【AIGC数字人】EchoMimic:基于可编辑关键点条件的类人音频驱动肖像动画
GitHub:https://github.com/BadToBest/EchoMimic
论文: https://arxiv.org/pdf/2407.08136
comfyui: https://github.com/smthemex/ComfyUI_EchoMimic
相关工作
Wav2Lip
Wav2Lip是一个开创性的工作 ,但输出会出现面部模糊或扭曲的牙齿结构等伪影。
SadTalker
从音频生成 3D Morphable 模型的 3D 运动系数(头部姿势、表情),并隐式调制 3D 感知人脸渲染以生成说话头。为了学习真实的运动系数,SadTalker 明确地模拟了音频和不同类型运动系数之间的联系。然后将生成的3D运动系数映射到所提出的人脸渲染的无监督3D关键点空间,合成最终的视频。
AniPortrait
AniPortrait表示该领域的另一个显着步幅,在将音频信号映射到 2D 面部地标之前,熟练地将音频信号转换为详细的 3D 面部结构。随后的扩散模型,加上运动模块,将这些地标渲染成时间连贯的视频序列,丰富自然情绪的描绘,并实现细微的面部运动改变和重演。
V-Express
V-Express扩展视听对齐的范围,采用分层结构,将音频与嘴唇运动、面部表情和头部姿势的细微动态进行细致同步。它复杂的面部损失函数进一步细化模型对细微情感细微差别的敏感性和面部特征的整体审美吸引力。
Hallo
Hallo [23] 为肖像图像动画提供了一种分层音频驱动的视觉合成方法,解决了嘴唇同步、表情和姿势对齐的复杂性。通过将基于扩散的生成模型与UNet降噪器和交叉注意机制相结合,实现了对表情多样性和姿态变化的增强控制,证明了视频质量、唇形同步精度和运动多样性的改进。
然而,尽管基于图像的方法取得了相当大的进步,但仍有一些挑战。这些方法通常分别对音频或姿势输入进行条件合成,很少同时集成两者。此外,评估协议往往严重依赖图像级指标,如Fŕechet Inception Distance (FID)和Expression Fŕechet Inception Distance (E-FID),可能忽略了面部结构和动力学的关键方面。解决这些复杂性对于提高“说话头”动画的真实性和保真度至关重要,为更身临其境和类似生活的多媒体体验铺平了道路。
方法
网络结构

Echomimic的基础成分是Denoising UNet,为了网络吸收多样化输入的能力,Echomimic集成了三个模块:Reference UNet用于编码参考图片;Landmark Encoder用于使用脸部关键点引导网络;Audio Encoder用于编码声音输入。
Denoising UNet
去噪 U-Net 旨在增强在不同条件下由噪声破坏的多帧潜在表示,从完善的 SDv1.5 架构中汲取灵感,并在每个 Transformer 中加入三个不同的注意力层.最初的参考注意层促进了对当前帧和参考图像之间关系的熟练编码,而第二个音频注意层捕获视觉和音频内容之间的交互,在空间维度上运行。此外,Temporal-Attention 层部署了一种时间自注意力机制来破译连续视频帧之间的复杂时间动态和关系。这些增强对于跨网络的空间和时间关系的细微理解和集成至关重要.
Reference U-Net
参考图像对于在 EchoMimic 框架内保持面部身份和背景一致性至关重要。为了促进这一点,我们引入了专门的模块 Reference U-Net,它反映了 SDv1.5 的架构设计,并与去噪 U-Net 并行运行。在参考 U-Net 的每个 Transformer 块中,自注意力机制用于提取参考图像特征,随后用作去噪 U-Net 中相应 Transformer 块参考注意力层中的键和值输入。参考 U-Net 的唯一函数是对参考图像进行编码,确保没有引入噪声,并且扩散过程中只执行单独的前向传递。此外,为了防止引入无关信息,将空文本占位符输入 ReferenceNet 的交叉注意力层。这种细致的设计确保了参考图像的本质在生成过程中的准确捕获和无缝集成,促进了高保真输出的创建。
Audio Encoder
合成人物的动画主要是由语音中发音和音调的细微差别驱动的。我们通过使用预训练的 Wav2Vec 模型 [17] 的各种处理块连接从输入音频序列中提取的特征来导出相应帧的音频表示嵌入。字符的运动可能会受到未来和过去的音频片段的影响,需要考虑时间上下文。为了解决这个问题,我们通过连接相邻帧的特征来定义每个生成帧的音频特征。随后,我们在去噪 U-Net 中使用 Audio-Attention 层来实现潜在代码和每个参考注意层输出之间的交叉注意机制,有效地将语音特征集成到生成过程中。这确保了合成字符的运动被精细调整到伴随音频的动态微妙之处,从而增强输出的真实感和表现力。
Landmark Encoder
利用每个面部地标图像及其相关目标帧之间的鲁棒空间对应关系,集成了地标编码器在我们的 EchoMimic 框架中。地标编码器,实例化为流线型卷积模型,负责将每个面部地标图像编码为与潜在空间维度对齐的特征表示。随后,编码后的面部地标图像特征在摄取到去噪U-Net之前通过元素相加直接与多帧潜伏期集成。该策略能够无缝地结合精确的空间信息,这对于在生成过程中保持准确的解剖结构和运动至关重要,最终提高输出序列的保真度和连贯性。
Temporal Attention Layer
为了生成时间连贯的视频序列,EchoMimic 结合了时间注意层来编码视频数据中固有的时间动态。这些层通过重塑隐藏状态并沿帧序列的时间轴应用自我注意机制,熟练地捕获连续帧之间的复杂依赖关系。具体来说,给定一个隐藏状态 h ∈ Rb×f ×d×h×w,其中 b、f、d、h 和 w 表示批量大小、帧数、特征维度、高度和宽度。我们的 Temporal Attention 层擅长捕捉连续帧之间的复杂依赖关系。这是通过首先将隐藏状态重塑为 h ∈ R(b×h×w)×f ×d 来实现的,从而能够沿帧序列的时间轴应用自注意力机制。通过这个过程,时间注意层识别和学习细微的运动模式,确保合成帧中的平滑和谐过渡。因此,视频序列表现出高度的时间一致性,反映自然运动和流体运动,提高生成内容的视觉质量和真实性。
Spatial Loss
由于潜在空间的分辨率(512 * 512图像的64 * 64)相对较低,无法捕捉细微的面部细节,因此提出了一种时间步感知的空间损失,直接在像素空间中学习人脸结构。特别是,预测的潜在 zt 首先通过采样器映射到 z0。然后通过将 z0 传递给 vae 解码器来获得预测图像。最后,在预测图像及其对应的基本事实上计算 mse 损失。除了 mse 损失外,还采用了 LPIPS 损失来进一步细化图像的细节。此外,由于模型在时间步长 t 很大时很难收敛,我们提出了一个时间步感知函数来减少目标 t 的权重。详细的目标函数如下所示:

训练细节
我们在之前的工作之后采用了两阶段训练策略。我们提出了包括随机地标选择和音频增强在内的有效技术来促进训练过程。
第一阶段
在第一阶段,参考 unet 和去噪 unet 在单帧数据上进行训练以学习图像-音频和图像-姿势之间的关系。特别是,在阶段1中,时间注意层没有插入到去噪中。
第二阶段
在阶段2中,时间注意层被插入到去噪UNet中。整个管道是在12帧视频上训练的,用于最终的视频生成。只有时间模型的训练,而其他部分在阶段2被冻结。
随机关键点选择
为了实现鲁棒的基于地标的图像驱动,我们提出了一种随机地标选择(RLS)技术。特别是,脸被分成几个部分,包括眉毛、眼睛、瞳孔、鼻子和嘴巴。在训练过程中,我们随机地放弃面部的一个或几个部分。
空间损失和音频增强
在实验中,我们发现两个关键技术可以显著提高生成视频的质量。一是上述提出的空间损失,它迫使扩散模型直接从像素空间学习空间信息。另一种是音频增强,它在原始音频中插入噪声和其他扰动,以实现与图像类似的数据增强。
推理
对于音频驱动的情况,推理过程很简单。而对于姿势驱动或音频+姿势驱动的情况,重要的是根据以前的作品将姿势与参考图像对齐。尽管提出了几种运动对齐技术,但挑战仍然存在。例如,现有的方法通常采用全面透视的翘曲仿射,而忽略了面部部位的匹配。为此,我们提出了一个发展版本的运动校准称为部分感知运动同步。
部分感知运动同步
在实验中,我们发现两个关键技术可以显著提高生成视频的质量。一是上述提出的空间损失,它迫使扩散模型直接从像素空间学习空间信息。另一种是音频增强,它在原始音频中插入噪声和其他扰动,以实现与图像类似的数据增强。
实验
实验细节
硬件:8个NVIDIA A100GPU。训练分为两个过程,每个过程30000步。这些步骤在批处理大小为4的情况下执行,处理以512 × 512像素的分辨率格式化的视频数据。在第二阶段的训练中,每次迭代生成14个视频帧,将从运动模块导出的潜在变量与最初的2个实际视频帧进行整合,以确保叙事的一致性。在整个训练阶段,始终保持1e-5的学习率。运动模块使用来自Animatediff模型的预训练权重进行初始化,以加快学习过程。为了引入可变性并提高模型的生成能力,在训练过程中以5%的概率随机忽略参考图像、引导音频和运动帧等元素。在推理阶段,系统通过将被噪声干扰的潜在变量与运动模块中前一步最新的2个运动帧提取的特征表示合并来保持序列相干性。这种策略保证了连续视频序列之间的无缝过渡,从而提高了生成视频的整体质量和连续性。
数据
我们从互联网上收集了大约540小时(每个视频片段约15秒长,总计约130,000个视频片段)的说话头视频,并补充了HDTF[26]和CelebV-HQ[27]数据集来训练我们的模型。为了维护严格的训练数据标准,我们实施了细致的数据清理程序。这个过程的重点是保留那些以一个人说话为特征的视频,这些视频在嘴唇运动和伴随的音频之间有很强的相关性,同时丢弃那些有场景过渡、明显的镜头运动、过度表达的面部动作或完全以侧面为导向的观点的视频。我们使用MediaPipe[9]提取训练视频的面部地标。
评估指标
用于评估肖像图像动画方法性能的指标包括FID(初始距离),FVD(视频距离),SSIM(结构相似性指数测量)和E-FID(表达-FID)。FID和FVD衡量的是合成图像与实际数据的接近程度,分数越低,表现越逼真。SSIM指数衡量真实视频和生成视频之间的结构相似性。此外,E-FID利用盗梦空间网络的功能来严格评估生成图像的真实性,提供更精细的图像保真度标准。首先,E-FID采用人脸重构方法提取表情参数,详见[2]。然后,计算这些提取参数的FID,定量评估面部表情之间的差异
结果展示

相关文章:
【AIGC数字人】EchoMimic:基于可编辑关键点条件的类人音频驱动肖像动画
GitHub:https://github.com/BadToBest/EchoMimic 论文: https://arxiv.org/pdf/2407.08136 comfyui: https://github.com/smthemex/ComfyUI_EchoMimic 相关工作 Wav2Lip Wav2Lip是一个开创性的工作 ,但输出会出现面部模糊或扭…...

变量数据类型 Day3
1. 变量 1.1 变量的概念 变量是计算机内存中的一块存储单元,是存储数据的基本单元变量的组成包括:数据类型、变量名、值,后文会具体描述变量的本质作用就是去记录数据的,比如说记录一个人的身高、体重、年龄,就需要去…...

SpringBoot2:请求处理原理分析-RESTFUL风格接口
一、RESTFUL简介 Rest风格支持(使用HTTP请求方式,动词来表示对资源的操作) 以前:/getUser 获取用户 /deleteUser 删除用户 /editUser 修改用户 /saveUser 保存用户 现在: /user GET-获取用户 DELETE-删除用户 PUT-修改…...

[Linux][配置]Linux修改history存储的最大记录数
Linux修改History最大记录为20000行 sed -i s/^HISTSIZE1000/HISTSIZE20000/ /etc/profile source /etc/profile 在 Linux 系统中,HISTSIZE 环境变量用于定义历史记录的大小,即在终端中可以回溯的命令数量。默认情况下,这个值通常是 1000&…...
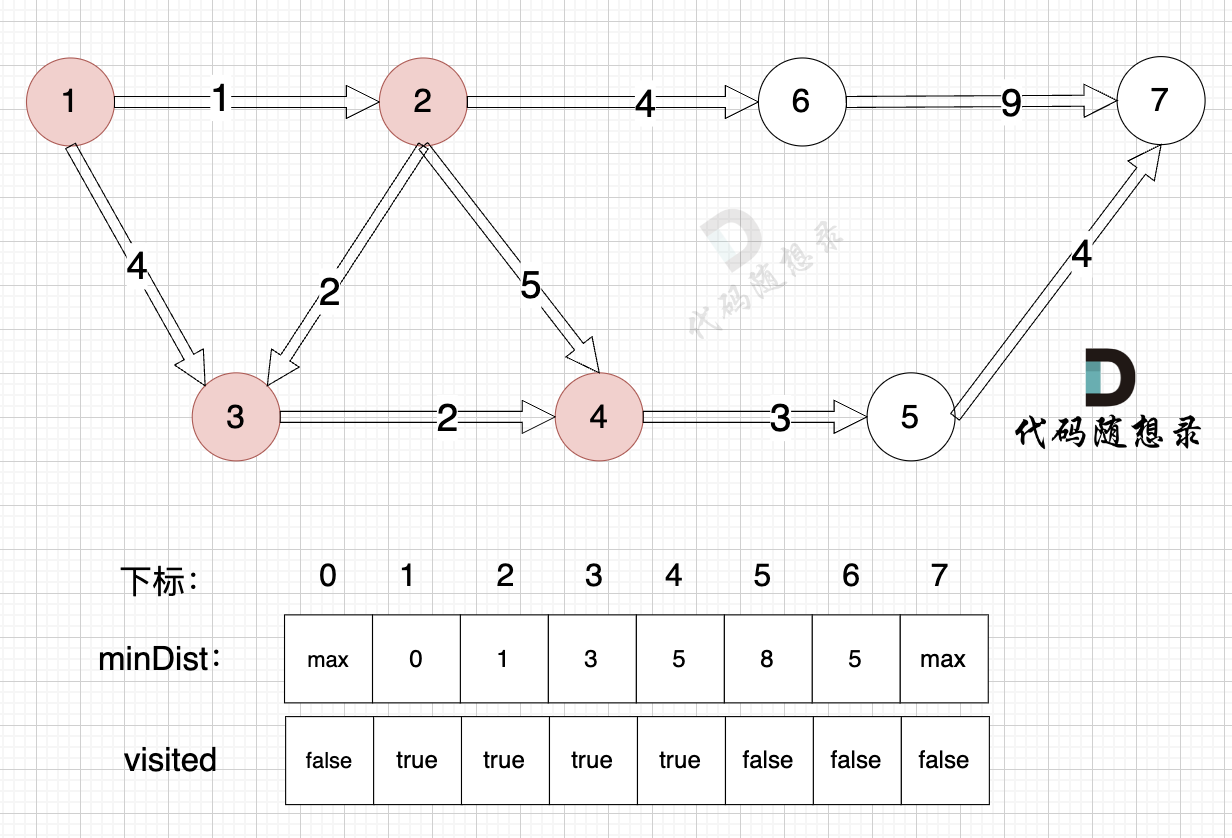
代码随想录 刷题记录-28 图论 (5)最短路径
一、dijkstra(朴素版)精讲 47. 参加科学大会 思路 本题就是求最短路,最短路是图论中的经典问题即:给出一个有向图,一个起点,一个终点,问起点到终点的最短路径。 接下来讲解最短路算法中的 d…...

大数据-124 - Flink State 01篇 状态原理和原理剖析:状态类型 执行分析
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

C++复习day04
一、函数重载 1.什么是函数重载? 自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重 载了。 比如:以前有一个笑话,国有两个体育项目大家根本不用看,也不用…...
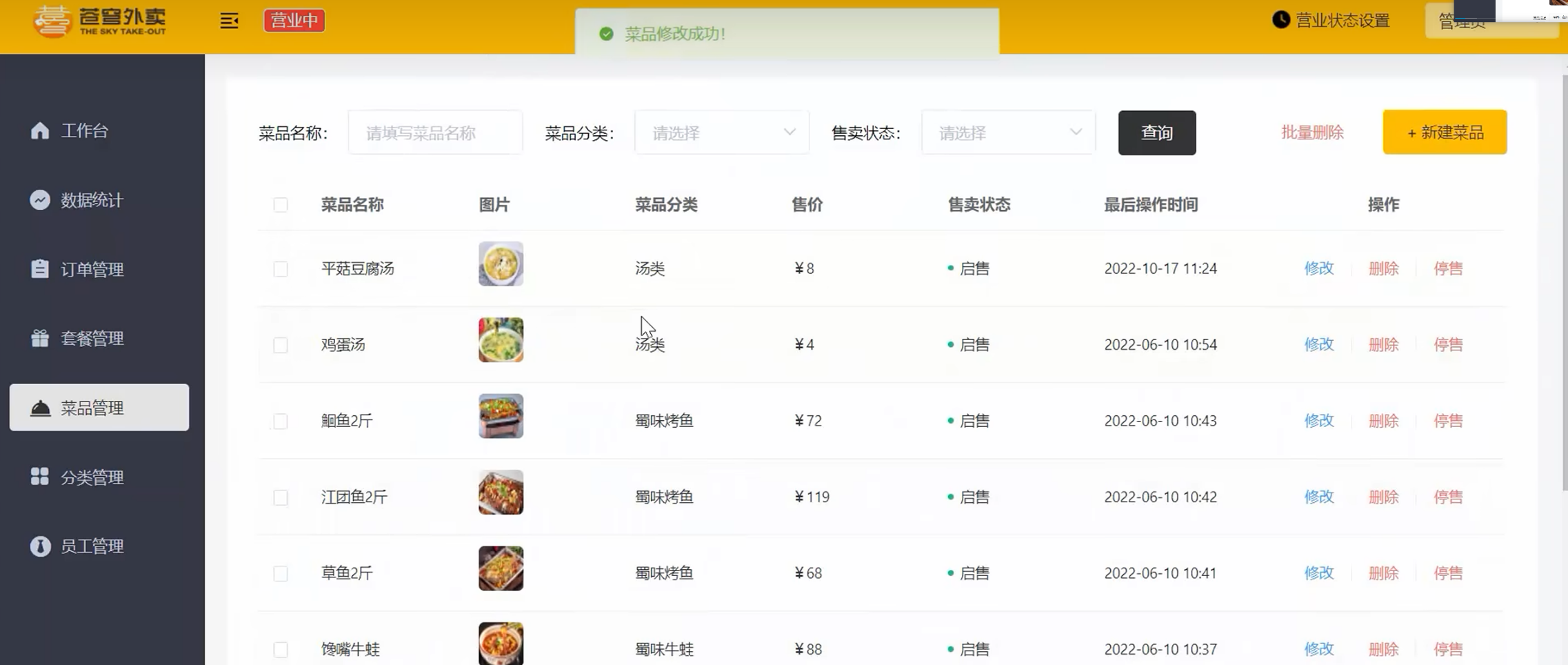
[苍穹外卖]-04菜品管理接口开发
效果预览 新增菜品 需求分析 查看产品原型分析需求, 包括用到哪些接口, 业务的限制规则 业务规则 菜品名称必须是唯一的菜品必须属于某个分类下, 不能单独存在新增菜品时可以根据情况选择菜品的口味每个菜品必须对应一张图片 接口设计 根据类型查询分类接口 文件上传接口 …...

gitlab 启动/关闭/启用开机启动/禁用开机启动
文章目录 启动 gitlab关闭 gitlab查看 gitlab 运行状态启用 gitlab 开机启动禁用 gitlab 开机启动GitlabGit启动 gitlab hxstrive@localhost:~$ sudo gitlab-ctl start ok: run: alertmanager: (pid 65953) 0s ok: run: gitaly: (pid 65965) 0s ok: run: gitlab-exporter: (pi…...

中间件解析漏洞(附环境搭建教程)
⼀:IIS解析漏洞 环境资源: https://download.csdn.net/download/Nai_zui_jiang/89717504 环境安装 windows2003iis6 1.创建新的虚拟机 2.在下⼀步中选择我们的iso⽂件镜像 vm已主动识别到windows2003 3.产品密钥⽹上搜⼀个 密码自己设置一个简单的&…...

matlab实现kaiser窗+时域采样序列(不管原信号拉伸成什么样子)是一样的,变到频谱后再采样就是一样的频域序列。
下图窗2的频谱在周期化的时候应该是2(w-k*pi/T)我直接对2w减得写错了 可见这两个kaiser窗频谱不一样,采样间隔为2T的窗,频谱压缩2倍,且以原采样频率的一半周期化。 但是这两个不同的kaiser窗在频域采样点的值使完全一…...

git为不同的项目设置不同的提交作者
方法1:找到项目的.git文件夹打开 打开config在下面添加自己作者信息 [user]name 作者名email 邮箱方法2:直接在.git文件夹设置作者名(不使用–global参数) git config user.name "xxxxx"如果想要修改之前提交的…...

防爆定位信标与防爆定位基站有什么区别?
新锐科技 https://baijiahao.baidu.com/s?id1804974957959442238&wfrspider&forpc http://www.xinruikc.cn/biaoqian/52.html http://www.xinruikc.cn/xinbiao/...

QT 编译报错:C3861: ‘tr‘ identifier not found
问题: QT 编译报错:C3861: ‘tr’ identifier not found 原因 使用tr的地方所在的类没有继承自 QObject 类 或者在不在某一类中, 解决方案 就直接用类名引用 :QObject::tr( )...

谈谈ES搜索引擎
一 ES的定义 ES 它的全称是 Elasticsearch,是一个建立在全文搜索引擎库Lucene基础上的一个开源搜索和分析引擎。ES 它本身具备分布式存储,检索速度快的特性,所以我们经常用它来实现全文检索功能。目前在 Elastic 官网对 ES 的定义,…...

【MySQL】MySQL基础
目录 什么是数据库主流数据库基本使用MySQL的安装连接服务器服务器、数据库、表关系使用案例数据逻辑存储 MySQL的架构SQL分类什么是存储引擎 什么是数据库 mysql它是数据库服务的客户端mysqld它是数据库服务的服务器端mysql本质:基于C(mysql)…...

Spring中Bean的相关注解
目录 1.Spring IoC&DI 2.关于Bean存储的相关注解(类注解与方法注解) Bean的获取方式 类注解和方法注解的重命名 2.1 类注解 2.1.1 Controller 2.1.2 Service 2.1.3 Repository 2.1.4 Component 2.1.5 Configuration 2.2 方法注解-Bean 2.2.1 定义多个对象 2.2…...

Golang | Leetcode Golang题解之第385题迷你语法分析器
题目: 题解: func deserialize(s string) *NestedInteger {if s[0] ! [ {num, _ : strconv.Atoi(s)ni : &NestedInteger{}ni.SetInteger(num)return ni}stack, num, negative : []*NestedInteger{}, 0, falsefor i, ch : range s {if ch - {negati…...

【Java 优选算法】双指针(上)
欢迎关注个人主页:逸狼 创造不易,可以点点赞吗~ 如有错误,欢迎指出~ 目录 移动零 分析 代码 复写零 分析 代码 快乐数 分析 代码 盛最多水的容器 分析 代码 移动零 题目链接 分析 双指针算法,利用两个指针cur和dest将数组划分为三个区间…...

【自动驾驶】控制算法(八)横向控制Ⅰ | 算法与流程
写在前面: 🌟 欢迎光临 清流君 的博客小天地,这里是我分享技术与心得的温馨角落。📝 个人主页:清流君_CSDN博客,期待与您一同探索 移动机器人 领域的无限可能。 🔍 本文系 清流君 原创之作&…...

手把手拆解蓝牙Extended Advertising数据包:从HCI Command到空口PDU的完整流程
手把手拆解蓝牙Extended Advertising数据包:从HCI Command到空口PDU的完整流程 蓝牙技术演进到5.0版本后,Extended Advertising(扩展广播)机制的引入彻底改变了低功耗蓝牙的通信范式。这项技术突破不仅解决了传统广播模式的诸多限…...

5分钟搭建炫酷企业抽奖系统:Magpie-LuckyDraw完整指南 [特殊字符]
5分钟搭建炫酷企业抽奖系统:Magpie-LuckyDraw完整指南 🎉 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https://gitcode.com/gh_mi…...

机器学习加速辐照材料缺陷预测:从团簇动力学到神经网络代理模型
1. 项目概述:当机器学习遇见辐照材料缺陷预测在核能、航空航天以及先进反应堆材料的设计与安全评估中,有一个问题始终萦绕在材料科学家和工程师的心头:一块材料在长期、高强度的粒子辐照下,其内部究竟会发生什么?微观层…...

工业智能化的时序选型指南:当数据底座遇见机器学习
随着工业 4.0 和物联网的深入发展,企业对时序数据的诉求已经发生了质的改变:“仅仅把海量数据存下来,并在大屏上画成折线图”已经远远无法满足高阶的业务需求。风机设备的预测性维护、流水线能耗的异常检测、智能电网的产量预测……这些高价值…...

中医馆升级|结合瑞式养老模式的医养结合完整落地方案
传统中医馆最大瓶颈是:客流老化、单次交易、依赖坐诊、复购不稳定、没有社区刚需流量。中医馆最高级的升级路径,不是继续做针灸开药,而是转型社区银发康养中心,嫁接瑞式养老标准化体系,打造「中医诊疗瑞式社区养老」双…...

ATLO-ML:自适应时序预测窗口与采样率优化框架详解
1. 项目概述:为什么时序预测的“窗口”和“节奏”如此重要?在机器学习的时间序列预测任务中,我们常常会陷入一个看似简单、实则充满陷阱的环节:如何设置模型的“输入窗口”?具体来说,就是应该用过去多长时间…...
)
从下载到网页管理:TrueNAS SCALE最新版保姆级安装图文教程(VMware Workstation 17环境)
TrueNAS SCALE在VMware Workstation 17中的全流程部署指南 对于需要在本地环境中快速搭建网络存储测试平台的用户来说,TrueNAS SCALE无疑是一个理想选择。作为TrueNAS家族的最新成员,它不仅继承了传统存储管理系统的稳定性和可靠性,还引入了…...

基于图神经网络的机器学习有限区域模型:边界处理与图结构设计实战
1. 项目概述与核心挑战最近几年,机器学习天气预测(MLWP)的进展让人有点兴奋,又有点眼花缭乱。从全球尺度的大模型到区域性的精细化预报,数据驱动的方法正在重新定义我们对大气模拟的理解。作为一名长期混迹在气象和计算…...

不止于播放:用VideoPlayer脚本控制实现一个简易的Unity视频播放器UI
不止于播放:用VideoPlayer脚本控制实现一个简易的Unity视频播放器UI在Unity中构建一个功能完整的视频播放器UI,远不止简单地调用VideoPlayer.Play()这么简单。本文将带您从零开始,实现一个具备播放控制、进度条拖拽、音量调节等完整功能的视频…...

《当下的力量》4-6章深度解读:从理论到实践,掌握临在的核心技术
《当下的力量》4-6章深度解读:从理论到实践,掌握临在的核心技术续篇:承接前三章"为什么要活在当下",这三章将告诉你"如何真正活在当下"前言 在前三章中,埃克哈特托利向我们揭示了人类痛苦的根源—…...