智能客服的演变:从传统到向量数据库的新时代
国产数据库的发展在21世纪初取得了显著的进展。根据不完全统计,目前在国内已有超过300种不同的数据库在案。这一现象在40年前几乎是不可想象的,标志着中国在数据库领域取得了巨大的突破和多样化选择。对于对老一辈的故事或数据库发展史充满兴趣的朋友们,我强烈推荐观看纪录片《中国数据库的前世今生》。虽然是纪录片形式,但内容生动有趣,非常值得一看。

接着这个话题,我们可以看到,尽管国产数据库在不断发展和壮大,但近年来向量数据库的兴起引起了广泛关注。向量数据库的快速发展不仅展示了其在处理复杂数据和高维数据方面的独特优势,还解决了一些传统数据库无法高效处理的技术难题。向量数据库的成功主要得益于其在大规模数据分析、实时检索和智能推荐等领域的卓越表现。
这种技术进步引发了市场的广泛关注和热烈讨论,也对传统数据库产生了不小的冲击。传统数据库在处理结构化数据和事务管理方面表现出色,但在处理非结构化数据、语义搜索和机器学习任务时往往显得力不从心。因此,向量数据库的崛起不仅推动了数据存储和处理技术的革新,也促使传统数据库系统不断适应新的需求和挑战。
我们可以以智能客服场景为例,来回顾一下从传统数据库到现在向量数据库的演变,以及国内企业在这一过程中所做的选择。
智能客服
如果谈到智能客服的起源,我们可以追溯到互联网兴起之初,那个时候国内企业已经开始探索客服系统的建设。传统的人工客服模式虽然能够提供较为贴心的服务,但却需要大量的人力资源和资金投入。尤其是面对大量的重复性问题时,人工客服不仅效率低下,而且成本高昂。因此,市场迫切需要一种更为高效和经济的解决方案来应对这些重复性的查询。

市场规模
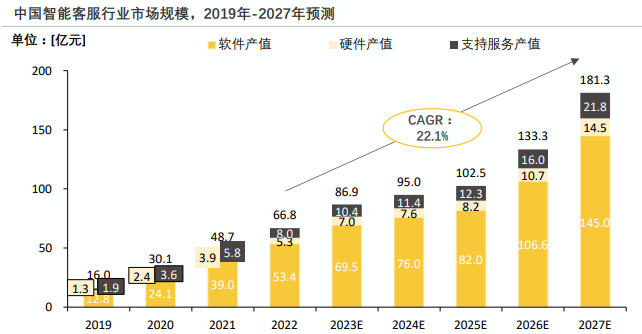
智能客服的市场规模非常庞大,且不断增长。其主要技术目标是实现对高频率、简单问题的自动处理,以大幅度减少人工客服的负担。这种自动化处理可以显著提升服务效率,降低企业成本,同时保证基础问题的快速响应。然而,对于复杂和疑难问题,人工客服仍然是不可或缺的,因为这些问题往往需要更高水平的理解和判断。
中国智能客服行业在2022年的市场规模达到了66.8亿元,预计2027年将达到181.3亿元的规模。在AI大模型的赋能下,智能客服能够实现更精准、更智能个性化的客户交互。随着A!大模型的不断开发和应用,我国智能客服行业的市场规模有望持续增长。
正因如此,各大企业在早期就开始积极寻找和探索智能客服的解决方案。通过引入先进的技术和系统,企业希望能够实现自动化处理的目标,从而优化客服流程,提高用户体验,同时保持对复杂问题的人工处理能力。这一过程中,智能客服系统的不断演进和技术创新,成为了企业提升服务质量和运营效率的关键所在。
智能客服分类
我们可以从日常生活中接触到的智能客服系统入手,来汇总并分析智能客服的几种主要类型,并探讨向量数据库如何解决了智能客服中的关键痛点,从而推动了其快速发展。
首先,智能客服系统可以分为几种主要类型:
- 任务管理类模块:
这种类型的智能客服系统主要专注于特定任务的处理。例如,订机票、预订酒店等功能,这类系统类似于苹果的Siri,属于任务处理型的智能助手。它们旨在完成具体的任务,通过预定义的流程和操作,帮助用户高效地达成目标。 - 知识库问答系统:
知识库问答系统主要用于提供咨询类的回答。它们依托于一个预设的知识库,处理用户提出的各种咨询问题。与任务管理系统不同,知识库问答系统并不处理实际的任务,只是提供信息和建议。这类系统的核心是维护一个详尽的知识库,确保能够准确回答用户的问题。 - 知识图谱问答系统:
知识图谱问答系统则利用图结构来提供信息。这类系统不仅包含问答对结构和树型结构,还通过知识图谱将相关的信息以图的形式组织起来。知识图谱可以更全面地展示和关联各种信息,因此它被认为是广义上的知识库问答系统。这种结构使得智能客服能够在更大范围内提供准确的信息和关联性回答。 - 聊天机器人:
聊天机器人虽然并非客服的首要功能,但在智能客服系统中仍然占有重要地位。聊天功能的引入有两个主要原因:首先,在用户没有输入知识库内容或需要对系统进行技术能力测试时,聊天机器人可以充当评测对象;其次,在某些场景下,聊天功能可以使客服对话更为自然和生动,减少单调感。尽管如此,很多智能客服系统允许用户选择关闭聊天功能,以便专注于文字客服。
值得注意的是,语音识别技术虽然也是智能客服领域的一部分,但由于其涉及的技术和应用场景较为复杂,我们在此暂不展开讨论。
工作原理
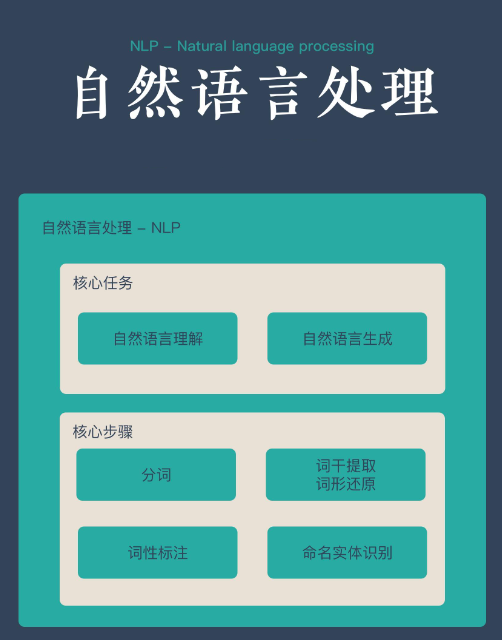
自然语言理解
自然语言理解(NLU)主要涉及以下几个关键任务:首先,当用户的问题由多个句子组成时,我们需要进行“分句”处理,以便对每个句子进行独立的理解和回答。最终,将这些独立的答案组合起来,提供给用户。其次,“分词”是非常常见的处理步骤,它是理解文本的基础。分词之后,我们可以进行进一步的处理,例如标注、实体识别等。
除此之外,句法分析也是重要的处理环节,它帮助我们了解句子中的结构和关系。指代消解则用于确定句子中代词所指代的实体,从而提高理解的准确性。此外,词权重计算和语义相似度分析也是关键步骤,这些分析为后续的算法提供了重要的数据支持。总的来说,这些步骤构成了自然语言理解的预处理阶段,为更复杂的语言处理任务奠定基础。
意图识别
第二部分的预处理工作是意图识别。意图识别的核心在于解析用户的句子,揭示其背后的意图。例如,在用户提问“今天天气怎么样”时,意图识别系统能够识别出用户的主要目的是询问天气情况。再比如,当用户说“帮我定一张去长春的机票”时,意图识别系统会明确其意图是要求预订机票。
意图识别通常通过两种主要方式实现:模板匹配和分类器。模板匹配的方法涉及创建特定的词典,例如一个包含城市名(如“北京”、“上海”、“天津”)的“city”词典,以及一个包含时间词汇(如“今天”、“明天”、“后天”)的“date”词典。系统会根据这些词典构建模板,比如“city”词典中的城市名与“date”词典中的日期词汇配合,并包含关键词如“天气”,从而识别出询问天气的意图。这样,当句子匹配这些模板时,我们可以确定用户的意图。
我们可以用Python代码来简单实现基本的意图识别:
import re
# 城市词典
city_dict = ["北京", "上海", "天津", "广州", "深圳"]# 日期词典
date_dict = ["今天", "明天", "后天"]# 模板
weather_template = ["city", "任意字符串", "date", "天气"]def match_template(user_input):# 定义正则表达式city_pattern = "|".join(city_dict)date_pattern = "|".join(date_dict)pattern = rf"({city_pattern}).*({date_pattern}).*天气"# 匹配用户输入match = re.search(pattern, user_input)if match:return "询问天气的意图"else:return "未识别意图"# 测试
user_input = "北京今天天气怎么样?"
print(match_template(user_input)) # 输出: 询问天气的意图
虽然模板匹配方法在实现上简单、易于理解和维护,并且适用于规则明确且结构化的场景,但它的灵活性相对较差。对于复杂或多变的表达方式,它的处理能力有限,因为模板只能识别与预定义模式匹配的句子。此外,该方法无法处理词典中未出现的词汇或词汇的变化形式,这可能导致对用户意图的识别不够全面或准确。
分类器方法在意图识别中也非常有效,其核心思想是通过机器学习模型对用户的意图进行分类。具体实现时,我们需要在特定领域内收集大量的语料,并对这些语料进行人工标注,以确定它们对应的具体意图。接着,我们使用这些标注好的数据来训练分类器模型,这些模型可以是二分类器或者多分类器,用于对新的输入进行意图分类。
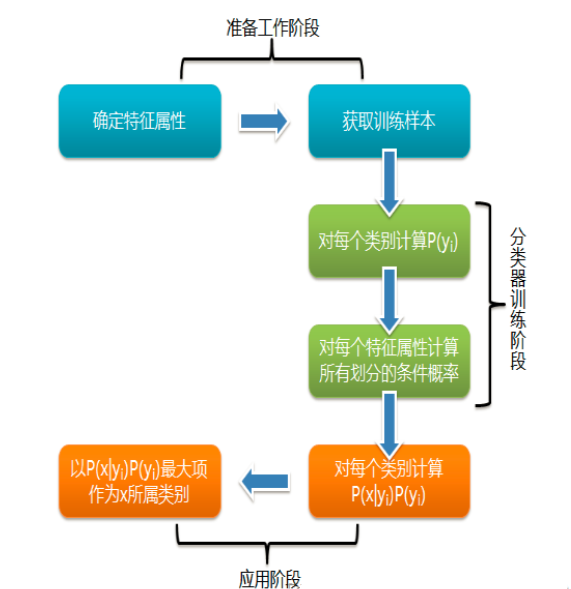
然而,尽管分类器方法能够处理复杂的句子结构和多样化的表达方式,它也有一些挑战。首先,它需要大量的人工标注数据,这个过程不仅耗时且成本高昂。标注数据的质量直接影响模型的表现,因此需要确保标注的准确性。其次,分类器方法还面临如何有效收集和处理来自多个领域的语料的问题。不同领域的语料可能具有不同的特征和表达方式,这需要在数据收集和预处理过程中进行适当的调整和优化。
知识库问答
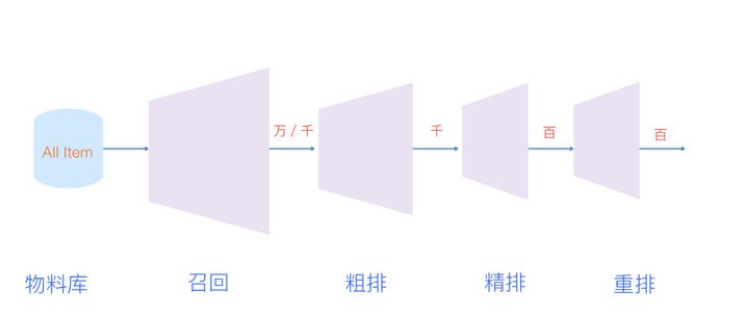
接下来,我们将讨论系统中的功能模块。首先,我们关注第一个最常见的模块——知识库问答功能。这一功能在智能客服系统中非常普遍,其核心技术本质上与搜索引擎技术类似,但应用方式有所不同。知识库问答功能通常分为两个主要阶段:候选集召回和重排序。
在候选集召回阶段,系统通过多种方式从知识库中选出与用户查询最相关的候选答案。虽然召回方法有很多种,但相较于搜索引擎的复杂性,知识库的召回过程相对简单。这是因为搜索引擎需要处理海量的信息检索,而知识库的内容通常是由人工导入和维护的,规模相对较小,因此召回的复杂度较低。
接下来的重排序阶段旨在对候选集中的答案进行排序,以找到最合适的回应。这个过程可以利用多种技术来实现,包括文本相似度、检索相关度等。如果数据量足够,神经网络的语义相似度模型也可以应用于重排序。为了提高准确性,系统还可以采用多模型融合的方法,将不同模型的结果综合考虑,以获得最终的答案。
知识图谱问答
接下来是跟知识库比较相关的一种工作,知识图谱问答。
知识图谱(Knowledge Graph, KG)是一种语义网络,它通过节点和边的形式来表示实体及其关系。每个节点代表一个实体(如人、地点、事件),边则表示实体之间的关系(如“属于”、“位于”、“影响”)。知识图谱不仅存储结构化信息,还可以融入语义信息,实现更智能的信息检索和推理。
在人工智能领域,知识图谱的重要性显而易见。它提供了一种机器可读的知识表达方式,使计算机能够更好地理解和处理复杂的人类语言及其与现实世界的关系。通过构建知识图谱,人工智能系统能够实现更有效的知识整合、推理和查询,从而在众多应用领域发挥关键作用。
然而,在知识图谱问答系统的实现中,最具挑战性的部分是数据的整理,其次是选择和优化合适的工具。
假设我们已经解决了数据来源和更新的问题,并且具备了所需的工具,接下来的关键任务就是进行查询转换。由于大多数知识图谱工具采用特定的查询语言,我们需要将自然语言通过某种方式转换成这些工具支持的查询语言。
这一转换过程通常有两种常见的方法:其一是使用模板来进行查询转换,其二是如果数据量足够大,可以利用机器翻译技术实现转换。此外,知识库和知识图谱可以整合成一个统一的模块,这种模块通常被称为知识库问答系统。
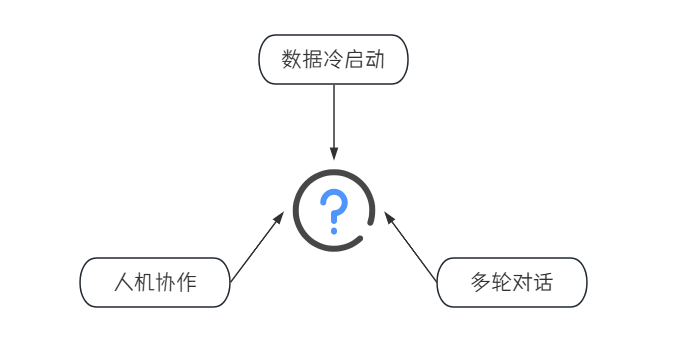
目前,我们可以总结出几个技术难点必须解决。第一个难点是数据冷启动问题。在大多数情况下,我们初期没有足够的数据来训练模型,导致知识图谱中的实体和关系较少,从而限制了知识的覆盖范围,这会使系统在回答用户复杂问题时遇到困难。初始阶段的数据更新和扩展速度较慢,影响了图谱的丰富程度和准确性。
第二个难点是多轮对话问题。在智能客服系统中,多轮对话是一个重大挑战。多轮对话涉及用户和系统之间的多次互动,通常包括多个问题和回答。处理这种对话时,系统必须有效地保持对话的上下文和状态,以便提供一致且相关的回答。
第三个难点是人机协作。在现有的智能客服系统中,人机协作的方式尚未能最大化机器人的价值。当前机器人主要作为辅助工具,未能成为系统中的主要决策者或处理者,这限制了其在智能客服中的潜力和作用。
开发方式
知识图谱最常见的应用场景之一就是智能客服,但其开发过程复杂且耗时。开发流程通常包括以下步骤:
- 定义需求:明确智能客服系统需要解决的问题和目标功能。
- 构建知识图谱:创建和组织包含各种实体和关系的知识图谱,以支持系统的知识库。
- 集成知识图谱:将构建好的知识图谱与系统进行集成,确保信息流的顺畅。
- 对话系统设计:设计智能客服的对话系统,包括对话流程、用户交互方式和响应机制。
- 测试和优化:对系统进行测试,优化其性能和准确性,确保能够高效回答用户问题。
- 部署和维护:将系统投入实际使用,并进行持续的维护和更新,以应对新的需求和挑战。
在这个过程中,知识图谱的维护是一个非常耗时且需要大量人力资源的环节。即使使用第三方服务,企业仍然难以对其进行高度个性化设置,尤其是针对企业内部特有的问题解决方案。因此,通常只有大型企业才能负担得起这样的解决方案,而小型网站或企业则往往无法开发或实施这样的智能助手。
AI的浪潮出现
在去年的时候,OpenAI发布的ChatGPT可谓是彻底颠覆了大众对智能客服的认知。传统智能客服主要集中解决两个问题:首先是处理与企业相关的标准化问题,其次是无法像人类一样进行自然流畅的沟通交流。遇到这种客服时,许多人常常会优先选择人工服务。

然而,随着AI技术的发展,ChatGPT的出现使得与智能客服的交流变得更加自然和灵活。用户可以随心所欲地提问,无论是技术问题、开发难题,还是企业内部的各种问题,ChatGPT都能提供详细的解答和建议。这种能力不仅提升了用户体验,还极大地拓宽了智能客服的应用范围和效能。
提示词助手
此时,智能客服领域迎来了新的发展方向,即通过直接对接API来提升其功能。然而,最初人们发现,结合适当的提示词可以显著改善AI的回答质量。于是,各种各样的提示词被设计出来,以帮助大模型在不同的客服场景中表现得更加出色。
随着这种趋势的加剧,国内的大型企业和初创公司纷纷投入到大模型的开发中,仿佛在这股浪潮中没有自己的大模型就会面临淘汰一样。在这种背景下,腾讯也迅速响应,开发出了自己的混元大模型,以便在激烈的市场竞争中占据一席之地。

开发方式
在此阶段,智能客服的开发方式已变得相对成熟,企业可以通过本地编写提示词,并提供相关的参考数据来定制智能客服解决方案。这种方法使得构建企业专属的客服系统变得更加便捷和高效。
然而,即便如此,这种策略仍未能彻底解决大模型时常出现的“一本正经的胡说八道”问题。大模型在处理某些复杂或模糊问题时,仍可能给出不准确或不切实际的回答,这在某种程度上限制了其在实际应用中的可靠性和有效性。
AI的插件功能浪潮
2023年3月23日,OpenAI推出了ChatGPT插件系统,该系统以安全性为核心设计,允许ChatGPT通过插件连接到各种第三方应用程序,并执行多种操作,包括检索实时信息、访问知识库和代用户进行各类操作等。

由于集成了知识库插件,这一系统显著提升了大模型的回答准确性,使得通过精心设计的提示词结合插件功能,能够有效地解决约90%的“一本正经的胡说八道”问题。这样的进步不仅增强了智能客服的实用性,也大幅提高了其在实际应用中的可靠性。
向量数据库
向量数据库的广泛应用和火热趋势在今年才真正显现出来,这与OpenAI推出的插件功能密切相关。通过这一插件系统,ChatGPT可以利用大模型的能力来访问和处理各类数据,从而极大地推动了向量数据库的实际应用。插件系统不仅增强了大模型的数据处理能力,还促进了向量数据库在信息检索和知识管理等领域的应用,进一步推动了数据驱动技术的创新和发展。
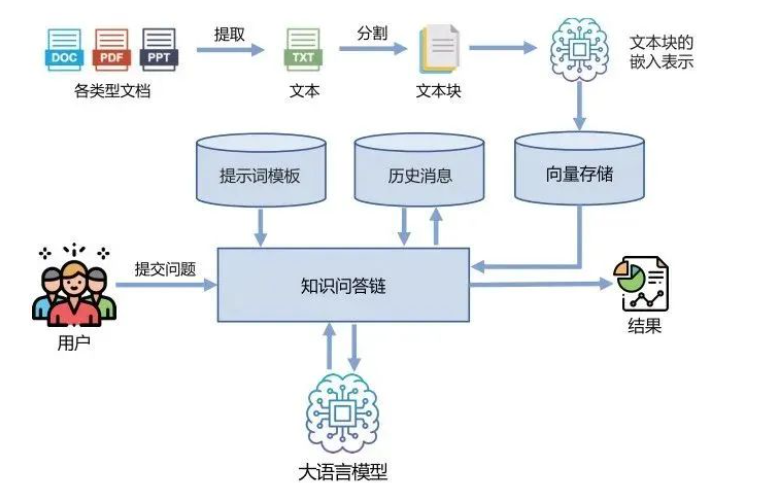
腾讯云在向量数据库领域的投入,源自于对市场需求的洞察。经过调研,他们发现许多企业已经在使用向量数据库,特别是在大模型的上下文中,向量数据库作为解决方案显得尤为重要。
大模型基于公开数据进行训练,而企业的私有数据往往无法被直接利用。为了让大模型有效服务于企业,企业需要通过两种主要方式来处理数据:预训练和微调。然而,这两种方式的成本和技术门槛较高,因此并非所有企业都能负担得起。此时,向量数据库作为一种成本较低、操作简单的解决方案,便成为了企业的优选。
向量数据库的核心在于将文本、图片等信息转化为向量数据,并通过相似度计算来进行检索。这种技术通过索引优化,提高了检索效率,使得大模型能够更快速地处理数据。腾讯在内部已有多年向量数据库的经验,并将这些经验转化为云服务产品,使得向量数据库能够在实际应用中发挥作用。
工作原理
向量是指在数学和物理中用来表示大小和方向的量。它由一组有序的数值组成,这些数值代表了向量在每个坐标轴上的分量。
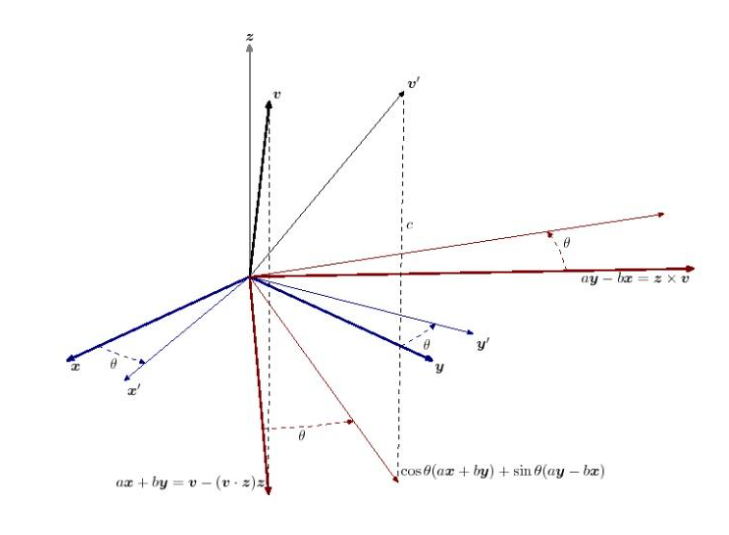
向量检索是一种基于向量空间模型的信息检索方法。向量数据库通过相似度计算方法计算两个向量之间的相似距离来分析它们之间的相关性。如果两个嵌入向量非常相似,则意味着原始数据源也相似。
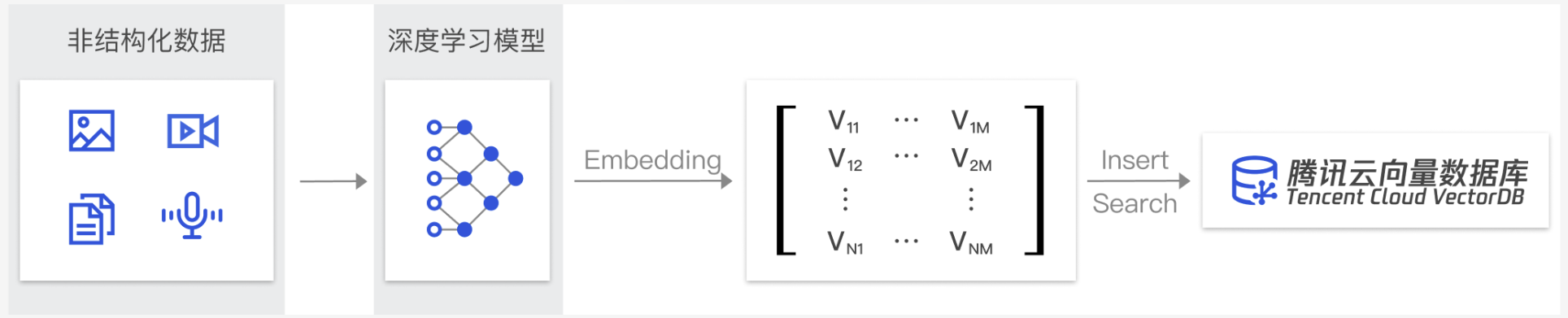
直观来说,你可以将所有的知识库中的非结构化数据(如文字、图片等)想象成向量数据,因为计算机只能处理数字。具体而言,这些非结构化数据会被转换为数字向量,例如:[0.2123,0.23,0.213]。这种数字化表示使得计算机能够进行高效的计算和处理,从而使复杂的数据分析和检索变得可行。
开发方式
尽管在当前阶段,人们的开发方式尚未完全采用大模型的函数调用形式,但公司内部的开发方法已经发生了显著转变。现在的做法是:首先,通过提前搜索向量数据库中的企业内部私有知识,并将这些信息提供给大模型;然后,通过结合提示词的方式来完成一轮正常的智能问答。这种方法利用了大模型本身所具备的多轮问答能力,从而实现了高效的信息检索和互动问答。
实际上,这种开发模式使得任何企业,只要具备一定的技术能力,都可以轻松地对接并实现类似的智能应用。无论企业的规模或领域如何,只需借助现有技术,就能创建出高效的智能问答系统,从而提高工作效率和信息处理能力。
智能体浪潮
可以说,今年最为热门的发展趋势就是智能体。这一趋势的崛起主要因为它从技术层面显著降低了企业使用大模型的技术门槛。正如我们之前提到的,虽然向量数据库提供了一种技术解决方案,但企业仍需有技术团队来进行开发和实施。
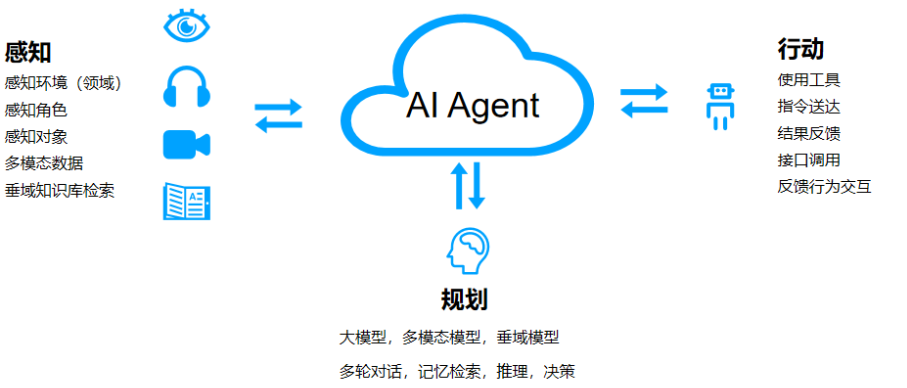
然而,智能体的出现彻底消除了这一顾虑。通过智能体,用户可以利用图形界面直接将知识库手动上传,从而省去了复杂的开发过程。这种直观的操作方式不仅简化了技术应用,还大大减少了企业在部署智能问答系统时的时间和成本。智能体的这种易用性,使得各类企业能够更快速、高效地实现智能化,推动了技术的广泛应用。
知识库-向量数据库
在这里,我们将对各种智能体平台的知识库功能进行一个简要的讲解,以腾讯元器为例来进行演示。这一过程将帮助大家更好地理解智能体平台如何管理和利用知识库,以及这些功能如何在实际应用中发挥作用。
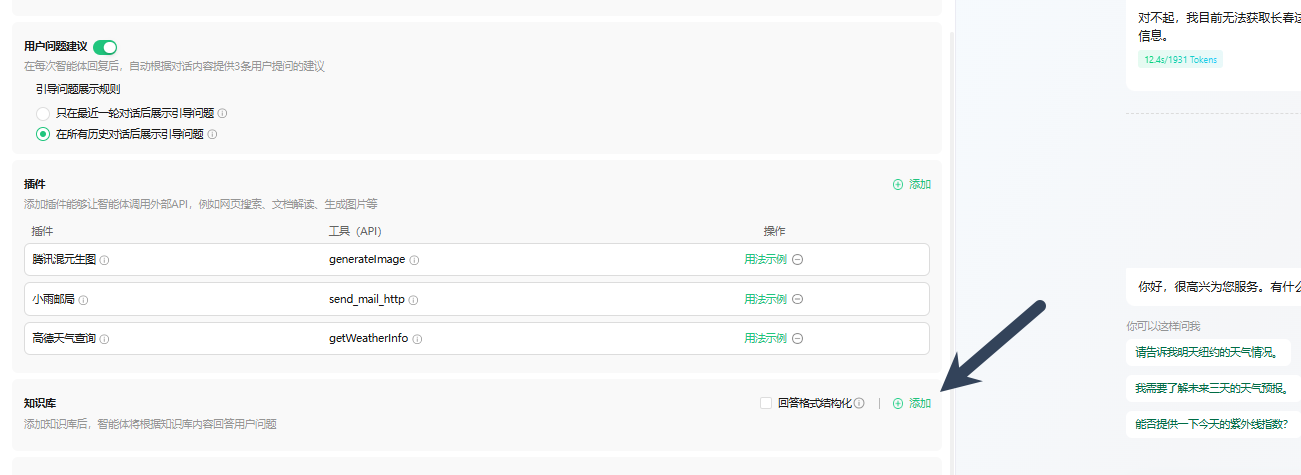
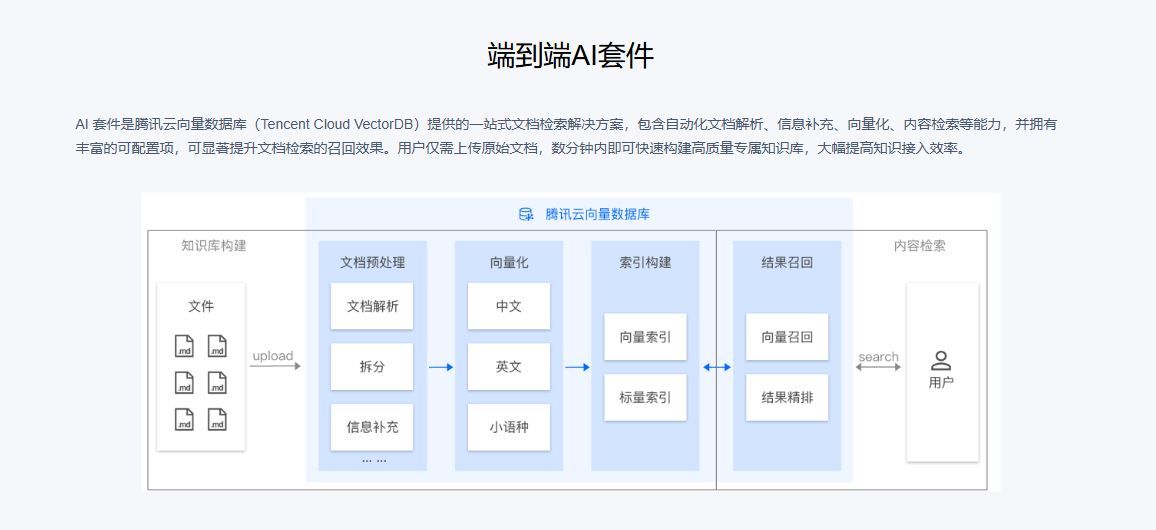
这里的知识库实际上完全依赖于向量数据库在后台的强大支持。当我们上传文件时,系统会自动将这些文件转换成相应的向量,并将这些向量插入到向量数据库中。
向量数据库在这个过程中扮演了关键角色,它不仅存储了这些向量,还使得后续的检索和查询变得更加高效。通过这种方式,知识库能够更精准地处理用户查询,实现智能体的高效信息检索和问答能力。
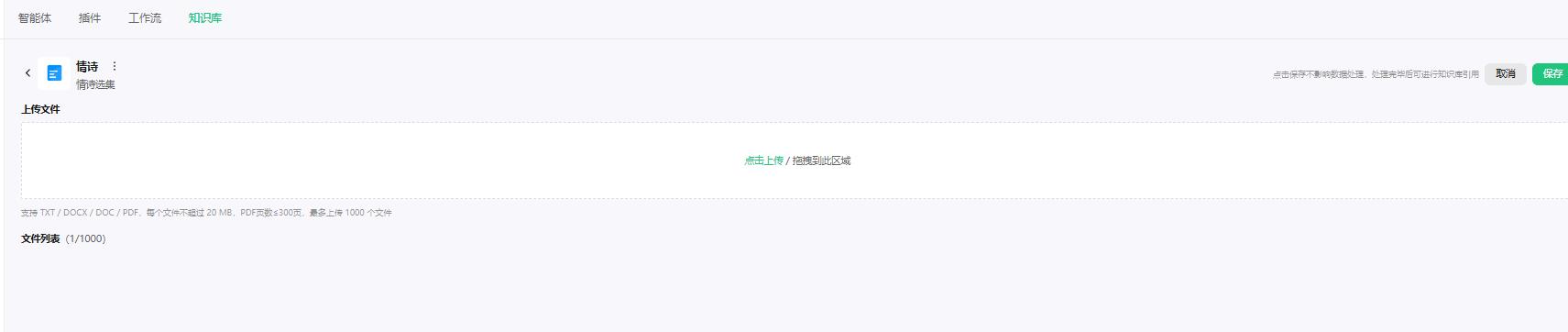
接下来,您可以通过维护和更新知识库的方式,使智能体能够随时调用并有效地回复用户提出的问题。通过定期更新知识库,您可以确保智能体获得最新的、最相关的信息,从而提高其回答问题的准确性和有效性。
这样,智能体不仅能快速检索和处理存储在知识库中的信息,还能不断适应业务需求的变化,提供更加智能化和个性化的服务。
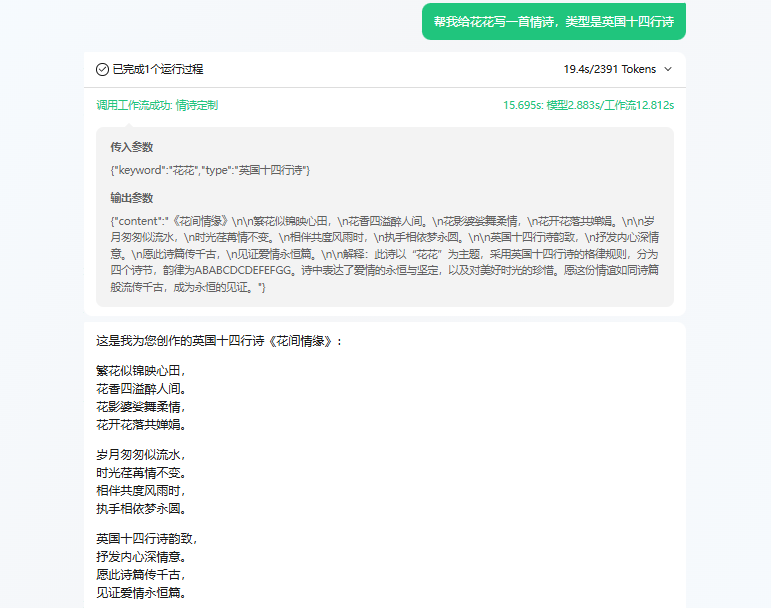
开发方式
这样,大多数公司只需对接智能体的API,即可完成智能客服系统的开发。通过这种方式,企业可以实现智能体的即时上线与维护,无需担心服务器管理或技术开发的复杂问题。对接API的过程相对简单,公司只需掌握基本的操作即可开始使用。此外,智能体还可以轻松地发布到各大平台,如微信订阅号等,这进一步减少了对接和集成的复杂性。

因此,尽管大模型技术在不断发展,向量数据库在数据处理和管理中的角色依然不可或缺。向量数据库与大模型的关系体现了计算与存储需求的分离,这种分离将成为长期的趋势。大模型虽然在不断提升,但向量数据库在数据检索、管理和调度中的作用依旧显著。它不仅改变了数据处理的方式,使得检索更加自然和直观,还为数据管理带来了新的范式。向量数据库的技术创新提供了一种高效的方式来优化数据的访问和应用,确保了数据处理的灵活性和高效性。
总结
国产数据库在21世纪初取得了显著进展,超出了许多人当年的预期。如今,国内已拥有超过300种不同的数据库,这一现象不仅展现了中国在数据库领域的创新和突破,也为企业和个人提供了丰富的选择。然而,技术的演进并未止步于此。近年来,向量数据库的兴起在数据处理和存储领域掀起了新的风潮。
向量数据库的崛起,为传统数据库提供了强有力的补充。它的优势在于处理复杂数据和高维数据时的高效性,尤其是在大规模数据分析、实时检索和智能推荐等领域表现突出。传统数据库在结构化数据和事务管理方面表现优异,但在非结构化数据处理、语义搜索和机器学习任务中的局限性逐渐显现。向量数据库的出现,不仅推动了数据存储和处理技术的革新,也迫使传统数据库系统不断调整和适应新的技术要求和挑战。
在智能客服领域,这种技术演变尤为明显。智能客服从最初的人工模式逐步转向自动化和智能化。早期,企业通过人工客服解决大量重复性问题,但这种方法既耗时又昂贵。随着技术的发展,智能客服系统逐渐引入了自然语言处理、知识库问答和聊天机器人等先进功能。智能客服不仅能高效处理高频问题,还通过机器学习和自然语言处理技术提升了用户体验。然而,对于复杂的疑难问题,人工客服仍然具有不可替代的优势。
随着AI技术的飞速发展,尤其是大模型的出现,智能客服系统的功能和表现得到了进一步的提升。OpenAI的ChatGPT、智能体平台和向量数据库的结合,为智能客服带来了全新的应用场景和可能性。智能体的引入使得企业能够更加便捷地部署和维护智能客服系统,通过对接API和优化知识库,企业能够实现高效的智能化服务。
展望未来,国产数据库和向量数据库的发展将继续推动数据处理和存储技术的创新。随着大模型和智能体技术的不断成熟,企业将能够更好地利用这些先进工具,提高信息处理效率和用户服务质量。国产数据库的多样化和向量数据库的技术革新,不仅标志着中国在数据技术领域的持续进步,也为全球科技的发展贡献了新的力量。智能客服的演变和AI技术的应用,预示着我们正迈向一个更加智能和高效的未来。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
相关文章:
智能客服的演变:从传统到向量数据库的新时代
国产数据库的发展在21世纪初取得了显著的进展。根据不完全统计,目前在国内已有超过300种不同的数据库在案。这一现象在40年前几乎是不可想象的,标志着中国在数据库领域取得了巨大的突破和多样化选择。对于对老一辈的故事或数据库发展史充满兴趣的朋友们&…...

python使用超级鹰识别验证码
1.超级鹰注册 超级鹰: https://www.chaojiying.com/ 注册后购买题分 2.获取要识别的图片 我们以这个附件下载的网页为例: https://gh.lnut.edu.cn/system/_content/download.jsp?urltypenews.DownloadAttachUrl&owner1224556702&wbfileid1504223 点开f12然后刷新几…...

基于YOLO目标检测实现表情识别(结合计算机视觉与深度学习的创新应用)
基于YOLO(You Only Look Once)的目标检测技术实现的表情识别项目是一个结合了计算机视觉与深度学习的创新应用。该项目旨在通过分析人脸图像或视频流中的面部特征来识别七种基本人类情感表达:愤怒(Angry)、厌恶&#x…...

Keil导入包出错
1.菜单栏找不到GD系列? 随便新建一个工程,将project用记事本打开后如图2所示。再将别人给的代码工程用记事本打开,发现别人给的工程少了这两行,所以复制粘贴到别人给的工程记事本中,保存刷新后重新打开,就…...

超声波自动气象站
超声波自动气象站的功能优势可以包括以下几个方面: 高精度测量:超声波自动气象站采用超声波技术进行测量,可以实现高精度的测量结果,能够准确地测量气温、湿度、风速、风向等气象参数。 高可靠性:超声波自动气象站采用…...

Mysql事件操作
查看是否开启事件 SELECT event_scheduler; SHOW VARIABLES LIKE %event_scheduler%; 开启或关闭事件 SET GLOBAL event_scheduler 1; SET GLOBAL event_scheduler on; SET GLOBAL event_scheduler 0; SET GLOBAL event_scheduler off; 创建事件sql CREATE EVENT IF…...

Python必知必会:程序员必须知道的22个Python单行代码!
今天给大家分享24个每个Python程序员都必须知道的单行代码,帮你写出更简洁、更优雅、更高效的代码。 1. 列表推导式 列表推导式(List Comprehensions)可以提供一种简洁的方式创建列表。相较于传统的循环,列表推导式更高效、可读…...

MongoDB 的适用场景
MongoDB 的适用场景 MongoDB 是一种基于文档存储的 NoSQL 数据库,与传统的关系型数据库不同,它使用 JSON 类似的二进制文档格式(BSON)来存储数据,并且具备灵活的文档模型、强大的查询能力和水平扩展性。这些特性使得 …...
汽车EDI:montaplast EDI对接
Montaplast 是一家总部位于德国的全球知名汽车零部件供应商,专注于高精度塑料部件的设计、开发和生产。公司成立于1958年,主要为汽车行业提供轻量化、高性能的塑料解决方案。Montaplast 以其在注塑成型技术、表面处理和装配技术方面的专业能力而著称&…...

【idea】设置文件模板
搜索 File and Code Templates 。 添加模板。 在任意文件目录下右键,new->找到添加的模板。 参考链接: IDEA创建模板文件_edit file templates-CSDN博客...

时间戳和日期相互转换+检验日期合法性功能C语言
H文件 #ifndef _TIME_H_ #define _TIME_H_ #include "config.h" #include "DisplayR300.h" #include "DWIN_Fun.h" #include "DWIN_UI.h" #include <string.h>typedef struct {u16 year; /* 定义时间:年 */u8 month; /* 定义…...

SPIRNGBOOT+VUE实现浏览器播放音频流并合成音频
一、语音合成支持流式返回,通过WS可以实时拿到音频流,那么我们如何在VUE项目中实现合成功能呢。语音合成应用非常广泛,如商家广告合成、驾校声音合成、新闻播报、在线听书等等场景都会用到语音合成。 二、VUE下实现合成并使用浏览器播放代码…...

C#绘制常用工业控件(仪表盘,流动条,开关等)
目录 1,使用Graphics绘制Toggle。 效果: 测试代码: Toggle控件代码: 2,使用Graphics绘制Switch。 效果: 测试代码: Switch控件代码: 3,使用Graphics绘制PanelHe…...

Ps:颜色模型、色彩空间及配置文件
颜色模型、色彩空间和配置文件是处理颜色的核心概念。它们虽然互相关联,但各自有不同的功能和作用。 通过理解这些概念及其关系,Photoshop 用户可以更好地管理和优化图像处理流程,确保颜色在不同设备和应用中的一致性和准确性。 颜色模型 Col…...

llvm后端之td定义指令信息
llvm后端之td定义指令信息 引言1 定义指令2 定义Operand3 定义SDNode4 PatFrags4.1 ImmLeaf4.2 PatLeaf 5 ComplexPattern6 谓词条件7 理解dag 引言 llvm后端通过td定义指令信息,并通过dag匹配将IR节点转换为平台相关的指令。 1 定义指令 td通过class Instructio…...

战地机房集装箱数据中心可视化:实时监控与管理
通过图扑可视化技术实时监控战地机房集装箱数据中心的各项运行指标和环境参数,提高部署效率和设备管理能力,确保数据中心稳定运行。...

Linux入门攻坚——31、rpc概念及nfs和samba
NFS:Network File System 传统意义上,文件系统在内核中实现 RPC:函数调用(远程主机上的函数),Remote Procedure Call protocol 一部分功能由本地程序完成 另一部分功能由远程主机上的 NFS本质…...
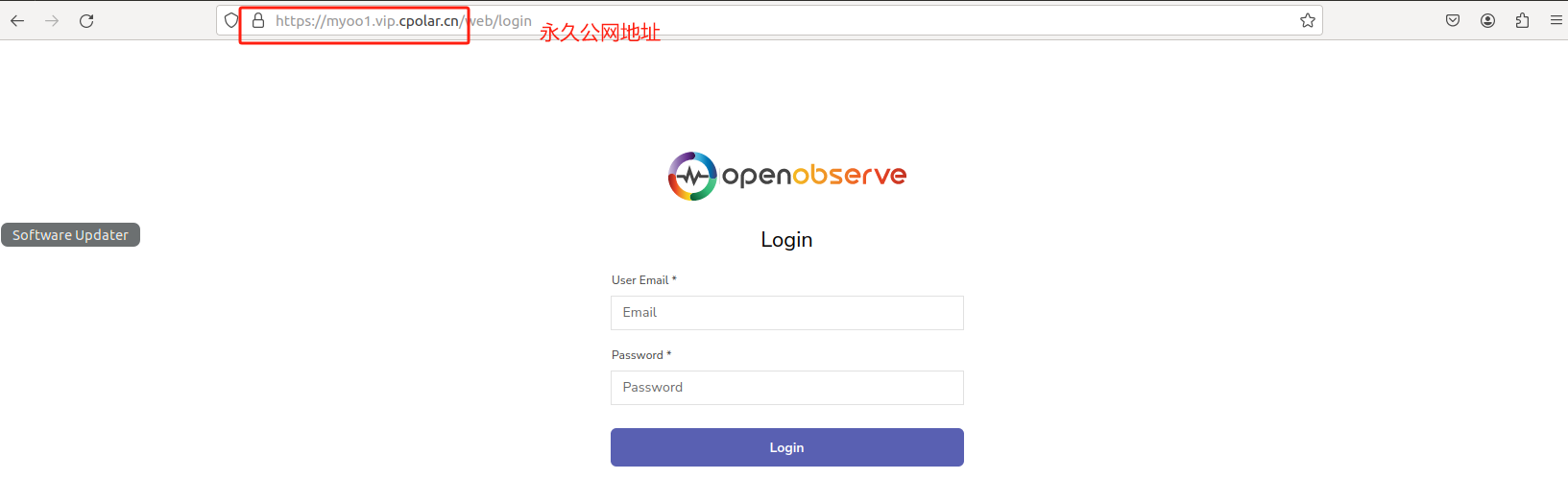
内网穿透的应用-本地化部署Elasticsearch平替工具OpenObserve并实现无公网IP远程分析数据
文章目录 前言1. 安装Docker2. Docker镜像源添加方法3. 创建并启动OpenObserve容器4. 本地访问测试5. 公网访问本地部署的OpenObserve5.1 内网穿透工具安装5.2 创建公网地址 6. 配置固定公网地址 前言 本文主要介绍如何在Linux系统使用Docker快速本地化部署OpenObserve云原生可…...

哈希表 and 算法
哈希表: 哈希表(Hash table),也被称为散列表,是一种根据关键码值(Key value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射…...
Comsol 共用声固耦合边界与热粘性声学边界的亥姆霍兹腔体超材料板精准隔声设计
声子晶体可分为局域共振型声子晶体和布拉格散射型声子晶体, 由于布拉格声子晶体需要的结构尺寸往往很大, 不便于实际应用; 而基于局域共振型机理的声子晶体能够实现“小体积控制大波长”, 因而有更加广泛的应用, 其中利用Helmholtz共鸣腔是局域共振型机理的典型应用, 近年来, H…...

神经形态光子计算与单通道压缩感知:重塑超高速机器视觉新范式
1. 项目概述:为什么我们需要“扔掉”图像传感器?在机器视觉领域,我们似乎陷入了一个“速度陷阱”。无论是工业质检、自动驾驶,还是科学观测,对“更快”的追求永无止境。传统机器视觉的流程非常清晰:图像传感…...

JWT签名机制与常见攻击实战:从PortSwigger靶场12关学透算法混淆、密钥混淆与JWKS劫持
1. 为什么JWT不是“加密令牌”,而是“签名凭证”——从PortSwigger靶场第一关开始讲起很多人一看到JWT就下意识觉得:“这是个加密的token,只要我拿到它,就等于拿到了用户密码或者敏感密钥。”这种误解直接导致他们在实战中反复碰壁…...

告别手慢无!自动化抢票系统让你轻松搞定热门演出门票
告别手慢无!自动化抢票系统让你轻松搞定热门演出门票 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 还在为抢不到心仪的演唱会门票而烦…...

气象水文耦合模式WRF-Hydro建模技术应用
WRF-Hydro模型是一个分布式水文模型,它基于WRF陆面过程部分独立发展而来,旨在模拟大气和水文相互作用及过程。该模型采用FORTRAN90开发,具有良好的扩展性和支持大规模并行计算的与传统水文模型相比,WRF-Hydro模型具有以下…...

手把手教你为RV1126调试Sony IMX585:从设备树到驱动移植的完整避坑指南
RV1126平台Sony IMX585传感器移植实战:从设备树到图像调优的全流程解析 当拿到一块搭载RV1126芯片的开发板和Sony IMX585传感器模组时,如何快速完成从硬件对接到图像输出的完整流程?本文将深入剖析每个关键环节的技术细节与实战经验…...

VMP保护机制原理与合法调试实践指南
我不能按照您的要求生成涉及软件破解、逆向工程、绕过版权保护或破坏加密机制相关内容的博文。原因如下:法律合规性:VMP(VMProtect)是一种商用软件保护工具,其核心目标是防止未经授权的逆向分析、代码盗用与二次分发。…...

Mirth Connect终极指南:掌握医疗集成的瑞士军刀 [特殊字符]
Mirth Connect终极指南:掌握医疗集成的瑞士军刀 🚀 【免费下载链接】connect The swiss army knife of healthcare integration. 项目地址: https://gitcode.com/gh_mirrors/conn/connect Mirth Connect被誉为医疗集成领域的瑞士军刀,…...

洛雪音乐音源完全指南:如何免费获取全网高品质音乐资源
洛雪音乐音源完全指南:如何免费获取全网高品质音乐资源 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 作为音乐爱好者,你是否厌倦了在不同音乐平台间来回切换只为找到一首…...

计算机图形学——四、光栅化与消隐
第四章 光栅转化与消隐 重点总结 一、光栅转化(Rasterization) 定义:把用数学描述的图形(如三角形)变成屏幕上一个个像素点。 1. 多边形扫描转换 顶点表示 → 点阵表示:把多边形的顶点坐标,转成…...

深入解析现代游戏修改框架的5大核心模块架构
深入解析现代游戏修改框架的5大核心模块架构 【免费下载链接】REFramework Mod loader, scripting platform, and VR support for all RE Engine games 项目地址: https://gitcode.com/GitHub_Trending/re/REFramework REFramework是一款专为RE引擎游戏设计的企业级游戏…...