[译] 大模型推理的极限:理论分析、数学建模与 CPU/GPU 实测(2024)
译者序
本文翻译自 2024 年的一篇文章: LLM inference speed of light, 分析了大模型推理的速度瓶颈及量化评估方式,并给出了一些实测数据(我们在国产模型上的实测结果也大体吻合), 对理解大模型推理内部工作机制和推理优化较有帮助。
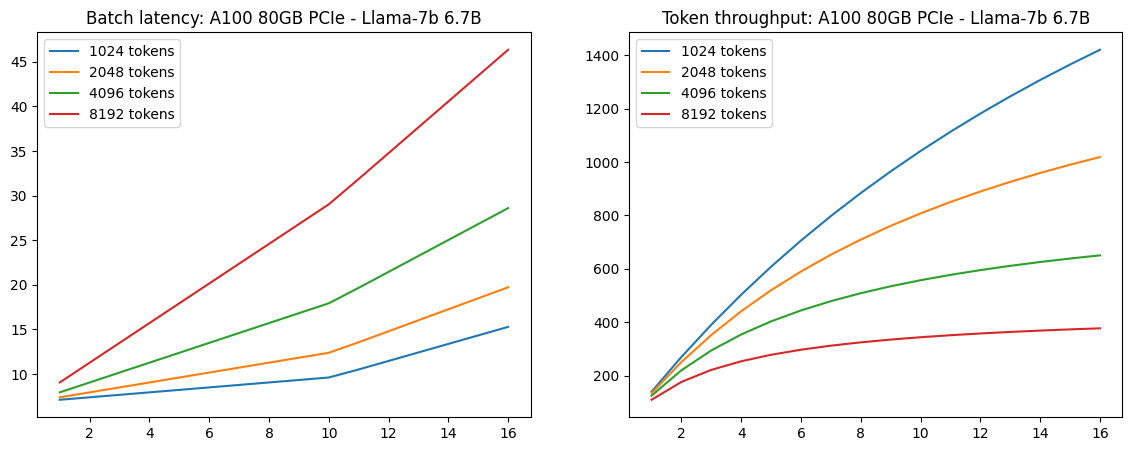
A100-80GB PICe 推理延迟与吞吐。Image Source
译者水平有限,不免存在遗漏或错误之处。如有疑问,敬请查阅原文。
以下是译文。
摘要
在开发 calm 的过程中,我们考虑的一个核心问题是: 推理的极限在哪儿?因为我们需要以此为准绳,去衡量真实推理系统的速度。
calm 是一个基于 CUDA、完全从头开始编写的轻量级 transformer-based language models 推理实现。
本文试图讨论这个极限及其影响。 如果对推导细节感兴趣,可参考这个 python notebook。
1 推理机制
1.1 transformer:逐 token 生成,无法并行
当语言模型生成文本时,它是逐个 token 进行的。 可以把语言模型(特别是 decoder-only text transformer,本文统称为 LLM) 看做是一个函数,
- 输入:一个 token
- 输出:一组概率,每个概率对应词汇表中一个 token。
- 推理程序使用概率来指导抽样,产生(从词汇表中选择)下一个 token 作为最终输出。
词汇表(vocabulary):通常由单词、单词片段、中文汉字等组成(这些都称为 token)。 vocabulary 长什么样,可以可以看一下
bert-base-chinese的词典 vocab.txt。 更多基础:
- GPT 是如何工作的:200 行 Python 代码实现一个极简 GPT(2023)。
- Transformer 是如何工作的:600 行 Python 代码实现 self-attention 和两类 Transformer(2019)
译注。
文本生成过程就是不断重复以上过程。可以看出,在生成一个文本序列时,没有并行性的可能性。
speculative execution尝试通过一个 less accurate predictor 来实现某种程度的并行,本文不讨论。
1.2 生成过程建模:矩阵乘法
广义上,当处理一个 token 时,模型执行两种类型的操作:
- 矩阵-向量乘法:一个大矩阵(例如 8192x8192)乘以一个向量,得到另一个向量,
-
attention 计算。
在生成过程中,模型不仅可以看到当前 token 的状态,还可以看到序列中所有之前 token 的内部状态 —— 这些状态被存储在一个称为
KV-cache的结构中, 它本质上是文本中每个之前位置的 key 向量和 value 向量的集合。attention 为当前 token 生成一个 query 向量,计算它与所有之前位置的 key 向量之间的点积, 然后归一化得到的一组标量,并通过对所有之前的 value 向量进行加权求和来计算一个 value 向量,使用点积得到最终得分。
This description omits multi-head attention and the details of “normalization” (softmax), but neither are critical for understanding the inference performance.
1.3 瓶颈分析
以上两步计算有一个重要的共同特征:从矩阵或 KV-cache 读取的每个元素,只需要进行非常少量的浮点运算。
- 矩阵-向量乘法对每个矩阵元素执行一次乘加运算(2 FLOPs);
- attention 对每个 key 执行一次乘加,对每个 value 执行一次乘加。
1.3.1 典型“算力-带宽”比
现代 CPU/GPU 的 ALU 操作(乘法、加法)内存 IO 速度要快得多。例如:
- AMD Ryzen 7950X:
67 GB/s内存带宽和 2735 GFLOPS,Flop:byte = 40:1 - NVIDIA GeForce RTX 4090:
1008 GB/s显存带宽和 83 TFLOPS,Flop:byte = 82:1 - NVIDIA H100 SXM:
3350 GB/s内存带宽和 67 TFLOPS, 对于矩阵乘法,tensor core 提供 ~494 TFLOPS 稠密算力,Flop:byte = 147:1。
对于 FP16/FP8 等精度较低的浮点数,比率更夸张:
- H100 TensorCore 对于 dense FP8 矩阵的理论吞吐量为 1979 TFLOPS,
FLOP:byte = 590:1。
在这些场景中,无论是否使用 TensorCore 或使用什么浮点格式,ALU 都非常充足。
1.3.2 瓶颈:访存带宽
因此,transformer 这种只需要对每个元素执行两次操作的场景,必定受到访存带宽的限制。 所以,基于下面几个因素,
- 模型配置(参数多少)
- KV-cache 大小
- 访存带宽
我们就能估计推理过程的最短耗时。 下面以 Mistral 7B 为例来具体看看。
2 以 Mistral-7B 为例,极限推理延迟的计算
2.1 参数(权重)数量的组成/计算
Mistral-7B 有 72 亿参数(所有矩阵元素的总数是 72 亿个)。 参数的组成如下:
4096 * 32000 = 131M用于 embedding 矩阵;- 4096: hidden size (tokens per hidden-vector)
- 32000: vocabulary size
矩阵-向量乘法中不会使用这整个大矩阵,每个 token 只读取这个矩阵中的一行,因此数据量相对很小,后面的带宽计算中将忽略这个;
32 * (4096 * (128 * 32 + 128 * 8 * 2) + 4096 * 128 * 32) = 1342M用于计算与 attention 相关的向量;32 * (4096 * 14336 * 3) = 5637M用于通过 feed-forward 转换 hidden states;4096 * 32000 = 131M用于将 hidden states 转换为 token 概率;这与 embedding 矩阵不同,会用于矩阵乘法。
以上加起来,大约有 7111M (~7B) “活跃”参数用于矩阵乘法。
2.2 计算一个 token 所需加载的数据量
2.2.1 总数据量
如果模型使用 FP16 作为矩阵元素的类型, 那每生成一个 token,需要加载到 ALU 上的数据量:
7111M params * 2Byte/param = ~14.2 GB
虽然计算下一个 token 时每个矩阵都可以复用,但硬件缓存的大小通常只有几十 MB, 矩阵无法放入缓存中,因此我们可以断定,这个生成(推理)过程的速度不会快于显存带宽。
attention 计算需要读取当前 token 及前面上下文中所有 tokens 对应的 KV-cache, 所以读取的数据量取决于生成新 token 时模型看到多少前面的 token, 这包括
- 系统提示词(通常对用户隐藏)
- 用户提示词
- 前面的模型输出
- 可能还包括长聊天会话中多个用户的提示词。
2.2.2 KV-cache 部分的数据量
对于 Mistral,KV-cache
- 为每层的每个 key 存储 8 个 128 元素向量,
- 为每个层的每个 value 存储 8 个 128 元素向量,
这加起来,每个 token 对应 32 * 128 * 8 * 2 = 65K 个元素; 如果 KV-cache 使用 FP16,那么对于 token number P,我们需要读取 P * 130 KB 的数据。 例如, token number 1000 将需要从 KV-cache 读取 130MB 的数据。 跟 14.2GB 这个总数据量相比,这 130MB 可以忽略不计了。
2.3 以 RTX 4090 为例,极限延迟计算
根据以上数字,现在可以很容易地计算出推理所需的最小时间。
例如,在 NVIDIA RTX 4090(1008 GB/s)上,
- 14.2GB (fp16) 需要
~14.1ms读取,因此可以预期对于位置靠前的 token, 每个 token 大约需要14.1ms(KV-cache 影响可以忽略不计)。 - 如果使用
8bit权重,需要读取 7.1GB,这需要大约7.0ms。
这些都是理论下限,代表了生成每个 token 的最小可能时间。
2.4 ChatGLM3-6B/Qwen-7B 实测推理延迟(译注)
简单的单卡推理测试,16bit 权重,平均延迟,仅供参考:
| LLM | RTX 4090 24GB (2022) | A100 80GB (2020) | V100 32GB (2017) |
|---|---|---|---|
| ChatGLM3-6B | 16ms/token | 18ms/token | 32ms/token |
| Qwen-7B | 19ms/token | 29ms/token | 41ms/token |
可以看到,单就推理速度来说,只要模型能塞进去(< 24GB),4090 与 A100 相当甚至更快,比 V100 快一倍。
说明:以上测的是 4090,不带
D(4090D)。
3 数学模型和理论极限的用途
以上根据数学建模和计算得出了一些理论极限数字,接下来看看这些理论极限有什么用。
3.1 评估推理系统好坏
要接近理论极限,需要一个高质量的软件实现,以及能够达到峰值带宽的硬件。 因此如果你的软件+硬件离理论最优很远,那肯定就有问题:可能在软件方面,也可能在硬件方面。
例如,在 RTX 4090 上 calm 使用 16 位权重时达到 ~15.4 ms/tok,使用 8 位权重时达到 ~7.8 ms/tok, 达到了理论极限的 90%。
Close, but not quite there - 100% bandwidth utilization is unfortunately very hard to get close to on NVidia GPUs for this workload. Larger GPUs like H100 are even more difficult to fully saturate; on Mixtral - this is a different architecture but it obeys the same tradeoffs for single sequence generation if you only count active parameters - calm achieves ~80% of theoretically possible performance, although large denser models like Llama 70B can get closer to the peak.
在 Apple M2 Air 上使用 CPU 推理时,calm 和 llama.cpp 只达到理论 100 GB/s 带宽的 ~65%, 然后带宽就上不去了,这暗示需要尝试 Apple iGPU 了。
3.2 指导量化
带宽与每个权重使用的 bit 数成正比;这意味着更小的权重格式(量化)能实现更低的延迟。 例如,在 RTX 4090 上 llama.cpp 使用 Mistral 7B
- 16 bit 权重:~17.1 ms/tok(82% 的峰值)
- 8.5 bit 权重:~10.3ms/tok (71% 的峰值)
- 4.5 bit 权重:~6.7ms/tok (58% 的峰值)
因此对于低延迟场景,可以考虑低精度量化。
3.3 指导优化方向
除了为推理延迟提供下限外,上述建模还表明:推理过程并未充分利用算力(ALU)。 要解决这个问题,需要重新平衡 FLOP:byte 比例, speculative decoding 等技术试图部分解决这个问题。
3.3.1 批处理 batch 1 -> N:瓶颈 访存带宽 -> 算力
这里再另一种场景:多用户场景。注意到,
- 当多个用户请求同时处理时,我们用相同的矩阵同时执行多个矩阵-向量乘法, 这里可以将多个矩阵-向量乘法变成一个矩阵-矩阵乘法。
- 对于足够大的矩阵来说,只要矩阵-矩阵乘法实现得当,速度就比访存 IO 快,
因此这种场景下,瓶颈不再是访存 IO,而是算力(ALU)。这就是为什么这种 ALU:byte 不平衡对于生产推理系统不是关键问题 —— 当使用 ChatGPT 时,你的请求与同一 GPU 上许多其他用户的请求并发评估,GPU 显存带宽利用更加高效。
3.3.2 批处理无法改善所需加载的 KV-cache 数据量
批处理通常不会减轻 KV-cache 带宽(除非多个请求共享非常大的前缀),因为 KV-cache 大小和带宽随请求数量的增加而增加,而不像权重矩阵保持不变。
像 Mistral 这样的混合专家模型(MoE)scaling 特性稍有不同:batching initially only increases the bandwidth required, but once the expert utilization becomes significant the inference becomes increasingly ALU bound.
3.4 硬件相对推理速度评估
带宽是评估推理性能的关键指标,对于模型变化/设备类型或架构来说是一个恒定的, 因此即使无法使用 batch processing,也可以用它来评估你用的硬件。
例如,NVIDIA RTX 4080 有 716 GB/s 带宽,所以可以预期它的推理速度是 RTX 4090 的 ~70% —— 注意,游戏、光线追踪或推理其他类型的神经网络等方面,相对性能可能与此不同!
4 GQA (group query attention) 的影响
Mistral-7B 是一个非常平衡的模型;在上面的所有计算中,几乎都能忽略 KV-cache 部分的 IO 开销。 这背后的原因:
- 较短的上下文(Mistral-7B 使用 windowed attention,限制 4096 token 的窗口),
- 使用了 GQA,这个是更重要的原因。
LLaMA 2:开放基础和微调聊天模型(Meta/Facebook,2023) 也使用了 GQA。
4.1 GQA 为什么能减少带宽
在 GQA 中(with a 4x ratio),为了得到 attention 的 4 个点积,
- 不是使用 4 个 query 向量并分别与 4 个相应的 key 向量计算点积,
- 而是只取一个 key 向量,然后执行 4 个点积。
这能够减少 KV-cache 的大小和所需带宽,也在某种程度上重新平衡了 ALU:bandwidth 比例。
4.2 有无 GQA 的数据量对比
这对于 KV-cache 内存大小也很关键,不过,这可能对短上下文模型不太明显:
- 4096 token 上下文的 Mistral 需要 0.5GiB,
- 没有 GQA 的可比模型(如 Llama 7B)“只需要”2 GiB。
让我们看看一个最近不使用 GQA 的模型,Cohere 的 Command-R。
Command-R has a large vocab (256K) and large hidden state (8192) so it spends a whopping 2B parameters on embeddings, but it reuses the same matrix for embedding and classification so we don’t need to exclude this from the inference bandwidth calculation.
模型本身有大约 35b 参数,所以以 16 位/权重计算,我们在推理期间需要为每个 token 读取 70 GB 的权重。 对于每个 token ,它需要在 KV-cache 中存储 40 * 128 * 64 * 2 = 655K 元素,以 16 位/元素计算是每个 token 1.3 MB。
因此,一个 4096 token 的上下文将需要大约 5.3GB; 与 ~70 GB 的权重相比,这已经相当显著了。然而,如果考虑到 Cohere 的模型宣传有 200K token 上下文窗口 —— 计算最后一个 token 需要读取 260 GB(还需要 260GB 的显存来存储它)!
4.3 多用户场景下 KV-cache 占用的显存规模
这么大的模型,典型的生产环境配置(单用户),
weights通常使用4bit量化(通常的实现占用 ~4.5bit/权重)KV-cache可能会使用8bit(FP8)值。
如果我们“保守地”假设上下文为 100K,则
- 模型权重占 ~19.7GB
- KV-cache 占
~65GB
计算到最后一个 token 时,我们需要从内存中读取这么大的数据。 可以看到,突然之间,attention 计算部分的数据量(最终转变成耗时)从微不足道变成了占 ~75%!
虽然 100K 上下文可能看起来有点极端,但在短上下文+多用户场景中,情况也是类似的:
- 批处理优化将多次矩阵-向量乘法变成了一次矩阵-矩阵乘法(为一批用户请求读取一次模型权重),瓶颈来到算力(ALU),
- 但每个用户请求通常都有自己的 KV-cache,
因此最终的 attention 仍然受访存带宽限制,并且需要大量内存/显存才能将所有用户请求放到单个节点!
4.4 GQA:减小从 KV-cache 加载的数据量
如果模型使用 4x GQA,KV-cache 的大小和所需带宽将会变成原来的 1/4。
对于 100k+ token 的上下文场景,虽然 KV-cache 的开销仍然很大(65GB -> 16GB+),但已经进入实用范围。
4.5 GQA 的问题
对于 Cohere 的目标使用场景,引入 GQA 可能会导致模型质量有下降,具体得看他们的技术报告。
但是,纯粹从成本/性能角度来看,每个基于 transformer 的 LLM 都需要评估是否能引入 GQA,因为收益太大了。
5 总结
对于大模型推理场景,计算和访存的次数是已知的,因此可以进行数学建模,计算理论极限。 这非常有用,不仅可以用来验证推理系统的性能, 而且能预测架构变化带来的影响。
相关文章:
[译] 大模型推理的极限:理论分析、数学建模与 CPU/GPU 实测(2024)
译者序 本文翻译自 2024 年的一篇文章: LLM inference speed of light, 分析了大模型推理的速度瓶颈及量化评估方式,并给出了一些实测数据(我们在国产模型上的实测结果也大体吻合), 对理解大模型推理内部工…...

vue3 响应式 API:readonly() 与 shallowReadonly()
readonly() readonly()是一个用于创建只读代理对象的函数。它接受一个对象 (不论是响应式还是普通的) 或是一个 ref,返回一个原值的只读代理。 类型 function readonly<T extends object>(target: T ): DeepReadonly<UnwrapNestedRefs<T>>以下…...

迁移学习与知识蒸馏对比
应用场景不同 迁移学习:通常用于不同但相关的任务之间的知识迁移。特别是当目标任务的数据量不足时,可以从一个已经在大规模数据上训练好的模型中获取有用的特征或参数。典型场景包括计算机视觉任务,比如你在ImageNet上训练了一个ResNet&…...

【Java-反射】
什么是反射? JAVA反射机制是在运行状态中,创建任意一个类,能获取这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言…...
移动UI设计要求越来越高,最为设计师应如何迎头赶上
一、引言 在当今数字化高速发展的时代,移动设备已经成为人们生活中不可或缺的一部分。随着科技的不断进步和用户需求的日益增长,移动 UI 设计的要求也越来越高。作为移动 UI 设计师,我们面临着巨大的挑战,需要不断提升自己的能力…...

大数据-121 - Flink Time Watermark 详解 附带示例详解
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

国行 iPhone 15 Pro 开启苹果 Apple Intelligence 教程
一、前言苹果在 iOS 18.1 测试版上正式开启了 Apple Intelligence 的内测,但国行设备因政策原因不支持,且国行设备在硬件上被锁定。不过,我们可以通过一些方法来破解国行 iPhone 15 Pro,使其能够开启 Apple Intelligence。 以下是…...

conda、anaconda、pip、torch、pytorch、tensorflow到底是什么东西?(转载自本人的知乎回答)
转载自本人的知乎回答(截止2024年9月,1700赞同,2400收藏) https://www.zhihu.com/question/566592612/answer/3063465880 如果你是一个大四的CS准研究生回去补基础课,假如是科班CS甚至科班EE的话那你基础也太差了。你…...

数据库系列之GaussDB数据库中逻辑对象关系简析
初次接触openGauss或GaussDB数据库的逻辑对象,被其中的表空间、数据库、schema和用户之间的关系,以及授权管理困惑住了,与熟悉的MySQL数据库的逻辑对象又有明显的不同。本文旨在简要梳理下GaussDB数据库逻辑对象之间的关系,以加深…...

如何进行不同数据库的集群操作?--从部署谈起,今天来看MySQL和NoSql数据库Redis的集群
篇幅较长,主要分为mysql和Redis两部分。找想要的部分可见目录食用。。 目录 什么是集群?为什么要集群? 1.1 数据库主要分为两大类:关系型数据库与 NoSQL 数据库 1.2 为什么还要用 NoSQL 数据库呢? ----------------…...

第 6 章图像聚类
本章将介绍几种聚类方法,并展示如何利用它们对图像进行聚类,从而寻找相似的图像组。聚类可以用于识别、划分图像数据集,组织与导航。此外,我们还会对聚类后的图像进行相似性可视化。 6.1 K-means聚类 K-means 是一种将输入数据划…...

HC-SR501人体红外传感器详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 3.工作原理介绍 三、程序设计 main.c文件 body_hw.h文件 body_hw.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 HC-SR501人体红外模块是基于红外线技术的自动控制模块,采用德国原装进口LHI77…...

关于武汉芯景科技有限公司的IIC电平转换芯片XJ9517开发指南(兼容PCF9517)
一、芯片引脚介绍 1.芯片引脚 2.引脚描述 二、系统结构图 三、功能描述 1.电平转换 2.芯片使能/失能 EN 引脚为高电平有效,内部上拉至 VCC(B),允许用户选择中继器何时有效。这可用于在上电时隔离行为不良的从机,直到…...
、getchar()、gets())
C语言:scanf()、getchar()、gets()
一、gets() gets()能吸收空格和换行,因此输入后,对输出要去除空格 和换行\n; #include <stdio.h> #include <string.h> int main() {char str[1000];int count0;gets(str);for(int i0;i<strlen(str);i)count;printf("%s\n",str…...

基于MATLAB的全景图像拼接系统实现
简要的论文框架和技术思路 摘要 本文深入探讨了基于MATLAB平台的块匹配全景图像拼接系统的设计与实现。通过详细解析SIFT/SURF特征提取、RANSAC变换估计、APAP局部对齐、图割算法拼接缝选择及multi-band blending图像融合等关键技术,构建了高效且高质量的全景图像…...

AI模型“减肥”风潮:量化究竟带来了什么?
量化对大模型的影响是什么 ©作者|YXFFF 来源|神州问学 引言 大模型在NLP和CV领域的广泛应用中展现了强大的能力,但随着模型规模的扩大,对计算和存储资源的需求也急剧增加,特别是在资源受限的设备上面临挑战。量化技术通过将模型参数和…...

第四届“长城杯”网络安全大赛 暨京津冀网络安全技能竞赛(初赛) 全方向 题解WriteUp
战队名称:TeamGipsy 战队排名:18 SQLUP 题目描述:a website developed by a novice developer. 开题,是个登录界面。 账号admin,随便什么密码都能登录 点击头像可以进行文件上传 先简单上传个木马试试 测一下&…...

ETCD的备份和恢复
一、引言 ETCD是一个高度可用的键值存储系统,被广泛应用于Kubernetes等分布式系统中以存储关键配置数据和服务发现信息。由于ETCD的重要性,确保其数据的安全性和可靠性至关重要。本文将介绍ETCD备份与恢复的基础知识、常用方法及最佳实践。 二、概述 …...

Linux Makefile文本处理函数知识详解
1.Makefile函数 GNU make 提供了大量的函数用来处理文件名、变量、文本和命令。通过这些函数,用户可以节省很多精力,编写出更加灵活和健壮的Makefile。函数的使用和变量引用的展开方式相同: $(function arguments)${function arguments}关于…...

Rust的数据类型
【图书介绍】《Rust编程与项目实战》-CSDN博客 《Rust编程与项目实战》(朱文伟,李建英)【摘要 书评 试读】- 京东图书 (jd.com) Rust到底值不值得学,之一 -CSDN博客 Rust到底值不值得学,之二-CSDN博客 3.5 数据类型的定义和分类 在Rust…...
)
医疗票据 OCR 识别 API 多场景落地指南:医保结算 + 商保理赔 + 医疗信息化(附 Python/Java 完整示例)
《医疗 OCR 识别 API 怎么选?(报告单 / 发票 / 检测单)》医疗票据 OCR 识别 API 多场景落地指南:医保结算 商保理赔 医疗信息化(附 Python/Java 完整示例) 导语:每天上万张医疗票据ÿ…...

AI 应用开发到底在开发什么?
很多人刚开始接触 AI 应用开发时,会把它理解成“调用一个大模型接口”。这个理解不能说错,但太浅了。真正能在公司里上线、能产生价值的 AI 应用,往往不是一个简单的聊天框,而是一套完整系统。它要接用户入口,要接业务…...

Wannakey:无需支付赎金,从内存中恢复WannaCry加密文件
Wannakey:无需支付赎金,从内存中恢复WannaCry加密文件 【免费下载链接】wannakey Wannacry in-memory key recovery 项目地址: https://gitcode.com/gh_mirrors/wa/wannakey Wannakey是一款专为WannaCry勒索软件受害者设计的内存密钥恢复工具&…...

如何高效管理华硕笔记本性能:G-Helper轻量级控制工具完整指南
如何高效管理华硕笔记本性能:G-Helper轻量级控制工具完整指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenb…...

5步搭建私人云游戏服务器:Sunshine游戏串流完全指南
5步搭建私人云游戏服务器:Sunshine游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经想过在客厅电视上玩电脑游戏,或者在平板上继…...

3步搞定M3U8视频下载:告别在线播放限制的终极方案
3步搞定M3U8视频下载:告别在线播放限制的终极方案 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 你是否曾遇到过这样的烦恼?在线观看的视频无法保存&…...
)
Flink架构与集群部署(一)
Apache Flink架构Flink组件栈在Flink的整个软件架构体系中,同样遵循这分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富且友好的接口。上图是Flink基本组件栈,从上图可以看出整个Flink的架构体系可…...

Unity本地化工作流:基于ULP的可维护多语言工程实践
1. 这不是“加个插件就完事”的翻译方案,而是Unity项目里真正能落地的本地化工作流 “Unity游戏自动翻译插件”——光看标题,很多人第一反应是:拖进Project窗口、点几下按钮、导出Excel、等AI吐出译文、再一键回填……然后就上线多语言了&…...

Windows curl证书错误SEC_E_UNTRUSTED_ROOT解决方案
1. 这个错误不是curl的问题,而是Windows在替你“把关” 你在Windows命令行里敲下 curl https://api.example.com ,结果弹出一串红色报错: curl: (35) schannel: next InitializeSecurityContext failed: Unknown error (0x80092012) - T…...

QuantConnect Lean引擎架构深度剖析:构建模块化量化交易系统的技术实现
QuantConnect Lean引擎架构深度剖析:构建模块化量化交易系统的技术实现 【免费下载链接】Lean Lean Algorithmic Trading Engine by QuantConnect (Python, C#) 项目地址: https://gitcode.com/GitHub_Trending/le/Lean QuantConnect Lean引擎是一个开源的量…...