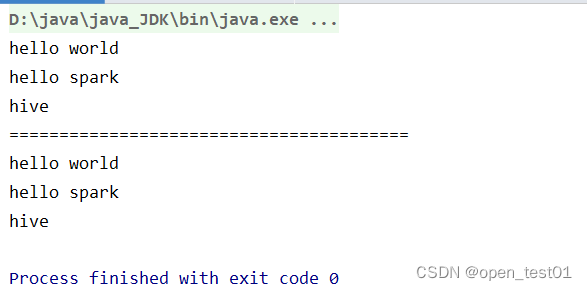
object spark_02 {def main(args: Array[String]): Unit = {//准备环境//"*"代表线程的核数 应用程序名称"RDD"val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")val sc = new SparkContext(sparkConf)val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))//创建查询对象val search = new Search("h")//函数传递,打印:ERROR Task not serializablesearch.getMatch1(rdd).collect().foreach(println)println("========================================")//属性传递,打印:ERROR Task not serializablesearch.getMatch2(rdd).collect().foreach(println)//关闭环境sc.stop()}
}//查询对象
//类的构造参数是类的属性,构造参数需要进行闭包检查(对类进行闭包检查)
class Search(query:String) extends Serializable {def isMatch(s: String): Boolean = {s.contains(query)}// 函数序列化案例def getMatch1 (rdd: RDD[String]): RDD[String] = {rdd.filter(isMatch)}// 属性序列化案例def getMatch2(rdd: RDD[String]): RDD[String] = {rdd.filter(x => x.contains(query))}
}
依赖关系
相邻的两个RDD关系称之为依赖关系
RDD 血缘关系
多个连续的RDD的依赖关系称之为血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage (血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转 换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的 数据分区。
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString) //打印输出血缘关系
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用, 窄依赖我们形象的比喻为独生子女。
RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会 引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
RDD 任务划分
RDD 任务切分中间分为:Application、Job、Stage 和 Task:
- Application:初始化一个 SparkContext 即生成一个 Application;
- Job:一个 Action 算子就会生成一个 Job;
- Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
- Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
RDD 持久化
RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存 在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算 子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
// cache 操作会增加血缘关系,不改变原有的血缘关系
println(wordToOneRdd.toDebugString)
// 数据缓存。
wordToOneRdd.cache()
// 可以更改存储级别
//mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机 制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数 据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可, 并不需要重算全部 Partition。 Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样 做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时 候,如果想重用数据,仍然建议调用 persist 或 cache。
RDD CheckPoint 检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘 由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点 之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。 对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
// 设置检查点路径
sc.setCheckpointDir("./checkpoint1")
// 创建一个 RDD,读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input/1.txt")
// 业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {word => {(word, System.currentTimeMillis())}
}
// 增加缓存,避免再重新跑一个 job 做 checkpoint
wordToOneRdd.cache()
// 数据检查点:针对 wordToOneRdd 做检查点计算
wordToOneRdd.checkpoint()
// 触发执行逻辑
wordToOneRdd.collect().foreach(println)
缓存和检查点区别
- Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
- Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存 储在 HDFS 等容错、高可用的文件系统,可靠性高。
- 建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存 中读取数据即可,否则需要再从头计算一次 RDD。
相关文章:
Spark-序列化、依赖关系、持久化
序列化 闭包检查 序列化方法和属性 依赖关系 RDD 血缘关系 RDD 窄依赖 RDD 宽依赖 RDD 任务划分 RDD 持久化 RDD Cache 缓存 RDD CheckPoint 检查点 缓存和检查点区别 序列化 闭包检查 从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 E…...

蓝桥杯刷题冲刺 | 倒计时16天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录1.青蛙跳杯子1.青蛙跳杯子 题目 链接: 青蛙跳杯子 - 蓝桥云课 (lanqiao.cn) X 星球的…...

Java设计模式-12 、建造者模式
建造者模式 (将一个 复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。) 建造者模式是一种创建型的模式,有一些对象的创建过程new 是很繁杂的。 什么时候去使用建造者模式 由上文可以得出在一些对象创建…...
一款全新的基于GPT4的Python神器,关键还免费
chartgpt大火之后,随之而来的就是一大类衍生物了。 然后,今天要给大家介绍的是一款基于GPT4的新一代辅助编程神器——Cursor。 它最值得介绍的地方在于它免费,我们可以直接利用它来辅助我们编程,真正做到事半功倍。 注意&#…...

上岸整理:2023前端面试题-vue,小程序,js,css
前端: 今年疫情结束后,前端行情不好,竞争压力很大,现在整理下个人认为面试很频繁的前端问题。 正题:无分类,因为面试官的问题也是随机的 一、基础 1、浏览器常见的报错信息与含义 2、304与204的区别&am…...

Linux下LED设备驱动开发(LED灯实现闪烁)
文章目录一、配置连接说明二、更新设备树(1)将led灯引脚添加到pinctrl子系统(2)设备树中添加LDE灯的设备树节点(3)编译更新设备树三、驱动开发与测试(1)编写设备驱动代码(…...
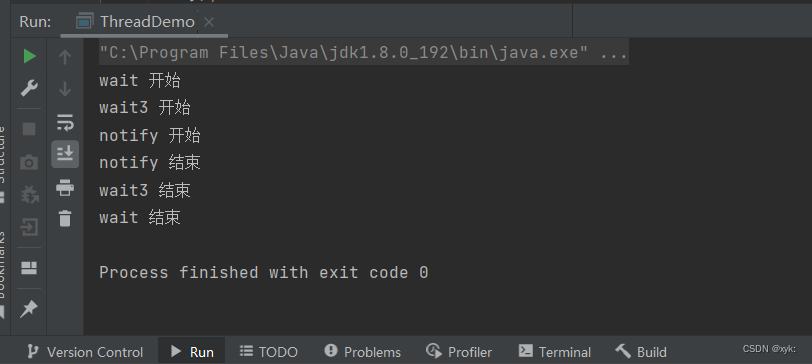
JavaEE-多线程中wait和notify都有哪些区别?
更多内容请点击了解 本篇文章将详细讲述wait和notify的区别,请往下看 目录 更多内容请点击了解 文章目录 一、wait和notify概念 二、wait()方法详解 三、notify()方法详解 代码如下: 3.1notifyAll()详解 四、wait和sleep的对比 一、wait和notif…...

JavaScript实现列表分页(小白版)
组件用惯了,突然叫你用纯cssJavaScript写一个分页,顿时就慌了。久久没有接触js了,不知道咋写了。本文章也是借与参考做的一个demo案例,小白看了都会的那种。咱们就以ul列表为例进行分页: 首先模拟的数据列表是这样的&a…...

Python调用GPT3.5接口的最新方法
GPT3.5接口调用方法主要包括openai安装、api_requestor.py替换、接口调用、示例程序说明四个部分。 1 openai安装 Python openai库可直接通过pip install openai安装。如果已经安装openai,但是后续提示找不到ChatCompletion,那么请使用命令“pip instal…...

Java开发 - 拦截器初体验
目录 前言 拦截器 什么是拦截器 拦截器和过滤器 Spring MVC的拦截器 Mybatis的拦截器...

【数据仓库-7】-- 使用维度建模的一些缘由
维度建模是一种用于设计数据仓库和商业智能系统的方法。以下是选择维度建模的两类理由。 1.传统方法,有背书且可靠 易于理解和使用:维度建模使用直观的图形和术语,使得非技术人员也能够理解和使用数据仓库和商业智能系统。 快速开发和部署:维度建模是一种迭代开发方法,能…...

【开发实践】在线考试系统(一) 生成错题知识点的思维导图
一、需求分析设计 笔者开发了一个在线考试系统,导师提出一个需求:添加对考试错题相关知识点的总结。 在question表中关联知识点的编号,题目可能关联多个知识点。这里笔者的设计是,只关联一个知识点,便于维护。 下面是知…...

Java Web 实战 17 - 计算机网络之传输层协议(2)
大家好 , 这篇文章继续给大家讲解 TCP 协议当中的一些操作 , 比如 : 滑动窗口、流量控制、拥塞控制、延时应答、捎带应答、面向字节流这几个提升 TCP 效率的操作 . 我们还会给大家分析 TCP 连接出现异常的时候 , 该如何处理 . 最后会将 TCP 和 UDP 进行比较 上一篇文章的链接也…...
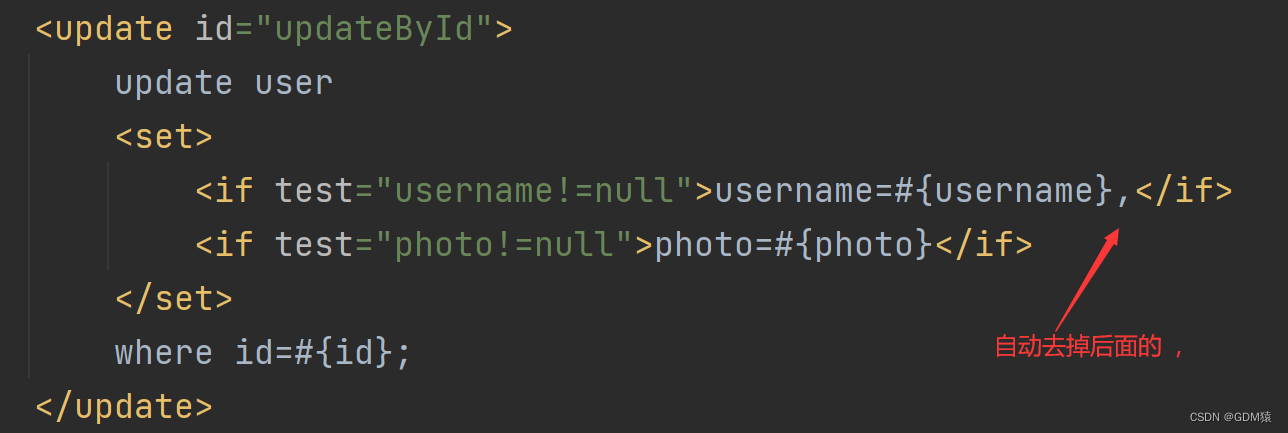
MyBatis<3>:动态SQL的使用<if><trim><where><set><foreach>
动态SQL是MyBatis的强大特性之一,能够完成不同条件下不同的sql拼接。参考官方文档:https://mybatis.org/mybatis-3/zh/dynamic-sql.html<if>标签看这个场景,有必填字段 和 非必填字段 ,当字段不确定是否传入的时候ÿ…...

【超好懂的比赛题解】暨南大学2023东软教育杯ACM校赛个人题解
title : 暨南大学2023东软教育杯ACM校赛 题解 tags : ACM,练习记录 date : 2023-3-26 author : Linno 文章目录暨南大学2023东软教育杯ACM校赛 题解A-小王的魔法B-苏神的遗憾C-神父的碟D-基站建设E-小王的数字F-Uziの真身G-电子围棋H-二分大法I-丁真的小马朋友们J-单车运营K-超…...

go-zero学习及使用中遇到的问题
go-zero学习及使用中遇到的问题1 go-zero入门--单体服务demo1.1 单体服务【官方示例】1.1.1 创建greet服务1.1.2 目录结构1.1.3 编写逻辑1.1.4 启动并访问服务1.2 修改GET入参1.2.1 去除options限制的入参值1.2.2 重启并访问服务1.3 添加post请求【新增方法】1.3.1 修改 greet/…...
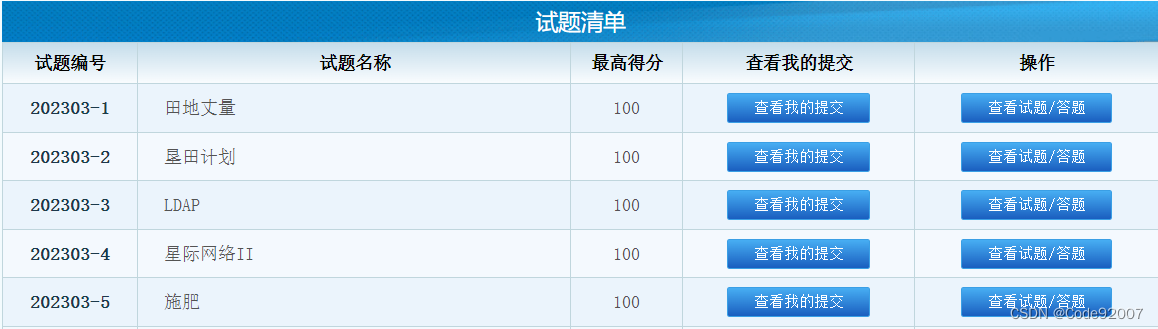
CCF-CSP认证 202303 500分题解
202303-1 田地丈量(矩阵面积交) 矩阵面积交x轴线段交长度*y轴线段交长度 线段交长度,相交的时候是min右端点-max左端点,不相交的时候是0 #include<bits/stdc.h> using namespace std; int n,a,b,ans,x,y,x2,y2; int f(in…...

板内盘中孔设计狂飙,细密间距线路中招
一博高速先生成员:王辉东大风起兮云飞扬,投板兮人心舒畅。赵理工打了哈欠,伸了个懒腰,看了看窗外,对林如烟说道:“春天虽美,但是容易让人沉醉。如烟,快女神节了,要不今晚…...
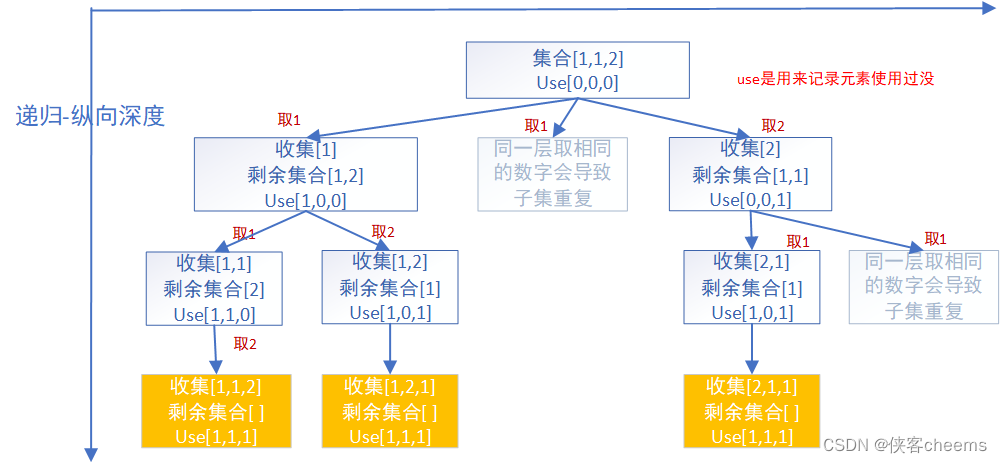
面试热点题:回溯算法 递增子序列与全排列 II
前言: 如果你一点也不了解什么叫做回溯算法,那么推荐你看看这一篇回溯入门,让你快速了解回溯算法的基本原理及框架 递增子序列 给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两…...

怎么找回回收站删除的文件
我们都知道,电脑文件都是放在桌面上的,单独存放或者一起存放在文件夹里。但总会有已用完或者是没用的文件,这让我们不得不对其进行清理。而清空回收站也是不可避免的。如果出现了清空文件中还有我们需要的文件,怎么找回回收站删除…...
)
高通平台实战:手把手教你解析和修改CDT中的board-id(附常见报错排查)
高通平台深度实战:CDT中board-id的解析与定制化修改指南 引言:为什么需要关注board-id? 在Android底层开发中,board-id就像设备的"身份证号",它决定了系统如何识别硬件配置并加载对应的设备树和驱动。对于从…...
)
别再死记硬背了!用MATLAB 5分钟搞定控制系统的稳定裕度计算(附代码)
用MATLAB高效计算控制系统稳定裕度的工程实践指南 在自动控制系统的设计与分析中,稳定裕度是评估系统鲁棒性的关键指标。传统手工计算不仅耗时费力,还容易出错。本文将展示如何利用MATLAB这一强大工具,在5分钟内完成从传递函数定义到稳定裕度…...
)
从404到无损输出:一个Favicon抓取API的三年优化笔记(含CDN、懒加载避坑指南)
从404到毫秒响应:Favicon API架构演进与高并发实践 第一次收到用户反馈"favicon接口返回500错误"时,我们团队正在会议室讨论如何优化爬虫性能。那是个典型的周一早晨——咖啡还没喝完,警报先响了起来。这个看似简单的图标抓取服务&…...

【完整源码+数据集+部署教程】光纤缺陷检测系统源码分享[一条龙教学YOLOV8标注好的数据集一键训练_70+全套改进创新点发刊_Web前端展示]
一、背景意义 随着光纤通信技术的迅猛发展,光纤作为信息传输的主要媒介,其质量的优劣直接影响到通信系统的性能和稳定性。光纤在生产、运输和安装过程中,可能会出现各种缺陷,如划痕、气泡、折弯等,这些缺陷不仅会导致信…...
通义千问Qwen2-VL模型部署避坑指南:如何用transformers库绕过Flash-Attention2安装
通义千问Qwen2-VL模型轻量化部署实战:避开Flash-Attention2的安装陷阱 最近在测试通义千问的多模态模型Qwen2-VL时,发现官方推荐的Flash-Attention2依赖项安装过程异常繁琐,不仅编译耗时数小时,还经常因环境配置问题报错。经过多次…...

Omni-Vision Sanctuary 集成 MySQL 数据库:自动化图像元数据管理与检索方案
Omni-Vision Sanctuary 集成 MySQL 数据库:自动化图像元数据管理与检索方案 1. 场景痛点与解决方案 数字内容创作领域正面临一个普遍挑战:随着AI生成图像的爆发式增长,如何高效管理海量图片资产成为棘手问题。某电商设计团队负责人曾向我们…...
结合鸿蒙系统特性:在HarmonyOS应用中嵌入Pixel Couplet Gen生成能力
结合鸿蒙系统特性:在HarmonyOS应用中嵌入Pixel Couplet Gen生成能力 1. 引言:当传统艺术遇见分布式技术 春节贴春联是中国人延续千年的文化传统,而如今,借助AI技术和鸿蒙系统的分布式能力,我们可以让这一传统焕发新的…...

别再浪费手机性能了!Blackmagic Camera 搭配 LUT 滤镜包,解锁夜景和人物拍摄的隐藏技巧
Blackmagic Camera 与 LUT 滤镜包:解锁手机摄影的隐藏潜力 手机摄影早已不再是简单的记录工具,而是可以创作出专业级影像的利器。对于追求画质的摄影爱好者和小型工作室来说,Blackmagic Camera 这款专业级拍摄应用配合精心调校的 LUT 滤镜包&…...

Part 1:Python 语言核心 - 变量与命名规则
Python 基础语法 - 变量与命名规则 一、python 变量的真实模型变量 名字(name)→ 对象(object)的“绑定关系”python 中变量本身不存值,值永远存储在对象里,变量只是标签/引用。 a 10底层语义等价于&…...

3步打造专业级H5页面:开源编辑器h5maker零代码解决方案
3步打造专业级H5页面:开源编辑器h5maker零代码解决方案 【免费下载链接】h5maker h5编辑器类似maka、易企秀 账号/密码:admin 项目地址: https://gitcode.com/gh_mirrors/h5/h5maker 在数字化营销与内容传播领域,H5页面已成为连接品牌…...