GPU 带宽功耗优化
移动端GPU 的内存结构:

先简述移动端内存cache结构;上图的UMA结构 on-Chip memory 包括了 L1、L2 cache,非常关键的移动端的 Tiles 也是保存在 on-chip上还包括寄存器文件:提供给每个核心使用的极高速存储。
- 共享内存(Shared Memory):用于同一计算单元内的线程组SM共享数据,访问速度比全局内存快。
- 常量缓存(Constant Cache):专门用于缓存常量数据。
- 纹理内存(Texture Memory):类似于常量缓存,也是具有缓存的全局内存,容量较大且一般仅可读。它们通过特定的方式进行访问,适用于纹理采样等操作。
移动端GPU流程
下图以arm 的mail为例(以后有机后再展开说):

load 与 store:
- load与 store决定了每个Render Pass开始时如何处理Tile内存中的数据。
- 从 SystemMemory 拷贝数据到 TileMemory 是 Load Action。
- 从 TileMemory 拷贝数据到 SystemMemory 是 Store Action。
在移动端图形中GPU Load Actions(加载操作)决定了在渲染一个新的帧缓冲区FBO,如何处理FBO中已经存在的数据,这在优化性能和内存带宽方面非常重要。主要有三种GPU Load Actions:don‘t care、Load、Clear。

在移动端图形中GPU Store Actions(存储操作)决定了在渲染完成一帧后如何处理FBO中已经存在的数据:主要有三种dont’care 、resolve、store


Apple 的Store Action 有三种, Store, DontCare,MultisampleResolve ,还有两种处理 MSAA 等的 Metal、vulkan 的storeAndMultisampleResolve, MultisampleResolve. 感兴趣可以直接参苹果的文档 Metal Best Practices Guide: Load and Store Actions

想要优化pipline的性能,就一定要注意设置好每个RenderTarget的Load Action 和 Store Actions。比如,Depth和Stencil通常只有在Rasterize阶段才会使用,所以直接放到了On-chip上, 或者后处理执行后深度没有用Store Actions设置为Don‘t care这样就不用把结果写入system内存,省下了大量的带宽。
fast clear
Fast Clear 是 GPU 对帧缓冲区进行快速clear的一种硬件优化机制。当帧缓冲区被clear时,只需将每个像素初始化到一个特定的颜色值。如果直接操作整个帧缓冲区对整个缓冲区的逐步遍历,会非常耗时
Fast Clear 本质上是一些硬件预设的清除值,比如clear成黑色或者白色这种,比自己传一个clear value进去要快!现代的硬件都有 Fast Clear,不管是 PC 、Apple A系列、ARM使用的Transaction Elimination 的技术,Adreno等都支持。
调用 clear 的时候根据硬件支持与驱动的设置会触发Fast Clear。比如在 amd 上Fast clear 在设计上比不同clear快约100倍
- Fast clear 需要全图像clear。
- Fast clear RT的 需要以下颜色RGBA(0,0,0,0),RGBA(0,0,0,1),RGBA(1,1,1,0) ,RGBA(1,1,1,1)
- Depth RT Fast clear 需要将深度值设为1.f或者0.f。
- 模板设置值为 0x00。
- Depth target arrays 需要将全部slices都清除才能实现fast clear。
- vulkan 与 D12有Discard或LOAD_OP_DONT_CARE 标记时(opengles 无),会跳过Clear。
opengles 的dont’t care 实现
在 opengl 中don’t care 对应的是glinvalidate,clear对应glclear,综上所述在 opengl 中glinvalidate与glclear不等价。所以glinvalidate应该会比clear会更好。glInvalidateFramebuffer 在 ogles2.0 是需要扩展,在 es3.0 是支持的详细参考 gl 文档: glInvalidateFramebuffer - OpenGL ES 3 Reference Pages
pipline开始时将显卡内存初始化使用glclear然后fast clear设置为特定颜色值,而无需system从内存中读回旧的帧缓冲区内容。在进行任何绘制调用之前,除非需要前一帧中渲染的内容上做处理,都可以使用以下的
glClear()
glClearBuffer()
glInvalidateFramebuffer()
你需要使用 glclear 、glClearBuffer、glInvalidateFramebuffer给 GPU 驱动标记opengl驱动会自己优化load过程。但是需要特别注意:每一帧中只有开始是免费(几乎无消耗)的。在pipline中的第一次绘制调用再后调用 glClear() 或 glClearBuffer*() 不是免费的,会增多指令并且这会导致每个着色器的片段都会被清除。同时这些是清除整个 framebuffer,而不仅仅是它的一个子区域!
对于store过程,最重要的是可以通过调用glInvalidateFramebuffer()作为pipline中的最后一个绘制调用,将内容标记为无效!
arm Mali参考
Minimizing-Start-of-Tile-Loads
Minimizing End of Tile Stores
gl 的例子 glInvalidateFramebuffer(GL_FRAMEBUFFER, 1, &attachment);
Load/Store Unit的性能指标含义:
首先,特别注意:
1、issues在 GPU 中是专业术语不能直接翻译成“问题”应该翻译成“发射”或者”调度“用于描述GPU在某个时钟周期内,某种操作(例如读、写、计算)被硬件单元执行或发射的次数。
2、beats 指的是内存控制器中的一个传输单元。它代表一次数据传输中的“拍子”或“节奏”,可以理解为传输过程中一个周期内的数据量。因此,这里的 beats 应该翻译为“传输单位”。
其次,如下表的指标主要是android GPU inspector的指标也是最全的,同样的 Arm 、adreno 等的指标都是下表的特定指标;



load/store参数的分析:
Demo假设你在分析一个 GPU 程序,并且性能分析工具streamline提供了如下参数值:
Load/Store Read Beats from L2 Cache: 5000
Load/Store Read Beats from External Memory: 20000
Internal Load/Store Writeback/Other Write Beats: 15000
从这些数据你可以推断出:
- 程序高度依赖外部内存:因为从外部内存的读取节拍(20000)显著高于从 L2 缓存的读取节拍(5000),表明许多数据访问没有命中 L2 缓存。
- 写操作较频繁:内部加载/存储写回和其他写操作节拍总数(15000)表明有大量的数据写入,可能是计算结果或状态更新(这个时候使用dontcare会有较好的优化效果)。
假设你有以下参数值:
- Load Read Bytes from L2 Cache:320000 / 每访问周期 64 字节
- Load Read Bytes from External Memory:640000 / 每访问周期 128 字节
从这组数据中可以看到: - 从 L2 缓存读取总共 320,000 字节,平均每个访问周期读取 64 字节。
- 从外部内存读取总共 640,000 字节,平均每个访问周期读取 128 字节。
尽管外部内存每个周期读取的字节数较大,但外部内存访问的延迟比 L2 缓存高,整体访问效率可能较低。因此,如果程序频繁地访问外部内存,而不是 L2 缓存,可能会导致性能下降。在这种情况下,优化策略可能包括:
- 提高 L2 缓存命中率,通过更有效的数据布局(内存对齐)和访问模式减少对外部内存的依赖。
- 使用共享内存(内存数组等)或寄存器来缓存频繁访问的数据,从而减少全局内存访问。
参考资料:
1、 移动端高性能图形开发 - 移动端GPU架构探究
2、 移动GPU体系结构
3、 OpenGL ES 3.0 帧缓冲区失效-
4、 移动平台的GPU性能分析
相关文章:
GPU 带宽功耗优化
移动端GPU 的内存结构: 先简述移动端内存cache结构;上图的UMA结构 on-Chip memory 包括了 L1、L2 cache,非常关键的移动端的 Tiles 也是保存在 on-chip上还包括寄存器文件:提供给每个核心使用的极高速存储。 共享内存(…...

Linux Centos 7网络配置
本步骤基于Centos 7,使用的虚拟机是VMware Workstation Pro,最终可实现虚拟机与外网互通。如为其他发行版本的linux,可能会有差异。 1、检查外网访问状态 ping www.baidu.com 2、查看网卡配置信息 ip addr 3、配置网卡 cd /etc/sysconfig…...

第三天旅游线路规划
第三天:从贾登峪到禾木风景区,晚上住宿贾登峪; 从贾登峪到禾木风景区入口: 1、行程安排 根据上面的耗时情况,规划一天的行程安排如下: 1)早上9:00起床,吃完早饭&#…...

C++第四十七弹---深入理解异常机制:try, catch, throw全面解析
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】 目录 1.C语言传统的处理错误的方式 2.C异常概念 3. 异常的使用 3.1 异常的抛出和捕获 3.2 异常的重新抛出 3.3 异常安全 3.4 异常规范 4.自定义…...

go 和 java 技术选型思考
背景: go和java我这边自身都在使用,感受比较深,java使用了有7年多,go也就是今年开始的,公司需要所以就学了使用,发现这两个语言都很好,需要根据场景选择,我写下我这边的看法。 关于…...

传统CV算法——边缘算子与图像金字塔算法介绍
边缘算子 图像梯度算子 - Sobel Sobel算子是一种用于边缘检测的图像梯度算子,它通过计算图像亮度的空间梯度来突出显示图像中的边缘。Sobel算子主要识别图像中亮度变化快的区域,这些区域通常对应于边缘。它是通过对图像进行水平和垂直方向的差分运算来…...

图像去噪算法性能比较与分析
在数字图像处理领域,去噪是一个重要且常见的任务。本文将介绍一种实验,通过MATLAB实现多种去噪算法,并比较它们的性能。实验中使用了包括中值滤波(MF)、自适应加权中值滤波(ACWMF)、差分同态算法…...
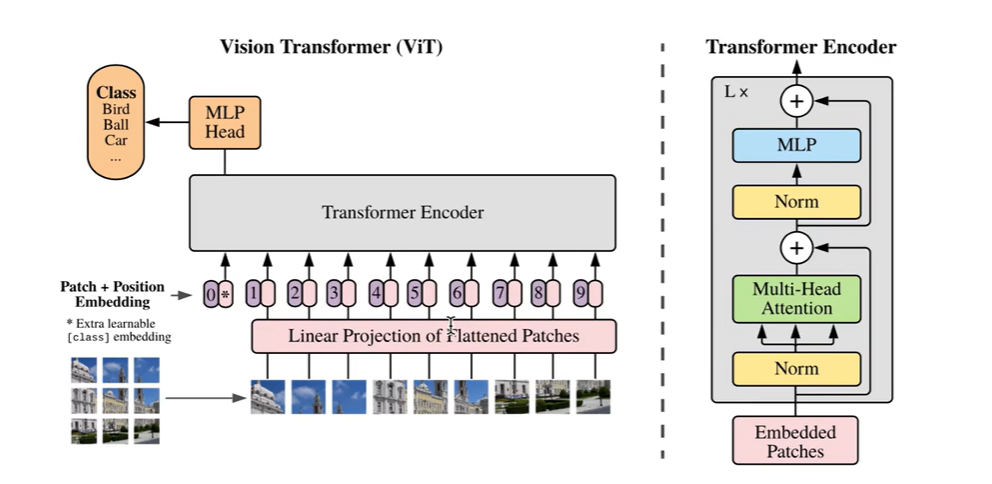
Vision Transformer(ViT)模型原理及PyTorch逐行实现
Vision Transformer(ViT)模型原理及PyTorch逐行实现 一、TRM模型结构 1.Encoder Position Embedding 注入位置信息Multi-head Self-attention 对各个位置的embedding融合(空间融合)LayerNorm & ResidualFeedforward Neural Network 对每个位置上单…...

828华为云征文 | Flexus X实例CPU、内存及磁盘性能实测与分析
引言 随着云计算的普及,企业对于云资源的需求日益增加,而选择一款性能强劲、稳定性高的云实例成为了关键。华为云Flexus X实例作为华为云最新推出的高性能实例,旨在为用户提供更强的计算能力和更高的网络带宽支持。最近华为云828 B2B企业节正…...
队列)
FreeRTOS学习笔记(六)队列
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、队列的基本内容1.1 队列的引入1.2 FreeRTOS 队列的功能与作用1.3 队列的结构体1.4 队列的使用流程 二、相关API详解2.1 xQueueCreate2.2 xQueueSend2.3 xQu…...

【Python篇】PyQt5 超详细教程——由入门到精通(中篇一)
文章目录 PyQt5入门级超详细教程前言第4部分:事件处理与信号槽机制4.1 什么是信号与槽?4.2 信号与槽的基本用法4.3 信号与槽的基础示例代码详解: 4.4 处理不同的信号代码详解: 4.5 自定义信号与槽代码详解: 4.6 信号槽…...

LinuxQt下的一些坑之一
我们在使用Qt开发时,经常会遇到Windows上应用正常,但到Linux嵌入式下就会出现莫名奇妙的问题。这篇文章就举例分析下: 1.QPushButton按钮外侧虚线框问题 Windows下QPushButton按钮设置样式正常,但到了Linux下就会有一个虚线边框。…...

Statement batch
我们可以看到 Statement 和 PreparedStatement 为我们提供的批次执行 sql 操作 JDBC 引入上述 batch 功能的主要目的,是加快对客户端SQL的执行和响应速度,并进而提高数据库整体并发度,而 jdbc batch 能够提高对客户端SQL的执行和响应速度,其…...

PPP 、PPPoE 浅析和配置示例
一、名词: PPP: Point to Point Protocol 点到点协议 LCP:Link Control Protocol 链路控制协议 NCP:Network Control Protocol 网络控制协议,对于上层协议的支持,N 可以为IPv4、IPv6…...

【Python机器学习】词向量推理——词向量
目录 面向向量的推理 使用词向量的更多原因 如何计算Word2vec表示 skip-gram方法 什么是softmax 神经网络如何学习向量表示 用线性代数检索词向量 连续词袋方法 skip-gram和CBOW:什么时候用哪种方法 word2vec计算技巧 高频2-gram 高频词条降采样 负采样…...
)
Python 语法糖:让编程更简单(续二)
Python 语法糖:让编程更简单(续) 10. Type hints Type hints 是 Python 中的一种语法糖,用于指定函数或变量的类型。例如: def greet(name: str) -> None:print(f"Hello, {name}!")这段代码将定义一个…...

6 - Shell编程之sed与awk编辑器
目录 一、sed 1.概述 2.sed命令格式 3.常用操作的语法演示 3.1 输出符合条件的文本 3.2 删除符合条件的文本 3.3 替换符合条件的文本 3.4 插入新行 二、awk 1.概述 2. awk命令格式 3.awk工作过程 4.awk内置变量 5.awk用法示例 5.1 按行输出文本 5.2 按字段输出文…...

什么是XML文件,以及如何打开和转换为其他文件格式
本文描述了什么是XML文件以及它们在哪里使用,哪些程序可以打开XML文件,以及如何将XML文件转换为另一种基于文本的格式,如JSON、PDF或CSV。 什么是XML文件 XML文件是一种可扩展标记语言文件。它们是纯文本文件,除了描述数据的传输、结构和存储外,本身什么也不做。 RSS提…...

海外直播对网速、带宽、安全的要求
要满足海外直播的要求,需要拥有合适的网络配置。在全球化的浪潮下,海外直播正逐渐成为企业、个人和各类组织的重要工具。不论是用于市场推广、品牌宣传,还是与观众互动,海外直播都为参与者带来了丰富的机会。然而,确保…...

UWB定位室外基站
定位基站,型号SW,是一款基于无线脉冲技术开发的UWB定位基站,基站可用于人员、车辆、物资的精确定位, 该基站专为恶劣环境使用而设计,防尘、防水等级IP67,工业级标准支持365天连续运行,本安防爆可…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

收藏|2026年AI大模型就业爆发!岗位暴涨12倍、月薪6W+,小白零基础入门指南
2026年,AI已从“科技热点”彻底变为职场“刚需赛道”!脉脉高聘人才智库最新发布的《2026年1-2月中高端人才求职招聘洞察》,用硬核数据揭示行业真相:AI人才成招聘市场顶流,岗位量、薪资双双爆发式增长。尤其对零基础小白…...

为开源项目OpenClaw配置Taotoken作为其大模型服务后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为其大模型服务后端 OpenClaw 是一个功能强大的开源工具,它允许开发者便捷地调用各类…...
:openclaw agent 如何触发一次 Agent 运行?)
OpenClaw 源码解析(六):openclaw agent 如何触发一次 Agent 运行?
1. 本期要解决的问题 前几期我们已经从项目整体结构、CLI 命令体系、配置加载、Gateway 运行机制等角度理解了 OpenClaw 的基础框架。到了这一期,可以进一步进入 OpenClaw 最核心的使用动作:用户在终端中执行一条 openclaw agent --message "...&q…...