基于百度AIStudio飞桨paddleRS-develop版道路模型开发训练
基于百度AIStudio飞桨paddleRS-develop版道路模型开发训练
参考地址:https://aistudio.baidu.com/projectdetail/8271882
基于python35+paddle120+env环境
预测可视化结果:

(一)安装环境:
先上传本地下载的源代码PaddleRS-develop.zip
解压PaddleRS-develop.zip到目录PaddleRS
然后分别执行下面安装命令!pip install
!unzip -q /home/aistudio/data/data191076/PaddleRS-develop.zip && mv PaddleRS-develop PaddleRS
!pip install matplotlib==3.4 scikit-image pycocotools -t /home/aistudio/external-libraries
!pip install opencv-contrib-python -t /home/aistudio/external-libraries
!pip install -r PaddleRS/requirements.txt -t /home/aistudio/external-libraries
!pip install -e PaddleRS/ -t /home/aistudio/external-libraries
!pip install paddleslim==2.6.0 -t /home/aistudio/external-libraries
添加环境组件
# 因为`sys.path`可能没有及时更新,这里选择手动更新
import sys
sys.path.append('/home/aistudio/external-libraries')
sys.path.append('/home/aistudio/PaddleRS')
(二)数据预处理tran_dataPre.py
%run tran_dataPre.py
(三)开始模型训练
%run trans.py
(四) tran_dataPre.py内容如下所示:
#先解压数据集
#!unzip -oq -d /home/aistudio/massroad /home/aistudio/data/data56961/mass_road.zip# 划分训练集/验证集/测试集,并生成文件名列表import random
import os.path as osp
from os import listdirimport cv2# 随机数生成器种子
RNG_SEED = 56961
# 调节此参数控制训练集数据的占比
TRAIN_RATIO = 0.9
# 数据集路径
DATA_DIR = '/home/aistudio/massroad'# 分割类别
CLASSES = ('background','road',
)def write_rel_paths(phase, names, out_dir, prefix):"""将文件相对路径存储在txt格式文件中"""with open(osp.join(out_dir, phase+'.txt'), 'w') as f:for name in names:f.write(' '.join([osp.join(prefix, 'input', name),osp.join(prefix, 'output', name)]))f.write('\n')random.seed(RNG_SEED)train_prefix = osp.join('road_segmentation_ideal', 'training')
test_prefix = osp.join('road_segmentation_ideal', 'testing')
train_names = listdir(osp.join(DATA_DIR, train_prefix, 'output'))
train_names = list(filter(lambda n: n.endswith('.png'), train_names))
test_names = listdir(osp.join(DATA_DIR, test_prefix, 'output'))
test_names = list(filter(lambda n: n.endswith('.png'), test_names))
# 对文件名进行排序,以确保多次运行结果一致
train_names.sort()
test_names.sort()
random.shuffle(train_names)
len_train = int(len(train_names)*TRAIN_RATIO)
write_rel_paths('train', train_names[:len_train], DATA_DIR, train_prefix)
write_rel_paths('val', train_names[len_train:], DATA_DIR, train_prefix)
write_rel_paths('test', test_names, DATA_DIR, test_prefix)# 写入类别信息
with open(osp.join(DATA_DIR, 'labels.txt'), 'w') as f:for cls in CLASSES:f.write(cls+'\n')print("数据集划分已完成。")# 将GT中的255改写为1,便于训练import os.path as osp
from glob import globimport cv2
from tqdm import tqdm# 数据集路径
# DATA_DIR = '/home/aistudio/massroad'train_prefix = osp.join('road_segmentation_ideal', 'training')
test_prefix = osp.join('road_segmentation_ideal', 'testing')train_paths = glob(osp.join(DATA_DIR, train_prefix, 'output', '*.png'))
test_paths = glob(osp.join(DATA_DIR, test_prefix, 'output', '*.png'))
for path in tqdm(train_paths+test_paths):im = cv2.imread(path, cv2.IMREAD_GRAYSCALE)im[im>0] = 1# 原地改写cv2.imwrite(path, im)
(五) trans.py内容如下所示:
# 导入需要用到的库import random
import os.path as ospimport cv2
import numpy as np
import paddle
import paddlers as pdrs
from paddlers import transforms as T
from matplotlib import pyplot as plt
from PIL import Imageimport sys
sys.path.append('/home/aistudio/external-libraries')
sys.path.append('/home/aistudio/PaddleRS')# 定义全局变量# 随机种子
SEED = 56961
# 数据集存放目录
DATA_DIR = '/home/aistudio/massroad/'
# 训练集`file_list`文件路径
TRAIN_FILE_LIST_PATH = '/home/aistudio/massroad/train.txt'
# 验证集`file_list`文件路径
VAL_FILE_LIST_PATH = '/home/aistudio/massroad/val.txt'
# 测试集`file_list`文件路径
TEST_FILE_LIST_PATH = '/home/aistudio/massroad/test.txt'
# 数据集类别信息文件路径
LABEL_LIST_PATH = '/home/aistudio/massroad/labels.txt'
# 实验目录,保存输出的模型权重和结果
EXP_DIR = '/home/aistudio/exp/'# 固定随机种子,尽可能使实验结果可复现random.seed(SEED)
np.random.seed(SEED)
paddle.seed(SEED)# 构建数据集# 定义训练和验证时使用的数据变换(数据增强、预处理等)
train_transforms = T.Compose([T.DecodeImg(),# 随机裁剪T.RandomCrop(crop_size=512),# 以50%的概率实施随机水平翻转T.RandomHorizontalFlip(prob=0.5),# 以50%的概率实施随机垂直翻转T.RandomVerticalFlip(prob=0.5),# 将数据归一化到[-1,1]T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),T.ArrangeSegmenter('train')
])eval_transforms = T.Compose([T.DecodeImg(),T.Resize(target_size=1500),# 验证阶段与训练阶段的数据归一化方式必须相同T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),T.ArrangeSegmenter('eval')
])# 分别构建训练和验证所用的数据集
train_dataset = pdrs.datasets.SegDataset(data_dir=DATA_DIR,file_list=TRAIN_FILE_LIST_PATH,label_list=LABEL_LIST_PATH,transforms=train_transforms,num_workers=4,shuffle=True
)val_dataset = pdrs.datasets.SegDataset(data_dir=DATA_DIR,file_list=VAL_FILE_LIST_PATH,label_list=LABEL_LIST_PATH,transforms=eval_transforms,num_workers=0,shuffle=False
)# 构建DeepLab V3+模型,使用ResNet-50作为backbone
model = pdrs.tasks.seg.DeepLabV3P(in_channels=3,num_classes=len(train_dataset.labels),backbone='ResNet50_vd'
)
model.initialize_net(pretrain_weights='CITYSCAPES',save_dir=osp.join(EXP_DIR, 'pretrain'),resume_checkpoint=None,is_backbone_weights=False
)# 构建优化器
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.net.parameters()
)# 执行模型训练
model.train(num_epochs=100,train_dataset=train_dataset,train_batch_size=8,eval_dataset=val_dataset,optimizer=optimizer,save_interval_epochs=10,# 每多少次迭代记录一次日志log_interval_steps=30,save_dir=EXP_DIR,# 是否使用early stopping策略,当精度不再改善时提前终止训练early_stop=False,# 是否启用VisualDL日志功能use_vdl=True,# 指定从某个检查点继续训练resume_checkpoint=None
)
(六)训练生成过程信息
Output exceeds the size limit. Open the full output data in a text editor
2024-09-05 14:16:51 [INFO] Loading pretrained model from /home/aistudio/exp/pretrain/model.pdparams
2024-09-05 14:16:53 [WARNING] [SKIP] Shape of parameters head.decoder.conv.weight do not match. (pretrained: [19, 256, 1, 1] vs actual: [2, 256, 1, 1])
2024-09-05 14:16:53 [WARNING] [SKIP] Shape of parameters head.decoder.conv.bias do not match. (pretrained: [19] vs actual: [2])
2024-09-05 14:16:53 [INFO] There are 358/360 variables loaded into DeepLabV3P.
2024-09-05 14:17:46 [INFO] [TRAIN] Epoch=1/100, Step=30/90, loss=0.133503, lr=0.001000, time_each_step=1.77s, eta=4:24:32
2024-09-05 14:18:25 [INFO] [TRAIN] Epoch=1/100, Step=60/90, loss=0.181917, lr=0.001000, time_each_step=1.31s, eta=3:14:53
2024-09-05 14:19:02 [INFO] [TRAIN] Epoch=1/100, Step=90/90, loss=0.112567, lr=0.001000, time_each_step=1.22s, eta=3:2:6
2024-09-05 14:19:03 [INFO] [TRAIN] Epoch 1 finished, loss=0.15933047160506247 .
2024-09-05 14:19:44 [INFO] [TRAIN] Epoch=2/100, Step=30/90, loss=0.141528, lr=0.001000, time_each_step=1.36s, eta=3:22:2
2024-09-05 14:20:20 [INFO] [TRAIN] Epoch=2/100, Step=60/90, loss=0.165187, lr=0.001000, time_each_step=1.22s, eta=3:0:42
2024-09-05 14:20:57 [INFO] [TRAIN] Epoch=2/100, Step=90/90, loss=0.145009, lr=0.001000, time_each_step=1.22s, eta=2:59:1
2024-09-05 14:20:58 [INFO] [TRAIN] Epoch 2 finished, loss=0.1168842613697052 .
2024-09-05 14:21:39 [INFO] [TRAIN] Epoch=3/100, Step=30/90, loss=0.126603, lr=0.001000, time_each_step=1.38s, eta=3:22:13
2024-09-05 14:22:16 [INFO] [TRAIN] Epoch=3/100, Step=60/90, loss=0.117296, lr=0.001000, time_each_step=1.22s, eta=2:58:14
2024-09-05 14:22:53 [INFO] [TRAIN] Epoch=3/100, Step=90/90, loss=0.072859, lr=0.001000, time_each_step=1.23s, eta=2:58:46
2024-09-05 14:22:53 [INFO] [TRAIN] Epoch 3 finished, loss=0.10787189056475957 .
2024-09-05 14:23:34 [INFO] [TRAIN] Epoch=4/100, Step=30/90, loss=0.081685, lr=0.001000, time_each_step=1.37s, eta=3:18:39
2024-09-05 14:24:11 [INFO] [TRAIN] Epoch=4/100, Step=60/90, loss=0.087735, lr=0.001000, time_each_step=1.23s, eta=2:57:28
2024-09-05 14:24:48 [INFO] [TRAIN] Epoch=4/100, Step=90/90, loss=0.084795, lr=0.001000, time_each_step=1.22s, eta=2:55:44
2024-09-05 14:24:49 [INFO] [TRAIN] Epoch 4 finished, loss=0.10476481277081702 .
2024-09-05 14:25:30 [INFO] [TRAIN] Epoch=5/100, Step=30/90, loss=0.098625, lr=0.001000, time_each_step=1.37s, eta=3:16:59
2024-09-05 14:26:07 [INFO] [TRAIN] Epoch=5/100, Step=60/90, loss=0.078188, lr=0.001000, time_each_step=1.24s, eta=2:57:12
2024-09-05 14:26:43 [INFO] [TRAIN] Epoch=5/100, Step=90/90, loss=0.098015, lr=0.001000, time_each_step=1.21s, eta=2:52:11
2024-09-05 14:26:44 [INFO] [TRAIN] Epoch 5 finished, loss=0.10311256903741095 .
2024-09-05 14:27:25 [INFO] [TRAIN] Epoch=6/100, Step=30/90, loss=0.109136, lr=0.001000, time_each_step=1.38s, eta=3:16:8
...
2024-09-05 15:39:38 [INFO] Start to evaluate (total_samples=81, total_steps=81)...
2024-09-05 15:40:14 [INFO] [EVAL] Finished, Epoch=40, miou=0.716638, category_iou=[0.96831487 0.46496069], oacc=0.969164, category_acc=[0.97447995 0.81316509], kappa=0.619485, category_F1-score=[0.98390241 0.63477565] .
2024-09-05 15:40:14 [INFO] Current evaluated best model on eval_dataset is epoch_10, miou=0.7255623401044613
2024-09-05 15:40:18 [INFO] Model saved in /home/aistudio/exp/epoch_40.
(七) 测试集预测结果:
# 构建测试集
test_dataset = pdrs.datasets.SegDataset(data_dir=DATA_DIR,file_list=TEST_FILE_LIST_PATH,label_list=LABEL_LIST_PATH,transforms=eval_transforms,num_workers=0,shuffle=False
)# 为模型加载历史最佳权重
state_dict = paddle.load(osp.join(EXP_DIR, 'best_model/model.pdparams'))
model.net.set_state_dict(state_dict)# 执行测试
test_result = model.evaluate(test_dataset)
print("测试集上指标:IoU为{:.2f},Acc为{:.2f},Kappa系数为{:.2f}, F1为{:.2f}".format(test_result['category_iou'][1], test_result['category_acc'][1],test_result['kappa'],test_result['category_F1-score'][1])
)
2024-09-05 20:07:40 [INFO] 13 samples in file /home/aistudio/massroad/test.txt
2024-09-05 20:07:41 [INFO] Start to evaluate (total_samples=13, total_steps=13)...
测试集上指标:IoU为0.47,Acc为0.82,Kappa系数为0.62, F1为0.64
(八)预测结果可视化情况:
# 预测结果可视化
# 重复运行本单元可以查看不同结果def read_image(path):im = cv2.imread(path)return im[...,::-1]def show_images_in_row(ims, fig, title='', quantize=False):n = len(ims)fig.suptitle(title)axs = fig.subplots(nrows=1, ncols=n)for idx, (im, ax) in enumerate(zip(ims, axs)):# 去掉刻度线和边框ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)ax.spines['bottom'].set_visible(False)ax.spines['left'].set_visible(False)ax.get_xaxis().set_ticks([])ax.get_yaxis().set_ticks([])if isinstance(im, str):im = read_image(im)if quantize:im = (im*255).astype('uint8')if im.ndim == 2:im = np.tile(im[...,np.newaxis], [1,1,3])ax.imshow(im)# 需要展示的样本个数
num_imgs_to_show = 4
# 随机抽取样本
chosen_indices = random.choices(range(len(test_dataset)), k=num_imgs_to_show)# 参考 https://stackoverflow.com/a/68209152
fig = plt.figure(constrained_layout=True)
fig.suptitle("Test Results")subfigs = fig.subfigures(nrows=3, ncols=1)# 读取输入影像并显示
im_paths = [test_dataset.file_list[idx]['image'] for idx in chosen_indices]
show_images_in_row(im_paths, subfigs[0], title='Image')# 获取模型预测输出
with paddle.no_grad():model.net.eval()preds = []for idx in chosen_indices:input, mask = test_dataset[idx]input = paddle.to_tensor(input["image"]).unsqueeze(0)logits, *_ = model.net(input)pred = paddle.argmax(logits[0], axis=0)preds.append(pred.numpy())
show_images_in_row(preds, subfigs[1], title='Pred', quantize=True)# 读取真值标签并显示
im_paths = [test_dataset.file_list[idx]['mask'] for idx in chosen_indices]
show_images_in_row(im_paths, subfigs[2], title='GT', quantize=True)# 渲染结果
fig.canvas.draw()
Image.frombytes('RGB', fig.canvas.get_width_height(), fig.canvas.tostring_rgb())

(九) 导出静态模型
训练后保存的模型为动态模型,布署发布模型为静态模型,因此需要导出操作
import matplotlib.pyplot as plt
import random
import cv2
import numpy as np
import paddle
import paddlers as pdrs
from PIL import Imageimport os
from paddlers.tasks import load_modelmodel_path = './exp/best_model'img_14="i:/cwgis_ai/cup/mass_road/road_segmentation_ideal/testing/input/img-14.png"
img_10="i:/cwgis_ai/cup/mass_road/road_segmentation_ideal/testing/input/img-10.png"#save_dir="./models/road_infer_model_100"
save_dir="./models/road_infer_model_100_custom"# export model OK
# Set environment variables
os.environ['PADDLEX_EXPORT_STAGE'] = 'True'
os.environ['PADDLESEG_EXPORT_STAGE'] = 'True'# Load model from directory
model = load_model(model_path)#fixed_input_shape = None
#fixed_input_shape = [1500,1500]
fixed_input_shape = [17761,25006] #[w,h]# Do dynamic-to-static cast 动态到静态的转换
# XXX: Invoke a protected (single underscore) method outside of subclasses.
model.export_inference_model(save_dir, fixed_input_shape)
(十) 预测单张图片代码
import matplotlib.pyplot as plt
import random
import cv2
import numpy as np
import paddle
import paddlers as pdrs
from PIL import Imageimport os
from paddlers.tasks import load_model# 因为`sys.path`可能没有及时更新,这里选择手动更新
import sys
sys.path.append('/home/aistudio/external-libraries')
sys.path.append('/home/aistudio/PaddleRS')img_14="./massroad/road_segmentation_ideal/testing/input/img-14.png"
img_10="./massroad/road_segmentation_ideal/testing/input/img-10.png"
img_5="./massroad/road_segmentation_ideal/testing/input/img-5.png"customImg="./customImage/DeepLearning_Image.png" #file tif to png #model_dir="./models/road_infer_model_100"
#model_dir="./models/road_infer_model_100_None"
model_dir="./models/road_infer_model_100_custom"#model = pdrs.deploy.Predictor(model_dir)
model = pdrs.deploy.Predictor(model_dir,use_gpu=True)# 读取输入影像并显示
im_paths = [customImg]
im_lis = []
for name in im_paths:print(name)img = cv2.imread(name) print(img.shape) #img = paddle.to_tensor(img) #.unsqueeze(0) #标量输入im_lis.append(img)
# 获取模型预测输出img_file=img_10
preds = []
results = model.predict(im_lis)
#print(results)label_map=results[0]["label_map"]
#print(label_map)
label_map[label_map>0] = 255
cv2.imwrite('./outImage/label_map_custom.png', label_map)score_map=results[0]["score_map"]
#cv2.imwrite('./outImage/score_map.png', score_map[0])
print(score_map)print("预测完成")
本blog地址:https://blog.csdn.net/hsg77
相关文章:
基于百度AIStudio飞桨paddleRS-develop版道路模型开发训练
基于百度AIStudio飞桨paddleRS-develop版道路模型开发训练 参考地址:https://aistudio.baidu.com/projectdetail/8271882 基于python35paddle120env环境 预测可视化结果: (一)安装环境: 先上传本地下载的源代码Pad…...

【 C++ 】C/C++内存管理
前言: 😘我的主页:OMGmyhair-CSDN博客 目录 一、C/C内存分布 二、C语言中动态内存管理方式:malloc/calloc/realloc/free malloc: calloc: realloc: free: 三、C内存管理方式…...

智能客服的演变:从传统到向量数据库的新时代
国产数据库的发展在21世纪初取得了显著的进展。根据不完全统计,目前在国内已有超过300种不同的数据库在案。这一现象在40年前几乎是不可想象的,标志着中国在数据库领域取得了巨大的突破和多样化选择。对于对老一辈的故事或数据库发展史充满兴趣的朋友们&…...

python使用超级鹰识别验证码
1.超级鹰注册 超级鹰: https://www.chaojiying.com/ 注册后购买题分 2.获取要识别的图片 我们以这个附件下载的网页为例: https://gh.lnut.edu.cn/system/_content/download.jsp?urltypenews.DownloadAttachUrl&owner1224556702&wbfileid1504223 点开f12然后刷新几…...

基于YOLO目标检测实现表情识别(结合计算机视觉与深度学习的创新应用)
基于YOLO(You Only Look Once)的目标检测技术实现的表情识别项目是一个结合了计算机视觉与深度学习的创新应用。该项目旨在通过分析人脸图像或视频流中的面部特征来识别七种基本人类情感表达:愤怒(Angry)、厌恶&#x…...

Keil导入包出错
1.菜单栏找不到GD系列? 随便新建一个工程,将project用记事本打开后如图2所示。再将别人给的代码工程用记事本打开,发现别人给的工程少了这两行,所以复制粘贴到别人给的工程记事本中,保存刷新后重新打开,就…...

超声波自动气象站
超声波自动气象站的功能优势可以包括以下几个方面: 高精度测量:超声波自动气象站采用超声波技术进行测量,可以实现高精度的测量结果,能够准确地测量气温、湿度、风速、风向等气象参数。 高可靠性:超声波自动气象站采用…...

Mysql事件操作
查看是否开启事件 SELECT event_scheduler; SHOW VARIABLES LIKE %event_scheduler%; 开启或关闭事件 SET GLOBAL event_scheduler 1; SET GLOBAL event_scheduler on; SET GLOBAL event_scheduler 0; SET GLOBAL event_scheduler off; 创建事件sql CREATE EVENT IF…...

Python必知必会:程序员必须知道的22个Python单行代码!
今天给大家分享24个每个Python程序员都必须知道的单行代码,帮你写出更简洁、更优雅、更高效的代码。 1. 列表推导式 列表推导式(List Comprehensions)可以提供一种简洁的方式创建列表。相较于传统的循环,列表推导式更高效、可读…...

MongoDB 的适用场景
MongoDB 的适用场景 MongoDB 是一种基于文档存储的 NoSQL 数据库,与传统的关系型数据库不同,它使用 JSON 类似的二进制文档格式(BSON)来存储数据,并且具备灵活的文档模型、强大的查询能力和水平扩展性。这些特性使得 …...
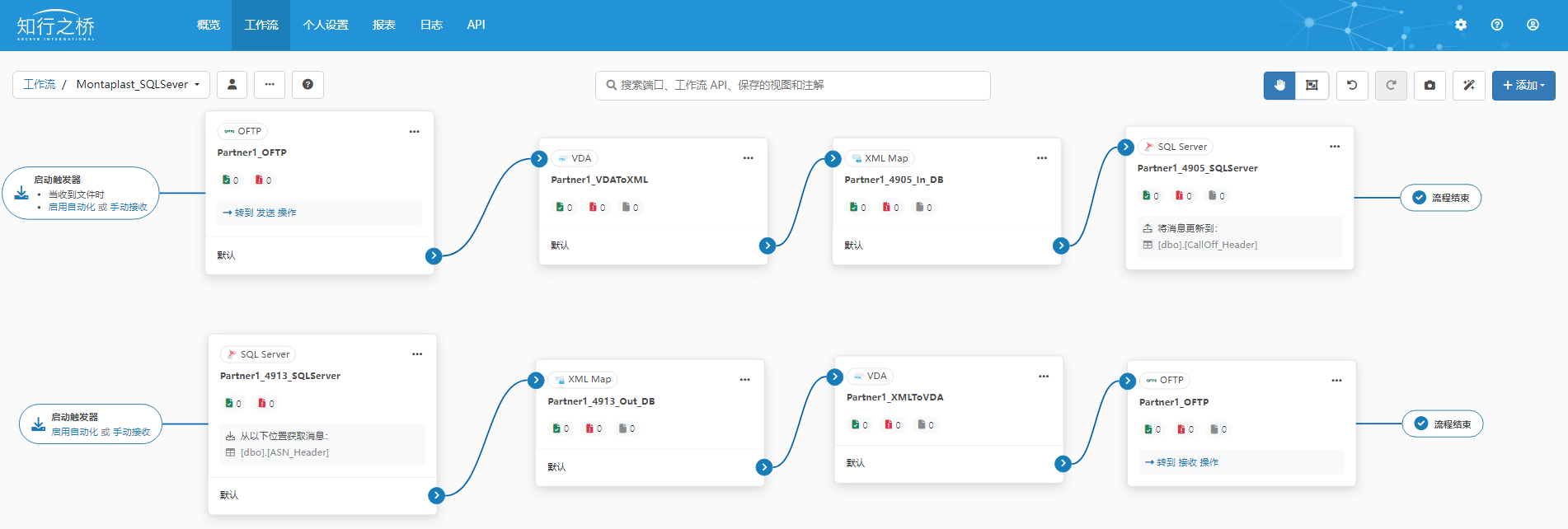
汽车EDI:montaplast EDI对接
Montaplast 是一家总部位于德国的全球知名汽车零部件供应商,专注于高精度塑料部件的设计、开发和生产。公司成立于1958年,主要为汽车行业提供轻量化、高性能的塑料解决方案。Montaplast 以其在注塑成型技术、表面处理和装配技术方面的专业能力而著称&…...

【idea】设置文件模板
搜索 File and Code Templates 。 添加模板。 在任意文件目录下右键,new->找到添加的模板。 参考链接: IDEA创建模板文件_edit file templates-CSDN博客...

时间戳和日期相互转换+检验日期合法性功能C语言
H文件 #ifndef _TIME_H_ #define _TIME_H_ #include "config.h" #include "DisplayR300.h" #include "DWIN_Fun.h" #include "DWIN_UI.h" #include <string.h>typedef struct {u16 year; /* 定义时间:年 */u8 month; /* 定义…...

SPIRNGBOOT+VUE实现浏览器播放音频流并合成音频
一、语音合成支持流式返回,通过WS可以实时拿到音频流,那么我们如何在VUE项目中实现合成功能呢。语音合成应用非常广泛,如商家广告合成、驾校声音合成、新闻播报、在线听书等等场景都会用到语音合成。 二、VUE下实现合成并使用浏览器播放代码…...

C#绘制常用工业控件(仪表盘,流动条,开关等)
目录 1,使用Graphics绘制Toggle。 效果: 测试代码: Toggle控件代码: 2,使用Graphics绘制Switch。 效果: 测试代码: Switch控件代码: 3,使用Graphics绘制PanelHe…...

Ps:颜色模型、色彩空间及配置文件
颜色模型、色彩空间和配置文件是处理颜色的核心概念。它们虽然互相关联,但各自有不同的功能和作用。 通过理解这些概念及其关系,Photoshop 用户可以更好地管理和优化图像处理流程,确保颜色在不同设备和应用中的一致性和准确性。 颜色模型 Col…...

llvm后端之td定义指令信息
llvm后端之td定义指令信息 引言1 定义指令2 定义Operand3 定义SDNode4 PatFrags4.1 ImmLeaf4.2 PatLeaf 5 ComplexPattern6 谓词条件7 理解dag 引言 llvm后端通过td定义指令信息,并通过dag匹配将IR节点转换为平台相关的指令。 1 定义指令 td通过class Instructio…...

战地机房集装箱数据中心可视化:实时监控与管理
通过图扑可视化技术实时监控战地机房集装箱数据中心的各项运行指标和环境参数,提高部署效率和设备管理能力,确保数据中心稳定运行。...

Linux入门攻坚——31、rpc概念及nfs和samba
NFS:Network File System 传统意义上,文件系统在内核中实现 RPC:函数调用(远程主机上的函数),Remote Procedure Call protocol 一部分功能由本地程序完成 另一部分功能由远程主机上的 NFS本质…...
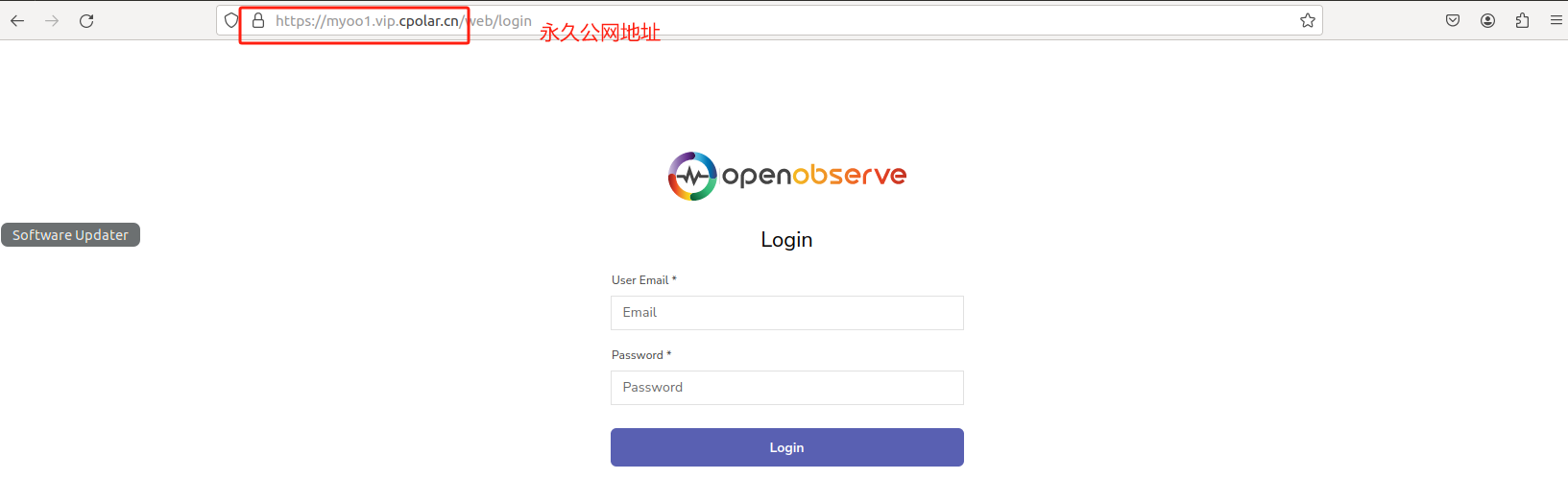
内网穿透的应用-本地化部署Elasticsearch平替工具OpenObserve并实现无公网IP远程分析数据
文章目录 前言1. 安装Docker2. Docker镜像源添加方法3. 创建并启动OpenObserve容器4. 本地访问测试5. 公网访问本地部署的OpenObserve5.1 内网穿透工具安装5.2 创建公网地址 6. 配置固定公网地址 前言 本文主要介绍如何在Linux系统使用Docker快速本地化部署OpenObserve云原生可…...

3分钟学会:全网资源一键下载神器res-downloader完全指南
3分钟学会:全网资源一键下载神器res-downloader完全指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 还在为无…...

RD-VLA:机器人动态思考的潜在空间迭代推理架构
1. 项目概述:为什么我们需要一个会“思考”的机器人模型?在机器人控制领域,我们一直梦想着能造出一个像人一样“聪明”的助手:让它去拿杯水,它能轻松完成;让它在一个杂乱无章的抽屉里找出并组装一个小零件&…...

8个必备的数据采集工具详解,低代码爬虫~
网络爬虫是一种常见的数据采集技术,你可以从网页、 APP上抓取任何想要的公开数据,当然需要在合法前提下。 爬虫使用场景也很多,比如: 搜索引擎机器人爬行网站,分析其内容,然后对其进行排名,比…...

CANN NPU 功耗优化:推理服务的能效比提升实战
功耗直接影响部署成本和设备寿命。同样的推理任务,功耗优化后能省 30% 电费,设备温度降低 10C。本文讲解 NPU 功耗的来源、动态调频策略、算子级功耗控制,以及在 CANN 上实现绿色推理的实战方法。一、NPU 功耗从哪来 1.1 功耗的三个来源 计算…...
)
AI大神吴恩达力荐,轻松入门大语言模型实战(附中文PDF+代码)
这本书由AI科普大神Jay Alammar与BERTopic算法作者Maarten Grootendorst联合撰写,是O’Reilly出版的LLM入门标杆指南,获吴恩达推荐。全书以图解方式讲解LLM原理、提示工程、文本分类生成、多模态应用及优化技术,分为理解原理、应用及优化三部…...

DMXAPI:国产多模态大模型API聚合平台,让开发者一键调用通义千问等主流模型
在国产大模型百花齐放的今天,如何高效、稳定地接入各类模型能力,成为开发者和企业面临的核心痛点。DMXAPI 应运而生,作为中国多模态大模型API聚合平台,致力于打造"国产模型一站式调用中心",让开发者无需对接…...

AI赋能百业,从城市治理到智能家居,这些应用场景让你大开眼界!
文章深入探讨了人工智能在各个领域的创新应用,包括城市治理、医疗、金融、教育、交通出行、零售电商、制造、能源、农业、智能家居、娱乐传媒、文化旅游等。通过具体的案例和技术手段,展示了AI如何提升效率、优化决策、改善生活质量。例如,成…...

零基础构建智能语音助手:小智ESP32后端服务完全指南
零基础构建智能语音助手:小智ESP32后端服务完全指南 【免费下载链接】xiaozhi-esp32-server 本项目为xiaozhi-esp32提供后端服务,帮助您快速搭建ESP32设备控制服务器。Backend service for xiaozhi-esp32, helps you quickly build an ESP32 device cont…...
)
手把手教你用WSL搞定RAX3000M路由器的SSH配置修改(Win10/Win11适用)
在Windows系统下通过WSL高效配置RAX3000M路由器的完整指南 对于习惯Windows操作系统的技术爱好者来说,想要修改路由器配置文件常常面临一个尴尬的处境——大多数高级配置工具和教程都默认用户已经熟悉Linux环境。本文将彻底解决这个痛点,教你如何在不安装…...

在自动化客服系统中集成多模型API以提升回答稳定性与成本可控性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化客服系统中集成多模型API以提升回答稳定性与成本可控性 对于需要7x24小时稳定运行的智能客服系统而言,单一模型…...