PyTorch 卷积层详解
PyTorch 卷积层详解
卷积层(Convolutional Layers)是深度学习中用于提取输入数据特征的重要组件,特别适用于处理图像和序列数据。PyTorch 提供了多种卷积层,分别适用于不同维度的数据。本文将详细介绍这些卷积层,特别是二维卷积层(nn.Conv2d),并结合示例说明其使用方法。
二维卷积层(nn.Conv2d)
二维卷积层(nn.Conv2d)是处理图像数据的核心组件,在计算机视觉任务中广泛应用。它通过卷积运算提取图像的局部特征,如边缘、纹理等,从而为后续的图像分类、目标检测等任务提供有用的信息。
参数解释
in_channels:输入图像的通道数。例如,对于 RGB 图像,该值为 3。out_channels:卷积层输出的通道数,通常是超参数。kernel_size:卷积核的大小,可以是单个整数或(高度, 宽度)的元组。stride:卷积操作的步幅,默认为 1,可以是单个整数或(高度, 宽度)的元组。padding:在输入图像周围填充的像素数,默认为 0,可以是单个整数或(高度, 宽度)的元组。dilation:卷积核元素之间的间距,默认为 1。groups:控制输入和输出之间的连接方式,默认为 1。bias:如果设置为 True,则添加一个偏置项,默认为 True。
示例:读取 JPEG 图片,进行卷积操作,并保存结果为新的 JPEG 图片
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
import os
import argparse# 定义二维卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=4, kernel_size=3, stride=1, padding=1)# 读取 JPEG 图片,并转换为 Tensor
def load_image(image_path):image = Image.open(image_path).convert('RGB')transform = transforms.ToTensor() # 将图片转换为 Tensor 并归一化到 [0, 1]image_tensor = transform(image).unsqueeze(0) # 增加一个批次维度return image_tensor# 保存 Tensor 为 JPEG 图片
def save_image(tensor, output_dir, base_filename):transform = transforms.ToPILImage()os.makedirs(output_dir, exist_ok=True) # 创建输出目录# 对于每个通道,保存为单独的图片for i in range(tensor.shape[1]):channel_tensor = tensor[:, i, :, :].squeeze(0) # 取出第 i 个通道并去掉批次维度image = transform(channel_tensor)image.save(os.path.join(output_dir, f"{base_filename}_channel_{i+1}.jpg"))# 进行卷积操作
def apply_convolution(image_tensor, conv_layer):with torch.no_grad(): # 不需要计算梯度output_tensor = conv_layer(image_tensor)return output_tensor# 主函数
def main(input_image_path, output_dir):base_filename = 'output' # 基础文件名# 加载图片image_tensor = load_image(input_image_path)# 打印输入图片plt.imshow(image_tensor.squeeze(0).permute(1, 2, 0))plt.title("Input Image")plt.show()# 进行卷积操作output_tensor = apply_convolution(image_tensor, conv2d)# 对输出结果进行处理,使其适合保存为图片output_tensor = torch.sigmoid(output_tensor) # 使用 sigmoid 函数将输出限制在 [0, 1] 之间# 打印输出图片for i in range(output_tensor.shape[1]):plt.imshow(output_tensor[0, i, :, :], cmap='gray')plt.title(f"Output Image Channel {i+1}")plt.show()# 保存输出图片save_image(output_tensor, output_dir, base_filename)if __name__ == "__main__":parser = argparse.ArgumentParser(description="Apply a convolution layer to an input image and save the results.")parser.add_argument('input_image_path', type=str, help="Path to the input JPEG image.")parser.add_argument('output_dir', type=str, help="Directory to save the output images.")args = parser.parse_args()main(args.input_image_path, args.output_dir)
解释
-
定义卷积层:
- 我们定义了一个二维卷积层,输入通道数为 3,输出通道数为 4,卷积核大小为 3x3,步幅为 1,填充为 1。
-
读取图片:
- 使用
PIL.Image.open读取 JPEG 图片,并转换为 RGB 模式。 - 使用
transforms.ToTensor将图片转换为 Tensor,并归一化到 [0, 1]。 - 增加一个批次维度,使其形状变为
(1, 3, H, W)。
- 使用
-
卷积操作:
- 使用
with torch.no_grad()关闭梯度计算。 - 将输入图片 Tensor 传入卷积层,得到输出 Tensor。
- 使用
-
处理输出:
- 使用
torch.sigmoid(output_tensor)将卷积层的输出限制在 [0, 1] 范围内。 - 打印并展示每个输出通道的图像。
- 使用
-
保存输出图片:
save_image函数被优化以处理多个通道。对于每个通道,保存为单独的图片。- 输出图片将被保存到指定的目录中,文件名格式为
output_channel_X.jpg。
-
主函数:
- 读取输入图片,进行卷积操作,并保存输出图片。
-
命令行参数处理:
- 使用
argparse模块处理命令行参数,允许用户通过命令行指定输入图像路径和输出目录路径。
- 使用
运行代码
将上述代码保存为一个 Python 文件(例如 conv2d_image_processing.py),然后在命令行中运行该文件,并指定输入图像路径和输出目录路径:
python conv2d_image_processing.py path/to/your/input.jpg path/to/output/directory
原始图像

卷积核及特征图
卷积操作会提取特定的特征(如边缘、纹理等),因此卷积后的图像包含的是经过卷积核处理后的特征图。卷积后的图像可能会丢失一些原始的细节,同时突出某些特征。卷积核(又称滤波器)在输入图像上滑动并执行点积运算的过程是卷积神经网络(CNN)中的核心操作,用于特征提取。
4个卷积通道,每个通道输出的卷积特征图:

以下是详细介绍这个过程的步骤:
1. 输入图像和卷积核
首先,定义输入图像和卷积核:
- 输入图像:这是一个二维矩阵(对于灰度图像)或者三维矩阵(对于彩色图像,第三维是颜色通道)。
- 卷积核:这是一个较小的二维矩阵(对于灰度图像)或者三维矩阵(对于彩色图像,第三维与输入图像的颜色通道数相同)。
2. 设置参数
- 步幅(Stride):卷积核每次移动的像素数。
- 填充(Padding):在输入图像的边缘添加额外的像素(通常是零)以控制输出特征图的尺寸。
3. 滑动卷积核
卷积核从输入图像的左上角开始,以步幅为单位在图像上滑动。每次滑动的具体步骤如下:
-
定位:
- 将卷积核的左上角与输入图像的当前区域对齐。
-
提取子区域:
- 从输入图像提取与卷积核尺寸相同的子区域。
-
点积运算:
- 对应元素相乘:将卷积核的每一个元素与子区域的对应元素相乘。
- 求和:将所有乘积结果相加,得到一个单一的标量值。
-
存储结果:
- 将上述标量值存储在输出特征图的对应位置。
4. 重复滑动
按照步幅参数,继续滑动卷积核到下一个位置,重复上述步骤,直到遍历整个输入图像。
5. 处理边界
根据填充策略(如零填充),在滑动过程中处理输入图像的边界:
- 无填充(Valid Padding):卷积核只在输入图像的有效区域内滑动,输出特征图尺寸会小于输入图像。
- 零填充(Same Padding):在输入图像边缘添加零,使得卷积核可以覆盖到边缘区域,输出特征图尺寸等于输入图像。
6. 生成输出特征图
经过上述滑动和计算过程,最终生成的输出特征图是一个新矩阵,包含了卷积运算后的结果。
卷积核在输入图像上滑动并执行点积运算的过程是通过一系列的矩阵操作实现的。这个过程可以有效地提取输入图像中的局部特征,并生成新的特征图用于后续的处理和分析。
stride 和 padding 参数说明
在卷积操作中,stride 和 padding 是两个重要的参数,它们决定了输出特征图的大小。下面详细介绍 Conv2d(in_channels=3, out_channels=1, kernel_size=3, stride=1, padding=1) 中 stride=1 和 padding=1 的作用,并解释为什么设置为 1 可以保证特征图大小和原始图像大小相同。
1. Stride(步幅)
stride 参数决定了卷积核在输入图像上滑动的步幅。具体来说,stride 控制了卷积核每次移动的像素数。默认情况下,stride 为 1,这意味着卷积核每次移动 1 个像素。
作用
- 步幅为 1:卷积核每次移动 1 个像素,覆盖输入图像的所有位置。
- 步幅大于 1:卷积核每次移动多个像素,跳跃式地覆盖输入图像,导致输出特征图的尺寸缩小。
2. Padding(填充)
padding 参数决定了在输入图像的边缘填充额外的像素数。填充可以确保卷积操作不会丢失输入图像的边缘信息。
作用
- 填充为 0(无填充):卷积核只在原始输入图像上移动,输入图像的边缘像素会被忽略。
- 填充大于 0:在输入图像的边缘添加额外的像素,使得卷积核可以覆盖到输入图像的边缘。Padding值为1就会在上下左右4个维度各增加1个像素,这样宽和高都是增加2;
3. 卷积核大小(Kernel Size)
kernel_size 参数决定了卷积核的大小。在这个例子中,kernel_size=3 表示使用 3x3 的卷积核。
4. 计算输出特征图的大小
输出特征图的大小可以通过以下公式计算:
输出高度 = ⌊ 输入高度 + 2 × 填充 − 卷积核大小 步幅 ⌋ + 1 \text{输出高度} = \left\lfloor \frac{\text{输入高度} + 2 \times \text{填充} - \text{卷积核大小}}{\text{步幅}} \right\rfloor + 1 输出高度=⌊步幅输入高度+2×填充−卷积核大小⌋+1
输出宽度 = ⌊ 输入宽度 + 2 × 填充 − 卷积核大小 步幅 ⌋ + 1 \text{输出宽度} = \left\lfloor \frac{\text{输入宽度} + 2 \times \text{填充} - \text{卷积核大小}}{\text{步幅}} \right\rfloor + 1 输出宽度=⌊步幅输入宽度+2×填充−卷积核大小⌋+1
对于 Conv2d(in_channels=3, out_channels=1, kernel_size=3, stride=1, padding=1):
- 输入高度和宽度:假设为 ( H ) 和 ( W )
- 卷积核大小:3
- 步幅:1
- 填充:1
代入公式:
输出高度 = ⌊ H + 2 × 1 − 3 1 ⌋ + 1 = ⌊ H 1 ⌋ + 1 = H \text{输出高度} = \left\lfloor \frac{H + 2 \times 1 - 3}{1} \right\rfloor + 1 = \left\lfloor \frac{H}{1} \right\rfloor + 1 = H 输出高度=⌊1H+2×1−3⌋+1=⌊1H⌋+1=H
输出宽度 = ⌊ W + 2 × 1 − 3 1 ⌋ + 1 = ⌊ W 1 ⌋ + 1 = W \text{输出宽度} = \left\lfloor \frac{W + 2 \times 1 - 3}{1} \right\rfloor + 1 = \left\lfloor \frac{W}{1} \right\rfloor + 1 = W 输出宽度=⌊1W+2×1−3⌋+1=⌊1W⌋+1=W
因此,输出特征图的大小与输入图像的大小相同。
5. 具体示例
假设输入图像的大小为 32x32:
- 输入图像大小:32x32
- 卷积核大小:3x3
- 步幅:1
- 填充:1
代入公式:
输出高度 = ⌊ 32 + 2 × 1 − 3 1 ⌋ + 1 = 32 \text{输出高度} = \left\lfloor \frac{32 + 2 \times 1 - 3}{1} \right\rfloor + 1 = 32 输出高度=⌊132+2×1−3⌋+1=32
输出宽度 = ⌊ 32 + 2 × 1 − 3 1 ⌋ + 1 = 32 \text{输出宽度} = \left\lfloor \frac{32 + 2 \times 1 - 3}{1} \right\rfloor + 1 = 32 输出宽度=⌊132+2×1−3⌋+1=32
因此,输出特征图的大小为 32x32,与输入图像的大小相同。
总结
通过设置 stride=1 和 padding=1,可以确保卷积操作后的输出特征图的大小与输入图像的大小相同。这是因为填充操作在输入图像的边缘添加额外的像素,使得卷积核可以完全覆盖输入图像的每个位置,而步幅为 1 确保卷积核逐像素移动,不会跳跃。此外,卷积核的大小也影响输出特征图的大小,但在这种设置下(kernel_size=3),输出特征图的大小与输入图像的大小保持一致。
out_channels 参数
在 nn.Conv2d 定义中,out_channels 参数非常重要,它决定了卷积操作后输出特征图的数量。以下是对 out_channels 参数的详细解释和常见设置方法:
out_channels 的作用
-
输出通道数:
out_channels指定了卷积层输出特征图的数量。每个特征图都是通过与输入图像进行卷积操作得到的。- 输出特征图的数量由卷积核(filter)的数量决定,每个卷积核会生成一个特征图。
-
特征提取:
- 不同的卷积核可以提取输入图像的不同特征,例如边缘、纹理、形状等。通过增加
out_channels,可以提取更多种类的特征。 - 每个卷积核会与输入图像进行卷积,生成一个特征图。多个卷积核生成多个特征图,这些特征图堆叠在一起,形成输出的多个通道。
- 不同的卷积核可以提取输入图像的不同特征,例如边缘、纹理、形状等。通过增加
-
模型复杂度:
- 增加
out_channels会增加模型的参数数量,从而提高模型的表达能力,但也会增加计算复杂度。 - 在实际应用中,需要根据具体任务和计算资源来选择合适的
out_channels数量。
- 增加
常见设置方法
-
基本卷积层:
- 在简单的卷积神经网络中,
out_channels通常设置为 32、64、128 等,逐层递增。例如,第一个卷积层可能有 32 个输出通道,第二个卷积层有 64 个输出通道,依此类推。 - 这种设置方法可以逐步增加模型的表达能力,同时控制计算复杂度。
- 在简单的卷积神经网络中,
-
深度卷积神经网络:
- 在深度卷积神经网络(如 ResNet、VGG 等)中,
out_channels通常设置为较大的值,如 256、512 等。这些网络通过增加卷积层的深度和宽度来提高模型的性能。
- 在深度卷积神经网络(如 ResNet、VGG 等)中,
-
任务需求:
- 具体任务的需求也会影响
out_channels的设置。例如,在图像分类任务中,较大的out_channels可以提取更多的特征,提高分类精度。 - 在实时处理任务中,可能需要平衡模型性能和计算速度,选择较小的
out_channels以减少计算量。
- 具体任务的需求也会影响
在 nn.Conv2d 方法中,卷积核的数量由 out_channels 参数决定。你可以根据需要设置任意数量的卷积核,具体数量取决于你的计算资源和应用需求。以下是对 nn.Conv2d 中卷积核数量设置和每个卷积核差异的详细解释:
每个卷积核(卷积通道)的差异
每个卷积核在卷积层中是独立的,并且有以下几个方面的差异:
-
初始化:
- 每个卷积核的权重在初始化时是随机的,通常根据某种分布(如正态分布或均匀分布)进行初始化。
- PyTorch 提供了多种初始化方法,可以通过
torch.nn.init模块进行自定义初始化。
-
权重:
- 每个卷积核都有自己独立的权重矩阵,权重矩阵的大小由
kernel_size参数决定。 - 例如,对于
kernel_size=3,每个卷积核的权重矩阵大小为 3x3。
- 每个卷积核都有自己独立的权重矩阵,权重矩阵的大小由
-
学习过程:
- 在模型训练过程中,每个卷积核的权重会根据反向传播算法进行更新,以最小化损失函数。
- 因此,不同的卷积核会学习到不同的特征,提取输入图像的不同方面。
-
提取特征:
- 由于初始权重和学习过程的差异,每个卷积核会提取输入图像的不同特征,如边缘、纹理、形状等。
- 例如,一个卷积核可能对水平边缘反应强烈,而另一个卷积核可能对垂直边缘反应强烈。
示例代码
以下是一个示例代码,展示了如何定义多个卷积核的二维卷积层,以及每个卷积核在初始化时的权重差异:
import torch
import torch.nn as nn# 定义一个二维卷积层,输入通道数为3,输出通道数为4,卷积核大小为3x3
conv2d = nn.Conv2d(in_channels=3, out_channels=4, kernel_size=3, stride=1, padding=1)# 打印每个卷积核的权重
for i, weight in enumerate(conv2d.weight):print(f"卷积核 {i+1} 的权重:")print(weight)print()# 创建一个随机输入张量,形状为 (batch_size, in_channels, height, width)
input_tensor = torch.randn(1, 3, 32, 32) # 例如:1张3通道的32x32图像# 通过卷积层进行前向传播
output_tensor = conv2d(input_tensor)# 输出张量的形状
print("输出张量的形状:", output_tensor.shape) # (1, 4, 32, 32)
- 卷积核的数量:在
nn.Conv2d中,卷积核的数量由out_channels参数决定,可以根据需要设置任意正整数值。 - 每个卷积核的差异:每个卷积核在初始化和学习过程中是独立的,有自己独立的权重矩阵。不同的卷积核会提取输入图像的不同特征,从而生成多个特征图。
- 应用:通过合理设置卷积核的数量和参数,可以提高卷积神经网络的特征提取能力,从而提升模型的性能。
输入图像的通道数(in_channels)
在卷积神经网络(CNN)中,处理多通道输入图像(例如 RGB 图像)的卷积操作需要考虑输入图像的通道数(in_channels)。
如何处理多通道输入图像
- 单通道图像:灰度图像,
in_channels = 1。 - 多通道图像:彩色图像,例如 RGB 图像,
in_channels = 3(红、绿、蓝三个通道)。
多通道卷积操作
对于多通道输入图像,卷积操作在每个通道上进行独立的卷积运算,然后将结果相加。假设输入图像有 ( C ) 个通道,每个通道的卷积核大小为 ( K_h \times K_w ),卷积核的数量为 ( N ),则卷积操作的步骤如下:
- 提取子区域:从输入图像的每个通道提取一个 ( K_h \times K_w ) 的子区域。
- 逐通道点积:对每个通道进行逐元素相乘并求和,得到 ( C ) 个标量值。
- 通道结果相加:将 ( C ) 个通道的结果相加,得到一个标量值。
具体数学表达式如下:
假设输入图像的三个通道为 ( I_r, I_g, I_b ),卷积核的三个通道为 ( K_r, K_g, K_b ),在某个滑动位置上的点积结果为:
O = ∑ i = 1 K h ∑ j = 1 K w ( I r [ i , j ] ⋅ K r [ i , j ] + I g [ i , j ] ⋅ K g [ i , j ] + I b [ i , j ] ⋅ K b [ i , j ] ) O = \sum_{i=1}^{K_h} \sum_{j=1}^{K_w} (I_r[i, j] \cdot K_r[i, j] + I_g[i, j] \cdot K_g[i, j] + I_b[i, j] \cdot K_b[i, j]) O=i=1∑Khj=1∑Kw(Ir[i,j]⋅Kr[i,j]+Ig[i,j]⋅Kg[i,j]+Ib[i,j]⋅Kb[i,j])
对于多通道输入图像(如 RGB 图像),卷积核在每个通道上进行独立的点积运算,然后将各通道的结果相加,得到一个标量值,存储在输出特征图的对应位置。输出特征图的尺寸取决于输入图像的尺寸、卷积核的尺寸、步幅和填充方式。
归一化与反归一化
transforms.ToTensor()和transforms.ToPILImage()是PyTorch中torchvision.transforms模块提供的两个常用的图像转换操作。它们分别用于在PIL图像和PyTorch张量之间进行转换。
transforms.ToTensor()
transforms.ToTensor()将PIL图像或NumPy数组转换为PyTorch的张量,并自动将图像的像素值归一化到[0, 1]范围。具体的转换步骤如下:
-
转换数据类型:
- 将输入的PIL图像或NumPy数组转换为PyTorch张量。
-
归一化:
- 如果输入是PIL图像,像素值通常在[0, 255]范围内。
transforms.ToTensor()会将这些像素值除以255,归一化到[0, 1]范围。
- 如果输入是PIL图像,像素值通常在[0, 255]范围内。
transforms.ToPILImage()
transforms.ToPILImage()将PyTorch张量转换为PIL图像。具体的转换步骤如下:
-
反归一化:
- 如果输入的张量在[0, 1]范围内,
transforms.ToPILImage()会将其乘以255,转换回[0, 255]范围内的像素值。
- 如果输入的张量在[0, 1]范围内,
-
转换数据类型:
- 将PyTorch张量转换为PIL图像。输入张量的形状通常是(C, H, W),即通道、高度和宽度。
为什么要将图像值转换到[0, 1]范围
将图像值归一化到[0, 1]范围有以下几个主要原因:
-
数值稳定性:
- 计算机在进行数值计算时,较小的数值范围通常更稳定,能够减少溢出和下溢的风险。
-
一致性:
- 大多数深度学习模型和框架期望输入数据在一个标准化的范围内(通常是[0, 1]或[-1, 1])。这使得模型可以更容易地泛化到不同的数据集和任务。
-
加速收敛:
- 归一化后的数据可以加速模型训练的收敛速度。模型参数的初始值通常是基于假设输入数据在一个特定范围内(如[0, 1])来设计的,归一化可以使参数更新更有效。
-
避免数值问题:
- 在一些计算过程中(例如计算距离、相似度等),较大的值范围可能会导致数值误差的积累,影响计算的准确性。归一化可以减少这些误差。
-
标准化处理:
- 归一化是标准化处理的一部分。标准化不仅包括将值范围缩放到[0, 1],还可能包括去均值和标准化方差等步骤。这些处理可以使数据更符合模型的假设,提高模型性能。
通过使用transforms.ToTensor()和transforms.ToPILImage(),可以方便地在PIL图像和PyTorch张量之间进行转换,并且能够确保数据在适当的范围内,从而更好地进行后续的处理和训练。
为什么使用 Sigmoid 函数
- 将值限制在 [0, 1] 之间:Sigmoid 函数的输出范围是 (0, 1),这非常适合将卷积操作的输出转换为图像格式,因为图像的像素值通常在 [0, 1] 或 [0, 255] 之间。如果直接使用输出 Tensor,可能会导致像素值超出这些范围,影响图像的显示和保存。
- 平滑输出:Sigmoid 函数能够平滑输出,使得图像看起来更加自然,没有突变。
- 适用于灰度图像:在示例代码中,我们将 RGB 三通道图像通过卷积层转换为单通道输出(灰度图像)。使用 Sigmoid 函数可以确保灰度值在 [0, 1] 之间,便于后续的图像保存和显示。
总结
通过本文,我们详细介绍了 PyTorch 的卷积层,特别是二维卷积层(nn.Conv2d)。我们讨论了卷积层的参数设置、卷积核的作用、特征图的生成过程,以及如何根据不同的任务需求设置 out_channels 参数。通过示例代码,我们展示了如何使用二维卷积层对图像进行卷积操作,并将结果保存为新的 JPEG 图片。希望通过这篇文章,读者能够更好地理解和应用 PyTorch 的卷积层,构建出高效的深度学习模型。
一维卷积层(nn.Conv1d)
一维卷积层(nn.Conv1d)是处理序列数据的核心组件,在自然语言处理、时间序列分析等任务中广泛应用。它通过卷积运算提取序列的局部特征,如模式、趋势等,从而为后续的分类、预测等任务提供有用的信息。
参数解释
- in_channels:输入序列的通道数。例如,对于单通道时间序列,该值为1。
- out_channels:卷积层输出的通道数,通常是超参数。
- kernel_size:卷积核的大小,可以是单个整数。
- stride:卷积操作的步幅,默认为1。
- padding:在输入序列周围填充的元素数,默认为0。
- dilation:卷积核元素之间的间距,默认为1。
- groups:控制输入和输出之间的连接方式,默认为1。
- bias:如果设置为True,则添加一个偏置项,默认为True。
一维数据和二维数据的差别
- 一维数据:一维数据通常是序列数据,如时间序列、音频信号或文本数据。它们可以表示为形状为(C, L)的张量,其中C是通道数,L是序列长度。
- 二维数据:二维数据通常是图像数据,表示为形状为(C, H, W)的张量,其中C是通道数,H是高度,W是宽度。
一维卷积核和二维卷积核的差别
- 一维卷积核:一维卷积核的大小是一个整数,如3,表示在序列上覆盖的元素数。卷积核在序列上滑动,提取局部特征。
- 二维卷积核:二维卷积核的大小是一个二维矩阵,如3x3,表示在图像上覆盖的像素数。卷积核在图像的高度和宽度上滑动,提取局部特征。
滑动方式的差别
- 一维卷积滑动方式:一维卷积核在序列上滑动,每次移动一个步幅(stride),在每个位置进行卷积操作。
- 二维卷积滑动方式:二维卷积核在图像的高度和宽度上滑动,每次移动一个步幅(stride),在每个位置进行卷积操作。
示例:对一维序列数据进行卷积操作
在深度学习和信号处理领域,音频信号通常被视为一维数据。这是因为音频信号主要是时间序列数据,表示为随时间变化的振幅值。具体来说,音频信号可以看作是一个一维的时间序列,每一个采样点对应一个时间点的振幅值。
为什么音频是一维数据
-
时间序列特性:
- 音频信号是时间序列数据,表示为随时间变化的振幅值。这种数据类型本质上是一维的,因为它只有一个主要的变化维度,即时间。
-
数据表示:
- 音频信号通常被表示为一个一维数组(或向量),其中每个元素表示在特定时间点上的振幅值。例如,对于一个采样率为44.1 kHz的音频文件,每秒钟会有44,100个采样点,这些采样点可以表示为一个一维数组。
-
独立通道:
- 虽然音频信号可以有多个通道(如立体声的左右声道),每个通道仍然是一个独立的一维时间序列。因此,对于多通道音频数据,可以将其表示为多个并行的一维时间序列。
形状解释
-
单通道音频数据的形状:
(C, L)- C:通道数,对于单通道音频(如单声道),通道数为1。
- L:序列长度,表示音频信号的总采样点数。
-
多通道音频数据的形状:
(Batch, Channels, Length)- Batch:批次大小,表示一次处理的样本数量。
- Channels ©:通道数,例如立体声音频的通道数为2(左右声道)。
- Length (L):序列长度,表示每个通道的总采样点数。
一维卷积层的作用
一维卷积层(nn.Conv1d)通过在时间序列上滑动卷积核,提取序列的局部特征。它可以用于检测音频信号中的模式、频率变化和其他特征。
示例解释
以下是一个示例程序,展示了如何读取音频信号并进行一维卷积操作:
import torch
import torch.nn as nn
import librosa
import matplotlib.pyplot as plt# 定义一维卷积层
conv1d = nn.Conv1d(in_channels=1, out_channels=2, kernel_size=3, stride=1, padding=1)# 读取音频文件并转换为Tensor
def load_audio(audio_path):y, sr = librosa.load(audio_path, sr=None) # 读取音频文件y = torch.tensor(y).unsqueeze(0).unsqueeze(0) # 转换为Tensor并增加批次和通道维度return y, sr# 保存处理后的音频
def save_audio(tensor, sr, output_path):y = tensor.squeeze().numpy() # 去掉批次和通道维度librosa.output.write_wav(output_path, y, sr) # 保存为WAV文件# 进行卷积操作
def apply_convolution(audio_tensor, conv_layer):with torch.no_grad(): # 不需要计算梯度output_tensor = conv_layer(audio_tensor)return output_tensor# 主函数
def main(input_audio_path, output_audio_path):# 加载音频audio_tensor, sr = load_audio(input_audio_path)print("Input Audio Shape:", audio_tensor.shape)# 进行卷积操作output_tensor = apply_convolution(audio_tensor, conv1d)print("Output Audio Shape:", output_tensor.shape)# 可视化输入和输出音频信号plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(audio_tensor.squeeze().numpy())plt.title("Input Audio Signal")plt.subplot(1, 2, 2)plt.plot(output_tensor.squeeze().numpy().T)plt.title("Output Audio Signal")plt.show()# 保存处理后的音频save_audio(output_tensor[0, 0], sr, output_audio_path)if __name__ == "__main__":input_audio_path = 'path/to/your/input.wav'output_audio_path = 'path/to/your/output.wav'main(input_audio_path, output_audio_path)
解释
-
读取音频数据:
- 使用
librosa库读取音频文件,并将其转换为PyTorch张量。音频数据的形状为(1, 1, L),其中1表示批次大小,1表示通道数,L表示序列长度。
- 使用
-
定义一维卷积层:
- 定义一个一维卷积层,指定输入通道数、输出通道数、卷积核大小、步幅和填充等参数。
-
进行卷积操作:
- 使用卷积层对输入音频数据进行卷积操作,提取局部特征。
-
可视化和保存输出:
- 可视化输入和输出音频信号。
- 保存处理后的音频信号。
通过这个示例,我们可以看到如何使用PyTorch中的nn.Conv1d进行一维卷积操作,并理解为什么音频信号被视为一维数据。音频信号是时间序列数据,主要变化维度是时间,通过一维卷积可以提取序列中的局部特征。
三维卷积层(nn.Conv3d)
三维卷积层(nn.Conv3d)是处理三维数据(如视频、医学图像)的核心组件。在视频分析、3D图像处理等任务中广泛应用。它通过卷积运算提取三维数据的局部特征,如运动信息、空间结构等,从而为后续的分类、检测等任务提供有用的信息。
参数解释
- in_channels:输入数据的通道数。例如,对于RGB视频帧,该值为3。
- out_channels:卷积层输出的通道数,通常是超参数。
- kernel_size:卷积核的大小,可以是单个整数或(深度, 高度, 宽度)的元组。
- stride:卷积操作的步幅,默认为1,可以是单个整数或(深度, 高度, 宽度)的元组。
- padding:在输入数据周围填充的元素数,默认为0,可以是单个整数或(深度, 高度, 宽度)的元组。
- dilation:卷积核元素之间的间距,默认为1。
- groups:控制输入和输出之间的连接方式,默认为1。
- bias:如果设置为True,则添加一个偏置项,默认为True。
三维数据和二维数据的差别
- 三维数据:三维数据通常是视频数据或三维医学图像,表示为形状为(C, D, H, W)的张量,其中C是通道数,D是深度,H是高度,W是宽度。
- 二维数据:二维数据通常是图像数据,表示为形状为(C, H, W)的张量,其中C是通道数,H是高度,W是宽度。
三维卷积核和二维卷积核的差别
- 三维卷积核:三维卷积核的大小是一个三维矩阵,如3x3x3,表示在深度、高度和宽度上覆盖的元素数。卷积核在三维数据上滑动,提取局部特征。
- 二维卷积核:二维卷积核的大小是一个二维矩阵,如3x3,表示在高度和宽度上覆盖的像素数。卷积核在二维图像上滑动,提取局部特征。
滑动方式的差别
- 三维卷积滑动方式:三维卷积核在深度、高度和宽度上滑动,每次移动一个步幅(stride),在每个位置进行卷积操作。
- 二维卷积滑动方式:二维卷积核在高度和宽度上滑动,每次移动一个步幅(stride),在每个位置进行卷积操作。
示例:对三维数据(如视频帧)进行卷积操作
在深度学习和计算机视觉中,视频数据通常被视为三维数据。这是因为视频不仅包含空间信息(如图像的高度和宽度),还包含时间信息(即帧的序列)。具体来说,视频数据可以表示为一个四维张量,形状为 (C, D, H, W),其中:
- C:通道数(Channels),例如对于RGB视频,每帧有3个颜色通道。
- D:深度(Depth),即视频中的帧数(Frames)。
- H:高度(Height),每帧图像的高度。
- W:宽度(Width),每帧图像的宽度。
因此,视频数据可以看作是由多个帧组成的一个三维结构,每个帧本身是一个二维图像。
为什么视频是三维数据
-
时间维度:
- 视频由一系列连续的帧组成,这些帧按照时间顺序排列,形成一个时间维度。这个维度通常被称为深度(Depth),表示视频的帧数。
-
空间维度:
- 每个视频帧都是一个二维图像,具有高度(Height)和宽度(Width)两个空间维度。
-
通道维度:
- 每个视频帧可以有多个通道(如RGB图像的3个颜色通道),表示为通道数(Channels)。
形状解释
- 输入视频数据的形状:
(Batch, Channels, Depth, Height, Width)- Batch:批次大小,表示一次处理的样本数量。
- Channels ©:通道数,例如RGB视频的通道数为3。
- Depth (D):帧数,表示视频的时间维度。
- Height (H):每帧图像的高度。
- Width (W):每帧图像的宽度。
三维卷积层的作用
三维卷积层(nn.Conv3d)通过在视频数据的深度、高度和宽度三个维度上滑动卷积核,提取视频的局部特征。这些特征不仅包括空间特征(如图像的边缘、纹理等),还包括时间特征(如运动信息、帧间变化等)。
示例解释
以下是一个示例程序,展示了如何读取视频数据并进行三维卷积操作:
import torch
import torch.nn as nn
import cv2
import numpy as np
import matplotlib.pyplot as plt# 定义三维卷积层
conv3d = nn.Conv3d(in_channels=3, out_channels=4, kernel_size=3, stride=1, padding=1)# 读取视频文件并转换为Tensor
def load_video(video_path, num_frames=16):cap = cv2.VideoCapture(video_path)frames = []for _ in range(num_frames):ret, frame = cap.read()if not ret:breakframe = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 转换为RGB格式frames.append(frame)cap.release()frames = np.stack(frames, axis=0) # 形状为 (num_frames, height, width, channels)frames = torch.tensor(frames).permute(3, 0, 1, 2).unsqueeze(0) # 转换为Tensor并增加批次维度return frames# 保存处理后的视频帧
def save_video(tensor, output_path):frames = tensor.squeeze().permute(1, 2, 3, 0).numpy().astype(np.uint8) # 转换为NumPy数组并调整维度height, width, _ = frames[0].shapeout = cv2.VideoWriter(output_path, cv2.VideoWriter_fourcc(*'mp4v'), 30, (width, height))for frame in frames:frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # 转换回BGR格式out.write(frame)out.release()# 进行卷积操作
def apply_convolution(video_tensor, conv_layer):with torch.no_grad(): # 不需要计算梯度output_tensor = conv_layer(video_tensor)return output_tensor# 主函数
def main(input_video_path, output_video_path):# 加载视频video_tensor = load_video(input_video_path)print("Input Video Shape:", video_tensor.shape)# 进行卷积操作output_tensor = apply_convolution(video_tensor, conv3d)print("Output Video Shape:", output_tensor.shape)# 可视化输入和输出视频的一个帧plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.imshow(video_tensor[0, :, 0, :, :].permute(1, 2, 0).numpy().astype(np.uint8))plt.title("Input Video Frame")plt.subplot(1, 2, 2)plt.imshow(output_tensor[0, 0, 0, :, :].detach().numpy(), cmap='gray')plt.title("Output Video Frame (Channel 1)")plt.show()# 保存处理后的视频save_video(output_tensor[0, 0:3], output_video_path) # 保存前三个通道if __name__ == "__main__":input_video_path = 'path/to/your/input.mp4'output_video_path = 'path/to/your/output.mp4'main(input_video_path, output_video_path)
解释
-
读取视频数据:
- 使用OpenCV库读取视频文件,并将每帧图像转换为RGB格式。
- 将所有帧堆叠成一个NumPy数组,并转换为PyTorch张量,形状为
(Batch, Channels, Depth, Height, Width)。
-
定义三维卷积层:
- 定义一个三维卷积层,指定输入通道数、输出通道数、卷积核大小、步幅和填充等参数。
-
进行卷积操作:
- 使用卷积层对输入视频数据进行卷积操作,提取局部特征。
-
可视化和保存输出:
- 可视化输入和输出视频的一个帧。
- 保存处理后的视频帧。
通过这个示例,我们可以看到如何使用PyTorch中的nn.Conv3d进行三维卷积操作,并理解为什么视频数据被视为三维数据。视频数据包含时间、空间和通道维度,通过三维卷积可以同时提取时间和空间特征。
相关文章:
PyTorch 卷积层详解
PyTorch 卷积层详解 卷积层(Convolutional Layers)是深度学习中用于提取输入数据特征的重要组件,特别适用于处理图像和序列数据。PyTorch 提供了多种卷积层,分别适用于不同维度的数据。本文将详细介绍这些卷积层,特别…...

【Kubernetes知识点问答题】kubernetes 控制器
目录 1. 说明 K8s 控制器的作用? 2. 什么是 ReplicaSet,说明它的主要用途。 3. Deployment 控制器是如何工作的,举例说明其常见用途。 4. 解释 DaemonSet,列举其使用场景。 5. 什么是 StatefulSet,其主要作用是什么…...
Patlibc———更快捷的更换libc
起初是为了简化做pwn题目时,来回更换libc的麻烦,为了简化命令,弄了一个小脚本,可以加入到/usr/local/bin中,当作一个快捷指令🔢 这个写在了tools库(git clone https://github.com/CH13hh/tools…...
基于飞腾平台的Hive的安装配置
【写在前面】 飞腾开发者平台是基于飞腾自身强大的技术基础和开放能力,聚合行业内优秀资源而打造的。该平台覆盖了操作系统、算法、数据库、安全、平台工具、虚拟化、存储、网络、固件等多个前沿技术领域,包含了应用使能套件、软件仓库、软件支持、软件适…...

c# json使用
安装包 用NuGet安装包:Newtonsoft.Json 对象转为Json字符串 public class Person {public string Name { get; set; }public int Age { get; set; } }Person person new Person { Name "John Doe", Age 30 }; string json2 JsonConvert.SerializeO…...

单点登录:cas单点登录实现原理浅析
cas单点登录实现原理浅析 一晃几个月没写博客了,今年多灾多难的一年。 安能摧眉折腰事权贵,使我不得开心颜! 财富是对认知的补偿,不是对勤奋的嘉奖。勤奋只能解决温饱,要挣到钱就得预知风口,或者有独到见解…...

java报错
java.lang.RuntimeException: org.hibernate.PersistentObjectException: detached entity passed to persist: com.tengzhi.base.model.E_xt_xmda...

uniapp动态页面API
目录 uni.setNavigationBarTitle动态设置标题 uni.showNavigationBarLoading为标题添加加载动画与uni.hideNavigationBarLoading停止加载动画 编辑 uni.setNavigationBarColor用于设置导航栏的颜色,包括背景颜色和文字颜色。这对于自定义应用的主题和风格非常有…...

最优化方法Python计算:求解约束优化问题的拉格朗日乘子算法
从仅有等式约束的问题入手。设优化问题(7.8) { minimize f ( x ) s.t. h ( x ) o ( 1 ) \begin{cases} \text{minimize}\quad\quad f(\boldsymbol{x})\\ \text{s.t.}\quad\quad\quad \boldsymbol{h}(\boldsymbol{x})\boldsymbol{o} \end{cases}\quad\quad(1) {minimizef(x)s.…...
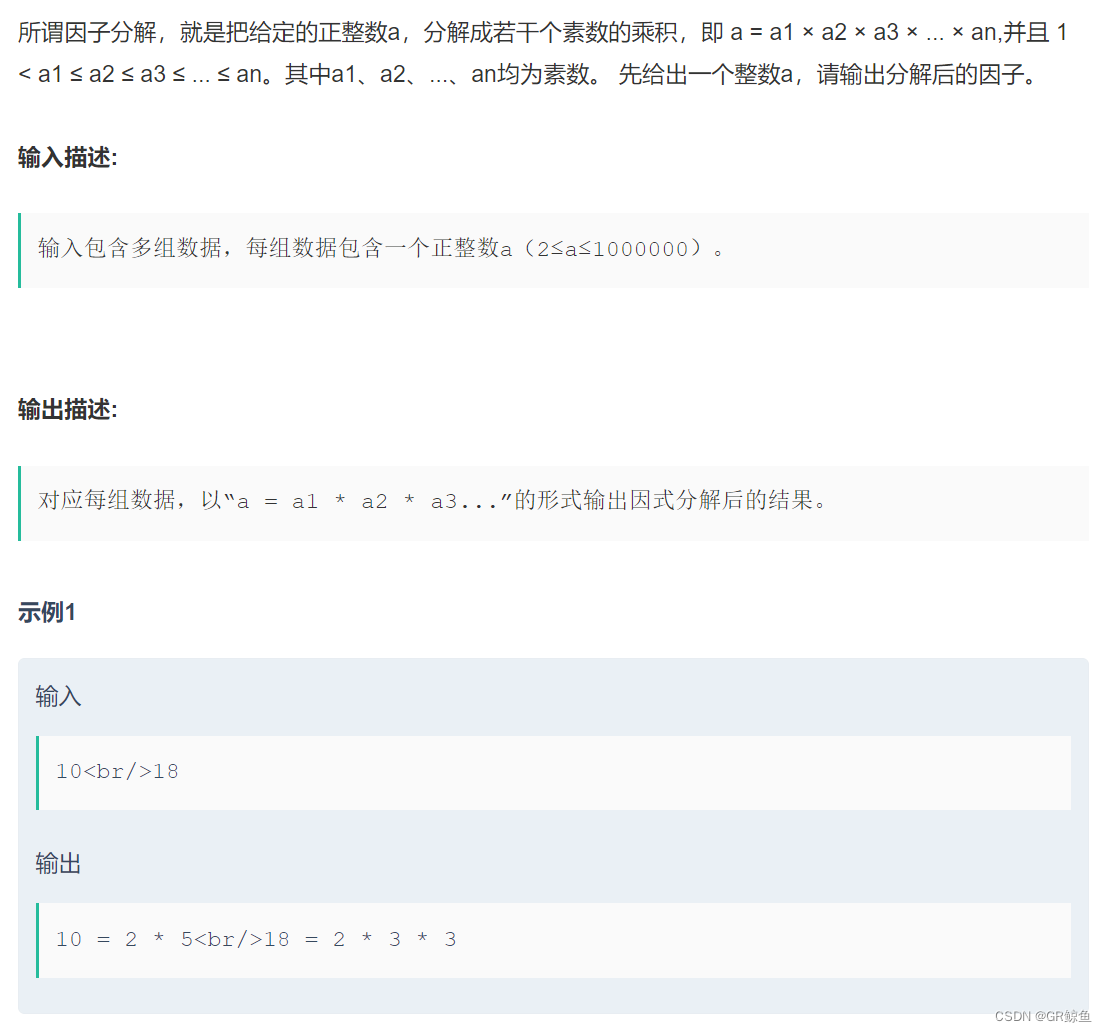
每日OJ_牛客_骆驼命名法(递归深搜)
目录 牛客_骆驼命名法(简单模拟) 解析代码 牛客_骆驼命名法(简单模拟) 骆驼命名法__牛客网 解析代码 首先一个字符一个字符的读取内容: 遇到 _ 就直接跳过。如果上一个字符是 _ 则下一个字符转大写字母。 #inclu…...

MySQL 数据库管理与操作指南
文章目录 MySQL 数据库管理与操作指南1. 忘记 MySQL 密码的处理方法2. MySQL 数据库备份与恢复2.1 数据库备份2.2 数据库恢复 3. MySQL 用户与权限管理3.1 创建用户与授权3.2 查看所有用户3.3 删除用户 4. 关闭 GTID 复制模式5. 查看数据表的存储引擎5.1 查看 MySQL 支持的存储…...

Android Manifest 权限描述大全对照表
115工具网(115工具网-一个提供高效、实用、方便的在线工具集合网站)提供Android Manifest 权限描述大全对照表,可以方便andriod开发者查看安卓权限描述功能 权限名称描述android.permission.ACCESS_CHECKIN_PROPERTIES访问登记属性读取或写入…...

Ollama Qwen2 支持 Function Calling
默认 Ollama 中的 Qwen2 模型不支持 Function Calling,使用默认 Qwen2,Ollama 会报错。本文将根据官方模板对 ChatTemplate 进行改进,使得Qwen2 支持 Tools,支持函数调用。 Ollama 会检查对话模板中是否存在 Tools,如…...

APP测试工程师岗位面试题
一、你们公司研发团队采用敏捷开发模式的原因? 由于版本节奏比较快,开发与测试几乎并行,一个版本周期内会有两版在推动,也就是波次发布,波次发布用于尝试新加入的功能,做小范围快速的开发,验证…...

如何进行 AWS 云监控
什么是 AWS? Amazon Web Services(AWS)是 Amazon 提供的一个全面、广泛使用的云计算平台。它提供广泛的云服务,包括计算能力、存储选项、网络功能、数据库、分析、机器学习、人工智能、物联网和安全。 使用 AWS 有哪些好处&…...

第十六篇:走入计算机网络的传输层--传输层概述
1. 传输层的功能 ① 分割与重组数据 一次数据传输有大小限制,传输层需要做数据分割,所以在数据送达后必然也需要做数据重组。 ② 按端口号寻址 IP只能定位数据哪台主机,无法判断数据报文应该交给哪个应用,传输层给每个应用都设…...
提升效率!ArcGIS中创建脚本工具
在我们日常使用的ArcGIS中已经自带了很多功能强大的工具,但有时候遇到个人的特殊情况还是无法满足,这时就可以试着创建自定义脚本工具。 一、编写代码 此处的代码就是一个很简单的给图层更改别名的代码。 1. import arcpy 2. input_fc arcpy.GetParam…...

无人机之报警器的作用
一、紧急救援与辅助搜救 紧急救援:在事故或紧急情况下,无人机报警器可以迅速发出警报,指引救援人员前往事故地点,提高救援效率。 辅助搜救:无人机搭载报警器可以辅助寻找失踪人员或其他需要搜救的场景,通…...

风格控制水平创新高!南理工InstantX小红书发布CSGO:简单高效的端到端风格迁移框架
论文链接:https://arxiv.org/pdf/2408.16766 项目链接:https://csgo-gen.github.io/ 亮点直击 构建了一个专门用于风格迁移的数据集设计了一个简单但有效的端到端训练的风格迁移框架CSGO框架,以验证这个大规模数据集在风格迁移中的有益效果。…...

python文件自动化(4)
接上节课内容,在开始正式移动文件到目标文件夹之前,我们需要再思考一个问题。在代码运行之前,阿文的下载文件夹里已经存在一些分类文件夹了,比如图例中“PDF文件”这个文件夹就是已经存在的。这样的话,在程序运行时&am…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

XXPermissions:Android权限管理框架的架构设计与最佳实践
XXPermissions:Android权限管理框架的架构设计与最佳实践 【免费下载链接】XXPermissions Android Permissions Framework, Adapt to Android 16 项目地址: https://gitcode.com/GitHub_Trending/xx/XXPermissions 在Android应用开发中,权限管理一…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

在ubuntu上为node.js后端服务接入taotoken统一大模型api
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 上为 Node.js 后端服务接入 Taotoken 统一大模型 API 为后端服务集成大模型能力已成为提升应用智能水平的关键步骤。对于…...