MYSQL1
一、为什么学习数据库
1、岗位技能需求
2、现在的世界,得数据者得天下
3、存储数据的方法
4、程序,网站中,大量数据如何长久保存?
5、数据库是几乎软件体系中最核心的一个存在。
二、数据库相关概念
(一)数据库DB
数据库是将大量数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合。
简单来讲就是存储数据的仓库。
(二)数据库管理系统DBMS
用来管理数据库的计算机系统称为数据库管理系统(DBMS)。比如MySQL
(三)DBMS的种类
1.关系数据库
关系数据库是现在应用最广泛的数据库。关系数据库在1969年诞生,可谓历史悠久。和Excel工作表一样,它也采用由行和列组成的二维表来管理数据,所以简单易懂(表1-1)。同时,它还使用专门的SQL(Structured Query Language,结构化查询语言)对数据进行操作。
比较具有代表性的RDBMS有如下5种:
-
OracleDatabase:甲骨文公司的RDBMS
-
SQLServer:微软公司的RDBMS
-
DB2:IBM公司的RDBMS
-
PostgreSQL:开源的RDBMS
-
MySQL:开源的RDBMS
2.非关系型数据库
-
- Redis , MongoDB , …
- 非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定
三、MySQL版本及版本号
对不同的用户,MySQL 分为两个版本:
- MySQL Community Server(社区版):该版本完全免费,但是官方不提供技术支持。
- MySQL Enterprise Server(企业版):该版本能够以很高的性价比为企业提供数据仓库应用,支持 ACID 事物处理,提供完整的提交、回滚、崩溃恢复和行级锁定功能,但是该版本需要付费使用,官方提供电话技术支持。
注意:MySQL Cluster 主要用于架设群服务器,需要在社区服务或企业版的基础上使用。
MySQL 的命名机制由 3 个数字和 1 个后缀组成,例如 mysql-5.7.20:
- 第 1 个数字“5”是主版本号,用于描述文件的格式,所有版本 5 的发行版都有相同的文件夹格式。
- 第 2 个数字“7”是发行级别,主版本号和发行级别组合在一起便构成了发行序列号。
- 第 3 个数字“20”是在此发行系列的版本号,随每次新发行的版本递增。通常选择已经发行的最新版本。
在 MySQL 开发过程中,同时存在多个发布系列,每个发布系列的成熟度处在不同阶段。
-
- MySQL 5.7 是最新开发的稳定(GA)发布系列,是将执行新功能的系列,目前已经可以正常使用。
- MySQL 5.6 是比较稳定的(GA)发布系列,只针对漏洞修复重新发布,不增加会影响稳定性的新功能。
- MySQL 5.1 是一个稳定的(产品质量)发布系列,只针对严重漏洞修复和安全修复重新发布,不增加影响该系列稳定性的重要功能。
注意:对于 MySQL 4.1 等低于 5.0 的老版本,官方将不再提供支持。所有发布的 MySQL 版本已经经过严格标准的测试,可以保证其安全可靠地使
四、MySQL安装
Windows安装
5.7版本
配置环境变量
五、常规操作
(一)登录与退出
-
登录
mysql -u root -p(注意空格)
-
退出
exit/quit
(二)服务的启动和关闭
计算机 右键 管理 服务 找到 MySQL56 可以启动和停止MySQL服务
(三)数据库导入导出
一般形式
#本地访问
mysqldump -u 用户名 -p -d 数据库名 > 导出的文件名#远程访问
mysqldump -h IP -u 用户名 -p -d 数据库名 > 导出的文件名
参数解析:
-h:表示host地址。windows本地操作不用写ip地址
-u:表示user用户
-p:表示password密码
-d:表示不导出数据
注意:
(1)-p 后面不能加password,只能单独输入数据库名称
(2)mysqldump是在cmd下的命令,不能再mysql下面,即不能进入mysql的(如果进入了mysql,得exit退出mysql后才可以的。)
导出
在Windows的dos命令窗口中直接执行
导出数据库结构和数据(此时不用加-d),如下导出库dbtest中所有表结构和数据
mysqldump -h 192.168.182.134 -u root -p dbtest > C:\Users\Administrator\Desktop\users2.sql
只导出数据库结构(此时要加-d),如下导出库dbtest结构
mysqldump -h 192.168.182.134 -u root -p -d dbtest > C:\Users\Administrator\Desktop\users2.sql
导出某张表结构和数据(此时不用加-d),如下导出库dbtest中的users表结构和数据
mysqldump -h 192.168.182.134 -u root -p dbtest users > C:\Users\Administrator\Desktop\users2.sql
导出某张表结构(此时要加-d),如下导出库dbtest中的users表结构
mysqldump -h 192.168.182.134 -u root -p -d dbtest users > C:\Users\Administrator\Desktop\users2.sql
导入
需要先登录数据库,然后创建数据库、使用数据库
前提已经建好数据库,导入数据库文件
登录
本地访问:
mysql -u root -p远程访问:
mysql -h 192.168.182.120 -uroot -p
参数解析:
-h:表示host地址,本地直接使用localhost,远程需要使用ip地址
-u:表示user用户
-p:表示password密码
登录成功后执行导入命令
source+文件路径
source C:\Users\Administrator\Desktop\users2.sql
(四)远程授权
远程授权属于DCL(数据控制语言)。
授予所有权限
#授权。
格式:grant all privileges on *.* to '用户名'@'%' identified by '密码' with grant option;例子:grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;#刷新权限,否则不会生效
flush privileges;
参数说明
- grant:赋权命令
- all privileges:当前用户的所有权限
- on:介词
- *.*:当前用户对所有数据库和表的相应操作权限
- to:介词
- ‘root’@‘%’:权限赋给root用户,%代表所有ip都能连接
- identified by ‘123456’:连接时输入密码,密码为123456
- with grant option:允许级联赋权
注意
-
如果别人远程访问不了的话,那么需要关掉本地的防火墙
-
如果想指定数据库和表名可以将 * . * 替换成以下格式
数据库名.表名
(五)MySQL5.7修改密码
1.windows修改
- 需要将mysql添加到环境变量中
mysqladmin修改
- 因为我们将bin已经添加到环境变量了,这个mysqladmin也在bin目录下,所以可以直接使用这个mysqladmin功能,使用它来修改密码
- 修改时要处于未登录状态
1.方法一
格式:mysqladmin -u用户名 -p旧密码 password 新密码例子:mysqladmin -u root -p 123456 password 1122332.方法二
语法:mysqladmin -u用户名 -p password 新密码例子:mysqladmin -u root -p password 112233
update修改
- update直接编辑那个自动的mysql库中的user表
- use mysql的意思是切换到mysql这个库,这个库是所有的用户表和权限相关的表都在这个库里面,我们进入到这个库才能修改这个库里面的表。
- mysql5.7 user表里已经去掉了password字段,改为了authentication_string。
1.先进行登录
mysql -u root -p2.切换mysql库
use mysql;3.修改
格式: update mysql.user set authentication_string=password('新密码') where user='用户名' and Host = 'ip';例子:update mysql.user set authentication_string=password('112233') where user='root' and Host = 'localhost';4.刷新权限
flush privileges;5.exit退出,重新登录
注意:如果Mysql的版本是5.7以下的话update语句更换如下:
update user set password=password("112233") where user="root";
set password修改
- localhost指的是本机
1.先进行登录
mysql -u root -p2.修改
格式:set password for 用户名@'ip'=password('新密码');例子:set password for 'root'@'localhost'=password('112233');3.刷新权限
flush privileges;4.exit退出,重新登录
alter修改
1.先进行登录
mysql -u root -p2.修改
格式:alter user '用户名'@'ip' identified by '新密码';例子:alter user 'root'@'localhost' identified by 'xaS@DrxGA#B*fXsq#g';3.刷新权限
flush privileges;4.exit退出,重新登录
2.修改远程授权密码
mysql修改完密码后,远程授权也要修改,否则Navcait会连接不上
#登录
use mysql;#授权。
格式:grant all privileges on *.* to 'root'@'%' identified by '密码' with grant option;
例子:grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;#刷新权限,否则不会生效
flush privileges;
(六)忘记密码
windows为例
1. 关闭正在运行的MySQL服务。 2. 打开DOS窗口,转到mysql\bin目录。 3. 输入mysqld --skip-grant-tables 回车。--skip-grant-tables 的意思是启动MySQL服务的时候跳过权限表认证。 4. 再开一个DOS窗口(因为刚才那个DOS窗口已经不能动了),转到mysql\bin目录。 输入mysql回车,如果成功,将出现MySQL提示符 >。 5. 连接权限数据库: use mysql; 。 6. 改密码:update user set password=password("123456") where user="root";(别忘了最后加分号) 。 7. 刷新权限(必须步骤):flush privileges; 。 8. 退出 quit。 9. 注销系统,再进入,使用用户名root和刚才设置的新密码123456登录。
六、SQL语言种类
DDL 数据定义
create(创建库、表)
show(查询库、表、创表语句)
alter(修改库字符集和排序规则、修改表)
drop(删除库、表、表字段)
use(选择数据库)
desc(查询表结构)
truncate(截断表)
rename(表重命名)
modify(修改字段排序顺序和字段类型)
change(修改字段名和字段类型)
add(添加字段)
DML 数据操作
insert(增)
delete(删)
update(改)
DQL 数据查询
select(查)
DCL 数据控制
-
创建用户
-
grant(授权)
-
revoke(撤销权限)
-
查看用户权限
-
删除用户
七、MySQL书写规则
-
数据库名、表名、列名由英文字母、数字、下划线(_)组成,不能使用数字开头
chen_123
-
SQL语句要以英文分号结尾
-
SQL语句关键字不区分大小写
不管写成SELECT还是select,解释都是一样的。
-
SQL语句有字符串是,使用单引号:’ '。有日期时同样也要使用单引号括起来
-
数字不要用引号括起来,直接写数字即可
-
单词之间要用空格或换行符进行分隔
八、DDL 数据定义
针对数据库、数据表的操作语句叫做数据定义语言(DDL)
1.数据库操作
创建(create)
语法
create database [if not exists] <数据库名> charset <字符集名> collate <排序规则名>;
- 创建不指定字符集和排序规则,会默认为utf8和utf8_general_ci
例子
#简单创建
create database chen;#创建数据库chen,并指定字符集utf8和排序规则utf8_general_ci
create database chen charset utf8 collate utf8_general_ci;#添加条件判断,创建一个数据库
create database if not exists chen charset utf8 collate utf8_general_ci;
查询(show)
语法
show databases [like '数据库名']
- [ like ’ ’ ] 是可选项,用于匹配指定的数据库名称
- [ like ’ ’ ] 可以模糊匹配,也可以精确匹配
- 数据库名由单引号 ’ ’ 包围,在navicat中可以双引号
例子
#查询所有数据库
show databases;#模糊匹配。
show databases like '%chen%';#精确匹配
show databases like 'chen';
#查询所有数据库
+--------------------+
| Database |
+--------------------+
| information_schema |
| chen |
| dajun |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.00 sec)
修改(alter)
语法
alter databases [数据库名] charset <字符集名> collate <排序规则名>;
- 不一定要写数据库名,但需要当前有在使用的数据库
- 只能支持修改字符集和字符校验规则,如果要修改数据库名可以直接通过工具重命名数据库,Mysql暂时不支持语句修改
- 修改数据库不常用,了解即可
例子
#修改字符集和排序规则
alter database chen charset utf8 collate utf8_general_ci;#也可以进入数据库后进行修改
use chen;alter database charset utf8;
删除(drop)
语法
drop database [if exists] <数据库名>;
- 如果删除不存在的数据库,则会报 1008 - Can’t drop database ‘yytest’; database doesn’t exist
- 所以建议,删除数据库一定要加上 if exists
例子
#简单删除
drop database chen;#如果存在才删除
drop database if exists chen;
数据库选择(use)
- 作用:用来完成一个数据库到另一个数据库的跳转【切换当前操作的数据库】
- 当用 CREATE DATABASE 语句创建数据库之后,该数据库不会自动成为当前数据库,需要用 USE 来指定使用当前数据库
#选择数据库
use chen;
2.数据类型
整型
| MySQL数据类型 | 含义(有符号) | 用途 |
|---|---|---|
| tinyint(m) | 1个字节 范围(-128~127) | 小整数值 |
| smallint(m) | 2个字节 范围(-32768~32767) | 大整数值 |
| mediumint(m) | 3个字节 范围(-8388608~8388607) | 大整数值 |
| int(m) | 4个字节 范围(-2147483648~2147483647) | 大整数值 |
| bigint(m) | 8个字节 范围(±9.22*10的18次方) | 极大整数值 |
取值范围如果加了unsigned,则最大值翻倍,如tinyint unsigned的取值范围为(0~256)。
int(m)里的m是表示SELECT查询结果集中的显示宽度,并不影响实际的取值范围,没有影响到显示的宽度,不知道这个m有什么用。
浮点型
| MySQL数据类型 | 含义 |
|---|---|
| float(m,d) | 单精度浮点型 8位精度(4字节) m总个数,d小数位 |
| double(m,d) | 双精度浮点型 16位精度(8字节) m总个数,d小数位 |
M参数称为精度,是数据的总长度,小数点不占位置。D参数成为标度,是指小数点后面的长度是D。
举个例子:float(6,2)的含义数据是float型,数据长度是6,小数点后保留2位。所以,1234.56是符合要求的。
定点数
浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值。
| MySQL数据类型 | 含义 |
|---|---|
| decimal(m, d) | M为总数,D为小数,M必须大于D 大浮点数,30位小数 |
字符串
| MySQL数据类型 | 含义 | 用途 |
|---|---|---|
| char(n) | 固定长度,最多255个字符 | 定长字符串 |
| varchar(n) | 可变长度,最多65535个字符 | 变长字符串 |
| tinytext | 可变长度,最多255个字符 | 短文本字符串 |
| text | 可变长度,最多65535个字符 | 长文本数据 |
| mediumtext | 可变长度,最多2的24次方-1个字符 | 中等长度文本数据 |
| longtext | 可变长度,最多2的32次方-1个字符 | 极大文本数据 |
char和varchar:
-
CHAR的长度是不可变的
定义一个CHAR[10],不管存入几个字符都会占10个字节。比如存进去的是‘ABCD’, 那么CHAR所占的长度依然为10,除了字符‘ABCD’外,后面的全部用空格补齐。查询时通过trim()去掉多余的空格,而VARCHAR类型是不需要的。
-
VARCHAR的长度是可变的。
定义一个VARCHAR[10],存进去的是‘ABCD’, 那么CHAR所占的长度只是4。
-
CHAR的存取速度要比VARCHAR快得多,因为其长度固定,方便程序的存储与查找;但是CHAR为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可以说是以空间换取时间效率,而VARCHAR则是以空间效率为首位的。
varchar和text:
- varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),text是实际字符数+2个字节。
- text类型不能有默认值。
- varchar可直接创建索引,text创建索引要指定前多少个字符。varchar查询速度快于text,在都创建索引的情况下,text的索引似乎不起作用。
二进制数据
| MySQL数据类型 | 含义 | 用途 |
|---|---|---|
| tinyblob | 最多255个字符 | 二进制字符串 |
| blob | 最多65535个字符 | 二进制形式的长文本数据 |
| mediumblob | 最多16777215个字符 | 二进制形式的中等长度文本数据 |
| longbolob | 最多4294967295个字符 | 二进制形式的极大文本数据 |
blob类型 blob类型是一种特殊的二进制类型。blob可以用来保存数据量很大的二进制数据,如图片等。blob类型包括tinyblob,blob,mediumblob,longblob。这几种blob类型最大的区别就是能够保存的最大长度不同。longblob的长度最大,tinyblob的长度最小。blob类型与text类型很类似,不同点在于blob类型用于存储二进制数据,blob类型数据是根据其二进制编码进行比较和排序的,而text类型是文本模式进行比较和排序的。
blob类型主要用来存储图片,PDF文档等二进制文件,通常情况下,可以将图片,PDF文档都可以存储在文件系统中,然后在数据库中存储这些文件的路径,这种方式存储比直接存储在数据库中简单,但是访问速度比存储在数据库中慢。
日期时间类型
| MySQL数据类型 | 含义 |
|---|---|
| date | 日期 ‘2008-12-2’ |
| time | 时间 ‘12:25:36’ |
| datetime | 日期时间 ‘2008-12-2 22:06:44’ |
| timestamp | 自动存储记录修改时间 |
若定义一个字段为timestamp,这个字段里的时间数据会随其他字段修改的时候自动刷新,所以这个数据类型的字段可以存放这条记录最后被修改的时间。
3.数据表操作
创建(creat)
语法
create table <表名> ( [表定义选项] )[表选项][分区选项];
- 表名:两种写法,可以直接写数据表的名字 tbl_name ,也可以 db_name.tbl_name ,先指定数据库再指定数据表名;后者写法是为了:无论是否在当前数据库,也能通过这种方式在指定数据库下创建表
- **表定义选项:**一般都是 列名、列定义、默认值、约束、索引组成
例子
创表过程中,暂时不添加约束,添加约束例子后面写
#创建数据表
--先要通过use选择一个数据库再使用此方法建表
create table yytest (id int(10),uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
); # 指定数据库,创建数据表
create table dajun.polotest (id int(10) ,stu_id int(10),c_name varchar(20),istester varchar(50),grade int(10)
);#通过comment创建表时给字段添加注释
create table yytest (id int(10) comment '编号',uname varchar(20) comment '姓名',sex varchar(4) comment '性别',birth year comment '生日',department varchar(20),address varchar (50),yypolo varchar (20)
);
查看当前库中的表(show)
show tables;结果:
+-----------------+
| Tables_in_dajun |
+-----------------+
| polotest |
| yytest |
+-----------------+
2 rows in set (0.00 sec)
查看表创建语句(show)
- 不仅可以查看创建表时的详细语句,而且可以查看存储引擎和字符编码
#先创建一个表
create table yytest (id int(10),uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
);
#查看
show create table yytest;结果:
+--------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| yytest | CREATE TABLE `yytest` (`id` int(10) DEFAULT NULL,`uname` varchar(20) DEFAULT NULL,`sex` varchar(4) DEFAULT NULL,`birth` year(4) DEFAULT NULL,`department` varchar(20) DEFAULT NULL,`address` varchar(50) DEFAULT NULL,`yypolo` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+--------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
查看表结构(desc)
- Null:表示该字段是否可以存储 NULL 值
- Key:表示该字段是否已编制索引。PRI 表示主键,UNI 表示UNIQUE 索引,MUL 表示某个给定值允许出现多次
- Default:表示该字段是否有默认值,如果有,值是多少
- Extra:表示该字段的附加信息,如 AUTO_INCREMENT 等
语法
desc <表名>;
desc <库名.表名>;
例子
#查询当前库的表结构
desc yytest;#查询别的库的表结构
desc chen.yytest
结果:
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | YES | | NULL | |
| uname | varchar(20) | YES | | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
复制(creat)
语法
#仅复制表结构
create table <新表名> like <原表名>;# 复制表结构和所有数据
create table<新表名> as select * from <原表名>;
- 仅复制全部字段的结构直接加 like
- 复制表不包含主键、索引、自增等
where 1<>1 的作用
- 当我们只需要获取表的字段(结构)信息,而不需要理会实际保存的记录时,可以使用where 1<> 1。因为系统仅会读取结构信息,而不会将具体的表记录读入内存中,这无疑节省了系统开销。
例子
#仅复制表结构。yytest2指新表
create table yytest2 like yytest;# 复制表结构和所有数据
create table yytest3 as select * from yytest;# 仅复制表的指定字段结构
create table yytest4 as select id,uname,sex from yytest where 1<>1;# 复制表的指定字段结构和数据
create table yytest5 as select id,uname,sex from yytest;# 查看表创建语句:没有包含主键和自增
show create table yytest5;
修改(alter)
常用的修改表的操作
- 修改表名
- 修改字段数据类型或字段名
- 增加和删除字段
- 修改字段的排列位置
- add、drop、change、modify、rename
修改表名(rename)
语法
alter table <旧表名> rename [to] <新表名>;
- [to] 加不加都行,不影响结果
- 修改表名不影响表结构
例子
alter table yytest2 rename yytest22;alter table yytest22 rename to yytest2;
修改字段排列顺序(modify)
语法
alter table <表名> modify <字段名> <数据类型> [first|after 已存在的字段名];
# 放在首位
alter table yytest2 modify sex int(2) first;# 放在birth字段后面
alter table yytest2 modify sex int(2) after birth;
修改字段数据类型(modify)
语法
alter table <表名> modify <字段名> <数据类型>;
例子
# 修改字段数据类型为varchar
alter table yytest2 modify sex varchar(10);
修改字段名字(change)
语法
alter table <表名> change <旧字段> <新字段> <数据类型>;
- change不仅可以改字段名,也可以改字段数据类型
例子
# 修改字段名
alter table yytest2 change sex sexs varchar(10);# 修改字段数据类型和字段名
alter table yytest2 change sexs sex int(2);
添加字段(add)
语法
alter table <表名> add <字段名> <数据类型> [约束条件] [first|after 已存在的字段名];
例子
# 添加字段
alter table yytest2 add phone varchar(11);# 添加字段到首位
alter table yytest2 add phone2 varchar(11) not null default 2 first;# 添加phone3字段到sex字段后面
alter table yytest2 add phone3 varchar(11) after sex;
删除字段(drop)
语法
alter table <表名> drop <字段名>;
例子
# 删除字段
alter table yytest2 drop phone2;
删除表(drop)
语法
drop [if exists] 表名1 [ ,表名2, 表名3 ...]
语法
#普通删除单个表
drop table yytest5;# 删除多个表,如果存在
drop table if exists yytest3,yytest4;
截断表(truncate)
(1)清空表内数据,不删除表结构
官方解释:删除表,然后再重建表结构
truncate table 表名;
九、七大约束
含义
一种限制,用于限制表中的数据,为了保证表中的数据的准确性和可靠性。
分类
主键、外键、唯一、非空、默认值、自增、检查
添加约束的时机
- 创建表时
- 修改表时
约束的添加分类
- 列级约束
- 直接在字段名和类型后面追加
- 支持主键、非空、默认、唯一、自增。外键虽然语法上支持但是没效果。只能用于表级约束
- 表级约束
- 所有字段名和类型添加完后,最后统一添加约束
- 支持主键、外键、唯一。不支持非空、默认,自增
1.主键约束(primary key)
介绍
主键约束即在表中定义一个主键来唯一确定表中每一行数据的标识符。主键可以是表中的某一列或者多列的组合,其中由多列组合的主键称为复合主键。比如学号、员工编号就要主键约束。
主键遵守规则
- 每个表只能定义一个主键。
- 主键值必须唯一标识表中的每一行,且不能为 NULL,即表中不可能存在两行数据有相同的主键值。这是唯一性原则。
- 一个列名只能在复合主键列表中出现一次。
- 复合主键不能包含不必要的多余列。当把复合主键的某一列删除后,如果剩下的列构成的主键仍然满足唯一性原则,那么这个复合主键是不正确的。这是最小化原则。
特点
- 自带非空和唯一约束
- 用来标志当前记录的唯一性,区别于其他记录
- 一般是单个字段,也可以是联合多个字段
添加主键
建表时添加
1.方法一:列级约束。
#直接在字段名和类型后追加
create table yytest (id int(10) primary key,uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
); mysql> desc yytest;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | YES | | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
2.方法二:表级约束
#所有字段名和类型完成后添加
create table yytest2 (id int(10),uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20),primary key(id)
); mysql> desc yytest2;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | YES | | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
建表时设置复合主键
create table yytest3 (id int(10),uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20),primary key(id,uname)
); mysql> desc yytest3;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | NO | PRI | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
修改表时添加主键
注意:使用alter添加主键前提是该表中没有任何有主键约束。否则会报错
-
语法
#约束单个字段 alter table 表名 add primary key(字段名); #约束多个字段 alter table 表名 add primary key(字段名1,字段名2); -
例子
先查看yytest表
desc yytest;+------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | id | int(10) | NO | PRI | NULL | | | uname | varchar(20) | YES | | NULL | | | sex | varchar(4) | YES | | NULL | | | birth | year(4) | YES | | NULL | | | department | varchar(20) | YES | | NULL | | | address | varchar(50) | YES | | NULL | | | yypolo | varchar(20) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+ 7 rows in set (0.00 sec)通过alter给id和iname添加主键
alter table yytest add primary key(id,uname);再次查看yytest表
desc yytest;+------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | id | int(10) | NO | PRI | NULL | | | uname | varchar(20) | NO | PRI | NULL | | | sex | varchar(4) | YES | | NULL | | | birth | year(4) | YES | | NULL | | | department | varchar(20) | YES | | NULL | | | address | varchar(50) | YES | | NULL | | | yypolo | varchar(20) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+ 7 rows in set (0.00 sec)
删除主键
语法
alter table <表名> drop primary key;
例子
alter table yytest drop primary key;
2.外键约束(foreign key)
介绍
MySQL 外键约束(foreign key)用来在两个表的数据之间建立链接,它可以是一列或者多列。一个表可以有一个或多个外键。
外键对应的是参照完整性,一个表的外键可以为空值,若不为空值,则每一个外键的值必须等于另一个表中主键的某个值。
外键是表的一个字段,不是本表的主键,但对应另一个表的主键。定义外键后,不允许删除另一个表中具有关联关系的行。
外键的主要作用是保持数据的一致性、完整性。例如,部门表 tb_dept 的主键是 id,在员工表 tb_emp5 中有一个键 deptId 与这个 id 关联。
- 主表(父表):对于两个具有关联关系的表而言,相关联字段中主键所在的表就是主表。
- 从表(子表):对于两个具有关联关系的表而言,相关联字段中外键所在的表就是从表。
目的
用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值。
在从表添加外键约束,用于引用主表中某列的值
例子
现有两张表:学员表(从表)和专业表(主表)。
学员表中major_id来源于专业表中mid。那么就应该给学员表的major_id添加外键
-
学员表
id name major_id 1 大君 1 2 麦肯娜·格瑞丝 2 3 迪丽热巴 3 -
专业表
mid major_name 1 计算机 2 软件工程 3 人工智能
外键遵守规则
- 主表必须已经存在于数据库中,或者是当前正在创建的表。如果是后一种情况,则主表与从表是同一个表,这样的表称为自参照表,这种结构称为自参照完整性。
- 必须为主表定义主键,从表设置外键
- 主键不能包含空值,但允许在外键中出现空值。也就是说,只要外键的每个非空值出现在指定的主键中,这个外键的内容就是正确的。
- 在主表的表名后面指定列名或列名的组合。这个列或列的组合必须是主表的主键或候选键。
- 从表的外键列的数目必须和主表的主键中列的数目相同。
- 从表的外键列的数据类型必须和主表的关联列的数据类型相同。
- 主表的关联列必须是一个key(一般是主键或唯一)
注意
- 插入数据时,先插入主表,再插入从表
- 删除数据时,先删除从表,再删除主表
添加外键
建表时添加
-
语法
方法一的索引名就是索引名,并不是外建名
方法二的外建名和索引名都是指定的同一个名字
方法一: foreign key <索引名> (字段名1,字段名2,...) references studentinfo(主键列1,主键列2,...)方法二: constraint <外建名> foreign key (字段名1,字段名2,...) references (主键列1,主键列2,...) -
例子
#创建主表 create table studentinfo (mid int(10) primary key,major_name varchar(20) not null#非空 ); #创建从表 create table major (id int(10) primary key,uname varchar(20) not null,#非空major_id int(10),foreign key fk1 (major_id) references studentinfo(mid)#fk1指的是索引名 ); #创建从表 create table major2 (id int(10) primary key,uname varchar(20) not null,#非空major_id int(10),constraint fk2 foreign key (major_id) references studentinfo(mid) ); mysql> desc major; +----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+-------+ | id | int(10) | NO | PRI | NULL | | | uname | varchar(20) | NO | | NULL | | | major_id | int(10) | YES | MUL | NULL | | +----------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec)因为major(major_id)要参考 studentinfo(mid)所以要给父表添加主键约束
修改表时添加
-
语法
方法一的索引名就是索引名,并不是外建名
方法二的外建名和索引名都是指定的名字
1.方法一 alter table 从表名 add foreign key 索引名(字段名) references 主表名(字段名);2.方法二 alter table 从表名 add constraint 外建名 foreign key(字段名) references 主表名(字段名); -
例子
#创建从表 create table major3 (id int(10) primary key,uname varchar(20) not null,#非空major_id int(10) ); #方法一 alter table major3 add foreign key fk3(major_id) references studentinfo(mid);#创建从表 create table major4 (id int(10) primary key,uname varchar(20) not null,#非空major_id int(10) );#方法二 alter table major4 add constraint fk4 foreign key(major_id) references studentinfo(mid);
删除外键
语法
alter table <表名> drop foreign key <外键名>
例子
1.先通过Navicat或命令查看外键名#通过查看建表语句来查看
show create table major;结果:
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| major | CREATE TABLE `major` (`id` int(10) NOT NULL,`uname` varchar(20) NOT NULL,`major_id` int(10) DEFAULT NULL,PRIMARY KEY (`id`),KEY `fk1` (`major_id`),CONSTRAINT `major_ibfk_1` FOREIGN KEY (`major_id`) REFERENCES `studentinfo` (`mid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
2.删除
alter table major drop foreign key major_ibfk_1;结果:
mysql> show create table major;
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| major | CREATE TABLE `major` (`id` int(10) NOT NULL,`uname` varchar(20) NOT NULL,`major_id` int(10) DEFAULT NULL,PRIMARY KEY (`id`),KEY `fk1` (`major_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
原有的名称为 major_ibfk_1的外键约束删除成功。
3.唯一约束(unique)
介绍
- 要求该列唯一,允许为空,但只能出现一个空值。
- 唯一约束可以确保一列或者几列不出现重复值。比如座位号
unique和primary key 的区别
一个表可以有多个字段声明为 unique,但只能有一个 primary key 声明;声明为 primary key 的列不允许有空值,但是声明为 unique的字段允许空值的存在。
添加唯一
建表时添加
1.方法一:列级约束。
#直接在字段名和类型后追加
create table yytest4 (id int(10) primary key,uname varchar(20) unique,sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
); mysql> desc yytest4;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | YES | UNI | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)2.方法二:表级约束
#所有字段名和类型完成后添加
create table yytest5 (id int(10),uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20),primary key(id),unique(uname)
); mysql> desc yytest5;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | YES | UNI | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)修改表时添加
-
语法
alter table <表名> add constraint unique(字段名); -
例子
alter table yytest5 add constraint unique(sex);mysql> desc yytest5; +------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | id | int(10) | NO | PRI | NULL | | | uname | varchar(20) | YES | UNI | NULL | | | sex | varchar(4) | YES | UNI | NULL | | | birth | year(4) | YES | | NULL | | | department | varchar(20) | YES | | NULL | | | address | varchar(50) | YES | | NULL | | | yypolo | varchar(20) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+ 7 rows in set (0.00 sec)
删除唯一
语法
alter table <表名> drop index <唯一约束索引名>;
例子
1.先查看建表语句
show create table yytest5;+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| yytest5 | CREATE TABLE `yytest5` (`id` int(10) NOT NULL,`uname` varchar(20) DEFAULT NULL,`sex` varchar(4) DEFAULT NULL,`birth` year(4) DEFAULT NULL,`department` varchar(20) DEFAULT NULL,`address` varchar(50) DEFAULT NULL,`yypolo` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `uname` (`uname`),UNIQUE KEY `sex` (`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
2.删除唯一约束
alter table yytest5 drop index uname;结果:
mysql> show create table yytest5;
+---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| yytest5 | CREATE TABLE `yytest5` (`id` int(10) NOT NULL,`uname` varchar(20) DEFAULT NULL,`sex` varchar(4) DEFAULT NULL,`birth` year(4) DEFAULT NULL,`department` varchar(20) DEFAULT NULL,`address` varchar(50) DEFAULT NULL,`yypolo` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `sex` (`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
4.非空约束(not null)
介绍
指字段的值不能为空。对于使用了非空约束的字段,如果用户在添加数据时没有指定值,数据库系统就会报错。比如姓名、学号不能为空的。
添加非空
建表时添加
1.列级约束。不能用表级约束
#直接在字段名和类型后追加
create table yytest5 (id int(10) primary key,uname varchar(20) not null,sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
); mysql> desc yytest5;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | NO | | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
修改表时添加
-
语法
在这里为了语法的正确,新字段名其实可以和旧字段名一样的
alter table <数据表名> change <旧字段名> <新字段名> <数据类型> not null; -
例子
#通过改字段名,不改数据类型添加非空值 alter table yytest5 change sex sex varchar(4) not null;mysql> desc yytest5; +------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | id | int(10) | NO | PRI | NULL | | | uname | varchar(20) | NO | | NULL | | | sex | varchar(4) | NO | | NULL | | | birth | year(4) | YES | | NULL | | | department | varchar(20) | YES | | NULL | | | address | varchar(50) | YES | | NULL | | | yypolo | varchar(20) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+ 7 rows in set (0.00 sec)
删除非空
把not null改为null即可
语法
在这里为了语法的正确,新字段名其实可以和旧字段名一样的
alter table <数据表名> change <旧字段名> <新字段名> <数据类型> null;
例子
#通过改字段名,不改数据类型添加非空值
alter table yytest4 change sex sex varchar(4) null;mysql> desc yytest4;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | NO | | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
5.默认值(default 值)
介绍
“默认值(Default)”的完整称呼是“默认值约束(Default Constraint)”。MySQL 默认值约束用来指定某列的默认值。
例如女性同学较多,性别就可以默认为“女”。如果插入一条新的记录时没有为这个字段赋值,那么系统会自动为这个字段赋值为“女”。
添加默认值
建表时添加
create table yytest6 (id int(10) primary key,uname varchar(20),sex varchar(4) default '女',birth year,department varchar(20),address varchar (50),yypolo varchar (20)
); mysql> desc yytest6;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | YES | | NULL | |
| sex | varchar(4) | YES | | 女 | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)添加默认值null
null default null
- 这样写法意思是给null添加默认值null,不能写default null,会报错
修改表时添加
-
语法
在这里为了语法的正确,新字段名其实可以和旧字段名一样的
alter table <表名> change <旧字段名> <新字段名> <数据类型> default <默认值>; -
例子
alter table yytest6 change yypolo yypolo varchar(20) default '大菠萝';mysql> desc yytest6; +------------+-------------+------+-----+-----------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+-----------+-------+ | id | int(10) | NO | PRI | NULL | | | uname | varchar(20) | YES | | NULL | | | sex | varchar(4) | YES | | 女 | | | birth | year(4) | YES | | NULL | | | department | varchar(20) | YES | | NULL | | | address | varchar(50) | YES | | NULL | | | yypolo | varchar(20) | YES | | 大菠萝 | | +------------+-------------+------+-----+-----------+-------+ 7 rows in set (0.00 sec)
删除默认值
语法
在这里为了语法的正确,新字段名其实可以和旧字段名一样的
alter table <表名> change <旧字段名> <新字段名> <数据类型> default null;
例子
alter table yytest6 change yypolo yypolo varchar(20) default null;mysql> desc yytest6;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | YES | | NULL | |
| sex | varchar(4) | YES | | 女 | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
6.自增约束(auto_increment)
特点
-
一个表只能有一个自增约束
-
自增只能用于int类型,列只能是整数列
-
考虑到自增是唯一的,自增约束的列必须是键列(主键,唯一键,外键),
-
实际中一般是主键自增最多
-
delete删除数据之后,再次添加则按照删除之前的最后一个值,作为起点进行自增
trucate清空数据之后,再次添加则从原始值1开始增加
添加自增
建表时添加
create table yytest7 (id int(10) primary key auto_increment,uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
); mysql> desc yytest7;
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(10) | NO | PRI | NULL | auto_increment |
| uname | varchar(20) | YES | | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+----------------+
7 rows in set (0.00 sec)
修改表时添加
-
语法
在这里为了语法的正确,新字段名其实可以和旧字段名一样的
alter table <表名> change <旧字段名> <新字段名> <数据类型> <主键约束> <外键约束> ; -
例子
1.建表 create table yytest8 (id int(10),uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20) );2.添加主键和自增约束 alter table yytest8 change id id int(10) primary key auto_increment;mysql> desc yytest8; +------------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+----------------+ | id | int(10) | NO | PRI | NULL | auto_increment | | uname | varchar(20) | YES | | NULL | | | sex | varchar(4) | YES | | NULL | | | birth | year(4) | YES | | NULL | | | department | varchar(20) | YES | | NULL | | | address | varchar(50) | YES | | NULL | | | yypolo | varchar(20) | YES | | NULL | | +------------+-------------+------+-----+---------+----------------+ 7 rows in set (0.00 sec)
添加数据
添加数据具体方法在后面讲解
添加多行数据-指定字段
由于id是自增的,不指定id字段对id添加数据
insert into yytest8(uname,sex,birth,department,address,yypolo) values('大君1','女','1998','美丽部','杭州','菠萝'),('大君2','女','1998','美丽部','杭州','菠萝'),('大君3','女','1998','美丽部','杭州','菠萝');
查询结果
通过select语句查询,查询语句比较复杂,后面会讲解
mysql> select * from yytest8;
+----+---------+------+-------+------------+---------+--------+
| id | uname | sex | birth | department | address | yypolo |
+----+---------+------+-------+------------+---------+--------+
| 1 | 大君1 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
| 2 | 大君2 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
| 3 | 大君3 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
+----+---------+------+-------+------------+---------+--------+
3 rows in set (0.00 sec)
delete删除数据后id的变化
- delete删除数据之后,再次添加则按照删除之前的最后一个值,作为起点进行自增
这里暂时举例子用,后面会讲解
删除表中所有数据
delete from yytest8;
添加1条数据
insert into yytest8(uname,sex,birth,department,address,yypolo) values('大君4','女','1998','美丽部','杭州','菠萝');
查询数据
可以看出id是根据删除之前的最后一个值作为起点进行自增的
mysql> select * from yytest8;
+----+---------+------+-------+------------+---------+--------+
| id | uname | sex | birth | department | address | yypolo |
+----+---------+------+-------+------------+---------+--------+
| 4 | 大君4 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
+----+---------+------+-------+------------+---------+--------+
1 row in set (0.00 sec)
truncate清空数据id的变化
trucate清空数据之后,再次添加则从原始值1开始增加
清空数据
truncate table yytest8;
添加1条数据
insert into yytest8(uname,sex,birth,department,address,yypolo) values('大君1','女','1998','美丽部','杭州','菠萝');
查询
可以看到,id是从原始值1开始的
mysql> select * from yytest8;
+----+---------+------+-------+------------+---------+--------+
| id | uname | sex | birth | department | address | yypolo |
+----+---------+------+-------+------------+---------+--------+
| 1 | 大君1 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
+----+---------+------+-------+------------+---------+--------+
1 row in set (0.00 sec)
删除自增
语法
在这里为了语法的正确,新字段名其实可以和旧字段名一样的
alter table <表名> change <字段名> <字段名> <数据类型>;
例子
alter table yytest8 change id id int(10);mysql> desc yytest8;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(10) | NO | PRI | NULL | |
| uname | varchar(20) | YES | | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
设置步长
- 设置步长对所有表的自增都会起作用
创表
create table yytest9 (id int(10) primary key auto_increment,uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
);
设置步长为2
set auto_increment_increment=2;
添加数据
insert into yytest9(uname,sex,birth,department,address,yypolo) values('大君1','女','1998','美丽部','杭州','菠萝'),('大君2','女','1998','美丽部','杭州','菠萝'),('大君3','女','1998','美丽部','杭州','菠萝');
查看表数据
mysql> select * from yytest9;
+----+---------+------+-------+------------+---------+--------+
| id | uname | sex | birth | department | address | yypolo |
+----+---------+------+-------+------------+---------+--------+
| 1 | 大君1 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
| 3 | 大君2 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
| 5 | 大君3 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
+----+---------+------+-------+------------+---------+--------+
3 rows in set (0.00 sec)
取消步长
- 取消步长后添加数据第1条数据不会生效,还是会延续步长,从第2条数据开始生效
set auto_increment_increment=0;
设置起始值
创表
create table yytest10 (id int(10) primary key auto_increment,uname varchar(20),sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
);
修改表时设置起始值
alter table yytest10 auto_increment=5;
添加数据
insert into yytest10(uname,sex,birth,department,address,yypolo) values('大君','女','1998','美丽部','杭州','菠萝');mysql> select * from yytest10;
+----+--------+------+-------+------------+---------+--------+
| id | uname | sex | birth | department | address | yypolo |
+----+--------+------+-------+------------+---------+--------+
| 5 | 大君 | 女 | 1998 | 美丽部 | 杭州 | 菠萝 |
+----+--------+------+-------+------------+---------+--------+
1 row in set (0.00 sec)
7.检查约束(check)
目前MySQL不支持、Oracle支持
8.同一个字段添加多个约束
create table yytest11 (id int(10) primary key auto_increment,#添加主键和自增uname varchar(20) not null unique,#添加非空和唯一sex varchar(4),birth year,department varchar(20),address varchar (50),yypolo varchar (20)
); mysql> desc yytest11;
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(10) | NO | PRI | NULL | auto_increment |
| uname | varchar(20) | NO | UNI | NULL | |
| sex | varchar(4) | YES | | NULL | |
| birth | year(4) | YES | | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+----------------+
7 rows in set (0.00 sec)
9.查看表中约束
语法
以下两种方法作为互补查看
#通过查看表结构
desc <表名>#通过查看建表语句
show create table <表名>;
例子
#创表
create table yytest12 (id int(10) primary key auto_increment,uname varchar(20) not null,sex varchar(4) default '女',birth year unique,department varchar(20),address varchar (50),yypolo varchar (20)
);
desc查看
mysql> desc yytest12;
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(10) | NO | PRI | NULL | auto_increment |
| uname | varchar(20) | NO | | NULL | |
| sex | varchar(4) | YES | | 女 | |
| birth | year(4) | YES | UNI | NULL | |
| department | varchar(20) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| yypolo | varchar(20) | YES | | NULL | |
+------------+-------------+------+-----+---------+----------------+
7 rows in set (0.00 sec)
show create查看
mysql> show create table yytest12;
+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| yytest11 | CREATE TABLE `yytest11` (`id` int(10) NOT NULL AUTO_INCREMENT,`uname` varchar(20) NOT NULL,`sex` varchar(4) DEFAULT '女',`birth` year(4) DEFAULT NULL,`department` varchar(20) DEFAULT NULL,`address` varchar(50) DEFAULT NULL,`yypolo` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `birth` (`birth`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
10.主键和唯一区别
| 保证唯一性 | 是否允许为空 | 表中可以有多个 | 是否允许组合 | |
|---|---|---|---|---|
| 主键 | √ | × | × | √不推荐 |
| 唯一 | √ | √ | √ | √不推荐 |
十、DML 数据操纵
1.增(insert into)
语法
#按顺序添加
insert into <表名> values(值1,值2,...)#指定字段名添加
insert into <表名>(字段名1,字段名2...) values(值1,值2,...);
不指定字段
#默认按顺序添加
insert into yytest values(1,'大君','女','1998','美丽部','杭州','菠萝');
指定字段
#指定字段
insert into yytest(id,uname,sex,birth,department,address,yypolo) values(2,'大君2','女','1998','美丽部','杭州','菠萝');#假如表中有可以为null的字段,注意可以通过以下两种方式插入null值
方法一:字段和值都省略
insert into yytest(id,uname,sex,birth,department,address) values(3,'大君3','女','1998','美丽部','杭州');方法二:字段写上,值使用null
insert into yytest(id,uname,sex,birth,department,address,yypolo) values(4,'大君4','女','1998','美丽部','杭州',null);
增加多行数据
insert into yytest values(5,'大君5','女','1998','美丽部','杭州','菠萝'),(6,'大君6','女','1998','美丽部','杭州','菠萝');
复制表数据来插入
语法
insert into <表名>(字段名1,字段名2...) select ....
- 如果是复制表数据的话,不用加 values() !
例子
#复制id=1那一行数据插入,新数据id为7
insert into yytest(id,uname,sex,birth,department,address,yypolo) select
7,
uname,
sex,
birth,
department,
address,
yypolo
from yytest where id=1;
2.改(update)
语法
update <表名> set 字段1=值1 [,字段2=值2… ] [where 子句 ] [limit 子句]
- 指定多个字段,需要用 , 隔开
- 如果修改的字段有默认值,可以用 default 来设置字段的值,如: name = default ,这样就会把字段的值修改成默认值
- where 就不用多说了,一般 update 数据都会指定条件
- 添加 limit 是为了限制被修改的行数,加不加都行
例子
#修改单个字段.
--修改第7行uname为‘大君7’
update yytest set uname = '大君7' where id = 7;#修改多个字段
update yytest set sex='男',birth='2000',department='漂亮部' where id = 7;
3.删(delete from)
语法
delete from <表名> [where 子句] [limit子句]
- where 就不用多说了,一般 delete 数据都会指定条件,会将符合条件的那一行数据删掉
- 添加 limit 是为了限制被删除的行数,加不加都行
例子
#根据条件删除表中的数据
delete from yytest where yypolo = '菠萝' or yypolo is null;#删除表中全部数据
delete from yytest;
十一、drop、truncate、delete区别
-
drop和truncate属于DDL语句,delete属于DML语句
-
drop删除表的数据和结构
truncate清空表中的数据,保留表的结构。官方定义是删除表,然后再重建表结构
delete即可以对行数据进行删除,也可以对整表数据进行删除
-
delete可以回滚,drop和truncate不能
十二、DQL 数据查询
MySQL关键字书写顺序及执行循序
书写顺序
92语法
select --> distinct --> 聚合函数(sum、avg、max、min) --> from --> where --> group by --> having --> order by --> limit
99语法
select --> distinct --> 聚合函数(sum、avg、max、min) --> from --> join --> on --> where --> group by --> having --> order by --> limit
执行顺序
99语法
from --> where --> group by --> 聚合函数(sum、avg、max、min) --> having --> select --> distinct --> order by --> limit
99语法
from --> join --> on --> where --> group by --> 聚合函数(sum、max、min、avg、count) --> having --> select --> distinct --> order by --> limit
sql语句示范
现在有下面一个表 t ,存储了每个商品类别的成交明细,我们需要通过下面这张表获取订单量大于10对应的类别,并从中取出订单量前3的商品类别,会有一些测试的订单(catid=c666的为测试),我们需要过滤掉。
| catid | orderid |
|---|---|
| c1 | 1 |
| c1 | 2 |
| c1 | 3 |
| c2 | 4 |
| c2 | 5 |
| c3 | 6 |
| … | … |
| c100 | 10000 |
sql语句
要做上面的需求,我们的 Sql 可以这么写:
selectcatid,count(orderid) as sales
fromt
where catid <> "c666"#<>表示不等于
group by catid
havingcount(orderid) > 10
order by count(orderid) desc
1. 基础查询
特点
1、查询列表可以是:表中的字段、常量值、表达式、函数
2、查询的结果是一个虚拟的表格
语法
select 字段名 from 表名;
1.查询表中的单个字段
SELECT last_name FROM employees;
2.查询表中的多个字段
SELECT last_name,salary,email FROM employees;
3.查询表中的所有字段
SELECT * FROM employees;
4.查询常量值
SELECT 100;SELECT 'john';
5.查询表达式
SELECT 100%98;
6.查询函数
SELECT VERSION();
7.起别名 as
- 可以给字段 or 数据表取别名
- **取别名的好处就是:**如果数据表太长或者字段名太长,查询结果显示就不够优雅,而且取别名还能中文命名,何乐而不为
- 表名取的别名不能和其他表名相同,字段名取的别名不能和其他字段名相同
语法
- as是可以忽略不写的
<表名> 【as】 <别名>
<字段名>【as】 <别名>
#方式一:使用as
SELECT 100%98 AS 结果;
SELECT last_name AS 姓,first_name AS 名 FROM employees;#方式二:使用空格
SELECT last_name 姓,first_name 名 FROM employees;
8.去重 distinct
-
特点
- distinct只能在select语句中使用
- distinct必须在所有字段前面
- 如果有多个字段需要去重,则会对多个字段进行组合去重,即所有字段的数据重复才会被去重
-
常见使用场景
- 查看去重字段有哪几种值**【返回值】**
- 查看去重字段有多少个值**【返回数量】**
-
注意
当使用distinct的时候,只会返回指定的字段,其他字段都不会返回,所以查询语句就变成去重查询语句
语法
select distinct <字段名>,<字段名>, FROM <表名>;
#查询员工表中涉及到的所有的部门编号
SELECT DISTINCT department_id FROM employees;#查询去重字段有多少种值
SELECT COUNT(DISTINCT department_id) FROM employees;
9.+号作用
mysql中的+号:仅仅只有一个功能:运算符
select 100+90; 两个操作数都为数值型,则做加法运算
select '123'+90;只要其中一方为字符型,试图将字符型数值转换成数值型如果转换成功,则继续做加法运算
select 'john'+90; 如果转换失败,则将字符型数值转换成0select null+10; 只要其中一方为null,则结果肯定为null
10.拼接 conat
SELECT CONCAT('a','b','c') AS 结果;
#查询员工名和姓连接成一个字段,并显示为 姓名
SELECT CONCAT(last_name,first_name) AS 姓名
FROMemployees;
11.判断字段是否为null
判断commission_pct内容是否为空,0代表是null显示的值,不是null就显示原本的值
SELECT IFNULL(commission_pct,0) AS 奖金率,commission_pct
FROM employees;
练习---------
#显示出表employees中的全部job_id(不能重复)SELECT DISTINCT job_id FROM employees;
#显示出表employees的全部列,各个列之间用逗号连接,列头显示成OUT_PUT SELECT CONCAT(`first_name`,',',`last_name`,',',`job_id`,',',IFNULL(commission_pct,0)) AS out_put
FROMemployees;
- CONCAT:将过个字符拼接成一个字符串
2. 条件查询
- 五种查询条件
- 比较运算符、逻辑运算符
- between and 关键字
- is null 关键字
- in、exist 关键字
- like 关键字
语法
select 字段名 from 表名 where 筛选条件;
1.按比较运算符查询
比较运算符:
大于:>
小于:<
等于:=
不等于:!= <>
大于等于:>=
小于等于:<=
安全等于:<=>
#查询工资>12000的员工信息
SELECT * FROM employees WHERE salary>12000;#查询部门编号不等于90号的员工名和部门编号
SELECT last_name,department_id FROM employees WHERE department_id<>90;
2.按逻辑表达式筛选
逻辑运算符:
作用:用于连接条件表达式
and、&&:所有查询条件均满足才会被查询出来。两个条件都为true,结果为true,反之为false
or、||: 满足任意一个查询条件就会被查询出来。只要有一个条件为true,结果为true,反之为false
not: 不满足条件的会被查询出来。如果连接的条件本身为false,结果为true,反之为false
#查询工资在10000到20000之间的员工名、工资以及奖金
SELECT last_name,salary,commission_pct FROM employees WHERE salary>=10000 AND salary<=20000;#查询部门编号不是在90到110之间,或者工资高于15000的员工信息
SELECT * FROM employees WHERE NOT(department_id>=90 AND department_id<=110) OR salary>15000;
3.like(模糊查询)
特点
一般和%、_ 两个通配符搭配使用
-
%:任意多个字符,包含0个字符
a%b 表示以字母 a 开头,以字母 b 结尾的任意长度的字符串;该字符串可以代表 ab、acb、accb、accrb 等字符串
-
_:任意单个字符,字符的长度不能等于0
a_b 可以代表 acb、adb、aub 等字符串
语法
like '字符串'
not like '字符串'
- not:取反,不满足指定字符串时匹配
- 字符串:可以是精确的字符串,也可以是包含通配符的字符串
% 例子
#查询员工名中包含字符a的员工信息
SELECT * FROM employees WHERE last_name LIKE '%a%';#查询last_name中开头不为a
SELECT * FROM employees WHERE last_name NOT LIKE 'a%';
_ 例子
#查询员工名中第三个字符为n,第五个字符为l的员工名和工资
SELECT last_name,salary FROM employees WHERE last_name LIKE '__n_l%';#查询员工名中第二个字符为_的员工名
SELECT last_name FROM employees WHERE last_name LIKE '_$_%' ESCAPE '$';
like 区分大小写
- 默认情况下,like匹配的字符串是不区分大小写的; like “test1” 和 like “TEST1” 匹配的结果是一样的
- 如果需要区分大小写,需要加入 binary 关键字
#不会返回任何记录,test1和test2不会被匹配到
select * from yyTest where username like binary "TEST_";
转义符使用
- 如果查询的字符串包含%,可以使用 \ 转义符
- **实际场景:**搜索功能,搜索框只输入%看是否返回所有记录,如果是的话证明没有做转义可以提个优化项哦!
select * from yyTest where username like "%\%"
使用通配符的注意点
- **注意大小写:**不加binary关键字的话,大小写是不敏感的
- 注意头部、尾部多余的空格: " test% " 是不会匹配到“test1”的
- **注意NULL:**通配符是不能匹配到字段为NULL的记录的
- 不要过度使用通配符:因为Mysql对通配符的处理速度会比其他操作花费更长的时间
- **在确定使用通配符后:除非绝对有必要,否则不要把它们用在字符串的开始处,**把通配符置于搜索模式的开始处,搜索起来是最慢的。
4.between and(范围查询)
- 使用between and 可以提高语句的简洁度
- 包含临界值
- 两个临界值不要调换顺序
语法
between 起始值 and 终止值
not between 起始值 and 终止值
#查询员工编号在100到120之间的员工信息
SELECT * FROM employees WHERE employee_id >= 120 AND employee_id<=100;#使用between and
SELECT * FROM employees WHERE employee_id BETWEEN 120 AND 100;
5.in
- 含义:判断某字段的值是否属于in列表中的某一项
- 特点
- 使用in提高语句简洁度
- in列表的值类型必须一致或兼容
- in列表中不支持通配符
语法
#属于
in#不属于
not in
查询员工的工种编号是 IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号#传统写法
SELECT last_name,job_id FROM employees WHERE job_id = 'IT_PROT' OR job_id = 'AD_VP' OR JOB_ID ='AD_PRES';#使用in
SELECT last_name,job_id FROM employees WHERE job_id IN( 'IT_PROT' ,'AD_VP','AD_PRES');#查询员工的工种编号不是 IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号
SELECT last_name,job_id FROM employees WHERE job_id NOT IN( 'IT_PROT' ,'AD_VP','AD_PRES');
6.is null(空值查询)
- is null是一个关键字来的,用于判断字段的值是否为空值(NULL)
- 空值 ≠ 0,也 ≠ 空字符串""
- is null 是一个整体,不能用 = null 替代
- is not null 同理,不能用 != null 或 <> 替代
语法
#判断为空
is null#判断不为空
is not null
#查询没有奖金的员工名和奖金率
SELECT last_name,commission_pct FROM employees WHERE commission_pct IS NULL;#查询有奖金的员工名和奖金率
SELECT last_name,commission_pct FROM employees WHERE commission_pct IS NOT NULL;7.安全等于 <=>
#查询没有奖金的员工名和奖金率
SELECT last_name,commission_pct FROM employees WHERE commission_pct <=>NULL;#查询工资为12000的员工信息
SELECT last_name, salary FROM employees WHERE salary <=> 12000;8.is null 和<=>
is null: 仅仅可以判断null值,可读性较高,建议使用
<=> : 既可以判断null值,又可以判断普通的数值,可读性较低
3. 排序查询
特点
-
order by子句可以支持 单个字段、别名、表达式、函数、多个字段
-
order by子句在查询语句的最后面,除了limit子句
-
order by关键字后可以跟子查询(后面展开讲)
-
如果字段值是NULL,则当最小值处理
-
如果指定多个字段排序,则按照字段的顺序从左往右依次排序
语法
select 字段名 from 表名 【where 筛选条件】 order by 排序的字段或表达式 【asc | desc】
;
- asc:升序排序,默认值
- desc:降序排序
1.按单个字段排序
SELECT * FROM employees ORDER BY salary DESC;
2.按多个字段排序
- 对多个字段排序时,只有第一个排序字段有相同的值,才会对第二个字段进行排序,以此类推
- 如果第一个排序字段的所有数据都是唯一的,将不会对第二个排序字段进行排序,以此类推
- 按字母(A-Z进行排序,大小写不敏感)
#查询员工信息,要求先按工资降序,再按employee_id升序
SELECT * FROM employees ORDER BY salary DESC,employee_id ASC;
3.添加筛选条件再排序
#查询部门编号>=90的员工信息,并按员工编号降序
SELECT * FROM employees WHERE department_id>=90 ORDER BY employee_id DESC;
4.按表达式排序
#查询员工信息 按年薪降序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) FROM employees ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
5.按别名排序
#查询员工信息 按年薪升序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪 FROM employees ORDER BY 年薪 ASC;
6.按函数排序
#查询员工名,并且按名字的长度降序
SELECT LENGTH(last_name),last_name FROM employees ORDER BY LENGTH(last_name) DESC;
练习---------
1.查询员工的姓名和部门号和年薪,按年薪降序 按姓名升序
SELECT last_name,department_id,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
ORDER BY 年薪 DESC,last_name ASC;2.选择工资不在8000到17000的员工的姓名和工资,按工资降序
SELECT last_name,salary FROM employees WHERE salary NOT BETWEEN 8000 AND 17000
ORDER BY salary DESC;3.查询邮箱中包含e的员工信息,并先按邮箱的字节数降序,再按部门号升序
SELECT *,LENGTH(email)
FROM employees
WHERE email LIKE '%e%'
ORDER BY LENGTH(email) DESC,department_id ASC;
4. 分组函数(聚合函数)
功能:用作统计使用,又称为聚合函数或统计函数或组函数
特点
1、sum、avg一般用于处理数值型
max、min、count可以处理任何类型
2、以上分组函数都忽略null值
3、可以和distinct搭配实现去重的运算
4、count函数的单独介绍
一般使用count(*)用作统计行数
5、和分组函数一同查询的字段要求是group by后的字段
sum 求和avg 平均值max 最大值 min 最小值 count 计算个数
1.简单的使用
SELECT SUM(salary) FROM employees;
SELECT AVG(salary) FROM employees;
SELECT MIN(salary) FROM employees;
SELECT MAX(salary) FROM employees;
SELECT COUNT(salary) FROM employees;SELECT SUM(salary) 和,AVG(salary) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数
FROM employees;SELECT SUM(salary) 和,ROUND(AVG(salary),2) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数
FROM employees;
2.是否忽略null
SELECT SUM(commission_pct) ,AVG(commission_pct),SUM(commission_pct)/35,SUM(commission_pct)/107 FROM employees;SELECT MAX(commission_pct) ,MIN(commission_pct) FROM employees;SELECT COUNT(commission_pct) FROM employees;
SELECT commission_pct FROM employees;
3.和distinct搭配
SELECT SUM(DISTINCT salary),SUM(salary) FROM employees;SELECT COUNT(DISTINCT salary),COUNT(salary) FROM employees;
4.count函数的详细介绍
SELECT COUNT(salary) FROM employees;SELECT COUNT(*) FROM employees;SELECT COUNT(1) FROM employees;
-
执行效率排序
MYISAM存储引擎下 ,COUNT(*)的效率高
INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)要高一些count(字段)<count(主键 id)<count(1)≈count(*)
注意
- where后面不能使用分组函数,可以再group by后面使用
练习---------
1.查询公司员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary) 最大值,MIN(salary) 最小值,AVG(salary) 平均值,SUM(salary) 和 FROM employees;2.查询员工表中的最大入职时间和最小入职时间的相差天数 (DIFFRENCE)
SELECT DATEDIFF(MAX(hiredate),MIN(hiredate)) DIFFRENCE
FROM employees;SELECT DATEDIFF('1995-2-7','1995-2-6');3.查询部门编号为90的员工个数
SELECT COUNT(*) FROM employees WHERE departmenK_id = 90;
5. 分组查询
特点
- 和分组函数一同查询的字段必须是group by后出现的字段
- 筛选分为两类:分组前筛选和分组后筛选
- 分组前筛选:对原始表操作,在group by的前面,使用where
- 分组后筛选:对分组后的结果筛选,在group by的后面,使用having
- 分组函数做条件肯定放在having后面,不能放在where后面
- 分组可以按单个字段也可以按多个字段(用逗号隔开,没有顺序要求)
语法
select 字段名 from 表【where 筛选条件】 group by 分组的字段【order by 排序的字段】;
1.单个字段分组
#对job_id分组
SELECT * FROM employees GROUP BY job_id;
- 分组之后,只会返回组内第一条数据

2.按多个字段分组
#查询每个工种每个部门的最低工资
SELECT MIN(salary),job_id,department_id
FROM employees
GROUP BY department_id,job_id
- 多个字段分组查询时,先按照第一个字段分组,如果第一个字段有相同值,则把分组结果再按第二个字段进行分组,以此类推
- 如果第一个字段每个值都是唯一的,则不会按照第二个字段再进行分组了,具体原理可看下图
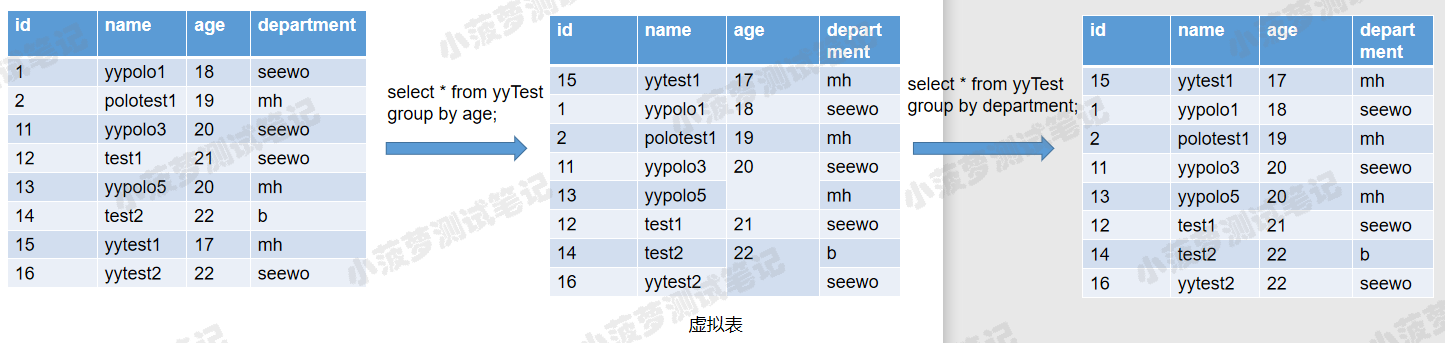
3.group by +聚合函数
#查询每个工种的员工平均工资
SELECT AVG(salary),job_id FROM employees GROUP BY job_id;#查询每个位置的部门个数
SELECT COUNT(*),location_id FROM departments GROUP BY location_id;
4.分组前的筛选(where)
#查询邮箱中包含a字符的 每个部门的最高工资
SELECT MAX(salary),department_id
FROM employees
WHERE email LIKE '%a%'
GROUP BY department_id;#查询有奖金的每个领导手下员工的平均工资
SELECT AVG(salary),manager_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id;
5.分组后的筛选(having)
- having关键字对group by分组后的数据进行过滤
- having支持where的所有操作符和语法
where和having区别对比
| where | having |
|---|---|
| 不可以使用聚合函数 | 可以使用聚合函数 |
| 数据 group by 前过滤 | 数据 group by 后过滤 |
| 查询条件中不可以使用字段别名 | 查询条件中可以使用字段别名 |
| 用于过滤数据行 | 用于过滤分组后的结果集 |
| 根据数据表的字段直接过滤 | 根据已查询出的字段进行过滤 |
语法
having <查询条件>
#查询哪个部门的员工个数>5
SELECT COUNT(*),department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>5;
7.where+having
#每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id,MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>12000;#领导编号>102的每个领导手下的最低工资大于5000的领导编号和最低工资
SELECT manager_id,MIN(salary)
FROM employees
WHERE manager_id>102
GROUP BY manager_id
HAVING MIN(salary)>5000;
8.按表达式或函数分组
按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>5的有哪些
SELECT count(*),LENGTH(last_name) len_name
FROM employees
GROUP BY len_name
HAVING COUNT(*)>5;
9.添加排序
#查询每个部门每个工种的员工的平均工资,并且按平均工资的高低显示SELECT AVG(salary),department_id,job_id
FROM employees
WHERE department_id IS NOT NULL
GROUP BY job_id,department_id
HAVING AVG()
ORDER BY AVG(salary) DESC;#每个工种有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序SELECT job_id,MAX(salary) m
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING m>6000
ORDER BY m;
8.group by + group_concat()
group_concat()可以将分组后每个组内的值都显示出来
select department,group_concat(username) as "部门员工名字" from yyTest group by department;
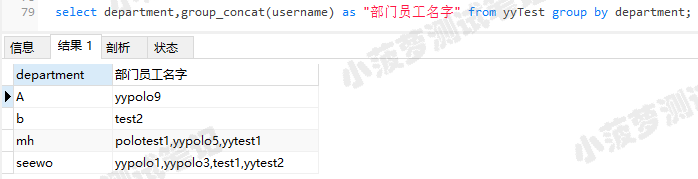
可以看到,按department部门分组 ,然后查看每个部门都有哪些员工的名字
10.group by + with rollup
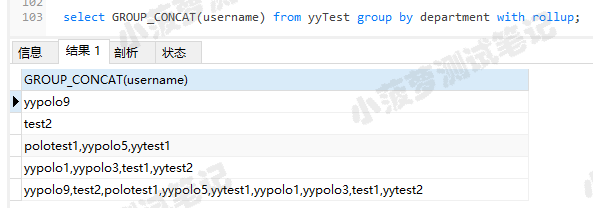
with rollup用来在所有记录的最后加上一条记录,显示上面所有记录每个字段的总和
select GROUP_CONCAT(username) from yyTest group by department with rollup;
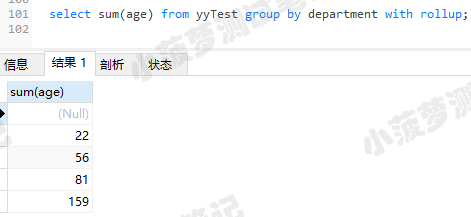
select sum(age) from yyTest group by department with rollup;
select count(*) from yyTest group by department with rollup;
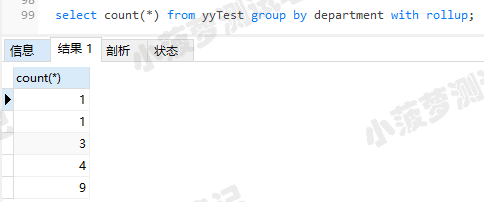
练习---------
1.查询各job_id的员工工资的最大值,最小值,平均值,总和,并按job_id升序
SELECT MAX(salary),MIN(salary),AVG(salary),SUM(salary),job_id
FROM employees
GROUP BY job_id
ORDER BY job_id;2.查询员工最高工资和最低工资的差距(DIFFERENCE)
SELECT MAX(salary)-MIN(salary) DIFFRENCE
FROM employees;3.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
SELECT MIN(salary),manager_id
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
HAVING MIN(salary)>=6000;#4.查询所有部门的编号,员工数量和工资平均值,并按平均工资降序
SELECT department_id,COUNT(*),AVG(salary) a
FROM employees
GROUP BY department_id
ORDER BY a DESC;#5.选择具有各个job_id的员工人数
SELECT COUNT(*) 个数,job_id
FROM employees
GROUP BY job_id;
6. 多表查询(表连接查询)
介绍
- 实际工作中,每次查询基本都是需要结合多个表去查询数据,所以Mysql的多表查询我们必须掌握
- 多表查询可以是两张表,也可以是很多张表,取决于需要查询的数据要关联多少张表
分类
按年代分类:
- sql92标准:仅仅支持内连接
- sql99标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接
按类型分类:
- 内连接(inner join):
- 等值连接
- 非等值连接
- 自连接
- 外连接:
- 左外连接(left join)
- 右外连接(right join)
- 交叉连接(cross join)
- 全连接(MySQL不支持)
- Mysql并没有全连接,Oracle才有全连接(full join)
- 但是在MySQL中,可以通过左联接+Union+右联接的方式变相实现。
多表查询区别
| 查询类型 | 简述 | 图表 |
|---|---|---|
| 内连接 | 获取两张表字段相互匹配到的数据且不会null才会返回**(满足查询条件的数据)**,简单理解就是:取交集 | 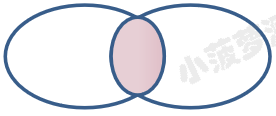 |
| 左外连接 | 获取左表所有记录右表为空的字段补null | 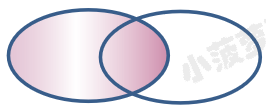 |
| 右外连接 | 获取右表所有记录左表为空的字段补null | 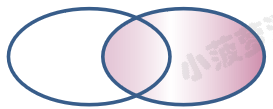 |
| 全连接 | 获取左右表所有记录 |  |
| 交叉连接 | 两张表的笛卡尔积 |
书写格式要求
- 在多表查询的时候,字段名都需要通过表名指定 :表名.字段名
- 如果表名太长可以用给表起别名,这样就变成:别名.字段名 。比如a 、 b 就是别名, a.dept_id 、 b.id
1.笛卡尔积现象
- 左表中的每一行与右表中的所有行组合
发生原因:没有有效的连接条件
如何避免:添加有效的连接条件
举例
假设,有两个集合A、B
A = {1,2}
B = {3,4}
集合A和集合B的笛卡尔积 = 集合A * 集合B;即,两表相乘,如下:
AxB = {(1,3),(1,4),(2,3),(2,4)}
笛卡尔积示范
SELECT NAME,boyName FROM boys,beauty
去除笛卡尔积
通过添加有效的连接条件去除
SELECT NAME,boyName FROM boys,beauty
WHERE beauty.boyfriend_id= boys.id;
2.等值连接
① 多表等值连接的结果为多表的交集部分
②n表连接,至少需要n-1个连接条件
③ 多表的顺序没有要求
④一般需要为表起别名
⑤可以搭配前面介绍的所有子句使用,比如排序、分组、筛选
#查询女神名和对应的男神名
SELECT NAME,boyName FROM boys,beauty
WHERE beauty.boyfriend_id= boys.id;#查询员工名和对应的部门名
SELECT last_name,department_name FROM employees,departments
WHERE employees.department_id`=departments.department_id`;
为表起别名
①提高语句的简洁度
②区分多个重名的字段
注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
#查询员工名、工种号、工种名
SELECT e.last_name,e.job_id,j.job_title FROM employees e,jobs j
WHERE e.`job_id`=j.`job_id`;
表顺序互换
#查询员工名、工种号、工种名
SELECT e.last_name,e.job_id,j.job_title FROM jobs j,employees e
WHERE e.`job_id`=j.`job_id`;
添加筛选
#查询有奖金的员工名、部门名
SELECT last_name,department_name,commission_pct
FROM employees e,departments d
WHERE e.department_i`=d.department_id
AND e.`commission_pct` IS NOT NULL;#查询城市名中第二个字符为o的部门名和城市名
SELECT department_name,city
FROM departments d,locations l
WHERE d.location_id = l.location_id
AND city LIKE '_o%';
添加分组
#查询每个城市的部门个数
SELECT COUNT(*) 个数,city
FROM departments d,locations l
WHERE d.location_id=l.location_id
GROUP BY city;#查询有奖金的每个部门的部门名和部门的领导编号和该部门的最低工资
SELECT department_name,d.manager_id,MIN(salary)
FROM departments d,employees e
WHERE d.department_id=e.department_id
AND commission_pct IS NOT NULL
GROUP BY department_name,d.manager_id;
添加排序
#查询每个工种的工种名和员工的个数,并且按员工个数降序
SELECT job_title,COUNT(*)
FROM employees e,jobs j
WHERE e.`job_id`=j.`job_id`
GROUP BY job_title
ORDER BY COUNT(*) DESC;
三表连接
#查询员工名、部门名和所在的城市,且城市名是以s开头的,对部门名进行降序排序
SELECT last_name,department_name,city
FROM employees e,departments d,locations l
WHERE e.`department_id`=d.`department_id`
AND d.`location_id`=l.`location_id`
AND city LIKE 's%'ORDER BY department_name DESC;
3.非等值连接
#查询员工的工资和工资级别,并只查看A级别的。lowest_sal和highest_sal指的是最低工资和最高工资
SELECT salary,grade_level
FROM employees e,job_grades g
WHERE salary BETWEEN g.`lowest_sal` AND g.`highest_sal`
AND g.`grade_level`='A';
4.自连接
本质是把一张表当成两张表来使用。 就是和自己进行连接查询,给一张表取两个不同的别名,然后附上连接条件。
#查询员工名和上级的名称
SELECT e.employee_id,e.last_name,m.employee_id,m.last_name
FROM employees e,employees m
WHERE e.`manager_id`=m.`employee_id`;
查询与姓名 HH 同龄且籍贯也相同的学生信息SELECT B.学号, B.姓名, B.性别, B.籍贯, B.年龄
FROM student A
JOIN student B
ON A.年龄=B.年龄 AND A.籍贯=B.籍贯 AND A.姓名='HH'
练习---------
#1.显示所有员工的姓名,部门号和部门名称。
SELECT last_name,d.department_id,department_name
FROM employees e,departments d
WHERE e.`department_id` = d.`department_id`;#2.查询90号部门员工的job_id和90号部门的location_id
SELECT job_id,location_id
FROM employees e,departments d
WHERE e.`department_id`=d.`department_id`
AND e.`department_id`=90;#3. 选择所有有奖金的员工的last_name , department_name , location_id , city
SELECT last_name , department_name , l.location_id , city
FROM employees e,departments d,locations l
WHERE e.department_id = d.department_id
AND d.location_id=l.location_id
AND e.commission_pct IS NOT NULL;#4.选择city在Toronto工作的员工的last_name , job_id , department_id , epartment_name
SELECT last_name , job_id , d.department_id , department_name
FROM employees e,departments d ,locations l
WHERE e.department_id = d.department_id
AND d.location_id=l.location_id
AND city = 'Toronto';#5.查询每个工种、每个部门的部门名、工种名和最低工资
SELECT department_name,job_title,MIN(salary) 最低工资
FROM employees e,departments d,jobs j
WHERE e.`department_id`=d.`department_id`
AND e.`job_id`=j.`job_id`
GROUP BY department_name,job_title;#6.查询每个国家下的部门个数大于2的国家编号
SELECT country_id,COUNT(*) 部门个数
FROM departments d,locations l
WHERE d.`location_id`=l.`location_id`
GROUP BY country_id
HAVING 部门个数>2;#7、选择指定员工的姓名,员工号,以及他的管理者的姓名和员工号,结果类似于下面的格式
employees Emp# manager Mgr#
kochhar 101 king 100SELECT e.last_name employees,e.employee_id "Emp#",m.last_name manager,m.employee_id "Mgr#"
FROM employees e,employees m
WHERE e.manager_id = m.employee_id
AND e.last_name='kochhar';
7. sql99语法表连接
语法
- 92语法连接条件和筛选条件用的都是where,99语法连接条件用的on,筛选条件用的where
- 连接类型指的是内连、外连、交叉连接
select 字段名 from 表1 别名 【连接类型】 join 表2 别名 on 连接条件
【where 筛选条件】
【group by 分组】
【having 筛选条件】
【order by 排序列表】
1.分类
-
内连接(★):inner
等值连接
非等值连接
自连接
-
外连接
左外(★):left 【outer】
右外(★):right 【outer】 -
全连接
mysql不支持,可以通过左联接+Union+右联接的方式变相实现
-
交叉连接:cross
2.内连接(inner join)
特点
- 添加排序、分组、筛选
- inner join通过 on 来设置条件表达式,如果没有加on的话,inner join和cross join是相同的
- 连接条件放在on后面, 筛选条件放在where后面,提高分离性,便于阅读
- cross join … on 和 inner join … on 其实效果也是一样的**(但在标准sql中,cross join是不支持on的,只是Mysql支持)**
- inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集
语法
-
inner join 可以连接 ≥ 两个的表
-
inner可以省略
select 字段名 from 表1 别名 inner join 表2 别名 on 连接条件;
等值连接
#案例1.查询员工名、部门名
SELECT last_name,department_name
FROM departments d
INNER JOIN employees e
ON e.`department_id` = d.`department_id`;#案例2.查询名字中包含e的员工名和工种名(添加筛选)
SELECT last_name,job_title FROM employees e
INNER JOIN jobs j
ON e.`job_id`= j.`job_id`
WHERE e.`last_name` LIKE '%e%';#案例3. 查询部门个数>3的城市名和部门个数,(添加分组+筛选)
#①查询每个城市的部门个数
#②在①结果上筛选满足条件的
SELECT city,COUNT(*) 部门个数
FROM departments d
INNER JOIN locations l
ON d.`location_id`=l.`location_id`
GROUP BY city
HAVING COUNT(*)>3;#案例4.查询哪个部门的员工个数>3的部门名和员工个数,并按个数降序(添加排序)
#①查询每个部门的员工个数
SELECT COUNT(*),department_name
FROM employees e
INNER JOIN departments d
ON e.`department_id`=d.`department_id`
GROUP BY department_name#② 在①结果上筛选员工个数>3的记录,并排序
SELECT COUNT(*) 个数,department_name
FROM employees e
INNER JOIN departments d
ON e.`department_id`=d.`department_id`
GROUP BY department_name
HAVING COUNT(*)>3
ORDER BY COUNT(*) DESC;三表连接
查询员工名、部门名、工种名,并按部门名降序(添加三表连接)
SELECT last_name,department_name,job_title
FROM employees e
INNER JOIN departments d ON e.`department_id`=d.`department_id`
INNER JOIN jobs j ON e.`job_id` = j.`job_id`
ORDER BY department_name DESC;查询张三丰数学成绩
select s.Sname,c.Cname,sc.score from student s join sc on s.Sno = sc.Sno join course c on c.Cno = sc.Cno where s.Sname="张三丰" and c.Cname="数学";
非等值连接
#查询员工的工资级别
SELECT salary,grade_level
FROM employees e
JOIN job_grades g
ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`;#查询工资级别的个数>20的个数,并且按工资级别降序
SELECT COUNT(*),grade_level FROM employees e
JOIN job_grades g ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`
GROUP BY grade_level
HAVING COUNT(*)>20
ORDER BY grade_level DESC;
自连接
#查询员工的名字、上级的名字
SELECT e.last_name,m.last_name FROM employees e
JOIN employees m
ON e.`manager_id`= m.`employee_id`;#查询姓名中包含字符k的员工的名字、上级的名字
SELECT e.last_name,m.last_name FROM employees e
JOIN employees m
ON e.`manager_id`= m.`employee_id`
WHERE e.`last_name` LIKE '%k%';
3.外连接
应用场景
用于查询一个表中有,另一个表没有的记录
特点
- 外连接分为两种:left join、right join
- 外连接显示的内容要比内连接多,是对内连接的补充
- left join的主表是左表,从表是右表
- right join的主表是右表,从表是左表
- 外连接会返回主表的所有数据,无论在从表是否有与之匹配的数据,若从表没有匹配的数据则默认为空值(NULL)
- 外连接只返回从表匹配上的数据
- **重点:**在使用外连接时,要分清查询的结果,是需要显示左表的全部记录,还是右表的全部记录
- 左外和右外交换两个表的顺序,可以实现同样的效果
左外连接(left join)
左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。如果左表的某行在右表中没有匹配行会显示NULL
语法
- outer可以省略,只写 left join
- on是设置左连接的连接条件,不能省略
select <字段名> from <表1> left outer join <表2> <on子句>
例子
SELECT * FROM boys bo
LEFT OUTER JOIN beauty b
ON b.`boyfriend_id` = bo.`id`
left join + where例子
- **where的作用:**将上面的查询结果集进行过滤,最终只返回 id 是 null的记录
- 如果外连接中有 where 关键字,on是为了关联两张表,而where是将外连接查询的结果集进行条件筛选
- 所以执行顺序是:on -> join -> where
- **on:**筛选两张表可以进行连接数据
- **join:**将筛选后的数据连接起来
- **where:**将连接后的数据结果集再次条件筛选
#查询男朋友 不在男神表的的女神名
SELECT b.*,bo.* FROM boys bo
LEFT OUTER JOIN beauty b
ON b.`boyfriend_id` = bo.`id`
WHERE b.`id` IS NULL;#查询哪个部门没有员工
SELECT d.*,e.employee_id FROM departments d
LEFT OUTER JOIN employees e
ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
右外连接(right join)
与左(外)连接相反。右表(b_table)的记录将会全部表示出来,而左表(a_table)只会显示符合搜索条件的记录。如果右表的某行在左表中没有匹配行会显示NULL
语法
- outer可以省略,只写 right join
- on是设置左连接的连接条件,不能省略
select <字段名> from <表1> right outer join <表2> <on子句>
例子
SELECT * FROM boys bo
RIGHT OUTER JOIN beauty b
ON b.`boyfriend_id` = bo.`id`
right join + where例子
#查询哪个部门没有员工
SELECT d.*,e.employee_id FROM employees e
RIGHT OUTER JOIN departments d
ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
left join on后面where和and区别
优先级不一样
两者放置相同条件,之所以可能会导致结果集不同,就是因为优先级。on的优先级是高于where的。
例子
-
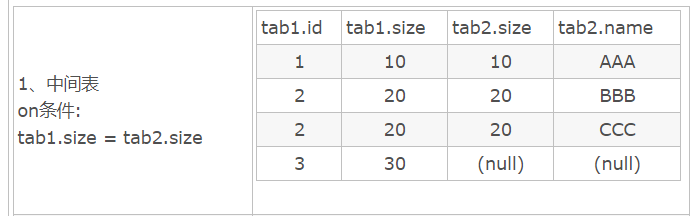
左连接结果
select * form tab1 left join tab2 on tab1.size = tab2.size
-
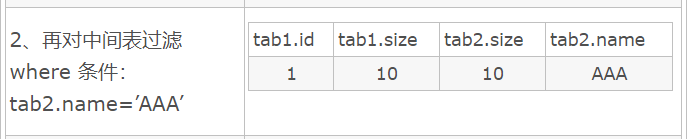
添加where结果
select * form tab1 left join tab2 on tab1.size = tab2.size where tab2.name=’AAA’只返回符合条件的行
-
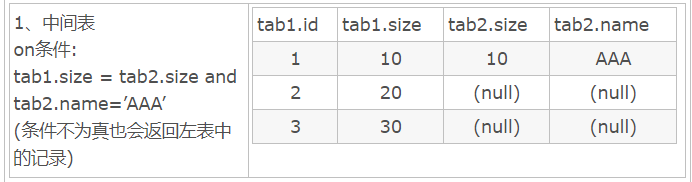
添加and结果
select * form tab1 left join tab2 on tab1.size = tab2.size and tab2.name=’AAA’哪怕不符合条件的行也会返回左表的记录
总结
- 对于JOIN参与的表的关联操作,如果需要不满足连接条件的行也在我们的查询范围内的话,我们就必需把连接条件放在ON后面,而不能放在WHERE后面(比如左表的数据范围比连接表的范围大,连接条件放在on后面,不满足连接表的会以null形式显示,如果放在where后面,就会把这些数据过滤掉)。
- 如果我们把连接条件放在了WHERE后面,那么所有的LEFT,RIGHT,等这些操作将不起任何作用,对于这种情况,它的效果就完全等同于INNER连接。对于那些不影响选择行的条件,放在ON或者WHERE后面就可以。
4.全连接
- MySQL目前不支持此种方式。
- 可以通过左联接+Union+右联接的方式变相实现。
SELECT * FROM t1
LEFT JOIN t2 ON t1.id = t2.id
UNION
SELECT * FROM t1
RIGHT JOIN t2 ON t1.id = t2.id
5.交叉连接(cross join)
- 99语法中的笛卡尔积现象,cross join相当于92中的逗号
- 添加连接条件时可以where或on(在标准sql中,cross join是不支持on的,只有Mysql支持)
- cross join … on 和 inner join … on 其实效果也是一样的
语法
select <字段名> from <表1> cross join <表2> [where]
SELECT b.*,bo.*
FROM beauty b
CROSS JOIN boys bo;
6. 联合查询(union)
定义
将多条查询语句的结果合并成一个结果
应用场景
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点
-
要求多条查询语句的查询列数是一致的!
-
要求多条查询语句的查询的每一列的类型和顺序最好一致。否则内容会错乱。
-
最终 union 连接查询的结果集的字段顺序会以第一个 sql 查出来结果集的字段顺序为基准
语法
[sql1]
union [all | distinct]
[sql2]
union [all | distinct]
[sql3]
....
- sql1、sql2、sql3:平时写的查询 sql,可以连接很多条 sql
- ALL:可选参数,返回所有结果集,包含重复数据
- distinct:可选参数,删除结果集中重复的数据(默认只写 union 也会删除重复数据,所以不加也没事)
用法
union例子
#引入的查询部门编号>90或邮箱包含a的员工信息
传统做法:
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;;联合查询:
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
union all例子
#查询中国用户中男性的信息以及外国用户中年男性的用户信息
SELECT id,cname FROM t_ca WHERE csex='男'
UNION ALL
SELECT t_id,tname FROM t_ua WHERE tGender='male';
7.92和99语法对比
功能:sql99支持的较多
可读性:sql99实现连接条件和筛选条件的分离,可读性较高
练习---------
#查询编号>3的女神的男朋友信息,如果有则列出详细,如果没有,用null填充
SELECT b.id,b.name,bo.*
FROM beauty b
LEFT OUTER JOIN boys bo
ON b.`boyfriend_id` = bo.`id`
WHERE b.id`>3;#查询哪个城市没有部门
SELECT city
FROM departments d
RIGHT OUTER JOIN locations l
ON d.`location_id`=l.`location_id`
WHERE d.`department_id` IS NULL;#查询部门名为SAL或IT的员工信息
SELECT e.*,d.department_name,d.`department_id`
FROM departments d
LEFT JOIN employees e
ON d.`department_id` = e.`department_id`
WHERE d.`department_name` IN('SAL','IT');SELECT * FROM departments
WHERE `department_name` IN('SAL','IT');
相关文章:
MYSQL1
一、为什么学习数据库 1、岗位技能需求 2、现在的世界,得数据者得天下 3、存储数据的方法 4、程序,网站中,大量数据如何长久保存? 5、数据库是几乎软件体系中最核心的一个存在。 二、数据库相关概念 (一)数据库DB 数据库是将大量数据保存起来,通过计算机加…...

一文解答Swin Transformer + 代码【详解】
文章目录 1、Swin Transformer的介绍1.1 Swin Transformer解决图像问题的挑战1.2 Swin Transformer解决图像问题的方法 2、Swin Transformer的具体过程2.1 Patch Partition 和 Linear Embedding2.2 W-MSA、SW-MSA2.3 Swin Transformer代码解析2.3.1 代码解释 2.4 W-MSA和SW-MSA…...

Vue3:<Teleport>传送门组件的使用和注意事项
你好,我是沐爸,欢迎点赞、收藏、评论和关注。 Vue3 引入了一个新的内置组件 <Teleport>,它允许你将子组件树渲染到 DOM 中的另一个位置,而不是在父组件的模板中直接渲染。这对于需要跳出当前组件的 DOM 层级结构进行渲染的…...
项目之家:又一家项目信息发布合作对接及一手接单平台
这几天“小三劝退师时薪700”的消息甚嚣尘上,只能说从某一侧面来看心理咨询师这个职业的前景还是可以的,有兴趣的朋友可以关注下。话说上一篇文章给大家介绍了U客直谈,今天趁热打铁再给大家分享一个地推拉新项目合作平台~项目之家:…...

02-java实习工作一个多月-经历分享
一、描述一下最近不写博客的原因 离我发java实习的工作的第一天的博客已经过去了一个多月了,本来还没入职的情况是打算每天工作都要写一份博客来记录一下的(最坏的情况也是每周至少总结一下的),其实这个第一天的博客都是在公司快…...

JVM 调优篇2 jvm的内存结构以及堆栈参数设置与查看
一 jvm的内存模型 2.1 jvm内存模型概览 二 实操案例 2.1 设置和查看栈大小 1.代码 /*** 演示栈中的异常:StackOverflowError** author shkstart* create 2020 下午 9:08** 设置栈的大小: -Xss (-XX:ThreadStackSize)** -XX:PrintFlagsFinal*/ public class S…...

微信可以设置自动回复吗?
在日常的微信聊天中,我们或许会频繁地遭遇客户提出的相同问题,尤其是对于从事销售工作的朋友们来说,客户在添加好友后的第一句话往往是“在吗”或者“你好”。当我们的好友数量众多时,手动逐个回复可能会耗费大量的时间。因此&…...

同样数据源走RTMP播放延迟低还是RTSP低?
背景 在比较同一个数据源,是RTMP播放延迟低还是RTSP延迟低之前,我们先看看RTMP和RTSP的区别,我们知道,RTMP(Real-Time Messaging Protocol)和RTSP(Real Time Streaming Protocol)是…...

@开发者极客们,网易2024低代码大赛来啦
极客们,网易云信拍了拍你 9月6日起,2024网易低代码大赛正式开启啦! 低代码大赛是由网易主办的权威赛事,鼓励开发者们用低代码开发的方式快速搭建应用,并最终以作品决出优胜。 从2022年11月起,网易低代码大赛…...

数据分析-16-时间序列分析的常用模型
1 什么是时间序列 时间序列是一组按时间顺序排列的数据点的集合,通常以固定的时间间隔进行观测。这些数据点可以是按小时、天、月甚至年进行采样的。时间序列在许多领域中都有广泛应用,例如金融、经济学、气象学和工程等。 时间序列的分析可以帮助我们理解和预测未来的趋势和…...

SpringMVC使用:类型转换数据格式化数据验证
01-类型转换器 先在pom.xml里面导入依赖,一个是mvc框架的依赖,一个是junit依赖 然后在web.xml里面导入以下配置(配置的详细说明和用法我在前面文章中有写到) 创建此测试类的方法用于测试springmvc是具备自动类型转换功能的 user属…...

多语言ASO – 本地化的10个技巧
ASO优化是一个复杂的领域,即使你只关注讲英语的用户。如果您想面向国际受众并在全球范围内发展您的应用程序业务,您必须在App Store和Google Play Store上本地化应用程序的产品页面。不过,应用程序商店本地化的过程也有很多陷阱。 应用商店本…...

C程序设计——函数0
函数定义 前面说过C语言是结构化的程序设计语言,他把所有问题抽象为数据和对数据的操作,前面讲的变量、常量,都是数据。现在开始讲对数据操作——函数。 C语言的函数,定义方式如下: 返回值类型 函数名(参数列表) {…...

第二十一章 rust与动静态库的结合使用
注意 本系列文章已升级、转移至我的自建站点中,本章原文为:rust与动静态库的结合使用 目录 注意一、前言二、库生成三、库使用四、总结一、前言 rust中多了很多类型的库,比如前面章节中我们提到基本的bin与lib这两种crate类型库。 如果你在命令行执行下列语句: rustc -…...

修改服务器DNS解析及修改自动对时时区
修改服务器DNS解析: 1、搜索一下当地的DNS服务器的地址 2、登录服务器,执行 vim /etc/resolv.conf文件,在nameserver字段后填写DNS服务的地址 3、chattr i /etc/resolv.conf 加上不可修改权限,防止重启DNS被修改 修改自动对时…...

中科院TOP“灌水神刊”合集!盘点那些“又牛又水”的国人友好SCI
【SciencePub学术】本期,小编给大家推荐几本“又牛又水”的期刊,并且都是清一色的国人友好刊,涵盖各领域,以供各位学者参考! NO.1 Nature Communications IF:14.7 分区:JCR1区中科院1区TOP 年…...

Python列表浅拷贝的陷阱与破解之道
引言 在Python编程世界中,列表的拷贝操作看似简单,却常常隐藏着一些令人意想不到的陷阱,尤其是当涉及到浅拷贝时。今天,我们将深入探讨Python列表浅拷贝现象及产生原因,并提供有效的解决方案,帮助你写出更…...

开放式系统互连(OSI)模型的实际意义
0 前言 开放式系统互连(OSI,Open Systems Interconnection)模型,由国际标准化组织(ISO)在1984年提出,目的是为了促进不同厂商生产的网络设备之间的互操作性。 定义了一种在层之间进行协议实现…...

回溯——10.全排列 II
力扣题目链接 给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。 示例 1: 输入:nums [1,1,2]输出: [[1,1,2], [1,2,1], [2,1,1]] 解题思路: 排序:首先对数组进行排序…...

基于百度AIStudio飞桨paddleRS-develop版道路模型开发训练
基于百度AIStudio飞桨paddleRS-develop版道路模型开发训练 参考地址:https://aistudio.baidu.com/projectdetail/8271882 基于python35paddle120env环境 预测可视化结果: (一)安装环境: 先上传本地下载的源代码Pad…...

焰境·万载——新一代文旅网站制作展示
江西万载数字文旅平台 北京高校在读生发起 AI 技术赋能县域文旅数字化转型 项目简介 焰境万载是围绕江西省万载县打造的数字文旅平台,以"中国花炮之乡"的千年烟花文化为核心,融合非遗传承、美食特产、旅游导览,以 AI 动漫角色&q…...

DVWA通关教程2
本博客所有网络安全相关教程、漏洞原理、渗透实操、攻防技术等内容,仅用于合法安全学习、白帽技术交流、企业授权安全测试。 所有技术严禁用于未授权探测、非法入侵、数据窃取、网络攻击等任何违反《中华人民共和国网络安全法》的违法行为。 任何个人利用本文内容实…...

Python异步编程深度解析:从asyncio到实战应用
Python异步编程深度解析:从asyncio到实战应用 引言 异步编程是现代Python后端开发中不可或缺的技能。作为从Python转向Rust的后端开发者,我发现Python的异步生态非常成熟,尤其是asyncio库提供了强大的异步编程能力。本文将深入探讨Python异步…...

Kubernetes StatefulSet深度解析:管理有状态应用的最佳实践
Kubernetes StatefulSet深度解析:管理有状态应用的最佳实践 一、StatefulSet概述 StatefulSet 是Kubernetes中用于管理有状态应用的控制器。它为Pod提供稳定的网络标识和持久化存储,确保Pod的有序部署、扩展和更新。 1.1 StatefulSet vs Deployment …...

Unity离线语音识别插件:解决无网/隐私/延迟三大痛点
1. 这不是“又一个语音识别SDK”——它解决的是Unity开发者真正卡脖子的三个痛点我在2022年做一款医疗陪护类AR应用时,被语音识别拖垮过整整三个月。当时用的是某云厂商的在线SDK,结果在医院内网环境下,每次识别都要等2.3秒以上,患…...

用Delphi 7打造动物农场小游戏:一场编程与数据结构的趣味之旅
文章来自:用Delphi 7打造动物农场小游戏:一场编程与数据结构的趣味之旅 当经典的Pascal语言遇上可爱的动物农场,会擦出怎样的火花? 前言 还记得第一次接触编程时的兴奋吗?当你敲下第一行代码,看到"He…...

Kali365 钓鱼平台突袭 Microsoft 365 用户:FBI 紧急预警新型 OAuth 令牌攻击链
近期,美国联邦调查局(FBI)联合网络安全与基础设施安全局(CISA)发布了一则编号为 I-052126-PSA 的私营行业通知,披露了一个正在暗处快速膨胀的威胁——名为 Kali365 的网络钓鱼即服务(PhaaS&…...

Hotkey Detective:3分钟找出Windows热键冲突的终极指南
Hotkey Detective:3分钟找出Windows热键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否遇…...

终极指南:如何在3DS上原生运行GBA游戏,告别模拟器卡顿
终极指南:如何在3DS上原生运行GBA游戏,告别模拟器卡顿 【免费下载链接】open_agb_firm open_agb_firm is a bare metal app for running GBA homebrew/games using the 3DS builtin GBA hardware. 项目地址: https://gitcode.com/gh_mirrors/op/open_a…...

终极指南:如何用TQVaultAE管理你的泰坦之旅装备库
终极指南:如何用TQVaultAE管理你的泰坦之旅装备库 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 你是否曾在《泰坦之旅周年版》中因为背包空间不足而烦恼&#…...