数据结构————内核链表
内核链表是Linux内核中广泛使用的一种数据结构,它具有以下特点:
1.双向循环链表:每个节点包含两个指针,一个指向前驱节点(prev),另一个指向后继节点(next),形成一个闭环。
2.结构封装:链表节点不直接包含数据。这样的设计使得同一个链表结构可以用于不同类型的数据节点。
3.通用性:由于链表节点与数据分离,可以方便地将链表结构嵌入到各种数据结构中,提高了代码的复用性和灵活性。
定义
内核链表是一种线性数据结构,其中每个节点包含了数据元素本身以及指向下一个节点的指针。在Linux内核中,这种链表通常被实现为双向链表或循环链表,以支持更高效的插入、删除和遍历操作。
节点结构
内核链表的节点通常包含至少两个指针:一个指向前一个节点(prev),另一个指向后一个节点(next)。在某些实现中,还可能包含一个指向数据本身的指针,但在Linux内核的链表中,节点本身并不直接存储用户数据,而是将用户数据保存在包含链表节点的结构体中。
链表头
链表头是一个特殊的节点,它通常不包含有效数据,但用于标识链表的开始位置。在双向链表中,链表头还可能包含指向链表最后一个节点的指针,以及一个指向链表第一个节点的指针。
| 单向链表 | 单向链表是最基本的链表结构,每个节点包含数据域和一个指向下一个节点的指针。它只能向前遍历,不能直接访问链表中的任意元素,需要从头开始遍历找到指定位置的节点。插入和删除操作的时间复杂度为 O(1),但由于不能直接访问链表中的任意元素,因此在需要频繁访问链表中间节点的场景中效率较低。 |
| 双向链表 | 双向链表是每个节点包含数据域、一个指向前一个节点的指针和一个指向下一个节点的指针的链表。它可以向前和向后遍历,因此查找操作的时间复杂度为 O(1)。但是,双向链表的插入和删除操作需要更多的指针操作,时间复杂度较高。由于双向链表需要更多的存储空间来存储额外的指针,因此空间复杂度也较高。 |
| 内核链表 | 内核链表的链表节点不直接包含数据。这样的设计使得同一个链表结构可以用于不同类型的数据节点。 由于链表节点与数据分离,可以方便地将链表结构嵌入到各种数据结构中,提高了代码的复用性和灵活性。 |
内核链表的操作
1. 初始化
在创建链表之前,需要先对链表头进行初始化。这通常包括设置链表头的指针为NULL(对于
单向链表)或指向自身(对于双向循环链表)。
typedef struct knode
{struct knode *ppre;struct knode *pnext;}Knode_t;typedef struct klink
{Knode_t *phead;int clen;pthread_mutex_t mutex;
}Klink_t;
2. 插入节点
在链表中插入节点时,需要找到插入位置的前一个节点,并修改该节点和待插入节点的指
针。对于双向链表,还需要更新待插入节点的前驱指针。
int push_klink_head(Klink_t *pklink, void *p)
{Knode_t *pnode = (Knode_t *)p;pnode->pnext = NULL;pnode->ppre = NULL;pnode->pnext = pklink->phead;if (pklink->phead != NULL){pklink->phead->ppre = pnode;}pklink->phead = pnode;pklink->clen++;return 0;
}
int push_klink_tail(Klink_t *pklink,void *p)
{Knode_t *pnode = (Knode_t *)p;pnode->pnext =NULL;pnode->ppre =NULL;if(pklink->phead!=NULL){Knode_t *p = pklink->phead;while(p->pnext!=NULL){p=p->pnext;}p->pnext=pnode;pnode->ppre=p;}else if(pklink->phead==NULL){pklink->phead = pnode;}pklink->clen++;return 0;
}3. 删除节点
删除链表中的节点时,需要找到该节点的前一个节点和后一个节点,并修改它们的指针以绕
过被删除的节点。对于双向链表,还需要更新被删除节点的前驱指针的指向。
int pop_klink_head(Klink_t *pklink)
{if(pklink->phead ==NULL){return 0;}Knode_t *p = pklink->phead;pklink->phead = p->pnext;p->ppre = NULL;free(p);if(pklink->phead !=NULL){pklink->phead->ppre=NULL;}pklink->clen--;return 0;
}
int pop_klink_tail(Klink_t *pklink)
{if(pklink->phead==NULL){return 0;}Knode_t *p = pklink->phead;while(p->pnext != NULL){p=p->pnext;}if(p->ppre!= NULL){p->ppre->pnext=NULL;}else{pklink->phead = NULL;}free(p);pklink->clen--;return 0;
}4. 遍历链表
遍历链表通常从链表头开始,依次访问每个节点直到链表末尾。在双向链表中,可以从链表
头或链表尾开始遍历。
void klink_for_each(Klink_t *pklink, void (*pfun)(void *))
{Knode_t *pnode = pklink->phead;while (pnode != NULL){pfun(pnode);pnode = pnode->pnext;}printf("\n");
}
5.查找
KNode_t *find_klink(KLink_t *pklink, void *t, CMP_t pfun)
{KNode_t *pnode = pklink->phead;while (pnode != NULL){if (pfun(t, pnode)){return pnode;}pnode = pnode->pnext;}return NULL;
}
6.销毁
int is_empty_klink(KLink_t *pklink)
{return NULL == pklink->phead;
}
void destroy_klink(KLink_t *pklink)
{while (!is_empty_klink(pklink)){pop_klink_head(pklink);}free(pklink);
}相关文章:

数据结构————内核链表
内核链表是Linux内核中广泛使用的一种数据结构,它具有以下特点: 1.双向循环链表:每个节点包含两个指针,一个指向前驱节点(prev),另一个指向后继节点(next),…...

使用API接口获取某宝商品数据详情
什么是淘宝API接口? 淘宝API接口是淘宝开放平台为开发者提供的一种应用程序接口。它允许开发者通过编程方式,安全、高效地与淘宝平台进行数据交互,从而获取商品详细信息、用户信息、订单信息等多种数据。这些接口不仅简化了数据获取流程&…...

用Python实现时间序列模型实战——Day 15: 时间序列模型的选择与组合
一、学习内容 1. 模型选择的标准与方法(如 AIC、BIC) 在时间序列建模中,模型的选择是非常重要的,常用的模型选择标准包括 AIC (Akaike Information Criterion) 和 BIC (Bayesian Information Criterion)。 AIC (Akaike Informat…...

大数据之Flink(五)
15、Flink SQL 15.1、sql-client准备 启用Hadoop集群(在Hadoop100上) start-all.sh启用yarn-session模式 /export/soft/flink-1.13.0/bin/yarn-session.sh -d启动sql-client bin/sql-client.sh embedded -s yarn-sessionsql文件初始化 可以初始化模式、环境(流/批…...

SWAP作物生长模型安装教程、数据制备、敏感性分析、气候变化影响、R模型敏感性分析与贝叶斯优化、Fortran源代码分析、气候数据降尺度与变化影响分析
查看原文>>>全流程SWAP农业模型数据制备、敏感性分析及气候变化影响实践技术应用 SWAP模型是由荷兰瓦赫宁根大学开发的先进农作物模型,它综合考虑了土壤-水分-大气以及植被间的相互作用;是一种描述作物生长过程的一种机理性作物生长模型。它不但…...

基于 jenkins 的持续测试方案
CI/CD Continuous Integration; Continuous Deployment; 持续集成,将新代码和旧代码一起打包、构建;持续部署,将新构建的包进行部署;持续测试,将新代码、新单元测试一起测试;方案: 公有云DevO…...

我算见识到算法岗transformer面试的难度了
在面试算法岗的时候看到了这篇Transformer面试题,作者梳理一些关于Transformer的知识点,还会陆续更新最新的面试题和讲解答案! 也算是见识到了transformer的面试难度了 1.Transformer为何使用多头注意力机制?(为什么不使用一个头) 2.Tra…...
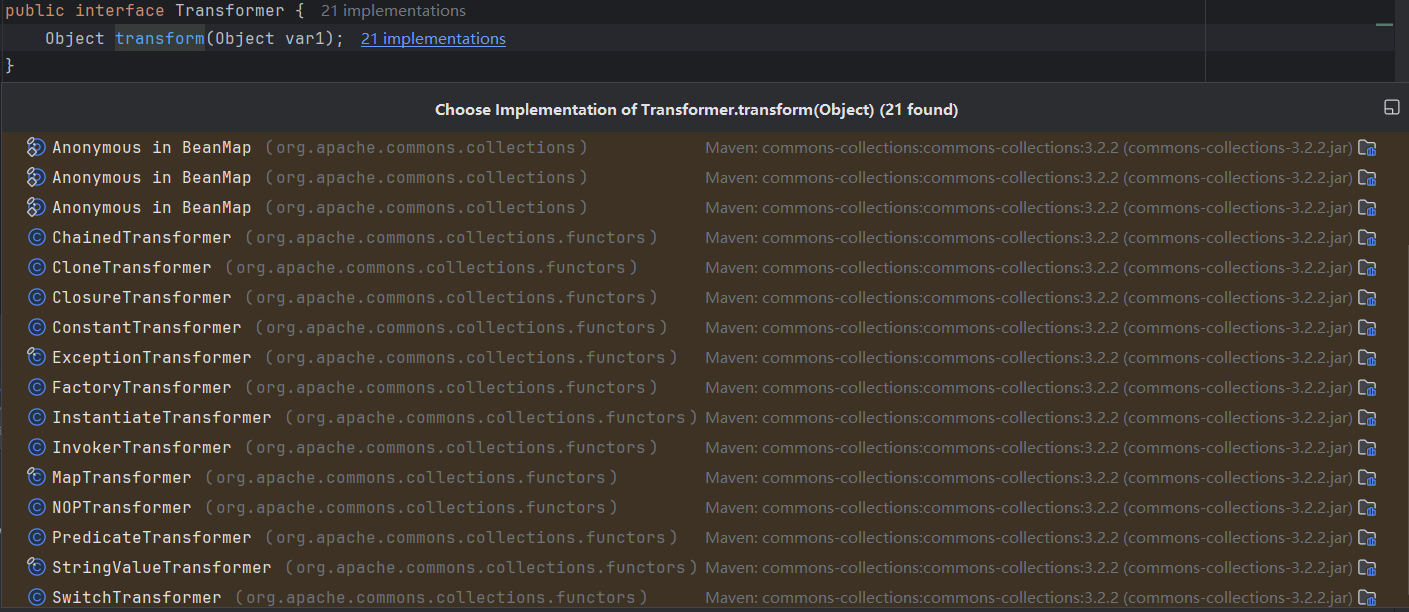
CommonCollections1
CommonCollections1链 CommonCollections1poc展示调用链分析AbstractInputCheckedMapDecoratorTransformedMapChainedTransformerConstantTransformerInvokerTransformer poc分析通过反射实现Runtime.getRuntime().exec("calc.exe")forNamegetMethodinvoke 依据反射构…...

6、关于Medical-Transformer
6、关于Medical-Transformer Axial-Attention原文链接:Axial-attention Medical-Transformer原文链接:Medical-Transformer Medical-Transformer实际上是Axial-Attention在医学领域的运行,只是在这基础上增加了门机制,实际上也就…...

19_单片机开发常用工具的使用
工欲善其事必先利其器,我们做单片机开发的时候,不管是调试电路还是调试程序,都需要借助一些辅助工具来帮助查找和定位问题,从而帮助我们顺利解决问题。没有任何辅助工具的单片机项目开发很可能就是无法完成的任务,不过…...

最新版微服务项目搭建
一,项目总体介绍 在本项目中,我将使用alibabba的 nacos 作为项目的注册中心,使用 spring cloud gateway 做为项目的网关,用 openfeign 作为服务间的调用组件。 项目总体架构图如下: 注意:我的Java环境是17…...

spring揭秘19-spring事务01-事务抽象
文章目录 【README】【1】事务基本元素【1.1】事务分类 【2】java事务管理【2.1】基于java的局部事务管理【2.2】基于java的分布式事务管理【2.2.1】基于JTA的分布式事务管理【2.2.2】基于JCA的分布式事务管理 【2.3】java事务管理的问题 【3】spring事务抽象概述【3.1】spring…...

基于Matlab的图像去雾系统(四种方法)关于图像去雾的基本算法代码的集合,方法包括局部直方图均衡法、全部直方图均衡法、暗通道先验法、Retinex增强。
基于Matlab的图像去雾系统(四种方法) 关于图像去雾的基本算法代码的集合,方法包括局部直方图均衡法、全部直方图均衡法、暗通道先验法、Retinex增强。 所有代码整合到App designer编写的GUI界面中,包括导入图片,保存处…...

油猴插件录制请求,封装接口自动化参数
参考:如何使用油猴插件提高测试工作效率 一、背景 在酷家乐设计工具测试中,总会有许多高频且较繁琐的工作,比如: 查询插件版本:需要打开Chrome控制台,输入好几个命令然后过滤出版本信息。 查询模型商品&…...

循环购模式!结合引流和复购于一体的商业模型!
欢迎各位朋友,我是你们的电商策略顾问吴军。今天,我将向大家介绍一种新颖的商业模式——循环购模式,它将如何改变我们的消费和收益方式。你是否好奇,为何商家会提供如此慷慨的优惠?消费一千元,不仅能够得到…...

Ilya-AI分享的他在OpenAI学习到的15个提示工程技巧
Ilya(不是本人,claude AI)在社交媒体上分享了他在OpenAI学习到的15个Prompt撰写技巧。 以下是详细的内容: 提示精确化:在编写提示时,力求表达清晰准确。清楚地阐述任务需求和概念定义至关重要。例:不用"分析文本",而用&…...

c中 int 和 unsigned int
c语言中,char、short、int、int64以及unsigned char、unsigned short、unsigned int、unsigned int64等等类型都可以表示整数。但是他们表示整数的位数不同,比如:char/unisigned char表示8位整数; short/unsigned short表示16位整…...

sheng的学习笔记-AI-话题模型(topic model),LDA模型,Unigram Model,pLSA Model
AI目录:sheng的学习笔记-AI目录-CSDN博客 基础知识 什么是话题模型(topic model) 话题模型(topic model)是一族生成式有向图模型,主要用于处理离散型的数据(如文本集合),在信息检索、自然语言处理等领域有广泛应用…...

html 页面引入 vue 组件之 http-vue-loader.js
一、http-vue-loader.js http-vue-loader.js 是一个 Vue 单文件组件加载器,可以让我们在传统的 HTML 页面中使用 Vue 单文件组件,而不必依赖 Node.js 等其他构建工具。它内置了 Vue.js 和样式加载器,并能自动解析 Vue 单文件组件中的所有内容…...

html+css网页设计 旅行 蜘蛛旅行社3个页面
htmlcss网页设计 旅行 蜘蛛旅行社3个页面 网页作品代码简单,可使用任意HTML辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及修改编辑等操作)。 获取源码 1&#…...

基于MultiFold无分箱反卷积的轻子-喷注方位角不对称性测量
1. 项目概述与核心物理动机在粒子物理的高能前沿,我们常常通过“撞击”基本粒子来窥探其内部结构,深度非弹性散射(DIS)就是其中最经典、最有力的探针之一。想象一下,你用一束极高能量的电子(或正电子&#…...

OpenRA中稳定获取应用程序目录的C#实践
1. 这不是“获取当前路径”那么简单:OpenRA里目录逻辑的特殊性很多人第一次在OpenRA项目里写C#代码时,会下意识地用Directory.GetCurrentDirectory()或者AppDomain.CurrentDomain.BaseDirectory去拿“程序所在文件夹”,结果发现——要么返回的…...

7自由度机械臂逆运动学求解:13种算法对比与混合策略实战
1. 项目概述:当机械臂遇到“无限可能”的烦恼在机器人领域,让机械臂的“手”(末端执行器)精准地到达一个指定的位置和姿态,是一个看似简单实则复杂的基础问题,这就是逆运动学。对于常见的6自由度机械臂&…...

ET框架:Unity游戏服务端的工业级架构实践
1. 这不是又一个“Unity做服务器”的噱头,而是把游戏服务端从“能跑”推进到“可维、可扩、可测”的分水岭“ET框架革命:Unity游戏服务器开发的终极解决方案”——这个标题里,“革命”二字不是修辞,是实打实的工程范式切换&#x…...
)
Windows11下Detectron2安装避坑指南:从CUDA版本匹配到源码修改(附常见错误解决方案)
Windows 11下Detectron2深度安装指南:从环境配置到源码级问题解决 在计算机视觉领域,Detectron2作为Facebook Research推出的开源框架,凭借其模块化设计和出色的性能表现,已成为目标检测、实例分割等任务的首选工具之一。然而&…...

FPGA加速机器学习在粒子物理触发系统中的应用与实战
1. 项目概述:当FPGA遇上机器学习,为粒子物理装上“火眼金睛” 在大型强子对撞机(LHC)的心脏地带,每秒发生着数亿次质子对撞。每一次对撞都可能产生希格斯玻色子、顶夸克,或是我们尚未知晓的新物理现象。然而…...

基于FeFET的动态可重构FPGA:实现亚纳秒级上下文切换的硬件加速新架构
1. 项目概述与核心挑战如果你在硬件加速领域摸爬滚打过几年,大概率会对FPGA又爱又恨。爱的是它无与伦比的灵活性,恨的是它在“灵活”和“高效”之间那道难以逾越的鸿沟。传统基于SRAM的FPGA,其可重构性是通过烧写配置位流到SRAM单元来实现的。…...

用格拉姆矩阵特征值调整替代SVD,高效求解带正交约束的优化问题
1. 项目概述与核心问题在机器学习和数值优化的世界里,我们经常遇到一个经典难题:如何在一个带约束的复杂空间里,找到那个“最好”的解。这就像在一个布满规则的迷宫里寻找宝藏,你不能横冲直撞,必须遵守墙壁(…...

电池阻抗测量技术:伪随机序列与信号处理应用
1. 电池阻抗测量技术概述电池阻抗测量作为电化学系统状态监测的核心手段,其原理基于对电池施加特定激励信号并测量响应信号,通过分析两者的幅值和相位关系来获取阻抗谱。这种频域分析方法能够反映电池内部电荷转移、扩散过程等动力学特性,为电…...

NVIDIA Geforce RTX 5060 Ti显卡能本地部署的哪些AI应用?
我为你整理了NVIDIA GeForce RTX 5060 Ti显卡的核心规格,以及它能在本地运行的常见AI模型和应用。 📋 RTX 5060 Ti 核心规格速览 这张卡是NVIDIA RTX 50系列中面向主流市场的一员,在AI方面最大的亮点是可选16GB显存版,这对本地运行…...