mysql高级sql
文章目录
- 一,查询
- 1.按关键字排序
- 1.1按关键字排序操作
- (1)按分数排序查询(不加asc默认为升序)
- (2)按分数降序查询(DESC)
- (3)使用where进行条件查询
- (4)使用ORDER BY语句对多个字段排序
- 1.2使用区间判断查询(and/or 且和或)
- (1)and
- (2)or
- (3)嵌套多个条件
- (4)distinct 查询不重复记录
- 1.3对查询结果进行分组
- 1.4限制结果条目(limit重要)
- (1)查询所有信息只显示前2行记录
- (2)查询所有信息只显示从第4行开始,往后的2行内容
- (2)结合order by语句,查询id的大小升序排列显示前2行
- (3)查询信息只显示最后3行按降序显示出来(重要)
- (4)查询并显示出第一行开始的后两行
- 1.5设置别名
- (1)统计表内的字段有多少个,以数字形式显示(不加as也可以)
- (2)将查询出的结果插入新表中
- (3)使用别名查询
- 1.6通配符
- (1)查询c开头的
- (2)查询l开头和i结尾的
- (3)查询中间是g的
- (4) 查询以o结尾的
- (5)查询以h开头其中间有e的
- 1.7子查询(内查询)
- (1)单表查询
- (2)多表查询
- (3)update
- (4)delete
- (5)insert
- (6)NOT
- (7)EXISTS
- (8)别名as
- 二,SQL视图
- 1.什么是视图?
- 2.视图的作用
- 3.视图的使用场景
- 4.视图与表的区别
- 5.注意事项
- 6.视图操作
- (1)创建视图单表操作
- (2)多表视图创建
- (3)null值
- a.空值(空字符串)的处理
- 三,连接查询(重要)
- 3.1内连接
- 3.2左连接
- 3.3右连接
- 四,存储过程
- 1.什么是存储过程
- 2.存储过程简介
一,查询
1.按关键字排序
- 用
ORDER BY语句来实现排序:ORDER BY语句用于对查询结果进行排序。可以根据一个或多个字段的值进行升序(ASC)或降序(DESC)排序。
- 排序可针对一个或多个字段:
- 可以指定一个字段或者多个字段进行排序。如果是多个字段,查询结果会首先按第一个字段排序,在第一个字段相同时再按第二个字段排序,依此类推。
ASC:升序,默认排序方式:ASC是升序排序,从小到大排序。如果不指定排序方式,默认使用升序排序。
DESC:降序:DESC是降序排序,从大到小排序。需要在ORDER BY语句后明确指定。
ORDER BY** 的语法结构**:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
1.1按关键字排序操作
创建一个表
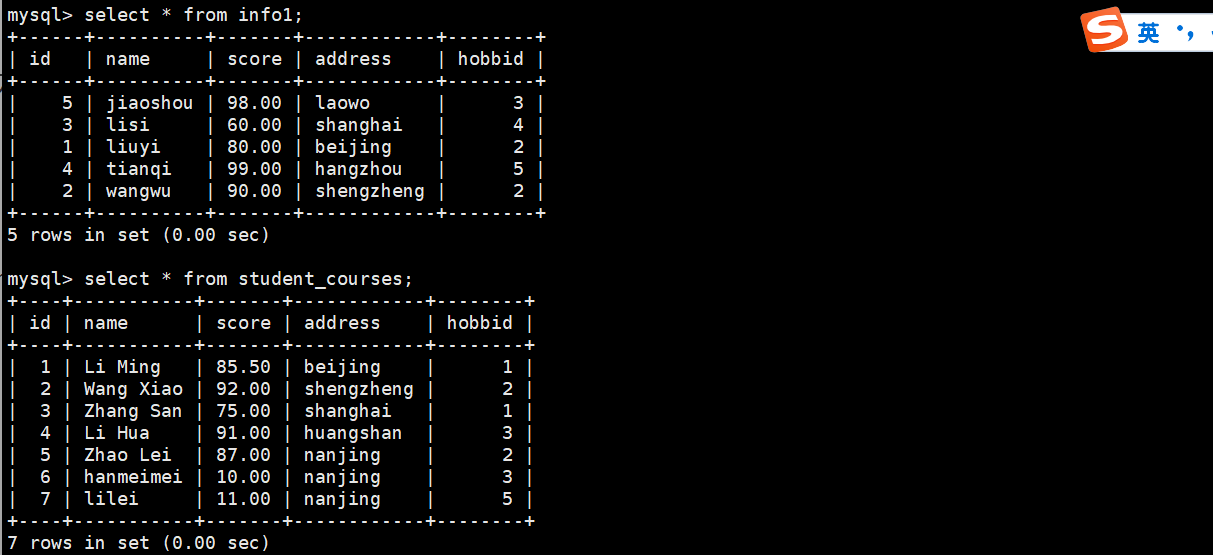
CREATE TABLE student_courses (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(50),score DECIMAL(4, 2),address varchar(20),hobbyid INT
);INSERT INTO student_courses (id, name, score, hobbyid) VALUES
(1, 'Li Ming', 85.5,'beijing', 1),
(2, 'Wang Xiao', 92.0,'shengzheng', 2),
(3, 'Zhang San', 75.0,'shanghai', 1),
(4, 'Li Hua', 91.0,'huangshan' 3),
(5, 'Zhao Lei', 87.0,'nanjing', 2);
(6,'hanmeimei',10,'nanjing',3);
(7,'lilei',11,'nanjing',5);
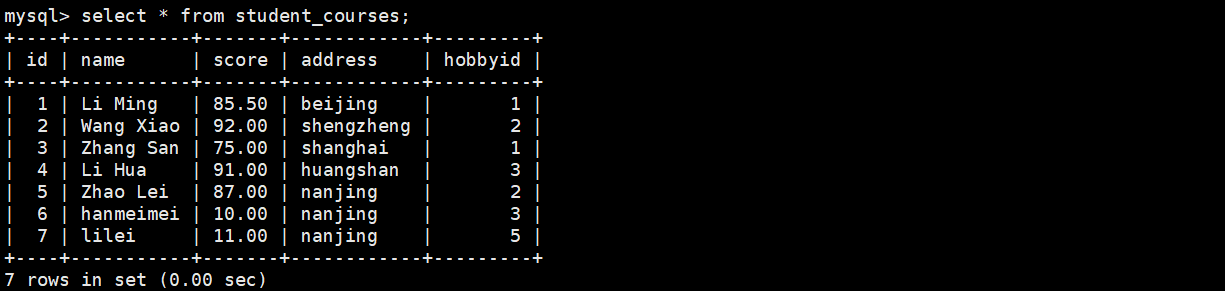
(1)按分数排序查询(不加asc默认为升序)
select id,name,score from student_courses order by score;
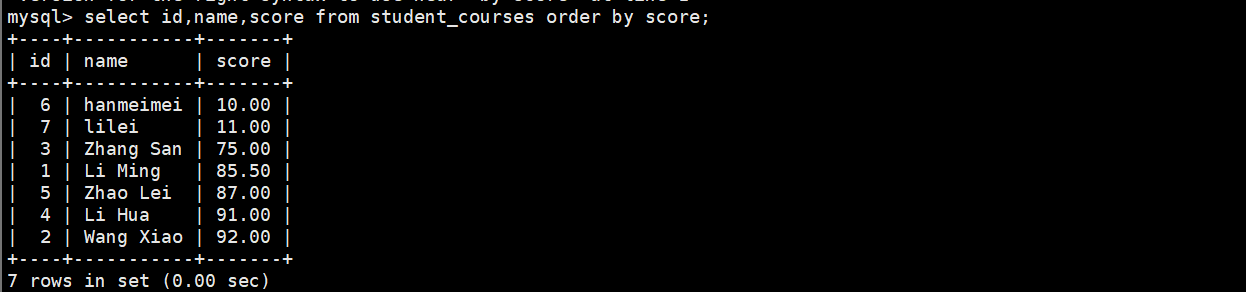
(2)按分数降序查询(DESC)
select id,name,score from student_courses order by score desc;
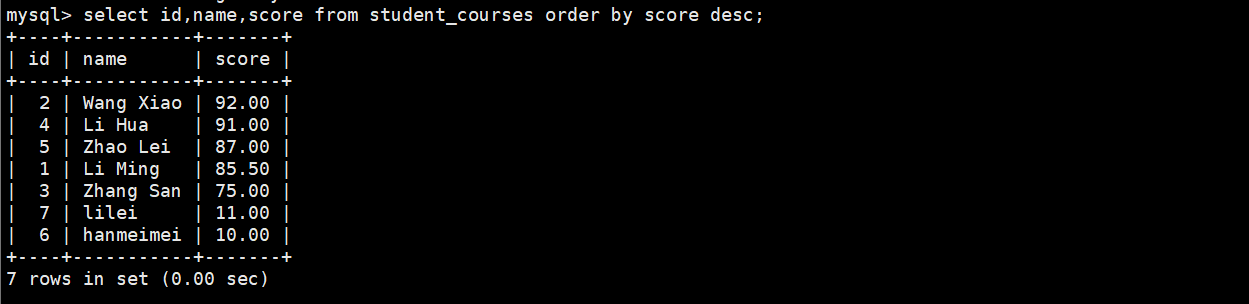
(3)使用where进行条件查询
过滤出南京并且按降序查询
select id,name,score from student_courses where address='nanjing' order by score desc;

(4)使用ORDER BY语句对多个字段排序
ORDER BY 语句可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,ORDER BY 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定,但是order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义
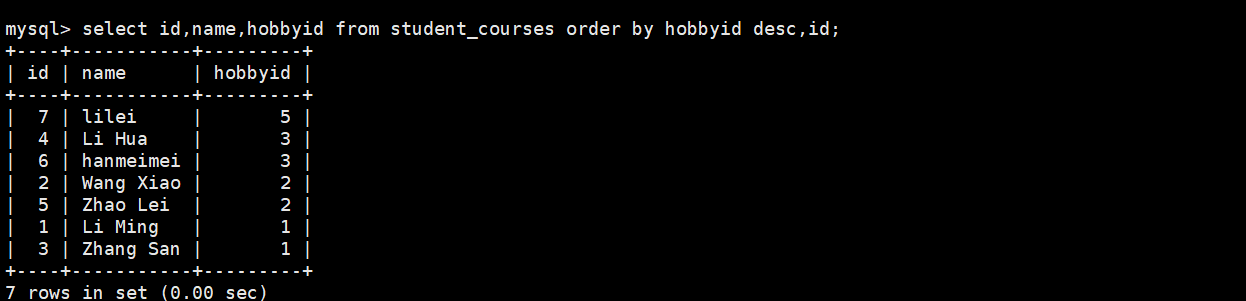
1.查询学生信息先按兴趣id降序排列,相同分数的,id按降序排列
select id,name,hobbyid from student_courses order by hobbyid desc,ind desc
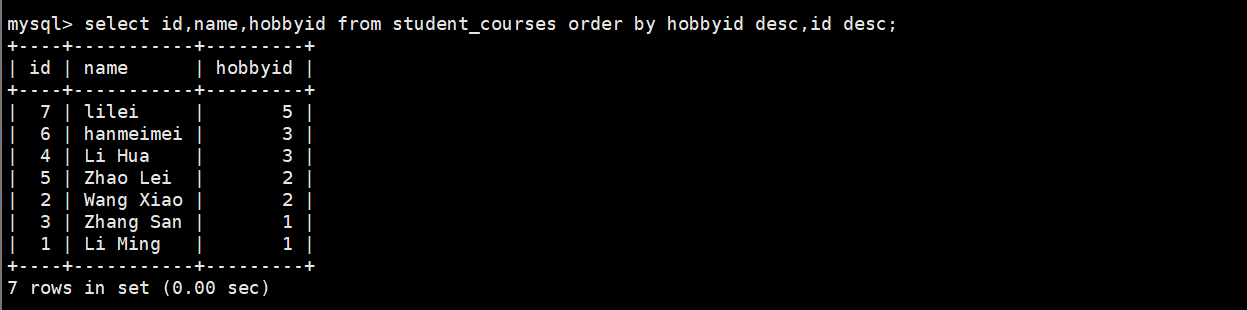
2.查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
select id,name,hobbyid from student_courses order by hobbyid desc,id;
1.2使用区间判断查询(and/or 且和或)
(1)and
select * from student_courses where score >80 and score <=90;

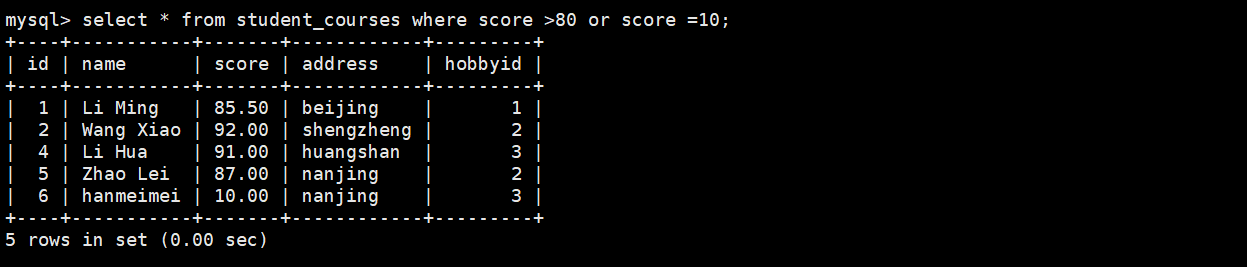
(2)or
select * from student_courses where score >80 or score =10;
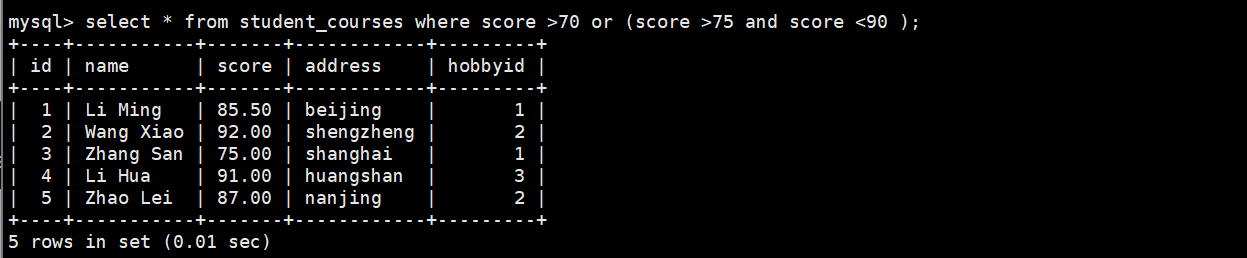
(3)嵌套多个条件
select * from student_courses where score >70 or (score >75 and score <90 );
(4)distinct 查询不重复记录
select distinct hobbyid from student_courses;

1.3对查询结果进行分组
SQL 查询出来的结果,可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
(1)count
统计hobbyid相同的分组,计算相同hobbyid的个数
select count(name),hobbyid from student_courses group by hobbyid;

结合where语句,筛选分数大于等于80的分组,计算有几个学生
select count(name),hobbyid from student_courses where score >=80 group by hobbyid;

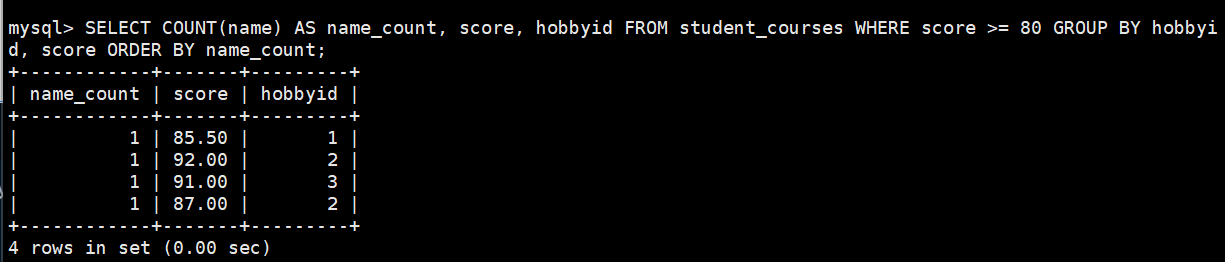
结合order by把计算出的学生个数按升序排列
SELECT COUNT(name) AS name_count, score, hobbyid
FROM student_courses
WHERE score >= 80
GROUP BY hobbyid,score
ORDER BY name_count;
1.4限制结果条目(limit重要)
limit 限制输出的结果记录
使用MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,此刻就需要用到 LIMIT 子句
(1)查询所有信息只显示前2行记录
select * from student_courses limit 2;

(2)查询所有信息只显示从第4行开始,往后的2行内容
select * from student_courses limit 4,2;

(2)结合order by语句,查询id的大小升序排列显示前2行
select id,name from student_courses order by id desc limit 2;

(3)查询信息只显示最后3行按降序显示出来(重要)
select id,name from student_courses order by id desc limit 3;

(4)查询并显示出第一行开始的后两行
SELECT * FROM student_courses LIMIT 2 OFFSET 1;

1.5设置别名
别名的作用和特点
简化查询语句:当表名或列名较长时,使用别名可以减少代码长度,使查询语句更简洁、易于书写和维护。
增强可读性:通过使用别名,尤其是在涉及多个表的复杂查询中,能够使查询语句更加清晰直观,便于理解。
临时性:别名仅在当前查询中有效,它不会改变数据库中实际的表名或列名。换句话说,别名是查询语句执行过程中的临时名称,用于替代表或列的原始名称。
列的别名:使用AS关键字为列设置别名。别名可以是任何合法的标识符,并且可以用于后续的查询中。
别名使用场景:
1.对复杂的表进行查询的时候,别名可以缩短查询语句的长度
2.多表相连查询的时候(通俗易懂、减短sql语句)
3.可以作为连接语句的操作符,可以将一个表的查询的结果插入新表中
格式
对于列的别名:SELECT column_name AS alias_name FROM table_name;
对于表的别名:SELECT column_name(s) FROM table_name AS alias_name;
(1)统计表内的字段有多少个,以数字形式显示(不加as也可以)

或
select count(*) as 总行数 from student_courses;

(2)将查询出的结果插入新表中
AS作用
1、创建了一个新表t1 并定义表结构,插入表数据(与info表相同)
2、但是”约束“没有被完全”复制“过来 #但是如果原表设置了主键,那么附表的:default字段会默认设置一个0
类似复制克隆
别名注意事项
1.在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突。
2.列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。
create table cheshi01 as select * from student_courses;
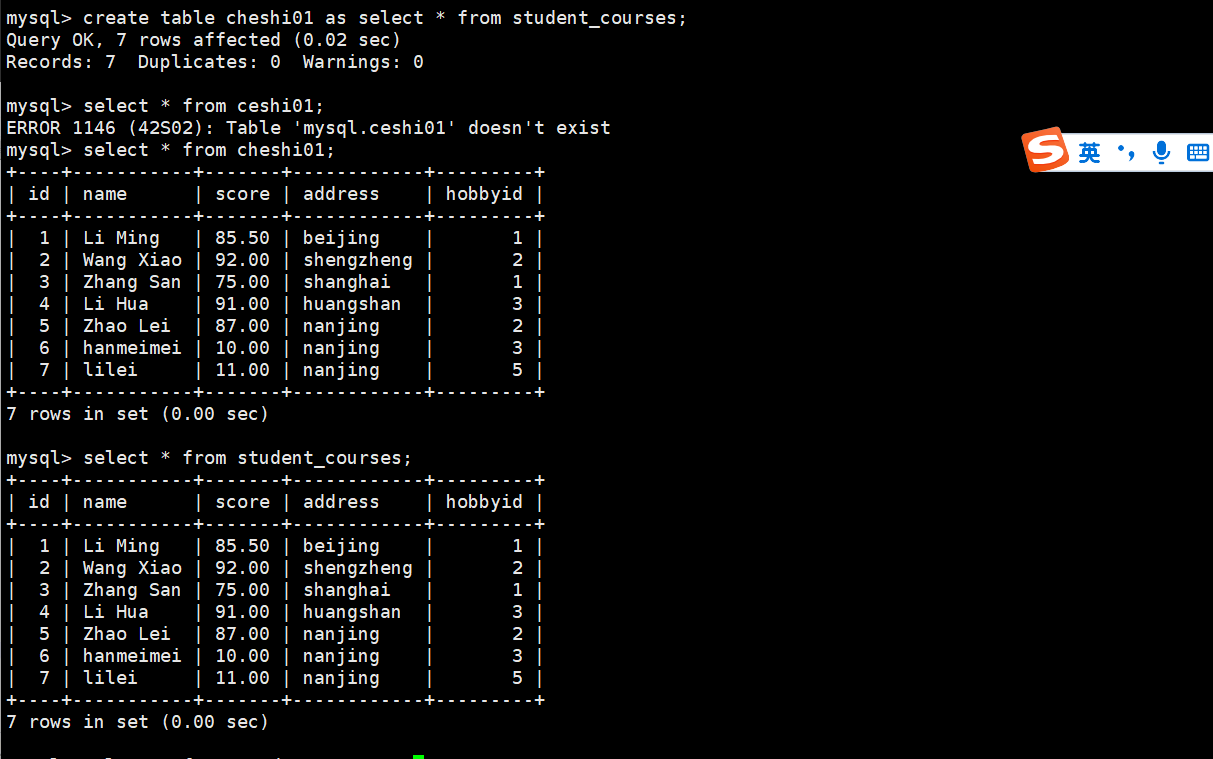
或
create table cheshi02 select * from student_courses;
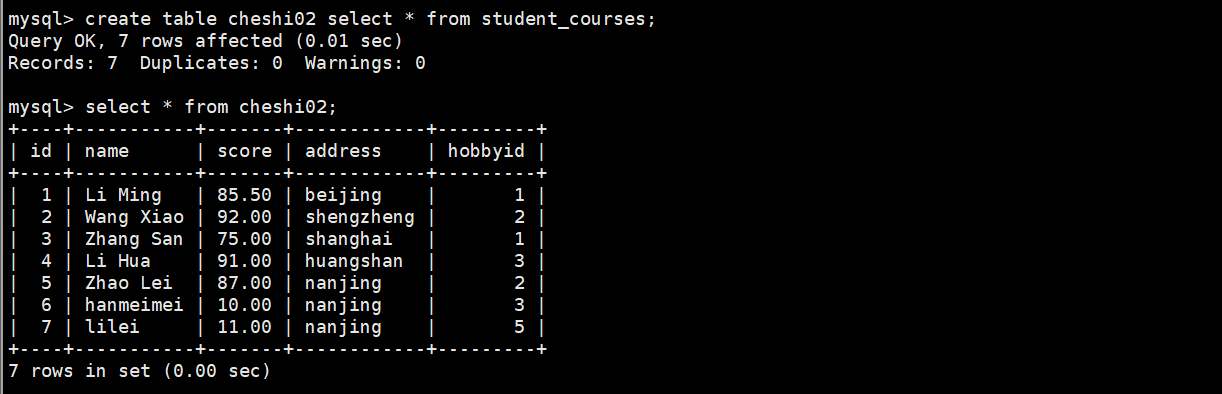
或
create table cheshi03 as select * from student_courses where score >=70;
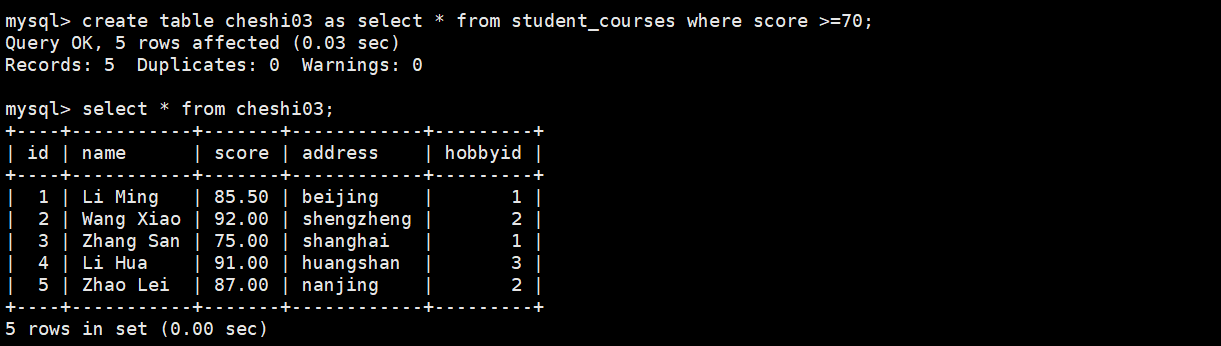 as创建了一个新表并定义表结构,插入表数据(与student_courses表相同)
as创建了一个新表并定义表结构,插入表数据(与student_courses表相同)
但是”约束“没有被完全”复制“过来
如果原表设置了主键,附表的default字段会默认设置一个0
(3)使用别名查询
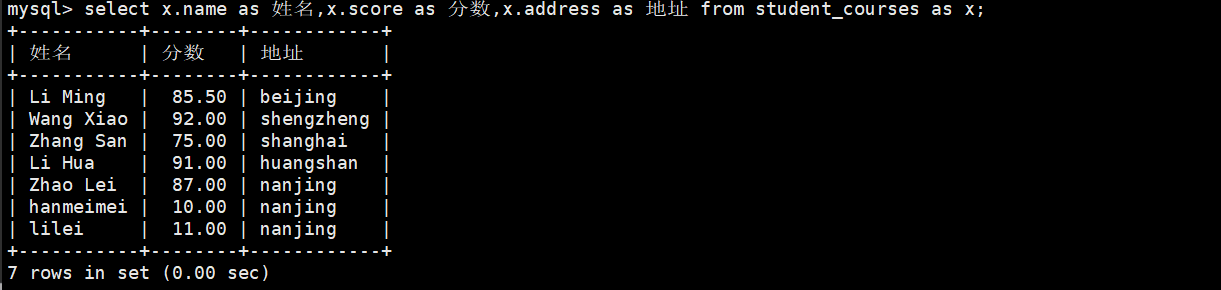
select name as 姓名,score as 分数,address as 地址 from student_courses;()
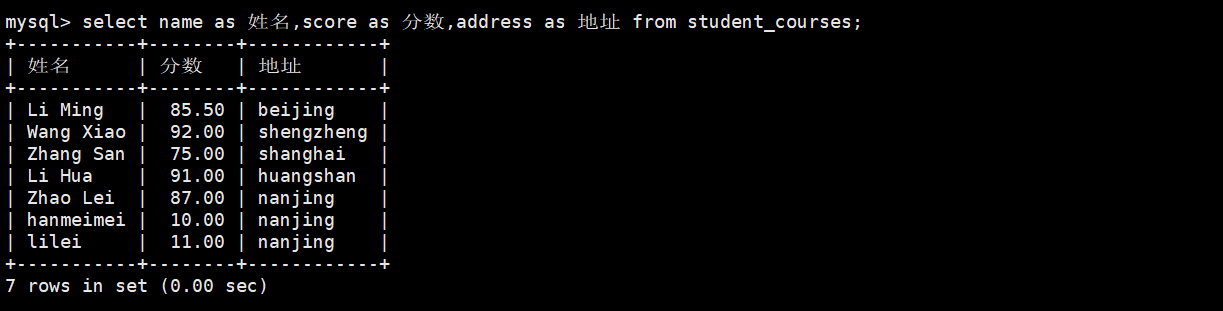
或
select x.name as 姓名,x.score as 分数,x.address as 地址 from student_courses as x;
1.6通配符
通配符主用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通配符通常都是与LIKE使用的,并协同 WHERE 子句共同来完成查询任务。
常用的通配符(重要)
% 百分号表示零个,一个或多个字符
_ 下划线表示单个字符
(1)查询c开头的
select id,name from student_courses where name like 'z%';

(2)查询l开头和i结尾的
select id,name from student_courses where name like 'l___i';

(3)查询中间是g的
select id,name from student_courses where name like '%n%';

(4) 查询以o结尾的
select id,name from student_courses where name like '%o';

(5)查询以h开头其中间有e的
select id,name from student_courses where name like 'h%e%';

1.7子查询(内查询)
- 子查询也叫作内查询或嵌套查询, 是指在一个 SQL 查询中嵌入另一个查询。
- 子查询的执行顺序是:首先执行子查询,然后将其结果提供给外层查询(主查询)使用。
- 子查询的主要作用是为主查询提供过滤条件或中间结果,用于进一步的数据处理。
- 子查询和主查询可以作用于同一个表也可以查询不同的表。
- 子查询可以在 SELECT 、INERT、UPDATE、DELETE语句中使用。在嵌套的时候,子查询内部还可以再次嵌套新的子查询,可以多层嵌套。
格式
select id,name,score from 表名1 where id in (select id from 表名2);
IN 用来判断某个值是否在给定的结果集中,通常结合子查询来使用
SQL 中子查询的使用场景
- 当一个表达式与子查询返回的结果集中的某个值匹配时,会返回
TRUE,否则返回FALSE。 - 如果使用了
NOT关键字,则结果会相反:不匹配时返回TRUE,匹配时返回FALSE。 - 注意子查询只能返回单列数据,如果查询需求较为复杂,单列结果无法满足时,可以通过多层嵌套的子查询来处理。
- 大多数情况下,子查询通常与
SELECT语句一起使用,用于从数据库中提取特定的数据。
(1)单表查询
查询表里大于90的
select name,score from info where id in (select id from info where score >90);

(2)多表查询
查询表里大于80的
select name,score from info where id in (select id from student_courses where score >80);

(3)update
update语句可以使用子查询,update里面的子查询,在set更新内容时,可以是单独的一列也可以是多列
将表内某某成绩改成50
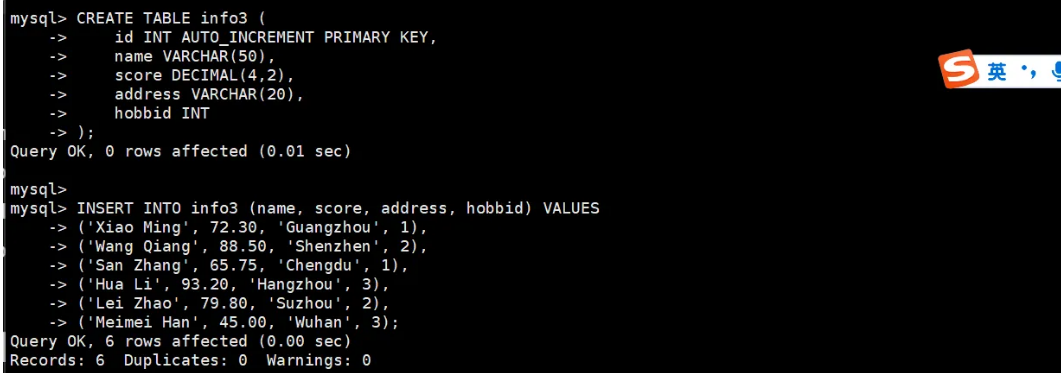
CREATE TABLE info3 (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50),score DECIMAL(4,2),address VARCHAR(20),hobbid INT
);INSERT INTO info3 (name, score, address, hobbid) VALUES
('Xiao Ming', 72.30, 'Guangzhou', 1),
('Wang Qiang', 88.50, 'Shenzhen', 2),
('San Zhang', 65.75, 'Chengdu', 1),
('Hua Li', 93.20, 'Hangzhou', 3),
('Lei Zhao', 79.80, 'Suzhou', 2),
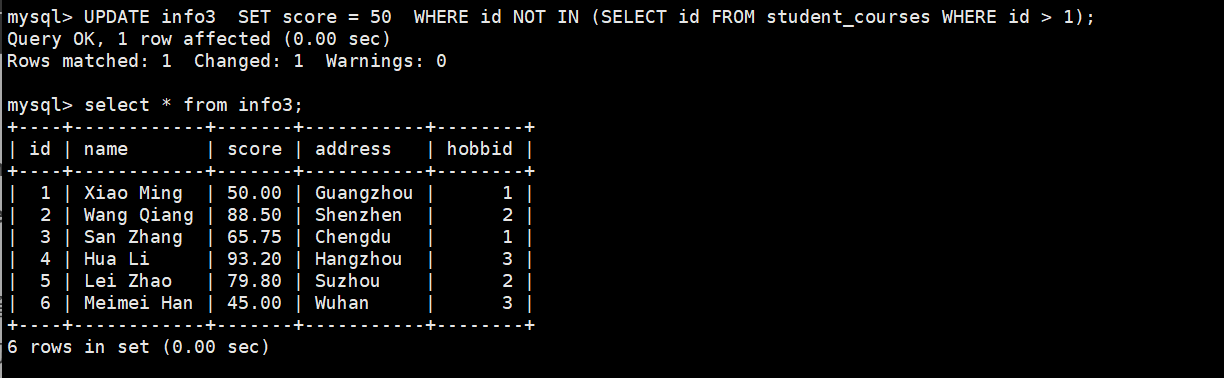
('Meimei Han', 45.00, 'Wuhan', 3);UPDATE info3
SET score = 50
WHERE id IN (SELECT id FROM student_courses WHERE id = 1);
(4)delete
删除大于70的
delete from info3 where id in (select id where score > 70);

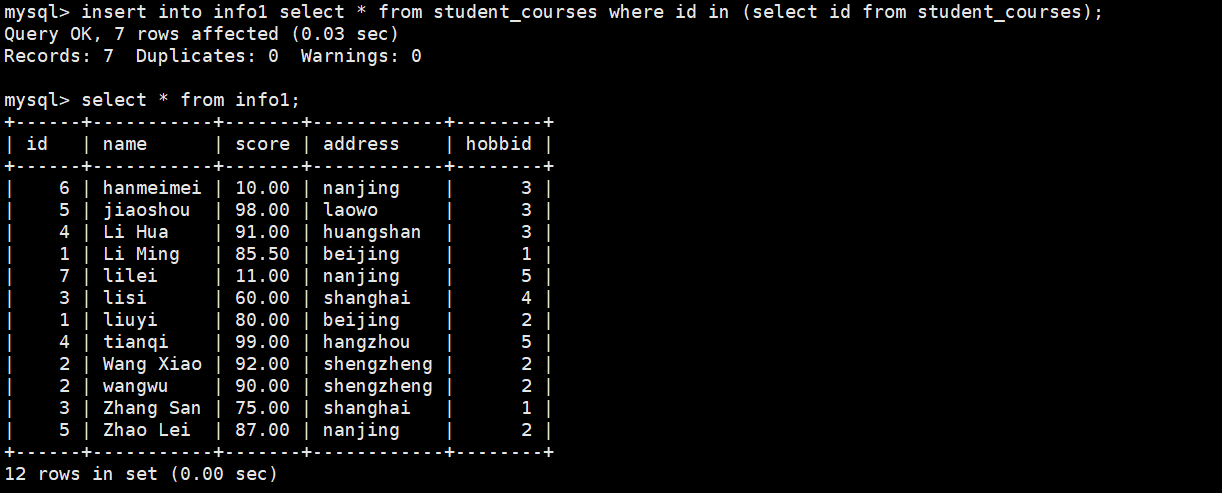
(5)insert
插入子查询查出来的数据
insert into info1 select * from student_courses where id in (select id from sudent_courses);
(6)NOT
在 IN 前面可以添加 NOT,其作用与IN相反,表示否定(即不在子查询的结果集里面)删除分数没有大于等于70的记录同表删除
delete from info3 where id not in (select id where score >= 70)

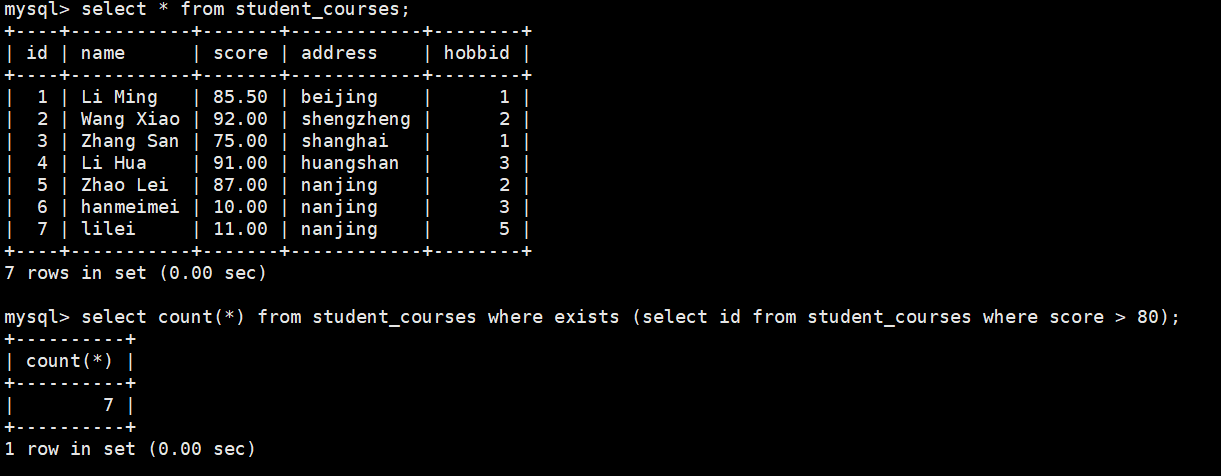
(7)EXISTS
EXISTS 关键字在子查询时,主要用于判断子查询的结果集是否为空。如果不为空, 则返回 TRUE;反之,则返回 FALSE
1.查询如果存在分数大于80的记录则计算表的字段数,存在大于80的就显示没有就不显示
select count(*) from student_courses where exists (select id from student_courses where score > 80);
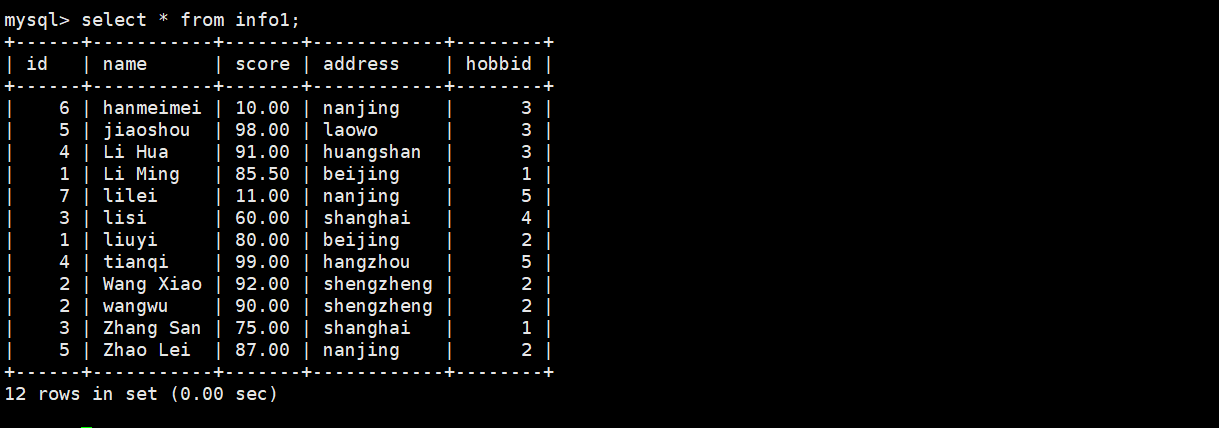
2.查询如果存在分数小等于90的记录则计算info的字段数,info表没有小于50的,所以返回0
条件为真查询条件为假不显示
select count(*) from info1 where existsz(select id from info1 where score < 10);

(8)别名as
将结果集做为一张表进行查询的时候,需要用到别名
例:需求:从info表中的id和name字段的内容做为"内容" 输出id的部分
select name from (select id,name from info1);
select name from (select id,name from info1) a;
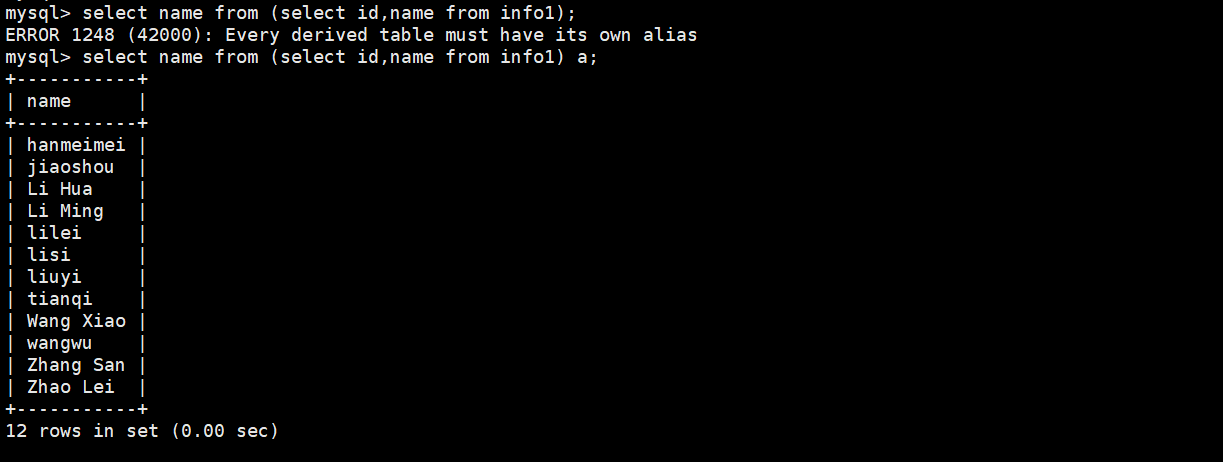
报错的原因:select * from 表名为标准格式,上面的查询语句,“表名"的位置是一个完整结果集,mysql并不能直接识别,而此时给与结果集设置一个别名,以”select a.id from a“的方式查询将此结果集视为一张"表”,就可以正常查询数据了,
二,SQL视图
1.什么是视图?
视图是 MySQL 中的一种虚拟表,它并不直接存储数据,而是基于实际的基础表进行查询的结果集。视图的作用是将查询的结果集作为表一样进行操作,但它并不占用物理空间。视图可以用于简化复杂查询、增强安全性和权限控制。
2.视图的作用
- 简化复杂查询:通过视图,可以将复杂的 SQL 查询封装起来,简化后续的操作。
- 安全性:可以限制用户只访问特定的数据列或行,而无需访问整个表,保护数据安全。
- 灵活性:不同用户或角色可以通过视图看到不同的数据集,而不需要修改基础表。
- 只读操作:视图适合用于浏览和查询操作,不推荐用于增、删、改操作。
3.视图的使用场景
- 不同角色权限管理:通过视图为不同的用户角色(如管理员、普通用户)提供不同的结果集。
- 数据聚合与筛选:可以通过视图将多个表连接后的结果集呈现为单个表。
4.视图与表的区别
- 视图没有实际的物理数据,它只是基础表数据的映射;而表是物理存储的数据结构。
- 视图是已经编译好的 SQL 查询,它是查询结果的动态展示;表则是真实存储数据的对象。
- 视图不占用物理存储空间,而表占用实际的存储空间。
- 视图的创建与删除不影响基础表,但视图的内容来自基础表,更新视图时,基础表的数据也会被更新。
- 视图是逻辑层的抽象,提供了一种灵活的方式查看基础表中的数据。
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
- 表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
5.注意事项
- 视图适用于多表查询和复杂 SQL 查询的封装,但不适用于频繁的增、删、改操作。
- 视图对性能的影响:虽然视图可以简化查询,但每次使用视图时,数据库都要重新执行视图的 SQL 查询,可能会影响性能,尤其是视图涉及多表连接时。
- 视图的更新限制:不是所有的视图都可以被更新,只有符合特定条件的视图(如基于单个表)才允许执行
UPDATE、DELETE操作。
6.视图操作
(1)创建视图单表操作
将大于等于80分的数据展示出来
create view v_score as aelect * from info1 where score >=80;
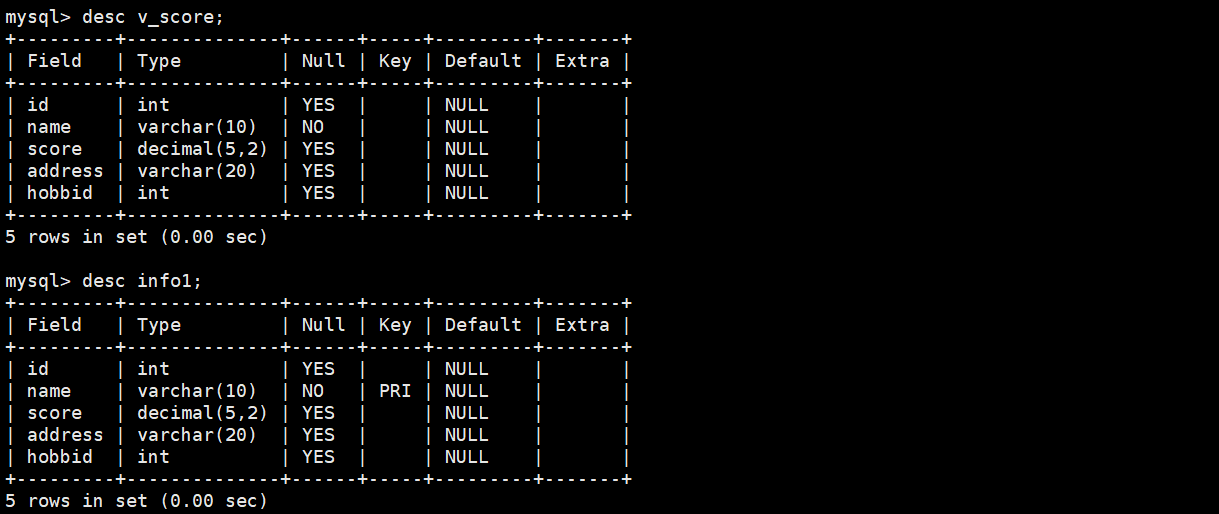
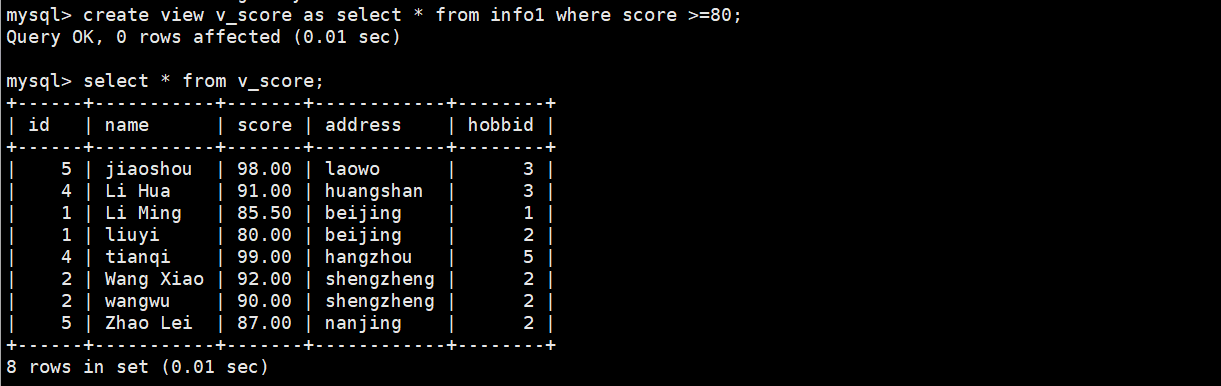 查看视图和原表结构,一模一样
查看视图和原表结构,一模一样
修改jiaoshou成绩为50 ,后查看表info1
update info1 set score=50 where='jiaoshou';
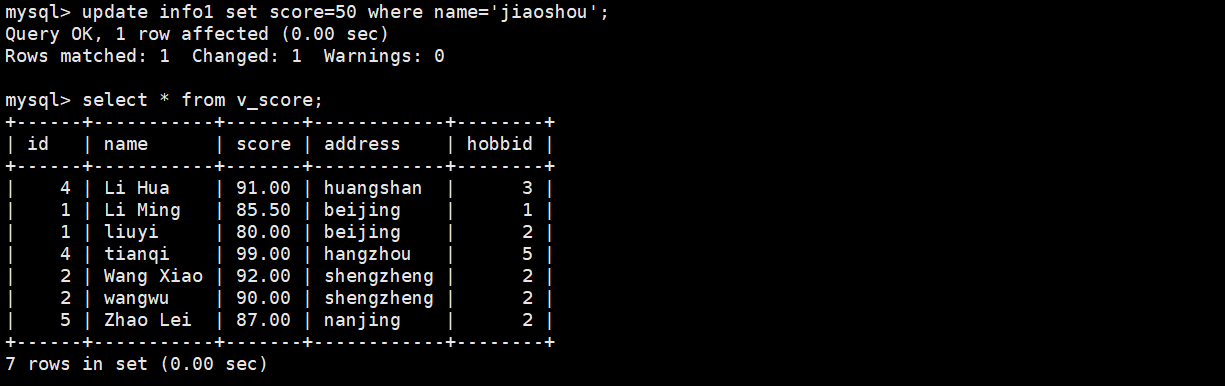
视图里面没有了jiaoshou这个名字,因为成绩是50而视图里面是大于等于80的,所以视图里面没jisodhou
满足视图的要求,会在视图更新,不满足不显示
(2)多表视图创建
创建一个视图,需要输出id、学生姓名、分数以及年龄
create view v_info3 (id,name,score,age) as select info3.id,info3.name,info3.score,t02.age from info3,t022 where info3.name=t02.name;
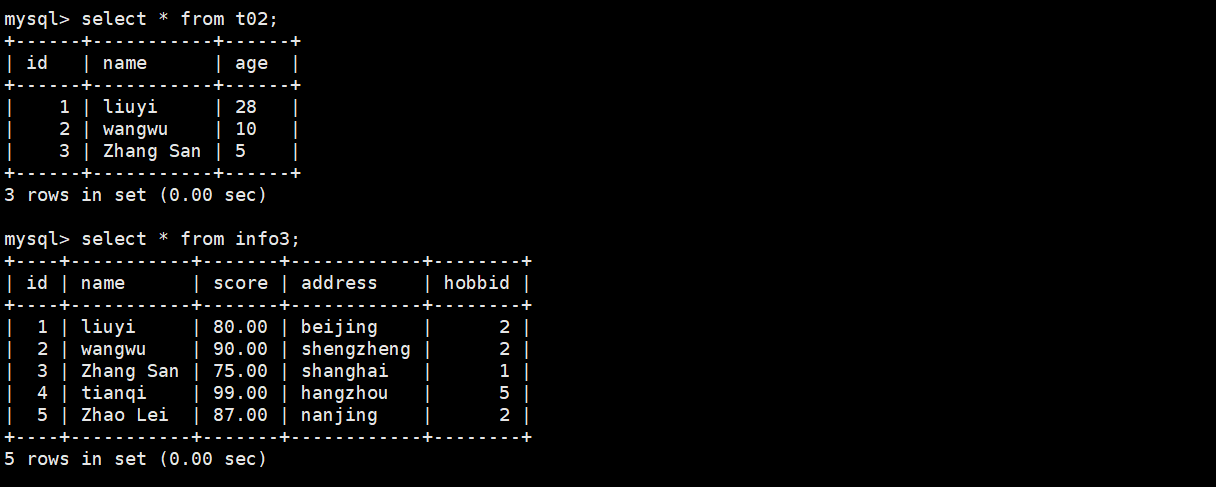
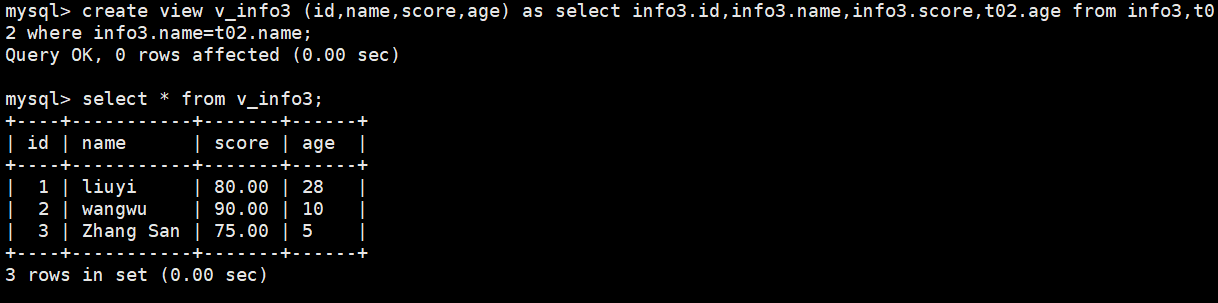
(3)null值
在 SQL 中,NULL 是一个特殊的标记,用于表示数据缺失或未知的值。
当一个字段的值是 NULL 时,表示没有值,而不是一个空字符串或零。
使用 NULL 可以帮助我们处理不完整的数据或未知的数据输入。
在创建表时,限制某些字段不为空 not null
空值长度为0,不占空间,NULL值的长度为null(字符串占空间),占用空间,is null无法判断空值
a.空值(空字符串)的处理
可以使用 =、<> 或 != 运算符来判断或处理空值
null的三种值

(1)插入一条记录,分数字段输入null,显示出来就是null
alter table info3 add addr varchar(60);
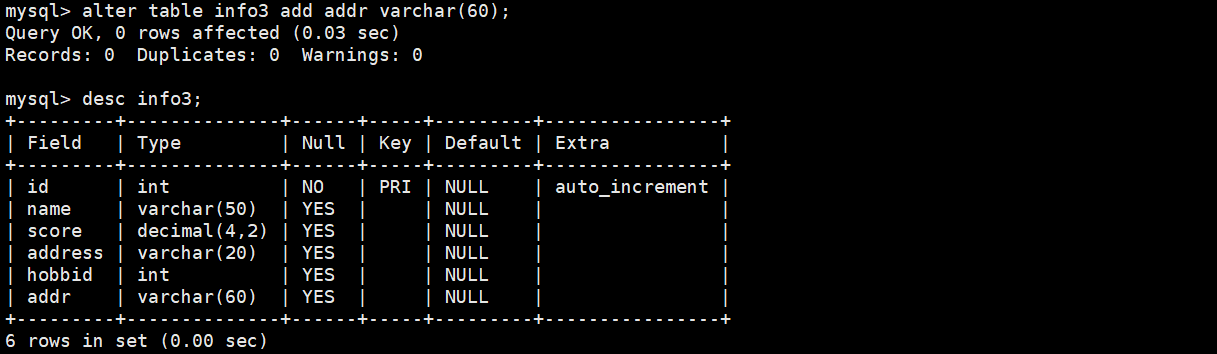
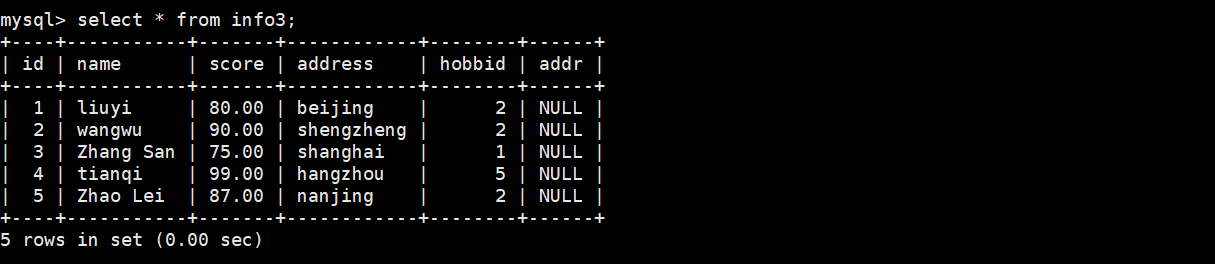
(2)把表里的字段修改后符合要求的显示出来
update info3 set name'shengzheng' where score >=80;
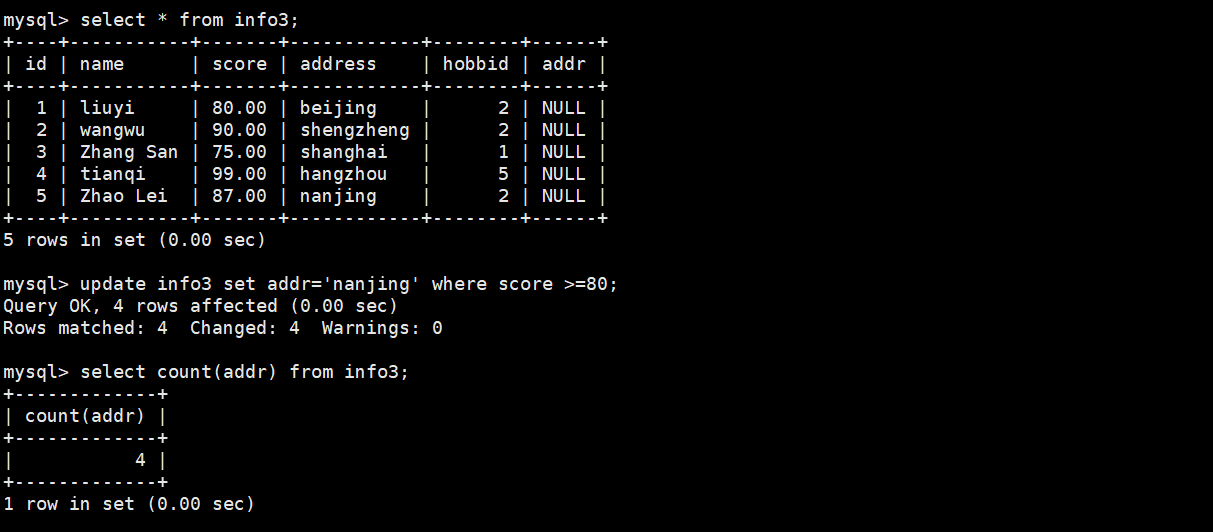
update info3 set addr='nanjing' where score <=90;
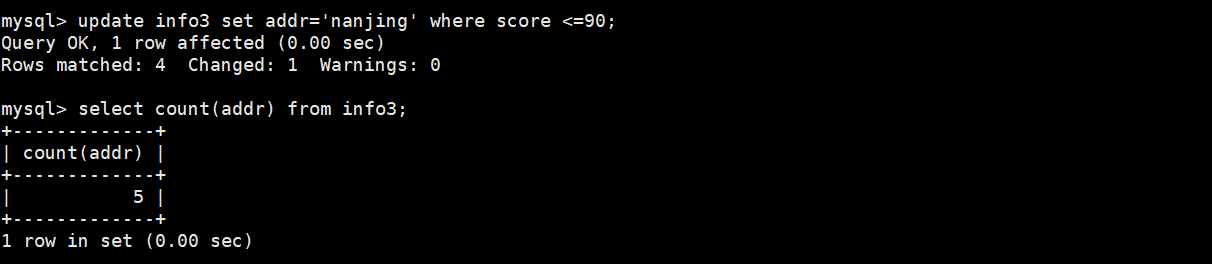
(3)将表里addr改成南京,只要是分数大于等于90的
update info3 set addr='nanjing' where score >=90;
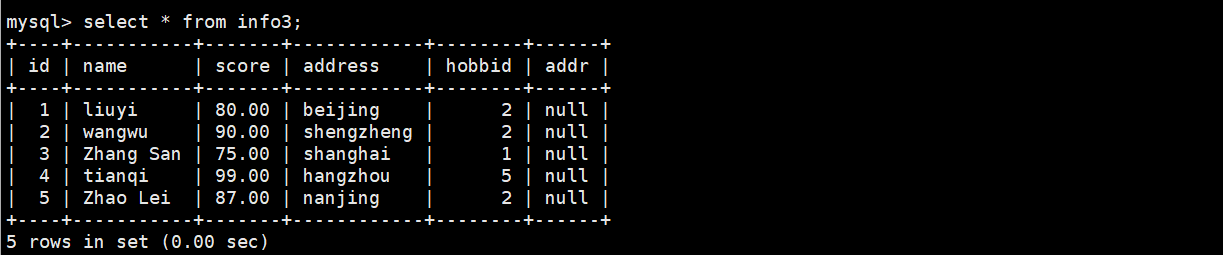
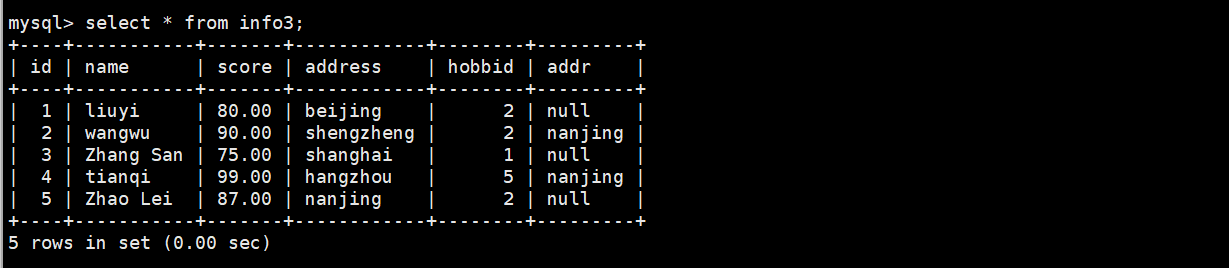

(4)将表里addr是null的显示出来
select * from info3 where addr is null;

(5)将表里addr不是null的显示出来
select * from info3 where is not null;

三,连接查询(重要)
- 在 MySQL 中,连接查询(JOIN)用于将来自两个或多个表的记录组合在一起,基于这些表之间的共同字段。
- 执行 SQL 连接查询时,通常需要指定一个主表(或基表),并将其他表的记录行有选择性地连接到这个主表的结果集上。主表的选择通常取决于查询的业务逻辑和数据需求。选择主表时,通常会选择那个包含核心数据或关系字段的表。
- 连接查询的主要类型包括内连接(INNER JOIN)、左连接(LEFT JOIN)、和右连接(RIGHT JOIN)
创建一个表
create table test11 (
c_id int(11) default null,
c_name varchar(32) default null,
c_level int(11) default null);create table test12 (
d_id int(11) default null,
d_name varchar(32) default null,
d_level int(11) default null);insert into test11 values (1,'aaaa',10);
insert into test11 values (2,'bbbb',20);
insert into test11 values (3,'cccc',30);
insert into test11 values (4,'dddd',40);insert into test12 values (2,'bbbb',20);
insert into test12 values (3,'cccc',30);
insert into test12 values (5,'eeee',50);
insert into test12 values (6,'ffff',60);3.1内连接
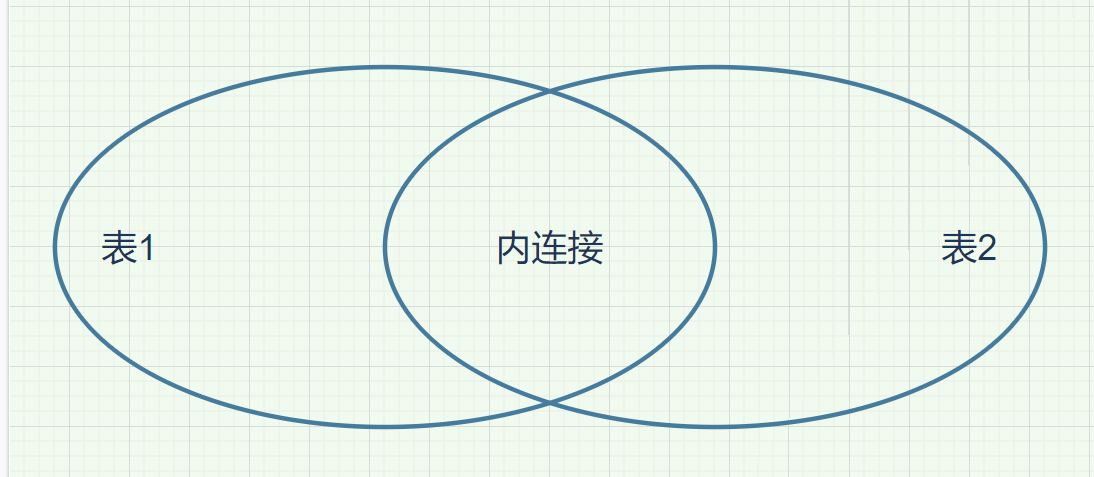
在 MySQL 中,内连接(INNER JOIN) 是用于组合两个或多个表中符合某个条件的记录的操作。内连接只返回在所有连接的表中匹配的行。INNER JOIN 是连接的默认类型,因此在 FROM 子句中,可以省略 INNER 关键字,直接使用 JOIN 关键字。 不超过三个表为好,超过三个需要优化了
格式
SELECT column_name(s)FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
select * from test11 inner join test12 on test11.c_id = test12.d_id;


3.2左连接
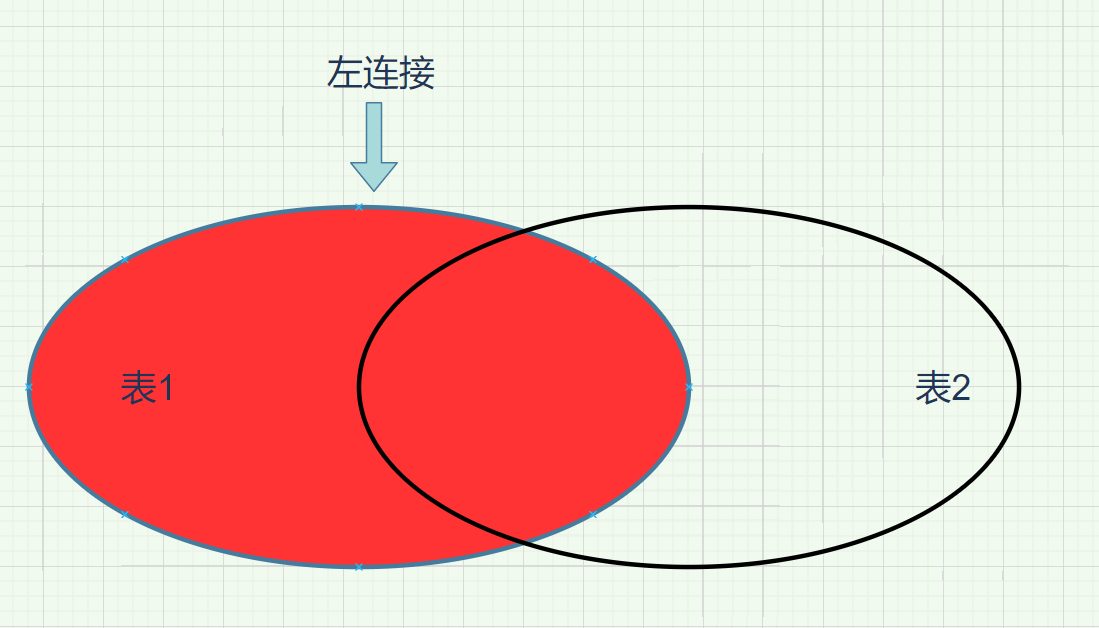
左连接
将两张表的内容进行匹配,按照sql查询的顺序从左至右,输出左表的全部内容和右表的重叠(相同,相等)的数据内容,其他都是nulll
select * from test11 left join on test12 on test11.c_name=test12.d_name;

3.3右连接
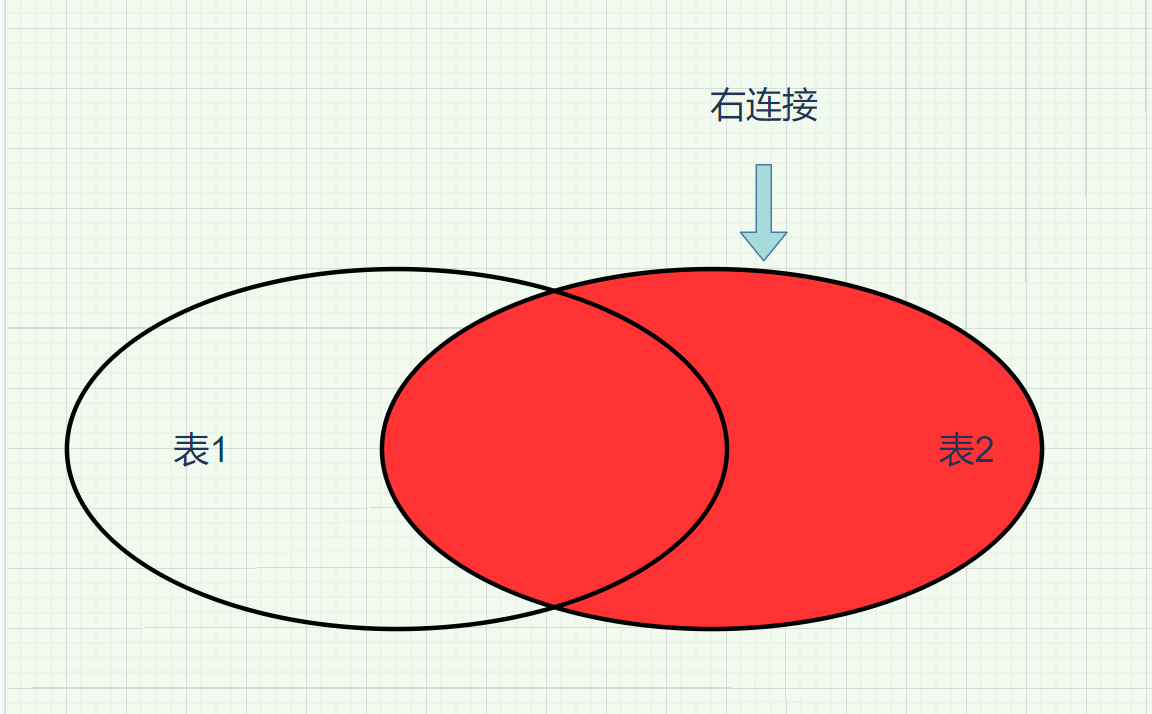 右连接
右连接
将两张表的内容进行匹配,按照sql查询的顺序从右至左,输出右表的全部内容和左表的重叠(相同,相等)的数据内容,其他都是nulll
select * from test12 right join test11 on test12.d_name=test11.c_name;

四,存储过程
1.什么是存储过程
在数据库应用中,简单的查询或数据操作通常可以通过单条 SQL 语句完成。然而,面对复杂的业务需求时,往往需要多条 SQL 语句联合执行才能实现。而存储过程提供了一种解决方案,它允许将一组相关的 SQL 语句封装为一个预定义的程序,并存储在数据库中,供以后反复调用。类似于编程语言中的函数,存储过程可以简化复杂操作,提高执行效率,减少开发中的重复性工作。通过存储过程,用户可以轻松地实现复杂的逻辑处理,同时减少网络开销和编译时间,提高数据库操作的整体性能。
2.存储过程简介
2.1 存储过程是一组为了完成特定任务而编写的 SQL 语句的集合,它能够将多条 SQL 语句封装在一个逻辑单元内,通过调用存储过程来执行这些语句。存储过程可以包含复杂的操作,如条件判断、循环以及事务处理。
存储过程的两个点
- 触发器(定时任务):触发器是数据库中的一种机制,它在特定事件(如插入、更新或删除操作)发生时自动执行相关的SQL操作。定时任务则可以按预定的时间间隔自动执行存储过程或其他操作,帮助自动化数据维护和处理。
- 判断:存储过程内部可以包含条件判断语句(如
IF、CASE)和循环控制语句,用于根据不同的业务逻辑和条件执行不同的操作,使得存储过程更加灵活和智能。
2.2MySQL 从 5.0 版本开始支持存储过程,这使得数据库能够更灵活地处理复杂的业务逻辑。存储过程经过预编译并存储在数据库服务器中,调用时无需再次编译,这大大提高了执行速度。同时,它减少了客户端和服务器之间的数据传输,从而提高了系统的效率。存储过程尤其适合处理频繁的操作、复杂的业务逻辑和批量数据处理场景。
访问select,假设访问超过了100万就会触发存储过程
存储过程在数据库中 创建并保存,它不仅仅是 SQ语句的集合,还可以加入一些特殊的控制结构,也可以控制数据的访问方式。存储过程的应用范围很广,例如封装特定的功能、 在不同的应用程序或平台上执行相同的函数等等。
2.3存储的优点
- 提高执行效率:存储过程在第一次执行时会被编译成二进制代码并存储在服务器的缓冲区中,后续调用时无需再次编译,提升了执行速度。
- 灵活性高:存储过程将SQL语句与控制语句结合,支持条件判断、循环等逻辑操作,能够灵活应对复杂的业务需求。
- 降低网络负载:存储过程存储在服务器端,客户端只需调用,无需频繁发送复杂的SQL语句,减少了客户端与服务器之间的网络传输量。
- 可重用性强:存储过程可以多次重复调用,且修改存储过程不会影响客户端的调用逻辑,方便维护和升级。
- 安全性与权限控制:存储过程能够执行所有的数据库操作,且可以通过定义权限来控制对敏感数据的访问,增强了数据库的安全性。
语法格式
CREATE PROCEDURE <过程名> ( [过程参数[,…] ] ) <过程体>
[过程参数[,…] ] 格式
<过程名>:尽量避免与内置的函数或字段重名
<过程体>:语句
[ IN | OUT | INOUT ] <参数名><类型>
(1)创建存储过程(不加参数)
DELIMITER $$ #将语句的结束符号从分号;临时改为两个$$(可以自定义)
CREATE PROCEDURE Proc() #创建存储过程,过程名为Proc,不带参数
-> BEGIN #过程体以关键字 BEGIN 开始
-> create table mk (id int (10), name char(10),score int (10));
-> insert into mk values (1, 'wang',13);
-> select * from mk; #过程体语句
-> END $$ #过程体以关键字 END 结束
DELIMITER ; #将语句的结束符号恢复为分号
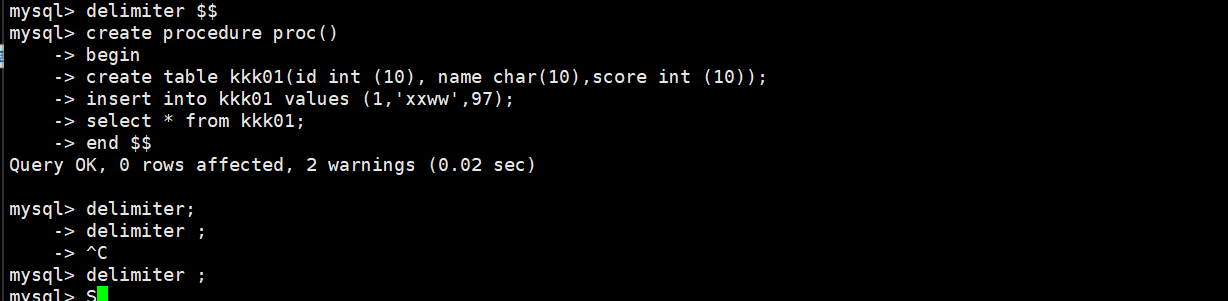
(2)调用存储过程
CALL Proc();
-
存储过程的主体被称为过程体
存储过程的主体部分包含所有的SQL语句和控制逻辑,用来执行特定的任务。 -
以
BEGIN开始,以END结束
如果存储过程包含多条 SQL 语句,必须用BEGIN和END来封装这些语句。
如果存储过程只包含一条 SQL 语句,则可以省略BEGIN和END。 -
以
DELIMITER开始和结束
在 MySQL 中,默认的 SQL 语句结束符是分号(;)。为了定义存储过程(尤其是包含多条 SQL 语句的过程),需要更改结束符,因为存储过程的定义中会使用分号作为 SQL 语句的结尾。
(3)查看存储过程
格式
SHOW CREATE PROCEDURE [数据库.]存储过程名; #查看某个存储过程的具体信息show create procedure proc\G
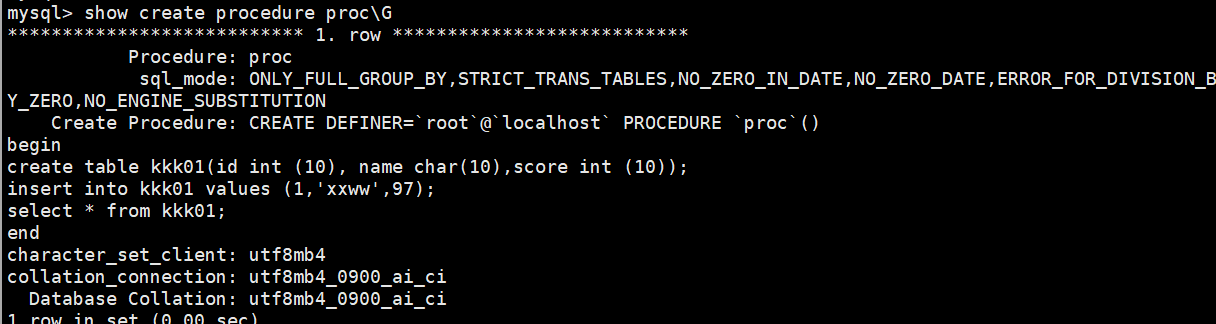
查看
查看存储过程
SHOW PROCEDURE STATUS #查看指定存储过程信息
mysql> SHOW PROCEDURE STATUS like '%proc%'\G
(4)存储过程参数
IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
表示调用者向过程传入值,又表示过程向调用者传出值(只能是变量)
DELIMITER @@
CREATE PROCEDURE proc_new (IN inname VARCHAR(70)) #行参BEGIN SELECT * FROM kkk01 WHERE name = inname; END @@mysql> DELIMITER ;call proc () #实参


(5)修改存储过程
格式
ALTER PROCEDURE <过程名>[<特征>... ]
ALTER PROCEDURE GetRole MODIFIES SQL DATA SQL SECURITY INVOKER;
MODIFIES SQLDATA:表明子程序包含写数据的语句
SECURITY:安全等级
invoker:当定义为INVOKER时,只要执行者有执行权限,就可以成功执行。
(6)删除存储过程
存储过程内容的最好修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
相关文章:
mysql高级sql
文章目录 一,查询1.按关键字排序1.1按关键字排序操作(1)按分数排序查询(不加asc默认为升序)(2)按分数降序查询(DESC)(3)使用where进行条件查询(4)使用ORDER BY语句对多个字段排序 1.2使用区间判断查询(and/…...

Linux CentOS 7.9 安装mysql8
1、新建mysql文件夹 数据比较大,所以我在服务器另外挂了一个盘装mysql,和默认安装一个道理,换路径即可 cd ../ //创建文件夹 mkdir mysql //进入mysql文件夹 cd mysql 2、下载mysql8.0安装包并解压、重命名 //下载安装包 wget https://dev…...

替代 Django 默认 User 模型并使用 `django-mysql` 添加数据库备注20240904
替代 Django 默认 User 模型并使用 django-mysql 添加数据库备注 前言 在 Django 项目开发中,默认的 User 模型虽然能够满足许多基础需求,但在实际项目中我们常常需要对用户模型进行定制化。通过覆盖默认的 User 模型,我们可以根据具体的业…...

三维激光扫描点云配准外业棋盘的布设与棋盘坐标测量
文章目录 一、棋盘标定板准备二、棋盘标定板布设三、棋盘标定板坐标测量一、棋盘标定板准备 三维激光扫描棋盘是用来校准和校正激光扫描仪的重要工具,主要用于提高扫描精度。棋盘标定板通常具有以下特点: 高对比度图案:通常是黑白相间的棋盘格,便于识别。已知尺寸:每个格…...

【Python知识宝库】文件操作:读写文件的最佳实践
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 文章目录 前言一、文件读取1. 使用open函数2. 逐行读取3. 使用readlines和readline 二、文件写入1. 写入文本2. 追加内容3. 写入…...
Chapter 13 普通组件的注册使用
欢迎大家订阅【Vue2Vue3】入门到实践 专栏,开启你的 Vue 学习之旅! 文章目录 前言一、组件创建二、局部注册三、全局注册 前言 在 Vue.js 中,组件是构建应用程序的基本单元。本章详细讲解了注册和使用 Vue 的普通组件的两种方式:…...

u盘显示需要格式化才能用预警下的数据拯救恢复指南
U盘困境:需要格式化的紧急应对 在数字信息爆炸的时代,U盘作为便携的数据存储介质,承载着我们工作、学习乃至生活中的大量重要资料。然而,当U盘突然弹出“需要格式化才能用”的提示时,这份便捷瞬间转化为焦虑与不安。这…...
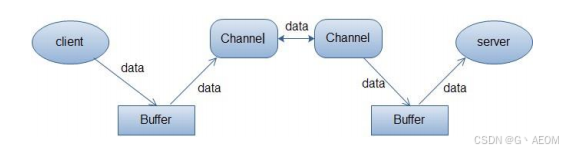
还不懂BIO,NIO,AIO吗
BIO(Blocking I/O)、NIO(Non-blocking I/O)和 AIO(Asynchronous I/O)是 Java 中三种不同的 I/O 模型,主要用于处理输入 / 输出操作。 一、BIO(Blocking I/O) 定义与工作原…...
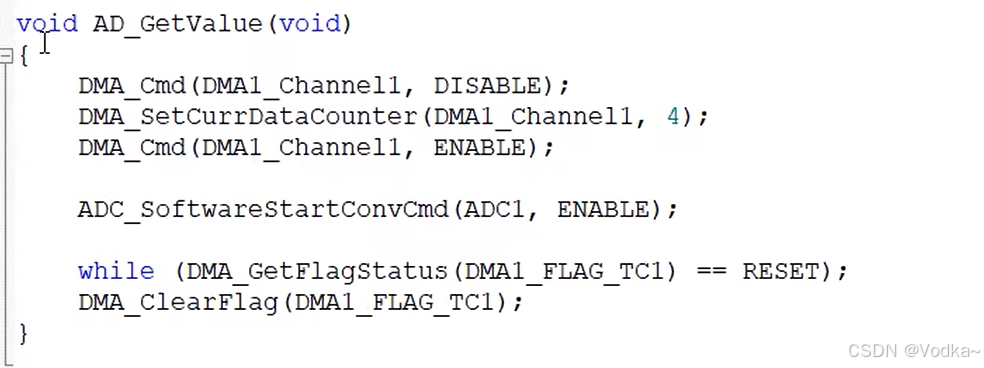
物联网——DMA+AD多通道
DMA简介 存储器映像 某些数据在运行时不会发生变化,则设置为常量,存在Flash存储器中,节省运行内存的空间 DMA结构图 DMA访问权限高于cpu 结构要素 软件触发源:存储器到存储器传输完成后,计数器清零 硬件触发源&…...

Vue 中 watch 和 watchEffect 的区别
watch 和 watcheffect 都是 vue 中用于监视响应式数据的 api,它们的区别在于:watch 用于监视特定响应式属性并执行回调函数。watcheffect 用于更通用的响应式数据监视,但回调函数中不能更新响应式数据。Vue 中 watch 和 watchEffect 的区别 …...

pip install pyaudio sounddevice error: externally-managed-environment
shgbitaishgbitai-C9X299-PGF:~/pythonworkspace/ai-accompany$ pip install pyaudio sounddevice error: externally-managed-environment This environment is externally managed ╰─> To install Python packages system-wide, try apt installpython3-xyz, where xyz …...

HTML 转 PDF API 接口
HTML 转 PDF API 接口 网络工具 / 文件处理 支持网页转 PDF 高效生成 PDF / 提供永久链接。 1. 产品功能 超高性能转换效率;支持将传递的 HTML 转换为 PDF,支持转换 HTML 中的 CSS 格式;支持传递网站 URL,直接转换页面成对应的 …...
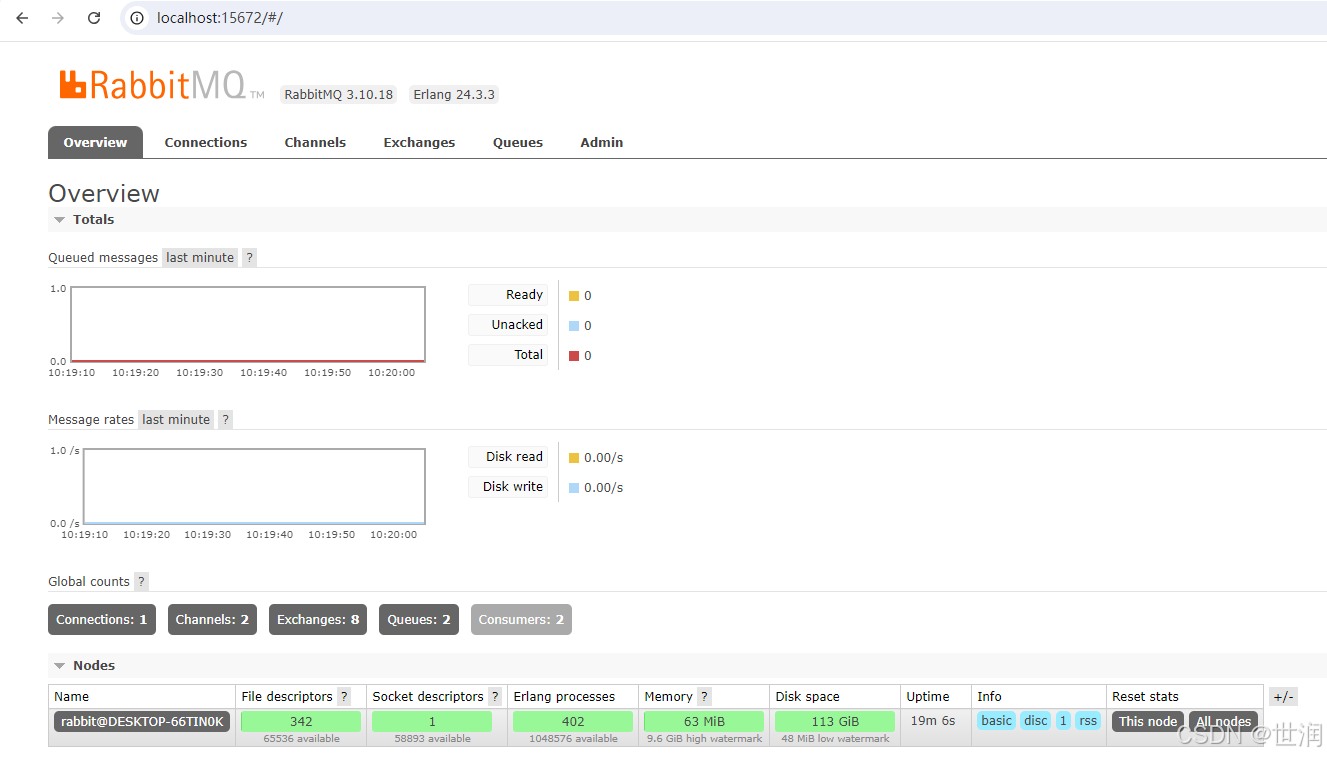
http://localhost:15672/ 无法访问
注意erlang版本和rabbitmq的版本要保持兼容 rabbitmq和erlang对应关系如下:https://www.rabbitmq.com/which-erlang.html 目前我选择的erlang版本是:otp_win64_24.3.3,rabbit版本是:rabbitmq-server-3.10.18.exe 如果两者之间的版…...
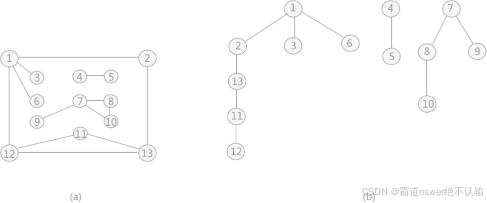
6.3图的遍历
图的遍历是指从某点出发,按照某种搜索方式沿着边访问图中所有节点 图的遍历算法主要有两种:广度优先,深度优先 都需要辅助数组visited[]来记录节点是否被访问过 6.3.1广度优先搜索 like层次遍历,需要辅助队列 代码实现 #include<stdio.h> #define maxnum 15 bool vi…...

2024数学建模国赛选题建议+团队助攻资料(已更新完毕)
目录 一、题目特点和选题建议 二、模型选择 1、评价模型 2、预测模型 3、分类模型 4、优化模型 5、统计分析模型 三、white学长团队助攻资料 1、助攻代码 2、成品论文PDF版 3、成品论文word版 9月5日晚18:00就要公布题目了,根据历年竞赛题目…...

大学课程-人机交互期末复习
绪论 什么是人机交互技术?⭐⭐ 是指关于设计、评价和实现供人们使用的交互式计算机系统,并围绕相关的主要现象进行研究的学。狭 义的讲,人机交互技术主要是研究人与计算机之间的信息交换,它主要包括人到计算机和计算机到人的 信息…...

畅游5G高速网络:联发科集成Wi-Fi6E与蓝牙5.2的系统级单芯片MT7922
这周末,除非外面下钞票,否则谁也拦不住我玩《黑神话悟空》(附:两款可以玩转悟空的显卡推荐) IPBrain平台君 集成电路大数据平台 2024年09月03日 17:28 北京 联发科一直以创新技术追赶市场需求…… “不努力向前游就会被海浪拍回岸边…” 芯片设计公司产品层出不穷,想要站…...

SpringSecurity原理解析(一)
一、SpringSecurity 核心组件 在SpringSecurity中的jar包有4个,作用分别为: spring-security-coreSpringSecurity的核心jar包,认证和授权的核心代码都在这里面spring-security-config如果使用Spring Security XML名称空间进行配置或Spring S…...

在Ubuntu 20.04上安装Nginx的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Nginx 是世界上最流行的 Web 服务器之一,负责托管互联网上一些最大和流量最高的网站。它是一个轻量级选择,…...

基于苹果Vision Pro的AI NeRF方案:MetalSplatter
随着苹果Vision Pro的发布,混合现实(Mixed Reality, MR)技术迎来了一个新的发展阶段。为了充分利用Vision Pro的潜力,一款名为MetalSplatter的Swift/Metal库应运而生,它允许开发者在Vision Pro上以全立体的方式体验捕捉内容。本文将详细介绍MetalSplatter的特点及其如何为…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

Midjourney V6锐化失控?3步诊断+5组--sref/--stylize协同参数公式,立竿见影修复模糊与锯齿
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6锐化失控的本质归因 Midjourney V6 引入的全新扩散架构与隐式细节增强机制,导致图像生成过程中高频纹理被过度强化,其根本原因并非参数误配,而是模型在…...