Hibernate不是过时了么?SpringDataJpa又是什么?和Mybatis有什么区别?
一、前言
ps: 大三下学期,拿到了一份实习。进入公司后发现用到的技术栈有Spring Data Jpa\Hibernate,但对于持久层框架我只接触了Mybatis\Mybatis-Plus,所以就来学习一下Spring Data Jpa。
1.回顾MyBatis
来自官方文档的介绍:MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
2.Spring Data Jpa介绍
来自官方文档的介绍:Spring Data JPA是更大的Spring Data家族的一部分,可以轻松实现基于JPA的存储库。本模块处理对基于 JPA 的数据访问层的增强支持。它使构建使用数据访问技术的 Spring 驱动的应用程序变得更加容易。
详解:JPA诞生的缘由是为了整合第三方ORM框架,建立一种标准的方式,是JDK为了实现ORM的天下归一,目前也是在按照这个方向发展,但是还没能完全实现。在ORM框架中,Hibernate是一支很大的部队,使用很广泛,也很方便,能力也很强,同时Hibernate也是和JPA整合的比较良好,我们可以认为JPA是标准,事实上也是,JPA几乎都是接口,实现都是Hibernate在做,宏观上面看,在JPA的统一之下Hibernate很良好的运行。
上面阐述了JPA和Hibernate的关系,那么Spring-data-jpa又是个什么东西呢?Spring在与第三方整合这方面,Spring做了持久化这一块的工作,所以就有了Spring-Data这一系列包。包括,Spring-Data-Jpa,Spring-Data-Template,Spring-Data-Mongodb,Spring-Data-Redis,还有个民间产品,mybatis-spring,和前面类似,这是和mybatis整合的第三方包,这些都是干的持久化工具干的事儿。
这里介绍Spring-data-jpa,表示与jpa的整合。
在使用持久化工具的时候,一般都有一个对象来操作数据库,在原生的Hibernate中叫做Session,在JPA中叫做EntityManager,在MyBatis中叫做SqlSession,通过这个对象来操作数据库。我们一般按照三层结构来看的话,Service层做业务逻辑处理,Dao层和数据库打交道,在Dao中,就存在着上面的对象。那么ORM框架本身提供的功能有什么呢?答案是基本的CRUD,所有的基础CRUD框架都提供,我们使用起来感觉很方便,业务逻辑层面的处理ORM是没有提供的,如果使用原生的框架,业务逻辑代码我们一般会自定义,会自己去写SQL语句,然后执行。在这个时候,Spring-data-jpa的威力就体现出来了,ORM提供的能力他都提供,ORM框架没有提供的业务逻辑功能Spring-data-jpa也提供,全方位的解决用户的需求。使用Spring-data-jpa进行开发的过程中,常用的功能,我们几乎不需要写一条sql语句,当然spring-data-jpa也提供自己写sql的方式。(Mybatis-plus虽然也可以但是对于Spring-Data-Jpa全自动的ORM来看,对于简单的业务显得没有Spring-Data-Jpa那么方便)
3.Spring Data JPA与MyBatis对比
Spring Data JPA与MyBatis对比,也就是hibernate与MyBatis对比。
从基本概念和框架目标上看,两个框架差别还是很大的。hibernate是一个自动化更强、更高级的框架,毕竟在java代码层面上,省去了绝大部分sql编写,取而代之的是用面向对象的方式操作关系型数据库的数据。而MyBatis则是一个能够灵活编写sql语句,并将sql的入参和查询结果映射成POJO的一个持久层框架。所以,从表面上看,hibernate能方便、自动化更强,而MyBatis 在Sql语句编写方面则更灵活自由。
如果更上一个抽象层次去看,对于数据的操作,hibernate是面向对象的,而MyBatis是面向关系的。 当然,用hibernate也可以写出面向关系代码和系统,但却得不到面向关系的各种好处,最大的便是编写sql的灵活性,同时也失去面向对象意义和好处——一句话,不伦不类。那么,面向对象和关系型模型有什么不同,体现在哪里呢?实际上两者要面对的领域和要解决的问题是根本不同的:面向对象致力于解决计算机逻辑问题,而关系模型致力于解决数据的高效存取问题。
mybatis:小巧、方便?、高效、简单、直接、半自动
半自动的ORM框架,
小巧: mybatis就是jdbc封装
在国内更流行。
场景: 在业务比较复杂系统进行使用,
hibernate:强大、方便、高效、(简单)复杂、绕弯子、全自动
全自动的ORM框架,
强大:根据ORM映射生成不同SQL
在国外更流。
场景: 在业务相对简单的系统进行使用,随着微服务的流行。
介绍这么多,来看一下Spring-Data-Jpa的具体用法吧
二、Spring-Data-Jpa的使用
JPA仅仅是一种规范,也就是说JPA仅仅定义了一些接口,而接口是需要实现才能工作的。所以底层需要某种实现,而Hibernate就是实现了JPA接口的ORM框架。也就是说:JPA是一套ORM规范,Hibernate实现了JPA规范!
2.1Hibernate示例
pom.xml
<dependencies><!-- junit4 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13</version><scope>test</scope></dependency><!-- hibernate对jpa的支持包 --><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-entitymanager</artifactId><version>5.4.32.Final</version></dependency><!-- Mysql and MariaDB --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.26</version></dependency><!--openjpa--><dependency><groupId>org.apache.openjpa</groupId><artifactId>openjpa-all</artifactId><version>3.2.0</version></dependency></dependencies>
实体类:
@Data
@Entity // 作为hibernate 实体类
@Table(name = "tb_customer") // 映射的表明
public class Customer {/*** @Id:声明主键的配置* @GeneratedValue:配置主键的生成策略* strategy* GenerationType.IDENTITY :自增,mysql* * 底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增)* GenerationType.SEQUENCE : 序列,oracle* * 底层数据库必须支持序列* GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增* GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略* @Column:配置属性和字段的映射关系* name:数据库表中字段的名称*/@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "id")private Long custId; //客户的主键@Column(name = "cust_name")private String custName;//客户名称@Column(name="cust_address")private String custAddress;//客户地址
}
hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD 3.0//EN""http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration><session-factory><!-- 配置数据库连接信息 --><property name="connection.driver_class">com.mysql.cj.jdbc.Driver</property><property name="connection.url">jdbc:mysql://localhost:3306/springdata_jpa?characterEncoding=UTF-8</property><property name="connection.username">root</property><property name="connection.password">123456</property><!-- 会在日志中记录sql 默认false--><property name="show_sql">true</property><!--是否格式化sql 默认false--><property name="format_sql">true</property><!--表生成策略默认none 不自动生成update 如果没有表会创建,有会检查更新create 创建--><property name="hbm2ddl.auto">update</property><!-- 配置方言:选择数据库类型 --><property name="dialect">org.hibernate.dialect.MySQL57InnoDBDialect</property><!--指定哪些pojo 需要进行ORM映射--><mapping class="com.tuling.pojo.Customer"></mapping></session-factory>
</hibernate-configuration>
测试
public class HibernateTest {// Session工厂 Session:数据库会话 代码和数据库的一个桥梁private SessionFactory sf;@Beforepublic void init() {StandardServiceRegistry registry = new StandardServiceRegistryBuilder().configure("/hibernate.cfg.xml").build();//2. 根据服务注册类创建一个元数据资源集,同时构建元数据并生成应用一般唯一的的session工厂sf = new MetadataSources(registry).buildMetadata().buildSessionFactory();}@Test //保存一个对象public void testC(){// session进行持久化操作try(Session session = sf.openSession()){Transaction tx = session.beginTransaction();Customer customer = new Customer();customer.setCustName("徐庶");session.save(customer);tx.commit();}}@Test //查找public void testR(){// session进行持久化操作try(Session session = sf.openSession()){Transaction tx = session.beginTransaction();Customer customer = session.find(Customer.class, 1L);System.out.println("=====================");System.out.println(customer);tx.commit();}}@Test //利用缓存查找对象public void testR_lazy(){// session进行持久化操作try(Session session = sf.openSession()){Transaction tx = session.beginTransaction();Customer customer = session.load(Customer.class, 1L);System.out.println("=====================");System.out.println(customer);tx.commit();}}@Test //更新public void testU(){// session进行持久化操作try(Session session = sf.openSession()){Transaction tx = session.beginTransaction();Customer customer = new Customer();//customer.setCustId(1L);customer.setCustName("徐庶");// 插入session.save()// 更新session.update();session.saveOrUpdate(customer);tx.commit();}}@Test //删除public void testD(){// session进行持久化操作try(Session session = sf.openSession()){Transaction tx = session.beginTransaction();Customer customer = new Customer();customer.setCustId(2L);session.remove(customer);tx.commit();}}@Test //自定义sqlpublic void testR_HQL(){// session进行持久化操作try(Session session = sf.openSession()){Transaction tx = session.beginTransaction();String hql=" FROM Customer where custId=:id";List<Customer> resultList = session.createQuery(hql, Customer.class).setParameter("id",1L).getResultList();System.out.println(resultList);tx.commit();}}
}
2.2Jpa示例
添加META-INF\persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0"><!--需要配置persistence-unit节点持久化单元:name:持久化单元名称transaction-type:事务管理的方式JTA:分布式事务管理RESOURCE_LOCAL:本地事务管理--><persistence-unit name="hibernateJPA" transaction-type="RESOURCE_LOCAL"><!--jpa的实现方式 --><provider>org.hibernate.jpa.HibernatePersistenceProvider</provider><!--需要进行ORM的POJO类--><class>com.tuling.pojo.Customer</class><!--可选配置:配置jpa实现方的配置信息--><properties><!-- 数据库信息用户名,javax.persistence.jdbc.user密码, javax.persistence.jdbc.password驱动, javax.persistence.jdbc.driver数据库地址 javax.persistence.jdbc.url--><property name="javax.persistence.jdbc.user" value="root"/><property name="javax.persistence.jdbc.password" value="123456"/><property name="javax.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/><property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/springdata_jpa?characterEncoding=UTF-8"/><!--配置jpa实现方(hibernate)的配置信息显示sql : false|true自动创建数据库表 : hibernate.hbm2ddl.autocreate : 程序运行时创建数据库表(如果有表,先删除表再创建)update :程序运行时创建表(如果有表,不会创建表)none :不会创建表--><property name="hibernate.show_sql" value="true" /><property name="hibernate.hbm2ddl.auto" value="update" /><property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" /></properties></persistence-unit><persistence-unit name="openJpa" transaction-type="RESOURCE_LOCAL"><!--jpa的实现方式 --><provider>org.apache.openjpa.persistence.PersistenceProviderImpl</provider><!-- 指定哪些实体需要持久化 --><class>com.tuling.pojo.Customer</class><!--可选配置:配置jpa实现方的配置信息--><properties><!-- 数据库信息用户名,javax.persistence.jdbc.user密码, javax.persistence.jdbc.password驱动, javax.persistence.jdbc.driver数据库地址 javax.persistence.jdbc.url--><property name="javax.persistence.jdbc.user" value="root"/><property name="javax.persistence.jdbc.password" value="123456"/><property name="javax.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/><property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/springdata_jpa?characterEncoding=UTF-8"/><!--配置jpa实现方(openjpa)的配置信息--><!-- 可以自动生成数据库表 --><property name="openjpa.jdbc.SynchronizeMappings" value="buildSchema(ForeignKeys=true)"/></properties></persistence-unit>
</persistence>
测试
提示:Hibernate中叫做Session,在JPA中叫做EntityManager
jpa的对象4种状态
- 临时状态:刚创建出来,∙没有与entityManager发生关系,没有被持久化,不处于entityManager中的对象
- 持久状态:∙与entityManager发生关系,已经被持久化,您可以把持久化状态当做实实在在的数据库记录。
- 删除状态:执行remove方法,事物提交之前
- 游离状态:游离状态就是提交到数据库后,事务commit后实体的状态,因事务已经提交了,此时实体的属
性任你如何改变,也不会同步到数据库,因为游离是没人管的孩子,不在持久化上下文中。
public void persist(Object entity)persist方法可以将实例转换为managed(托管)状态。在调用flush()方法或提交事物后,实
例将会被插入到数据库中。对不同状态下的实例A,persist会产生以下操作:
1. 如果A是一个new状态的实体,它将会转为managed状态;
2. 如果A是一个managed状态的实体,它的状态不会发生任何改变。但是系统仍会在数据库执行INSERT操作;
3. 如果A是一个removed(删除)状态的实体,它将会转换为受控状态;
4. 如果A是一个detached(分离)状态的实体,该方法会抛出IllegalArgumentException异常,具体异常根据不同的
JPA实现有关。
public class JpaTest {EntityManagerFactory factory;@Beforepublic void before(){factory= Persistence.createEntityManagerFactory("hibernateJPA");}@Testpublic void testC(){EntityManager em = factory.createEntityManager();EntityTransaction tx = em.getTransaction();tx.begin();Customer customer = new Customer();customer.setCustName("张三");em.persist(customer); // 保存并使得实体保持Managed状态tx.commit();}// 立即查询@Testpublic void testR(){EntityManager em = factory.createEntityManager();EntityTransaction tx = em.getTransaction();tx.begin();Customer customer = em.find(Customer.class, 1L);System.out.println("========================");System.out.println(customer);tx.commit();}// 延迟查询@Testpublic void testR_lazy(){EntityManager em = factory.createEntityManager();EntityTransaction tx = em.getTransaction();tx.begin();Customer customer = em.getReference(Customer.class, 1L);System.out.println("========================");System.out.println(customer);tx.commit();}@Testpublic void testU(){EntityManager em = factory.createEntityManager();EntityTransaction tx = em.getTransaction();tx.begin();Customer customer = new Customer();customer.setCustId(5L);customer.setCustName("王五");/**// 如果指定了主键:更新: 1.先查询 看是否有变化如果有变化 更新 如果没有变化就不更新* 如果没有指定了主键:* 插入* */em.merge(customer);tx.commit();}@Test//自定义sqlpublic void testU_JPQL(){EntityManager em = factory.createEntityManager();EntityTransaction tx = em.getTransaction();tx.begin();String jpql="UPDATE Customer set custName=:name where custId=:id";em.createQuery(jpql).setParameter("name","李四").setParameter("id",5L).executeUpdate();tx.commit();}@Testpublic void testU_SQL(){EntityManager em = factory.createEntityManager();EntityTransaction tx = em.getTransaction();tx.begin();String sql="UPDATE tb_customer set cust_name=:name where id=:id";em.createNativeQuery(sql).setParameter("name","王五").setParameter("id",5L).executeUpdate();tx.commit();}@Testpublic void testD(){EntityManager em = factory.createEntityManager();EntityTransaction tx = em.getTransaction();tx.begin();Customer customer = em.find(Customer.class,5L);em.remove(customer);tx.commit();}
}3.1Spring Data JPA实例
我们来实现一个基于Spring Data JPA的示例感受一下和之前单独使用的区别:
依赖:
父pom:
<!--统一管理SpringData子项目的版本--><dependencyManagement><dependencies><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-bom</artifactId><version>2021.1.0</version><scope>import</scope><type>pom</type></dependency></dependencies></dependencyManagement>
子pom:
<dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-jpa</artifactId></dependency><!-- junit4 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13</version><scope>test</scope></dependency><!-- hibernate对jpa的支持包 --><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-entitymanager</artifactId><version>5.4.32.Final</version></dependency><!-- Mysql and MariaDB --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.26</version></dependency><!--连接池--><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version></dependency><!--spring-test --><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId><version>5.3.10</version><scope>test</scope></dependency><!-- querydsl --><dependency><groupId>com.querydsl</groupId><artifactId>querydsl-jpa</artifactId><version>${querydsl.version}</version></dependency>
SpringDataJPAConfig
@Configuration // 标记当前类为配置类 =xml配文件
@EnableJpaRepositories(basePackages="com.tuling.repositories") // 启动jpa <jpa:repositories
@EnableTransactionManagement // 开启事务
public class SpringDataJPAConfig {/** <!--数据源--><bean class="com.alibaba.druid.pool.DruidDataSource" name="dataSource"><property name="username" value="root"/><property name="password" value="123456"/><property name="driverClassName" value="com.mysql.cj.jdbc.Driver"/><property name="url" value="jdbc:mysql://localhost:3306/springdata_jpa?characterEncoding=UTF-8"/></bean>* */@Beanpublic DataSource dataSource() {DruidDataSource dataSource = new DruidDataSource();dataSource.setUsername("root");dataSource.setPassword("123456");dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");dataSource.setUrl("jdbc:mysql://localhost:3306/springdata_jpa?characterEncoding=UTF-8");return dataSource;}/** <!--EntityManagerFactory--><bean name="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"><property name="jpaVendorAdapter"><!--Hibernate实现--><bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"><!--生成数据库表--><property name="generateDdl" value="true"></property><property name="showSql" value="true"></property></bean></property><!--设置实体类的包--><property name="packagesToScan" value="com.tuling.pojo"></property><property name="dataSource" ref="dataSource" ></property></bean>* */@Beanpublic LocalContainerEntityManagerFactoryBean entityManagerFactory() {HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();vendorAdapter.setGenerateDdl(true);vendorAdapter.setShowSql(true);LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();factory.setJpaVendorAdapter(vendorAdapter);factory.setPackagesToScan("com.tuling.pojo");factory.setDataSource(dataSource());return factory;}/** <bean class="org.springframework.orm.jpa.JpaTransactionManager" name="transactionManager"><property name="entityManagerFactory" ref="entityManagerFactory"></property></bean>* */@Beanpublic PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {JpaTransactionManager txManager = new JpaTransactionManager();txManager.setEntityManagerFactory(entityManagerFactory);return txManager;}
}
XML
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:jpa="http://www.springframework.org/schema/data/jpa" xmlns:tx="http://www.springframework.org/schema/tx"xsi:schemaLocation="http://www.springframework.org/schema/beanshttps://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/data/jpahttps://www.springframework.org/schema/data/jpa/spring-jpa.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd"><!--用于整合jpa @EnableJpaRepositories --><jpa:repositories base-package="com.tuling.repositories"entity-manager-factory-ref="entityManagerFactory"transaction-manager-ref="transactionManager"/><!--EntityManagerFactory--><bean name="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"><property name="jpaVendorAdapter"><!--Hibernate实现--><bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"><!--生成数据库表--><property name="generateDdl" value="true"></property><property name="showSql" value="true"></property></bean></property><!--设置实体类的包--><property name="packagesToScan" value="com.tuling.pojo"></property><property name="dataSource" ref="dataSource" ></property></bean><!--数据源--><bean class="com.alibaba.druid.pool.DruidDataSource" name="dataSource"><property name="username" value="root"/><property name="password" value="123456"/><property name="driverClassName" value="com.mysql.cj.jdbc.Driver"/><property name="url" value="jdbc:mysql://localhost:3306/springdata_jpa?characterEncoding=UTF-8"/></bean><!--声明式事务--><bean class="org.springframework.orm.jpa.JpaTransactionManager" name="transactionManager"><property name="entityManagerFactory" ref="entityManagerFactory"></property></bean><!--启动注解方式的声明式事务--><tx:annotation-driven transaction-manager="transactionManager"></tx:annotation-driven></beans>
pojo
@Data
@Entity // 作为hibernate 实体类
@Table(name = "tb_customer") // 映射的表明
public class Customer {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "id")private Long custId; //客户的主键@Column(name = "cust_name")private String custName;//客户名称@Column(name="cust_address")private String custAddress;//客户地址
}
CustomerRepository
使用 Spring Data Repositories抽象的目标是显着减少为各种持久性存储实现数据访问层所需的样板代码量。
CrudRepository
1
2 // 用来插入和修改 有主键就是修改 没有就是新增
3 // 获得插入后自增id, 获得返回值
4 <S extends T> S save(S entity);
5
6 // 通过集合保存多个实体
7 <S extends T> Iterable<S> saveAll(Iterable<S> entities);
8 // 通过主键查询实体
9 Optional<T> findById(ID id);
10 // 通过主键查询是否存在 返回boolean
11 boolean existsById(ID id);
12 // 查询所有
13 Iterable<T> findAll();
14 // 通过集合的主键 查询多个实体,, 返回集合
15 Iterable<T> findAllById(Iterable<ID> ids);
16 // 查询总数量
17 long count();
18 // 根据id进行删除
19 void deleteById(ID id);
20 // 根据实体进行删除
21 void delete(T entity);
22 // 删除多个
23 void deleteAllById(Iterable<? extends ID> ids);
24 // 删除多个传入集合实体
25 void deleteAll(Iterable<? extends T> entities);
26 // 删除所有
27 void deleteAll();
public interface CustomerRepository extends PagingAndSortingRepository<Customer, Long> {
}
测试
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class SpringdataJpaTest {@AutowiredCustomerRepository repository;@Testpublic void testR(){Optional<Customer> byId = repository.findById(1L);System.out.println(byId.orElse(null));}@Testpublic void testC(){Customer customer = new Customer();customer.setCustName("李四");System.out.println(repository.save(customer));}@Testpublic void testD(){Customer customer = new Customer();customer.setCustId(3L);customer.setCustName("李四");repository.delete(customer);}@Testpublic void testFindAll(){Iterable<Customer> allById = repository.findAllById(Arrays.asList(1L, 7L, 8L));System.out.println(allById);}}3.1.1分页
在 之上CrudRepository,有一个PagingAndSortingRepository抽象,它添加了额外的方法来简化对实体的分页访问:
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class SpringDataJpaPagingAndSortTest
{// jdk动态代理的实例@Autowired(required=false)CustomerRepository repository;@Testpublic void insertCustomer() {for (int i = 20; i < 50; i++) {Customer customer = new Customer();customer.setCustName("张三"+i);customer.setCustAddress("北京");repository.save(customer);}}@Testpublic void testPaging(){Page<Customer> all = repository.findAll(PageRequest.of(0, 2));System.out.println(all.getTotalPages());System.out.println(all.getTotalElements());System.out.println(all.getContent());}@Testpublic void testSort(){Sort sort = Sort.by("custId").descending();Iterable<Customer> all = repository.findAll(sort);System.out.println(all);}@Testpublic void testSortTypeSafe(){Sort.TypedSort<Customer> sortType = Sort.sort(Customer.class);Sort sort = sortType.by(Customer::getCustId).descending();Iterable<Customer> all = repository.findAll(sort);System.out.println(all);}
}3.1.2自定义操作
1.jpql(原生SQL): @Query
-
查询如果返回单个实体 就用pojo接收 , 如果是多个需要通过集合
-
参数设置方式
- 索引 : ?数字
- 具名: :参数名 结合@Param注解指定参数名字
-
增删改:
- 要加上事务的支持:
- 如果是插入方法:一定只能在hibernate下才支持 (Insert into
…select )
@Transactional // 通常会放在业务逻辑层上面去声明
@Modifying // 通知springdatajpa 是增删改的操作
2.规定方法名
支持的查询方法主题关键字(前缀)
- 决定当前方法作用
- 只支持查询和删除
详见官方文档
3.Query by Example
只支持查询
- 不支持嵌套或分组的属性约束,如 firstname = ?0 or (firstname = ?1
and lastname = ?2). - 只支持字符串 start/contains/ends/regex 匹配和其他属性类型的精确匹
配。
实现:
1.将Repository继承QueryByExampleExecutor
public interface CustomerQBERepositoryextends PagingAndSortingRepository<Customer, Long>, QueryByExampleExecutor<Customer> {}
2.测试代码
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class QBETest {// jdk动态代理的实例@AutowiredCustomerQBERepository repository;/*** 简单实例 客户名称 客户地址动态查询*/@Testpublic void test01(){// 查询条件Customer customer=new Customer();customer.setCustName("徐庶");customer.setCustAddress("BEIJING");// 通过Example构建查询条件Example<Customer> example = Example.of(customer);List<Customer> list = (List<Customer>) repository.findAll(example);System.out.println(list);}/*** 通过匹配器 进行条件的限制* 简单实例 客户名称 客户地址动态查询*/@Testpublic void test02(){// 查询条件Customer customer=new Customer();customer.setCustName("庶");customer.setCustAddress("JING");// 通过匹配器 对条件行为进行设置ExampleMatcher matcher = ExampleMatcher.matching()//.withIgnorePaths("custName") // 设置忽略的属性//.withIgnoreCase("custAddress") // 设置忽略大小写//.withStringMatcher(ExampleMatcher.StringMatcher.ENDING); // 对所有条件字符串进行了结尾匹配.withMatcher("custAddress",m -> m.endsWith().ignoreCase()); // 针对单个条件进行限制, 会使withIgnoreCase失效,需要单独设置//.withMatcher("custAddress", ExampleMatcher.GenericPropertyMatchers.endsWith().ignoreCase());// 通过Example构建查询条件Example<Customer> example = Example.of(customer,matcher);List<Customer> list = (List<Customer>) repository.findAll(example);System.out.println(list);}
}4.Specifications
在之前使用Query by Example只能针对字符串进行条件设置,那如果希望对所有类型支持,可以使用Specifications
实现:
public interface CustomerRepository extends CrudRepository<Customer, Long>, JpaSpecificationExecutor<Customer> {}
2.传入Specification的实现: 结合lambda表达式
repository.findAll((Specification<Customer>)(root, query, criteriaBuilder) ‐>{// Todo...return null;});
}
Root:查询哪个表(关联查询) = from
CriteriaQuery:查询哪些字段,排序是什么 =组合(order by . where )
CriteriaBuilder:条件之间是什么关系,如何生成一个查询条件,每一个查询条件都是什么类型(>
between in…) = where
Predicate(Expression): 每一条查询条件的详细描述
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class SpecificationTest {// jdk动态代理的实例@AutowiredCustomerSpecificationsRepository repository;@Testpublic void testR(){List<Customer> customer = repository.findAll(new Specification<Customer>() {@Overridepublic Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {// root from Customer , 获取列// CriteriaBuilder where 设置各种条件 (> < in ..)// query 组合(order by , where)return null;}});System.out.println(customer);}@Testpublic void testR5(){Customer params=new Customer();//params.setCustAddress("BEIJING");params.setCustId(0L);params.setCustName("徐庶,王五");List<Customer> customer = repository.findAll(new Specification<Customer>() {@Overridepublic Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {// root from Customer , 获取列// CriteriaBuilder where 设置各种条件 (> < in ..)// query 组合(order by , where)Path<Long> custId = root.get("custId");Path<String> custName = root.get("custName");Path<String> custAddress = root.get("custAddress");// 参数1 :为哪个字段设置条件 参数2:值List<Predicate> list=new ArrayList<>();if(!StringUtils.isEmpty(params.getCustAddress())) {list.add(cb.equal(custAddress, "BEIJING")) ;}if(params.getCustId()>-1){list.add(cb.greaterThan(custId, 0L));}if(!StringUtils.isEmpty(params.getCustName())) {CriteriaBuilder.In<String> in = cb.in(custName);in.value("徐庶").value("王五");list.add(in);}Predicate and = cb.and(list.toArray(new Predicate[list.size()]));Order desc = cb.desc(custId);return query.where(and).orderBy(desc).getRestriction();}});System.out.println(customer);}
}5.Querydsl
官网网址
QueryDSL是基于ORM框架或SQL平台上的一个通用查询框架。借助QueryDSL可以在任何支持的ORM框架或SQL平台上以通用API方式构建查询。
JPA是QueryDSL的主要集成技术,是JPQL和Criteria查询的代替方法。目前QueryDSL支持的平台包括JPA,JDO,SQL,Mongodb 等等
Querydsl扩展能让我们以链式方式代码编写查询方法。该扩展需要一个接口QueryDslPredicateExecutor,它定义了很多查询方法。
接口继承了该接口,就可以使用该接口提供的各种方法了
public interface QuerydslPredicateExecutor<T> {Optional<T> findOne(Predicate predicate);Iterable<T> findAll(Predicate predicate);Iterable<T> findAll(Predicate predicate, Sort sort);Iterable<T> findAll(Predicate predicate, OrderSpecifier<?>... orders);Iterable<T> findAll(OrderSpecifier<?>... orders);Page<T> findAll(Predicate predicate, Pageable pageable);long count(Predicate predicate);boolean exists(Predicate predicate);<S extends T, R> R findBy(Predicate predicate, Function<FetchableFluentQuery<S>, R> queryFunction);
}
引入依赖
<!-- querydsl --><dependency><groupId>com.querydsl</groupId><artifactId>querydsl-jpa</artifactId><version>${querydsl.version}</version></dependency>
添加插件
这个插件是为了让程序自动生成query type(查询实体,命名方式为:“Q”+对应实体名)。
<build><plugins><plugin><groupId>com.mysema.maven</groupId><artifactId>apt-maven-plugin</artifactId><version>${apt.version}</version><dependencies><dependency><groupId>com.querydsl</groupId><artifactId>querydsl-apt</artifactId><version>${querydsl.version}</version></dependency></dependencies><executions><execution><phase>generate-sources</phase><goals><goal>process</goal></goals><configuration><outputDirectory>target/generated-sources/queries</outputDirectory><processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor><logOnlyOnError>true</logOnlyOnError></configuration></execution></executions></plugin></plugins></build>
测试
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class QueryDSLTest {@AutowiredCustomerQueryDSLRepository repository;@Testpublic void test01() {QCustomer customer = QCustomer.customer;// 通过Id查找BooleanExpression eq = customer.custId.eq(1L);System.out.println(repository.findOne(eq));}/*** 查询客户名称范围 (in)* id >大于* 地址 精确*/@Testpublic void test02() {QCustomer customer = QCustomer.customer;// 通过Id查找BooleanExpression and = customer.custName.in("徐庶", "王五").and(customer.custId.gt(0L)).and(customer.custAddress.eq("BEIJING"));System.out.println(repository.findOne(and));}/*** 查询客户名称范围 (in)* id >大于* 地址 精确*/@Testpublic void test03() {Customer params=new Customer();params.setCustAddress("BEIJING");params.setCustId(0L);params.setCustName("徐庶,王五");QCustomer customer = QCustomer.customer;// 初始条件 类似于1=1 永远都成立的条件BooleanExpression expression = customer.isNotNull().or(customer.isNull());expression=params.getCustId()>-1?expression.and(customer.custId.gt(params.getCustId())):expression;expression=!StringUtils.isEmpty( params.getCustName())?expression.and(customer.custName.in(params.getCustName().split(","))):expression;expression=!StringUtils.isEmpty( params.getCustAddress())?expression.and(customer.custAddress.eq(params.getCustAddress())):expression;System.out.println(repository.findAll(expression));}// 解决线程安全问题@PersistenceContextEntityManager em;/*** 自定义列查询、分组* 需要使用原生态的方式(Specification)* 通过Repository进行查询, 列、表都是固定*/@Testpublic void test04() {JPAQueryFactory factory = new JPAQueryFactory(em);QCustomer customer = QCustomer.customer;// 构建基于QueryDSL的查询JPAQuery<Tuple> tupleJPAQuery = factory.select(customer.custId, customer.custName).from(customer).where(customer.custId.eq(1L)).orderBy(customer.custId.desc());// 执行查询List<Tuple> fetch = tupleJPAQuery.fetch();// 处理返回数据for (Tuple tuple : fetch) {System.out.println(tuple.get(customer.custId));System.out.println(tuple.get(customer.custName));}}@Testpublic void test05() {JPAQueryFactory factory = new JPAQueryFactory(em);QCustomer customer = QCustomer.customer;// 构建基于QueryDSL的查询JPAQuery<Long> longJPAQuery = factory.select(customer.custId.sum()).from(customer)//.where(customer.custId.eq(1L)).orderBy(customer.custId.desc());// 执行查询List<Long> fetch = longJPAQuery.fetch();// 处理返回数据for (Long sum : fetch) {System.out.println(sum);}}
}
3.1.3多表关联操作
一对一
1、配置管理关系
@OneToOne
@JoinColumn(name=“外键字段名”)
@OneToOne
@JoinColumn(name="customer_id")
private Customer customer;
@Entity // 作为hibernate 实体类
@Table(name = "tb_customer") // 映射的表明
@Data
@EntityListeners(AuditingEntityListener.class)
public class Customer {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "id")private Long custId; //客户的主键@Column(name = "cust_name")private String custName;//客户名称@Column(name="cust_address")private String custAddress;//客户地址// 单向关联 一对一/** cascade 设置关联操作* ALL, 所有持久化操作PERSIST 只有插入才会执行关联操作MERGE, 只有修改才会执行关联操作REMOVE, 只有删除才会执行关联操作fetch 设置是否懒加载EAGER 立即加载(默认)LAZY 懒加载( 直到用到对象才会进行查询,因为不是所有的关联对象 都需要用到)orphanRemoval 关联移除(通常在修改的时候会用到)一旦把关联的数据设置null ,或者修改为其他的关联数据, 如果想删除关联数据, 就可以设置trueoptional 限制关联的对象不能为nulltrue 可以为null(默认 ) false 不能为nullmappedBy 将外键约束执行另一方维护(通常在双向关联关系中,会放弃一方的外键约束)值= 另一方关联属性名**/@OneToOne(mappedBy = "customer",cascade = CascadeType.ALL,fetch = FetchType.LAZY,orphanRemoval=true/*,optional=false*/)// 设置外键的字段名@JoinColumn(name="account_id")private Account account;
}
测试
@ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class OneToOneTest {@AutowiredCustomerRepository repository;// 插入@Testpublic void testC(){// 初始化数据Account account = new Account();account.setUsername("xushu");Customer customer = new Customer();customer.setCustName("徐庶");customer.setAccount(account);account.setCustomer(customer);repository.save(customer);}// 插入@Test// 为什么懒加载要配置事务 :// 当通过repository调用完查询方法,session就会立即关闭, 一旦session你就不能查询,// 加了事务后, 就能让session直到事务方法执行完毕后才会关闭@Transactional(readOnly = true)public void testR(){Optional<Customer> customer = repository.findById(3L); // 只查询出客户, session关闭System.out.println("=================");System.out.println(customer.get()); // toString}@Testpublic void testD(){repository.deleteById(1L);}@Testpublic void testU(){Customer customer = new Customer();customer.setCustId(16L);customer.setCustName("徐庶");customer.setAccount(null);repository.save(customer);}
}差异
这两个设置之间的区别在于对 断开关系.例如,当设置 地址字段设置为null或另一个Address对象.如果指定了 orphanRemoval = true ,则会自动删除断开连接的Address实例.这对于清理很有用 没有一个不应该存在的相关对象(例如地址) 来自所有者对象(例如员工)的引用.
如果仅指定 cascade = CascadeType.REMOVE ,则不会执行任何自动操作,因为断开关系不是删除操作
一对多
1.、配置管理关系
@OneToMany
@JoinColumn(name=“customer_id”)
// 一对多
// fetch 默认是懒加载 懒加载的优点( 提高查询性能)
@OneToMany(cascade = CascadeType.ALL,fetch = FetchType.LAZY)
@JoinColumn(name="customer_id")
private List<Message> messages;
2、配置关联操作
/**** 一(客户)对多(信息)*/
@Entity
@Table(name="tb_message")
@Data
public class Message {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String info;// 多对一@ManyToOne(cascade = {CascadeType.PERSIST,CascadeType.REMOVE})@JoinColumn(name="customer_id")private Customer customer;// 一定要有、否则查询就会有问题public Message() {}public Message(String info) {this.info = info;}public Message(String info, Customer customer) {this.info = info;this.customer = customer;}@Overridepublic String toString() {return "Message{" +"id=" + id +", info='" + info + '\'' +", customerId=" + customer.getCustId() +", customerName=" + customer.getCustName() +'}';}
}多对一与一对多相似,就不做演示
多对多
1、配置管理关系
@ManyToMany
@JoinColumn(name=“customer_id”)
// 单向多对多
@ManyToMany(cascade = CascadeType.ALL)
/*中间表需要通过@JoinTable来维护外键:(不设置也会自动生成)
* name 指定中间表的名称
* joinColumns 设置本表的外键名称
* inverseJoinColumns 设置关联表的外键名称
* */
@JoinTable(name="tb_customer_role",joinColumns = {@JoinColumn(name="c_id")},inverseJoinColumns = {@JoinColumn(name="r_id")}
)
private List<Role> roles;
2、配置关联操作
/*** 多(用户)对多(角色)*/
@Entity
@Table(name="tb_role")
@Data
public class Role {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@Column(name="role_name")private String rName;public Role(String rName) {this.rName = rName;}public Role(Long id, String rName) {this.id = id;this.rName = rName;}public Role() {}@ManyToMany(cascade = CascadeType.ALL)private List<Role> roles;
}测试
ContextConfiguration(classes = SpringDataJPAConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class ManyToManyTest {@AutowiredCustomerRepository repository;@AutowiredRoleRepository roleRepository;@Testpublic void testSave(){List<Role> roles = new ArrayList<>();roles.add(new Role("管理员"));roles.add(new Role("普通用户"));Customer customer = new Customer();customer.setCustName("诸葛");customer.setRoles(roles);repository.save(customer);}// 保存/*1.如果保存的关联数据 希望使用已有的 ,就需要从数据库中查出来(持久状态)。否则 提示 游离状态不能持久化2.如果一个业务方法有多个持久化操作, 记得加上@Transactional ,否则不能共用一个session3. 在单元测试中用到了@Transactional , 如果有增删改的操作一定要加@Commit4. 单元测试会认为你的事务方法@Transactional, 只是测试而已, 它不会为你提交事务, 需要单独加上 @Commit*/@Test@Transactional@Commitpublic void testC() {List<Role> roles=new ArrayList<>();roles.add(roleRepository.findById(1L).get());roles.add(roleRepository.findById(2L).get());Customer customer = new Customer();customer.setCustName("诸葛");customer.setRoles(roles);repository.save(customer);}@Test@Transactional(readOnly = true)public void testR() {System.out.println(repository.findById(14L));//repository.save(customer);}/** 注意加上* @Transactional@Commit多对多其实不适合删除, 因为经常出现数据出现可能除了和当前这端关联还会关联另一端,此时删除就会: ConstraintViolationException。* 要删除, 要保证没有额外其他另一端数据关联* */@Test@Transactional@Commitpublic void testD() {Optional<Customer> customer = repository.findById(14L);repository.delete(customer.get());}
}乐观锁
hibernate
防并发修改
private @Version Long version;
三、SpringBoot整合Spring-Data-Jpa
依赖
<dependencies><!--data-jpa的场景启动器--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
常用配置
# 数据库表的生成策略
spring.jpa.hibernate.ddl-auto=update
spring.datasource.url=jdbc:mysql://localhost:3306/springdata_jpa?serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# 是否显示sql在控制台
spring.jpa.show-sql= true
spring.jpa.properties.hibernate.format_sql=true
server.port=8088
可选配置
Hibernate官方文档
SpirngDataJpa官方文档
剩下就是正常开发流程,持久层、业务层、控制层
四、总结
Hibernate随着微服务的流行,随着服务的拆分,使得业务变得简单起来,此时HIbernate这个全自动ORM框架,深受各个企业的青睐。JPA则是为了整合第三方ORM框架,建立一种标准的方式。Mybatis则是半自动的ORM框架,在一些业务比较复杂系统进行使用。所以对于一个大型项目公司往往会采用SpringDataJpa\Hibernate\Mybatis等几者结合来解决不同的业务场景。
相关文章:

Hibernate不是过时了么?SpringDataJpa又是什么?和Mybatis有什么区别?
一、前言 ps: 大三下学期,拿到了一份实习。进入公司后发现用到的技术栈有Spring Data Jpa\Hibernate,但对于持久层框架我只接触了Mybatis\Mybatis-Plus,所以就来学习一下Spring Data Jpa。 1.回顾MyBatis 来自官方文档的介绍:MyBatis 是一款…...
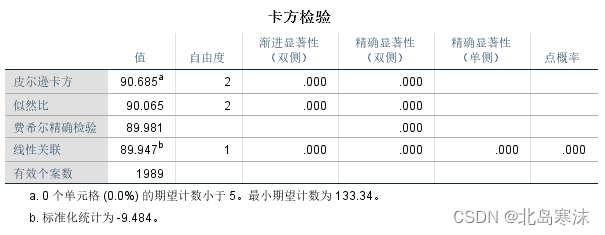
数学建模拓展内容:卡方检验和Fisher精确性检验(附有SPSS使用步骤)
卡方检验和Fisher精确性检验卡方拟合度检验卡方独立性检验卡方检验的前提假设Fisher精确性检验卡方拟合度检验 卡方拟合度检验概要:卡方拟合度检验也被称为单因素卡方检验,用于检验一个分类变量的预期频率和观察到的频率之间是否存在显著差异。 卡方拟…...

【Python学习笔记之七大数据类型】
Python数据类型:Number数字、Boolean布尔值、String字符串、list列表、tuple元组、set集合、dictionary字典 int整数 a1 print(a,type(a))float浮点数 b1.1 print(b,type(b))complex复数 c100.5j print(c,type(c))bool布尔值:True、False,true和false并非Python…...

Android系统之onFirstRef自动调用原理
前言:抽丝剥茧探究onFirstRef究竟为何在初始化sp<xxx>第一个调用?1.onFirstRef调用位置<1>.system/core/libutils/RefBase.cpp#include <utils/RefBase.h>//1.初始化强指针 void RefBase::incStrong(const void* id) const {weakref_i…...
ipv6上网配置
一般现在的宽带都已经支持ipv6了,但是需要一些配置才能真正用上ipv6。记录一下配置过程。 当前测试环境为移动宽带,光猫下面接了一个路由器,家里所有的设备都挂到这个路由器下面的。 1. 光猫改桥接 光猫在使用路由模式下,ipv6无…...

python实现聚类技术—复杂网络社团检测 附完整代码
实验内容 某跆拳道俱乐部数据由 34 个节点组成,由于管理上的分歧,俱乐部要分解成两个社团。 该实验的任务即:要求我们在给定的复杂网络上检测出两个社团。 分析与设计 实验思路分析如下: 聚类算法通常可以描述为用相似度来衡量两个数据的远近,搜索可能的划分方案,使得目标…...
如何判断两架飞机在汇聚飞行?(如何计算两架飞机的航向夹角?)内含程序源码
ok,在开始一切之前,让我先猜一猜,你是不是想百度“二维平面下如何计算两个移动物体的航向夹角?”如果是,那就请继续往下看。 首先,我们要明确一个概念:航向角≠航向夹角!࿰…...

Scipy稀疏矩阵bsr_array
文章目录基本原理初始化内置方法基本原理 bsr,即Block Sparse Row,bsr_array即块稀疏行矩阵,顾名思义就是将稀疏矩阵分割成一个个非0的子块,然后对这些子块进行存储。通过输入维度,可以创建一个空的bsr数组࿰…...

LeetCode笔记:Weekly Contest 332
LeetCode笔记:Weekly Contest 332 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/weekly-contest-332/ 1. 题目一…...

autox.js在vscode(win7)与雷神模拟器上的开发环境配置
目录 下载autox.js 安装autox.js? 在电脑上搭建autox.js开发环境 安装vscode 安装autox.js插件 雷神模拟器连接vscode 设置雷神模拟器IP 设置autox.js应用IP地址等 下载autox.js 大体来说,就是一个运行在Android平台上的JavaScript 运行环境 和…...

创建阿里云物联网平台
创建阿里云物联网平台 对云平台设备创建过程做记录,懒得再看视频 文章参考视频:https://www.bilibili.com/video/BV1jP4y1E7TJ?p26&vd_source50694678ae937a743c59db6b5ff46c31 阿里云:https://www.aliyun.com 1.物联网平…...
【链式二叉树】数据结构链式二叉树的(万字详解)
前言: 在上一篇博客中,我们已经详解学习了堆的基本知识,今天带大家进入的是二叉树的另外一种存储方式----“链式二叉树”的学习,主要用到的就是“递归思想”!! 本文目录1.链式二叉树的实现1.1前置说明1.2结…...

Koa2篇-简单介绍及使用
一.简介koa2是基于 Node.js 平台的下一代 web 开发框架, 致力于成为一个更小、更富有表现力、更健壮的 Web 框架。 可以避免异步嵌套. express中间件是异步回调,Koa2原生支持async/await二.async/awaitconst { rejects } require("assert"); const { resolve } req…...
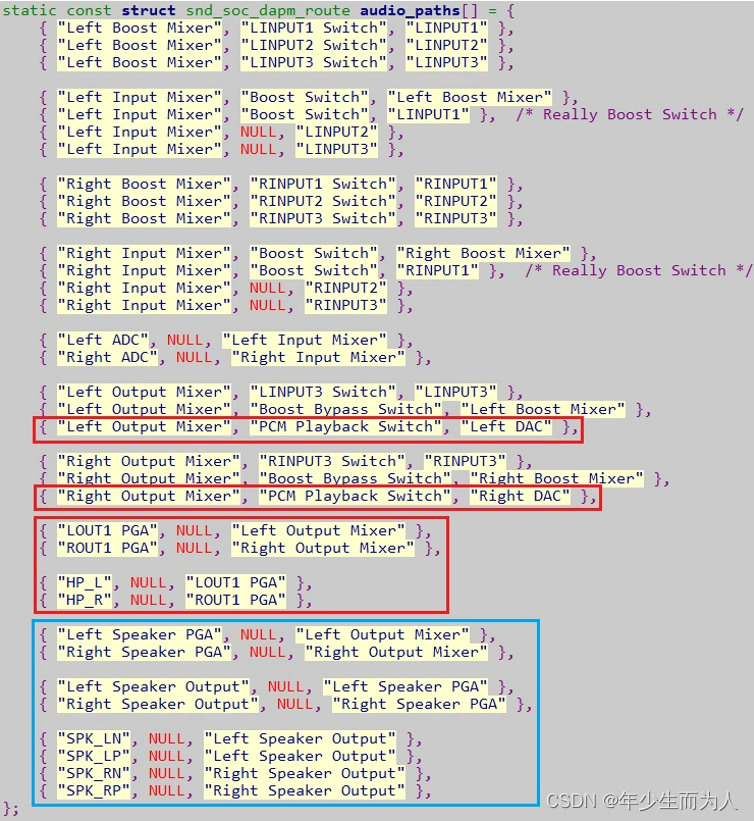
Linux ALSA 之十一:ALSA ASOC Path 完整路径追踪
ALSA ASOC Path 完整路径追踪一、ASoc Path 简介二、ASoc Path 完整路径2.1 tinymix 设置2.2 完整路径 route一、ASoc Path 简介 如前面小节所描述,ASoc 中 Machine Driver 是 platform driver 和 codec driver 的粘合剂,audio path 离不开 FE/BE/DAI l…...

【Spring Cloud总结】1、服务提供者与服务消费者快速上手
目录 文件结构 代码 1、api 1.1实体类(Dept ) 1.2数据库 2、provider 2.1 DeptController 2.2 DeptDao 2.3 DeptService 2.4 DeptServiceImpl 2.5 application.yml 3、consumer 3.1 ConfigBean 3.2 DeptConsumerController 测试 1.启动…...

若依项目学习之登录生成验证码
若依项目学习之登录生成验证码 使用DefaultKaptcha生成验证码 /*** 验证码配置* * author ruoyi*/ Configuration public class CaptchaConfig {/*** 生成字符类型的验证码**/Bean(name "captchaProducer")public DefaultKaptcha getKaptchaBean(){DefaultKaptcha…...
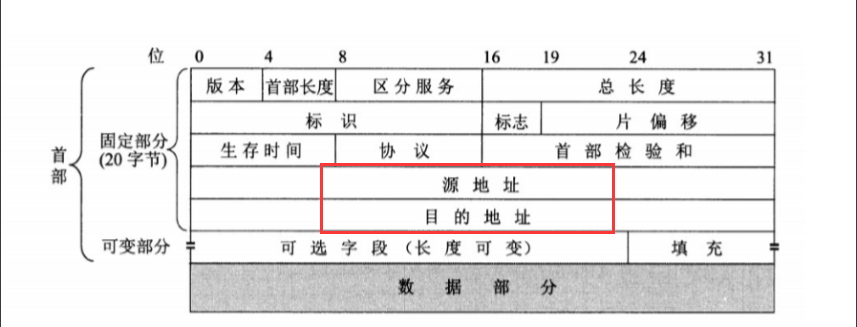
计算机网络5:数据在两台计算机之间是怎样传输的?
数据在两台计算机之间的传输总的来说包括了封装和解封两个过程 封装(5层协议) 以传送一张图片为例 **应用层:**将jpg格式的图片数据转化成计算机可以识别的0101的二进制的比特流 **传输层:**将应用层传输下来的数据进行分段&…...

就现在!为元宇宙和Web3对互联网的改造做准备!
欢迎来到Hubbleverse 🌍 关注我们 关注宇宙新鲜事 📌 预计阅读时长:8分钟 本文仅代表作者个人观点,不代表平台意见,不构成投资建议。 如今,互联网是各种不同的网站、应用程序和平台的集合。由于彼此分离…...
【mysql数据库】
目录SQL数据库分页聚合函数表跟表之间的关联关系SQL中怎么将行转成列SQL注入将一张表的部分数据更新到另一张表WHERE和HAVING的区别索引索引分类如何创建及保存MySQL的索引?怎么判断要不要加索引?索引设计原理只要创建了索引,就一定会走索引吗…...
【测试开发】web 自动化测试 --- selenium4
目录1. 什么是自动化为什么要做自动化2. 为什么选择selenium作为我使用的web自动化工具3. 什么是驱动?驱动的工作原理是什么5. 第一个自动化程序演示6. selenium基本语法6.1 定位元素的方法6.2 操作页面元素6.3 等待6.4 信息打印获取当前页面句柄,窗口切…...

猫抓:网页资源获取工具的技术革新与实战应用
猫抓:网页资源获取工具的技术革新与实战应用 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字化时代,我们每天浏览大量…...

AI写专著超实用攻略:精选工具推荐,提升写作效率与质量
第一次尝试写学术专著的挑战与AI写作工具介绍 对于第一次尝试写学术专著的研究者来说,写作的过程就像是一场充满挑战的冒险之旅,伴随着许多不确定的困难。在选题方面常常陷入困扰,难以在“具有价值”和“可行性”之间找到合适的平衡。有时选…...

提升vue开发效率的秘诀,快马平台一键生成通用组件库
最近在重构公司的中后台管理系统时,发现很多重复性的工作占用了大量开发时间。经过实践总结,我发现通过合理封装通用组件和工具集,可以显著提升Vue3项目的开发效率。今天就来分享下我的实战经验。 通用表格组件的封装 这个组件基于Element Pl…...
)
用Python手把手实现ALNS算法:从TSP路径规划到代码实战(附完整源码)
用Python手把手实现ALNS算法:从TSP路径规划到代码实战 旅行商问题(TSP)是组合优化中最经典的NP难问题之一,如何在合理时间内找到近似最优解一直是算法研究的重点。自适应大邻域搜索(ALNS)作为LNS算法的增强…...

STEP3-VL-10B开源大模型部署:从HuggingFace下载到CSDN算力上线全过程
STEP3-VL-10B开源大模型部署:从HuggingFace下载到CSDN算力上线全过程 想体验一个能看懂图片、理解图表、甚至帮你分析复杂文档的AI助手吗?今天要介绍的STEP3-VL-10B,就是一个让你用普通显卡就能跑起来的“多面手”AI模型。 你可能听说过那些…...

XXL-SSO用户画像构建:基于认证数据的用户行为分析
XXL-SSO用户画像构建:基于认证数据的用户行为分析 XXL-SSO是一款分布式单点登录框架,通过统一的认证中心实现多系统间的用户身份共享。在实际应用中,XXL-SSO积累的认证数据不仅可用于身份验证,还能通过用户画像构建实现精细化运营…...

Paperless-ng多语言文档管理终极指南:如何实现国际化支持的完整解决方案
Paperless-ng多语言文档管理终极指南:如何实现国际化支持的完整解决方案 【免费下载链接】paperless-ng A supercharged version of paperless: scan, index and archive all your physical documents 项目地址: https://gitcode.com/gh_mirrors/pa/paperless-ng …...
)
手把手教你用QQbot对接多青龙面板(含CK分配技巧)
手把手教你用QQbot对接多青龙面板(含CK分配技巧) 在自动化管理工具日益普及的今天,如何高效管理多个青龙面板成为许多开发者的痛点。本文将带你从零开始,通过QQbot实现多青龙面板的智能对接,并深入探讨Cookieÿ…...

Android购物商城APP实战:从零到一构建核心功能模块
1. 项目功能模块拆解与实现路径 一个完整的购物商城APP通常包含四大核心模块:用户系统、商品展示、购物车管理和订单处理。这就像搭建一个实体商店,需要先规划好门面(登录注册)、货架(商品展示)、购物篮&am…...

新手福音:借助快马AI生成代码,轻松入门天天直播应用开发
作为一个刚入门前端开发的新手,想尝试直播类应用开发时,面对复杂的技术栈和交互逻辑常常无从下手。最近我发现用InsCode(快马)平台可以快速生成可运行的学习项目,就以"天天直播"为例记录下我的实践过程。 项目结构设计 整个直播页面…...