transforemr网络理解
1.transformer网络中数据的流动过程:



2.transformer中残差的理解:
残差连接(Residual Connection) 的核心思想就是通过将输入与经过变化的输出相加,来最大限度地保留原始信息。

transforemr中注意力层网络和前馈神经网络的区别?
自注意力机制(Self-Attention Mechanism)
作用:
自注意力机制的主要作用是根据输入序列中的每个元素,动态地关注序列中其他相关元素。这种机制允许模型捕捉序列中不同位置的全局依赖关系,从而使得信息在整个序列中进行交互。
工作机制:
自注意力机制通过计算输入序列的 查询(Query)、键(Key) 和 值(Value) 矩阵,来决定每个输入元素与其他元素的相关性。相关性用点积注意力得分表示,并根据这些注意力得分对序列中的值进行加权求和。这样,序列中的每个位置都能根据其他位置的信息来更新自身的表示。
前馈神经网络:
作用:
前馈神经网络的主要作用是对每个输入元素进行独立的非线性变换。FFNN 在自注意力之后用于进一步处理和转化信息,但它并不考虑输入序列中元素之间的相互关系。
工作机制:
前馈神经网络通常是一个逐元素(即对每个序列位置单独操作)的两层全连接神经网络,带有激活函数。每个元素被映射到更高维度,然后再映射回原来的维度。

transformer中每个元素生成的对应的q,k,v是怎么生成的呢?


举个例子介绍:

3.Q,K,V矩阵在注意力机制中的作用:
 - 注意力机制(Self-Attention)的确主要作用是寻找序列中两个元素之间的相似性。它通过计算查询向量(Q)和键向量(K)的点积,来衡量序列中元素之间的关系或依赖性,并根据这些相似性来加权值向量(V)。这种机制使得每个元素都能动态调整自身表示,能够捕捉输入序列中全局的信息。简单来说,注意力机制在做的是“找相似”:通过 Q 和 K 的相关性,决定每个元素与其他元素的关联程度。
- 注意力机制(Self-Attention)的确主要作用是寻找序列中两个元素之间的相似性。它通过计算查询向量(Q)和键向量(K)的点积,来衡量序列中元素之间的关系或依赖性,并根据这些相似性来加权值向量(V)。这种机制使得每个元素都能动态调整自身表示,能够捕捉输入序列中全局的信息。简单来说,注意力机制在做的是“找相似”:通过 Q 和 K 的相关性,决定每个元素与其他元素的关联程度。
- 前馈神经网络(Feedforward Neural Network,
FFN)则是在序列的每个元素上独立进行非线性变换,相当于寻找一个拟合能力比较强的函数。它不关注元素间的依赖关系,而是通过复杂的非线性变换(通常是带有激活函数的全连接层)增强模型对数据的表达能力。FFN 可以理解为一种增强模型对复杂模式的拟合能力的操作。简单来说,前馈神经网络在做的是“拟合非线性函数”:通过对输入的复杂非线性变换,提升模型对输入的表达和拟合能力。
总结: - 注意力机制:主要作用是寻找序列中元素之间的相似性和依赖性。
- 前馈神经网络:主要作用是增强模型的非线性表达能力,相当于寻找一个拟合复杂模式的函数。
从矩阵变换的角度来理解transformer框架
从矩阵变换的角度解读 Transformer 框架时, 主要可以通过矩阵的操作理解整个模型中的计算过程, 特别是在自注意力机制、残差连接和前馈神经网络中。
- 输入与嵌入层
- 首先, 输入的序列通常是经过嵌入 (embedding) 后的词向量, 假设输入序列长度为 N N N, 每个词向量的维度为 d model d_{\text {model }} dmodel 。嵌入的结果就是一个 N × d model N \times d_{\text {model }} N×dmodel 的矩阵, 表示为 X X X 。
- X X X 会加入位置编码(Positional Encoding), 该位置编码也是一个矩阵, 大小同样为 N × d model N \times d_{\text {model }} N×dmodel ,它帮助模型捕捉序列中元素的顺序信息。
2.自注意力机制

注意力打分计算:
- 计算查询矩阵 Q Q Q 与键矩阵 K K K 的点积:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
这一步通过矩阵乘法 Q K T Q K^T QKT 来得到元素间的相似性得分。结果是一个 N × N N \times N N×N的矩阵,表示每个序列元素对其他元素的注意力权重。
权重矩阵与值矩阵相乘:
- 计算得到的注意力权重矩阵与 V V V 矩阵相乘, 得到最终的注意力输出。这样, 每个元素的输出实际上是其他元素的加权组合。
- 自注意力机制的整个过程可以看作是基于矩阵乘法的线性变换。通过这些矩阵乘法,模型能够捕捉到序列中不同位置间的依赖关系。
- 残差连接与层归一化
- 在自注意力机制计算完成后, 输出的矩阵会通过残差连接和层归一化操作。残差连接就是将输入 X X X 加到自注意力的输出上:
Z = LayerNorm ( X + Attention ( Q , K , V ) ) Z=\operatorname{LayerNorm}(X+\operatorname{Attention}(Q, K, V)) Z=LayerNorm(X+Attention(Q,K,V))
这里的加法是矩阵元素对应位置的相加, 这样可以帮助信息更好地传播, 避免梯度消失。
- 前馈神经网络
- 接下来的前馈神经网络对每个位置的表示进行独立的非线性变换。它也是通过两个线性变换完成的:
FFN ( Z ) = ReLU ( Z W 1 + b 1 ) W 2 + b 2 \operatorname{FFN}(Z)=\operatorname{ReLU}\left(Z W_1+b_1\right) W_2+b_2 FFN(Z)=ReLU(ZW1+b1)W2+b2
其中, W 1 W_1 W1 和 W 2 W_2 W2 是权重矩阵, b 1 b_1 b1 和 b 2 b_2 b2 是偏置。这个过程可以看作是对输入矩阵进行两次线性变换, 中间夹带 ReLU 激活函数。
transformer中的多头注意力机制的理解。
自注意力机制的并行化主要指的是多头注意力机制 (Multi-Head Attention)。这种机制通过将自注意力分成多个头来并行处理不同的子空间,从而提高模型的表示能力。我们来详细解释一下多头注意力的并行化原理。
- 单头注意力机制
在常规的自注意力机制中, 输入的每个序列元素通过生成查询矩阵 Q Q Q 、键矩阵 K K K和值矩阵 V V V 来计算注意力得分, 并最终通过注意力得分对序列元素进行加权组合。这个过程本质上是通过点积来捕捉序列中不同元素之间的依赖关系, 并生成新的表示。
但是, 单头注意力只能学习到一种特定的注意力模式, 可能不足以捕捉复杂的依赖关系。尤其是对于输入的不同特征, 模型可能希望从多个角度来捕捉序列元素之间的联系。 - 多头注意力机制
为了增强模型的表示能力,多头注意力机制被提出。它的核心思想是将输入的数据划分成多个注意力头(heads),每个注意力头在一个子空间中独立计算注意力,然后将各个头的结果拼接起来。这种方式允许模型从不同的角度来观察输入序列,从而捕捉到更丰富的关系。
具体操作流程: - 生成多个头的 Q , K , V Q, K, V Q,K,V 矩阵:
- 对输入的矩阵 X X X 通过不同的线性变换生成多个不同的 Q , K , V Q, K, V Q,K,V 矩阵。假设有 h h h 个头, 则每个头都会有自己的查询、键和值矩阵。
Q i = X W Q i , K i = X W K i , V i = X W V i Q_i=X W_Q^i, \quad K_i=X W_K^i, \quad V_i=X W_V^i Qi=XWQi,Ki=XWKi,Vi=XWVi
其中 W Q i , W K i , W V i W_Q^i, W_K^i, W_V^i WQi,WKi,WVi 是第 i i i 个头的线性变换权重。
2. 计算每个头的自注意力:
- 对每个头进行自注意力计算, 步骤与单头注意力相同。具体为:
Attention i = softmax ( Q i K i T d k ) V i \text { Attention }_i=\operatorname{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right) V_i Attention i=softmax(dkQiKiT)Vi
这一步会为每个头生成独立的注意力输出。
3. 拼接多个头的结果:
- 在得到所有注意力头的输出后, 将这些结果沿着特征维度进行拼接:
Concat ( head 1 , head 2 , … , head h ) \text { Concat }\left(\text { head }_1, \text { head }_2, \ldots, \text { head }_h\right) Concat ( head 1, head 2,…, head h)
这个拼接操作将所有头的输出组合成一个大的矩阵, 表示模型对输入的多角度注意力表示。
并行化的本质:
在计算多头注意力时,每个注意力头的计算是完全独立的,这意味着所有的头可以并行计算。这也是多头注意力机制的一大优势——并行计算能够提升计算效率,同时还可以增加模型的表示能力。
在硬件层面,GPU 等加速器非常擅长并行化操作,因此可以轻松处理多头注意力机制中的多个矩阵乘法操作。在实际应用中,这种并行化大大减少了模型的训练和推理时间。
相关文章:
transforemr网络理解
1.transformer网络中数据的流动过程: 2.transformer中残差的理解: 残差连接(Residual Connection) 的核心思想就是通过将输入与经过变化的输出相加,来最大限度地保留原始信息。 transforemr中注意力层网络和前馈神经…...

C++插件管理系统
插件加载目录结构 execute plug.exe plugify.dll plugify.pconfig res cpp-lang-module.pmodule example_plugin.pplugin bin cpp-lang-module.dll example_plugin.dll plugify.pconfig { "baseDir&…...

MyBatis 方法重载的陷阱及解决方案
在使用 MyBatis 进行开发时,尤其是使用注解模式(如 Select、Insert 等)时,开发者常常会遇到这样一个问题:为什么我的方法重载不能正常工作? 即使在 Java 中允许方法名相同但参数不同的重载,MyBa…...

STM32 ADC+DMA导致写FLASH失败
最近用STM32G070系列的ADCDMA采样时,遇到了一些小坑记录一下; 一、ADCDMA采样时进入死循环; 解决方法:ADC-dma死循环问题_stm32 adc dma死机-CSDN博客 将ADC的DMA中断调整为最高,且增大ADCHAL_ADC_Start_DMA(&ha…...

Python AttributeError: ‘dict_values’ object has no attribute ‘index’
Python AttributeError: ‘dict_values’ object has no attribute ‘index’ 在Python编程中,AttributeError 是一个常见的异常类型,通常发生在尝试访问对象没有的属性或方法时。今天,我们将深入探讨一个具体的 AttributeError:“…...
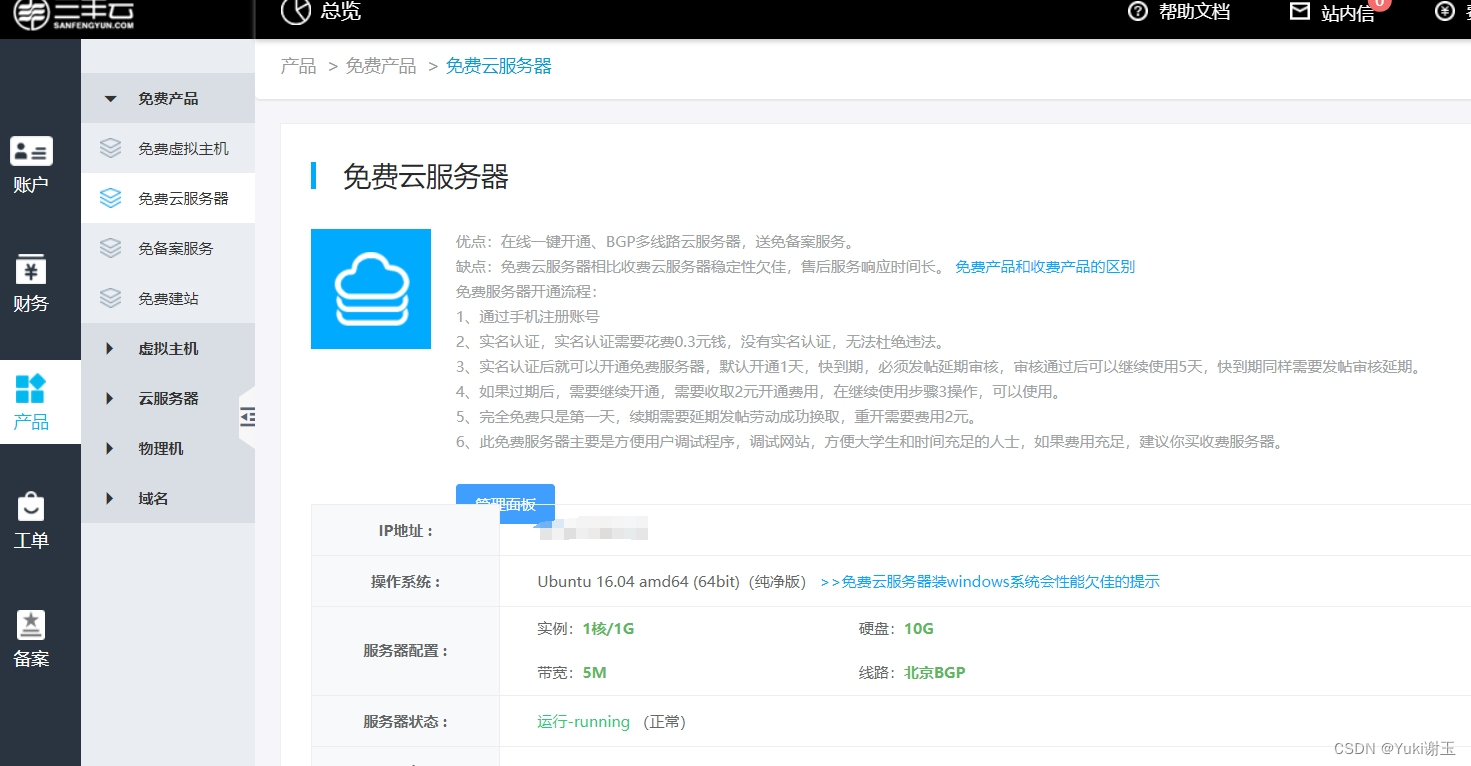
三丰云免费虚拟主机和免费云服务器评测
三丰云是一家提供免费虚拟主机和免费云服务器的知名服务提供商,深受用户好评。在这篇评测文章中,我们将对三丰云的免费虚拟主机和免费云服务器进行细致评测。 首先,我们来看看三丰云的免费虚拟主机服务。三丰云的免费虚拟主机提供稳定的服务器…...
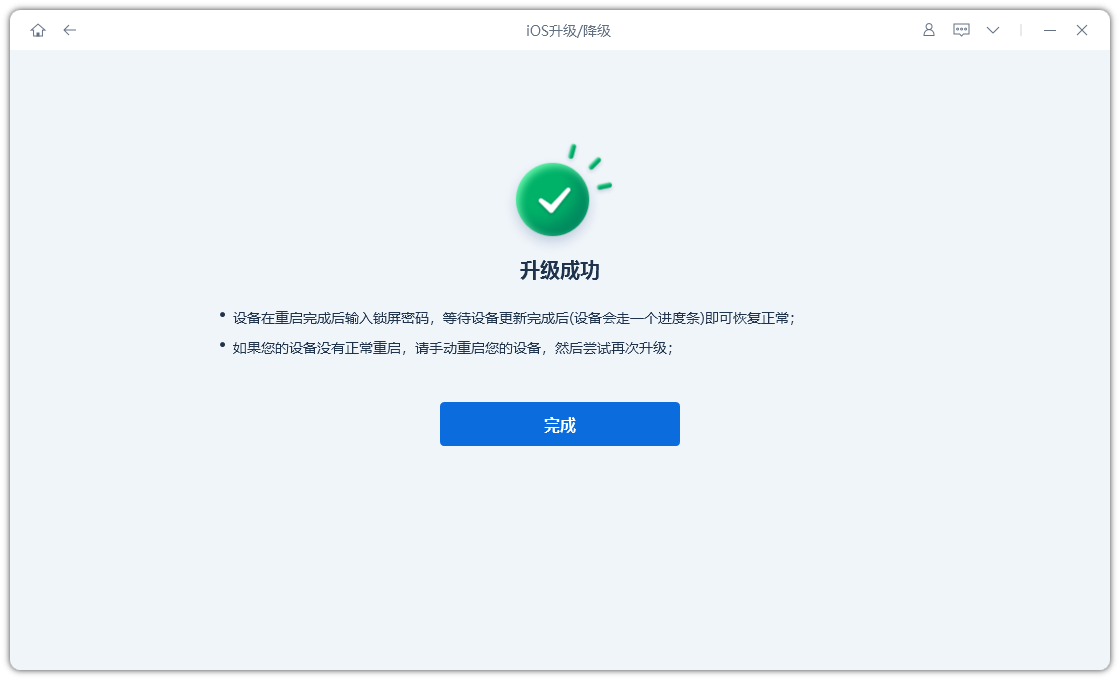
iOS18更新暂停卡住?iOS18升级失败解决办法分享
最近,苹果发布了iOS 18,许多用户都迫不及待更新更新系统体验新功能。然而,一些用户在网上反馈在iOS 18 更新在安装过程中会卡住或暂停,无法正常升级成功。 如果遇到“iOS 18更新暂停或卡住”问题,不用担心。在本文中&a…...

单片机软件工程师确认硬件
文章目录 简介流程确认能连接usb和调试器确认芯片信息确认芯片存储是否正常确认屏幕是否能点亮确认其他硬件 方式方法 简介 硬件工程师给出板子后,后面就是软件工程师的事儿了。 通常来说并不会很顺利。 流程 确认能连接usb和调试器 也是在“计算机管理”中 或者…...

乐鑫无线WiFi芯片模组,家电设备智能联网新体验,启明云端乐鑫代理商
在当今这个数字化飞速发展的时代,智能家居和物联网(IoT)设备已经成为我们生活中不可或缺的一部分。随着技术的进步,我们对于设备联网的需求也在不断提升。 智能家居、智能门锁、智能医疗设备等,这些设备通过联网实现了数据的实时传输和远程控…...

小米嵌入式面试题目RTOS面试题目 嵌入式面试题目
第一章-非RTOS bootloader工作流程 MCU启动流程 通信协议,SPI IIC MCU怎么选型,STM32F1和F4有什么区别 外部RAM和内部RAM区别,怎么分配 外部总线和内部总线区别 MCU上的固件,数据是怎么分配的 MCU启动流程 IAP是怎么升级的…...

Iceberg与SparkSQL写操作整合
前言 spark操作iceberg之前先要配置spark catalogs,详情参考Iceberg与Spark整合环境配置。 有些操作需要在spark3中开启iceberg sql扩展。 Iceberg使用Apache Spark的DataSourceV2 API来实现数据源和catalog。Spark DSv2是一个不断发展的API,在Spark版…...
MYSQL1
一、为什么学习数据库 1、岗位技能需求 2、现在的世界,得数据者得天下 3、存储数据的方法 4、程序,网站中,大量数据如何长久保存? 5、数据库是几乎软件体系中最核心的一个存在。 二、数据库相关概念 (一)数据库DB 数据库是将大量数据保存起来,通过计算机加…...

一文解答Swin Transformer + 代码【详解】
文章目录 1、Swin Transformer的介绍1.1 Swin Transformer解决图像问题的挑战1.2 Swin Transformer解决图像问题的方法 2、Swin Transformer的具体过程2.1 Patch Partition 和 Linear Embedding2.2 W-MSA、SW-MSA2.3 Swin Transformer代码解析2.3.1 代码解释 2.4 W-MSA和SW-MSA…...

Vue3:<Teleport>传送门组件的使用和注意事项
你好,我是沐爸,欢迎点赞、收藏、评论和关注。 Vue3 引入了一个新的内置组件 <Teleport>,它允许你将子组件树渲染到 DOM 中的另一个位置,而不是在父组件的模板中直接渲染。这对于需要跳出当前组件的 DOM 层级结构进行渲染的…...
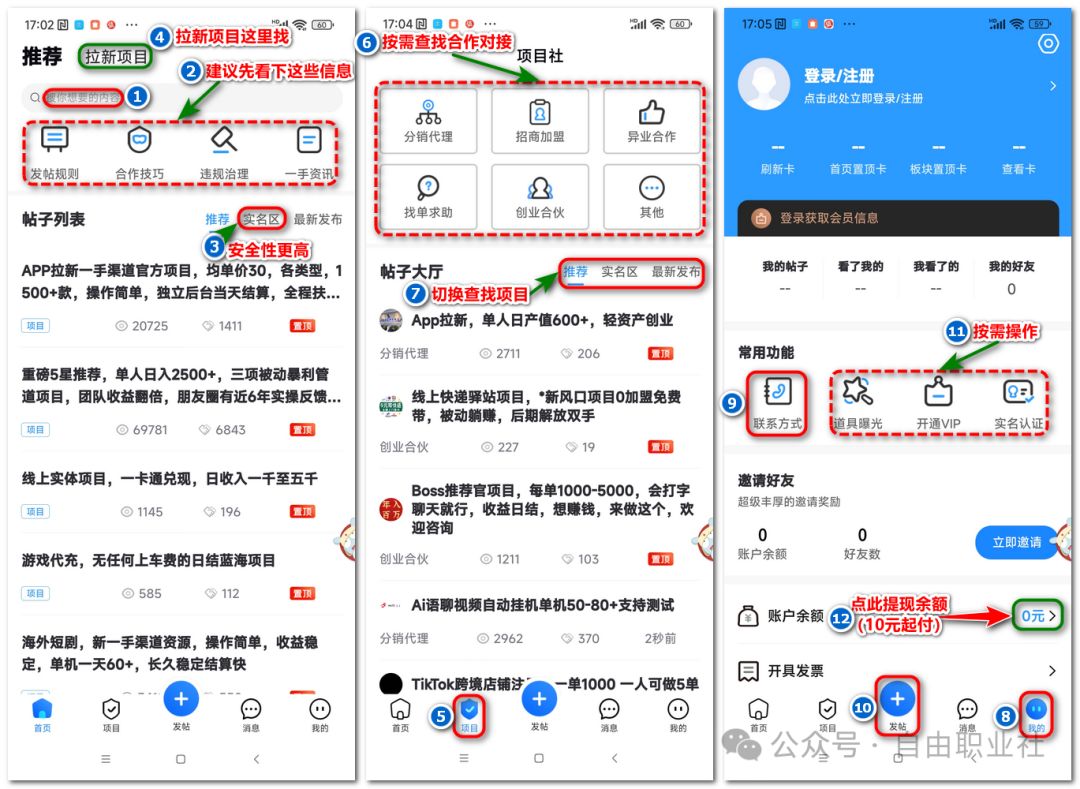
项目之家:又一家项目信息发布合作对接及一手接单平台
这几天“小三劝退师时薪700”的消息甚嚣尘上,只能说从某一侧面来看心理咨询师这个职业的前景还是可以的,有兴趣的朋友可以关注下。话说上一篇文章给大家介绍了U客直谈,今天趁热打铁再给大家分享一个地推拉新项目合作平台~项目之家:…...

02-java实习工作一个多月-经历分享
一、描述一下最近不写博客的原因 离我发java实习的工作的第一天的博客已经过去了一个多月了,本来还没入职的情况是打算每天工作都要写一份博客来记录一下的(最坏的情况也是每周至少总结一下的),其实这个第一天的博客都是在公司快…...

JVM 调优篇2 jvm的内存结构以及堆栈参数设置与查看
一 jvm的内存模型 2.1 jvm内存模型概览 二 实操案例 2.1 设置和查看栈大小 1.代码 /*** 演示栈中的异常:StackOverflowError** author shkstart* create 2020 下午 9:08** 设置栈的大小: -Xss (-XX:ThreadStackSize)** -XX:PrintFlagsFinal*/ public class S…...

微信可以设置自动回复吗?
在日常的微信聊天中,我们或许会频繁地遭遇客户提出的相同问题,尤其是对于从事销售工作的朋友们来说,客户在添加好友后的第一句话往往是“在吗”或者“你好”。当我们的好友数量众多时,手动逐个回复可能会耗费大量的时间。因此&…...

同样数据源走RTMP播放延迟低还是RTSP低?
背景 在比较同一个数据源,是RTMP播放延迟低还是RTSP延迟低之前,我们先看看RTMP和RTSP的区别,我们知道,RTMP(Real-Time Messaging Protocol)和RTSP(Real Time Streaming Protocol)是…...

@开发者极客们,网易2024低代码大赛来啦
极客们,网易云信拍了拍你 9月6日起,2024网易低代码大赛正式开启啦! 低代码大赛是由网易主办的权威赛事,鼓励开发者们用低代码开发的方式快速搭建应用,并最终以作品决出优胜。 从2022年11月起,网易低代码大赛…...
,实测涨点还省显存)
别再只用MaxPool了!试试在YOLOv9里集成Haar小波下采样(HWD),实测涨点还省显存
突破传统下采样瓶颈:YOLOv9集成Haar小波下采样的实战指南当你在训练YOLOv9模型时,是否遇到过这样的困境——为了提升检测精度而增加模型复杂度,却发现显存迅速耗尽;或是采用激进的下采样策略后,小目标检测性能明显下降…...

《离别的最后》的内容入口:收尾场景如何被记住
从内容传播角度看,《离别的最后》的入口在“最后”这个收束动作。它不是笼统告别,而是写到一段关系、一个阶段或一次转身即将落下尾音的时刻。这首歌不适合被写成普通伤感推荐。更准确的角度,是把它放在收尾场景里:删掉草稿、收起…...

单一职责原则 登录功能重构笔记
核心定义单一职责原则:一个类只干一件事,只有一个修改的理由,避免功能杂糅、代码耦合。原有问题原始 Login 登录类,把界面展示、数据库连接、数据查询、登录校验、程序启动全部堆在一个类里,职责混乱,任何小…...

深度学习优化器原理与图像分类实战指南
1. 项目概述:为什么优化器不是“调参配菜”,而是图像分类器的“神经节律控制器”你训练一个ResNet-50做CIFAR-10分类,学习率设成0.1,用SGD跑50轮,测试准确率卡在87.3%;换Adam,同样0.1学习率&…...

收藏!2026 程序员破局:Java 寒冬已至,大模型才是真风口
凌晨一点半,手机屏幕突然亮起,是做Java后端开发的发小发来的消息,字里行间全是慌乱与不甘:“刚收到公司裁员通知,名单已经定死了,我真的懵了——部门里干了五年的资深老程都没保住,我这三年经验…...

《纳瓦尔宝典》哲学篇精读:程序员的终极精神解药
本文是《纳瓦尔宝典》第五部分"哲学"的完整精读笔记,专为在技术洪流中迷失方向、陷入存在主义焦虑的程序员群体打造。纳瓦尔的哲学不是象牙塔里的空洞思辨,而是一套经过他亲身验证的、可落地的生活操作系统,能帮你在快速变化的世界…...

windows VS工具判断动态库是32位还是64位
dumpbin /headers yourfile.dll | findstr "machine"...

基于DSP与SC1083 ADC的光纤远程数据采集系统设计实战
1. 项目概述:当DSP遇上高速光缆,如何构建一个“快、准、稳”的远程数据采集系统在工业自动化、电力监测、超声无损检测这些领域,我们经常需要面对一个头疼的问题:如何把现场传感器采集到的大量、高速、有时甚至是微弱的模拟信号&a…...

优化缺陷密度,核心是从“事后救火”转向“全程预防”
优化缺陷密度,核心是从“事后救火”转向“全程预防”,通过系统化的流程和工具,在生产代码中构建 “计划-执行-检查-改进”的持续优化闭环。📈 第一步:测量与评估,建立基线测量缺陷密度:按质量阶…...

HTTPS抓包失败原因与Burp CA证书信任配置全指南
1. 为什么HTTPS抓包总卡在“连接失败”?——这不是网络问题,是证书信任链没打通你打开Burp Suite,配置好代理,浏览器也设成127.0.0.1:8080,一访问https://example.com,页面直接报“您的连接不是私密连接”&…...