NLTK:Python自然语言处理工具包及其参数使用详解
NLTK(Natural Language Toolkit)是一个领先的平台,用于构建处理人类语言数据的Python程序。它提供了易于使用的接口,用于超过50个语料库和词汇资源,如WordNet,以及一套文本处理库,用于分类、标记化、词干提取、标记、解析和语义推理。
NLTK的主要功能
- 语料库访问:提供多种语料库,如布朗语料库、Gutenberg语料库等。
- 文本预处理:包括文本清洗、标准化、分词等。
- 分词:将文本分割成单独的词语或符号。
- 词性标注:为文本中的每个词赋予相应的词性标签。
- 命名实体识别:从文本中识别特定类型的命名实体,如人名、地名等。
- 文本分类:自动将文本归类到特定类别。
- 语法分析:将句子解析成语法树。
常用NLTK函数及其参数
nltk.download()
下载所需的语料库和资源。
packages: 要下载的资源列表,如'punkt'、'averaged_perceptron_tagger'等。
nltk.word_tokenize(text, language='english')
分词,将文本分割成单独的词语。
text: 要分词的文本字符串。language: 使用的语言,默认为英语。
nltk.pos_tag(tokens, tag_set=None)
词性标注,为分词后的每个词赋予词性标签。
tokens: 分词后的词列表。tag_set: 使用的词性标记集,默认为None。
nltk.ne_chunk(tagged_tokens, binary=False)
命名实体识别,识别文本中的命名实体。
tagged_tokens: 已词性标注的词列表。binary: 是否返回二进制树。
nltk.classify.apply_features(features, training, search=None)
应用特征提取,用于文本分类。
features: 特征提取函数。training: 用于训练的特征集。search: 用于搜索的特征集。
nltk.classify.NaiveBayesClassifier.train(train_data)
训练朴素贝叶斯分类器。
train_data: 用于训练的数据,格式为[(features, label), ...]。
nltk.classify.NaiveBayesClassifier.classify(features)
使用训练好的分类器对文本进行分类。
features: 要分类的特征集。
示例
以下是一个使用NLTK进行文本处理的示例:
import nltk
from nltk.corpus import treebank
from nltk.tokenize import PunktSentenceTokenizer
from nltk import data# 下载所需的语料库
nltk.download('punkt')
data.path.append("/path/to/nltk_data")# 分词和词性标注
sentence = "At eight o'clock on Thursday morning, Arthur didn't feel very good."
tokens = nltk.word_tokenize(sentence)
tagged = nltk.pos_tag(tokens)# 命名实体识别
t = treebank.parsed_sents('wsj_0001.mrg')[0]
entities = nltk.ne_chunk(tagged)# 打印结果
print("Tokens:", tokens)
print("Tagged:", tagged)
print("Entities:", entities)# 文本分类
# 假设我们有一些训练数据
training_data = [(['the', 'quick', 'brown', 'fox'], 'fox'),(['the', 'lazy', 'dog'], 'dog')
]# 特征提取函数
def extract_features(words):return dict([word]=True for word in words)# 应用特征提取
featuresets = [(extract_features(sentence), category) for (sentence, category) in training_data]# 训练朴素贝叶斯分类器
classifier = nltk.NaiveBayesClassifier.train(featuresets)# 对新句子进行分类
new_sentence = ['the', 'quick', 'brown', 'fox', 'jumps']
print("Classify:", classifier.classify(extract_features(new_sentence)))
在这个示例中,我们首先下载了所需的语料库,然后对一段文本进行了分词和词性标注。接着,我们使用treebank语料库中的解析句子,并进行了命名实体识别。最后,我们创建了一些训练数据,定义了一个特征提取函数,应用了特征提取,训练了一个朴素贝叶斯分类器,并对一个新句子进行了分类。
相关文章:

NLTK:Python自然语言处理工具包及其参数使用详解
NLTK(Natural Language Toolkit)是一个领先的平台,用于构建处理人类语言数据的Python程序。它提供了易于使用的接口,用于超过50个语料库和词汇资源,如WordNet,以及一套文本处理库,用于分类、标记…...

php 之 php-fpm 和 nginx结合使用
php-fpm php-fpm是php面试必问的一个小考点,聊这个之前还是要铺垫一下,cgi 和 fastcgi。 CGI,通用网关接口,用于WEB服务器(比如 nginx)和应用程序(php)间的交互,简单的…...
数学建模笔记——TOPSIS[优劣解距离]法
数学建模笔记——TOPSIS[优劣解距离法] TOPSIS(优劣解距离)法1. 基本概念2. 模型原理3. 基本步骤4. 典型例题4.1 矩阵正向化4.2 正向矩阵标准化4.3 计算得分并归一化4.4 python代码实现 TOPSIS(优劣解距离)法 1. 基本概念 C. L.Hwang和 K.Yoon于1981年首次提出 TOPSIS(Techni…...

证书学习(四)X.509数字证书整理
目录 一、X.509证书 介绍1.1 什么是 X.509证书?1.2 什么是 X.509标准?1.3 什么是 PKI?二、X.509证书 工作原理2.1 证书认证机构(CA)2.1 PKI 的基础——加密算法2.2 PKI 证书编码三、X.509证书 结构3.1 证书字段3.2 证书扩展背景: 我们在日常的开发过程中,经常会遇到各种…...

氚云,低代码领风者如何破解行业的“中式焦虑”?
To B生意“难做”,很多公司的苦恼都难以掩盖。 上半年,一个“中国软件行业全军覆没”的帖子引发热烈讨论,评论竟是赞同的居多。那些以实现上市为目标的SaaS公司,或者已经上市的、主营业务为To B的企业,其整体的业绩状…...

“深入解析:MySQL半同步复制的配置指南与实践技巧“
本次配置是在已搭建好主从复制的架构中进行配置 配置环境 操作系统 master节点 slave节点 centos7 8.0.37 8.0.37 配置半同步复制 配置master 安装master半同步复制插件 INSTALL PLUGIN rpl_semi_sync_source SONAME semisync_source.so; 在MySQL的配置文件中添加配置…...

第四届长城杯部分wp
还是太菜了,要经常练了 1.BrickGame 读源码可以看到时间的值是由js设定的,所以控制台将timeleft的时间改成999999 通过游戏就可以得到flag 2.SQLUP 一道文件上传的题目,在登陆页面我用admin和1登陆成功了,但是按照正常的应该是…...
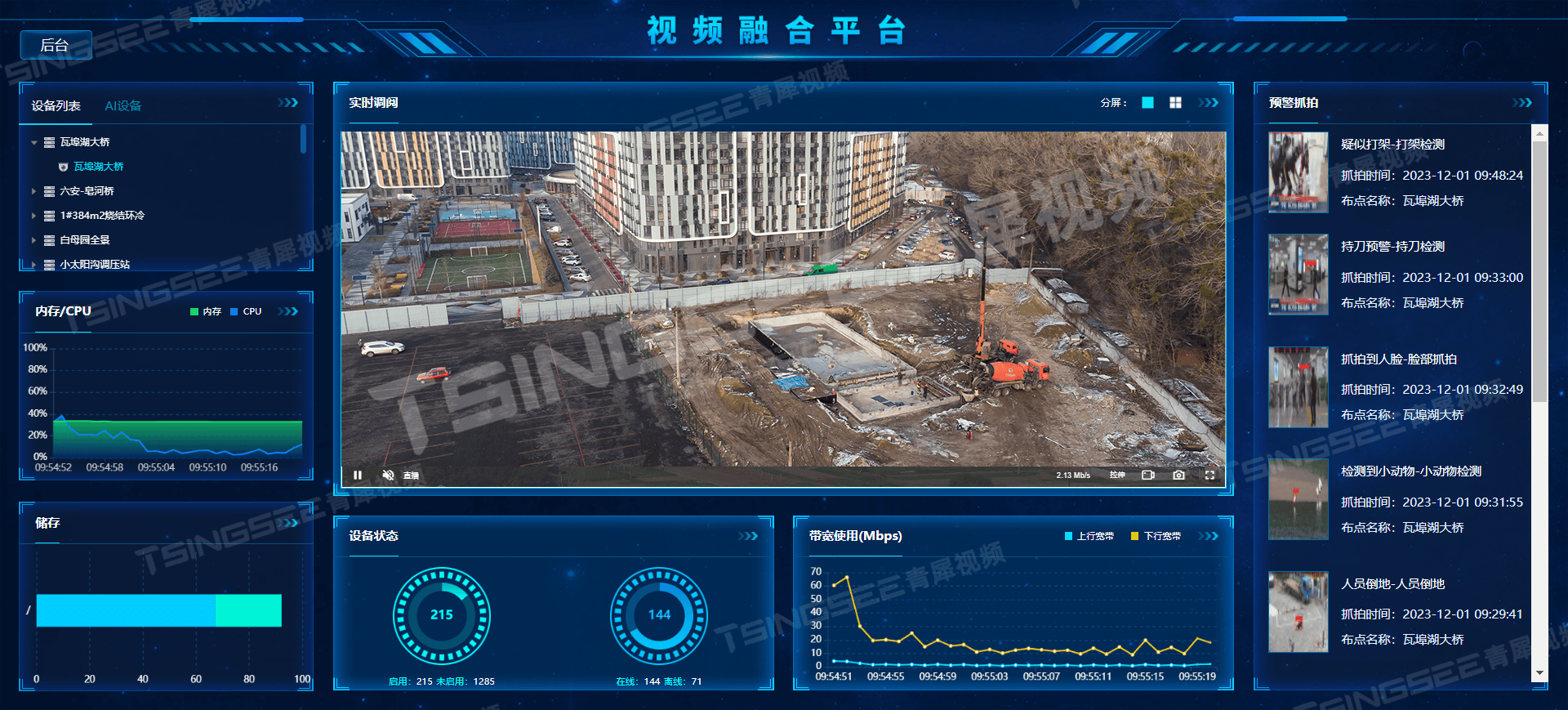
打造无死角安防网:EasyCVR平台如何助力智慧警务实现视频+AI的全面覆盖
一、背景概述 随着科技的飞速发展,智慧城市建设已成为提升社会治理能力、增强公共安全水平的重要途径。在警务领域,智慧警务作为智慧城市的重要组成部分,正通过融合视频监控技术与人工智能(AI)解决方案,实…...

批发订货系统源码怎么弄 门店订货系统小程序价格
上线批发订货系统可以显著提升业务效率和管理水平,它能够帮助企业自动化处理订单、实时跟踪库存、简化订单管理、生成数据报表…这些优势能最终帮助你降低成本、提高效率,提升业务竞争力。今天,小编为您分享批发订货系统源码怎么弄。大家点赞…...

终端安全如何防护?一文为你揭晓答案!
终端安全防护是确保组织内部网络及其连接设备免受威胁的关键措施。 以下是终端安全防护的一些核心方法: 1. 资产管理与识别 摸清家底:识别所有连接到网络的终端设备及其状态,包括硬件和软件配置。 资产分类:确定哪些资产最为关…...
价值流架构指南:构建业务创新与竞争优势的全面方法论
如何通过价值流引领企业数字化转型? 在当前数字化转型的背景下,企业面临的挑战日益复杂化:如何更快响应市场变化?如何优化资源配置提升效率?如何确保客户体验始终处于行业领先?《价值流指南》由The Open G…...

知识蒸馏(Knowledge Distillation)
Distilling the Knowledge in a Neural Network 知识蒸馏原理 1、Summarize 知识蒸馏技术 通过从大型的教师模型向小型的学生模型转移知识来实现模型压缩和优化。 知识蒸馏的核心思想是 利用教师模型在大量数据上积累的丰富知识,通过特定的蒸馏算法,使…...

【zsh】Linux离线安装zsh
首先从GitHub下载源码,然后编译源码后安装。以下是具体的步骤: 1. 下载并解压源码 首先,从GitHub下载了zsh源码的压缩包并解压到某个目录: tar -xvf zsh-<version>.tar.gz cd zsh-<version>2. 安装编译所需的依赖&…...
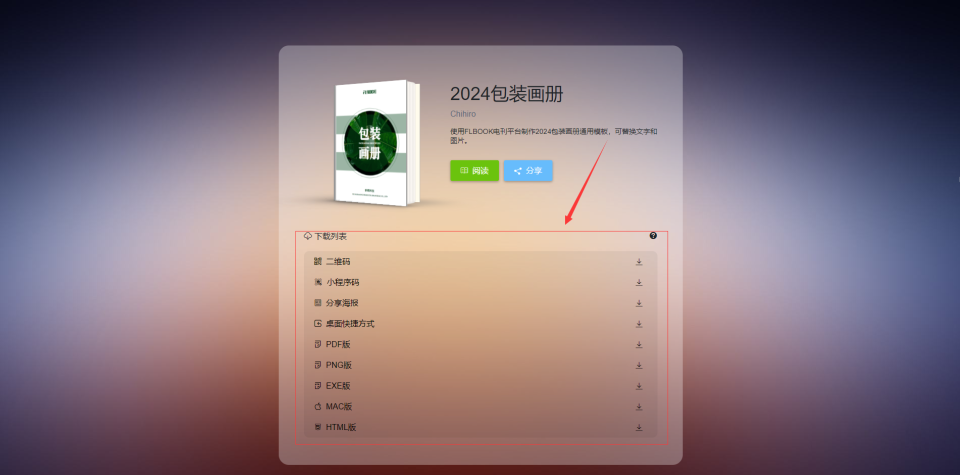
一款好用的电子样本册转换器
在数字化时代,电子样本册已成为各行各业必备的工具。一款好用的电子样本册转换器,可以让你在繁杂的资料管理中轻松解脱。今天,就为大家推荐一款实用的电子样本册转换神器,让你的工作效率翻倍! 工具推荐:FLB…...
TDesign:腾讯的开源企业级前端框架,能和ant-design一战吗?
TDesign 是一套拥有完整的 设计价值观 和 视觉风格指南 的企业级设计体系,同时提供了丰富的 设计资源。TDesign 在设计体系基础上产出基于 Vue、React、小程序等业界主流技术栈的组件库解决方案。是不是有点晚了? 请大家各抒己见。...

大语言模型LLM权重4bit向量量化(Vector Quantization)/查找表量化基本原理
参考 https://apple.github.io/coremltools/docs-guides/source/opt-palettization-overview.html https://apple.github.io/coremltools/docs-guides/source/opt-palettization-algos.html Apple Intelligence Foundation Language Models 苹果向量量化: DKM:…...

学习threejs,创建立方体,并执行旋转动画
文章目录 一、前言二、代码示例三、总结 一、前言 本文基于threejs,实现立方体的创建,并加入立方体旋转动画 二、代码示例 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>l…...

2024网安周今日开幕,亚信安全亮相30城
2024年国家网络安全宣传周今天在广州拉开帷幕。今年网安周继续以“网络安全为人民,网络安全靠人民”为主题。2024年国家网络安全宣传周涵盖了1场开幕式、1场高峰论坛、5个重要活动、15场分论坛/座谈会/闭门会、6个主题日活动和网络安全“六进”活动。亚信安全出席20…...

Unity Qframework 加载UI的方式
如图所示 : // Resources 加载 UIKit.OpenPanel("Resources/UIPrefab/UIMenuPanel"); // Resources 加载并传递数据 UIKit.OpenPanel<UIMenuPanel>(new UIMenuPanelData() { m_Modle this.m_Modle }, prefabName: "UIPrefab/UIMenuPanel"); …...

使用 Python 创建自动抽奖程序
介绍 自动抽奖程序在各种场景中非常有用,比如社交媒体活动、公司抽奖、在线课程奖励等。在这篇博文中,我们将学习如何使用 Python 创建一个自动抽奖程序。我们将涵盖以下内容: 需求分析环境设置基本抽奖逻辑图形用户界面(GUI&am…...

咖啡一杯,Token 无限,Real-Time Cafe 深圳站来了!新增「硬件晒晒桌」与「AI 桌游试玩桌」
咖啡一杯,Token 无限——「Real-Time Cafe」是一个让开发者聚在一起实时 coding、实时 debug、实时互动的咖啡馆快闪计划。 Real-Time Cafe 深圳站来了!就在本周日 5 月 24 日下午。 本站特设「硬件晒晒桌」与「AI 桌游试玩桌」——带上你的电子宠物、…...

WeChatFerry微信机器人完整指南:构建企业级智能自动化助手
WeChatFerry微信机器人完整指南:构建企业级智能自动化助手 【免费下载链接】WeChatFerry 微信机器人,可接入DeepSeek、Gemini、ChatGPT、ChatGLM、讯飞星火、Tigerbot等大模型。微信 hook WeChat Robot Hook. 项目地址: https://gitcode.com/GitHub_Tr…...

3步告别GitHub英文界面:GitHub中文化插件终极解决方案
3步告别GitHub英文界面:GitHub中文化插件终极解决方案 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 还在为GitHub的英文…...

本地 AI 编码助手从 0 配起来:先选模型,再接 Ollama、VS Code、Claude Code 和 Codex
配本地 AI 编码助手,我现在最不建议的做法,就是打开 Ollama 以后直接搜一个最大模型下载。 这条路我踩过。 模型能跑起来,不代表能写代码。能写一个函数,不代表能进项目改文件。能在终端里回一句话,也不代表 Claude …...

AI低代码产品,从“拖拽搭应用“到“对话即开发“,其中最关键的能力是什么?
作为一名在企业数字化一线摸爬滚打了10多年的项目负责人。这些年,我亲眼见证了低代码从小众工具变成企业标配的全过程。在2026年的当下,AI大模型现已全面融入低代码产品的底层,"对话生成应用"也已从概念名词变为了实际应用。但与此…...

F1C100s移植LVGL 8.2避坑指南:从Makefile修改到双缓冲配置
F1C100s移植LVGL 8.2实战手册:从编译优化到显示性能调优 在嵌入式Linux系统开发中,图形用户界面(GUI)的实现往往是最具挑战性的环节之一。对于资源受限的全志F1C100s芯片而言,如何在有限的RAM和CPU性能下实现流畅的图形交互,LVGL(…...

实战指南:5个关键技术揭秘PUBG罗技鼠标宏后坐力控制脚本
实战指南:5个关键技术揭秘PUBG罗技鼠标宏后坐力控制脚本 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg logitech-pubg是一个针对《绝…...

独立站 AI 智能推荐商品功能落地实操:从 0 到 1 提升转化与客单价
在独立站运营中,流量成本持续走高,很多站点陷入 “有流量、没转化、客单价低” 的困境。2026 年跨境电商数据显示,部署 AI 智能推荐的独立站,平均转化率提升 4.7%-15%,客单价上涨 20%-30%,复购率提高 18% 以…...

终极QR码修复指南:如何用QrazyBox免费恢复损坏的二维码
终极QR码修复指南:如何用QrazyBox免费恢复损坏的二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾遇到过重要的二维码因为打印模糊、水渍污染或物理磨损而无法扫描&a…...

article-extractor项目架构解析:模块化设计与可扩展性指南
article-extractor项目架构解析:模块化设计与可扩展性指南 【免费下载链接】article-extractor To extract main article from given URL with Node.js 项目地址: https://gitcode.com/gh_mirrors/ar/article-extractor article-extractor是一个强大的Node.j…...